POJO Quick Start¶
This section describes how to build and implement a POJO to use predictive scoring. Java developers should refer to the Javadoc for more information, including packages.
Notes:
POJOs are not supported for source files larger than 1G. For more information, refer to the POJO FAQ section below.
POJOs are not supported for GLRM, Stacked Ensembles, or Word2Vec models.
POJO predict cannot parse columns enclosed in double quotes (for example, “”2””).
What is a POJO?¶
H2O allows you to convert the models you have built to a Plain Old Java Object (POJO), which can then be easily deployed within your Java app and scheduled to run on a specified dataset.
POJOs allow users to build a model using H2O and then deploy the model to score in real-time, using the POJO model or a REST API call to a scoring server.
The only compilation and runtime dependency for a generated model is the h2o-genmodel.jar file produced as the build output of these packages. This file is a library that supports scoring, and it contains the base classes from which the POJO is derived from. (You can see “extends GenModel” in a pojo class. The GenModel class is part of this library.) The h2o-genmodel.jar file is required when POJO models are deployed to production.
Building a POJO¶
The example code below shows how to start H2O Flow, compile and run an example Flow, and then compile and run the POJO. This example uses GBM, but any supported algorithm can be used to build a model and run the POJO.
Start H2O in terminal window #1:
$ java -jar h2o.jarBuild a model using your web browser:
Go to http://localhost:54321
Click View Example Flows near the right edge of the screen. Here is a screenshot of what to look for:
Click
GBM_Airlines_Classification.flowIf a confirmation prompt appears asking you to “Load Notebook”, click it.
From the “Flow” menu choose the “Run all cells” option
Scroll down and find the “Model” cell in the notebook. Click on the Download POJO button as shown in the following screenshot:
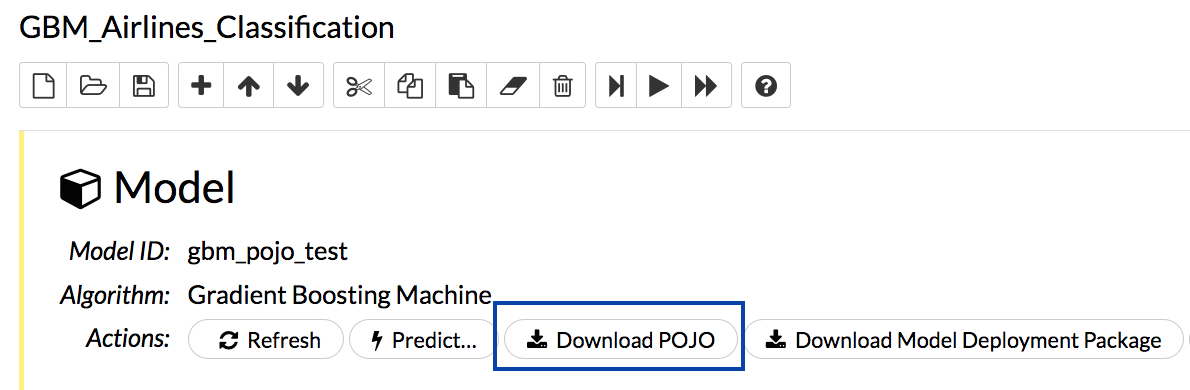
Note: The instructions below assume that the POJO model was downloaded to the “Downloads” folder.
Download model pieces in a new terminal window. Note that H2O must still be running in terminal window #1:
$ mkdir experiment $ cd experiment $ mv ~/Downloads/gbm_pojo_test.java . $ curl http://localhost:54321/3/h2o-genmodel.jar > h2o-genmodel.jar
Create your main program in terminal window #2 by creating a new file called main.java (
vim main.java) with the following contents:import java.io.*; import hex.genmodel.easy.RowData; import hex.genmodel.easy.EasyPredictModelWrapper; import hex.genmodel.easy.prediction.*; public class main { private static String modelClassName = "gbm_pojo_test"; public static void main(String[] args) throws Exception { hex.genmodel.GenModel rawModel; rawModel = (hex.genmodel.GenModel) Class.forName(modelClassName).newInstance(); EasyPredictModelWrapper model = new EasyPredictModelWrapper(rawModel); RowData row = new RowData(); row.put("Year", "1987"); row.put("Month", "10"); row.put("DayofMonth", "14"); row.put("DayOfWeek", "3"); row.put("CRSDepTime", "730"); row.put("UniqueCarrier", "PS"); row.put("Origin", "SAN"); row.put("Dest", "SFO"); BinomialModelPrediction p = model.predictBinomial(row); System.out.println("Label (aka prediction) is flight departure delayed: " + p.label); System.out.print("Class probabilities: "); for (int i = 0; i < p.classProbabilities.length; i++) { if (i > 0) { System.out.print(","); } System.out.print(p.classProbabilities[i]); } System.out.println(""); } }
Compile the POJO in terminal window 2:
$ javac -cp h2o-genmodel.jar -J-Xmx2g -J-XX:MaxPermSize=128m gbm_pojo_test.java main.java
Run the POJO in terminal window 2.
