Interpret a model
Model interpretations can be run on a Driverless AI experiment or on the predictions created by an external model (that is, a model not created by Driverless AI).
Use the Interpret This Model button on a completed experiment page to interpret a Driverless AI model on original and transformed features. You can also click the MLI link from the top navigation menu to interpret either a Driverless AI model or an external model.
Interpret a Driverless AI model
A completed Driverless AI model can be interpreted from either the Interpreted Models page or the Completed Experiment Page.
참고
This release deprecates experiments run in 1.8.9 and earlier. MLI migration is not supported for experiments from versions <= 1.8.9. This means that you can’t directly run interpretations on a Driverless AI model built using versions 1.8.9 and earlier, but you can still view interpretations built using those versions.
MLI is not supported for unsupervised learning models.
MLI is not supported for Image or multiclass Time Series experiments.
MLI does not require an Internet connection to run on current models.
To specify a port of a specific H2O instance for use by MLI, use the
h2o_portconfig.toml setting. You can also specify an IP address for use by MLI with theh2o_ipsetting.
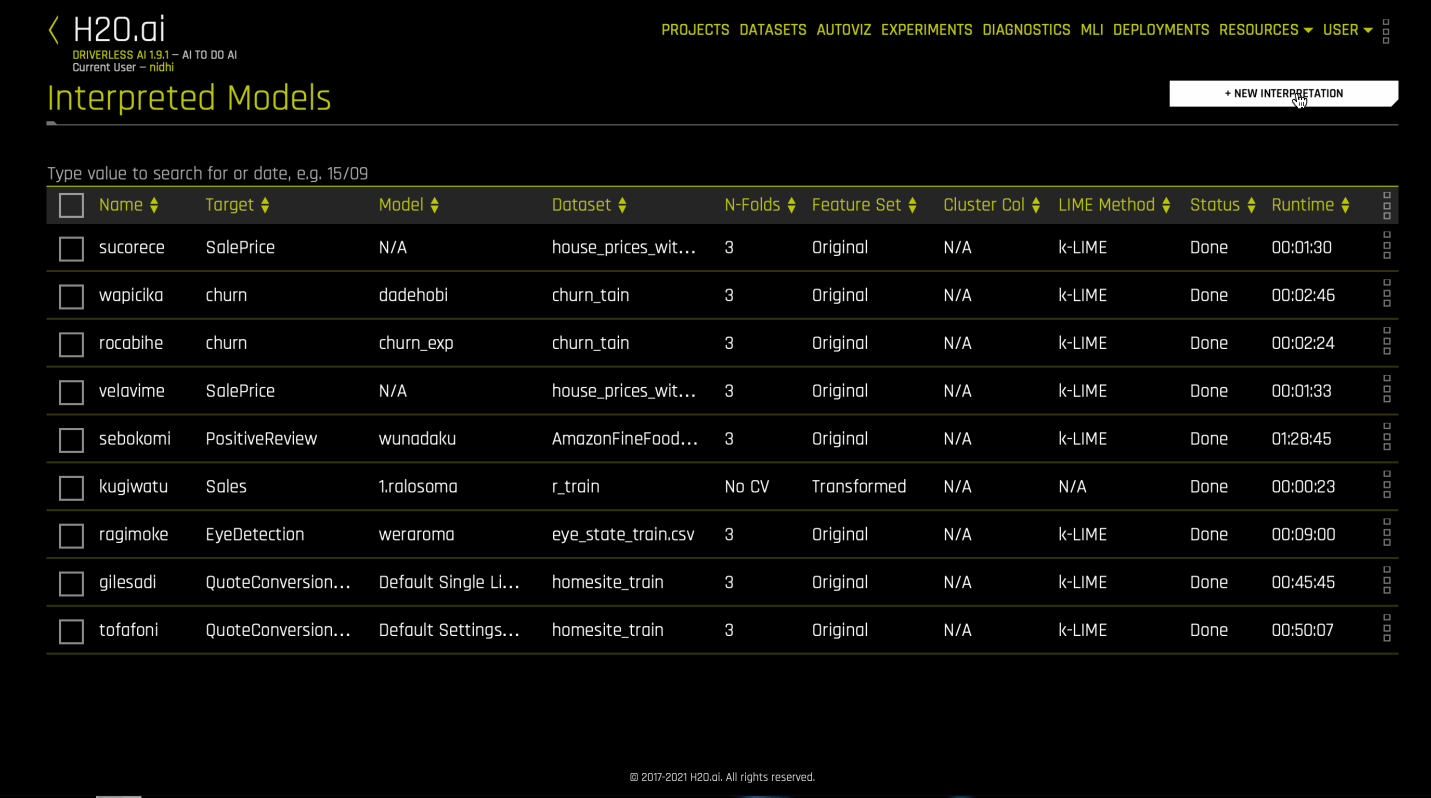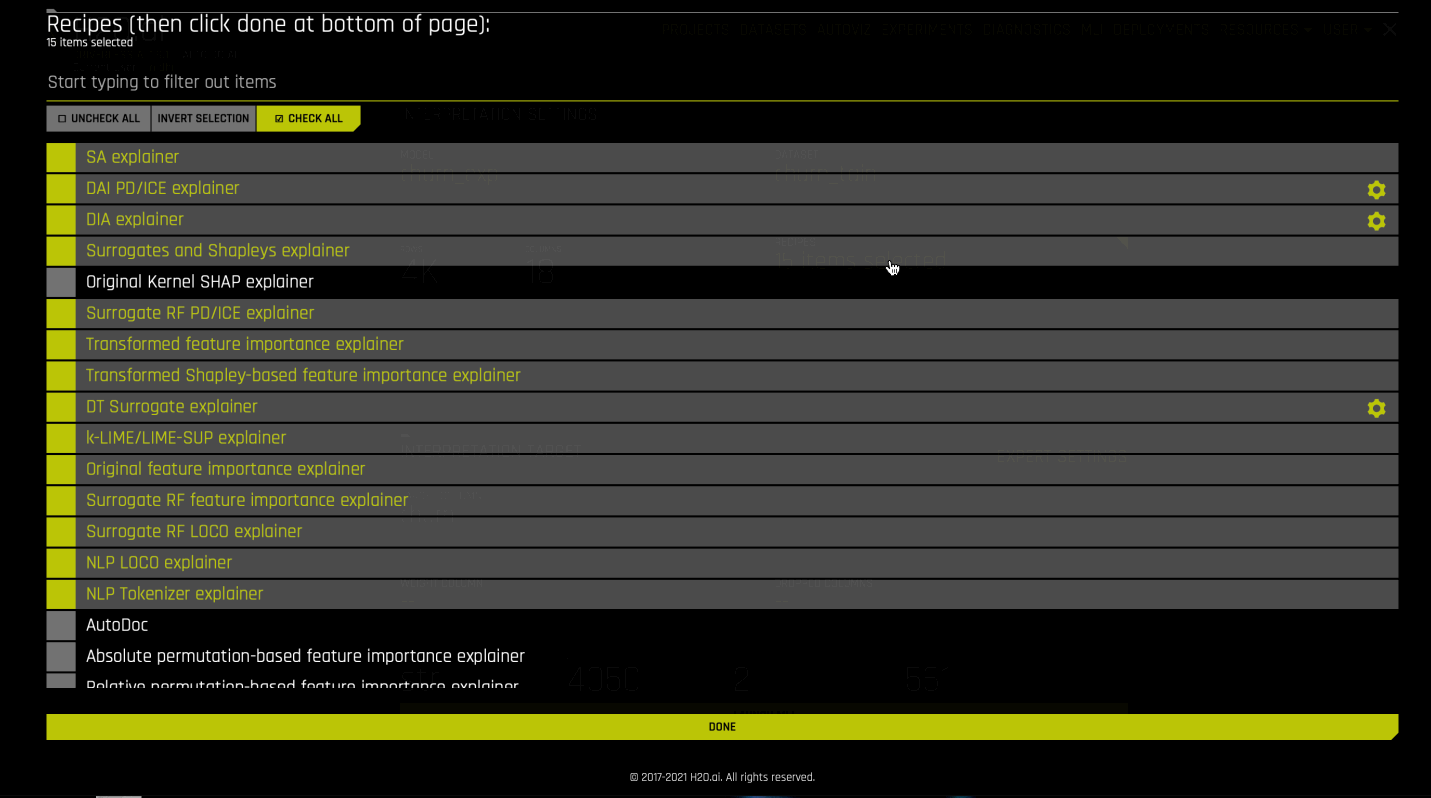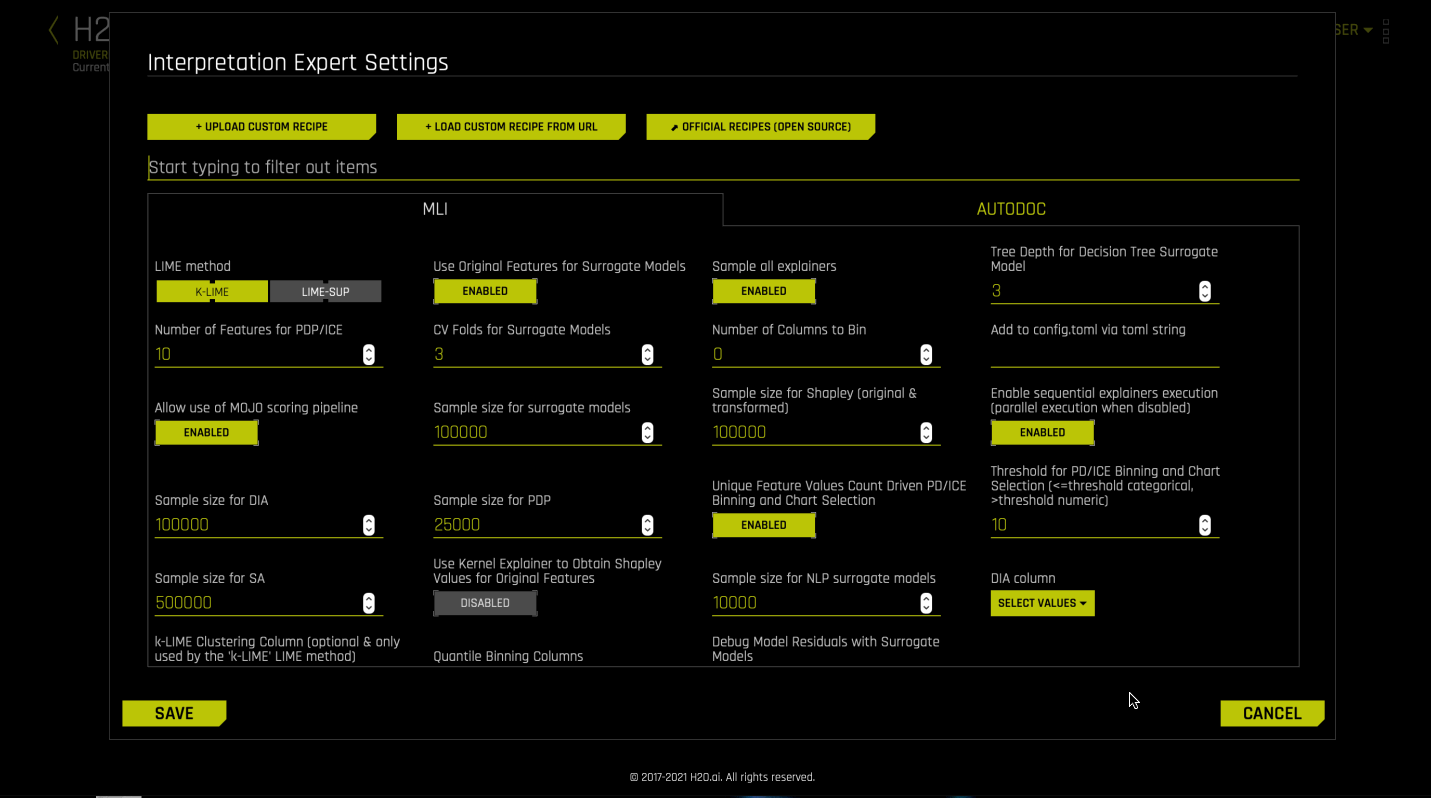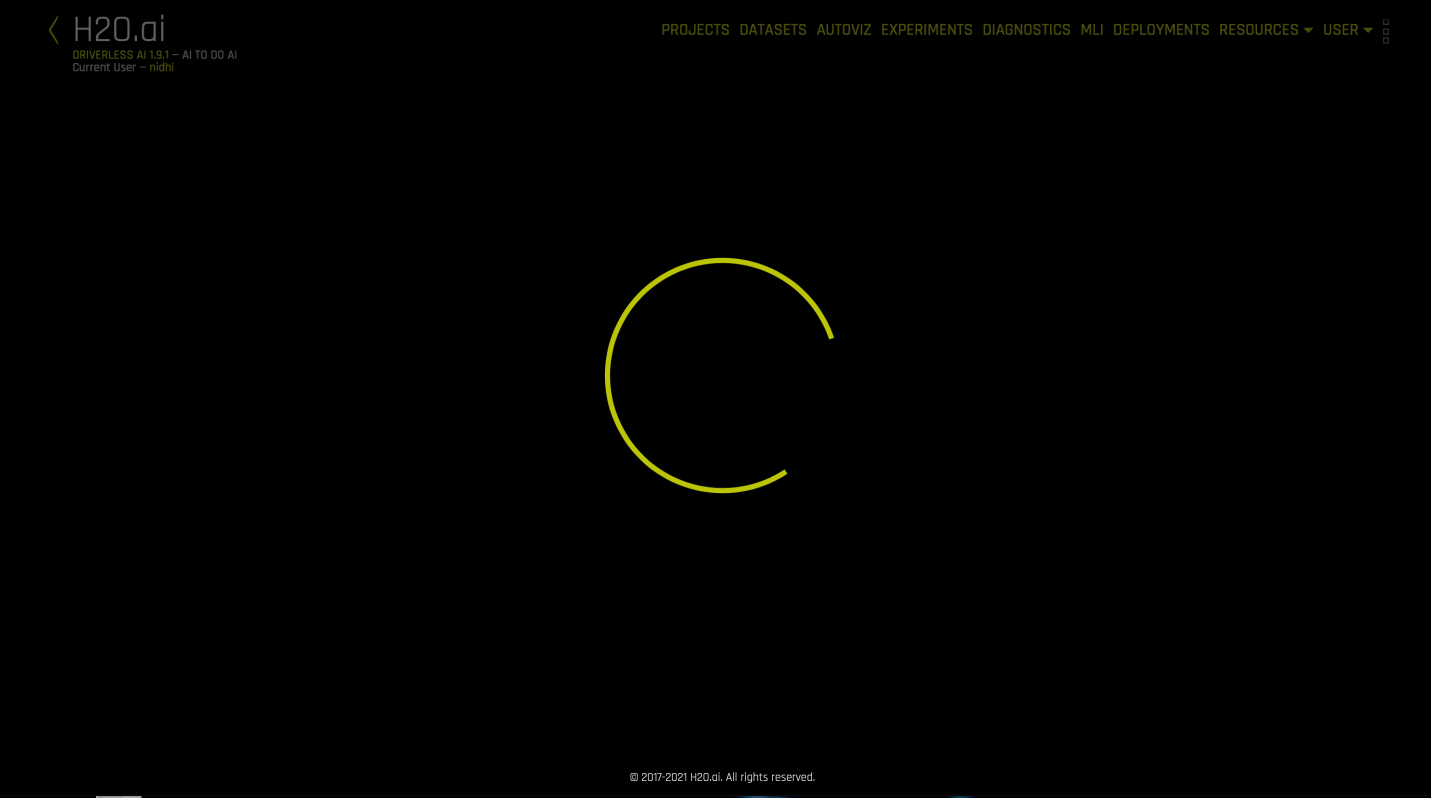
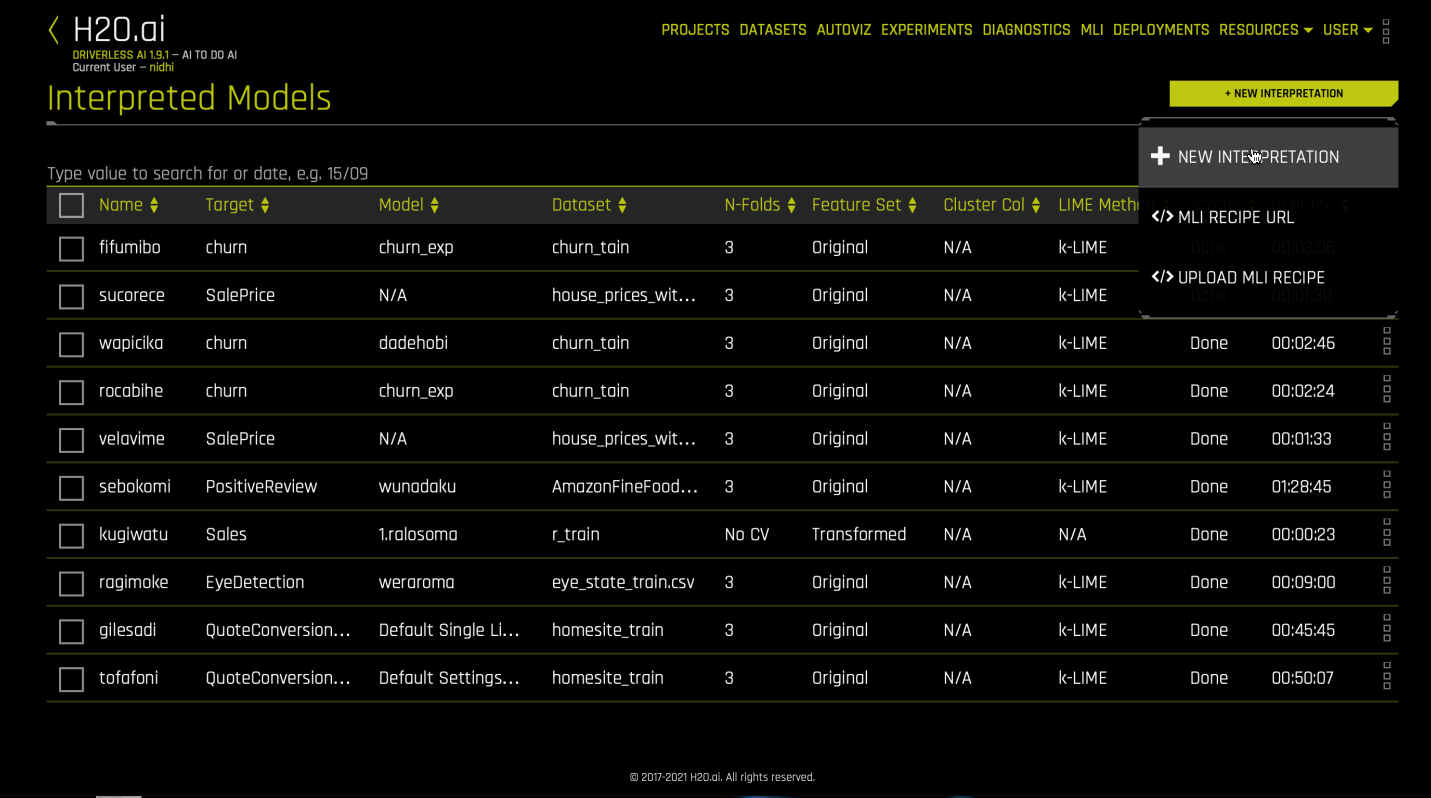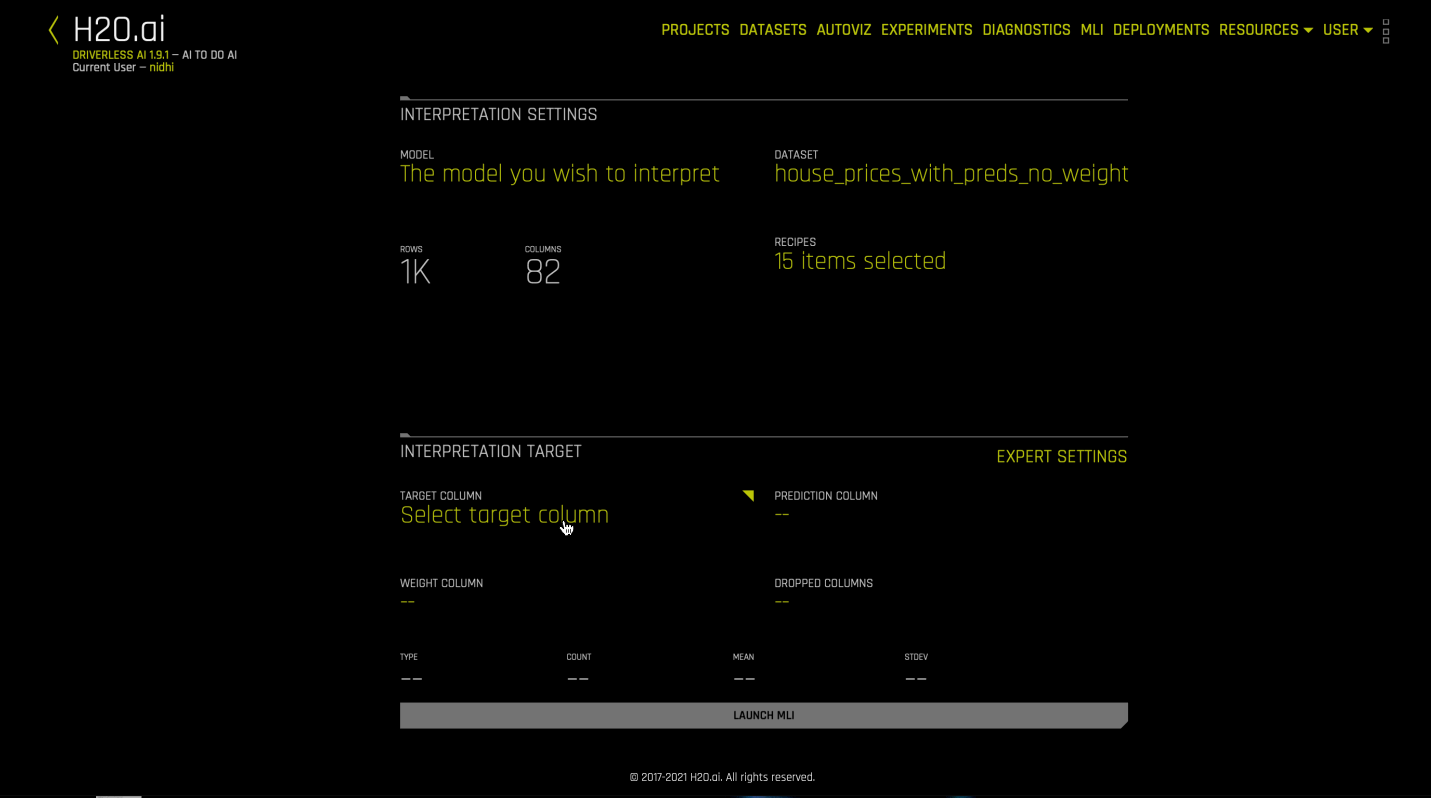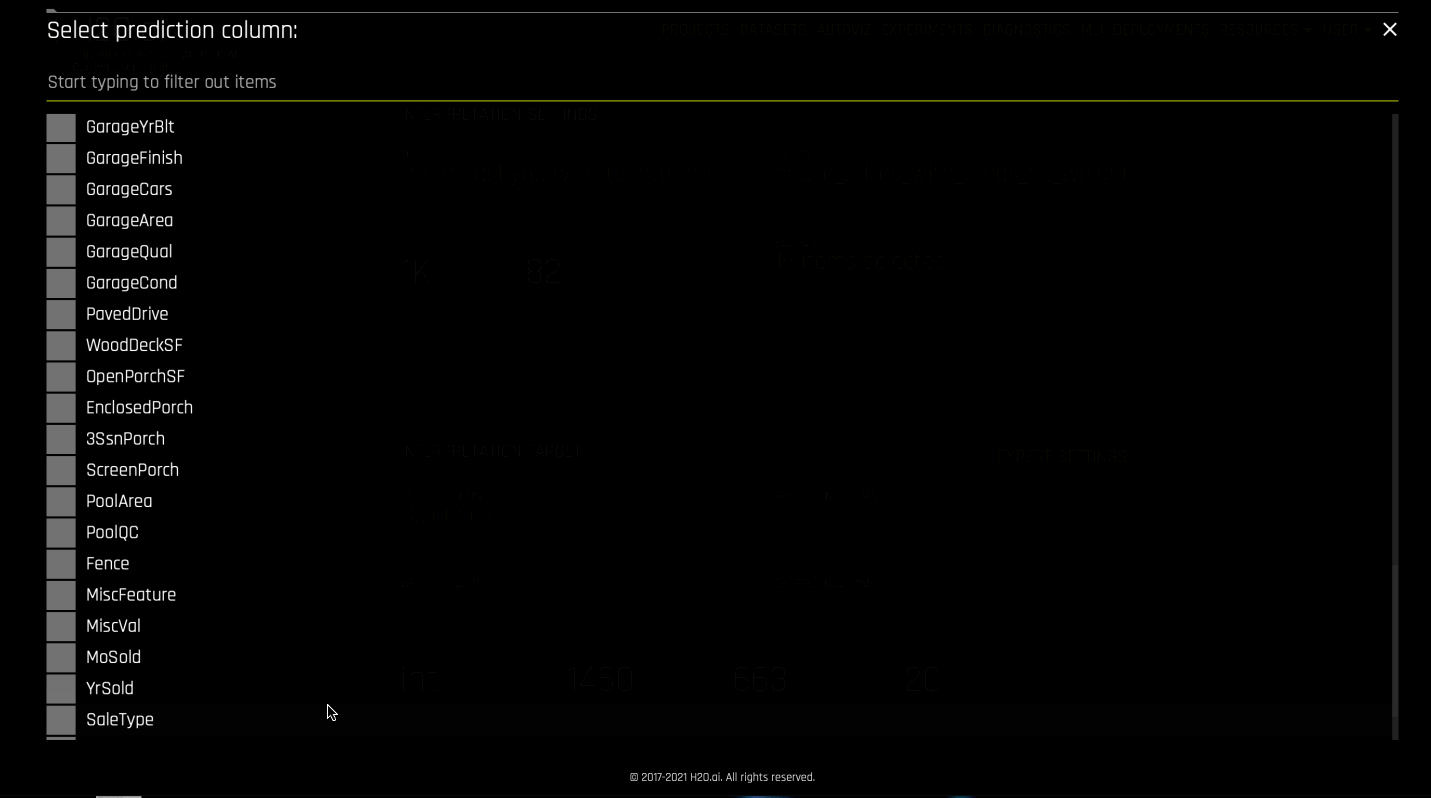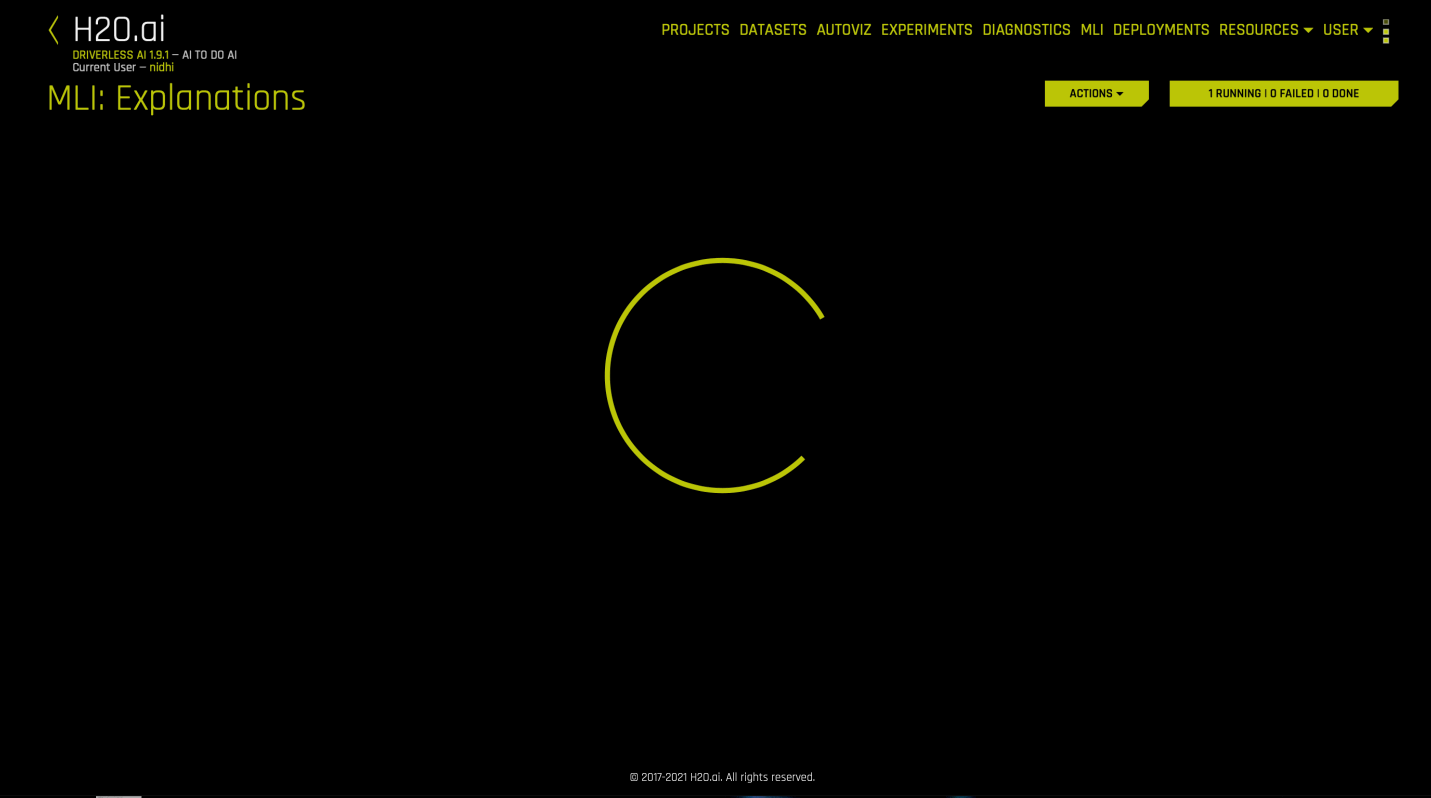
Run interpretations from the Interpreted Models page
