Expert Settings¶
This section describes the Expert Settings that are available when starting an experiment. Driverless AI provides a variety of options in the Expert Settings that allow you to customize your experiment. Use the search bar to refine the list of settings or locate a specific setting.
The default values for these options are derived from the configuration options in the config.toml file. Refer to the Sample Config.toml File section for more information about each of these options.
Note about Feature Brain Level: By default, the feature brain pulls in any better model regardless of the features even if the new model disabled those features. For full control over features pulled in via changes in these Expert Settings, users should set the Feature Brain Level option to 0.
Upload Custom Recipe¶
Driverless AI supports the use of custom recipes (optional). If you have a custom recipe available on your local system, click this button to upload that recipe. If you do not have a custom recipe, you can select from a number of recipes available in the https://github.com/h2oai/driverlessai-recipes repository. Clone this repository on your local machine and upload the desired recipe. Refer to the Custom Recipes appendix for examples.
Load Custom Recipe from URL¶
If you have a custom recipe available on an external system, specify the URL for that recipe here. Note that this must point to the raw recipe file (for example https://raw.githubusercontent.com/h2oai/driverlessai-recipes/master/transformers/text_sentiment_transformer.py). Refer to the Custom Recipes appendix for examples.
Official Recipes (External)¶
Click this button to access H2O’s official recipes repository (https://github.com/h2oai/driverlessai-recipes).
Experiment Settings¶
Max Runtime in Minutes Before Triggering the Finish Button¶
Specify the maximum runtime in minutes for an experiment. This is equivalent to pushing the Finish button once half of the specified time value has elapsed. Note that the overall enforced runtime is only an approximation.
This value defaults to 1440, which is the equivalent of a 24 hour approximate overall runtime. The Finish button will be automatically selected once 12 hours have elapsed, and Driverless AI will subsequently attempt to complete the overall experiment in the remaining 12 hours. Set this value to 0 to disable this setting.
Max Runtime in Minutes Before Triggering the Abort Button¶
Specify the maximum runtime in minutes for an experiment before triggering the abort button. This option preserves experiment artifacts that have been generated for the summary and log zip files while continuing to generate additional artifacts. This value defaults to 10080.
Pipeline Building Recipe¶
Specify the Pipeline Building recipe type (overrides GUI settings). Select from the following:
AUTO: Specifies that all models and features are automatically determined by experiment settings, config.toml settings, and the feature engineering effort. (Default)
COMPLIANT: Similar to AUTO except for the following:
Interpretability is set to 10.
Only uses GLM.
Fixed ensemble level is set to 0.
Feature brain level is set to 0.
Max feature interaction depth is set to 1.
Target transformers is set to ‘identity’ for regression.
Does not use distribution shift.
KAGGLE: Similar to AUTO except for the following:
Any external validation set is concatenated with the train set, with the target marked as missing.
The test set is concatenated with the train set, with the target marked as missing
Transformers that do not use the target are allowed to
fit_transformacross the entirety of the train, validation, and test sets.Has several config.toml expert options open-up limits.
Kaggle Username¶
Optionally specify your Kaggle username to enable automatic submission and scoring of test set predictions. If this option is specified, then you must also specify a value for the Kaggle Key option. If you don’t have a Kaggle account, you can sign up at https://www.kaggle.com.”
Kaggle Key¶
Specify your Kaggle API key to enable automatic submission and scoring of test set predictions. If this option is specified, then you must also specify a value for the Kaggle Username option. For more information on obtaining Kaggle API credentials, see https://github.com/Kaggle/kaggle-api#api-credentials.
Kaggle Submission Timeout in Seconds¶
Specify the Kaggle submission timeout in seconds. This value defaults to 120.
Make Python Scoring Pipeline¶
Specify whether to automatically build a Python Scoring Pipeline for the experiment. Select ON or AUTO (default) to make the Python Scoring Pipeline immediately available for download when the experiment is finished. Select OFF to disable the automatic creation of the Python Scoring Pipeline.
Make MOJO Scoring Pipeline¶
Specify whether to automatically build a MOJO (Java) Scoring Pipeline for the experiment. Select ON to make the MOJO Scoring Pipeline immediately available for download when the experiment is finished. With this option, any capabilities that prevent the creation of the pipeline are dropped. Select OFF to disable the automatic creation of the MOJO Scoring Pipeline. Select AUTO (default) to attempt to create the MOJO Scoring Pipeline without dropping any capabilities.
Attempt to Reduce the Size of the MOJO¶
Specify whether to attempt to reduce the size of the MOJO scoring pipeline when it is being built. A smaller MOJO has a smaller memory footprint during scoring. This is disabled by default.
Note: Enabling this setting can affect the overall predictive accuracy of the model because it is implemented by reducing values like interaction depth.
Measure MOJO Scoring Latency¶
Specify whether to measure the MOJO scoring latency at the time of MOJO creation. This is set to AUTO by default. In this case, MOJO scoring latency will be measured if the pipeline.mojo file size is less than 100 MB.
Timeout in Seconds to Wait for MOJO Creation at End of Experiment¶
Specify the amount of time in seconds to wait for MOJO creation at the end of an experiment. If the MOJO creation process times out, a MOJO can still be made from the GUI or the R and Python clients (the timeout contraint is not applied to these). This value defaults to 1800 (30 minutes).
Number of Parallel Workers to Use During MOJO Creation¶
Specify the number of parallel workers to use during MOJO creation. Higher values can speed up MOJO creation but use more memory. Set this value to -1 (default) to use all physical cores.
Make Pipeline Visualization¶
Specify whether to create a visualization of the scoring pipeline at the end of an experiment. This is set to AUTO by default. Note that the Visualize Scoring Pipeline feature is experimental and is not available for deprecated models. Visualizations are available for all newly created experiments.
Make Autoreport¶
Specify whether to create the experiment Autoreport after the experiment is finished. This is enabled by default.
Min Number of Rows Needed to Run an Experiment¶
Specify the minimum number of rows that a dataset must contain in order to run an experiment. This value defaults to 100.
Reproducibility Level¶
Specify one of the following levels of reproducibility. Note that this setting is only used when the Reproducible option is enabled in the experiment:
1 = Same experiment results for same O/S, same CPU(s), and same GPU(s) (Default)
2 = Same experiment results for same O/S, same CPU architecture, and same GPU architecture
3 = Same experiment results for same O/S, same CPU archicture (excludes GPUs)
4 = Same experiment results for same O/S (best approximation)
This value defaults to 1.
Random Seed¶
Specify a random seed for the experiment. When a seed is defined and the reproducible button is enabled (not by default), the algorithm will behave deterministically.
Allow Different Sets of Classes Across All Train/Validation Fold Splits¶
(Note: Applicable for multiclass problems only.) Specify whether to enable full cross-validation (multiple folds) during feature evolution as opposed to a single holdout split. This is enabled by default.
Max Number of Classes for Classification Problems¶
Specify the maximum number of classes to allow for a classification problem. A higher number of classes may make certain processes more time-consuming. Memory requirements also increase with a higher number of classes. This value defaults to 200.
