Genetic Algorithm in Driverless AI¶
Driverless AI aims to determine the best pipeline for a dataset. This involves data transformation, feature engineering, model hyperparameter tuning, scoring and ensembling.
The genetic algorithm process is a trial-and-error selection process, but it is reproducible. In Driverless AI, genetic algorithm is performed during the Feature Evolution stage of an experiment. Feature Evolution is a competition between slowly mutating parameters to find best individuals. The Feature Evolution is not completely random and is informed from the variable importance interactions tables of the modeling algorithms. Driverless AI Brain caches information about the set of best genes, interactions and parameters in the population and also information from previous experiments (if enabled), can be used during genetic algorithm mutations.
Driverless AI also integrates Optuna, that employs Bayesian optimization technique for model hyperparameter search. It can be enabled for model hyperparameter tuning in combination with genetic algorithm for feature engineering. Custom code can also be written to toggle inbuilt mutation strategy. For details see additional information section.
During model building and feature tuning processes, overfitting is prevented by doing bootstrapping and cross validation, while underfitting is prevented by balancing exploitation vs exploration in genetic algorithm.
Understanding Genetic Algorithm and its Driverless AI equivalent.
The Full Picture : The end to end pipeline in Driverless AI.
Reading the logs : Workflow as seen in the Experiment logs.
Understanding Genetic Algorithm¶
Genetic Algorithm is a search heuristic inspired by the process of natural selection where the fittest individuals are selected to produce offspring for the next generation.
Some Driverless AI equivalent definitions to consider before the deep dive:
A
genestores information about type of and parameters for a feature transformation. It is conceptually like the real gene where information is present to make say a protein.A
transformeris the actual code that applies the gene.An
individualconsists of a genome that includes a set of genes, i.e. information about which transformations and with what parameters to perform. It also includes model hyperparameters and some additional information like the target transformations applied etc.Individuals create a
populationthat goes through a randomly chosen pair-wise tournament process to decide the winners.
Fitness scorefor an individual is model evaluation or scores based on the scoring metric.
Below are the steps involved in a Genetic Algorithm and their Driverless AI equivalent:
Initialization
Consider all the probable solutions to the given problem. This creates the population. The most popular technique for initialization is the use of random binary strings.
Driverless AI : The individuals from the Tuning Phase are fed in as the random probable solutions for Feature evolution via genetic algorithm.
Fitness Assignment
Assign a fitness score to every individual, which further determines the probability of being chosen for reproduction. The higher the fitness score, the higher the chances of being chosen for reproduction.
Driverless AI : Fitness score for an individual is model evaluation based on the scoring metric.
Selection
Individuals are selected for the reproduction of offspring. The selected individuals are then arranged in pairs of two to enhance reproduction. These individuals pass on their genes to the next generation. The genetic algorithm uses the fitness proportionate selection technique to ensure that useful solutions are used for recombination.
Driverless AI : A tournament is performed within the population to find the best subset (half) of the population.
Reproduction : crossover mutation
This phase involves the creation of a child population. The algorithm employs variation operators that are applied to the parent population. The two main operators in this phase include crossover and mutation.
mutation : This operator adds new genetic information to the new child population. This is achieved by flipping some bits in the chromosome. Mutation solves the problem of local minimum and enhances diversification.
crossover : This operator swaps the genetic information of two parents to reproduce an offspring. It is performed on parent pairs that are selected randomly to generate a child population of equal size as the parent population.
Driverless AI : Winning sub population’s genes, features and model hyperparameters are mutated into new offspring (asexual reproduction). Mutation involves adding, perturbing, or pruning genes.
The strategy for adding genes is based on balancing exploitation and exploration of importance of original variables. Genes are added that explore additional transformations for original variables with high importance.
The best genes from prior winners become part of the pool of great genes that are used and can be shared amongst the offspring.
Specific output features can be pruned. Features are pruned when variable importance is below a certain threshold (based upon interpretability settings). Genes are pruned based on the Information Gain Variable Importance for most models (i.e model specific variable importance). For some like CUML RF, it is based upon Shapley Permutation Importance.
Replacement
Generational replacement takes place in this phase, which is a replacement of the old population with the new child population. The new population consists of higher fitness scores than the old population,
Driverless AI : Mutate winning sub-population’s Genes (add, prune and perturb), Features, Model hyper parameters to fill-up the population back to pre-tournament size.
Termination
After replacement has been done, a stopping criterion is used to provide the basis for termination. The algorithm will terminate after the threshold fitness solution has been attained. It will identify this solution as the best solution in the population.
Driverless AI: Score the individuals and either terminate the evolution if stopping criteria is reached or continue the selection process.
The Full Picture¶
Here we describe in details the working of the different stages that Driverless performs in sequence during an experiment to output the best pipeline for the dataset-
Convert Accuracy, Time and Interpretabilty knob settings to number of iterations and models to be built.
