H2O Driverless AI 简介¶
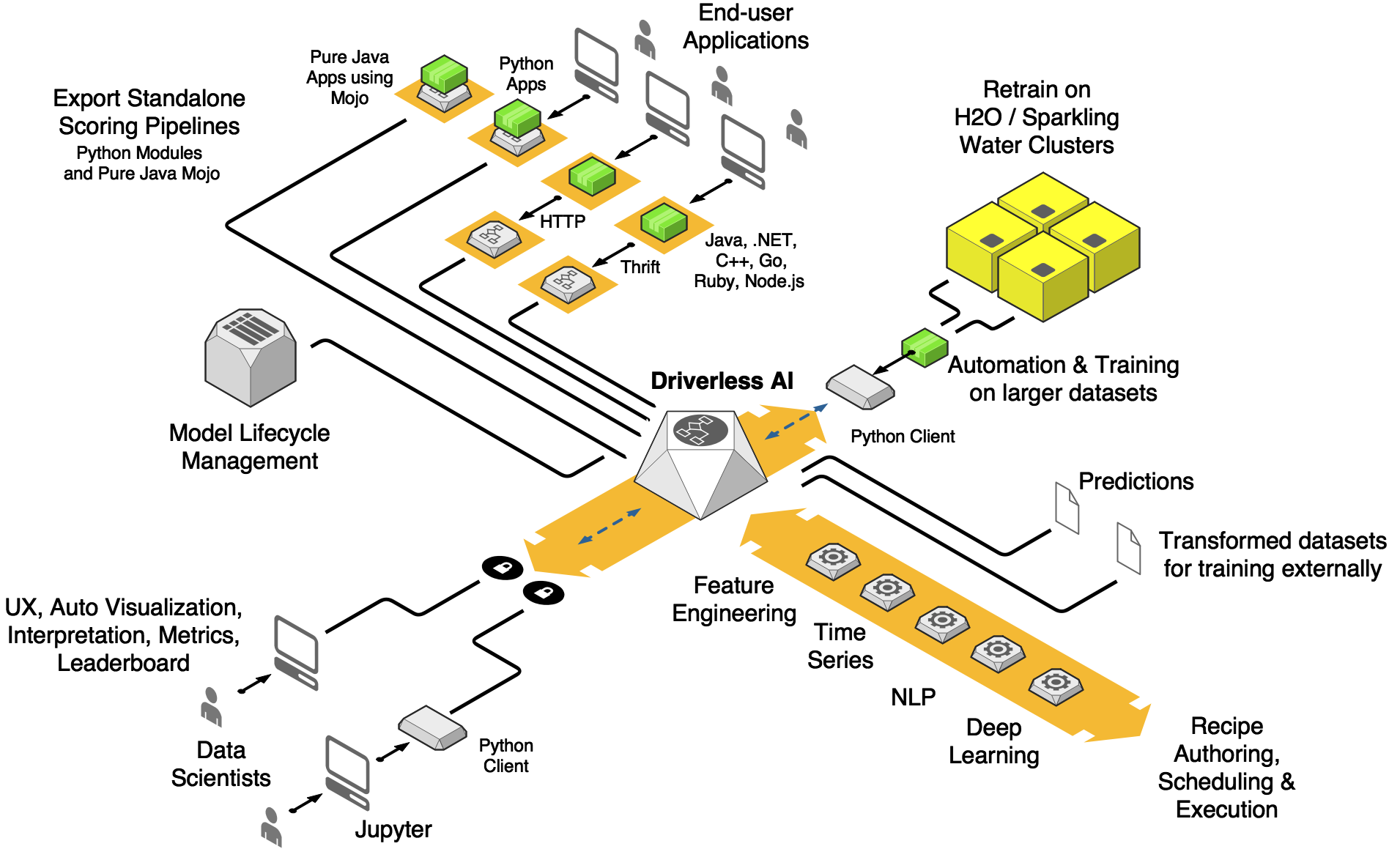
H2O Driverless AI 是一种支持 GPU 的高性能客户端-服务器应用程序,可用于快速开发和部署先进的预测分析模型。它会读取不同来源的表格数据,自动进行数据可视化、大师级自动特征工程、模型验证(预防过拟合和泄露)、模型参数调优、模型可解释性和模型部署。目前,H2O Driverless AI 主要用于常见的回归、二项分类和多项分类应用,包括违约损失率、违约概率、客户流失、活动响应、欺诈检测、反洗钱和预测性资产维护模型。此外,还可以通过时间因果特征工程和验证方案处理单个或分组时间序列的时间序列问题,比如每个门店和部门的周销量预测。Driverless 还可以处理图像和文本数据 (NLP) 用例。
高级功能:
客户端/服务器应用程序可以快速实验和部署先进的监督式机器学习模型
易于使用的 GUI
Python 和 R 客户端 API
自动创建预测准确度最高的机器学习建模管道
自动进行数据清理、特征选择、特征工程、模型选择、模型调优、集成
采用 Python 语言,可通过 HTTP 或 TCP 协议自动创建能够进行过程中评分或客户端/服务器评分的独立批量评分管道
采用 C++(带 R 和 Python 运行时间)和 Java(可在任意平台运行)语言,可通过 HTTP 或 TCP 协议自动创建能够进行过程中评分或客户端/服务器评分的独立 (MOJO) 低延迟评分管道
支持多 GPU 和多 CPU,可用于功能强大的工作站和 NVidia DGX 超级计算机
具有全局和局部模型解释功能的机器学习模型解释模块
自动可视化模块
多用户支持
向后兼容
支持的问题类型:
回归(连续型目标变量,例如年龄、收入、价格或损失预测、时间序列预测等)
二项分类(0/1 或 “N”/”Y”,用于欺诈预测、流失预测、故障预测等)
多项分类(分类目标变量为 “负”/”中性”/”正” 或 0/1/2/3 或 0.5/1.0/2.0,用于预测成员资格类型、下一步行动、产品推荐、情感分析等。)
支持的数据类型:
表格结构化数据,其中的行为观测值,列为字段/特征/变量
数值、分类和文本字段
图像
允许使用缺失值
i.i.d(独立同分布)数据
具有单个时间序列的时间序列数据(时间横跨整个数据集,而不是每个数据块)
分组时间序列(例如,每周每个部门每个门店的销量,全部放在一个文件中,其中有以下三列:门店、部门和周)
训练和测试数据之间存在间隔(即,部署所需的时间)以及具有已知预测期(在此之后必须重新训练模型)的时间序列问题
通过自定义插件支持的数据类型:
视频
音频
图表
支持的数据源:
本地文件系统或 NFS
从浏览器或 Python 客户端上传的文件
S3 (Amazon)
Hadoop (HDFS)
Azure Blob 存储
Blue Data Tap
Google BigQuery
Google Cloud Storage
kdb+
Minio
Snowflake
JDBC
自定义数据插件 BYOR(Python,自带插件)
支持的文件格式:
纵列数据的纯文本格式(.csv、.tsv、.txt)
压缩存档(.zip、.gz、.bz2)
Excel
Parquet
Feather
Python 数据表 (.jay)