Max Number of Classes to Compute ROC and Confusion Matrix for Classification Problems¶
Specify the maximum number of classes to use when computing the ROC and CM. When this value is exceeded, the reduction type specified by roc_reduce_type is applied. This value defaults to 200 and cannot be lower than 2.
Max Number of Classes to Show in GUI for Confusion Matrix¶
Specify the maximum number of classes to show in the GUI for CM, showing first max_num_classes_client_and_gui labels. This value defaults to 10, but any value beyond 6 will result in visually truncated diagnostics. Note that if this value is changed in the config.toml and the server is restarted, then this setting will only modify client-GUI launched diagnostics. To control experiment plots, this value must be changed in the expert settings panel.
ROC/CM Reduction Technique for Large Class Counts¶
Specify the ROC/CM reduction technique used for large class counts:
ROWS: Reduce by randomly sampling rows
CLASSES: Reduce by truncating classes to no more than the value specified by
max_num_classes_compute_roc
This defaults to ROWS.
Model/Feature Brain Level¶
Specify whether to use H2O.ai brain, which enables local caching and smart re-use (checkpointing) of prior experiments to generate useful features and models for new experiments. It can also be used to control checkpointing for experiments that have been paused or interrupted.
When enabled, this will use the H2O.ai brain cache if the cache file:
has any matching column names and types for a similar experiment type
has classes that match exactly
has class labels that match exactly
has basic time series choices that match
the interpretability of the cache is equal or lower
the main model (booster) is allowed by the new experiment
-1: Don’t use any brain cache (default)
0: Don’t use any brain cache but still write to cache. Use case: Want to save the model for later use, but we want the current model to be built without any brain models.
1: Smart checkpoint from the latest best individual model. Use case: Want to use the latest matching model. The match may not be precise, so use with caution.
2: Smart checkpoint if the experiment matches all column names, column types, classes, class labels, and time series options identically. Use case: Driverless AI scans through the H2O.ai brain cache for the best models to restart from.
3: Smart checkpoint like level #1 but for the entire population. Tune only if the brain population is of insufficient size. Note that this will re-score the entire population in a single iteration, so it appears to take longer to complete first iteration.
4: Smart checkpoint like level #2 but for the entire population. Tune only if the brain population is of insufficient size. Note that this will re-score the entire population in a single iteration, so it appears to take longer to complete first iteration.
5: Smart checkpoint like level #4 but will scan over the entire brain cache of populations to get the best scored individuals. Note that this can be slower due to brain cache scanning if the cache is large.
When enabled, the directory where the H2O.ai Brain meta model files are stored is H2O.ai_brain. In addition, the default maximum brain size is 20GB. Both the directory and the maximum size can be changed in the config.toml file. This value defaults to 2.
Feature Brain Save Every Which Iteration¶
Save feature brain iterations every iter_num % feature_brain_iterations_save_every_iteration == 0, to be able to restart/refit with which_iteration_brain >= 0. This is disabled (0) by default.
-1: Don’t use any brain cache.
0: Don’t use any brain cache but still write to cache.
1: Smart checkpoint if an old experiment_id is passed in (for example, via running “resume one like this” in the GUI).
2: Smart checkpoint if the experiment matches all column names, column types, classes, class labels, and time series options identically. (default)
3: Smart checkpoint like level #1 but for the entire population. Tune only if the brain population is of insufficient size.
4: Smart checkpoint like level #2 but for the entire population. Tune only if the brain population is of insufficient size.
5: Smart checkpoint like level #4 but will scan over the entire brain cache of populations (starting from resumed experiment if chosen) in order to get the best scored individuals.
When enabled, the directory where the H2O.ai Brain meta model files are stored is H2O.ai_brain. In addition, the default maximum brain size is 20GB. Both the directory and the maximum size can be changed in the config.toml file.
Feature Brain Restart from Which Iteration¶
When performing restart or re-fit of type feature_brain_level with a resumed ID, specify which iteration to start from instead of only last best. Available options include:
-1: Use the last best
1: Run one experiment with feature_brain_iterations_save_every_iteration=1 or some other number
2: Identify which iteration brain dump you wants to restart/refit from
3: Restart/Refit from the original experiment, setting which_iteration_brain to that number here in expert settings.
Note: If restarting from a tuning iteration, this will pull in the entire scored tuning population and use that for feature evolution. This value defaults to -1.
Feature Brain Refit Uses Same Best Individual¶
Specify whether to use the same best individual when performing a refit. Disabling this setting allows the order of best individuals to be rearranged, leading to a better final result. Enabling this setting allows you to view the exact same model or feature with only one new feature added. This is disabled by default.
Feature Brain Adds Features with New Columns Even During Retraining of Final Model¶
Specify whether to add additional features from new columns to the pipeline, even when performing a retrain of the final model. Use this option if you want to keep the same pipeline regardless of new columns from a new dataset. New data may lead to new dropped features due to shift or leak detection. Disable this to avoid adding any columns as new features so that the pipeline is perfectly preserved when changing data. This is enabled by default.
Restart-Refit Use Default Model Settings If Model Switches¶
When restarting or refitting, specify whether to use the model class’s default settings if the original model class is no longer available. If this is disabled, the original hyperparameters will be used instead. (Note that this may result in errors.) This is enabled by default.
Min DAI Iterations¶
Specify the minimum number of Driverless AI iterations for an experiment. This can be used during restarting, when you want to continue for longer despite a score not improving. This value defaults to 0.
Select Target Transformation of the Target for Regression Problems¶
Specify whether to automatically select target transformation for regression problems. Selecting identity disables any transformation. This is set to AUTO by default.
Tournament Model for Genetic Algorithm¶
Select a method to decide which models are best at each iteration. This is set to AUTO by default. Choose from the following:
auto: Choose based on scoring metric
fullstack: Choose from optimal model and feature types
feature: Individuals with similar feature types compete
model: Individuals with same model type compete
uniform: All individuals in population compete
Number of Cross-Validation Folds for Feature Evolution¶
Specify the fixed number of cross-validation folds (if >= 2) for feature evolution. Note that the actual number of allowed folds can be less than the specified value, and that the number of allowed folds is determined at the time an experiment is run. This value defaults to -1 (auto).
Number of Cross-Validation Folds for Final Model¶
Specify the fixed number of cross-validation folds (if >= 2) for the final model. Note that the actual number of allowed folds can be less than the specified value, and that the number of allowed folds is determined at the time an experiment is run. This value defaults to -1 (auto).
Max Number of Rows Times Number of Columns for Feature Evolution Data Splits¶
Specify the maximum number of rows allowed for feature evolution data splits (not for the final pipeline). This value defaults to 100,000,000.
Max Number of Rows Times Number of Columns for Reducing Training Dataset¶
Specify the upper limit on the number of rows times the number of columns for training the final pipeline. This value defaults to 500,000,000.
Maximum Size of Validation Data Relative to Training Data¶
Specify the maximum size of the validation data relative to the training data. Smaller values can make the final pipeline model training process quicker. Note that final model predictions and scores will always be provided on the full dataset provided. This value defaults to 2.0.
