常见问题解答¶
H2O Driverless AI 是一个用于自动机器学习的人工智能 (AI) 平台。Driverless AI 将一些最难解的数据科学和机器学习工作流(例如特征工程、模型验证、模型调优、模型选择和模型部署)实现了自动化。其旨在实现最高的预测准确度,可与专业数据科学家相媲美,但是由于端到端的自动化,Driverless AI 能在更短的时间内实现这一点。Driverless AI 还提供自动可视化和机器学习可解释性 (MLI)。特别是在受监管的行业中,模型的透明度和解释和其预测性能一样重要。建模管道(特征工程和模型)可作为 Python 模块和 Java 独立评分工件导出(完全保真,不采用近似法)。
本节提供常见问题的解答。如果您对于使用 Driverless AI 还有其他问题,请在 http://stackoverflow.com/questions/tagged/driverless-ai 上使用 driverless-ai 标签将问题发布至 Stack Overflow 版块。您还可在 #driverlessai 频道的 H2O.ai Community Slack 工作区 上发布问题。如果您尚未注册 H2O.ai Community Slack 工作区,则可以点击此处进行注册:https://www.h2o.ai/community/。
一般
安装/升级/身份验证
为什么在安装过程中会出现 “package dai-<version>.x86_64 does not verify: no digest” 的错误提示?
我收到了一条 “Must have exactly one OpenCL platform ‘NVIDIA CUDA’” 的错误提示。该如何解决此问题?
Driverless AI 启动失败,并在 Ubuntu 18/RHEL 7.6 上显示以下消息:”Segmentation fault (core dumped)”。我该如何解决此问题?
数据
连接器
插件
实验
特征转换
预测
部署
时间序列
日志记录
一般¶
Driverless AI 和任何其他黑盒机器学习算法有何区别?
Driverless AI 使用多种技术(旧技术和最新技术)来解释黑盒模型,包括为系统进行的每项预测创建原因码。我们还创建了大量开放源代码示例和免费出版物来介绍这些技术。请参阅下方列表,获取这些资源的链接和可解释性技术的参考资料。
开源可解释性示例:
免费的机器学习可解释性出版物:
Driverless AI 中 已 采用的机器学习技术:
多久推出一次新版本?
Driverless AI 的重要新版本大约为每两个月发布一次。
安装/升级/身份验证¶
如何更改用户名和密码?
用户名和密码将与您创建的实验绑定。例如,如果我使用用户名/密码:megan/megan 登录并启动实验,那么我以后将需要使用相同的用户名和密码重新登录,方可查看这些实验。但是,用户名和密码并不会限制您对 Driverless AI 的访问。如果您想要使用新的用户名和密码,则可使用新的用户名和密码重新登录,但是请注意,您将不能查看之前的实验。
能否在仅使用 CPU 的计算机上运行 Driverless AI?
能,尽管建议使用 GPU,但是 Driverless AI 能在仅使用 CPU 的计算机上运行。对 GPU 和 CPU 系统均提供了安装说明。更多信息,请参阅 开始前.
如何升级至 Driverless AI 的更新版本?
升级说明将因环境而异。请参阅适用于您的环境的安装部分内容。其中包含升级说明。
Driverless AI 支持何种类型的身份验证?
Driverless AI 支持“客户端证书”、LDAP、“本地”、mTLS、OpenID、PAM、“无”以及“不验证”(默认)等身份验证选项。以上身份验证方式可通过在 config.toml 文件中指定适当的环境变量或在启动 Driverless AI 时指定环境变量来进行配置。更多信息,请参阅 身份验证方式.
每次 GPU 系统重启时,如何自动开启持久模式?
对于使用 GPU 的计算机,可在每次重启后运行
sudo nvidia-persistenced --user dai命令以启用持久模式。对于具有 systemd 的系统,通过从 nvidia-persistenced.service 中移除--no-persistence-mode标记,即可在每次重启后自动启用持久模式。在执行以下步骤前,请务必查看以下内容,了解更多信息:
https://docs.nvidia.com/deploy/driver-persistence/index.html#persistence-daemon
https://docs.nvidia.com/deploy/driver-persistence/index.html#installation
运行以下命令以终止 nvidia-persistenced.service:
sudo systemctl stop nvidia-persistenced.service
打开文件 /lib/systemd/system/nvidia-persistenced.service。此文件包括一行 “ExecStart=/usr/bin/nvidia-persistenced –user nvidia-persistenced –no-persistence-mode –verbose”。
从此行中移除标记“–no-persistence-mode”,从而更改为:
ExecStart=/usr/bin/nvidia-persistenced --user nvidia-persistenced --verbose
运行以下命令以启用 nvidia-persistenced.service:
sudo systemctl start nvidia-persistenced.service
如何在除 12345 端口以外的其他端口上启动 Driverless AI?
当在 Docker 中启动 Driverless AI 时,
-p选项指定了将运行 Driverless AI 的端口。如果您需要在 12345 端口以外的端口上运行,可在启动脚本中更改此选项。以下示例展示了如何在 22345 端口上运行。(如果需要,可将nvidia-docker run更改为docker-run. )请注意, 特权端口将需要根访问权限 。nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ -u `id -u`:`id -g` \ -p 22345:12345 \ -v `pwd`/data:/data \ -v `pwd`/log:/log \ -v `pwd`/license:/license \ -v `pwd`/tmp:/tmp \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx若要在 12345 端口以外的端口上运行,则在 config.toml 文件中更新端口值。以下示例展示了如何在 22345 端口上运行 Driverless AI。请注意,特权端口将需要根访问权限.
# Export the Driverless AI config.toml file (or add it to ~/.bashrc) export DRIVERLESS_AI_CONFIG_FILE=“/config/config.toml” # IP address and port for Driverless AI HTTP server. ip = "127.0.0.1" port = 22345重启 Driverless AI 时指向更新后的配置文件。
能否在 Driverless AI 上设置 TLS/SSL?
能,Driverless AI 提供了让您能设置 HTTPS/TLS/SSL 的配置选项。您需要有自己的 SSL 证书,或者您可自行创建自签名证书。
若要在 Driverless AI 服务器上启用 HTTPS/TLS/SSL,可将以下内容添加至 config.toml 文件中:
enable_https = true ssl_key_file = "/etc/dai/private_key.pem" ssl_crt_file = "/etc/dai/cert.pem"您可以使用以下命令创建自签名证书以进行测试:
umask 077 openssl req -x509 -newkey rsa:4096 -keyout private_key.pem -out cert.pem -days 20 -nodes -subj '/O=Driverless AI' sudo chown dai:dai cert.pem private_key.pem sudo mv cert.pem private_key.pem /etc/dai若需配置特定版本的 TLS/SSL,则在 config.toml 文件中启用或禁用以下设置:
ssl_no_sslv2 = true ssl_no_sslv3 = true ssl_no_tlsv1 = true ssl_no_tlsv1_1 = true ssl_no_tlsv1_2 = false ssl_no_tlsv1_3 = false
能否在 AWS 中的 Driverless AI 上设置 TLS/SSL?
能,您可以在 AWS 环境中运行的 Driverless AI 上设置 HTTPS/TLS/SSL。需要在主机中配置 HTTPS/TLS/SSL,并需要在 AWS 端开放必要的端口。您将需要有自己的 TLS/SSL 证书,或者您可自行创建自签名证书。
以下是一个非常简单的示例,展示了如何使用存放于 /etc/nginx/ 中的密钥将带有 proxy pass 指令的 HTTPS 配置至容器上的端口 12345。将 <server_name> 替换为您的服务器名称。
server { listen 80; return 301 https://$host$request_uri; } server { listen 443; # Specify your server name here server_name <server_name>; ssl_certificate /etc/nginx/cert.crt; ssl_certificate_key /etc/nginx/cert.key; ssl on; ssl_session_cache builtin:1000 shared:SSL:10m; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!eNULL:!EXPORT:!CAMELLIA:!DES:!MD5:!PSK:!RC4; ssl_prefer_server_ciphers on; access_log /var/log/nginx/dai.access.log; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; # Fix the “It appears that your reverse proxy set up is broken" error. proxy_pass http://localhost:12345; proxy_read_timeout 90; # Specify your server name for the redirect proxy_redirect http://localhost:12345 https://<server_name>; } }如需详细了解 Ubuntu 16.04 中 Nginx 的 SSL,请访问 https://www.digitalocean.com/community/tutorials/how-to-create-a-self-signed-ssl-certificate-for-nginx-in-ubuntu-16-04。
我在安装过程中收到了 “package dai-<version>.x86_64 does not verify: no digest” 的错误提示。我该如何解决此问题?
在安装 4.11.3 以上版本的 RPM 时,您将收到 “package dai-<version>.x86_64 does not verify: no digest” 的错误提示。您可以运行以下命令来解决这一问题,将
<version>替换为您的 DAI 版本。rpm --nodigest -i dai-<version>.x86_64.rpm
我收到了一条 “Must have exactly one OpenCL platform ‘NVIDIA CUDA’” 的错误提示。我该如何解决此问题?
