Google Big Query Setup¶
Driverless AI allows you to explore Google BigQuery data sources from within the Driverless AI application. This section provides instructions for configuring Driverless AI to work with Google BigQuery. This setup requires you to enable authentication. If you enable GCS or GBP connectors, those file systems will be available in the UI, but you will not be able to use those connectors without authentication.
In order to enable the GBQ data connector with authentication, you must:
Obtain a JSON authentication file from GCP.
Mount the JSON file to the Docker instance.
Specify the path to the /json_auth_file.json in the gcs_path_to_service_account_json configuration option.
Note: The account JSON includes authentications as provided by the system administrator. You can be provided a JSON file that contains both Google Cloud Storage and Google BigQuery authentications, just one or the other, or none at all.
Google BigQuery with Authentication¶
This example enables the GBQ data connector with authentication by passing the JSON authentication file. This assumes that the JSON file contains Google BigQuery authentications.
Export the Driverless AI config.toml file or add it to ~/.bashrc. For example:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
Specify the following configuration options in the config.toml file.
# File System Support # upload : standard upload feature # file : local file system/server file system # hdfs : Hadoop file system, remember to configure the HDFS config folder path and keytab below # dtap : Blue Data Tap file system, remember to configure the DTap section below # s3 : Amazon S3, optionally configure secret and access key below # gcs: Google Cloud Storage, remember to configure gcs_path_to_service_account_json below # gbq: Google Big Query, remember to configure gcs_path_to_service_account_json below # minio: Minio Cloud Storage, remember to configure secret and access key below # snow: Snowflake Data Warehouse, remember to configure Snowflake credentials below (account name, username, password) # kdb: KDB+ Time Series Database, remember to configure KDB credentials below (hostname and port, optionally: username, password, classpath, and jvm_args) # azrbs: Azure Blob Storage, remember to configure Azure credentials below (account name, account key) # jdbc: JDBC Connector, remember to configure JDBC below. (jdbc_app_configs) # hive: Hive Connector, remember to configure Hive below. (hive_app_configs) # recipe_url: load custom recipe from URL # recipe_file: load custom recipe from local file system enabled_file_systems = "file, gbq" # GCS Connector credentials # example (suggested) -- "/licenses/my_service_account_json.json" gcs_path_to_service_account_json = "/service_account_json.json"
Save the changes when you are done, then stop/restart Driverless AI.
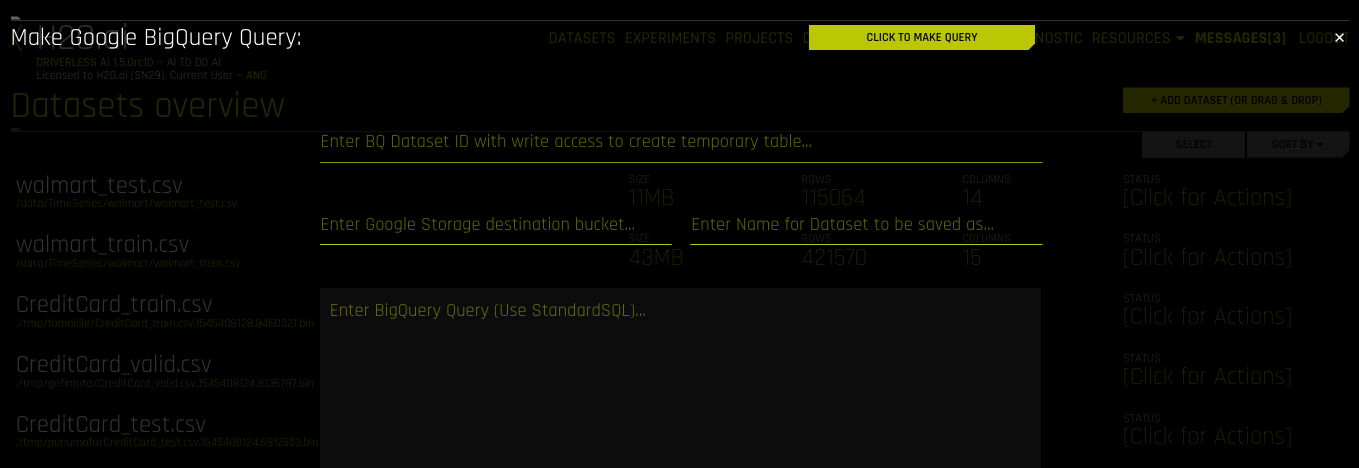
After Google BigQuery is enabled, you can add datasets by selecting Google Big Query from the Add Dataset (or Drag and Drop) drop-down menu.

Specify the following information to add your dataset.
Enter BQ Dataset ID with write access to create temporary table: Enter a dataset ID in Google BigQuery that this user has read/write access to. BigQuery uses this dataset as the location for the new table generated by the query.
Note: Driverless AI’s connection to GBQ will inherit the top-level directory from the service JSON file. So if a dataset named “my-dataset” is in a top-level directory named “dai-gbq”, then the value for the dataset ID input field would be “my-dataset” and not “dai-gbq:my-dataset”.
Enter Google Storage destination bucket: Specify the name of Google Cloud Storage destination bucket. Note that the user must have write access to this bucket.
Enter Name for Dataset to be saved as: Specify a name for the dataset, for example,
my_file.Enter BigQuery Query (Use StandardSQL): Enter a StandardSQL query that you want BigQuery to execute. For example:
SELECT * FROM <my_dataset>.<my_table>.When you are finished, select the Click to Make Query button to add the dataset.