Perform Stratified Sampling for Binary Classification If the Target Is More Imbalanced Than This¶
For binary classification experiments, specify a threshold ratio of minority to majority class for the target column beyond which stratified sampling is performed. If the threshold is not exceeded, random sampling is performed. This value defaults to 0.1. You can choose to always perform random sampling by setting this value to 0, or to always perform stratified sampling by setting this value to 1.
Add to config.toml via toml String¶
Specify any additional configuration overrides from the config.toml file that you want to include in the experiment. (Refer to the Sample Config.toml File section to view options that can be overridden during an experiment.) Setting this will override all other settings. Separate multiple config overrides with \n. For example, the following enables Poisson distribution for LightGBM and disables Target Transformer Tuning. Note that in this example double quotes are escaped (\" \").
params_lightgbm=\"{'objective':'poisson'}\" \n target_transformer=identity
Or you can specify config overrides similar to the following without having to escape double quotes:
""enable_glm="off" \n enable_xgboost_gbm="off" \n enable_lightgbm="off" \n enable_tensorflow="on"""
""max_cores=10 \n data_precision="float32" \n max_rows_feature_evolution=50000000000 \n ensemble_accuracy_switch=11 \n feature_engineering_effort=1 \n target_transformer="identity" \n tournament_feature_style_accuracy_switch=5 \n params_tensorflow="{'layers': [100, 100, 100, 100, 100, 100]}"""
When running the Python client, config overrides would be set as follows:
model = h2o.start_experiment_sync(
dataset_key=train.key,
target_col='target',
is_classification=True,
accuracy=7,
time=5,
interpretability=1,
config_overrides="""
feature_brain_level=0
enable_lightgbm="off"
enable_xgboost_gbm="off"
enable_ftrl="off"
"""
)
Model Settings¶
XGBoost GBM Models¶
This option allows you to specify whether to build XGBoost models as part of the experiment (for both the feature engineering part and the final model). XGBoost is a type of gradient boosting method that has been widely successful in recent years due to its good regularization techniques and high accuracy. This is set to AUTO by default. In this case, Driverless AI will use XGBoost unless the number of rows * columns is greater than a threshold. This threshold is a config setting that is 100M by default for CPU and 30M by default for GPU.
XGBoost Dart Models¶
This option specifies whether to use XGBoost’s Dart method when building models for experiment (for both the feature engineering part and the final model). This is set to AUTO (disabled) by default.
GLM Models¶
This option allows you to specify whether to build GLM models (generalized linear models) as part of the experiment (usually only for the final model unless it’s used exclusively). GLMs are very interpretable models with one coefficient per feature, an intercept term and a link function. This is set to AUTO by default (enabled if accuracy <= 5 and interpretability >= 6).
Decision Tree Models¶
This option allows you to specify whether to build Decision Tree models as part of the experiment. This is set to AUTO by default. In this case, Driverless AI will build Decision Tree models if interpretability is greater than or equal to the value of decision_tree_interpretibility_switch (which defaults to 7) and accuracy is less than or equal to decision_tree_accuracy_switch (which defaults to 7).
LightGBM Models¶
This option allows you to specify whether to build LightGBM models as part of the experiment. LightGBM Models are the default models. This is set to AUTO (enabled) by default.
TensorFlow Models¶
This option allows you to specify whether to build TensorFlow models as part of the experiment (usually only for text features engineering and for the final model unless it’s used exlusively). Enable this option for NLP experiments. This is set to AUTO by default (not used unless the number of classes is greater than 10).
TensorFlow models are not yet supported by MOJOs (only Python scoring pipelines are supported).
FTRL Models¶
This option allows you to specify whether to build Follow the Regularized Leader (FTRL) models as part of the experiment. Note that MOJOs are not yet supported (only Python scoring pipelines). FTRL supports binomial and multinomial classification for categorical targets, as well as regression for continuous targets. This is set to AUTO (disabled) by default.
RuleFit Models¶
This option allows you to specify whether to build RuleFit models as part of the experiment. Note that MOJOs are not yet supported (only Python scoring pipelines). Note that multiclass classification is not yet supported for RuleFit models. Rules are stored to text files in the experiment directory for now. This is set to AUTO (disabled) by default.
LightGBM Boosting Types¶
Specify which boosting types to enable for LightGBM. Select one or more of the following:
gbdt: Boosted trees
rf_early_stopping: Random Forest with early stopping
rf: Random Forest
dart: Dropout boosted trees with no early stopping
gbdt and rf are both enabled by default.
LightGBM Categorical Support¶
Specify whether to enable LightGBM categorical feature support (currently only available for CPU mode). This is disabled by default.
LightGBM CUDA Support¶
Specify whether to enable LightGBM CUDA implementation instead of OpenCL. This enables LightGBM models to run on GPUs on IBM Power machines. LightGBM CUDA is supported on both IBM Power and Linux x86-64 environments.
Constant Models¶
Specify whether to enable constant models. This is set to AUTO (enabled) by default.
Whether to Show Constant Models in Iteration Panel¶
Specify whether to show constant models in the iteration panel. This is disabled by default.
Parameters for TensorFlow¶
Specify specific parameters for TensorFlow to override Driverless AI parameters. The following is an example of how the parameters can be configured:
params_tensorflow = '{'lr': 0.01, 'add_wide': False, 'add_attention': True, 'epochs': 30,
'layers': [100, 100], 'activation': 'selu', 'batch_size': 64, 'chunk_size': 1000, 'dropout': 0.3,
'strategy': 'one_shot', 'l1': 0.0, 'l2': 0.0, 'ort_loss': 0.5, 'ort_loss_tau': 0.01, 'normalize_type': 'streaming'}'
The following is an example of how layers can be configured:
[500, 500, 500], [100, 100, 100], [100, 100], [50, 50]
More information about TensorFlow parameters can be found in the Keras documentation. Different strategies for using TensorFlow parameters can be viewed here.
Max Number of Trees/Iterations¶
Specify the upper limit on the number of trees (GBM) or iterations (GLM). This defaults to 3000. Depending on accuracy settings, a fraction of this limit will be used.
n_estimators List to Sample From for Model Mutations for Models That Do Not Use Early Stopping¶
For LightGBM, the dart and normal random forest modes do not use early stopping. This setting allows you to specify the n_estimators (number of trees in the forest) list to sample from for model mutations for these types of models.
Minimum Learning Rate for Final Ensemble GBM Models¶
Specify the minimum learning rate for final ensemble GBM models. This value defaults to 0.01.
Maximum Learning Rate for Final Ensemble GBM Models¶
Specify the maximum learning rate for final ensemble GBM models. This value defaults to 0.05.
Reduction Factor for Number of Trees/Iterations During Feature Evolution¶
Specify the factor by which max_nestimators is reduced for tuning and feature evolution. This option defaults to 0.2. So by default, Driverless AI will produce no more than 0.2 * 3000 trees/iterations during feature evolution.
Minimum Learning Rate for Feature Engineering GBM Models¶
Specify the minimum learning rate for feature engineering GBM models. This value defaults to 0.05.
Max Learning Rate for Tree Models¶
Specify the maximum learning rate for tree models during feature engineering. Higher values can speed up feature engineering but can hurt accuracy. This value defaults to 0.5.
Max Number of Epochs for TensorFlow/FTRL¶
When building TensorFlow or FTRL models, specify the maximum number of epochs to train models with (it might stop earlier). This value defaults to 10. This option is ignored if TensorFlow models and/or FTRL models is disabled.
Max Tree Depth¶
Specify the maximum tree depth. The corresponding maximum value for max_leaves is double the specified value. This value defaults to 12.
Max max_bin for Tree Features¶
Specify the maximum max_bin for tree features. This value defaults to 256.
Max Number of Rules for RuleFit¶
Specify the maximum number of rules to be used for RuleFit models. This defaults to -1, which specifies to use all rules.
Ensemble Level for Final Modeling Pipeline¶
Specify one of the following ensemble levels:
-1 = auto, based upon ensemble_accuracy_switch, accuracy, size of data, etc. (Default)
0 = No ensemble, only final single model on validated iteration/tree count. Note that holdout predicted probabilities will not be available. (Refer to the following FAQ.)
1 = 1 model, multiple ensemble folds (cross-validation)
2 = 2 models, multiple ensemble folds (cross-validation)
3 = 3 models, multiple ensemble folds (cross-validation)
4 = 4 models, multiple ensemble folds (cross-validation)
Cross-Validate Single Final Model¶
Driverless AI normally produces a single final model for low accuracy settings (typically, less than 5). When the Cross-validate single final model option is enabled (default for regular experiments), Driverless AI will perform cross-validation to determine optimal parameters and early stopping before training the final single modeling pipeline on the entire training data. The final pipeline will build \(N+1\) models, with N-fold cross validation for the single final model. This also creates holdout predictions for all non-time-series experiments with a single final model.
Note that the setting for this option is ignored for time-series experiments or when a validation dataset is provided.
Number of Models During Tuning Phase¶
Specify the number of models to tune during pre-evolution phase. Specify a lower value to avoid excessive tuning, or specify a higher to perform enhanced tuning. This option defaults to -1 (auto).
Sampling Method for Imbalanced Binary Classification Problems¶
Specify the sampling method for imbalanced binary classification problems. This is set to off by default. Choose from the following options:
auto: sample both classes as needed, depending on data
over_under_sampling: over-sample the minority class and under-sample the majority class, depending on data
under_sampling: under-sample the majority class to reach class balance
off: do not perform any sampling
This option is closely tied with the Imbalanced Light GBM and Imbalanced XGBoost GBM models, which can be enabled/disabled on the Recipes tab under Include Specific Models. Specifically:
If this option is ENABLED (set to a value other than off) and the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are ENABLED, then Driverless AI will check your target imbalance fraction. If the target fraction proves to be above the allowed imbalance threshold, then sampling will be triggered.
If this option is ENABLED and the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are DISABLED, then no special sampling technique will be performed. The setting here will be ignored.
If this option is DISABLED and the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are ENABLED, sampling will not be used, and the imbalanced models will be disabled.
This means that to enable sampling, you should enable this option (either as auto, over_under_sampling, or under_sampling) AND enable the imbalanced models.
Ratio of Majority to Minority Class for Imbalanced Binary Classification to Trigger Special Sampling Techniques (if Enabled)¶
For imbalanced binary classification problems, specify the ratio of majority to minority class. Special imbalanced models with sampling techniques are enabled when the ratio is equal to or greater than the specified ratio. This value defaults to 5.
Ratio of Majority to Minority Class for Heavily Imbalanced Binary Classification to Only Enable Special Sampling Techniques if Enabled¶
For heavily imbalanced binary classification, specify the ratio of the majority to minority class equal and above which to enable only special imbalanced models on the full original data without upfront sampling. This value defaults to 25.
Number of Bags for Sampling Methods for Imbalanced Binary Classification (if Enabled)¶
Specify the number of bags for sampling methods for imbalanced binary classification. This value defaults to -1.
Hard Limit on Number of Bags for Sampling Methods for Imbalanced Binary Classification¶
Specify the limit on the number of bags for sampling methods for imbalanced binary classification. This value defaults to 10.
Hard Limit on Number of Bags for Sampling Methods for Imbalanced Binary Classification During Feature Evolution Phase¶
Specify the limit on the number of bags for sampling methods for imbalanced binary classification. This value defaults to 3. Note that this setting only applies to shift, leakage, tuning, and feature evolution models. To limit final models, use the Hard Limit on Number of Bags for Sampling Methods for Imbalanced Binary Classification setting.
Max Size of Data Sampled During Imbalanced Sampling¶
Specify the maximum size of the data sampled during imbalanced sampling in terms of the dataset’s size. This setting controls the approximate number of bags and is only active when the “Hard limit on number of bags for sampling methods for imbalanced binary classification during feature evolution phase” option is set to -1. This value defaults to 1.
Target Fraction of Minority Class After Applying Under/Over-Sampling Techniques¶
Specify the target fraction of a minority class after applying under/over-sampling techniques. A value of 0.5 means that models/algorithms will be given a balanced target class distribution. When starting from an extremely imbalanced original target, it can be advantageous to specify a smaller value such as 0.1 or 0.01. This value defaults to -1.
Max Number of Automatic FTRL Interactions Terms for 2nd, 3rd, 4th order interactions terms (Each)¶
Specify a limit for the number of FTRL interactions terms sampled for each of second, third, and fourth order terms. This value defaults to 10,000.
Enable Detailed Scored Model Info¶
Specify whether to dump every scored individual’s model parameters to a csv/tabulated file. If enabled (default), Driverless AI produces files such as “individual_scored_id%d.iter%d*params*”. This is enabled by default.
Whether to Enable Bootstrap Sampling for Validation and Test Scores¶
Specify whether to enable bootstrap sampling. When enabled, this setting provides error bars to validation and test scores based on the standard error of the bootstrap mean. This is enabled by default.
For Classification Problems with This Many Classes, Default to TensorFlow¶
Specify the number of classes above which to use TensorFlow when it is enabled. Others model that are set to AUTO will not be used above this number. (Models set to ON, however, are still used.) This value defaults to 10.
Features Settings¶
Feature Engineering Effort¶
Specify a value from 0 to 10 for the Driverless AI feature engineering effort. Higher values generally lead to more time (and memory) spent in feature engineering. This value defaults to 5.
0: Keep only numeric features. Only model tuning during evolution.
1: Keep only numeric features and frequency-encoded categoricals. Only model tuning during evolution.
2: Similar to 1 but instead just no Text features. Some feature tuning before evolution.
3: Similar to 5 but only tuning during evolution. Mixed tuning of features and model parameters.
4: Similar to 5 but slightly more focused on model tuning.
5: Balanced feature-model tuning. (Default)
6-7: Similar to 5 but slightly more focused on feature engineering.
8: Similar to 6-7 but even more focused on feature engineering with high feature generation rate and no feature dropping even if high interpretability.
9-10: Similar to 8 but no model tuning during feature evolution.
