Driverless AI MOJO Scoring Pipeline - Java Runtime (With Shapley contribution)¶
For completed experiments, Driverless AI automatically converts models to MOJOs (Model Objects, Optimized). The MOJO Scoring Pipeline is a scoring engine that can be deployed in any Java environment for scoring in real time. (For information on the C++ scoring runtime with Python and R wrappers, see H2O MOJO C++ scoring pipeline.) For info on the available deployment options, see H2O MOJO Deployment.
MOJOs are tied to experiments. Experiments and MOJOs are not automatically upgraded when Driverless AI is upgraded.
Notes:
This scoring pipeline is not currently available for TensorFlow, BERT, RuleFit or Image models. TensorFlow/Bert are supported by C++ Runtime.
To disable the automatic creation of this scoring pipeline, set the Make MOJO Scoring Pipeline expert setting to Off while building an experiment.
You can have Driverless AI attempt to reduce the size of the MOJO scoring pipeline when the experiment is being built by enabling the Reduce MOJO Size expert setting also see.
Shapley contributions come with the downloaded experiment MOJO scoring pipeline (Java runtime).
Shapley contributions for transformed features and original features are currently available for XGBoost (GBM, GLM, RF, DART), LightGBM, Zero-Inflated, Imbalanced and DecisionTree models (and their ensemble). For ensemble with ExtraTrees meta learner (ensemble_meta_learner=’extra_trees’) models, we suggest to use the MLI Python scoring package.
Note
From version 1.10.7 onwards, the native Java runtime will only receive further updates in the form of security and bug fixes. All new features and enhancements will be available through the new Java Wrapper. For more information on the Java Wrapper, see H2O MOJO Java Wrapper.
Download¶
Because the Java MOJO runtime is backward compatible, we recommend using the latest available version. You can download the latest Java MOJO runtime from https://mvnrepository.com/artifact/ai.h2o/mojo2-runtime.
A Quick run¶
To get a quick output from the downloaded MOJO scoring pipeline in the console on the example test set:
Make sure Java7 or later is installed.
copy Driverless AI license file (say license.file) to the downloaded mojo-pipeline folder
cd into the mojo-pipeline folder
Score the rows of the example.csv file using the pipeline.mojo file( with the mojo2-runtime) created from the experiment to get the predictions.
java -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar pipeline.mojo example.csvTo get Shapley contributions for transformed features run using the flag
--show-contributionsjava -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar --show-contributions pipeline.mojo example.csvTo get Shapley contributions for original features run using the flag
--show-contributions-originaljava -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar --show-contributions-original pipeline.mojo example.csvTo get the prediction interval from the MOJO, run using the flag
--with-prediction-intervaljava -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar --with-prediction-interval pipeline.mojo example.csv
See run-example.sh for reference. Bigger test files/MOJOs may require more memory (Xmx) to score.
Notes:
Presently, Shapley contributions for transformed features and original features are available for XGBoost (GBM, GLM, RF, DART), LightGBM, Zero-Inflated, Imbalanced and DecisionTree models (and their ensemble). For ensemble with ExtraTrees meta learner (ensemble_meta_learner=’extra_trees’) models we suggest to use the MLI Python scoring package.
In MOJOs, Shapley values for original features are approximated from the accompanying Shapley values for transformed features with the Naive Shapley (even split) method.
The Shapley fast approximation uses only one model (from the first fold) with no more than the first 50 trees. For details see
fast_approx_num_treesandfast_approx_do_one_fold_one_modelconfig.toml settings.
Prerequisites¶
The following are required in order to run the MOJO scoring pipeline.
- Java runtime: The DAI MOJO runtime supports the following range of Java runtimes.
Minimum supported version: Java 8
Maximum supported version: Java 17
Note: It is recommended to use Java 11+ due to a bug in Java. (For more information, see https://bugs.openjdk.java.net/browse/JDK-8186464.)
Valid Driverless AI license. You can download the
license.sigfile from the machine hosting Driverless AI (usually in the license folder). Copy the license file into the downloadedmojo-pipelinefolder.mojo2-runtime.jar file. This is available from the top navigation menu in the Driverless AI UI and in the downloaded mojo-pipeline.zip file for an experiment.