Do Target Tuning: Find the best representation of the target variable for the problem at hand. This is achieved by building (LightGBM if available) models with simple allowed feature transformations and model parameters (chosen from the internal recipe pool) and choosing the target transformation with highest score. The
target_transform_tuning_leaderboard_simple.jsonfile in summary zip or Experiment GUI lists the built models with their scores and parameters.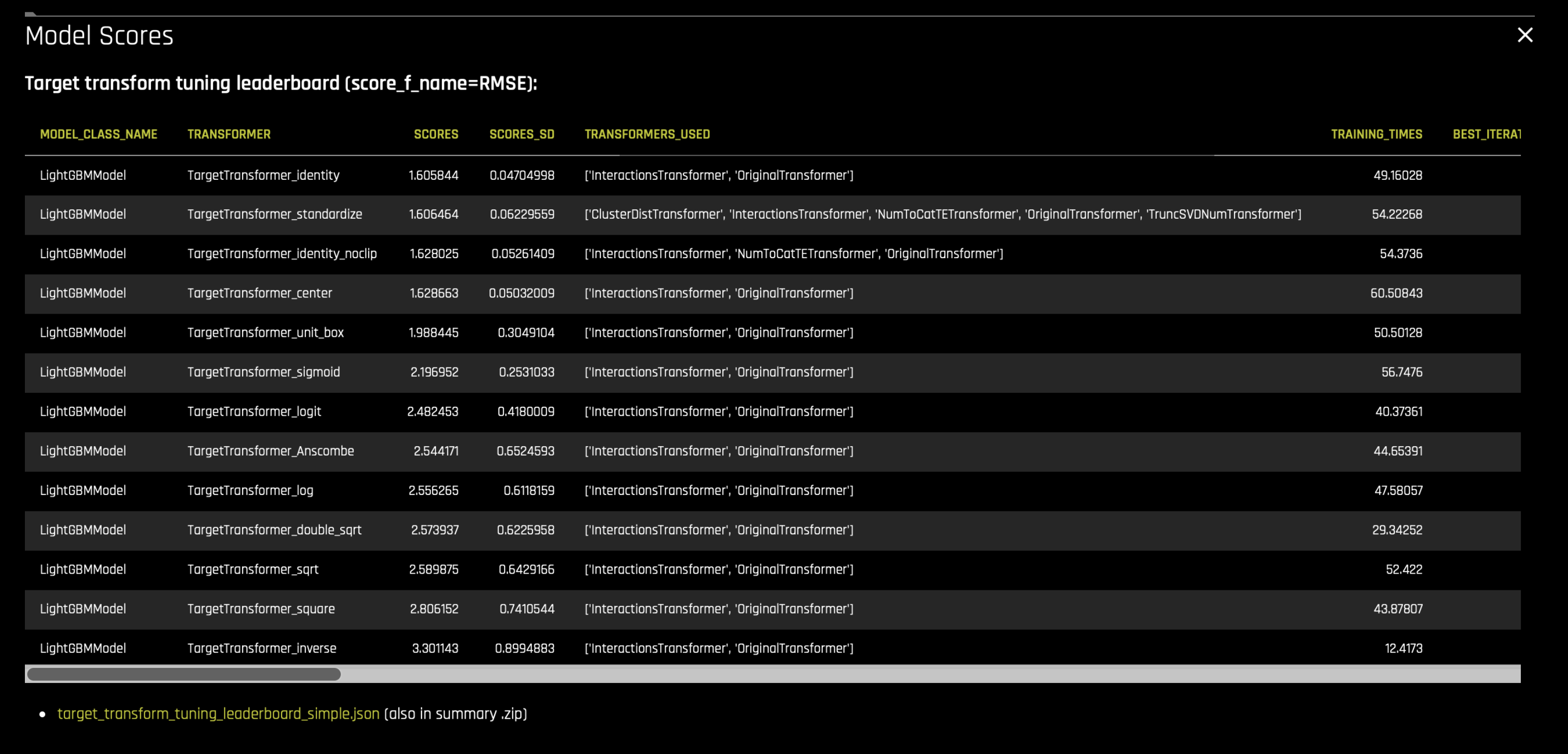
Data Leakage and Shift Detection:
Leakage Detection: To detect data leakage, Driverless AI runs a model (LightGBM if available) to get the variable importance table (that determines the predictive power of each feature on the target variable). Then, a simple model is built on each feature with significant variable importance. The models with high AUC (for classification) or R2 score (regression) are reported to the user as potential leak features.
Shift Detection: To detect shift in distribution between the training, validation or testing datasets, Driverless AI trains a binomial model to predict which dataset a row belongs to. Say, if the model built using only a specific feature as predictor, is able to separate the training and testing data with a high accuracy say an AUC of 0.9, this indicates that there is a drift in the distribution of that feature in the training and testing data. Shifted features should either be dropped. Or more meaningful aggregate features be created by using them as labels/bins.
These features are reported to the user as a notification and dropped if a threshold is set.
Model and Feature Tuning Phase: Tuning is random selection of parameters to find best individuals.
Driverless creates a diverse set of individuals. First, it goes through and creates a “SEQUENCE” of models (based on allowed algorithms), adding them with simple feature transformations and model parameters. These allowed algorithms and feature transformations are displayed in the preview of the experiment. The DEFAULT includes simple genes like original numeric, date, tfidf or bert embeddings for text data, Target encodings, Frequency encodings, Weight of evidence encodings, clustering, interactions, etc. These default features are simple and support MOJO creation. These model parameters lists and feature transformations are internally chosen by Driverless AI expert Data Scientists recipes that are suitable for the dataset in hand and allowed by the experiment settings.
Then, if more individuals are needed in the population, “RANDOM” models are added. These have same model types (algorithms) as in SEQUENCE but with mutated parameters calls to the model to get random hyper parameters and (default + extra) random features.
A “GLM ONE HOT ENCODED” model is evaluated and if seem to be performing well on the dataset, is added as an individual.
A reference individual “CONSTANT MODEL” is added to the mix, so that we know what best constant predictions (predict the same thing whatever the input data) would give for a score.
This is how a diverse population of individuals is created.
All individuals are scored :
Batches (given hardware) of individuals are scored for every tuning iteration
At higher accuracy, the original feature set is re-created, each batch passing feature importance to next batch so it can exploit the importance in order to create better features.
Every scored individual has gone through feature transformations, training the model, prediction making, and metric scoring.
Then a tournament is performed amongst the individuals to get the best individuals to be passed on to the evolution phase.
An “EXTRA_FS” model is added in case “FS” strategy (feature selection strategy) is chosen ( for high interpretability settings) and it replaces one of the above non-reference individuals. This special individual has features that are pre-pruned based on the permutation importance of the dataset.