如果您在使用服务器时遇到 opencl 错误的问题,则可能会看到以下消息:
2018-11-08 14:26:15,341 C: D:452.2GB M:246.0GB 21603 ERROR : Must have exactly one OpenCL platform 'NVIDIA CUDA', but got: Platform #0: Clover Platform #1: NVIDIA CUDA +-- Device #0: GeForce GTX 1080 Ti +-- Device #1: GeForce GTX 1080 Ti +-- Device #2: GeForce GTX 1080 Ti Uninstall all but 'NVIDIA CUDA' platform.对于 Ubuntu 而言,解决办法是执行以下命令:
sudo apt-get remove mesa-opencl-icd
是否有可能让多个用户共享一个 Driverless AI 实例?
Driverless AI 支持多用户使用,但 Driverless AI 许可证仅供单个具名用户使用。因此,为了让不同用户同时运行实验,每位用户均需要有许可证。Driverless AI 会管理为其分配的 GPU,并确保不同用户的不同实验可以安全地同时运行,且不会互相干扰。因此,当两个拥有许可证的用户使用不同凭据登录时,他们不会看到对方的实验。同样,如果一个拥有许可证的用户使用另一组凭据登录,则此用户将不会看到之前运行的任何实验。
能,您可以为一个 GPU 盒分配多个用户。例如,可以对一个装有四个 GPU 的盒子进行分配,让用户 1 使用两个 GPU,用户 2 使用另外两个 GPU。这可以通过使两个单独的 Driverless AI 实例在同一台服务器上运行来实现。
有两种方式可将特定 GPU 分配给 Driverless AI。在有四个 GPU(两个用户各分配到两个 GPU)的情况下,这两个选项均允许每个 Docker 容器仅能看到两个 GPU。
使用
CUDA_VISIBLE_DEVICES环境变量。就 Docker 部署而言,这将在传递-e CUDA_VISIBLE_DEVICES="0,1"的过程中,转译成nvidia-docker run命令。在
nvidia-docker run命令的开头传递NV_GPU选项。(请参阅以下示例。)#Team 1 NV_GPU='0,1' nvidia-docker run --pid=host --init --rm --shm-size=256m -u id -u:id -g -p port-to-team:12345 -e DRIVERLESS_AI_CONFIG_FILE="/config/config.toml" -v /data:/data -v /log:/log -v /license:/license -v /tmp:/tmp -v /config:/config h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx #Team 2 NV_GPU='0,1' nvidia-docker run --pid=host --init --rm --shm-size=256m -u id -u:id -g -p port-to-team:12345 -e DRIVERLESS_AI_CONFIG_FILE="/config/config.toml" -v /data:/data -v /log:/log -v /license:/license -v /tmp:/tmp -v /config:/config h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx但是请注意,Driverless AI 实例期望能充分利用且不共享各自分配到的 GPU。与其他 Driverless AI 实例或其他运行中的程序共享 GPU 可能会导致内存不足的问题。
如何获取 Driverless AI 用户列表?
使用 Python 客户端可获取用户列表。
h2o = Client(address='http://<client_url>:12345', username='<username>', password='<password>') h2o.get_users()
Driverless AI 启动失败,并在 Ubuntu 18/RHEL 7.6 上显示消息 ``Segmentation fault (core dumped)`` 。我该如何解决此问题?
此问题由
NotoColorEmoji.ttf字体引起,因为 Python matplotlib 库无法处理此字体。通过重命名来禁用此字体,即可解决此问题。(请勿使用 fontconfig,因为会被 matplotlib 忽略。)以下示例展示了应执行的命令。sudo find / -name "NotoColorEmoji.ttf" 2>/dev/null | xargs -I{} echo sudo mv {} {}.backup
Driverless AI 支持哪些 Linux 系统?
受支持的 Linux 系统包括 x86_64 RHEL 7、RHEL 8、CentOS 7 和 CentOS 8。
数据¶
数据集是否有文件大小限制?
对于 GBM,数据集的文件大小受限于系统上的 CPU 或 GPU 总内存,但我们将继续进行优化,以在实验中使用更多数据,例如使用 TensorFlow 串流来传输任意大小的数据集。
如何将使用 UTF-8 编码的 CSV 文件导入至 Excel?
Excel 需要字节顺序标记 (BOM) 以正确识别使用 UTF-8 编码的 CSV 文件。请参阅以下 常见问题解答条目 ,以进一步了解如何在写入带有数据表的 CSV 文件时使用 BOM。
在写入带有数据表的 CSV 文件时能否使用字节顺序标记?
能,启动 Driverless AI 时,在 config.toml 文件中启用
datatable_bom_csv,即可在写入带有数据表的 CSV 文件时使用字节顺序标记 (BOM)。请注意:要在 Excel 中支持 UTF-8 编码,需使用 BOM。
Driverless AI 支持哪个版本的 Longhorn?
Driverless AI 支持 v1.1.0 或更高版本的 Longhorn。
是否可能在 Driverless AI 中下载转换测试数据集?
可以,可以在 Driverless AI 中下载转换测试数据集。方法是,在完成的实验页面上点击 模型操作 > 转换数据集 ,然后指定要用于转换的训练和测试数据集。完成这个过程后,就可以下载转换测试数据集。
连接器¶
为什么在 Windows 上使用数据连接器时不能将文件夹导入为文件?
如果您尝试通过 Windows 上的数据连接器来使用 将文件夹导入为文件 ,若此文件夹包含没有文件扩展名的文件,则会导入失败。例如,如果文件夹包含 file1.csv、file2.csv、file3.csv 和 _SUCCESS 文件,则由于存在 _SUCCESS 文件,也将导入失败。
请注意,仅当数据源自通过
-v /path/to/windows/filesystem:/path/in/docker/container标记从 Windows 文件系统挂载至 Docker 容器的数据卷时,才会发生此种情况。由于 Windows 和 Docker 容器 (CentOS Linux) 处理无文件扩展名文件的方式不同,因此会出现此错误。
当我尝试选择 JDBC 连接时,收到了 ClassNotFoundException 的错误提示。我该如何解决此问题?
存储 JDBC jar 文件的文件夹必须可见/可由 dai 进程用户读取。
如果您从 Oracle 下载 JDBC jar 文件,他们可能会向您提供 tar.gz 文件,您可以使用以下命令解压:
tar --no-same-permissions --no-same-owner -xzvf <my-jdbc-driver.tar>.gz或者,您一般可通过运行以下命令来确保文件的权限设置正确:
chmod -R o+rx /path/to/folder_containing_jar_file最后,如果您只想检查权限,则使用
ls -altr命令,并检查权限输出的最后 3 个值。
当我尝试连接至 Hive 时,收到了 org.datanucleus.exceptions.NucleusUserException: Please check your CLASSPATH and plugin specification(org.datanucleus.exceptions.NucleusUserException:请检查您的 CLASSPATH 和插件规格)的错误提示。我该如何解决此问题?
请确保在
/etc/hive/conf中配置hive-site.xml,而不是在/etc/hadoop/conf中配置。
在 Hive 导入期间,我收到 “Permission Denied”(权限被拒绝)的错误提示。我该如何解决此问题?
如果您看到以下错误提示,由于文件系统权限限制,您的 Driverless AI 实例可能无法创建临时 Hive 文件夹。
ERROR HiveAgent: Error during execution of query: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied; org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied;要解决此问题,将以下名称-值对添加至您的
hive-site.xml文件中,以指定 Driverless AI 可访问的位置(即您的 Driverless AI/tmp目录)。<property> <name>hive.exec.local.scratchdir</name> <value>/path/to/dai/tmp</value> </property>
插件¶
可从何处获取 H2O 的自定义插件?
H2O 的自定义插件可从官方 Recipes for Driverless AI repository 获取。
如何创建自己的自定义插件?
请参阅 How to Write a Recipe 指南,详细了解如何创建自己的自定义插件。
使用自定义插件的实验是否支持 MOJO?
在大多数情况下,MOJO 都不适用于自定义插件。除非是简单的插件,否则仅在有额外的 MOJO 运行时支持时,方可创建 MOJO。请联系 support@h2o.ai,了解更多关于其自定义插件构建 MOJO 的信息。(请注意:Python 评分管道完全支持自定义插件。)
如何在隔离安装环境中使用 BYOR?
如果您的 Driverless AI 环境无法访问互联网,并且因此而不能从 GitHub 中访问 Driverless AI 的”自带插件”,请联系 `H2O 支持部门<support@h2o.ai>`__ 。我们可直接帮助您获取插件。
实验¶
Driverless AI 需要多少内存才能运行实验?
