자동 변수 가공¶
Driverless AI는 실험의 모델 구축 프로세스의 일부로 자동 변수 가공을 수행합니다. 새로운 기능은 데이터 세트 열에서 transformations 및/또는 interactions 을 수행하여 생성됩니다. Driverless가 선정한 기본 트랜스포머는 실험의 해석 가능성 설정에 의존합니다. 더 해석 가능한 모델의 경우 더 간단한 변환이 적용됩니다. 이는 실험의 미리보기에서 확인할 수 있습니다. include/exclude transformers 와 같은 변수 가공 상세 설정을 사용하여 적용한 변환을 제어할 수 있습니다. 비닝, 대상 인코딩, 증거 가중치, 클러스터링, 차원 축소, 자동 인코더, Tensorflow, NLP BERT 모델, 지연, 집계와 같은 트랜스포머를 사용하여 기능 상호 작용을 생성할 수 있습니다.
기능 생성 및 선택은 근본적으로 진화적이며(이전 반복의 가변적 중요성에 기초) genetic algorithm 을 사용하여 실험/데이터 세트에 대한 최적의 기능 변환 및 모델 매개변수 집합을 찾습니다.
생성(변환 적용)되고 실험에 사용된 기능에 대한 정보는 실험의 Autodoc 에서 얻을 수 있습니다.
변수 가공 활동과 진화는 실험 전문가 패널의 특성 설정 에서 제어할 수 있습니다.
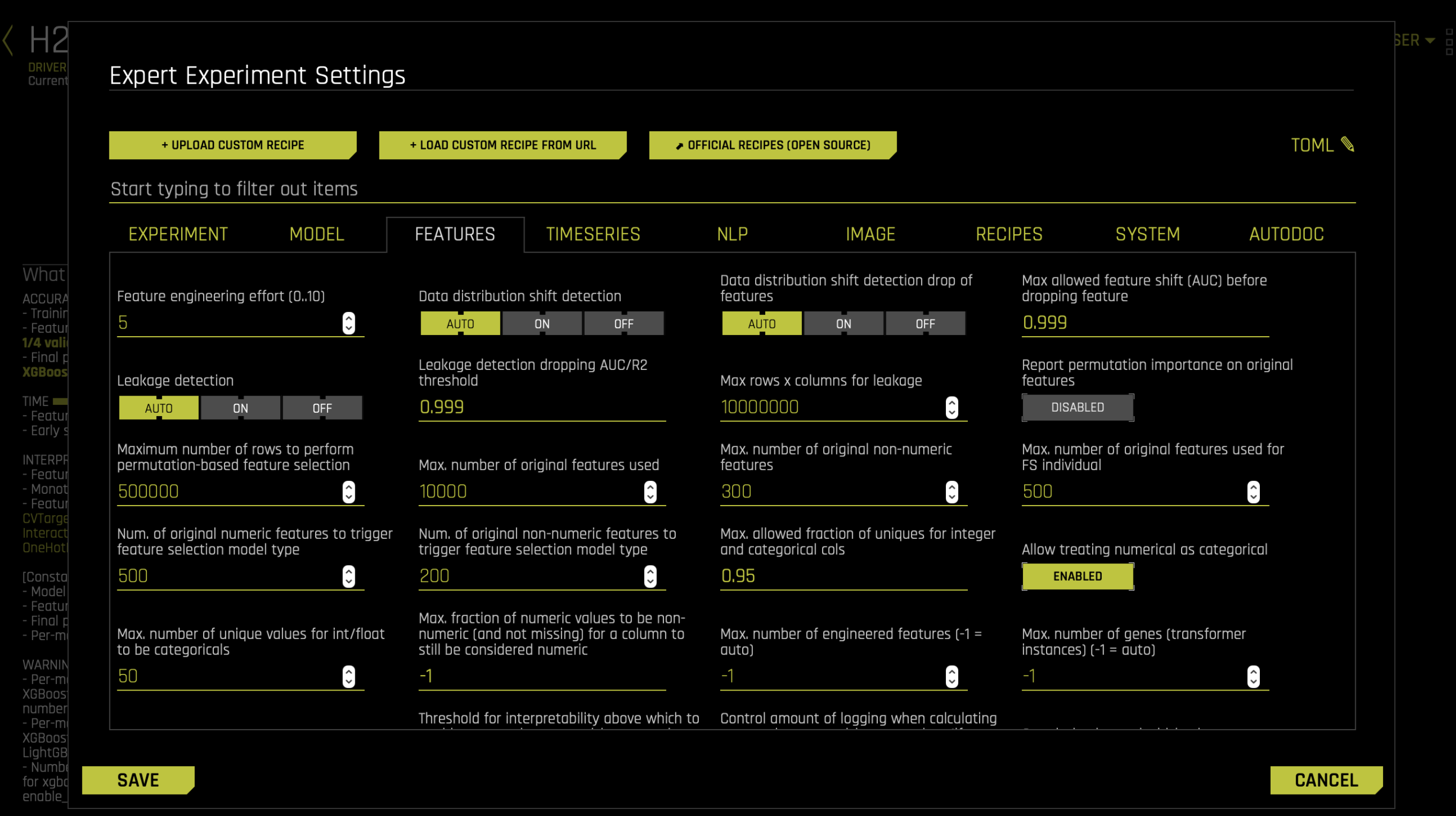
또한 트랜스포머에 내장된 Driverless AI에 추가로 포함할 자신의 custom transformers 를 업로드할 수 있습니다. 일부 오픈 소스 사용자 정의 트랜스포머는 Driverless AI 오픈 소스 custom recipes 에서 얻을 수 있습니다.