Data Distribution Shift Detection¶
Specify whether Driverless AI should detect data distribution shifts between train/valid/test datasets (if provided). Currently, this information is only presented to the user and not acted upon.
Data Distribution Shift Detection Drop of Features¶
Specify whether to drop high-shift features. This defaults to AUTO. Note that Auto for time series experiments turns this feature off.
Max Allowed Feature Shift (AUC) Before Dropping Feature¶
Specify the maximum allowed AUC value for a feature before dropping the feature.
When train and test differ (or train/valid or valid/test) in terms of distribution of data, then there can be a model built that tells you for each row whether the row is in train or test. That model includes an AUC value. If the AUC, GINI, or Spearman correlation is above this specified threshold, then Driverless AI will consider it a strong enough shift to drop those features.
This value defaults to 0.999.
Leakage Detection¶
Specify whether to check leakage for each feature. Note that this is always disabled if a fold column is specified and if the experiment is a time series experiment. This is set to AUTO by default.
Leakage Detection Dropping AUC/R2 Threshold¶
If Leakage Detection is enabled, specify the threshold for dropping features. When the AUC (or R2 for regression), GINI, or Spearman correlation is above this value, the feature will be dropped. This value defaults to 0.999.
Max Rows Times Columns for Leakage¶
Specify the maximum number of rows times the number of columns to trigger sampling for leakage checks. This value defaults to 10,000,000.
Report Permutation Importance on Original Features¶
Specify whether Driverless AI reports permutation importance on original features. This is disabled by default.
Maximum Number of Rows to Perform Permutation-Based Feature Selection¶
Specify the maximum number of rows to use when performing permutation feature importance. This value defaults to 500,000.
Max Number of Original Features Used¶
Specify the maximum number of columns to be selected from an existing set of columns using feature selection. This value defaults to 10,000.
Max Number of Original Non-Numeric Features¶
Specify the maximum number of non-numeric columns to be selected. Feature selection is performed on all features when this value is exceeded. This value defaults to 300.
Max Number of Original Features Used for FS Individual¶
Specify the maximum number of features you want to be selected in an experiment. Additional columns above the specified value add special individual with original columns reduced. This value defaults to 500.
Number of Original Numeric Features to Trigger Feature Selection Model Type¶
The maximum number of original numeric columns, above which Driverless AI will do feature selection. Note that this is applicable only to special individuals with original columns reduced. A separate individual in the genetic algorithm is created by doing feature selection by permutation importance on original features. This value defaults to 500.
Number of Original Non-Numeric Features to Trigger Feature Selection Model Type¶
The maximum number of original non-numeric columns, above which Driverless AI will do feature selection on all features. Note that this is applicable only to special individuals with original columns reduced. A separate individual in the genetic algorithm is created by doing feature selection by permutation importance on original features. This value defaults to 200.
Max Allowed Fraction of Uniques for Integer and Categorical Columns¶
Specify the maximum fraction of unique values for integer and categorical columns. If the column has a larger fraction of unique values than that, it will be considered an ID column and ignored. This value defaults to 0.95.
Allow Treating Numerical as Categorical¶
Specify whether to allow some numerical features to be treated as categorical features. This is enabled by default.
Max Number of Unique Values for Int/Float to be Categoricals¶
Specify the number of unique values for integer or real columns to be treated as categoricals. This value defaults to 50.
Max Number of Engineered Features¶
Specify the maximum number of features to include in the final model’s feature engineering pipeline. If -1 is specified (default), then Driverless AI will automatically determine the number of features.
Max Number of Genes¶
Specify the maximum number of genes (transformer instances) kept per model (and per each model within the final model for ensembles). This controls the number of genes before features are scored, so Driverless AI will just randomly samples genes if pruning occurs. If restriction occurs after scoring features, then aggregated gene importances are used for pruning genes. Instances includes all possible transformers, including original transformer for numeric features. A value of -1 means no restrictions except internally-determined memory and interpretability restriction.
Monotonicity Constraints¶
Interpretability setting equal and above which will use automatic monotonicity constraints in XGBoostGBM/LightGBM/DecisionTree models.
Correlation Beyond Which Triggers Monotonicity Constraints (if Enabled)¶
The threshold of Pearson product-moment correlation coefficient between numerical (or encoded transformed) features and the target to automatically enable monotonicity constraints. This value defaults to 0.1. If correlation <= -0.1, negative monotonicity will be enforced (-1). If correlation >= 0.1, positive monotonicity will be enforced (+1). Otherwise, no monotonocity will be enforced (0). This is only used if interpretability is high enough and only if monotonicity_constraints_dict is not provided.
Manual Override for Monotonicity Constraints¶
Specify a list of features for which monotonicity contraints are applied. Original numeric features are mapped to the desired constraint:
1: Positive constraint
-1: Negative constraint
0: Constraint disabled
Constraint is automatically disabled (set to 0) for features that are not in this list.
The following is an example of how this list can be specified:
"{'PAY_0': -1, 'PAY_2': -1, 'AGE': -1, 'BILL_AMT1': 1, 'PAY_AMT1': -1}"
If a list is not specified, then the automatic correlation-based method is used when monotonicity constraints are enabled at high enough interpretability setting levels.
Max Feature Interaction Depth¶
Specify the maximum number of features to use for interaction features like grouping for target encoding, weight of evidence, and other likelihood estimates.
Exploring feature interactions can be important in gaining better predictive performance. The interaction can take multiple forms (i.e. feature1 + feature2 or feature1 * feature2 + … featureN). Although certain machine learning algorithms (like tree-based methods) can do well in capturing these interactions as part of their training process, still generating them may help them (or other algorithms) yield better performance.
The depth of the interaction level (as in “up to” how many features may be combined at once to create one single feature) can be specified to control the complexity of the feature engineering process. Higher values might be able to make more predictive models at the expense of time. This value defaults to 8.
Fixed Feature Interaction Depth¶
Specify a fixed non-zero number of features to use for interaction features like grouping for target encoding, weight of evidence, and other likelihood estimates. To use all features for each transformer, set this to be equal to the number of columns. To do a 50/50 sample and a fixed feature interaction depth of \(n\) features, set this to -\(n\).
Enable Target Encoding¶
Specify whether to use Target Encoding when building the model. Target encoding refers to several different feature transformations (primarily focused on categorical data) that aim to represent the feature using information of the actual target variable. A simple example can be to use the mean of the target to replace each unique category of a categorical feature. These type of features can be very predictive but are prone to overfitting and require more memory as they need to store mappings of the unique categories and the target values.
Enable Lexicographical Label Encoding¶
Specify whether to enable lexicographical label encoding. This is disabled by default.
Enable Isolation Forest Anomaly Score Encoding¶
Isolation Forest is useful for identifying anomalies or outliers in data. Isolation Forest isolates observations by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of that selected feature. This split depends on how long it takes to separate the points. Random partitioning produces noticeably shorter paths for anomalies. When a forest of random trees collectively produces shorter path lengths for particular samples, they are highly likely to be anomalies.
This option allows you to specify whether to return the anomaly score of each sample. This is disabled by default.
Enable One HotEncoding¶
Specify whether one-hot encoding is enabled. The default AUTO setting is only applicable for small datasets and GLMs.