目前,Driverless AI 需要的系统内存大约为数据大小的 10 倍。
Driverless AI 可以处理多少列?
我们已使用具有 1 万列的数据集对 Driverless AI 进行过测试。当使用宽数据集运行实验时,Driverless AI 会自动检查内存是否不足,如果不足,则会减少特征数量,直至其能适应内存。这可能会导致出现较差的模型,Driverless AI 并不会因为宽数据集而崩溃。
如果我有大数据,应该如何使用 Driverless AI?
Driverless AI 可即时处理大数据集。对于非常大的数据集(超过 100 亿行 x 列),我们建议为 Driverless AI 进行数据抽样。请记住,Driverless AI 的目标是尝试多个特征和模型以找到最佳建模管道,而不是仅使用原始数据上训练一些模型(H2O-3 非常适用于这种情况)。
对于大数据集,建议执行以下步骤:
首先使用建议的准确度/时间/可解释性设置运行,特别是将准确度设置为小于或等于 7。
逐渐将准确度设置提高到 7,并仅在观测准确度小于或等于 7 时的运行情况后选择准确度 9 或 10。
Driverless AI 如何检测 ID 列?
ID 列的逻辑如下所示:
此列被明确命名为 ‘id’、’Id’、’ID’ 或 ‘iD’。
此列包含大量唯一值(超过 config.toml 文件中的
max_relative_cardinality或专家设置中的 整数和分类列所允许的唯一值最大分数)
Driverless AI 能否处理有缺失值/空值的数据?
能,导入至 Driverless AI 中的数据可能包含缺失值。特征工程完全能察觉到缺失值的存在,且缺失值将被作为信息处理 – 作为特殊的分类级别或作为特殊的数值。因此,对于目标编码,例如,具有某个缺失特征的行将属于同一组。在分类编码中,如果为分组的分类列计算数值列的聚合,则将保留缺失值。计算平均值的公式为:非缺失值的总和除以非缺失值的总数。对于聚类,我们将填充缺失值。对于频率编码,我们将对具有某个缺失特征的行进行计数。
插补策略如下所示:
XGBoost/LightGBM 不需要缺失值插补,事实上,使用任何特定的其他策略均可能使模型表现更差,除非用户对数据非常了解。
Driverless AI 会使用 GLM 平均值自动插补缺失值。
Driverless AI 在 config.toml 文件中为 TensorFlow 提供插补设置:
tf_nan_impute_value post-normalization. 如果您将此选项设置为 0,则将会插补缺失值。将其设置为(例如)+5 可指定分布之外的 5 个标准偏差。对于 TensorFlow,此选项默认设置为 -5,即指定 TensorFlow 将 NA 值作为缺失值。如果平均值更好,我们建议您将此选项指定为 0。更多信息,请参阅 缺失值和不可见值的处理 一节。
Driverless AI 如何处理分类变量?如果确实应将整数列作为分类列,那么应如何处理?
如果某列具有字符串值,则 Driverless AI 会将其作为分类特征。Driverless AI 可使用多种方法将分类变量转换为数值变量。这些方法包括:
独热编码:为每个值创建虚拟变量
频率编码:将类别替换为其在数据中出现的频率
目标编码:将类别替换为平均目标值(包括防止过度拟合的其他步骤)
证据权重:计算每个类别的证据权重:(http://ucanalytics.com/blogs/information-value-and-weight-of-evidencebanking-case/)
Driverless AI 将尝试多种表示列的方式并确定最佳表示形式。
如果此列具有整数,则 Driverless AI 会尝试将此列作为分类列和数值列。如果唯一值的数量少于 50,则会将任何整数列既作为分类列又作为数值列。
此选项可在 config.toml 文件中进行配置:
# Whether to treat some numerical features as categorical # For instance, sometimes an integer column may not represent a numerical feature but # represents different numerical codes instead. num_as_cat = true # Max number of unique values for integer/real columns to be treated as categoricals (test applies to first statistical_threshold_data_size_small rows only) max_int_as_cat_uniques = 50(请注意:Driverless AI 还将使用本福特定律检查任何数值列的分布与典型数值数据的分布之间是否存在显著差异。如果列的分布未遵循本福特定律,则即使有超过 50 个唯一值,我们仍将尝试将其作为分类列。)
如何处理异常值?
不会从数据中移除异常值。相反,Driverless AI 会寻找最佳的方式来表示具有异常值的数据。例如,Driverless AI 可能会发现对带有异常值的变量进行分箱可提高性能。
对于目标列,Driverless AI 首先会确定列的最佳表示形式。其可能会发现,对于带有异常值的目标列,最佳方式是预测此列的对数。
如果我从训练数据集中删除了几列,Driverless AI 是否会理解它需从测试数据集中删除相同的列?
如果您从训练数据集中删除几列,Driverless AI 将会从验证和测试数据集中删除相同的列(如果存在这些列)。由于不会从这些列中创建任何特征,因此无需使用。
Driverless AI 是否会将数值变量作为分类变量?
在某些情况下会。您可以通过将安装程序的 config.toml 文件中的
num_as_cat变量设置为false来防止这种行为。您还可以通过不使用安装程序的 config.toml 文件中的数值-分类目标编码转换器和数值-分类证据权值转换器及其相应的基因来更精细地控制此行为。请参阅 使用 config.toml 文件 一节,了解更多关于 config.toml 文件的信息。
Driverless AI 中使用哪些算法?
使用 Kaggle 中一系列专有的致胜统计方法特征进行处理,包括最为复杂的目标编码和基于分组、聚合和连接的似然估计,此外,我们还使用线性模型、神经网络、聚类和降维模型以及许多传统方法(例如独热编码)等。
除处理过的特征外,还会对复杂的模型进行拟合,包括但不限于:XGBoost(原始 XGBoost 和 ‘lossguide’ (LightGBM) 模式)、决策树、GLM、TensorFlow(包括基于 CNN 深度学习模型的 TensorFlow 自然语言处理插件)、RuleFit、FTR (Follow the Regularized Leader)、孤立森林和常量模型。(更多信息,请参阅 支持的算法. )其他算法可通过 Recipes 添加。
一般来说,GBM 是最佳的单发算法。自 2006 年以来,提升算法已被证明是用于图像和声音模式识别以外噪声预测建模任务的最准确算法 (https://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml06.pdf)。XGBoost 和 Kaggle 的出现仅仅是巩固了这一地位。
为什么我选择的算法未显示在实验预览中?
当通过 专家设置 > 模型 和 专家设置 > 插件 更改所使用的算法时,您可能会留意到,在实验预览中并未应用这些更改。Driverless AI 会根据这些专家设置的层次结构和数据类型(数值、分类、文本、图像等)和系统属性(GPU、多个 GPU 等)来确定是否包括某些模型和/或插件。
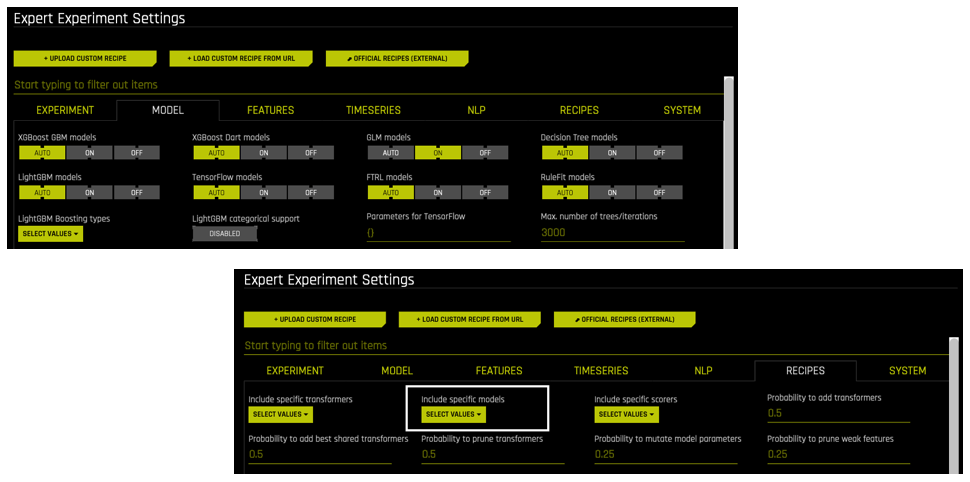
在专家设置中将某个算法设置为”关闭”:如果运行期间在专家设置中关闭某个算法(例如,GLM 模型),则不会在实验中使用此算法。
不包含在插件 (BYOR) 中的算法:如果在 包括特定模型 选项中没有为实验选择自定义插件中的某个算法,则将不会在实验中使用此算法,无论是否在 专家设置 > 模型 页面将此算法设置为自动或开启。
未被指定为 “关闭” 且包含在插件中的算法:如果某个 Driverless AI 算法被指定为 “自动” 或 “开启” ,并且在 包括特定模型 选项中为实验选择了其他模型,则可能会或可能不会在实验中使用这些算法。Driverless AI 将根据数据和实验类型确定要使用的算法。
若需在未使用模型的预览中显示警告,可在 config.toml 中设置
show_inapplicable_models_preview = true.