License Specification¶
Driverless AI requires a license to be specified in order to run the MOJO Scoring Pipeline. The license can be specified in one of the following ways:
Via an environment variable:
DRIVERLESS_AI_LICENSE_FILE: Path to the Driverless AI license file, orDRIVERLESS_AI_LICENSE_KEY: The Driverless AI license key (Base64 encoded string)
Via a system property of JVM (
-Doption):ai.h2o.mojos.runtime.license.file: Path to the Driverless AI license file, orai.h2o.mojos.runtime.license.key: The Driverless AI license key (Base64 encoded string)
Via an application classpath:
The license is loaded from a resource called
/license.sig.The default resource name can be changed via the JVM system property
ai.h2o.mojos.runtime.license.filename.
For example:
# Specify the license via a temporary environment variable
export DRIVERLESS_AI_LICENSE_FILE="path/to/license.sig"
MOJO Scoring Pipeline Files¶
The mojo-pipeline folder includes the following files:
run_example.sh: An bash script to score a sample test set.
pipeline.mojo: Standalone scoring pipeline in MOJO format.
mojo2-runtime.jar: MOJO Java runtime.
example.csv: Sample test set (synthetic, of the correct format).
DOT files: Text files that can be rendered as graphs that provide a visual representation of the MOJO scoring pipeline (can be edited to change the appearance and structure of a rendered graph).
