Google BigQuery Setup
Driverless AI lets you explore Google BigQuery (GBQ) data sources from within the Driverless AI application. This page provides instructions for configuring Driverless AI to work with GBQ.
참고
The setup described on this page requires you to enable authentication. Enabling the GCS and/or GBQ connectors causes those file systems to be displayed in the UI, but the GCS and GBQ connectors cannot be used without first enabling authentication.
Before enabling the GBQ data connector with authentication, the following steps must be performed:
In the Google Cloud Platform (GCP), create a private key for your service account. To create a private key, click Service Accounts > Keys, and then click the Add Key button. When the Create private key dialog appears, select JSON as the key type. To finish creating the JSON private key and download it to your local file system, click Create.
Mount the downloaded JSON file to the Docker instance.
Specify the path to the downloaded and mounted
auth-key.jsonfile with thegcs_path_to_service_account_jsonconfig option.
참고
For Docker 19.03 and later, use the --gpus all flag with docker run to enable GPU support. The older nvidia-docker wrapper is deprecated and no longer recommended. Ensure that the NVIDIA Container Toolkit is installed. To check your Docker version, run docker version.
The following sections describe how to enable the GBQ data connector:
Enabling GBQ with the config.toml file
This example enables the GBQ data connector with authentication by passing the JSON authentication file. This assumes that the JSON file contains Google BigQuery authentications.
docker run --gpus all \
--pid=host \
--rm \
--shm-size=2g --cap-add=SYS_NICE --ulimit nofile=131071:131071 --ulimit nproc=16384:16384 \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,gbq" \
-e DRIVERLESS_AI_GCS_PATH_TO_SERVICE_ACCOUNT_JSON="/service_account_json.json" \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-ubi8-x86_64:2.4.4-cuda11.8.0.xx
This example shows how to configure the GBQ data connector options in the config.toml file, and then specify that file when starting Driverless AI in Docker.
Configure the Driverless AI config.toml file. Set the following configuration options:
enabled_file_systems = "file, upload, gbq"
gcs_path_to_service_account_json = "/service_account_json.json"
Mount the config.toml file into the Docker container.
docker run --gpus all \ --pid=host \ --rm \ --shm-size=2g --cap-add=SYS_NICE --ulimit nofile=131071:131071 --ulimit nproc=16384:16384 \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-ubi8-x86_64:2.4.4-cuda11.8.0.xx
This example enables the GBQ data connector with authentication by passing the JSON authentication file. This assumes that the JSON file contains Google BigQuery authentications.
Export the Driverless AI config.toml file or add it to ~/.bashrc. For example:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
Specify the following configuration options in the config.toml file.
# File System Support # file : local file system/server file system # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below enabled_file_systems = "file, gbq" # GCS Connector credentials # example (suggested) -- "/licenses/my_service_account_json.json" gcs_path_to_service_account_json = "/service_account_json.json"
Save the changes when you are done, then stop/restart Driverless AI.
Enabling GBQ by setting an environment variable
The GBQ data connector can be configured by setting the GOOGLE_APPLICATION_CREDENTIALS environment variable as follows:
export GOOGLE_APPLICATION_CREDENTIALS="SERVICE_ACCOUNT_KEY_PATH"
In the preceding example, replace SERVICE_ACCOUNT_KEY_PATH with the path of the JSON file that contains your service account key. The following is an example of how this might look:
export GOOGLE_APPLICATION_CREDENTIALS="/etc/dai/service-account.json"
To see how to set this environment variable with Docker, refer to the following example:
docker run --gpus all \
--pid=host \
--rm \
--shm-size=2g --cap-add=SYS_NICE --ulimit nofile=131071:131071 --ulimit nproc=16384:16384 \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,gbq" \
-e GOOGLE_APPLICATION_CREDENTIALS="/service_account.json" \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-ubi8-x86_64:2.4.4-cuda11.8.0.xx
For more information on setting the GOOGLE_APPLICATION_CREDENTIALS environment variable, refer to the official documentation on setting the environment variable.