트랜스포머 포함은 실험 전문가 패널의 레시피 탭에서 제어할 수 있습니다.
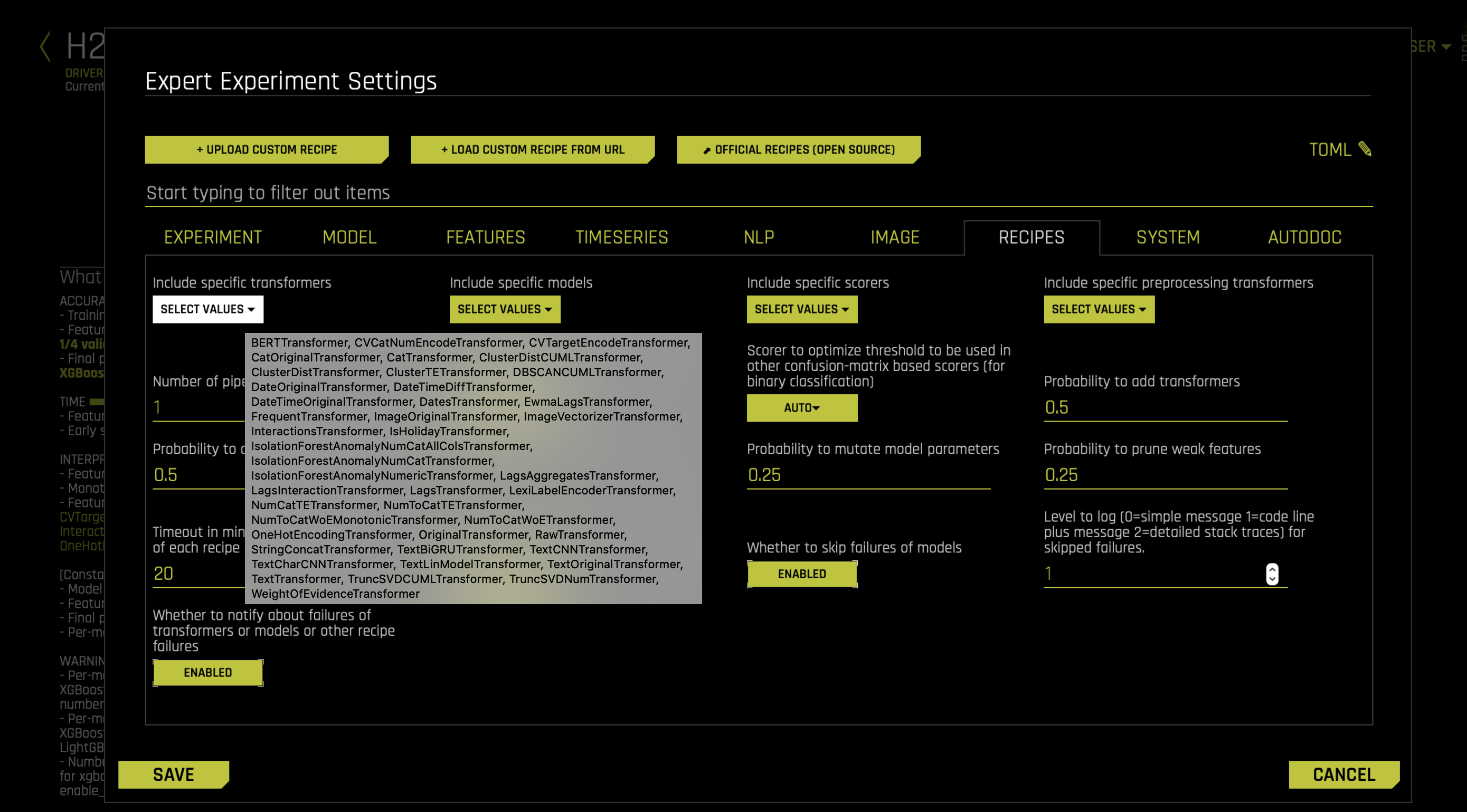
Preprocessing transformers 는 진화형 transformer 레이어에 공급되는 기능의 제어에 이용할 수 있습니다.