为什么我选择的转换器未显示在实验预览中?
当通过 专家设置 > 转换器 和 专家设置 > 插件 更改所使用的转换器时,您可能会留意到,在实验预览中并未应用这些更改。Driverless AI 会根据数据类型(数值、分类、文本、图像等)和系统属性(GPU、多个 GPU 等)来确定是否包括可使用的转换器。
不包含在插件 (BYOR) 中的转换器:如果在 包括特定模型 选项中没有为实验选择自定义插件中的某个转换器,则不会在实验中使用此转换器。
若需在未使用模型的预览中显示警告,可在 config.toml 中设置
show_inapplicable_transformers_preview = true.
如何开启 TensorFlow 神经网络以对其进行评估?
尽管默认情况下可能不会对神经网络进行评估,但是 Driverless AI 还是会考虑使用神经网络。若要确保会尝试使用神经网络,您可以在专家设置中开启 TensorFlow。

将 TensorFlow 设置为开启后。您应该能看到左侧的实验预览已发生变化并反映出将对 TensorFlow 模型进行评估。
如果您有一个多于 5 个唯一值的多项用例,我们建议使用 TensorFlow 神经网络。
Driverless AI 是否对数据进行标准化处理?
Driverless AI 将自动对某些算法实施变量标准化处理。例如,在使用线性模型和神经网络时,将自动对数据进行标准化处理。但是,对于决策树算法,由于这些算法并不能从标准化中受益,因此我们不会执行标准化。
XGBoost 中使用何种目标函数?
XGBoost 中使用的目标函数如下:
用于回归问题的
reg:squarederror和自定义绝对误差目标函数用于分类问题的
binary:logistic或multi:softprob目标函数不会因所选的评分器而更改。此评分器仅影响参数调优。对于回归问题,支持 Tweedie、Gamma 和泊松回归目标。
关于 XGBoost 实例化的更多信息,可在日志和模型摘要中找到,两者均可从 GUI 中下载或可在服务器的 /tmp/h2oai_experiment_<name>/ 文件夹中找到。
Driverless AI 是执行内部验证还是外部验证?
当仅提供训练数据时,Driverless AI 会执行内部验证。当提供训练和验证数据时,会执行外部验证。在任何一种情况下,验证数据均用于所有参数调优(模型和特征),而非仅用于特征选择。参数调优包括目标转换、模型选择、特征工程、特征选择、堆叠等。
具体而言:
内部验证(仅提供训练数据):
当数据接近于 i.i.d,或用于时间序列问题时,则为理想方式
内部验证保持用于参数调优,并将时间因果关系用于时间序列问题
根据准确度设置,将进行从单个保持拆分到 5 折交叉验证的全面分析
无需手动拆分训练数据
使用交叉验证通过训练数据训练最终模型
外部验证(提供训练和验证数据):
当数据中存在一些漂移,且验证集比训练数据能更好地模仿测试集数据时,则为理想方式
由于训练数据不用于参数调优,因此训练过程中不会浪费任何训练数据。
验证数据仅用于参数调优,并非为训练数据的一部分
无法执行交叉验证,因为我们明显不想对训练数据进行过度拟合
不允许用于时间序列问题(请参阅后续的“时间序列”常见问题解答部分)
提示:如果您想将训练数据和验证数据均用于参数调优(训练进程),只需将数据集连接在一起,并将它们均转换为用于“内部验证”方法的训练数据。
Driverless AI 如何防止过度拟合?
Driverless AI 会执行大量检查以防止过度拟合。例如,在某些转换过程中,Driverless AI 会使用交叉验证计算折外数据的平均值。Driverless AI 还会对所构建的每个模型执行早停,确保在其停止以改善保持数据时终止此模型。防止过度拟合的其他步骤包括在特征工程期间检查 i.i.d 和避免泄露。
以下博文更加详细地介绍了 Driverless AI 防止过度拟合的措施:https://www.h2o.ai/blog/driverless-ai-prevents-overfitting-leakage/。
Driverless AI 如何避免多重假设 (MH) 问题?
Driverless AI 使用可重复使用的保持技术的变体来解决多重假设问题。更多信息,请参阅 https://pdfs.semanticscholar.org/25fe/96591144f4af3d8f8f79c95b37f415e5bb75.pdf。
Driverless AI 如何对实验设置提出建议?
当您在数据集上运行实验时,Driverless AI 会自动对实验设置(准确度、时间和可解释性)提出建议。例如,Driverless AI 可能会根据您的数据建议以下参数:准确度 = 7,时间 = 3,可解释性 = 6。
Driverless AI 将根据数据集中的列数和行数自动对实验设置提出建议。数据较小时,建议使用这些设置以确保进行最佳处理。如果数据较小,Driverless AI 将建议使用这些设置,以防止过度拟合并确保利用整个数据集。
如果行数和列数均低于某个阈值,则:
将准确度提高到 8。
提高准确度以便进行交叉验证。(我们不希望由于内部验证而”丢弃”任何数据。)
将可解释性提高到 8。
可解释性设置越高,则最终模型中的特征数量就越少。
不允许使用更复杂的特征。
这可防止过度拟合。
将时间减小到 2。
为防止过度拟合,将减少特征工程迭代。
当我将可解释性和准确度设置为相同数值时,会发生什么?
就目前而言,可解释性控制着要创建哪些特征以及要保留哪些特征。(同样,如果可解释性超过 6,则将在 XGBoost GBM、XGBoost Dart、LightGBM 和决策树模型中使用单调性约束。)准确度指的是 Driverless AI 尝试将这些特征转变为最准确的模型的难易程度。
我能否指定在运行 Driverless AI 时需使用的 GPU 的数量?
运行实验时,专家设置让您能指定 Driverless AI 要使用的启动 GPU ID。您还可指定每个模型和每个实验要使用的最大 GPU 数量。更多信息,请参阅 专家设置 一节。
如何在 Driverless AI 中构建最简单的模型?
若需在 Driverless AI 构建最简单的模型,可设置以下实验设置:
将准确度设置为 1。请注意,由于将使用一个样本,因此可能会损害性能。如有必要,调整旋钮直至预览中显示无抽样。
将时间设置为 1。
将可解释性设置为 10。
接下来,配置以下专家设置:
关闭除 GLM 外的所有算法。
将 GLM 模型 设置为“开启” 。
将 集成级别 设置为 0。
将 选择回归问题的目标转换 设置为标识转换。
禁用 数据分布移位检测 。
禁用 目标编码 。
或者,您可以将 管道构建插件 设置为兼容模式。兼容模式会自动配置以下实验和专家设置:
可解释性 = 10(以避免复杂性。此设置将覆盖 GUI 或 Python 客户端的可解释性设置。)
enable_glm=’on’ (其余算法为 ‘关闭’ 状态,以避免复杂性并可与 MLI 支持的算法兼容。)
num_as_cat=true:将某些数值特征作为分类特征。例如,有时整数列可能不是表示数值特征,而是表示不同的数值代码。
fixed_ensemble_level=0:不使用任何集成(以避免复杂性)。
feature_brain_level=0:不使用任何特征大脑(以确保每次重启都完全相同)。
max_feature_interaction_depth=1:将交互深度设置为 1(无多特征交互,以避免复杂性)。
target_transformer=”identity”: 用于回归问题(以避免复杂性)。
check_distribution_shift=”off”: 不在训练、验证和测试数据之间使用分布移位来删除特征(如果不进行微调,会有一定风险)。
为什么实验突然变慢了?
由于主机系统发生了超出 Driverless AI 控制范围的变化,因此您的实验可能已经从使用 GPU 切换为使用 CPU。您可以使用以下任何方法来验证:
转至 Driverless AI 实验页面并点击实验右下方的“GPU 使用情况”选项卡,以检查 GPU 的使用情况。
在终端运行
nvidia-smi以查看是否有进程正以非预期的方式使用 GPU 资源(例如占用大量内存的进程)。检查之前的作业或其他任务是否占用了系统/GPU 内存,或者之前的作业是否仍在运行某些任务。
检查并禁用系统中 NVIDIA 驱动程序的自动更新(因为更新会干扰正在运行的实验)。
解决此类速度突然变慢问题的常用方法是重启:
如果使用 Docker,则重启 Docker
如果使用本机安装方式,则运行
pkill --signal 9 h2oai如果
nvidia-smi未按照预期运行(例如,在驱动程序更新后),则重启系统更多可能导致实验变慢的与 ML 相关的问题如下:
在内存不足的系统上选择高准确度设置
选择低可解释性设置(可能导致更多特征工程,因而可能会增加内存使用量)
使用具有很多列(多于 500 列)的数据集
当有多个目标类别(多于 5 个)时,使用 GBM 模型进行多类别分类
当我使用不同种子运行多个实验时,为什么会在实验列表页面上看到不同的评分、运行时和磁盘空间?