The Tuning stage leaderboard of an experiment lists all the wining individuals (i.e models that scored highest during the tournament). The summary zip artifact includes it as the
tuning_leaderboard_simple.jsonor txt file.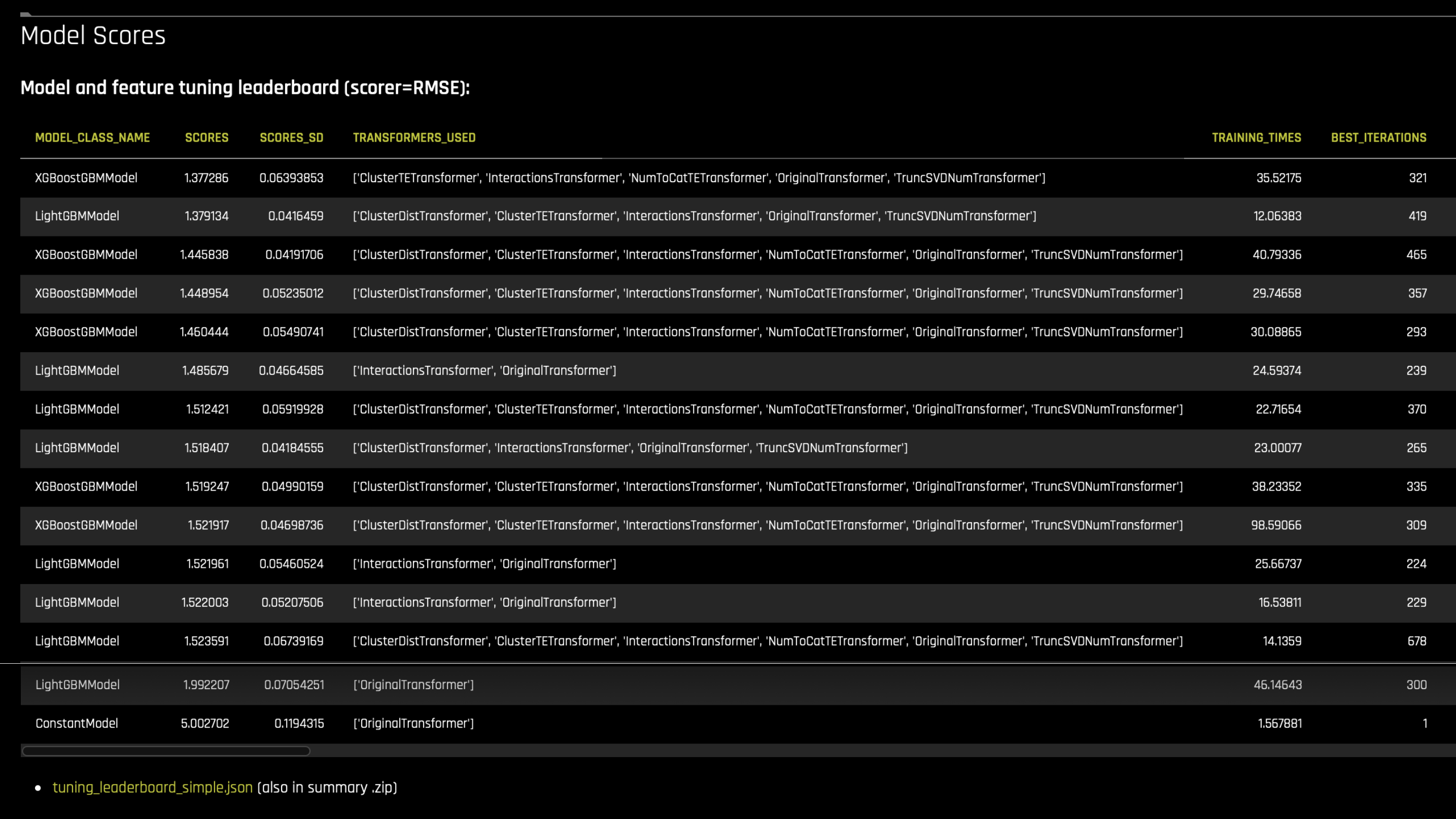
Feature Evolution Phase: Evolution is competition between slowly mutating parameters to find best individuals. During evolution phase, we start off with the best individuals (highest score) from the tuning phase. The tuning phase may have created more or less individuals than required in the population. So first step is to either prune or add new individuals to create the desired population size. The
evolution_begin_leaderboard_simple.jsonfile lists these individuals (the unscored are the new added individuals to bring the population to the right size).Every iteration of the experiment, each individual creates a new model based on its genes.
Population of individuals is trained on the training data, with early stopping if available.
Population is scored for given metric, with bootstrapping if chosen (default).
Tournament is performed amongst the individuals based on the selected strategy, to decide winning subset of population
Mutate winning sub-population’s Genes, Features, Model to fill-up the population back to pre-tournament size (asexual reproduction). In the genetic algorithm, Mutation involves adding, pruning, or perturbing genes. Specific output features can also be pruned. The strategy for adding genes is based on balancing exploitation and exploration of importance of original variables. Genes are added that explore additional transformations for original variables with high importance. Genes are pruned based on the Information Gain Variable Importance for most models, for some like CUML RF, it is based upon Shapley Permutation Importance. Features are pruned when variable importance is below a certain threshold (based upon interpretability settings). See also Mutation strategies.