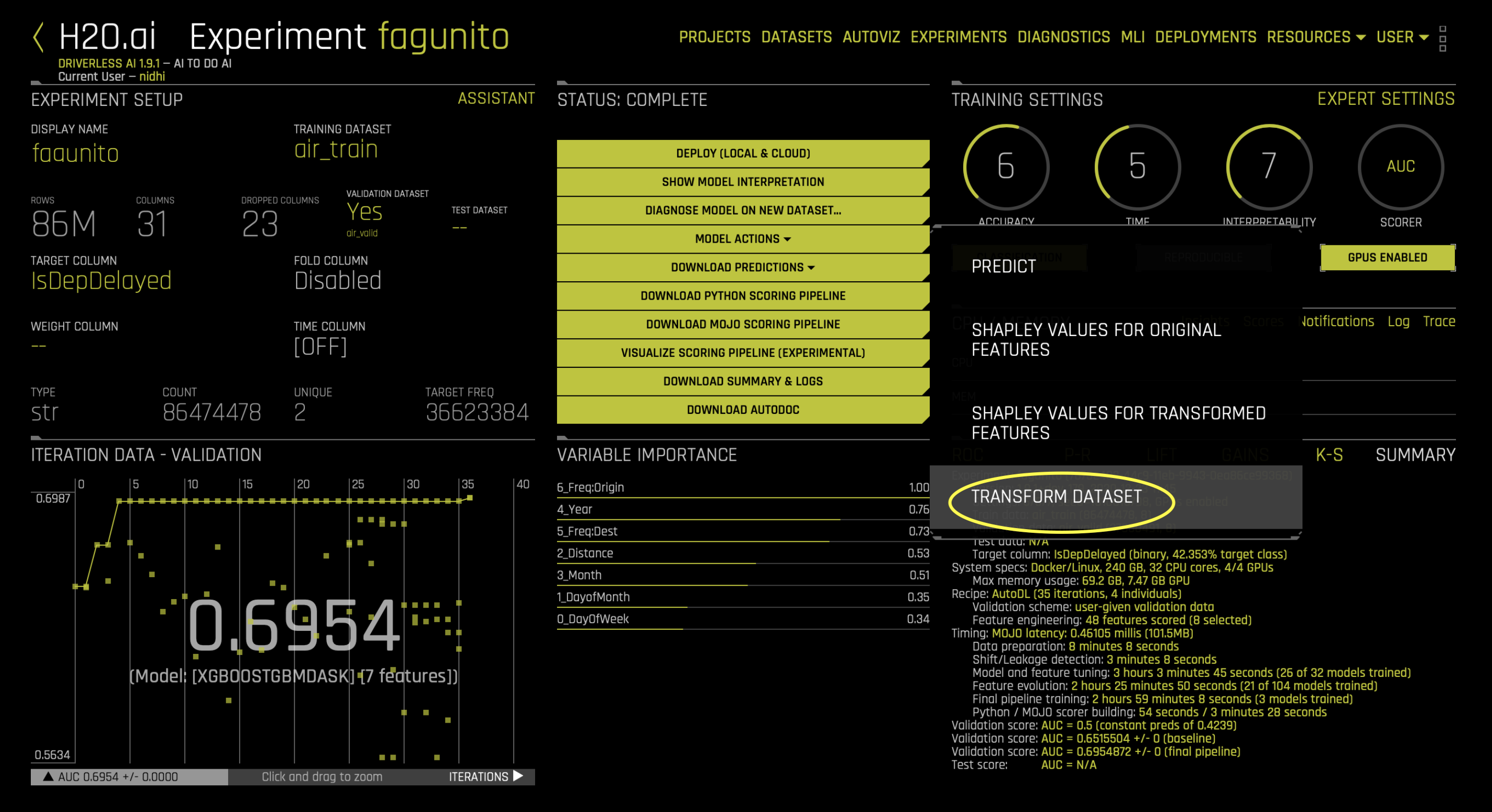
완료한 실험의 Model Actions 에서 Transform Dataset 를 클릭하여 (가공된) 기능이 있는 데이터 세트를 획득할 수 있습니다. 그에 따라 해당 실험의 가장 좋은 개별 모델의 파이프라인이 제공됩니다.
Driverless AI는 파이프라인을 튜닝하며, 이는 최적의 스코어링 파이프라인을 얻기 위해 진화 주기의 마지막에 유전 알고리즘의 진화 전략과 블렌딩 및 스태킹을 적용하여 변수 가공 및 모델 매개변수를 동시에 조정하는 것으로 구성됩니다.