当使用除种子外的所有相同设置运行多个实验时,请知悉特征大脑级别大于 0 可能会导致模型、特征、时序和磁盘空间的变化。(默认值为 2。)通过在 专家设置 或在 config.toml 文件中将 特征大脑级别 设置为 0,可禁用这些变化。
此外,如果您为每个实验使用不同的种子,则由于搜索最佳特征和模型参数的遗传算法的随机性,每个实验都将有差异。只有当使用相同种子和特征大脑级别为 0 来设置 可再现 时,用户才能期望得到相同的结果。设置不同的种子后,模型、特征、时序和模型大小均可能发生变化,变化的约束范围由为实验做出的选择来设置。(即,准确度、时间、可解释性、专家设置等均会限制结果,因此不同种子可以在这些限制内更改结果。)
为什么最终模型的性能看起来比之前迭代中的性能差?
您需要记住几件事:
Driverless AI 会尽全力 估算 目前为止发现的最佳建模管道的 泛化性能 。
性能估算始终基于保持数据进行(对模型不可见的数据)。
如果未提供验证数据集,则将对训练数据进行内部拆分以创建*内部验证*保持数据(进行一次或多次或交叉验证,视*准确度*设置而定)。
如果未提供验证数据集,则对于准确度小于或等于 7 的情况,使用单次保持拆分,并且 “幸运” 或 “不幸运” 的拆分可能会使小数据集或具有高方差的数据集出现估算偏差。
如果提供了验证数据集,则所有性能估算均仅基于整个验证数据集进行(不受 准确度 设置影响)。
所报告的评分均根据基于自举法的统计方法得出,并带有表示估算不确定性范围的*误差线*。
最后一次迭代后,使用已处理过的最终特征集上训练*最佳*的最终模型。根据*准确度*设置,可使用交叉验证对泛化性能进行更准确的估算。而且,最终模型可能是由多个基本模型组成的堆叠式集成模型,这通常会提高性能。因此,在极少数情况下,性能估算方法中的差异可能会使最终模型的估算性能看似比之前迭代中的性能更差一些。(即,最终模型的估算评分明显低于最后一次迭代的评分,并且误差线没有重叠。)在这种情况下,最终模型性能估算极有可能会更准确,而由于 “幸运” 拆分,之前的估算会有偏差。若需确认这一点,您可以多次重复运行实验(无需设置可再现标记)。
如果您希望最大程度地减小最终模型性能看起来比之前迭代中的性能差的可能性,则可参考以下建议:
提高准确度设置
提供验证数据集
提供更多数据
如何在 Driverless AI 模型中找到可能会导致数据泄露的特征?
若需查找导致泄露的原始特征,请查看所下载的实验摘要中的 features_orig.txt。导致泄露的特征具有比较高的重要性。若要获得关于可能导致泄露的衍生特征的提示,请创建一个新实验,将刻度盘设置为 2/2/8,并使用所有特征和响应对数据运行新实验。然后分析模型变量重要性居前 1 - 2 位的特征。如果发生数据泄露,则它们很可能是造成泄露的主要原因。
如何查看测试数据的性能指标?
只要您在测试集中提供目标列,Driverless AI 就会在实验结束时显示针对测试集的最终模型性能的最佳估算结果。测试集绝不会用于参数调优(与 Kagglers 经常执行的操作不同),这纯粹是为了方便。当然,您仍然可以使用所选择的方法进行测试集预测并计算指标。
如何查看实验中所有可能用到的性能指标?
实验结束时,对于所提供的各个带有目标列的数据集,模型性能估算结果将记录在实验日志中。例如,对于测试集:
Final scores on test (external holdout) +/- stddev: GINI = 0.87794 +/- 0.035305 (more is better) MCC = 0.71124 +/- 0.043232 (more is better) F05 = 0.79175 +/- 0.04209 (more is better) F1 = 0.75823 +/- 0.038675 (more is better) F2 = 0.82752 +/- 0.03604 (more is better) ACCURACY = 0.91513 +/- 0.011975 (more is better) LOGLOSS = 0.28429 +/- 0.016682 (less is better) AUCPR = 0.79074 +/- 0.046223 (more is better) optimized: AUC = 0.93386 +/- 0.018856 (more is better)
如果我的训练/验证和测试数据集来自不同的分布,应如何处理?
一般来说,Driverless AI 使用训练数据来处理特征并训练模型,并使用验证数据来对所有参数进行调优。如果未提供外部验证数据,则训练数据将被用于创建内部保持数据。创建内部保持数据的方式取决于是否存在较强的时间依赖性,请参阅下文。如果数据没有明显的时间依赖性(例如,如果没有隐式或显式时间列),或者数据可以任意排序且不会影响结果(例如,通过测量结果预测花卉种类的鸢尾属植物数据集),以及如果测试数据集不同(例如,新花或仅大朵花),则由于模型显然不能进行泛化,在最终测试中将无法获得训练过程中度量的(内部或外部)验证方面的模型性能。
Driverless AI 是否能处理加权数据?
能。您可以选择使用非负观测值权重在训练(和验证)数据中提供额外的权重列。这有助于实现特定于域的效果,例如时间权重或类别权重的指数加权。Driverless AI 中的所有算法和指标均支持观测值权重,但请注意,估算的似然率可能会因此而产生偏差。
Driverless AI 如何处理加权数据的折叠分配?
目前,Driverless AI 在创建折叠的过程中不会考虑权重,但是您可以提供折叠列以强制执行您自己的分组,即将属于同一组的行放在一起(放在训练数据或验证数据中)。折叠列必须为分类列(整数列也可以),为每一行分配一个组 ID。(至少需要 5 个组,因为我们要执行多达 5 折的交叉验证。)
为什么我觉得将新特征添加至数据集中会降低模型性能?
您可能会留意到,在将一个或多个新特征添加至数据集后,Driverless AI 模型的性能会降低。在 Driverless AI 中,特征工程序列是相当随机的,并且如果您使用新列完全重启,则特征工程可能最终无法对原始特征执行相同操作。
从 Driverless AI v1.4.0 开始,您可以选择 从最后一个检查点重新开始 。这让您能够调用具有更多列的新数据集,并且 Driverless AI 将进行更多迭代以利用新列。
Driverless AI 如何处理二元分类实验的不平衡数据?
如果您有不平衡的数据,则二元不平衡模型可使用各种不平衡抽样方法来帮助提高评分。抽样期间,不平衡模型能够利用不平衡数据集的大部分(甚至是全部)正值,而常规模型会显著限制正值的总体规模。但是,不平衡模型需花费更多时间来进行预测,而且并不总是比常规模型更准确。如果数据不平衡,我们仍然建议您尝试使用不平衡模型,以查看评分是否比常规模型高。请注意,此信息仅适用于二元模型。
Driverless AI 中是如何计算特征重要性的?
