Driverless AI - 训练时间序列模型¶
本 notebook 旨在展示一个使用 Driverless AI 训练时间序列模型的示例。示例中的目标是预测某一门店和部门在下周的销量。本 notebook 中使用的数据来源于:Walmart Kaggle Competition ,其中 features.csv 和 train.csv 被结合在一起。
点击此处,获取 Python 客户端文档资料 。
工作流¶
将数据导入 Python
格式化时间序列数据
将数据上传到 Driverless AI
启动 Driverless AI 实验
评估模型性能
[1]:
import pandas as pd
import driverlessai
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
第 1 步:导入数据¶
我们从使用 Pandas 导入我们的数据开始。首先在 Python 中处理数据,从而为 Driverless AI 时间序列用例正确格式化这些数据。
[3]:
sales_data = pd.read_csv('./walmart.csv')
sales_data.head()
[3]:
| Unnamed: 0 | Store | Date | IsHoliday | Dept | Weekly_Sales | Temperature | Fuel_Price | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | CPI | Unemployment | Type | Size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2010-02-05 | False | 1.0 | 24924.50 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 1 | 2 | 1 | 2010-02-05 | False | 26.0 | 11737.12 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 2 | 3 | 1 | 2010-02-05 | False | 17.0 | 13223.76 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 3 | 4 | 1 | 2010-02-05 | False | 45.0 | 37.44 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 4 | 5 | 1 | 2010-02-05 | False | 28.0 | 1085.29 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
[4]:
# Convert Date column to datetime
sales_data["Date"] = pd.to_datetime(sales_data["Date"], format="%Y-%m-%d")
sales_data.head()
[4]:
| Unnamed: 0 | Store | Date | IsHoliday | Dept | Weekly_Sales | Temperature | Fuel_Price | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | CPI | Unemployment | Type | Size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2010-02-05 | False | 1.0 | 24924.50 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 1 | 2 | 1 | 2010-02-05 | False | 26.0 | 11737.12 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 2 | 3 | 1 | 2010-02-05 | False | 17.0 | 13223.76 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 3 | 4 | 1 | 2010-02-05 | False | 45.0 | 37.44 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
| 4 | 5 | 1 | 2010-02-05 | False | 28.0 | 1085.29 | 42.31 | 2.572 | NaN | NaN | NaN | NaN | NaN | 211.096358 | 8.106 | A | 151315 |
第 2 步:格式化时间序列数据¶
在这些数据中,每个门店、部门和每周各有一条记录。对于此用例,我们的目标是预测下周的总销量。
我们应用作预测因子的唯一特征是我们在评分时可以使用的特征。温度、燃油价格和失业率等特征并不能提前知晓。因此,在我们开始 Driverless AI 实验之前,将选择使用上一周的温度、燃油价格、失业率和 CPI 属性。这些是我们在评分时会知道的信息。
[5]:
lag_variables = ["Temperature", "Fuel_Price", "CPI", "Unemployment"]
dai_data = sales_data.set_index(["Date", "Store", "Dept"])
lagged_data = dai_data.loc[:, lag_variables].groupby(level=["Store", "Dept"]).shift(1)
[6]:
# Join lagged predictor variables to training data
dai_data = dai_data.join(lagged_data.rename(columns=lambda x: x +"_lag"))
[7]:
# Drop original predictor variables - we do not want to use these in the model
dai_data = dai_data.drop(lagged_data, axis=1)
dai_data = dai_data.reset_index()
[8]:
dai_data.head()
[8]:
| Date | Store | Dept | Unnamed: 0 | IsHoliday | Weekly_Sales | MarkDown1 | MarkDown2 | MarkDown3 | MarkDown4 | MarkDown5 | Type | Size | Temperature_lag | Fuel_Price_lag | CPI_lag | Unemployment_lag | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2010-02-05 | 1 | 1.0 | 1 | False | 24924.50 | NaN | NaN | NaN | NaN | NaN | A | 151315 | NaN | NaN | NaN | NaN |
| 1 | 2010-02-05 | 1 | 26.0 | 2 | False | 11737.12 | NaN | NaN | NaN | NaN | NaN | A | 151315 | NaN | NaN | NaN | NaN |
| 2 | 2010-02-05 | 1 | 17.0 | 3 | False | 13223.76 | NaN | NaN | NaN | NaN | NaN | A | 151315 | NaN | NaN | NaN | NaN |
| 3 | 2010-02-05 | 1 | 45.0 | 4 | False | 37.44 | NaN | NaN | NaN | NaN | NaN | A | 151315 | NaN | NaN | NaN | NaN |
| 4 | 2010-02-05 | 1 | 28.0 | 5 | False | 1085.29 | NaN | NaN | NaN | NaN | NaN | A | 151315 | NaN | NaN | NaN | NaN |
正确格式化训练数据后,即可运行 Driverless AI 实验,预测下一周的销量。
第 3 步:将数据上传到 Driverless AI¶
我们会将数据拆分成两部分:训练数据和测试数据(这些数据包括上一周的数据)。
[13]:
train_data = dai_data.loc[dai_data["Date"] < "2012-09-28"]
test_data = dai_data.loc[dai_data["Date"] == "2012-09-28"]
为了上传数据集,我们将登录 Driverless AI。
[14]:
address = 'http://ip_where_driverless_is_running:12345'
username = 'username'
password = 'password'
dai = driverlessai.Client(address = address, username = username, password = password)
# make sure to use the same user name and password when signing in through the GUI
[19]:
train_path = "./train_data.csv"
test_path = "./test_data.csv"
[20]:
train_data.to_csv(train_path, index = False)
test_data.to_csv(test_path, index = False)
[21]:
# Add datasets to Driverless AI
train_data = dai.datasets.create(
data=train_path,
data_source='upload',
name='walmart-example-train'
)
test_data = dai.datasets.create(
data=test_path,
data_source='upload',
name='walmart-example-test'
)
Complete 100.00% - [4/4] Computing column statistics
Complete 100.00% - [4/4] Computing column statistics
Driverless 中的等效步骤:上传训练和测试 CSV 文件¶
第 4 步:启动 Driverless AI 实验¶
现在我们可以启动 Driverless AI 实验。为此,我们需要为实验指定参数。其中部分参数包括:
目标列:我们将尝试预测的列。
删除列:我们不想用作预测因子的列,例如 ID 列、存在数据泄露的列等。
是时间序列:实验是否为时间序列用例。
时间列:包含日期/日期时间信息的列。
时间分组列:指示如何对数据进行分组以便每个分组都有一个时间序列的分类属性列。在我们的实例中,“时间分组列”为
Store和Dept。每个Store和Dept对应于一个时间序列。预测期数:我们想预测未来多长时间内的指标?