Back to A…
The final evolution leaderboard population is listed in the
evolution_end_leaderboard_simple.jsonfile.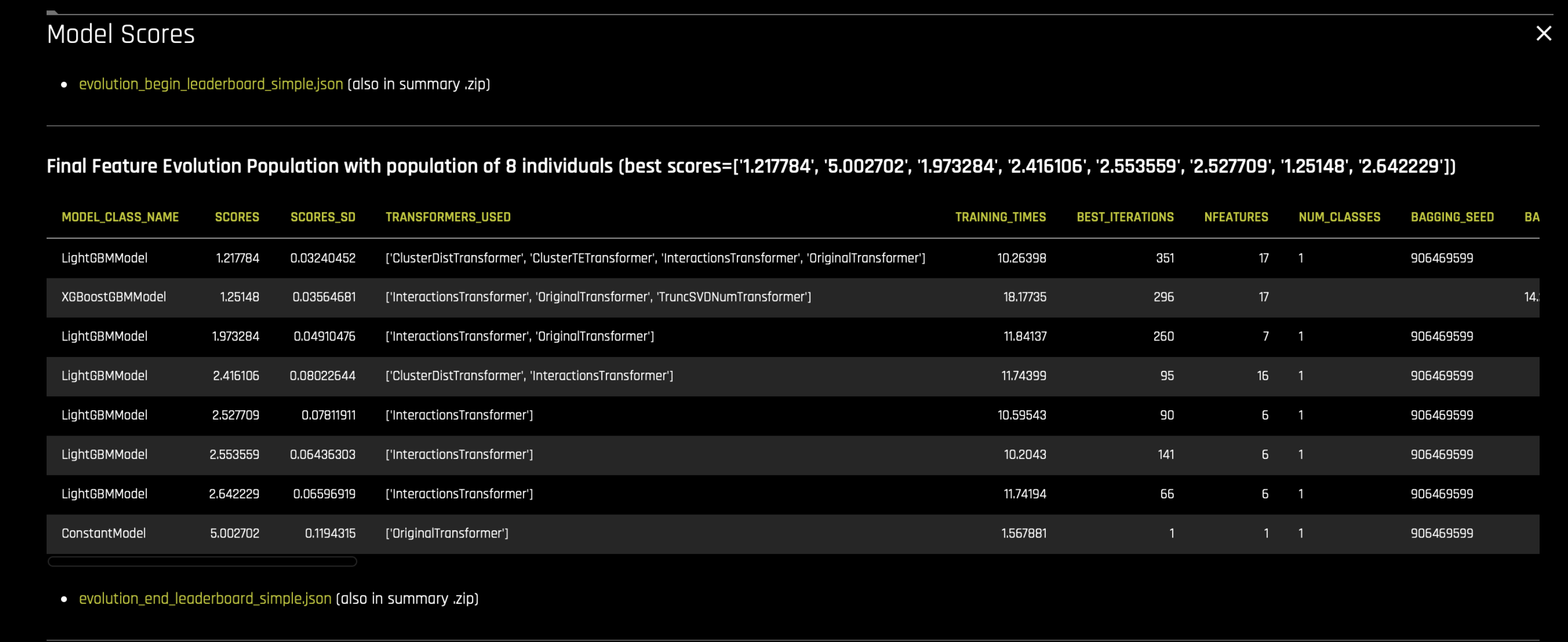
Select the final models from the evolution end leaderboard for ensembling. These are listed in the
final_leaderboard_simple.jsonfile in the summary zip.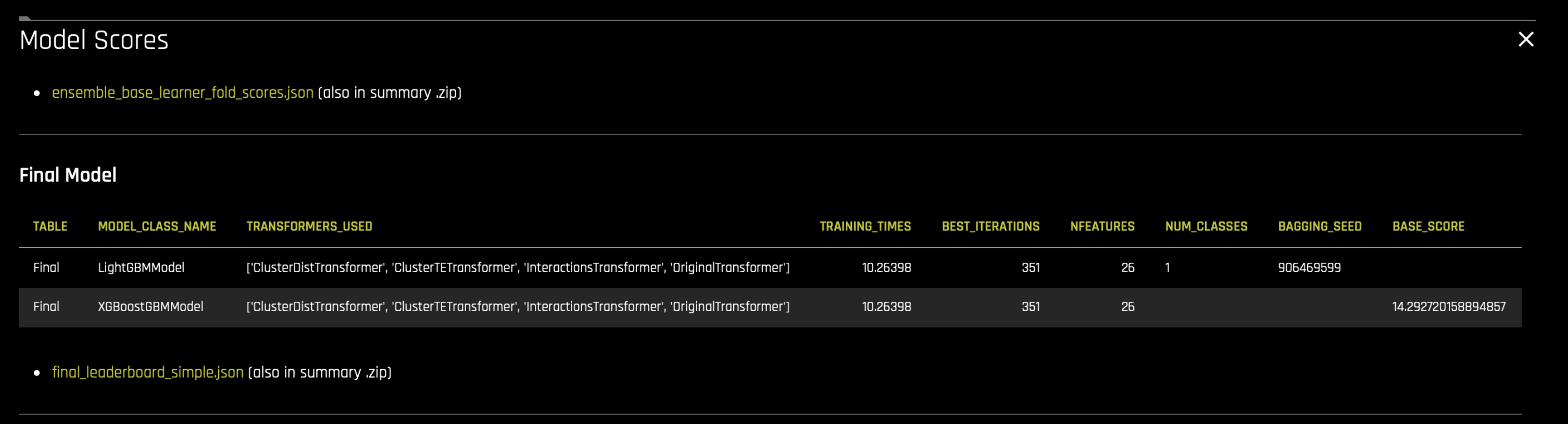
The
all_leaderboard_simple.jsonfile lists the complete journey of all the leaderboard models their scores and parameters and the stages that they were part of.
Ensembling and Final Scoring Pipeline creation: Ensemble the final models and build Final Pipeline for production with a MOJO and/or Python scoring pipelines.