对于 XGBoost 或 LightGBM 模型等大多数模型,Driverless AI 使用归一化的 information gain 计算特征重要性。其他的重要性估计有时用于某些模型。
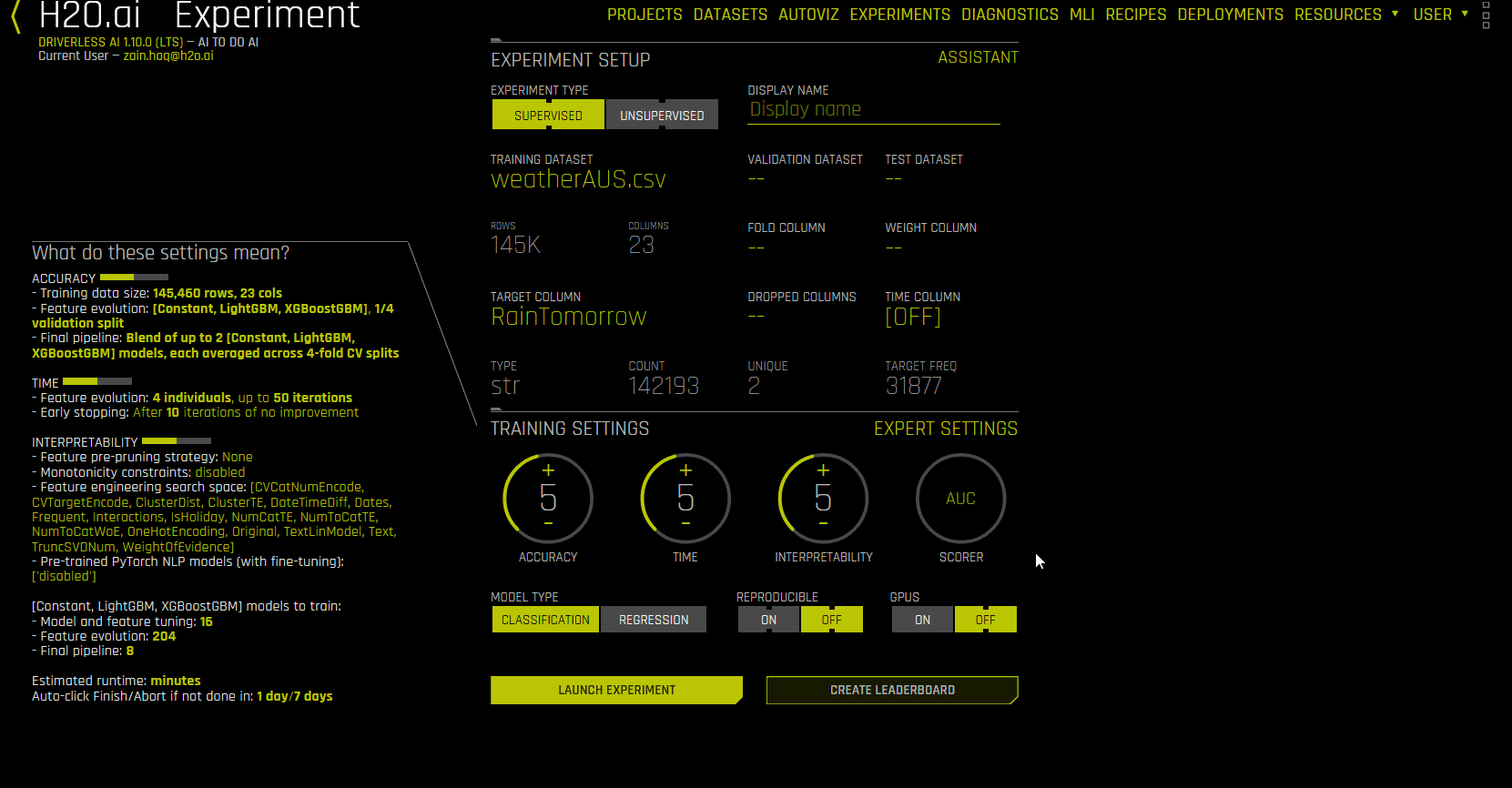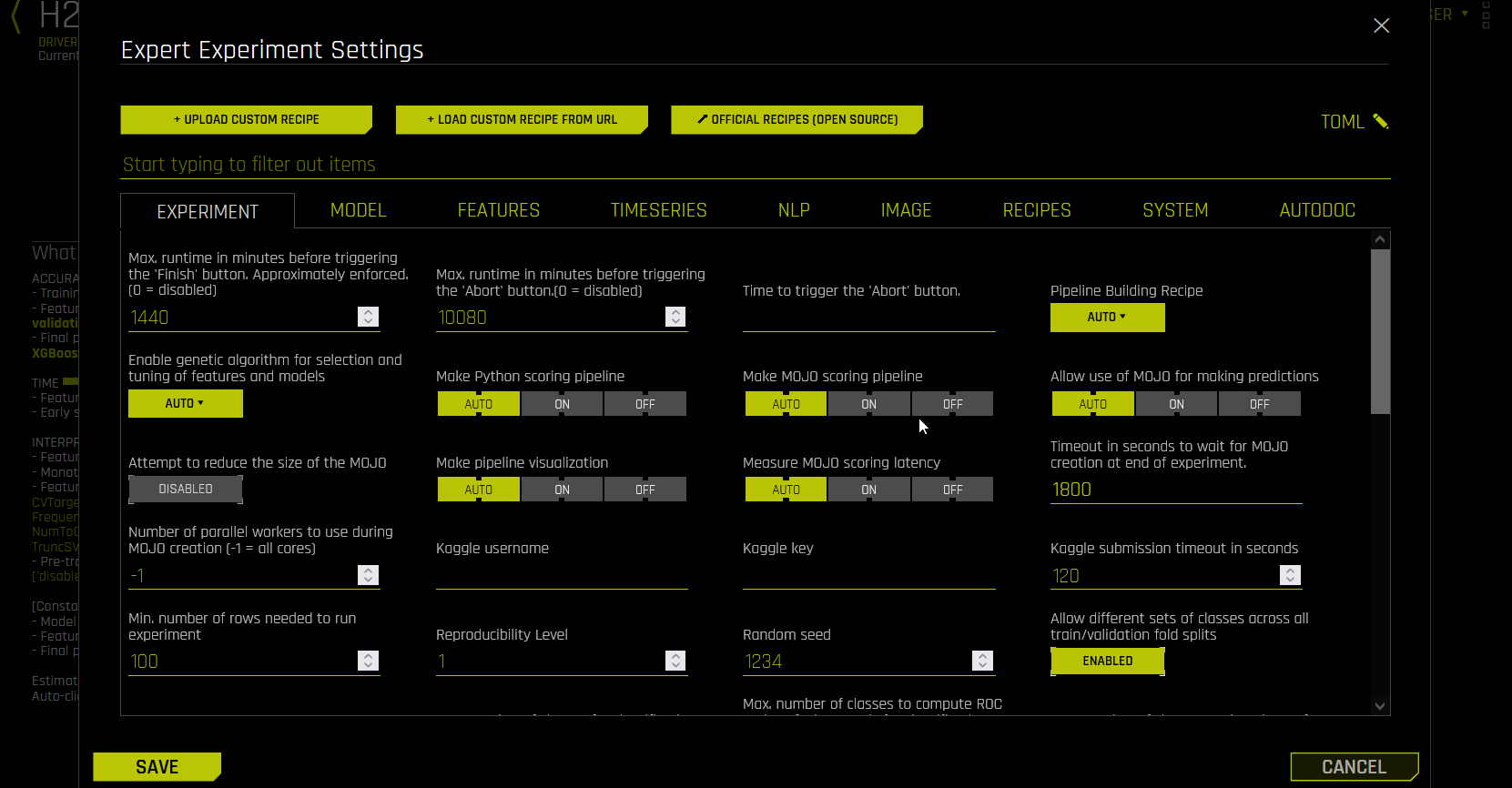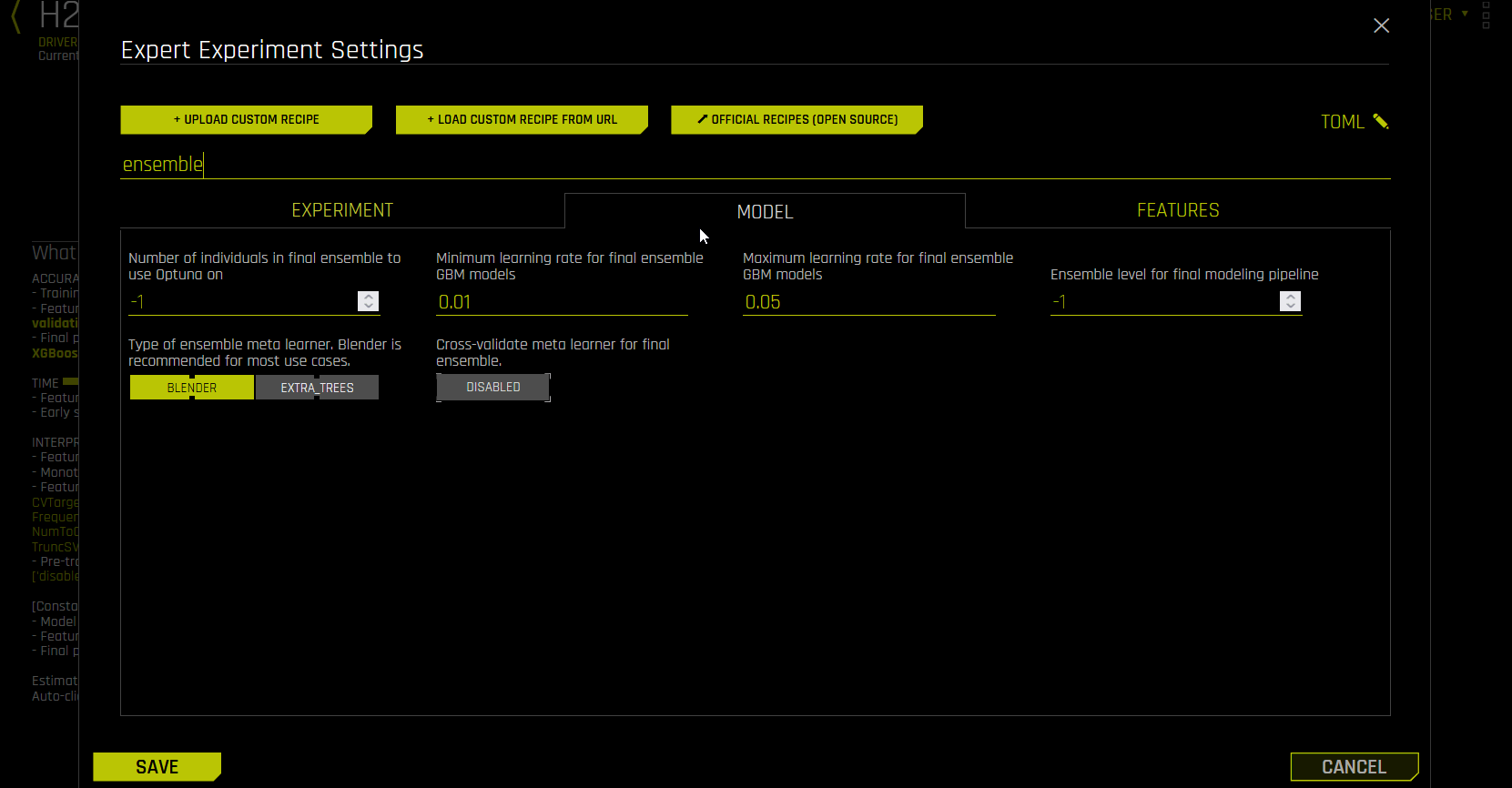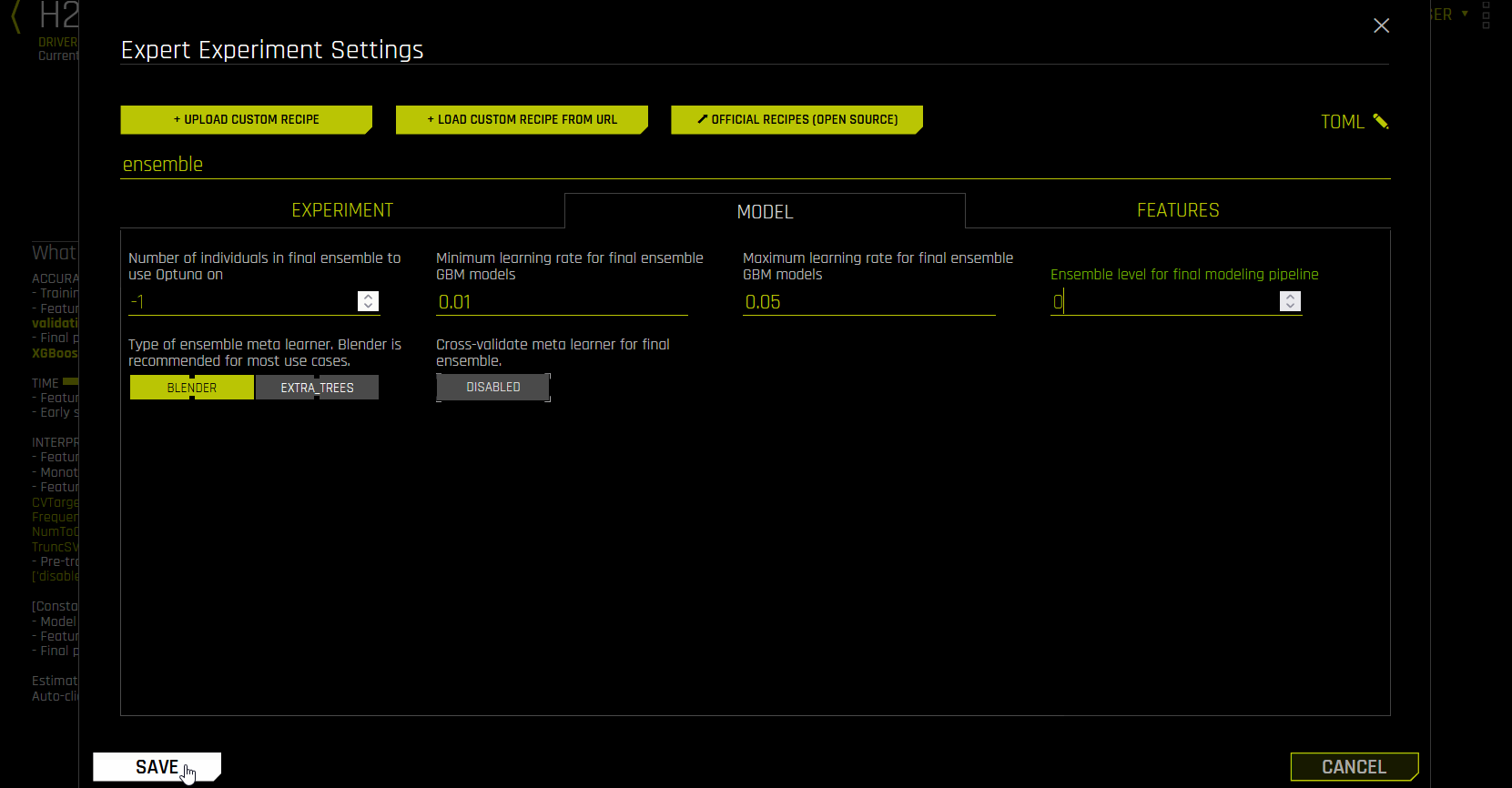
我想要最终管道中只有一个 LightGBM 模型。我怎样才能做到?
您可以使用 集成级别 做到这一点。要更改集成级别,使用位于 模型 选项卡中的 最终建模管道的集成级别 专家设置(config.toml 中的
fixed_ensemble_level)。如果您想要单个模型,使用级别 0。如果您可以使用具有超参数的相同模型,但又经过多个交叉验证折叠的训练,则使用级别 1。要仅使用一种模型类型,使用位于 插件 选项卡中的 包括特定模型 专家设置。
更多信息,请参阅 Driverless AI 中的集成学习.
注解
设置
fixed_ensemble_level = 0会返回经过 100% 数据训练的单个模型,而不仅仅是包含 CV 的单个模型类型。启用 交叉验证单个最终模型 专家设置时(默认),
fixed_ensemble_level = 0的单个模型具有最佳树数量,因为它使用 CV 进行了调优。当fixed_ensemble_level = 0时,不建议禁用此设置。
我只想要一个 LightGBM 模型,不要 FE。我怎样才能做到?
您可以通过额外将允许转换集仅限为 OriginalTransformer 来做到这一点,这会将数字特征保留为原始形式并删除所有非数值特征。要在您的 Driverless AI 环境中包括或排除特定转换器,使用位于 插件 选项卡中的 包括特定转换器 专家设置(config.toml 中的
included_transformers)。您还可以将 特征工程工作量 专家设置(config.toml 中的feature_engineering_effort)设置为零来实现这一效果。更多信息,请参阅 Driverless AI 转换.