The following steps describe how to run an interpretation from the Interpreted Models page.
Click the MLI link in the upper-right corner of the UI to view a list of interpreted models.
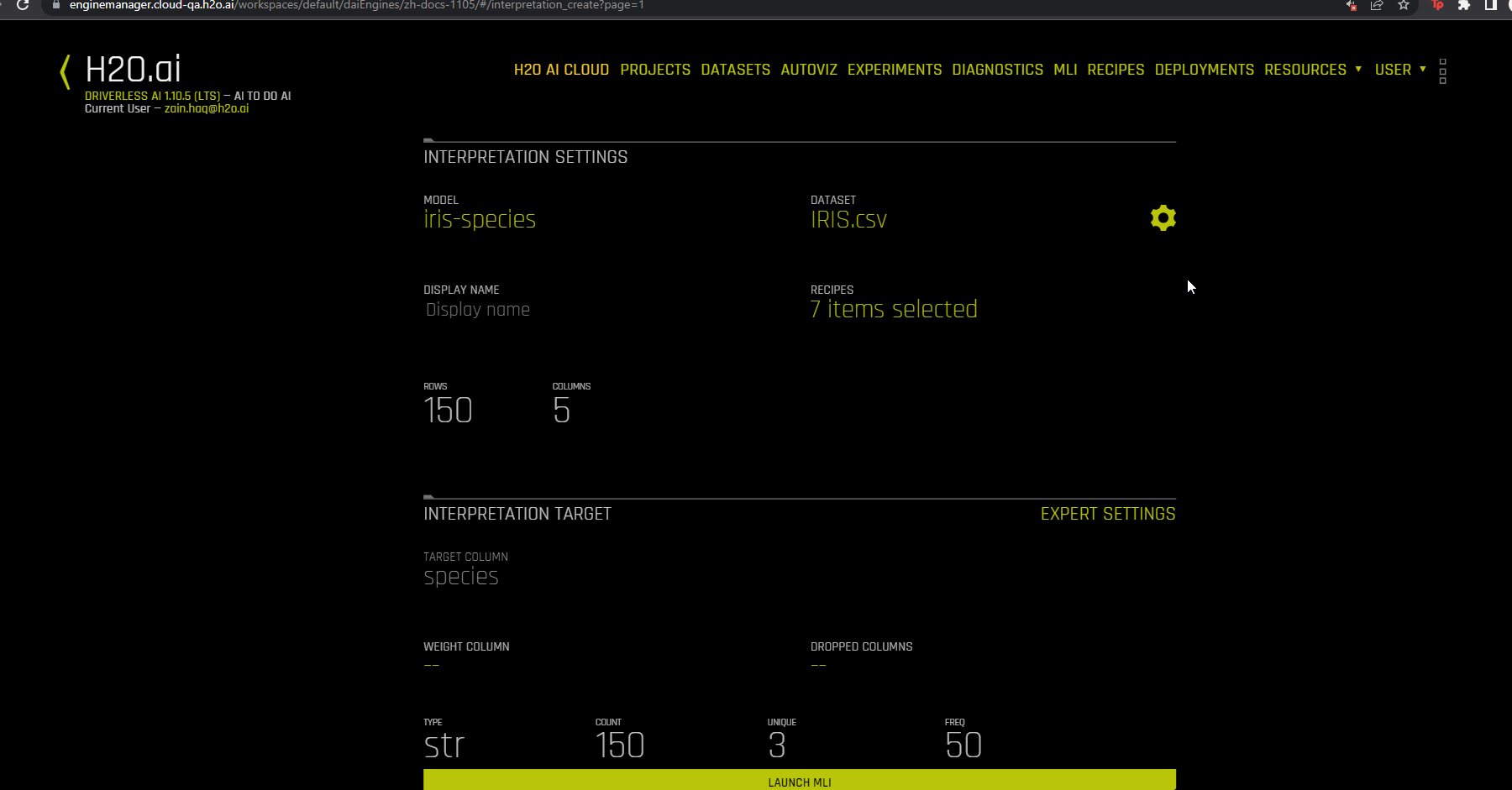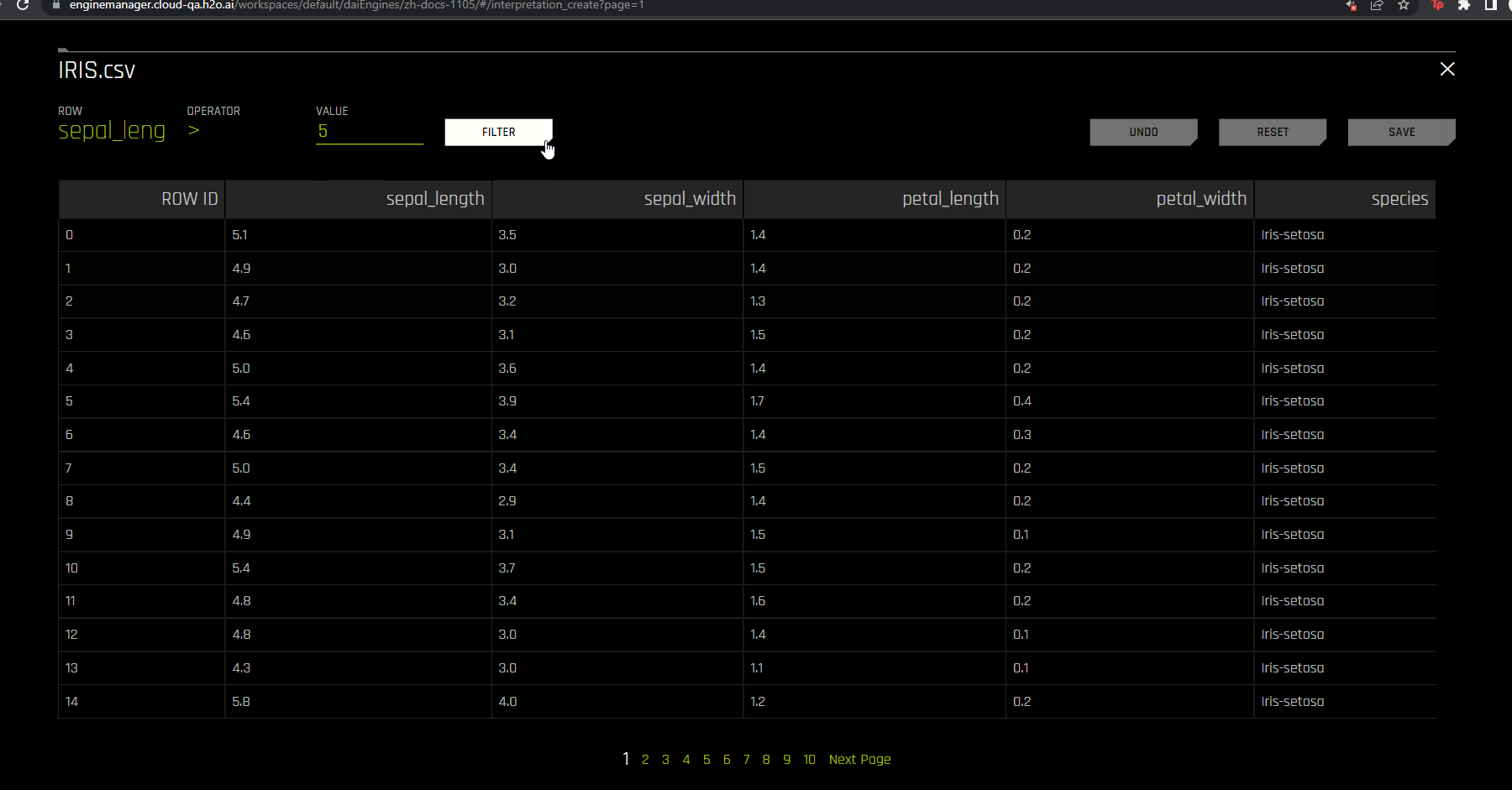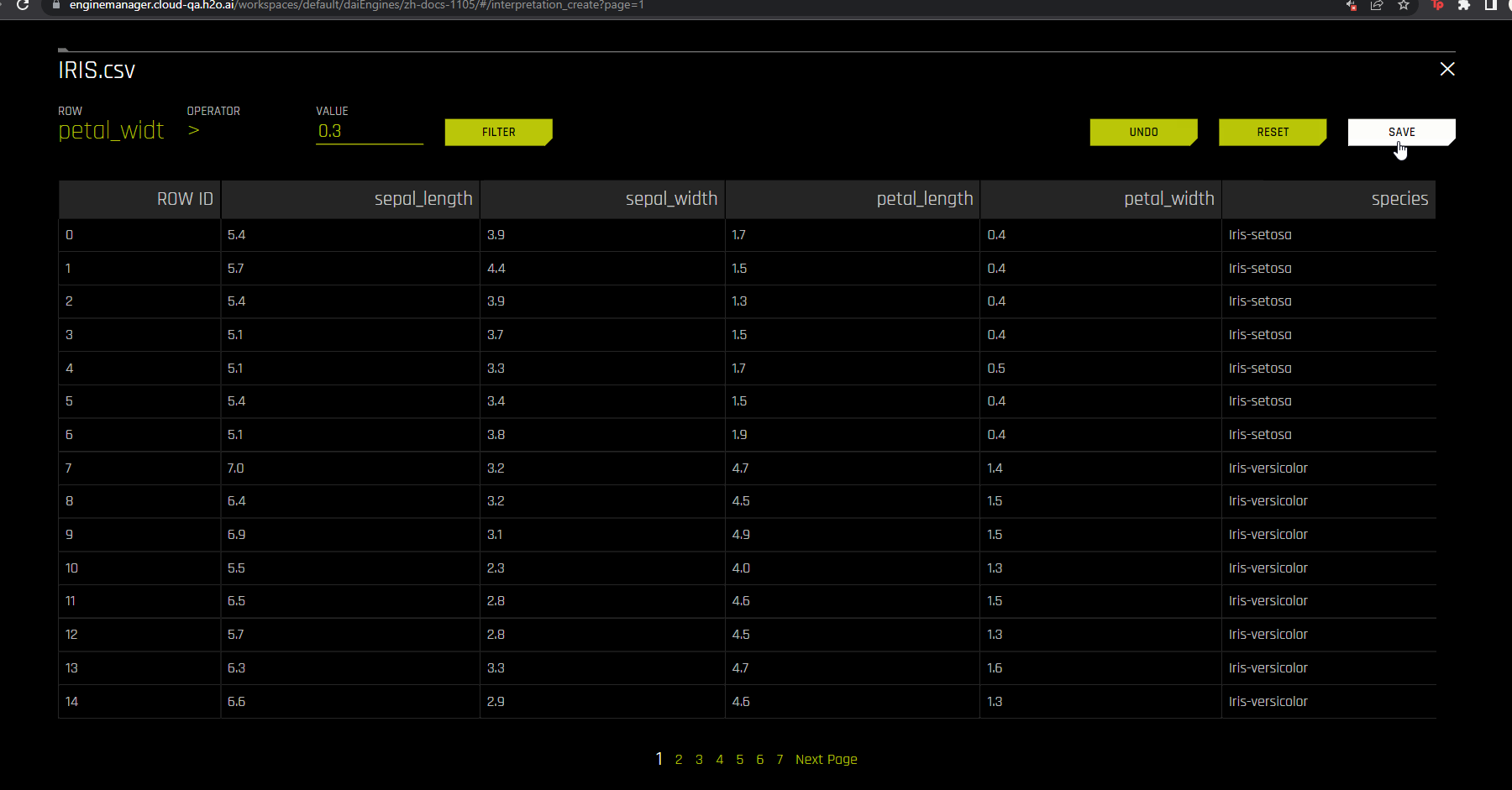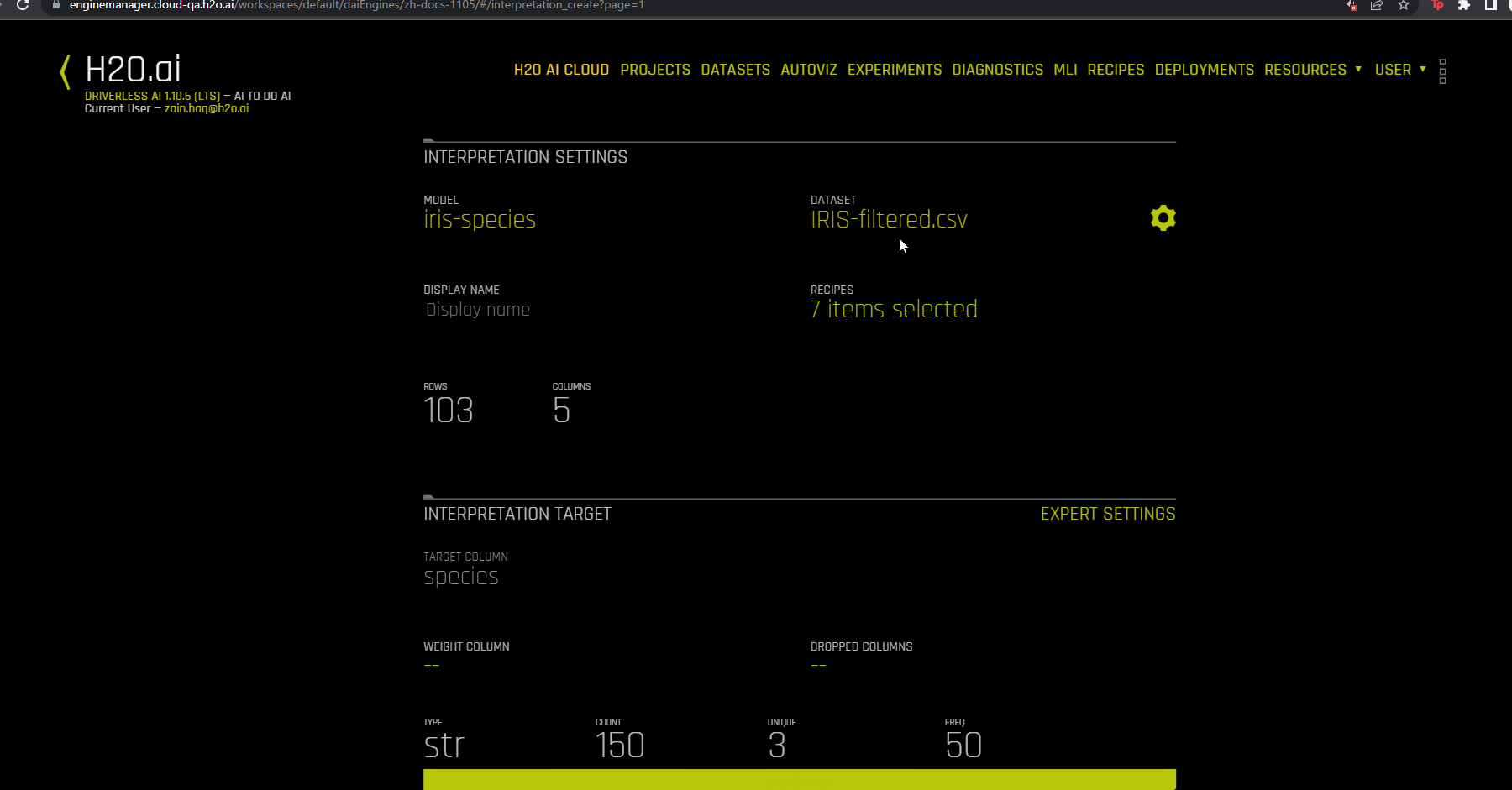
Click the New Interpretation button. The Interpretation Settings page is displayed.
Select a dataset to use for the interpretation. The selected dataset must contain the same columns as the training dataset used for the experiment.
Specify the Driverless AI model that you want to use for the interpretation. After you select a model, the Target Column used for the model is automatically selected.
Optionally specify which MLI recipes (or Explainers) to run. You can also change Explainer (recipe) specific settings when selecting which recipes to use for the interpretation.
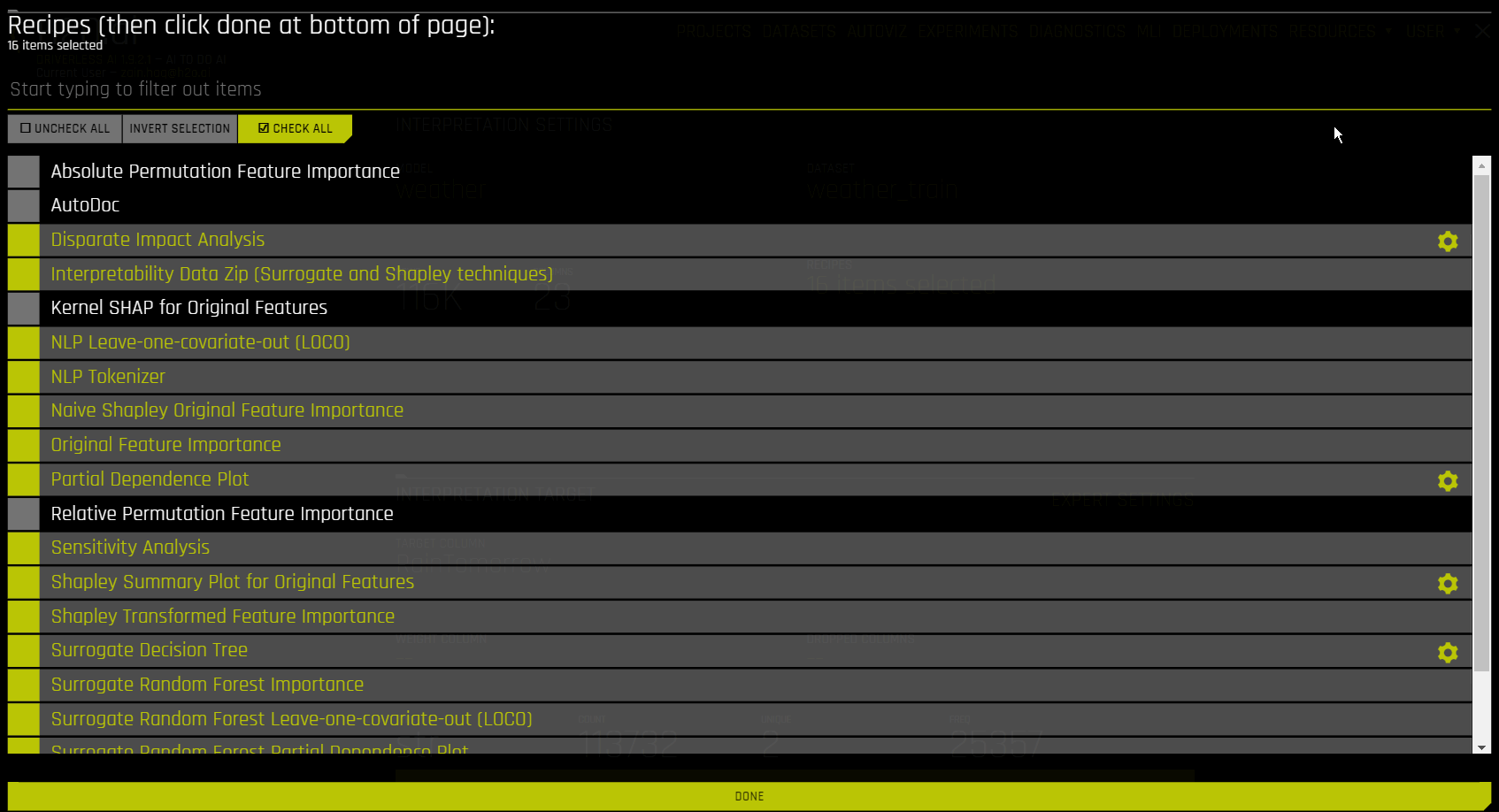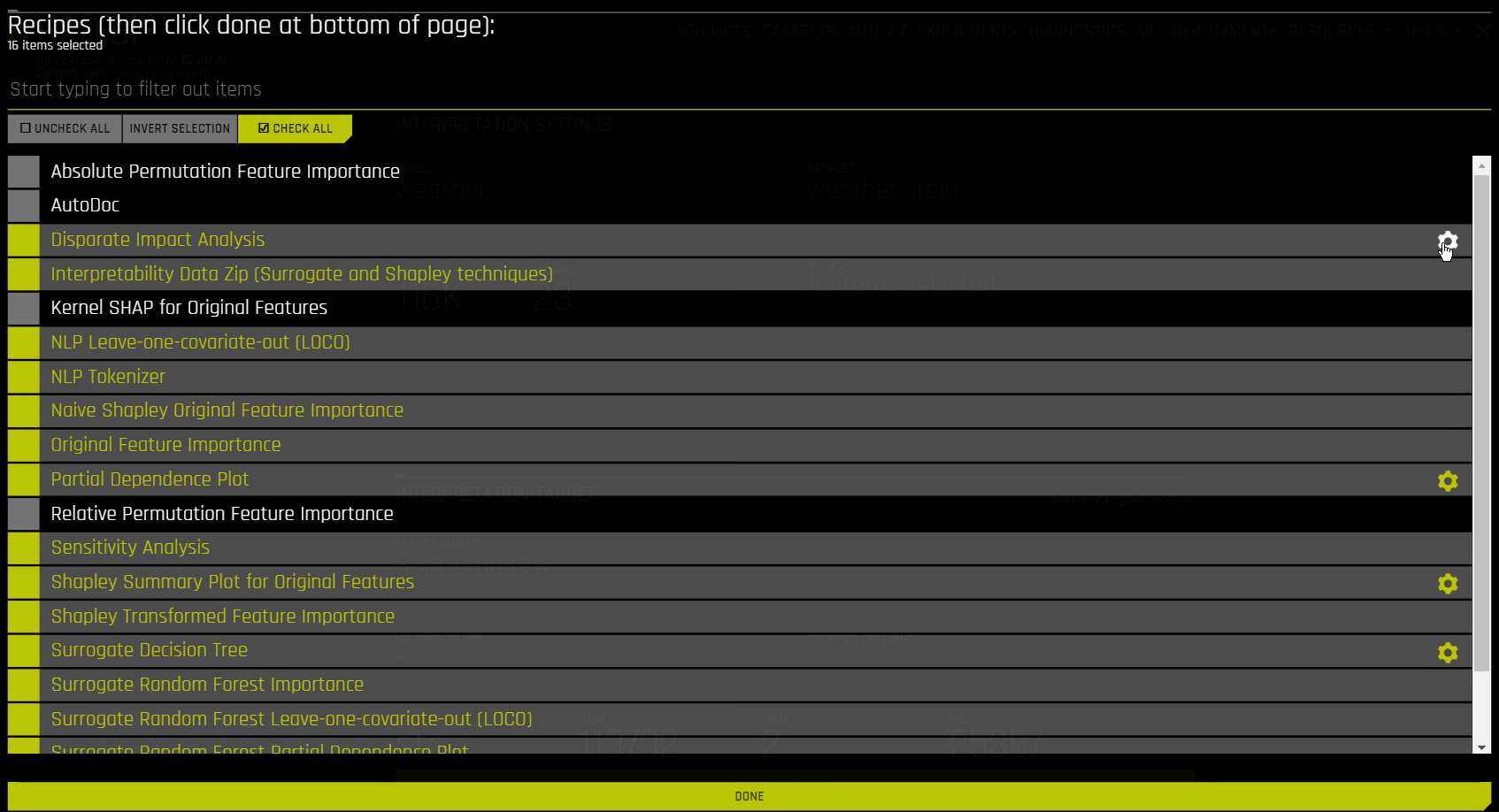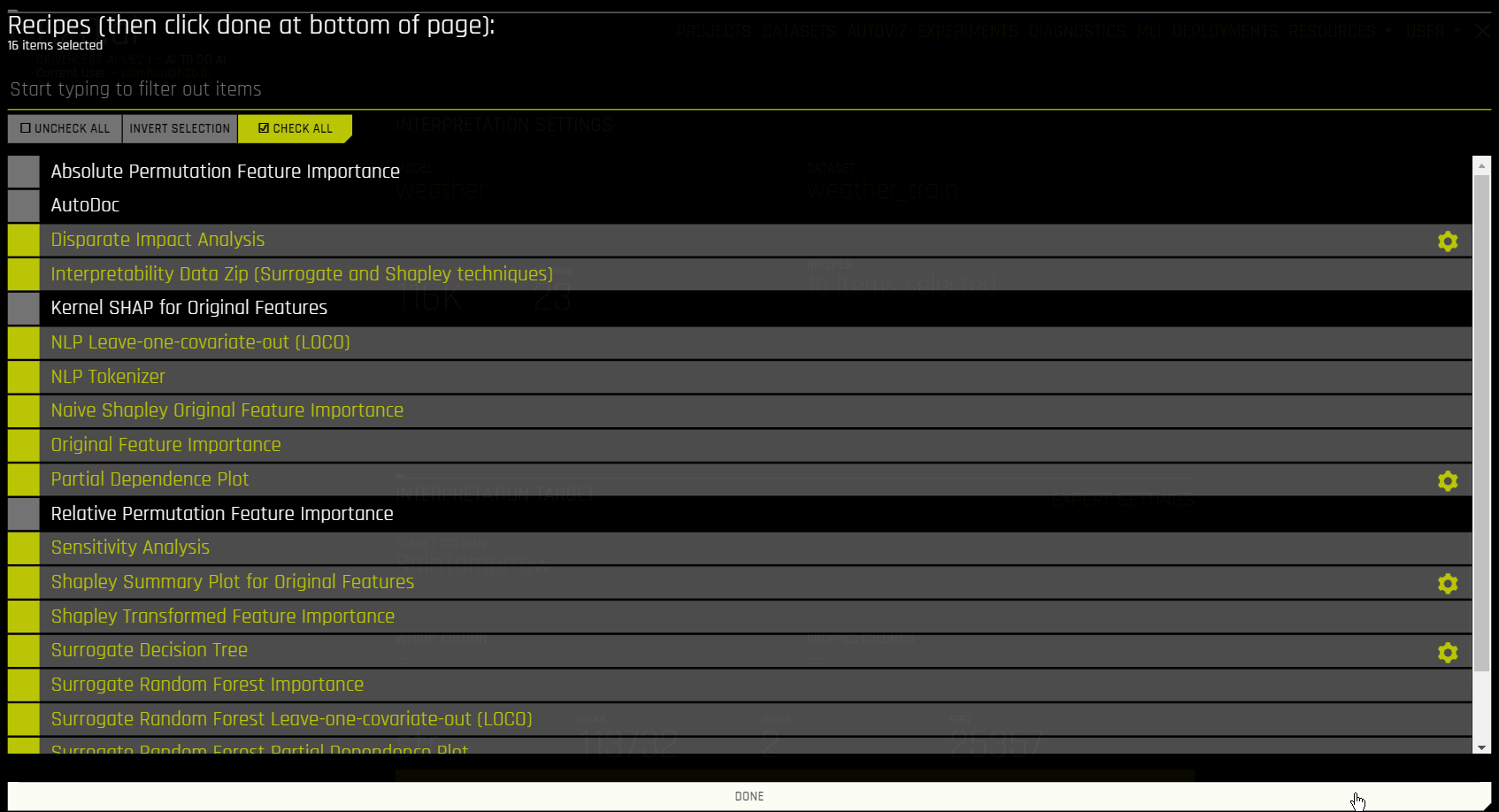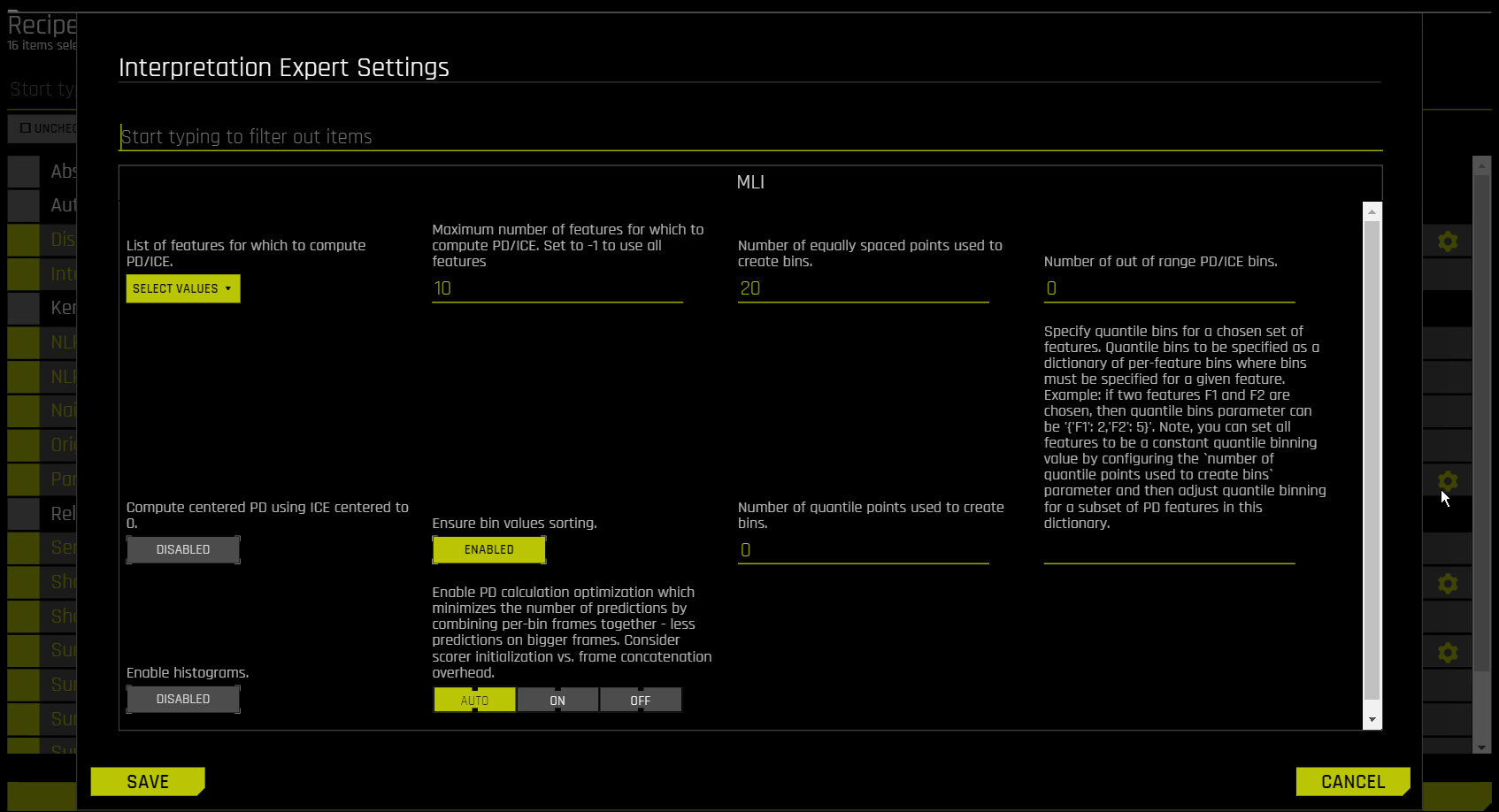
Optionally specify any additional Interpretation Expert Settings to use when running this interpretation.
Optionally specify a weight column.
Optionally specify one or more dropped columns. Columns that were dropped when the model was created are automatically dropped for the interpretation.
Click the Launch MLI button.
Filter input data to MLI
Driverless AI provides a built-in option to filter input data to MLI when creating a new interpretation. The following steps describe how to access and use the built-in input data filtering feature.
On the Interpreted Models page, click New Interpretation.
After specifying a dataset to use for the interpretation, click the gear icon next to the name of the dataset.
The rows and columns of the specified dataset are displayed. To filter the data, specify a row, operator, and value to filter by, then click the Filter button. To undo your most recent change, click the Undo button. You can also reset the data to its original unfiltered state by clicking the Reset button.
To confirm your changes, click the Save button. Specify a name for the filtered dataset, and then click Save to proceed. The newly created filtered dataset is automatically selected for the interpretation.
Run interpretation from the Completed Experiment page
The following steps describe how to run an interpretation from the Completed Experiment Page.
On the Completed Experiment page, click the Interpret This Model button.
Select a dataset to use for the interpretation. The selected dataset must contain the same columns as the training dataset used for the experiment.
Select one of the following options:
Show most recent interpretation: Go to the most recent interpretation of the selected experiment. Note that this option is only displayed if you have already run an interpretation on the experiment.
With Default Settings: Run an interpretation using the default settings.
With Custom Settings: Run an interpretation using custom settings. Selecting this option opens the Interpretation Settings page, where you can specify which MLI recipes (explainers) to use for the interpretation and change explainer-specific settings and interpretation expert settings. To run an interpretation with your specified custom settings, click the Launch MLI button.
The interpretation includes a summary of the interpretation, interpretations using the built Driverless AI model, and interpretations using surrogate models that are built on the predictions from the Driverless AI model. For information on the available plots, see Understanding the Model Interpretation page.
The plots are interactive, and the logs / artifacts can be downloaded by clicking on the Actions button.
For non-time-series experiments, this page provides several visual explanations and reason codes for the trained Driverless AI model and its results. More information about this page is available in the Understanding the Model Interpretation Page section later in this chapter.

Interpreting Predictions From an External Model
Model Interpretation does not need to be run on a Driverless AI experiment. You can train an external model and run Model Interpretability on the predictions from the model. This can be done from the MLI page.
Click the MLI link in the upper-right corner of the UI to view a list of interpreted models.
Click the New Interpretation button.
Leave the Select Model option to none
Select the dataset that you want to use for the model interpretation. This must include a prediction column that was generated by the external model. If the dataset does not have predictions, then you can join the external predictions. An example showing how to do this in Python is available in the Run Model Interpretation on External Model Predictions section of the Credit Card Demo.
Specify a Target Column (actuals) and the Prediction Column (scores from the external model).
Optionally specify any additional MLI Expert Settings to use when running this interpretation.
Optionally specify a weight column.
Optionally specify one or more dropped columns. Columns that were dropped when the model was created are automatically dropped for the interpretation.
Click the Launch MLI button.
Note: When running interpretations on an external model, leave the Select Model option empty. That option is for selecting a Driverless AI model.
The generated interpretation includes the plots and explanations created using the surrogate models and a summary. For more information, see Understanding the Model Interpretation page.
Explainer Recipes
Driverless AI Machine Learning Interpretability comes with a number of out-of-the-box explainer recipes for model interpretation that can be enabled when running a new interpretation from the MLI page. Details about the interpretations generated by these recipes can be found here. And a list of explainer specific expert settings can be found here. The following is a list of explainers that are run by default for MLI.
Disparate Impact Analysis (DIA)
Sensitivity Analysis (SA)
Shapley Summary Plot for Original Features (Naive Shapley Method)
Shapley Values for Original Features (Naive Method)
Shapley Values for Transformed Features
Partial Dependence Plot
Decision Tree Surrogate Model
NLP Leave-one-covariate-out (LOCO)
NLP Partial Dependence Plot
Note that this recipe list is extensible and that you can create your own custom recipes. For more information, see MLI Custom Recipes.
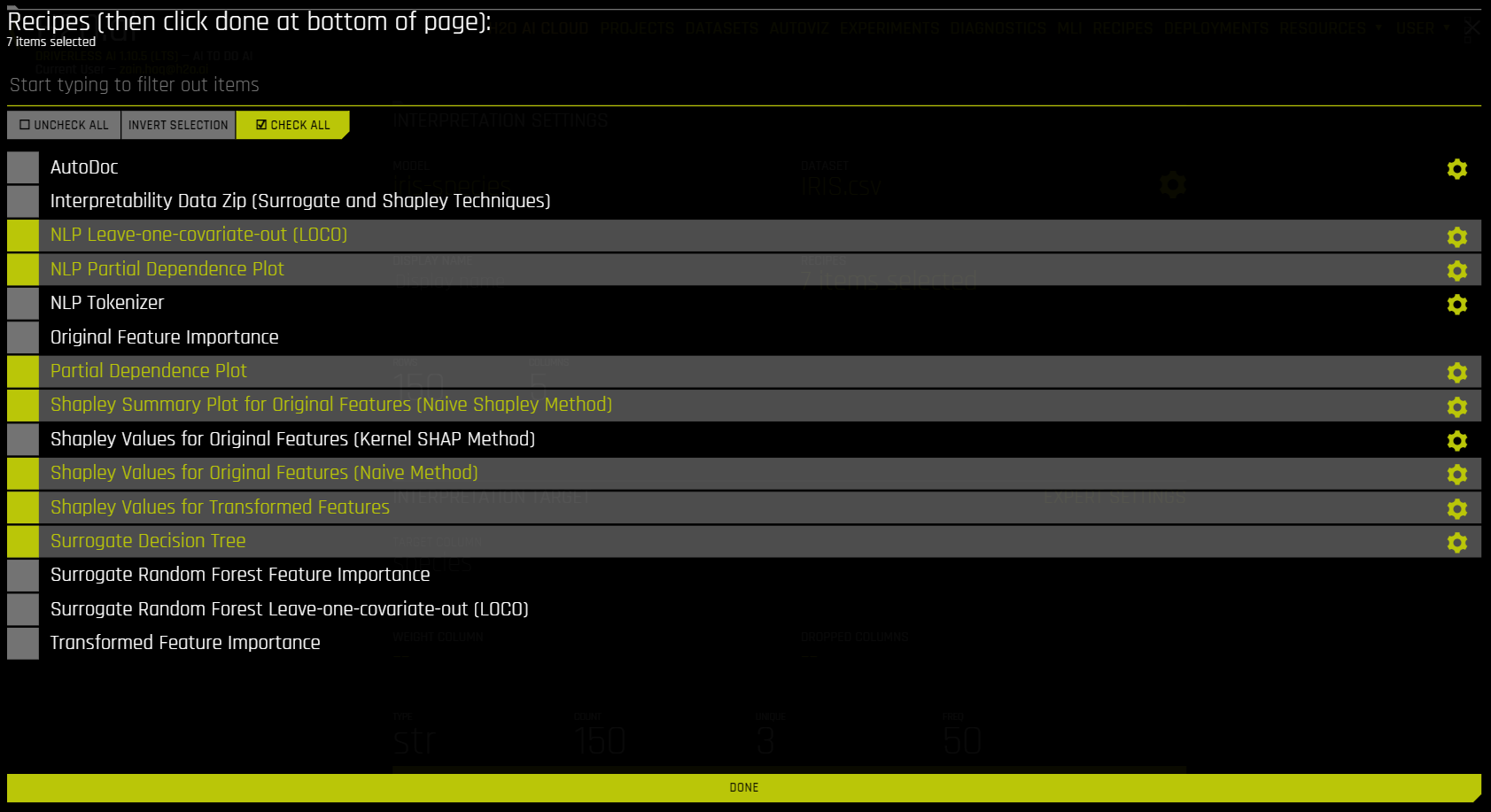
Legacy explainers
The following is a list of legacy explainers that are not run by default for MLI. You can run legacy explainers by using config variables.
Absolute Permutation Feature Importance
AutoDoc
Interpretability Data ZIP (Surrogate and Shapley Techniques)
NLP Tokenizer
NLP Vectorizer + Linear Model (VLM) Text Feature Importance
Original Feature Importance
Relative Permutation Feature Importance
Shapley Values for Original Features (Kernel SHAP Method)
Surrogate Random Forest Importance
Surrogate Random Forest Leave-one-covariate-out (LOCO)
Surrogate Random Forest Partial Dependence Plot
Transformed Feature Importance
k-LIME / LIME-SUP
Interpretation Expert Settings
When interpreting from the MLI page, a variety of configuration options are available in the Interpretation Expert Settings panel that let you customize interpretations. Recipe-specific settings are also available for some recipes. Use the search bar to refine the list of settings or locate a specific setting.
For more information on each of these settings, see Interpretation Expert Settings. Also see for explainer (recipe) specific expert settings.
Notes:
The selection of available expert settings is determined by the type of model you want to interpret and the specified LIME method.
Expert settings are not available for time-series models.
Expert Settings from Recipes (Explainers)
For some recipes like Driverless AI Partial dependence, Disparate Impact Analysis (DIA) explainer and DT (Decision Tree) Surrogate explainer, some of the settings can be toggled from the recipe page. Also, enabling some of the recipes like Original Kernel SHAP explainer will add new options to the expert settings.
For more information on explainer specific expert settings, see Explainer (Recipes) Expert Settings.