间隔期数:在多少个周期后我们可以开始预测?如果我们假设可以在训练数据结束后开始预测,则“间隔期数”为 0。
对于此实验,我们想预测每个 Store 和 Dept 的下一周销量。因此,我们将使用以下时间序列参数:
时间分组列:
[Store, Dept]预测期数:1 (也称为范围)
间隔期数:0
注意 Python 客户端并不知道周期大小。为了克服这一问题,您也可以指定可选的 time_period_in_seconds 参数,此参数能帮助以实时单位指定预测期。如果省略此参数,Driverless AI 将自动检测实验中的周期大小,并且范围值会与此周期相等,也就是说,如果您确定数据周期为 1 周,则您可以表示为 num_prediction_periods=14,否则模型有可能不能正确计算出工作。
[22]:
experiment = dai.experiments.create(name='walmart_time_series',
test_dataset=test_data,
train_dataset=train_data,
task='regression',
target_column='Weekly_Sales',
drop_columns=['sample_weight'],
time_column= 'Date',
scorer='RMSE',
accuracy=5,
time=3,
interpretability=5,
num_prediction_periods=1,
num_gap_periods=0,
time_groups_columns = ['Store', 'Dept'],
seed=1234)
Experiment launched at: http://localhost:12345/#experiment?key=9f376088-408b-11eb-b9de-0242ac110002
Complete 100.00% - Status: Complete
Driverless AI 中的等效步骤:启动 Driverless AI 实验¶
第 5 步:评估模型性能¶
我们的实验完成后,我们可以查看实验对象内的模型性能指标。
[23]:
metrics = experiment.metrics()
print("Validation RMSE: ${:,.0f}".format(metrics['val_score']))
print("Test RMSE: ${:,.0f}".format(metrics['test_score']))
Validation RMSE: $2,425
Test RMSE: $2,084
我们也可以根据测试数据绘制实际值-预测值对比图。
[25]:
target="Weekly_Sales"
prediction = experiment.predict(test_data, [target])
path = prediction.download('')
forecast_predictions = pd.read_csv(path)
forecast_predictions.head()
Complete
Downloaded '9f376088-408b-11eb-b9de-0242ac110002_preds_f6e2264e.csv'
[25]:
| Weekly_Sales | Weekly_Sales.predicted | |
|---|---|---|
| 0 | 14734.64 | 12660.375000 |
| 1 | 1163.75 | 1384.219238 |
| 2 | 1773.32 | 1579.065430 |
| 3 | 27205.40 | 29764.876953 |
| 4 | 4390.19 | 4197.859863 |
[26]:
plt.scatter(forecast_predictions['Weekly_Sales.predicted'], forecast_predictions['Weekly_Sales'])
plt.plot([0, max(forecast_predictions['Weekly_Sales.predicted'])],[0, max(forecast_predictions['Weekly_Sales'])], 'b--',)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
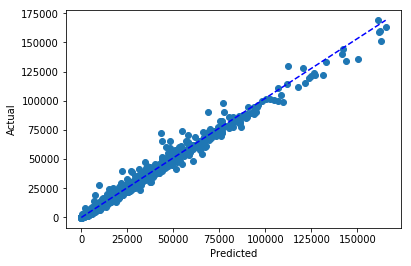
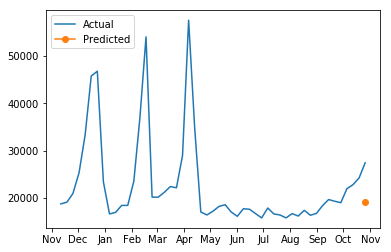
最后,我们可以通过 Driverless AI 下载测试预测结果,并针对所选门店和部门对比实际销量与预测销量。
[28]:
test_data = pd.read_csv('./test_data.csv')
selected_ts = sales_data.loc[(sales_data["Store"] == 1) & (sales_data["Dept"] == 1)].tail(n = 51)
selected_ts_forecast = forecast_predictions.loc[(test_data["Store"] == 1) &
(test_data["Dept"] == 1)]
[29]:
# Plot the forecast of a select store and department
years = mdates.MonthLocator()
yearsFmt = mdates.DateFormatter('%b')
fig, ax = plt.subplots()
ax.plot(selected_ts["Date"], selected_ts["Weekly_Sales"], label = "Actual")
ax.plot(selected_ts["Date"].iloc[-1], selected_ts_forecast["Weekly_Sales.predicted"], marker='o', label = "Predicted")
ax.xaxis.set_major_locator(years)
ax.xaxis.set_major_formatter(yearsFmt)
plt.legend(loc='upper left')
plt.show()
[ ]: