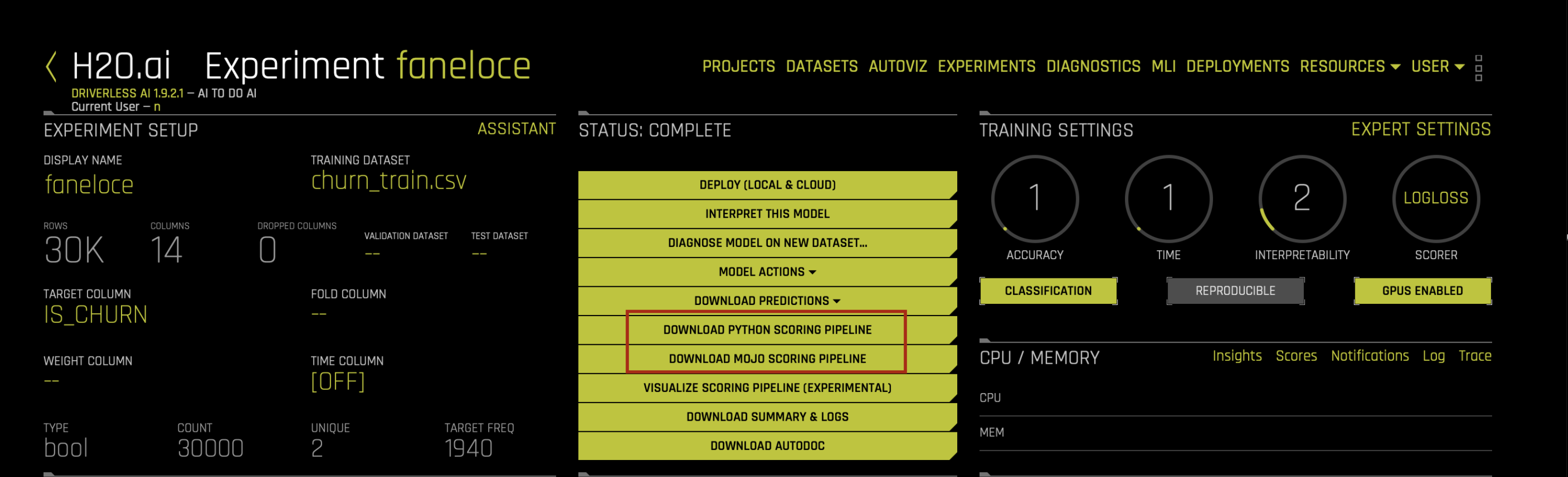
Which Pipeline Should I Use?
Driverless AI Python Scoring Pipeline
Driverless AI Python Scoring Pipeline is implemented as a Python whl file. While this allows for a single process scoring engine, the scoring service is generally implemented as a client/server architecture and supports interfaces for TCP and HTTP. When running the Python Scoring Pipeline:
HTTP is supported by virtually any language. HTTP supports RESTful calls via curl, wget, or supported packages in various scripting languages.
TCP is a bit more complex, though faster. TCP also requires Thrift, which currently does not handle NAs.
k-LIME reason codes and Shapley reason codes whl file can be obtained for all models from MLI Standalone Python Scoring Pipeline from the MLI experiment page.
Driverless AI MOJO Scoring Pipeline
Driverless AI MOJO Scoring Pipeline is flexible and is faster than the Python Scoring Pipeline. It requires some coding. The MOJO Scoring Pipeline is available as either a Java runtime or a C++ runtime (with R and Python wrappers).
k-LIME reason codes mojo can be downloaded as the K-Lime MOJO reason code Pipeline from the MLI experiment page.
Shapley reason codes contributions can be obtained from the Driverless AI Java MOJO Scoring Pipeline. Presently, Shapley contributions are available for XGBoost(GBM, GLM, RF, DART), LightGBM and DecisionTree models( and their ensemble)and are not available for ZeroInflated, Imbalanced and ensemble with ExtraTrees meta learner (ensemble_meta_learner=〉extra_trees〉).