Driverless AI supports both Stacking and Blending ensembling techniques. These can be enabled using ensemble_meta_learner parameter when launching the experiment. A linear blender with a hill climbing algorithm is used to decide the blending fractions or weights for the models in the ensemble. And Extra trees algorithm is used to do stacking. The weights and other parameters used for ensembling and the scores of the final model are listed in
ensemble_model_description.jsonandensemble_scores.jsonfiles in the summary zip archive of the experiment.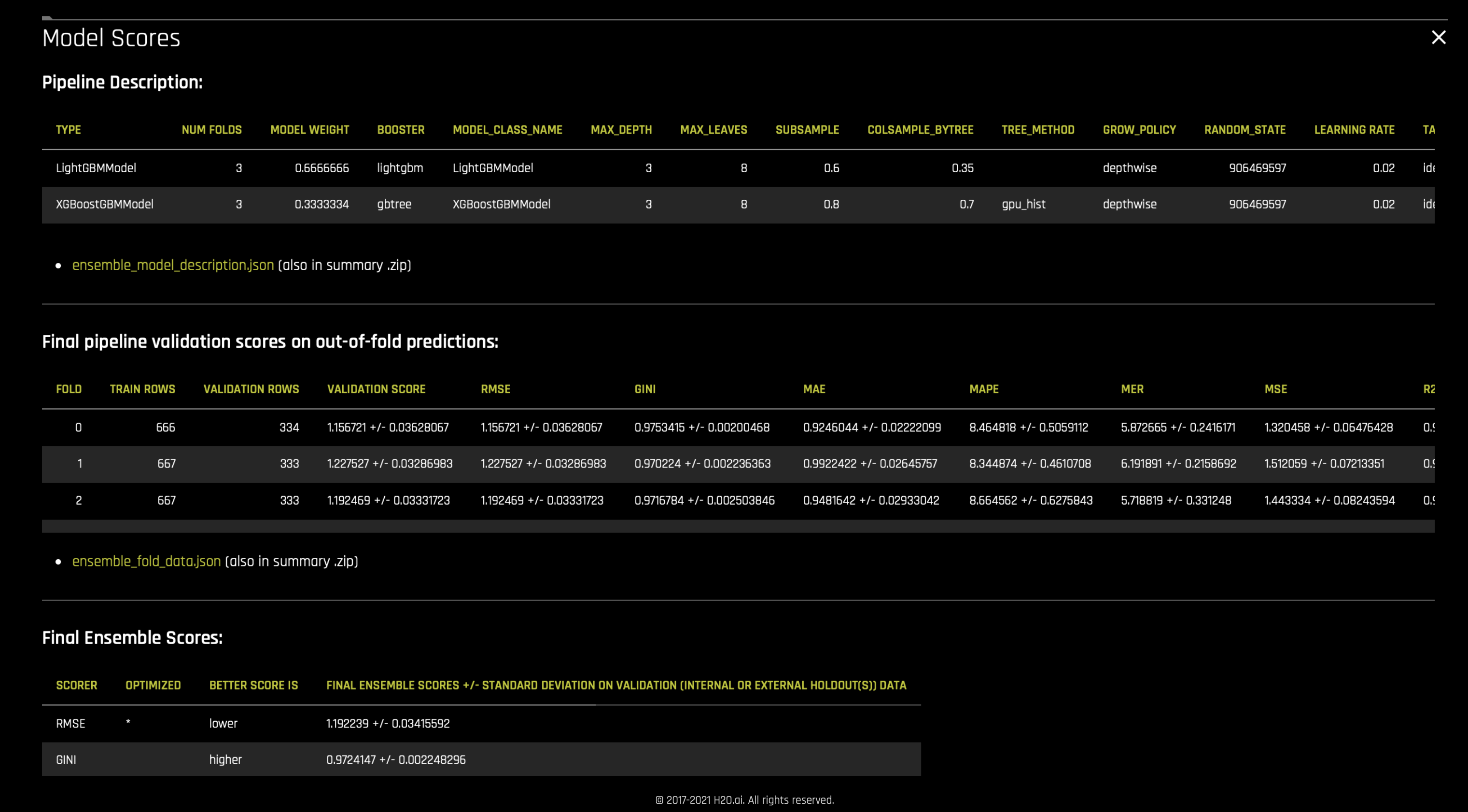
Notes:
Feature and Model Tuning leaderboard table lists a parameter called feature cost of a model. Feature cost is not equal to the number of features used in the model but is based on their complexity (or interpretability) i.e. transformation used/interactions applied/time taken. For example a low cost model may have greater number of more interpretable features than a high cost model (i.e. cost number != number of feature used). This parameter is used in the workflow during genetic algorithm to decide if need to reduce feature count given interpretability dial settings of the experiment.
Certain individuals in the Evolution Begin leaderboard table are unscored. This can happen if:
They violated some constraint on feature counts imposed for given choice of interpretability settings and so were changed, and the score no longer applies.
They were added at end to fill-up the needed total number of individuals in the population and hence have not been scored yet.
Also see additional details.
Reading the Logs¶
The Experiment preview gives an estimate of the number of iterations done and the total number of models(including cross validation models) that are built during the various stages of the experiment. For example (from logs) -
Click here to download and view the sample log file used in this example.