PNG files: Image files that provide a visual representation of the MOJO scoring pipeline.
Quickstart¶
Before running the quickstart examples, be sure that the MOJO scoring pipeline is already downloaded and unzipped:
On the completed Experiment page, click on the Download MOJO Scoring Pipeline button.
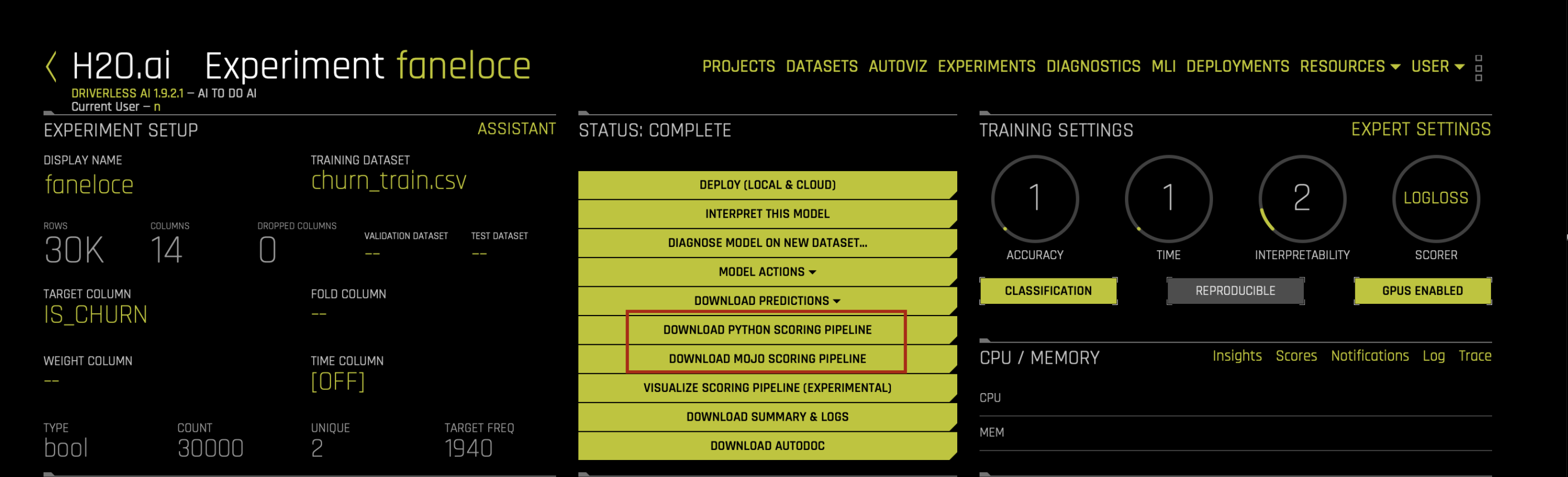
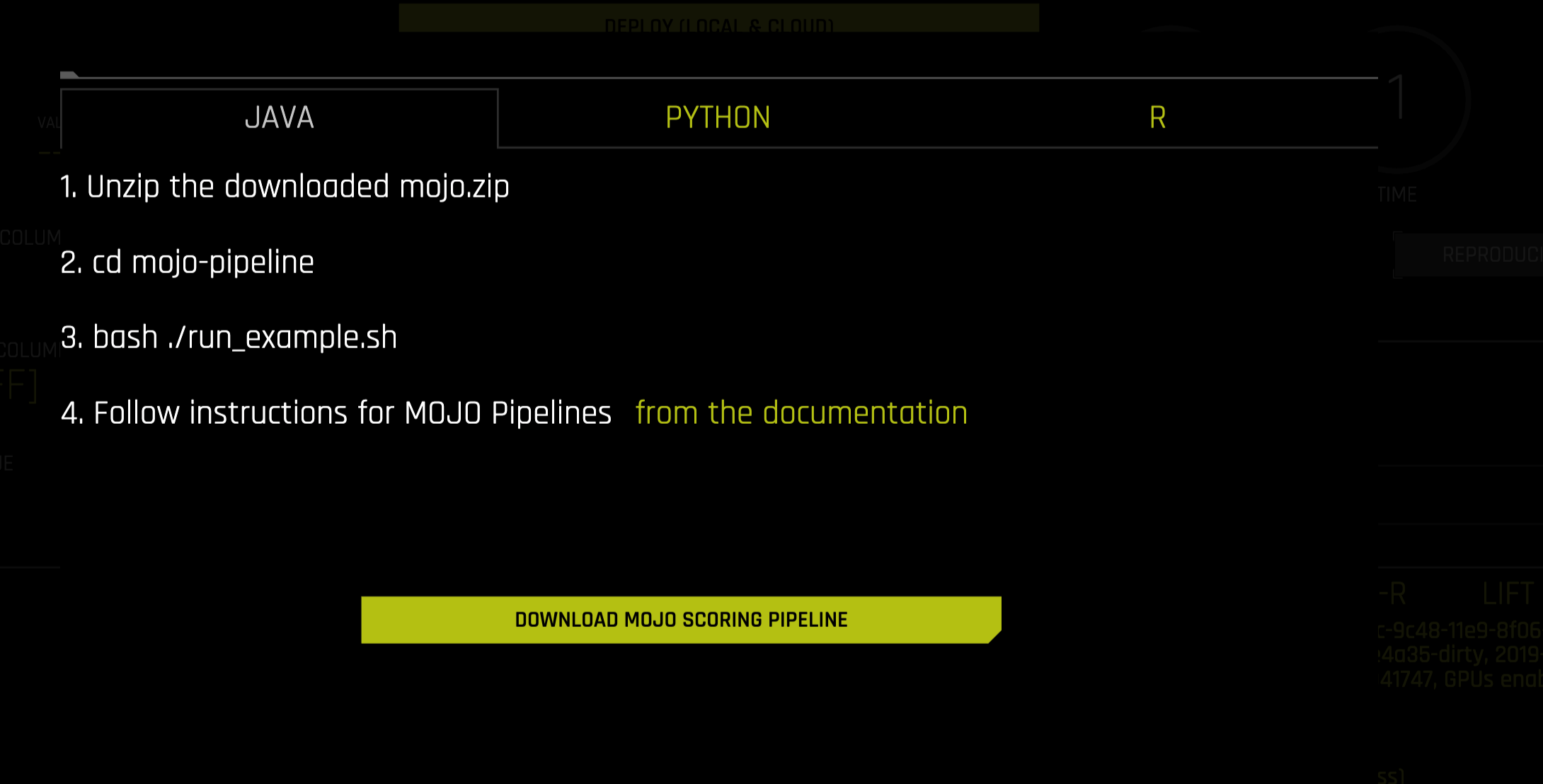
In the pop-up menu that appears, click on the Download MOJO Scoring Pipeline button once again to download the scorer.zip file for this experiment onto your local machine. Refer to the provided instructions for Java, Python, or R.
Run the following to score all rows in the sample test set with the file paths to the test set (example.csv), MOJO pipeline (pipeline.mojo) and license (license.sig) stored in environment variables
TEST_SET_FILE,MOJO_PIPELINE_FILE,DRIVERLESS_AI_LICENSE_KEY:
bash run_example.sh
Run the following to score a specific test set (example.csv) with MOJO pipeline (pipeline.mojo) and the license file (license.sig):
bash run_example.sh pipeline.mojo example.csv license.sig
To run the Java application for data transformation directly:
java -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csvNote: For very large models, it may be necessary to increase the memory limit when running the Java application for data transformation. This can be done by specifying
-Xmx25gwhen running the above command.