Number of Estimators for Isolation Forest Encoding¶
Specify the number of estimators for Isolation Forest encoding. This value defaults to 200.
Drop Constant Columns¶
Specify whether to drop columns with constant values. This is enabled by default.
Drop ID Columns¶
Specify whether to drop columns that appear to be an ID. This is enabled by default.
Don’t Drop Any Columns¶
Specify whether to avoid dropping any columns (original or derived). This is disabled by default.
Features to Drop¶
Specify which features to drop. This setting allows you to select many features at once by copying and pasting a list of column names (in quotes) separated by commas.
Features to Group By¶
Specify which features to group columns by. When this field is left empty (default), Driverless AI automatically searches all columns (either at random or based on which columns have high variable importance).
Sample from Features to Group By¶
Specify whether to sample from given features to group by or to always group all features. This is disabled by default.
Aggregation Functions (Non-Time-Series) for Group By Operations¶
Specify whether to enable aggregation functions to use for group by operations. Choose from the following (all are selected by default):
mean
sd
min
max
count
Number of Folds to Obtain Aggregation When Grouping¶
Specify the number of folds to obtain aggregation when grouping. Out-of-fold aggregations will result in less overfitting, but they analyze less data in each fold.
Type of Mutation Strategy¶
Specify which strategy to apply when performing mutations on transformers. Select from the following:
sample: Sample transformer parameters (Default)
batched: Perform multiple types of the same transformation together
full: Perform more types of the same transformation together than the above strategy
Enable Detailed Scored Features Info¶
Specify whether to dump every scored individual’s variable importance (both derived and original) to a csv/tabulated/json file. If enabled, Driverless AI produces files such as “individual_scored_id%d.iter%d*features*”. This is disabled by default.
Enable Detailed Logs for Timing and Types of Features Produced¶
Specify whether to dump every scored fold’s timing and feature info to a timings.txt file. This is disabled by default.
Compute Correlation Matrix¶
Specify whether to compute training, validation, and test correlation matrixes. When enabled, this setting creates table and heatmap PDF files that are saved to disk. Note that this setting is currently a single threaded process that may be slow for experiments with many columns. This is disabled by default.
Required GINI Relative Improvement for Interactions¶
Specify the required GINI relative improvement value for the InteractionTransformer. If the GINI coefficient is not better than the specified relative improvement value in comparison to the original features considered in the interaction, then the interaction is not returned. If the data is noisy and there is no clear signal in interactions, this value can be decreased to return interactions. This value defaults to 0.5.
Number of Transformed Interactions to Make¶
Specify the number of transformed interactions to make from generated trial interactions. (The best transformed interactions are selected from the group of generated trial interactions.) This value defaults to 5.
Time Series Settings¶
Time-Series Lag-Based Recipe¶
This recipe specifies whether to include Time Series lag features when training a model with a provided (or autodetected) time column. This is enabled by default. Lag features are the primary automatically generated time series features and represent a variable’s past values. At a given sample with time stamp \(t\), features at some time difference \(T\) (lag) in the past are considered. For example, if the sales today are 300, and sales of yesterday are 250, then the lag of one day for sales is 250. Lags can be created on any feature as well as on the target. Lagging variables are important in time series because knowing what happened in different time periods in the past can greatly facilitate predictions for the future. Note: Ensembling is disabled when the lag-based recipe with time columns is activated because it only supports a single final model. Ensembling is also disabled if a time column is selected or if time column is set to [AUTO] on the experiment setup screen.
More information about time series lag is available in the Time Series Use Case: Sales Forecasting section.
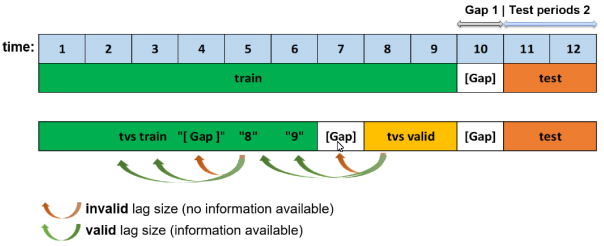
Custom Validation Splits for Time-Series Experiments¶
Specify date or datetime timestamps (in the same format as the time column) to use for custom training and validation splits.
Timeout in Seconds for Time-Series Properties Detection in UI¶
Specify the timeout in seconds for time-series properties detection in Driverless AI’s user interface. This value defaults to 30.
Generate Holiday Features¶
For time-series experiments, specify whether to generate holiday features for the experiment. This is enabled by default.
List of Countries for Which to Look up Holiday Calendar and to Generate Is-Holiday Features For¶
Specify country codes in the form of a list that is used to look up holidays.
Time-Series Lags Override¶
Specify the override lags to be used. These can be used to give more importance to the lags that are still considered after the override is applied. The following examples show the variety of different methods that can be used to specify override lags:
“[7, 14, 21]” specifies this exact list
“21” specifies every value from 1 to 21
“21:3” specifies every value from 1 to 21 in steps of 3
“5-21” specifies every value from 5 to 21
“5-21:3” specifies every value from 5 to 21 in steps of 3
Smallest Considered Lag Size¶
Specify a minimum considered lag size. This value defaults to -1.
Enable Feature Engineering from Time Column¶
Specify whether to enable feature engineering based on the selected time column, e.g. Date~weekday. This is enabled by default.
Allow Integer Time Column as Numeric Feature¶
Specify whether to allow an integer time column to be used as a numeric feature. Note that if you are using a time series recipe, using a time column (numeric time stamps) as an input feature can lead to a model that memorizes the actual timestamps instead of features that generalize to the future. This is disabled by default.
Allowed Date and Date-Time Transformations¶
Specify the date or date-time transformations to allow Driverless AI to use. Choose from the following transformers:
year
quarter
month
week
weekday
day
dayofyear
num (direct numeric value representing the floating point value of time, disabled by default)
hour
minute
second
Features in Driverless AI will appear as get_ followed by the name of the transformation. Note that get_num can lead to overfitting if used on IID problems and is disabled by default.
Consider Time Groups Columns as Standalone Features¶
Specify whether to consider time groups columns as standalone features. This is disabled by default.
Which TGC Feature Types to Consider as Standalone Features¶
Specify whether to consider time groups columns (TGC) as standalone features. If “Consider time groups columns as standalone features” is enabled, then specify which TGC feature types to consider as standalone features. Available types are numeric, categorical, ohe_categorical, datetime, date, and text. All types are selected by default. Note that “time_column” is treated separately via the “Enable Feature Engineering from Time Column” option. Also note that if “Time Series Lag-Based Recipe” is disabled, then all time group columns are allowed features.
Enable Time Unaware Transformers¶
Specify whether various transformers (clustering, truncated SVD) are enabled, which otherwise would be disabled for time series experiments due to the potential to overfit by leaking across time within the fit of each fold. This is set to AUTO by default.
Always Group by All Time Groups Columns for Creating Lag Features¶
Specify whether to group by all time groups columns for creating lag features. This is enabled by default.
Generate Time-Series Holdout Predictions¶
Specify whether to create diagnostic holdout predictions on training data using moving windows. This is enabled by default. This can be useful for MLI, but it will slow down the experiment considerably when enabled. Note that the model itself remains unchanged when this setting is enabled.
Number of Time-Based Splits for Internal Model Validation¶
Specify a fixed number of time-based splits for internal model validation. Note that the actual number of allowed splits can be less than the specified value, and that the number of allowed splits is determined at the time an experiment is run. This value defaults to -1 (auto).
Maximum Overlap Between Two Time-Based Splits¶
Specify the maximum overlap between two time-based splits. The amount of possible splits increases with higher values. This value defaults to 0.5.
Maximum Number of Splits Used for Creating Final Time-Series Model’s Holdout Predictions¶
Specify the maximum number of splits used for creating the final time-series Model’s holdout predictions. The default value (-1) will use the same number of splits that are used during model validation.
Whether to Speed up Calculation of Time-Series Holdout Predictions¶
Specify whether to speed up time-series holdout predictions for back-testing on training data. This setting is used for MLI and calculating metrics. Note that predictions can be slightly less accurate when this setting is enabled. This is disabled by default.
Whether to Speed up Calculation of Shapley Values for Time-Series Holdout Predictions¶
Specify whether to speed up Shapley values for time-series holdout predictions for back-testing on training data. This setting is used for MLI. Note that predictions can be slightly less accurate when this setting is enabled. This is enabled by default.
Generate Shapley Values for Time-Series Holdout Predictions at the Time of Experiment¶
Specify whether to enable the creation of Shapley values for holdout predictions on training data using moving windows at the time of the experiment. This can be useful for MLI, but it can slow down the experiment when enabled. If this setting is disabled, MLI will generate Shapley values on demand. This is enabled by default.
Lower Limit on Interpretability Setting for Time-Series Experiments (Implicitly Enforced)¶
Specify the lower limit on interpretability setting for time-series experiments. Values of 5 (default) or more can improve generalization by more aggressively dropping the least important features. To disable this setting, set this value to 1.
Dropout Mode for Lag Features¶
Specify the dropout mode for lag features in order to achieve an equal n.a. ratio between train and validation/tests. Independent mode performs a simple feature-wise dropout. Dependent mode takes the lag-size dependencies per sample/row into account. Dependent is enabled by default.
Probability to Create Non-Target Lag Features¶
Lags can be created on any feature as well as on the target. Specify a probability value for creating non-target lag features. This value defaults to 0.1.
Method to Create Rolling Test Set Predictions¶
Specify the method used to create rolling test set predictions. Choose between test time augmentation (TTA) and a successive refitting of the final pipeline. TTA is enabled by default.
Probability for New Time-Series Transformers to Use Default Lags¶
Specify the probability for new lags or the EWMA gene to use default lags. This is determined independently of the data by frequency, gap, and horizon. This value defaults to 0.2.
Probability of Exploring Interaction-Based Lag Transformers¶
Specify the unnormalized probability of choosing other lag time-series transformers based on interactions. This value defaults to 0.2.
Probability of Exploring Aggregation-Based Lag Transformers¶
Specify the unnormalized probability of choosing other lag time-series transformers based on aggregations. This value defaults to 0.2.
NLP Settings¶
Max TensorFlow Epochs for NLP¶
When building TensorFlow NLP features (for text data), specify the maximum number of epochs to train feature engineering models with (it might stop earlier). The higher the number of epochs, the higher the run time. This value defaults to 2 and is ignored if TensorFlow models is disabled.
Accuracy Above Enable TensorFlow NLP by Default for All Models¶
Specify the accuracy threshold. Values equal and above will add all enabled TensorFlow NLP models at the start of the experiment for text-dominated problems when the following NLP expert settings are set to AUTO:
Enable word-based CNN TensorFlow models for NLP
Enable word-based BigRU TensorFlow models for NLP
Enable character-based CNN TensorFlow models for NLP
If the above transformations are set to ON, this parameter is ignored.
At lower accuracy, TensorFlow NLP transformations will only be created as a mutation. This value defaults to 5.
Enable Word-Based CNN TensorFlow Models for NLP¶
Specify whether to use Word-based CNN TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
Enable Word-Based BiGRU TensorFlow Models for NLP¶
Specify whether to use Word-based BiG-RU TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
Enable Character-Based CNN TensorFlow Models for NLP¶
Specify whether to use Character-level CNN TensorFlow models for NLP. This option is ignored if TensorFlow is disabled. We recommend that you disable this option on systems that do not use GPUs.
Path to Pretrained Embeddings for TensorFlow NLP Models¶
Specify a path to pretrained embeddings that will be used for the TensorFlow NLP models. For example, /path/on/server/to/file.txt
You can download the Glove embeddings from here and specify the local path in this box.
You can download the fasttext embeddings from here and specify the local path in this box.
You can also train your own custom embeddings. Please refer to this code sample for creating custom embeddings that can be passed on to this option.
If this field is left empty, embeddings will be trained from scratch.
Allow Training of Unfrozen Pretrained Embeddings¶
Specify whether to allow training of all weights of the neural network graph, including the pretrained embedding layer weights. If this is disabled, the embedding layer will be frozen. All other weights, however, will still be fine-tuned. This is disabled by default.
Whether Python/MOJO Scoring Runtime Will Have GPUs¶
Specify whether the Python/MOJO scoring runtime will have GPUs (otherwise BiGRU will fail in production if this is enabled). Enabling this setting can speed up training for BiGRU, but doing so will require GPUs and CuDNN in production. This is disabled by default.
Fraction of Text Columns Out of All Features to be Considered a Text-Dominanted Problem¶
Specify the fraction of text columns out of all features to be considered as a text-dominated problem. This value defaults to 0.3.
Specify when a string column will be treated as text (for an NLP problem) or just as a standard categorical variable. Higher values will favor string columns as categoricals, while lower values will favor string columns as text. This value defaults to 0.3.
Fraction of Text per All Transformers to Trigger That Text Dominated¶
Specify the fraction of text columns out of all features to be considered a text-dominated problem. This value defaults to 0.3.
Threshold for String Columns to be Treated as Text¶
Specify the threshold value (from 0 to 1) for string columns to be treated as text (0.0 - text; 1.0 - string). This value defaults to 0.3.
Recipes Settings¶
Include Specific Transformers¶
Select the transformer(s) that you want to use in the experiment. Use the Check All/Uncheck All button to quickly add or remove all transfomers at once. Note: If you uncheck all transformers so that none is selected, Driverless AI will ignore this and will use the default list of transformers for that experiment. This list of transformers will vary for each experiment.
Include Specific Models¶
Specify the type(s) of models that you want Driverless AI to build in the experiment. This list includes natively supported algorithms and models added via custom recipes.
Note: The ImbalancedLightGBM and ImbalancedXGBoostGBM models are closely tied with the Sampling Method for Imbalanced Binary Classification Problems option. Specifically:
If the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are ENABLED and the Sampling Method for Imbalanced Binary Classification Problems is ENABLED (set to a value other than off), then Driverless AI will check your target imbalance fraction. If the target fraction proves to be above the allowed imbalance threshold, then sampling will be triggered.