INFO | Number of individuals: 8
INFO | Estimated target transform tuning iterations: 2
INFO | Estimated model and feature parameter tuning iterations: 4
INFO | Estimated total (tuning + feature evolution) number of iterations: 16
INFO | Estimated total (backend + tuning + feature evolution + final) number of models to train: 598
INFO | Backend tuning: 0 model(s)
INFO | Target transform tuning: 18 model(s)
INFO | Model and feature tuning: 48 model(s)
INFO | Feature pre-pruning: 0 model(s)
INFO | Feature evolution: 528 model(s)
INFO | Final pipeline: 3 model(s)
INFO | ACCURACY [7/10]:
INFO | - Training data size: *1,000 rows, 11 cols*
INFO | - Feature evolution: *LightGBM*, *3-fold CV**, 2 reps*
INFO | - Final pipeline: *LightGBM, averaged across 3-fold CV splits*
INFO |
INFO | TIME [2/10]:
INFO | - Feature evolution: *8 individuals*, up to *10 iterations*
INFO | - Early stopping: After *5* iterations of no improvement
INFO |
INFO | INTERPRETABILITY [8/10]:
INFO | - Feature pre-pruning strategy: Permutation Importance FS
INFO | - Monotonicity constraints: enabled
INFO | - Feature engineering search space: [Interactions, Original]
INFO |
INFO | LightGBM models to train:
INFO | - Target transform tuning: *18*
INFO | - Model and feature tuning: *48*
INFO | - Feature evolution: *528*
INFO | - Final pipeline: *3*
This experiment creates only LightGBM models. The listed model count estimate considers each nfold model as a count.
As this is a regression problem, target tuning is performed and 18 models are created to decide the best target transformation for the dataset. This create 3 models with 3 fold cross validation each with 2 repeats, i.e two different views of the dataset (in train/valid split). This is done in two iterations.
Next 4 iterations are be used for model and feature parameter tuning. This involves creation of approximately 8*3*2 (individuals*folds*repeats) ~ 48 models.
The output models from tuning stage undergo Feature Evolution by genetic algorithm. The genetic algorithm is performed on 8 individuals (population size). The next 10 iterations are used for feature evolution and around (10 * 8/2[population subset] * (3*2) (foldcv*repeats) ~240 new models are scored. The upper limit to it is 528 models. Early stopping is performed if the scores do not improve after 5 iterations.
The final pipeline is created with the a single individual with 3 fold cross validation.
These estimates are based on Accuracy/Time/Interpretabilty dial settings, types of models selected, and other expert settings for the experiment.
Then the transformer allowed search space for the experiment and per feature is mapped out.
WARNING| - Feature engineering search space: [CVCatNumEncode, CVTargetEncode, Frequent, Interactions, NumCatTE, OneHotEncoding, Original]
DATA | LightGBMModel *default* feature->transformer map
DATA | X_0 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_1 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_2 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_3 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_4 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_5 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_6 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_7 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_8 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_9 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
Validation splits creation. The dataset is split internally to create cross validation folds for model building and tuning. In this example, Feature evolution stage will require 3 folds for cross validation and and two repeats i.e data views are done. The for final pipeline will also perform 3 folds cv. After splitting the datasets in to folds for internal validations, a Kolmogorov-Smirnov statistics is calculated to see if the folds have similar distribution of data.
INFO | Preparing validation splits...
INFO | [Feature evolution (repeat 1)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | [Feature evolution (repeat 2)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01793 | means: [14.3447695, 14.362441, 14.366518, 14.318932, 14.340719, 14.370607]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.024698351045656434, pvalue=0.9985813106473687)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.027531279405342373, pvalue=0.9937850958604381)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02358730544637591, pvalue=0.9993204937887651)
INFO | [Final pipeline ] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | Feature engineering training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | split #4: 666 / 334 - target min -1.264726 / 1.490552, target mean: 14.344769 / 14.362441, target max: 27.710434 / 25.997716, target std: 5.026847 / 4.968671
INFO | split #5: 667 / 333 - target min -1.264726 / 1.101135, target mean: 14.366518 / 14.318931, target max: 26.492384 / 27.710434, target std: 4.981698 / 5.058766
INFO | split #6: 667 / 333 - target min 1.101135 / -1.264726, target mean: 14.340719 / 14.370606, target max: 27.710434 / 26.492384, target std: 5.010135 / 5.002203
INFO | Doing backend tuning on data of shape (666, 11) / (334, 11)
INFO | Maximum number of rows (train or valid) for feature evolution: 667
INFO | Final ensemble training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | Maximum number of rows (train or valid) for final model/ensemble: 667
The transformations and genes applicable and the tournament style for the genetic algorithm for feature evolution is registered.
INFO | Transformers used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsTransformer', 'OriginalTransformer']
INFO | Genes used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsGene', 'OriginalGene']
INFO | Tournament style: model
Backend tuning job is run to make sure that everything is working as expected.
INFO | Auto-tuning modeling backend: start.
INFO | Backend candidate Job# 0 Name: LightGBMModel using GPU (if applicable) with Booster: lightgbm
INFO | Backend candidate Job# 1 Name: LightGBMModel using CPU with Booster: lightgbm
...
INFO | Auto-tuning modeling backend: end : Duration: 299.8936 s
Leakage detection A model is run to determine the predictive power of each feature on the target. Then, a simple model is built on each feature with significant variable importance. The models with high AUC (for classification) or R2 score (regression) are reported to the user as potential leak.
INFO | Checking for leakage...
...
INFO | Time for leakage check for training and None: 30.6861 [secs]
INFO | No significant leakage detected in training data ( R2: 0.7957284 )
Target tuning is performed for regression problems to find the best distribution (log, unit box, square root, etc.) of the target variable to optimize for scorer So 3 models with 6 fold cross validation in 2 iterations. Each model tries a different target transformation.
INFO | Tuned 18/18 target transform tuning models. Tuned [LIGHTGBM] Tuning []
INFO | Target transform search: end : Duration: 389.6202 s
INFO | Target transform: TargetTransformer_identity_noclip
Parameter and feature tuning stage starts from 3rd iteration and 4 iterations are spent in building ~48 models (8*3*2).
8 Individuals are built and made sure that the features included in the models satisfy the interpretablity conditions (see nfeatures_max and ngenes_max). Also an additional FS individual is added during the 6th iteration. See tuning phase for reference. Hence this stage builds greater than 48 models.