MOJO Scoring Command-Line Options¶
Executing the Java Runtime¶
The following are two general examples of how the Java runtime can be executed from the command-line.
With additional libraries:
java <JVM options> [options...] -cp mojo2-runtime.jar:your-other.jar:many-more-libs.jar ai.h2o.mojos.ExecuteMojo path-to/pipeline.mojo path-to/input.csv path-to/output.csv
Without additional libraries:
java <JVM options> -jar mojo2-runtime.jar path-to/pipeline.mojo path-to/input.csv path-to/output.csv
For JDK >= 16, the following JVM argument must be passed:
java <JVM options> --add-opens=java.base/java.lang=ALL-UNNAMED -jar mojo2-runtime.jar path-to/pipeline.mojo path-to/input.csv path-to/output.csv
So, for example, the sys.ai.h2o.mojos.parser.csv.separator option can be passed with the following:
java -Dsys.ai.h2o.mojos.parser.csv.separator='|' -Dai.h2o.mojos.runtime.license.file=../license.sig -jar mojo2-runtime.jar pipeline.mojo input.csv output.csv
Similarly, the sys.ai.h2o.mojos.exposedInputs option can be passed with:
java -Xmx5g -Dsys.ai.h2o.mojos.exposedInputs=ALL -Dai.h2o.mojos.runtime.license.file= -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv
Note: Data can be streamed from stdin to stdout by replacing both the input and output CSV arguments with `-`.
Java Virtual Machine (JVM) Options¶
sys.ai.h2o.mojos.parser.csv.keepCarriageReturn(boolean) - Specify whether to keep the carriage return after parsing. This value defaults to True.sys.ai.h2o.mojos.parser.csv.stripCrFromLastColumn(boolean) - Workaround for issues relating to the OpenCSV parser. This value defaults to True.sys.ai.h2o.mojos.parser.csv.quotedHeaders(boolean) - Specify whether to quote header names in the output CSV file. This value defaults to False.sys.ai.h2o.mojos.parser.csv.separator(char) - Specify the separator used between CSV fields. The special value `TAB` can be used for tab-separated values. This value defaults to `,`.sys.ai.h2o.mojos.parser.csv.escapeChar(char) - Specify the escape character for parsing CSV fields. If this value is not specified, then no escaping is attempted. This value defaults to an empty string.sys.ai.h2o.mojos.parser.csv.batch(int) - Specify the number of input records brought into memory for batch processing (determines consumed memory). This value defaults to 1000.sys.ai.h2o.mojos.pipelineFormats(string) - When multiple formats are recognized, this option specifies the order in which they are tried. This value defaults to `pbuf,toml,klime,h2o3`.sys.ai.h2o.mojos.parser.csv.date.formats(string) - Specify a format for dates. This value defaults to an empty string.sys.ai.h2o.mojos.exposedInputs(string) - Specify a comma separated list of input cols that are needed on output. The special value `ALL` takes all inputs. This defaults to a null value.sys.ai.h2o.mojos.useWeakHash(boolean) - Specify whether to use WeakHashMap. This is set to False by default. Enabling this setting may improve MOJO loading times.
JVM Options for Access Control
ai.h2o.mojos.runtime.license.key- Specify a license key.ai.h2o.mojos.runtime.license.file- Specify the location of a license key.ai.h2o.mojos.runtime.license.filename- Override the default license file name.ai.h2o.mojos.runtime.signature.filename- Override the default signature file name.ai.h2o.mojos.runtime.watermark.filename- Override the default watermark file name.