For Linux and OS X users:
$ java -cp .:h2o-genmodel.jar mainFor Windows users:
$ java -cp .;h2o-genmodel.jar mainThe following output displays:
Label (aka prediction) is flight departure delayed: YES Class probabilities: 0.4319916897116479,0.5680083102883521
Extracting Models from H2O¶
Generated models can be extracted from H2O in the following ways:
From the H2O Flow Web UI¶
When viewing a model, click the Download POJO button at the top of the model cell, as shown in the example in the Quick start section. You can also preview the POJO inside Flow, but it will only show the first thousand lines or so in the web browser, truncating large models.
From R or Python¶
The following code snippets show an example of H2O building a model and downloading its corresponding POJO from an R script and a Python script.
library(h2o)
h2o.init()
path <- system.file("extdata", "prostate.csv", package = "h2o")
h2o_df <- h2o.importFile(path)
h2o_df$CAPSULE <- as.factor(h2o_df$CAPSULE)
model <- h2o.glm(y = "CAPSULE",
x = c("AGE", "RACE", "PSA", "GLEASON"),
training_frame = h2o_df,
family = "binomial")
h2o.download_pojo(model)
import h2o
h2o.init()
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
path = "http://s3.amazonaws.com/h2o-public-test-data/smalldata/prostate/prostate.csv.zip"
h2o_df = h2o.import_file(path)
h2o_df['CAPSULE'] = h2o_df['CAPSULE'].asfactor()
model = H2OGeneralizedLinearEstimator(family = "binomial")
model.train(y = "CAPSULE",
x = ["AGE", "RACE", "PSA", "GLEASON"],
training_frame = h2o_df)
h2o.download_pojo(model)
Use Cases¶
The following use cases are demonstrated with code examples:
Reading new data from a CSV file and predicting on it: The PredictCsv class is used by the H2O test harness to make predictions on new data points.
Getting a new observation from a JSON request and returning a prediction
Calling a user-defined function directly from hive: See the H2O-3 training github repository.
FAQ¶
Are POJOs thread safe?
Yes, all of H2O-3 POJOs are thread safe.
How do I score new cases in real-time in a production environment?
If you’re using the UI, click the Preview POJO button for your model. This produces a Java class with methods that you can reference and use in your production app.
What kind of technology would I need to use?
Anything that runs in a JVM. The POJO is a standalone Java class with no dependencies on H2O.
How should I format my data before calling the POJO?
Here are our requirements (assuming you are using the “easy” Prediction API for the POJO as described in the Javadoc).
Input columns must only contain categorical levels that were seen during training
Any additional input columns not used for training are ignored
If no input column is specified, it will be treated as an
NASome models do not handle NAs well (e.g., GLM)
Any transformations applied to data before model training must also be applied before calling the POJO predict method
How do I run a POJO on a Spark Cluster?
The POJO provides just the math logic to do predictions, so you won’t find any Spark (or even H2O) specific code there. If you want to use the POJO to make predictions on a dataset in Spark, create a map to call the POJO for each row and save the result to a new column, row-by-row.
How do I communicate with a remote cluster using the REST API?
You can dl the POJO using the REST API but when calling the POJO predict function, it’s in the same JVM, not across a REST API.
Is it possible to make predictions using my H2O cluster with the REST API?
Yes, but this way of making predictions is separate from the POJO. For more information about in-H2O predictions (as opposed to POJO predictions), see the documentation for the H2O REST API endpoint /3/Predictions.
Why did I receive the following error when trying to compile the POJO?
The following error is generated when the source file is larger than 1G.
Michals-MBP:b michal$ javac -cp h2o-genmodel.jar -J-Xmx2g -J-XX:MaxPermSize=128m drf_b9b9d3be_cf5a_464a_b518_90701549c12a.java An exception has occurred in the compiler (1.7.0_60). Please file a bug at the Java Developer Connection (http://java.sun.com/webapps/bugreport) after checking the Bug Parade for duplicates. Include your program and the following diagnostic in your report. Thank you. java.lang.IllegalArgumentException at java.nio.ByteBuffer.allocate(ByteBuffer.java:330) at com.sun.tools.javac.util.BaseFileManager$ByteBufferCache.get(BaseFileManager.java:308) at com.sun.tools.javac.util.BaseFileManager.makeByteBuffer(BaseFileManager.java:280) at com.sun.tools.javac.file.RegularFileObject.getCharContent(RegularFileObject.java:112) at com.sun.tools.javac.file.RegularFileObject.getCharContent(RegularFileObject.java:52) at com.sun.tools.javac.main.JavaCompiler.readSource(JavaCompiler.java:571) at com.sun.tools.javac.main.JavaCompiler.parse(JavaCompiler.java:632) at com.sun.tools.javac.main.JavaCompiler.parseFiles(JavaCompiler.java:909) at com.sun.tools.javac.main.JavaCompiler.compile(JavaCompiler.java:824) at com.sun.tools.javac.main.Main.compile(Main.java:439) at com.sun.tools.javac.main.Main.compile(Main.java:353) at com.sun.tools.javac.main.Main.compile(Main.java:342) at com.sun.tools.javac.main.Main.compile(Main.java:333) at com.sun.tools.javac.Main.compile(Main.java:76) at com.sun.tools.javac.Main.main(Main.java:61)