在 Driverless AI 中,快速近似是什么?
快速近似可用于常规预测和 Shapley 预测。MLI/AutoDoc 默认启用此功能,其他客户端则默认关闭此功能。可使用快速近似专家设置全面配置近似范围和关闭快速近似。启用快速近似可以显著提高大型预测任务的速度,例如创建部分依赖性图和其他 MLI 相关任务。
注解
以下是可用于配置快速近似的专家设置列表。
常规预测 :
Shapley 预测 :
MLI :
何时应关闭快速近似?
当需要更详细的部分依赖图或解释时,您可能想要禁用快速近似。
特征转换¶
可从何处获得实验中执行的各种转换的详细信息?
从 GUI 中下载实验日志 .zip 文件。此 zip 文件包括摘要信息、日志信息和 gene_summary.txt 文件,其中含有实验中所用转换的详细信息。具体而言,有一个包含所有子进程日志的 详细信息 文件夹。
在服务器上,当实验完成后,会将实验特定文件放置于 /tmp/h2oai_experiment_<name>/ 文件夹中,特别是 h2oai_experiment_logs_<name>.zip 和 h2oai_experiment_summary_<name>.zip 。
预测¶
如何将预测结果下载到运行 Driverless AI 的计算机?
当您选择 对另一数据集进行评分 时,预测结果将自动存储到运行 Driverless AI 的计算机。结果将被保存在以下位置(并且可由 Driverless AI 再次打开,.csv 文件和 .bin 文件均可打开):
训练数据预测结果:tmp/h2oai_experiment_<name>/train_preds.csv`(同样保存为.bin` 文件)
测试数据预测结果:tmp/h2oai_experiment_<name>/test_preds.csv`(同样保存为.bin` 文件)
新数据预测结果:tmp/h2oai_experiment_<name>/automatically_generated_name.csv. 请注意,自动生成的名称将与下载至本地计算机的文件名称相匹配。
当我运行没有使用集成模型的实验时,为什么无法使用预测的概率?