Execute the MOJO from Java¶
Open a new terminal window, create an experiment folder, and change directories to that new folder:
mkdir experiment && cd experiment
Create your main program in the experiment folder by creating a new file called DocsExample.java (for example, using
vim DocsExample.java). Include the following contents.
import ai.h2o.mojos.runtime.MojoPipeline; import ai.h2o.mojos.runtime.api.MojoPipelineService; import ai.h2o.mojos.runtime.frame.MojoFrame; import ai.h2o.mojos.runtime.frame.MojoFrameBuilder; import ai.h2o.mojos.runtime.frame.MojoRowBuilder; import ai.h2o.mojos.runtime.lic.LicenseException; import ai.h2o.mojos.runtime.utils.CsvWritingBatchHandler; import com.opencsv.CSVWriter; import java.io.BufferedWriter; import java.io.IOException; import java.io.OutputStreamWriter; import java.io.Writer; import java.io.File; public class DocsExample { public static void main(String[] args) throws IOException, LicenseException { // Load model and csv final MojoPipeline model = MojoPipelineService.loadPipeline(new File("pipeline.mojo")); // Get and fill the input columns final MojoFrameBuilder frameBuilder = model.getInputFrameBuilder(); final MojoRowBuilder rowBuilder = frameBuilder.getMojoRowBuilder(); rowBuilder.setValue("AGE", "68"); rowBuilder.setValue("RACE", "2"); rowBuilder.setValue("DCAPS", "2"); rowBuilder.setValue("VOL", "0"); rowBuilder.setValue("GLEASON", "6"); frameBuilder.addRow(rowBuilder); // Create a frame which can be transformed by MOJO pipeline final MojoFrame iframe = frameBuilder.toMojoFrame(); // Transform input frame by MOJO pipeline final MojoFrame oframe = model.transform(iframe); // `MojoFrame.debug()` can be used to view the contents of a Frame // oframe.debug(); // Output prediction as CSV final Writer writer = new BufferedWriter(new OutputStreamWriter(System.out)); final CSVWriter csvWriter = new CSVWriter(writer); CsvWritingBatchHandler.csvWriteFrame(csvWriter, oframe, true); } }
Compile the source code with the files of the MOJO runtime (mojo2-runtime.jar) and MOJO pipeline (pipeline.mojo) copied into the experiment:
javac -cp mojo2-runtime.jar -J-Xms2g -J-XX:MaxPermSize=128m DocsExample.java
Run the MOJO example with the license (license.sig) copied into the experiment:
# Linux and OS X users java -Dai.h2o.mojos.runtime.license.file=license.sig -cp .:mojo2-runtime.jar Main # Windows users java -Dai.h2o.mojos.runtime.license.file=license.sig -cp .;mojo2-runtime.jar Main
The following output is displayed:
CAPSULE.True 0.5442205910902282
Using the MOJO Scoring Pipeline with Spark/Sparkling Water¶
Note: The Driverless AI 1.5 release will be the last release with TOML-based MOJO2. Releases after 1.5 will include protobuf-based MOJO2.
MOJO scoring pipeline artifacts can be used in Spark to deploy predictions in parallel using the Sparkling Water API. This section shows how to load and run predictions on the MOJO scoring pipeline in Spark using Scala and the Python API.
In the event that you upgrade H2O Driverless AI, we have a good news! Sparkling Water is backwards compatible with MOJO versions produced by older Driverless AI versions.
Requirements¶
You must have a Spark cluster with the Sparkling Water JAR file passed to Spark.
To run with PySparkling, you must have the PySparkling zip file.
The H2OContext does not have to be created if you only want to run predictions on MOJOs using Spark. This is because the scoring is independent of the H2O run-time.
Preparing Your Environment¶
In order use the MOJO scoring pipeline, Driverless AI license has to be passed to Spark. This can be achieved via --jars argument of the Spark launcher scripts.
Note: In Local Spark mode, use --driver-class-path to specify path to the license file.
PySparkling¶
First, start PySpark with PySparkling Python package and Driverless AI license.
./bin/pyspark --jars license.sig --py-files pysparkling.zip
or, you can download official Sparkling Water distribution from H2O Download page. Follow the steps on the Sparkling Water download page. Once you are in the Sparkling Water directory, you can call:
./bin/pysparkling --jars license.sig
At this point, you should have available a PySpark interactive terminal where you can try out predictions. If you would like to productionalize the scoring process, you can use the same configuration, except instead of using ./bin/pyspark, you would use ./bin/spark-submit to submit your job to a cluster.