If the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are DISABLED and the Sampling Method for Imbalanced Binary Classification Problems option is ENABLED, then no special sampling technique will be performed.
If the ImbalancedLightGBM and/or ImbalancedXGBoostGBM models are ENABLED and the Sampling Method for Imbalanced Binary Classification Problems is DISABLED, sampling will not be used, and these imbalanced models will be disabled.
Include Specific Scorers¶
Specify the scorer(s) that you want Driverless AI to include when running the experiment.
Probability to Add Transformers¶
Specify the unnormalized probability to add genes or instances of transformers with specific attributes. If no genes can be added, other mutations are attempted. This value defaults to 0.5.
Probability to Prune Transformers¶
Specify the unnormalized probability to prune genes or instances of transformers with specific attributes. This value defaults to 0.5.
Probability to Mutate Model Parameters¶
Specify the unnormalized probability to change model hyper parameters. This value defaults to 0.25.
Probability to Prune Weak Features¶
Specify the unnormalized probability to prune features that have low variable importance instead of pruning entire instances of genes/transformers. This value defaults to 0.25.
Timeout in Minutes for Testing Acceptance of Each Recipe¶
Specify the number of minutes to wait until a recipe’s acceptance testing is aborted. A recipe is rejected if acceptance testing is enabled and it times out. This value defaults to 20.0.
Whether to Skip Failures of Transformers¶
Specify whether to avoid failed transformers. This is enabled by default.
Whether to Skip Failures of Models¶
Specify whether to avoid failed models. Failures are logged according to the specified level for logging skipped failures. This is enabled by default.
Level to Log for Skipped Failures¶
Specify one of the following levels for the verbosity of log failure messages for skipped transformers or models:
0 = Log simple message
1 = Log code line plus message (Default)
2 = Log detailed stack traces
System Settings¶
Number of Cores to Use¶
Specify the number of cores to use for the experiment. Note that if you specify 0, all available cores will be used. Lower values can reduce memory usage but might slow down the experiment. This value defaults to 0.
Maximum Number of Cores to Use for Model Fit¶
Specify the maximum number of cores to use for a model’s fit call. Note that if you specify 0, all available cores will be used. This value defaults to 10.
Maximum Number of Cores to Use for Model Predict¶
Specify the maximum number of cores to use for a model’s predict call. Note that if you specify 0, all available cores will be used. This value defaults to 0.
Maximum Number of Cores to Use for Model Transform and Predict When Doing MLI, Autoreport¶
Specify the maximum number of cores to use for a model’s transform and predict call when doing operations in the Driverless AI MLI GUI and the Driverless AI R and Python clients. Note that if you specify 0, all available cores will be used. This value defaults to 4.
Tuning Workers per Batch for CPU¶
Specify the number of workers used in CPU mode for tuning. A value of 0 uses the socket count, while a value of -1 uses all physical cores greater than or equal to 1 that count. This value defaults to 0.
Number of Workers for CPU Training¶
Specify the number of workers used in CPU mode for training:
0: Use socket count (Default)
-1: Use all physical cores >= 1 that count
#GPUs/Experiment¶
Specify the number of GPUs to user per experiment. A value of -1 (default) specifies to use all available GPUs. Must be at least as large as the number of GPUs to use per model (or -1).
Num Cores/GPU¶
Specify the number of CPU cores per GPU. In order to have a sufficient number of cores per GPU, this setting limits the number of GPUs used. This value defaults to 2. To disable this setting, set this value to -1.
#GPUs/Model¶
Specify the number of GPUs to user per model, with -1 meaning all GPUs per model. In all cases, XGBoost tree and linear models use the number of GPUs specified per model, while LightGBM and Tensorflow revert to using 1 GPU/model and run multiple models on multiple GPUs. This value defaults to 1.
Note: FTRL does not use GPUs. Rulefit uses GPUs for parts involving obtaining the tree using LightGBM.
Num. of GPUs for Isolated Prediction/Transform¶
Specify the number of GPUs to use for predict for models and transform for transformers when running outside of fit/fit_transform. If predict or transform are called in the same process as fit/fit_transform, the number of GPUs will match. New processes will use this count for applicable models and transformers. Note that enabling tensorflow_nlp_have_gpus_in_production will override this setting for relevant TensorFlow NLP transformers. This value defaults to 0.
Max Number of Threads to Use for datatable and OpenBLAS for Munging and Model Training¶
Specify the maximum number of threads to use for datatable and OpenBLAS during data munging (applied on a per process basis):
0 = Use all threads
-1 = Automatically select number of threads (Default)
Max Number of Threads to Use for datatable Read and Write of Files¶
Specify the maximum number of threads to use for datatable during data reading and writing (applied on a per process basis):
0 = Use all threads
-1 = Automatically select number of threads (Default)
Max Number of Threads to Use for datatable Stats and OpenBLAS¶
Specify the maximum number of threads to use for datatable stats and OpenBLAS (applied on a per process basis):
0 = Use all threads
-1 = Automatically select number of threads (Default)
GPU Starting ID¶
Specify Which gpu_id to start with.
If using CUDA_VISIBLE_DEVICES=… to control GPUs (preferred method), gpu_id=0 is the
first in that restricted list of devices. For example, if CUDA_VISIBLE_DEVICES='4,5' then gpu_id_start=0 will refer to device #4.
From expert mode, to run 2 experiments, each on a distinct GPU out of 2 GPUs, then:
Experiment#1: num_gpus_per_model=1, num_gpus_per_experiment=1, gpu_id_start=0
Experiment#2: num_gpus_per_model=1, num_gpus_per_experiment=1, gpu_id_start=1
From expert mode, to run 2 experiments, each on a distinct GPU out of 8 GPUs, then:
Experiment#1: num_gpus_per_model=1, num_gpus_per_experiment=4, gpu_id_start=0
Experiment#2: num_gpus_per_model=1, num_gpus_per_experiment=4, gpu_id_start=4
To run on all 4 GPUs/model, then
Experiment#1: num_gpus_per_model=4, num_gpus_per_experiment=4, gpu_id_start=0
Experiment#2: num_gpus_per_model=4, num_gpus_per_experiment=4, gpu_id_start=4
If num_gpus_per_model!=1, global GPU locking is disabled. This is because the underlying algorithms do not support arbitrary gpu ids, only sequential ids, so be sure to set this value correctly to avoid overlap across all experiments by all users.
More information is available at: https://github.com/NVIDIA/nvidia-docker/wiki/nvidia-docker#gpu-isolation Note that gpu selection does not wrap, so gpu_id_start + num_gpus_per_model must be less than the number of visibile GPUs.
Enable Detailed Traces¶
Specify whether to enable detailed tracing in Driverless AI trace when running an experiment. This is disabled by default.
Enable Debug Log Level¶
If enabled, the log files will also include debug logs. This is disabled by default.
Enable Logging of System Information for Each Experiment¶
Specify whether to include system information such as CPU, GPU, and disk space at the start of each experiment log. Note that this information is already included in system logs. This is enabled by default.