INFO | Model and feature tuning scores (RMSE, less is better):
INFO | Individual 0 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 1 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 2 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 3 : 1.643672 +/- 0.06142867 [Tournament: 1.643672 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 4 : 1.66976 +/- 0.04171555 [Tournament: 1.66976 Model: LIGHTGBM Feature Cost: 13]
INFO | Individual 5 : 1.683212 +/- 0.06572724 [Tournament: 1.683212 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 6 : 1.690918 +/- 0.05417363 [Tournament: 1.690918 Model: LIGHTGBM Feature Cost: 16]
INFO | Individual 7 : 1.692052 +/- 0.04037833 [Tournament: 1.692052 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 8 : 2.080228 +/- 0.03523514 [Tournament: 2.080228 Model: LIGHTGBM Feature Cost: 13]
INFO | Applying nfeatures_max and ngenes_max limits to tuning population
INFO | Parameter tuning: end : Duration: 634.5521 s
INFO | Prepare Feature Evolution
INFO | Feature evolution has 0 brain cached individuals out of 8 individuals
INFO | Making 1 new individuals during preparation for evolution
INFO | Pre-pruning 1 gene(s) from 12 active base genes
INFO | Starting search for statistically relevant features (FS scheme)
INFO | FS Permute population of size 1 has 2 unique transformations that include: ['InteractionsTransformer', 'OriginalTransformer']
INFO | Transforming FS train
INFO | Using 2 parallel workers (1 parent workers) for fit_transform.
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | Transforming FS valid
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | 10 features created during FS Permute
INFO | Using model LIGHTGBM for FS
The Feature evolution using genetic algorithm starts from the 7th iteration and in each iteration for the next 10 iterations, scores approximately (8/2)(subpopulation) *(3*2) =24 new models.
At the end of the 16th iteration, the experiment has not converged so the Feature evolution is stopped. It is made sure that the features included in the models satisfy the interpretablity conditions and are less than the maximum allowed limits (see nfeatures_max and ngenes_max). Best individual and population is stored in the Driverless AI brain for restart or refitting of the experiment. The best individual(s) is proceeded the next stage.
INFO | Scored 283/310 models on 31 features. Last Scored [LIGHTGBM]
INFO | Scores (RMSE, less is better):
INFO | Individual 0 : 1.540669 +/- 0.07447481 [Tournament: 1.540669 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 1 : 1.541396 +/- 0.07796533 [Tournament: 1.541396 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 2 : 1.542085 +/- 0.07796533 [Tournament: 1.542085 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 3 : 1.543484 +/- 0.07796533 [Tournament: 1.543484 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 4 : 1.547386 +/- 0.08567484 [Tournament: 1.547386 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 5 : 1.557151 +/- 0.08078833 [Tournament: 1.557151 Model: LIGHTGBM Feature Cost: 8]
INFO | Individual 6 : 3.961817 +/- 0.08480774 [Tournament: 3.961817 Model: LIGHTGBM Feature Cost: 4]
INFO | Individual 7 : 4.052189 +/- 0.05662354 [Tournament: 4.052189 Model: LIGHTGBM Feature Cost: 1]
INFO | Best individual with LIGHTGBM model has 7 transformers creating 10 total features and 10 features for model: 1.540669 RMSE
DATA | Top 10 variable importances of best individual:
DATA | LInteraction LGain
DATA | 0 3_X_3 1.000000
DATA | 1 10_InteractionMul:X_0:X_1 0.570066
DATA | 2 4_X_4 0.264919
DATA | 3 10_InteractionAdd:X_0:X_1 0.225805
DATA | 4 2_X_2 0.183059
DATA | 5 0_X_0 0.130161
DATA | 6 1_X_1 0.124281
DATA | 7 10_InteractionDiv:X_0:X_1 0.032255
DATA | 8 10_InteractionSub:X_0:X_1 0.013721
DATA | 9 7_X_7 0.007424
INFO | Experiment has not yet converged after 16 iteration(s). Last few scores: ['1.63849', '1.63852', '1.63852', '1.61909', '1.61909', '1.56956', '1.56956', '1.54208', '1.54208', '1.54067', '1.54067', '1.54067']
INFO | Completed all expected evolution iterations: 17
INFO | Final Feature Evolution Population with population of 8 individuals (best scores=['1.547386', '1.540669', '4.052189', '1.557151', '1.542085', '3.961817', '1.541396', '1.543484'])
...
INFO | Applying nfeatures_max and ngenes_max limits to final individual 0 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 1 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 2 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 3 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 4 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 5 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 6 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 7 layer 0
INFO | Exporting best individual pickle /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_individual.pickle
INFO | Exporting best population for model-feature caching to /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_population.pickle
INFO | Final population size before sampling: 8. After sampling expected population size: 1.
INFO | Final population size after sampling: 1 (0 reference) with models_final=3 and num_ensemble_folds=3
INFO | Final Model sampled population with population of 8 individuals (best scores=['1.540669'])
In iteration 17, three fold cross validation is performed on the final ensemble model, a few checks are done on the features used, predictions and python and mojo scoring pipelines are created. Logs and summary artifacts are collected.
INFO | Completed 3/3 final ensemble models.
INFO | Model performance:
INFO | fold: 0, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 2.4198, fit+predict model time: 0.376, total pipeline time: 0.48786, fit pipeline time: 0.29738
INFO | fold: 1, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 3.343, fit+predict model time: 0.34681, total pipeline time: 0.43664, fit pipeline time: 0.24267
INFO | fold: 2, model name: LightGBM, model iterations: 473, model transformed features: 10, total model time: 2.1446, fit+predict model time: 0.38534, total pipeline time: 0.41979, fit pipeline time: 0.23152
INFO | Checking for shift in tuning model -> final model variable importances
DATA | New features created only in final pipeline: Count: 0 List: []
DATA | Extra features created in final pipeline compared to genetic algorithm population: Count: 0 List: []
DATA | Missing features from final StackedEnsemble pipeline compared to genetic algorithm population: Count: 0 List: []
INFO | Completed training of the final scoring pipeline
INFO | Predictions and Scoring final pipeline...