# First, specify the dependencies
from pysparkling.ml import H2OMOJOPipelineModel, H2OMOJOSettings
# The 'namedMojoOutputColumns' option ensures that the output columns are named properly.
# If you want to use old behavior when all output columns were stored inside an array,
# set it to False. However we strongly encourage users to use True which is defined as a default value.
settings = H2OMOJOSettings(namedMojoOutputColumns = True)
# Load the pipeline. 'settings' is an optional argument. If it's not specified, the default values are used.
mojo = H2OMOJOPipelineModel.createFromMojo("file:///path/to/the/pipeline.mojo", settings)
# Load the data as Spark's Data Frame
dataFrame = spark.read.csv("file:///path/to/the/data.csv", header=True)
# Run the predictions. The predictions contain all the original columns plus the predictions
# added as new columns
predictions = mojo.transform(dataFrame)
# You can easily get the predictions for a desired column using the helper function as
predictions.select(mojo.selectPredictionUDF("AGE")).collect()
Sparkling Water¶
First, start Spark with Sparkling Water Scala assembly and Driverless AI license.
./bin/spark-shell --jars license.sig,sparkling-water-assembly.jar
or, you can download official Sparkling Water distribution from H2O Download page. Follow the steps on the Sparkling Water download page. Once you are in the Sparkling Water directory, you can call:
./bin/sparkling-shell --jars license.sig
At this point, you should have available a Sparkling Water interactive terminal where you can carry out predictions. If you would like to productionalize the scoring process, you can use the same configuration, except instead of using ./bin/spark-shell, you would use ./bin/spark-submit to submit your job to a cluster.
// First, specify the dependencies
import ai.h2o.sparkling.ml.models.{H2OMOJOPipelineModel, H2OMOJOSettings}
// The 'namedMojoOutputColumns' option ensures that the output columns are named properly.
// If you want to use old behavior when all output columns were stored inside an array,
// set it to false. However we strongly encourage users to use true which is defined as a default value.
val settings = H2OMOJOSettings(namedMojoOutputColumns = true)
// Load the pipeline. 'settings' is an optional argument. If it's not specified, the default values are used.
val mojo = H2OMOJOPipelineModel.createFromMojo("file:///path/to/the/pipeline.mojo", settings)
// Load the data as Spark's Data Frame
val dataFrame = spark.read.option("header", "true").csv("file:///path/to/the/data.csv")
// Run the predictions. The predictions contain all the original columns plus the predictions
// added as new columns
val predictions = mojo.transform(dataFrame)
// You can easily get the predictions for desired column using the helper function as follows:
predictions.select(mojo.selectPredictionUDF("AGE")).show()
Using the MOJO Java Wrapper of C++ Runtime¶
The new Java wrapper supports all of the models supported by the C++ MOJO runtime, including TensorFlow and NLP models. This section describes how to use the Java wrapper and run predictions on the MOJO scoring pipeline.
Note: The new Java wrapper is backward compatible with MOJO versions produced by older Driverless AI versions and is also included in the existing JAR file alongside java-runtime. Note that it is only tested and supported for Linux environments.
Requirements¶
The following are required in order to run the MOJO scoring pipeline.
Linux OS.
The DAI MOJO Java wrapper supports Java >= 8.
Valid Driverless AI license.
mojo2-runtime.jarfile. This is available from the top navigation menu in the Driverless AI UI and in the downloadedmojo-pipeline.zipfile for an experiment.
License Specification¶
Driverless AI requires a license to be specified in order to run the MOJO Scoring Pipeline. The license can be specified in one of the following ways:
Via an environment variable:
DRIVERLESS_AI_LICENSE_FILE: Path to the Driverless AI license file, orDRIVERLESS_AI_LICENSE_KEY: The Driverless AI license key (Base64 encoded string)
Via default Driverless AI license folder in HOME directory:
at
${HOME}/.driverlessai/license.sig.
Execute the Java Wrapper Runtime¶
This section describes how to execute the Java Wrapper. For Linux environments, by default the Java Wrapper is used without any configuration. (Note that you can disable the Java Wrapper and use the native Java runtime instead. For more information, refer to the second example in this section.)
The following are two general examples of how the Java runtime can be configured to use or not use the Java wrapper from the command-line.
To force usage of the Java Wrapper:
MOJO_USE_JAVA_WRAPPER=1 java <JVM options> [options...] -cp mojo2-runtime.jar:your-other.jar:many-more-libs.jar ai.h2o.mojos.ExecuteMojo path-to/pipeline.mojo path-to/input.csv path-to/output.csv
To disable the Java Wrapper and use the native Java runtime:
MOJO_USE_JAVA_WRAPPER=0 java <JVM options> -jar mojo2-runtime.jar path-to/pipeline.mojo path-to/input.csv path-to/output.csv