当 Driverless AI 在完成实验后提供预计算的预测结果时,仅使用建模管道中未针对要进行预测的特定行训练的部分。这意味着 Driverless AI 需要保持数据以创建预测,例如验证或测试集,而仅使用训练数据训练模型。在使用集成模型的情况下,Driverless AI 会使用交叉验证以在训练数据上生成保持折叠,因此我们能为训练数据的每一行提供无折叠的估算,因而还可提供训练保持预测结果(这将提供泛化性能的良好估算)。但是,在使用单个模型的情况下,将使用整个训练数据进行训练。无法为训练数据中任何一行创建无偏差的估算。虽然 DAI 使用内部验证数据集,但这是一个可重复使用的保持数据集,因此不会包含完整训练数据集的保持预测结果。您需要进行交叉验证方可得到无折叠的估算结果,之后这将不再是单个模型。如果您仍然想要获得单个模型训练数据的预测结果,则必须使用评分 API 对训练集创建预测。在 GUI 中,可对已完成的实验使用 对另一数据集进行评分 按钮来实现。但是请注意,结果可能会过于乐观,因为太好而有失真实,但实际上毫无用处。
部署¶
MOJO 的大小由什么决定?
MOJO 的大小取决于最终建模管道(即,特征工程和模型)的复杂性。其中一个最大的因素是特征之间(特别是目标编码和相关特征之间)的高阶交互量,必须为训练数据中观测到的所有可能组合存储查找表。您可以通过在专家设置中减小 最大特征交互深度 和/或 特征工程工作量 的值或通过提高实验的可解释性设置来减少这些转换的数量。由于每个模型均有其自己的管道,因此 集成模型 还增加了最终建模管道的复杂性。降低准确度设置或将 ensemble level 设置为较小的数值。 最大管道特征数量 的数值也会影响 MOJO 的大小。文本转换器也相当庞大,并可能会增加 MOJO 的大小。
若要在模型构建过程中一键切换至较小的 mojo,请参阅实验的“实验设置”中的 Reduce mojo size.
MOJO 是不是线程安全的?
是的,所有 Driverless AI MOJO 均是线程安全的。
运行 MOJO 评分管道需要消耗数个小时。如何能加快运行速度?
运行 example.sh 时,Driverless AI 会实施内存设置,这适用于大部分用例。但是对于非常大的模型,在运行 Java 应用程序进行数据转换时可能需要增加内存限制。可使用
-Xmx25g参数来实现。例如:java -Xmx25g -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv
为什么会遇到 “Best Score is not finite” 的错误提示?
Driverless AI 默认使用 32 位浮点数。如果您的数据值超过 1E38 或者您的解析分辨率超过千万分之一,则可能会遇到此错误提示。您可以使用以下方法解决此错误:
在实验的专家设置中启用 强制使用 64 位精确度 选项。
或
在 config.toml 中设置
data_precision="float64"和transformer_precision="float64".
时间序列¶
如果数据具有时间依赖性,应如何处理?
如果您知道数据具有较强的时间依赖性,则在启动实验前选择一个时间列。时间列必须以 pandas 可解析的日期时间格式呈现,例如 “2017-11-06 14:32:21”、 “2012 年 6 月 18 日,星期一” 或 “2018 年 6 月 18 日 14:34:00” 等,或仅包含整数。
如果您不确定时间依赖性的强度,则运行两个实验:一个将时间列设置为 “[关闭]” ,另一个将时间列设置为 “[自动]” (或者自己选择一个时间列)。
什么是滞后,以及它为什么会有用?
滞后是前指一个时间点的特征值。滞后有助于利用当前(未知)目标值通常与之前(已知)目标值相关这一事实。因此,滞后可以更好地沿时间轴捕捉目标模式。
为什么不能为时间序列问题指定验证数据集?为什么要查看用于时间序列问题的测试集
时间序列设置中验证集与测试集的问题在于只有一种定义拆分的有效方式。如果给定一个测试集,则其时长可定义验证拆分,并且验证数据必须是训练数据的一部分。否则,时间序列验证将毫无用处。
例如:假设我们有训练数据 = [1,2,3,4,5,6,7,8,9,10] 和测试数据 = [12,13],其中由整数定义时间周期(例如,星期)。在此示例中,模拟测试方案的最自然训练/验证拆分方式为:训练数据 = [1,2,3,4,5,6,7] 和验证数据 = [9,10],而考虑到间隔,第 8 个月将不包含在训练集中。请注意,我们将只看测试集的开始时间和持续时间(如果提供),而不看测试数据的内容(特征和目标均不查看)。如果用户提供了验证数据 = [8,9,10],而不是测试数据,则可能导致较差的验证策略和较差的泛化效果。因此,我们仅使用用户给定的测试集来创建最优的内部训练/验证拆分。如果未提供测试集,则用户可提供测试集的长度(以周期为单位)、训练/测试数据间隔的长度(以周期为单位)和周期本身的长度(以秒为单位)。
为什么训练数据和测试数据之间的间隔很重要?是不是因为在测试集上创建了滞后特征?
为避免过于乐观地估计真实误差,以及避免为训练和验证数据创建基于历史的特征(例如滞后)(由于缺失信息,无法为测试数据创建这些特征),有必要考虑此间隔。
关于将目标滞后应用于时间组列的不同子集,是否是指 Driverless AI 在各种时间序列”级别 “执行自相关?例如,对于沃尔玛数据集,其中包含门店和部门的数据(我的目标是周销量)。是否是指 Driverless AI 仅根据门店、仅根据部门以及根据门店和部门来检查周销售量的自相关性?
目前,自相关在最开始就仅应用于训练数据集关系中检测到的超键(整个 TGC)。它用于对潜在的滞后阶数进行排名,旨在为负责选择滞后特征的 GA 优化进程缩小搜索空间。
Driveless AI 如何检测时间周期?
Driverless AI 将每个时间序列视作频率为 1/ns 的函数。实际值通过最大长度 TGC 子组的时间间隔中位数来进行估算。所选的 SI 单位可最大程度地减小与所有可用的 SI 单位之间的间隔。
预测期长度的可选数值背后的逻辑是什么?
所示预测期选项基于有效拆分的分位数。由于 Driverless AI 通常无法显示所有可能的选项,因此十分有必要进行此操作。
假设在我的沃尔玛数据集中,所有门店均按周提供数据,但是有一家门店按天提供数据。Driverless AI 会如何处理?
在这种情况下,Driverless AI 仍然会假设使用 “每周数据” ,因为大多数门店都具有此属性。 “每天提供数据的” 门店将根据检测到的总体频率进行重新抽样。
假设在我的沃尔玛数据集中,所有门店和部门均按周提供数据,但是特定门店的某个部门两周提供一次周销量数据。Driverless AI 会如何处理?
这类似于缺失数据。由于会进行适当的重新抽样,Driverless AI 能够很好地处理,而不用担心会有什么问题。
为什么要进行预测的周数很重要?
如果没有可用的测试数据,此选项可提供训练-测试间隔。也就是说, “我还没有测试数据,但是我知道它与 x 的训练数据之间会有间隔。”
时间序列的评分组件是否对新数据的先后顺序较为敏感?即,评分时每行是否会单独评分,或评分时是否有实时窗口效应?
评分时会对每行进行独立评分。
如果用户在预测时为某一行赋予过小或过大的时间值,将会发生什么?
内部将使用特殊值对”超出范围”的时间值进行编码。虽然仍会对样本进行评分,但是预测结果并不可信。
时间序列插件的最小数据大小为多少?
我们建议您要有大约 10,000 个验证样本,以获得对真实误差的可靠估计。时间序列插件仍可应用于较小的数据,但是验证误差可能不准确。
必须对训练数据和测试数据进行多长时间的比较?
最起码,在时间轴上,训练数据必须至少是测试数据的两倍长。但是,我们建议训练数据至少为测试数据的三倍长。
时间序列插件如何处理缺失值?
缺失值将被转换为特殊值,这不同于任何非缺失特征值。不会应用显式插补方法。
能否将时间信息分布到输入数据的多个列中(例如 [年、日、月])?
目前,Driverless AI 要求数据在单个列中给定时间戳。如果被证明有用,则 Driverless AI 将自行创建其他时间特征,例如 [年、日、月]。
Driverless AI 为时间序列实验使用何种类型的建模方式?
Driverless AI 将基于历史的特征(例如滞后、移动平均值等)的创建与建模技术结合在一起,这同样适用于 i.i.d 数据。所选择的主模型是 XGBoost。
指数加权移动平均的概念是什么?
指数加权说明了一种可能性,即较新的观测值比以前的观测值更适合用于解释当前状况。
日志记录¶
如何缩减审计日志记录器的大小?
使用 Driverless AI 期间,每天都会创建一个审核日志记录器文件。
audit_log_retention_period配置变量让您能指定天数,在该天数之后将覆盖之前的 audit.log。此选项默认设置为 5 天,这意味着 Driverless AI 将保留最近 5 天的审核日志记录器文件,超过 5 天的 audit.log 文件将被移除并替换为更新的日志文件。当此选项设置为0时,audit.log 文件将不会被覆盖。