INFO | Scored 286/310 models on 31 features. Last Scored []
...
INFO | Experiment: buvobamu (59939c96-0150-11ec-a7e1-0242c0a8fe02)
INFO | Version: 1.10.0, 2021-08-20 01:48
INFO | Settings: 7/2/8, seed=1037348886, GPUs enabled
INFO | Train data: [XXXXX] (1000, 11)
INFO | Validation data: N/A
INFO | Test data: N/A
INFO | Target column: [XXXXX] (regression, identity_noclip-transformed)
INFO | System specs: Docker/Linux, 252 GB, 40 CPU cores, 2/2 GPUs
INFO | Max memory usage: 0.849 GB, 0.279 GB GPU
INFO | Recipe: AutoDL (16 iterations, 8 individuals)
INFO | Validation scheme: random, 6 internal holdouts (3-fold CV)
INFO | Feature engineering: 31 features scored (10 selected)
INFO | Timing: MOJO latency 0.0571 millis (512.7kB), Python latency 110.0896 millis (1.1GB)
INFO | Data preparation: 310.14 secs
INFO | Shift/Leakage detection: 30.75 secs
INFO | Model and feature tuning: 1027.26 secs (61 of 66 models trained)
INFO | Feature evolution: 2102.52 secs (222 of 528 models trained)
INFO | Final pipeline training: 17.77 secs (3 models trained)
INFO | Python / MOJO scorer building: 49.86 secs / 19.75 secs
INFO | Validation score: RMSE = 5.002508 (constant preds of 14.35)
INFO | Validation score: RMSE = 1.638517 +/- 0.04910973 (baseline)
INFO | Validation score: RMSE = 1.543872 +/- 0.04469455 (final pipeline)
INFO | Test score: RMSE = N/A
INFO |
INFO |
INFO | Final validation scores (internal holdout, bootstrap on folds) +/- stddev:
INFO | optimized: RMSE = 1.543872 +/- 0.04469455 (less is better)
INFO | GINI = 0.9528597 +/- 0.001413133 (more is better)
INFO | MAE = 1.148299 +/- 0.02813014 (less is better)
...
INFO |
2021-08-20 01:48:09,475 C: 14% D:935.5GB M:249.9GB NODE:LOCAL1 7646 INFO | Collecting logs
Some Additional Details¶
Upfront Feature Selection: Depending on the experiment settings, feature reduction can be applicable for either all models or can add one special FS (Feature Selection) individual with original columns reduced before genetic algorithm starts.Reducing number of features for all models is applicable only when (one of below satisfied):
num. of columns, is greater than max_orig_cols_selected or,
num of non-numeric columns, is greater than max_orig_nonnumeric_cols_selected or,
num. of numeric columns, is greater than max_orig_numeric_cols_selected
Given the above requirements for all models is not satisfied; reducing number of features only for the FS individual (EXTRA_FS) is applicable only when (one of below satisfied) :
num. of columns, is greater than fs_orig_cols_selected or,
num. of non-numeric columns, is greater than fs_orig_numeric_cols_selected or,
num. of numeric columns, is greater than fs_orig_nonnumeric_cols_selected
See tuning phase and permutation importance.
Tuning Phase Model Origins:SEQUENCE and DefaultIndiv: Feature transformations and model hyper-parameters are chosen at random from the basic transformation sets and parameter lists as suggested by internal proprietary data science recipes. This set is simple and supports MOJO creation for productionization of pipeline.
model_origin as RANDOM allows both features and model hyper-parameters to call their mutate lists or functions.
model_origin as EXTRA_FS is for the extra individuals added through Feature Selection(FS) based on permutation importance.
model_origin as REF_# denotes for reference individuals provided as a baseline(eg. ConstantModel).
model_origin as GLM_OHE denotes features generated by GLM + OHE.
Driverless AI Brain: During an experiment building, Brain caches the best iterations, parameters, models, genes and populations. These are used for informed lookups, cross overs during mutation, restarts and refits of experiment. For details see feature_brain_level.Mutation strategy: Strategy to apply when doing mutations on transformers:Sample mode is default, with tendency to sample transformer parameters.
Batched mode tends to do multiple types of the same transformation together.
Full mode does even more types of the same transformation together.
Here are some other related expert settings: Probability to add transformers (prob_add_genes), Probability to add best shared transformers (prob_addbest_genes), Probability to prune transformers (prob_prune_genes), Probability to mutate model parameters (prob_perturb_xgb), Probability to prune weak features (prob_prune_by_features). Note that the default Driverless AI settings perform best in most cases and these settings should be left as default.
Mutation via custom recipe: Users can control and specify their own mutation strategy and the list of parameters to mutate on, by writing their own custom python code and hooking it up with the inbuilt Driverless AI Genetic Algorithm. Here is an example of such a recipe. Theget_onefunction passes on the list of values to genetic algorithm or Optuna for that parameter. Reach out to support@h2o.ai if need more help with writing your own custom recipies.Optuna: Driverless AI supports Optuna for model hyperparameter tuning during the Tuning phase of an experiment. Optuna employs a Bayesian optimization algorithm called Tree-structured Parzen Estimator for hyperparameter optimization. For details see enable_genetic_algorithm and tournament_style. When Optuna is selected then, model hyperparameters are tuned with Optuna and genetic algorithm is used for feature engineering. Bayesian optimization exploits structure in the data; as Optuna employs Bayesian techniques, it is recommended to use it when the search space is not very complex. See the list of toggleable parameters for Optuna starting here.Leaderboard: During experiment building, Driverless can be instructed to build a bunch of varied experiments that try different approaches to build simple and complex models out of the box.