Enabling GBQ by enabling Workload Identity for your GKE cluster
The GBQ data connector can be configured by enabling Workload Identity for your Google Kubernetes Engine (GKE) cluster. For information on how to enable Workload Identity, refer to the official documentation on enabling Workload Identity on a GKE cluster.
참고
If Workload Identity is enabled, then the GOOGLE_APPLICATION_CREDENTIALS environment variable does not need to be set.
Adding Datasets Using GBQ
After Google BigQuery is enabled, you can add datasets by selecting Google Big Query from the Add Dataset (or Drag and Drop) drop-down menu.
참고
To run a BigQuery query with Driverless AI, the associated service account must have the following Identity and Access Management (IAM) permissions:
bigquery.jobs.create
bigquery.tables.create
bigquery.tables.delete
bigquery.tables.export
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
bigquery.tables.update
bigquery.tables.updateData
storage.buckets.get
storage.objects.create
storage.objects.delete
storage.objects.list
storage.objects.update
For a list of all Identity and Access Management permissions, refer to the IAM permissions reference from the official Google Cloud documentation.

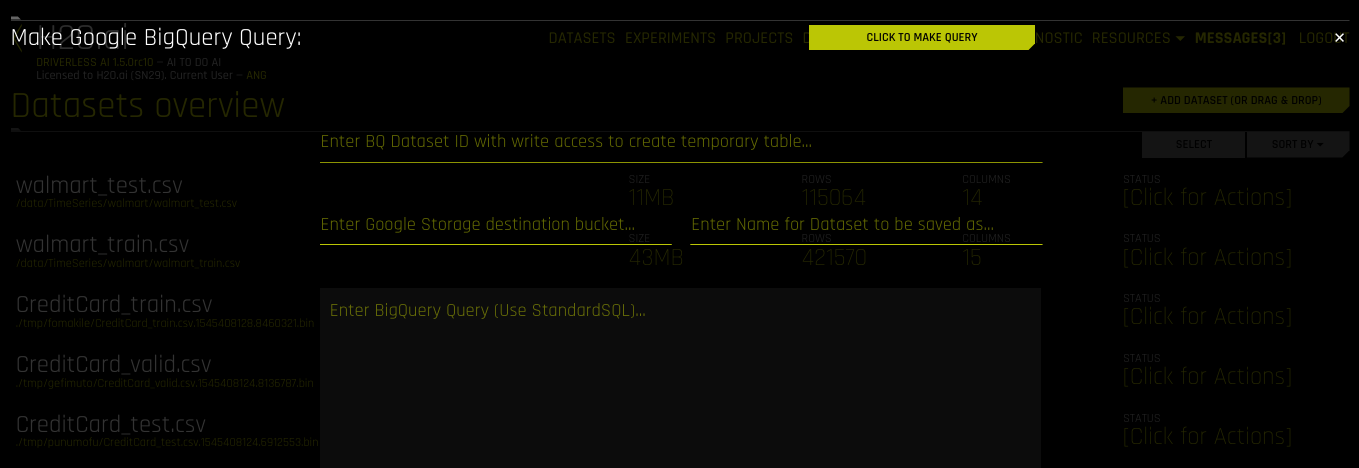
Specify the following information to add your dataset:
Enter BQ Dataset ID with write access to create temporary table: Enter a dataset ID in Google BigQuery that this user has read/write access to. BigQuery uses this dataset as the location for the new table generated by the query.
Note: Driverless AI’s connection to GBQ will inherit the top-level directory from the service JSON file. So if a dataset named 《my-dataset》 is in a top-level directory named 《dai-gbq》, then the value for the dataset ID input field would be 《my-dataset》 and not 《dai-gbq:my-dataset》.
Enter Google Storage destination bucket: Specify the name of Google Cloud Storage destination bucket. Note that the user must have write access to this bucket.
Enter Name for Dataset to be saved as: Specify a name for the dataset, for example,
my_file.Enter BigQuery Query (Use StandardSQL): Enter a StandardSQL query that you want BigQuery to execute. For example:
SELECT * FROM <my_dataset>.<my_table>.(Optional) Specify a project to use with the GBQ connector. This is equivalent to providing
--projectwhen using a command-line interface.When you are finished, select the Click to Make Query button to add the dataset.