Image Processing in Driverless AI
Image processing in Driverless AI is a powerful tool that can be used to gain insight from digital images. The following sections describe Driverless AI’s image processing capabilities.
Uploading Image dataset to Driverless AI
Image Transformer: Use image transformers when a dataset contains both images and other feature types.
Image Model: Use an Image model when the only feature in the dataset is an image.
Deploying an Image Model to Production
참고
For detailed per-tab Expert Settings, see Training Settings, Experiment Documentation Settings, System Settings, and Extra Settings.
참고
Image models from Driverless AI version 1.9.x aren’t supported in 1.10.x.
Image and NLP use cases in Driverless AI benefit significantly from GPU usage. For more information, see GPU usage in DAI.
You can share image datasets to H2O Storage (remote storage). For more information, see H2O Storage (remote storage) integration.
Supported File Types for Image processing
The following is a list of supported file types for image processing in Driverless AI:
Windows bitmaps - .bmp
JPEG files - .jpeg, .jpg, .jpe
JPEG 2000 files - .jp2
Portable Network Graphics - .png
WebP - .webp
Portable image format - .pbm, .pgm, .ppm, .pnm
TIFF files - .tiff, .tif
OpenEXR Image files - .exr
Radiance HDR - .hdr
Due to browser restrictions, images may not render for some formats (like .ppm, .tiff, .pnm and .exr) when viewing dataset rows from the GUI. These Images are still compatible with Driverless AI and will appear in the Insights column if DAI has insights to provide for them.
Ideally Driverless AI can support all OpenCV Image formats.
Uploading Data for Image Processing
Driverless AI supports multiple methods for uploading image datasets:
Archive with images in directories for each class. Labels for each class are automatically created based on directory hierarchy
Archive with images and a CSV file that contains at least one column with image names and a target column (best method for regression). Note that each image name must include the correct file extension.
CSV file with local paths to the images on the disk
CSV file with remote URLs to the images
Modeling Images
Driverless AI features two different approaches to modeling images.
Embeddings V2 Transformer (Image VectorizerV2)
The ImageVectorizerV2 transformer utilizes Pytorch pre-trained HuggingFace models to convert a column with an image path or URI to an embeddings (vector) representation that is derived from the last linear layer of the model. The resulting vector is then used for modeling in Driverless AI.
There are several options in the Expert Settings panel that let you configure the Image VectorizerV2 transformer. This panel is available from within the Experiments page above the Scorer knob. For more information on expert settings in DAI, refer to Understanding Expert Settings.
Notes:
This modeling approach supports classification and regression experiments.
This modeling approach supports the use of mixed data types (any number of image columns, text columns, numeric or categorical columns)
The Image VectorizerV2 transformer can also be enabled with the Pipeline Building Recipe expert setting, which is located in the Experiments tab.
Embeddings Transformer (Image Vectorizer)
The Image Vectorizer transformer utilizes TensorFlow pre-trained ImageNet models to convert a column with an image path or URI to an embeddings (vector) representation that is derived from the last global average pooling layer of the model. The resulting vector is then used for modeling in Driverless AI.
There are several options in the Expert Settings panel that let you configure the Image Vectorizer transformer. This panel is available from within the experiment page above the Scorer knob. For more information on expert settings in DAI, refer to Understanding Expert Settings.
Notes:
This modeling approach supports classification and regression experiments.
This modeling approach supports the use of mixed data types (any number of image columns, text columns, numeric or categorical columns)
The Image Vectorizer transformer can also be enabled with the Pipeline Building Recipe expert setting, which is located in the Experiment tab.
The Image Vectorizer transformer was deprecated in 2.3.0 version and will be removed in a future release.
Automatic Image Model
Automatic Image Model is an AutoML model that accepts only an image and a label as input features. This model automatically selects hyperparameters such as learning rate, optimizer, batch size, and image input size. It also automates the training process by selecting the number of epochs, cropping strategy, augmentations, and learning rate scheduler.
Automatic Image Model uses TensorFlow ImageNet models and starts the training process from them. The possible architectures list includes all the well-known models: (SE)-ResNe(X)ts; DenseNets; EfficientNets; etc.
Unique insights that provide information and sample images for the current best individual model are available for Automatic Image Model. To view these insights, click on the Insights option while an experiment is running or after an experiment is complete. Refer to ImageAuto Model Insights for more information.
Each individual model score (together with the neural network architecture name) is available in the Iteration Data panel. The last point in the Iteration Data is always called ENSEMBLE. This indicates that the final model ensembles multiple individual models.
Enabling Automatic Image Model
To enable Automatic Image Model, navigate to the pipeline-building-recipe expert setting and select the image_model option:
After confirming your selection, click Save. The experiment preview section updates to include information about Automatic Image Model:
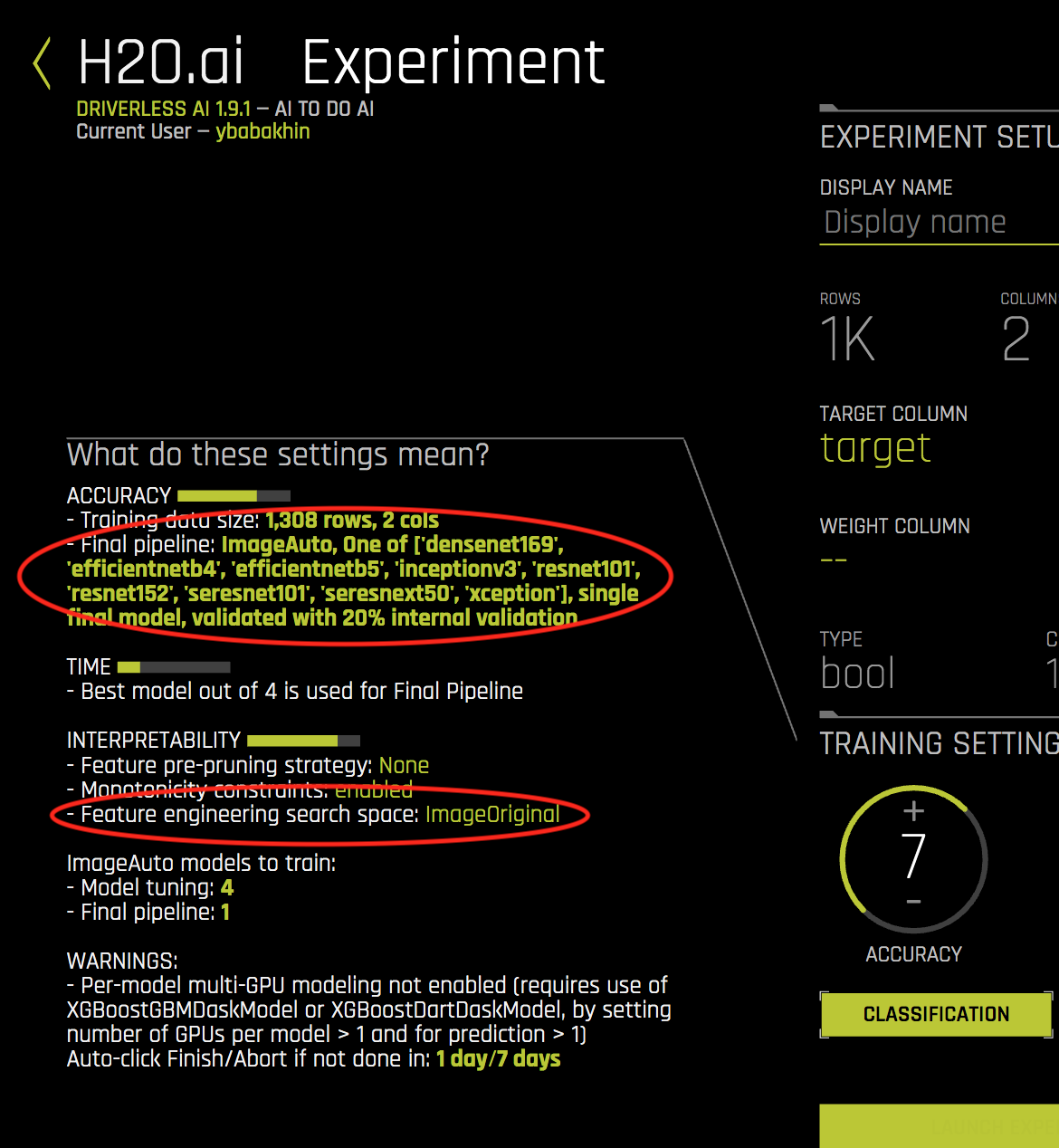
Notes:
This modeling approach only supports a single image column as an input.
This modeling approach does not support any transformers.
This modeling approach supports classification and regression experiments.
This modeling approach does not support the use of mixed data types because of its limitation on input features.
This modeling approach does not use Genetic Algorithm (GA).
The use of one or more GPUs is strongly recommended for this modeling approach.
If an internet connection is available, ImageNet pretrained weights are downloaded automatically. If an internet connection is not available, weights must be downloaded from http://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/pretrained/dai_image_models_1_11.zip and extracted into
tensorflow_image_pretrained_models_dir(./pretrained/image/by default).If extensively running image models with Driverless AI Docker install, we recommend setting
--shm-size=4g.
Deploying an Image Model
Python scoring and C++ MOJO scoring are both supported for the Image Vectorizer Transformer. Currently, only Python scoring is supported for image models.