解释专家设置¶
以下为“解释”专家设置列表,这些设置可在从 MLI page. 设置新建解释时使用。每项设置的名称前均带有其 config.toml 标签。关于解释器特定专家设置的信息,请参见 解释器(插件)专家设置.
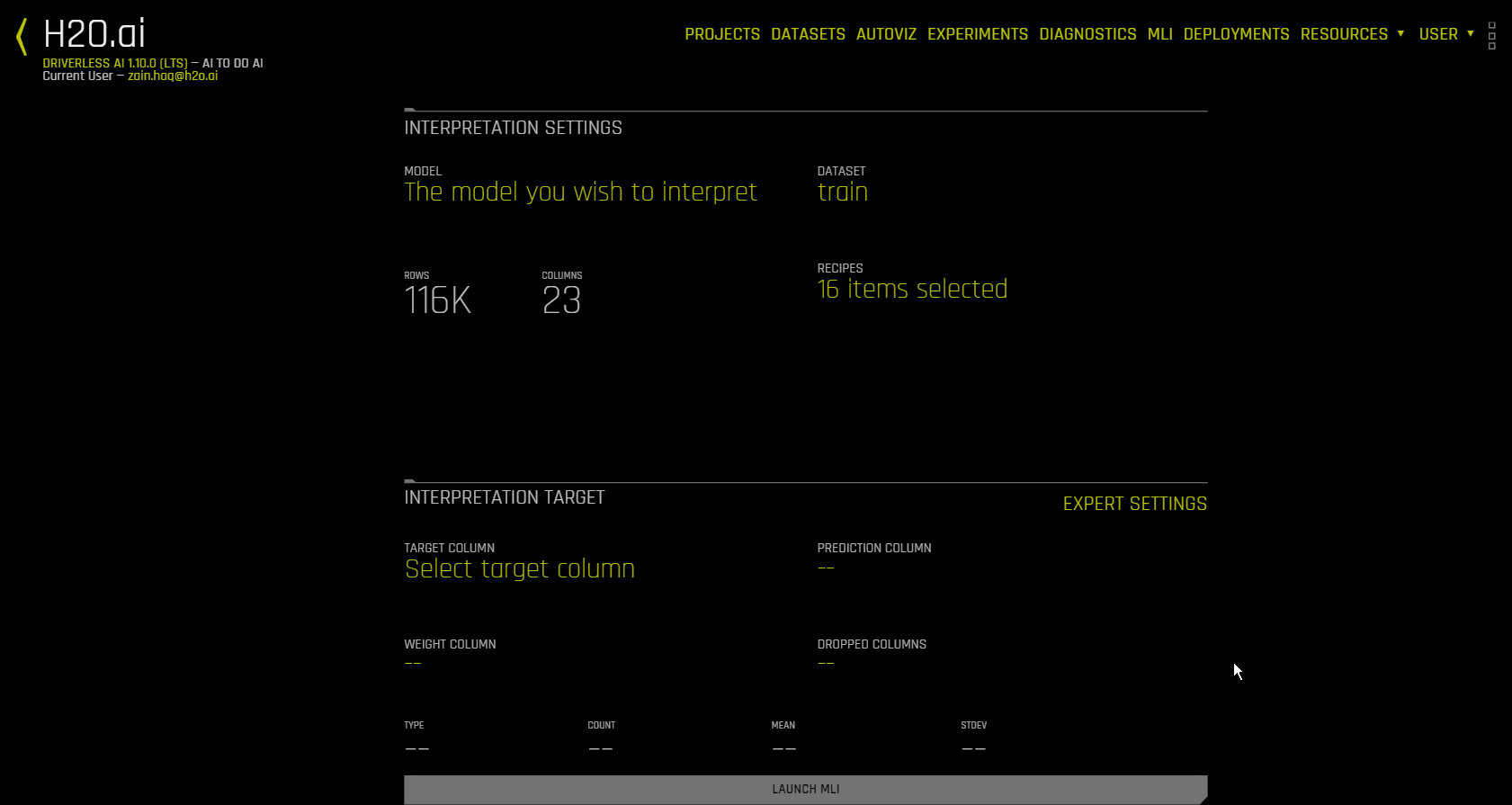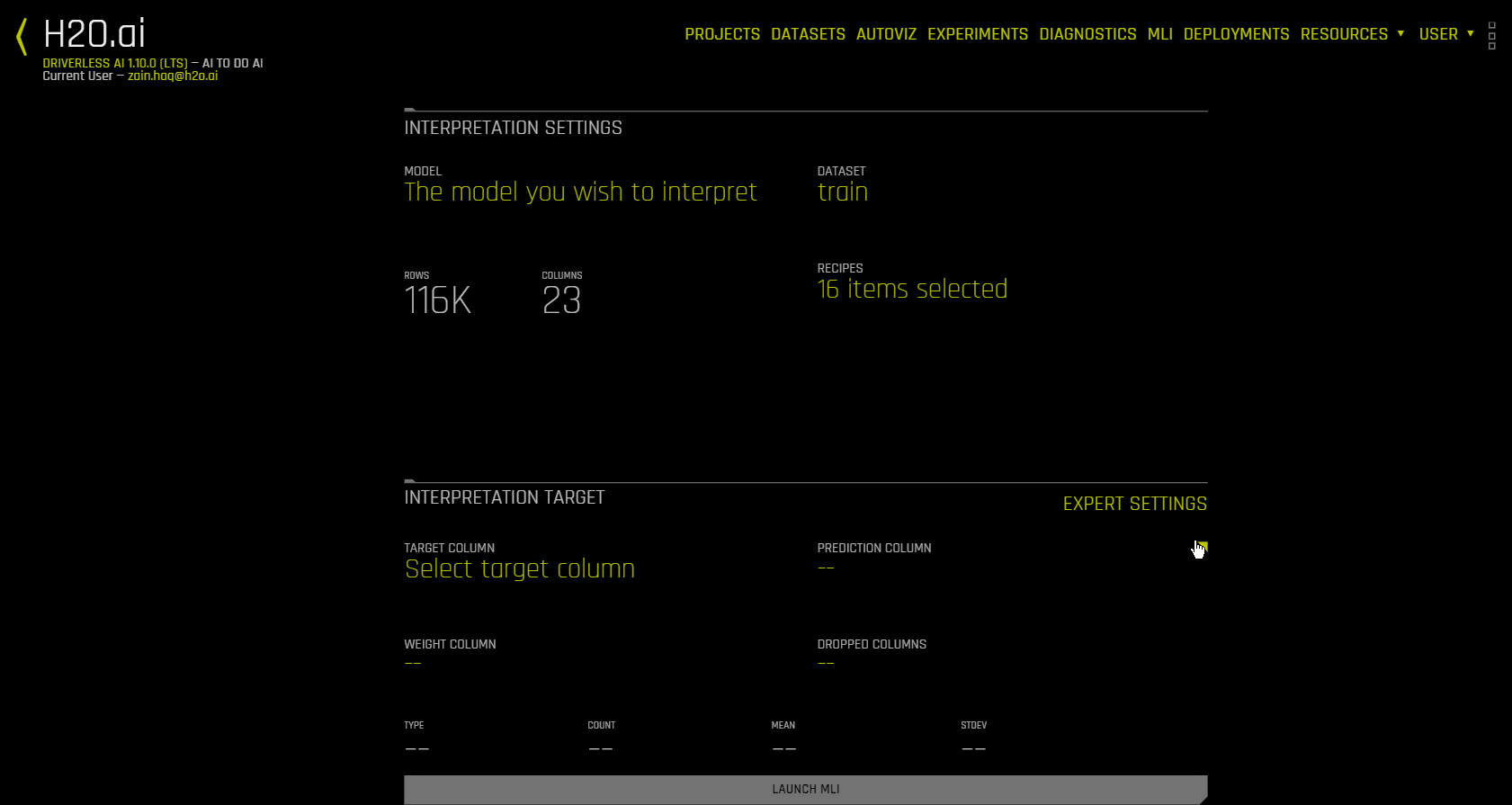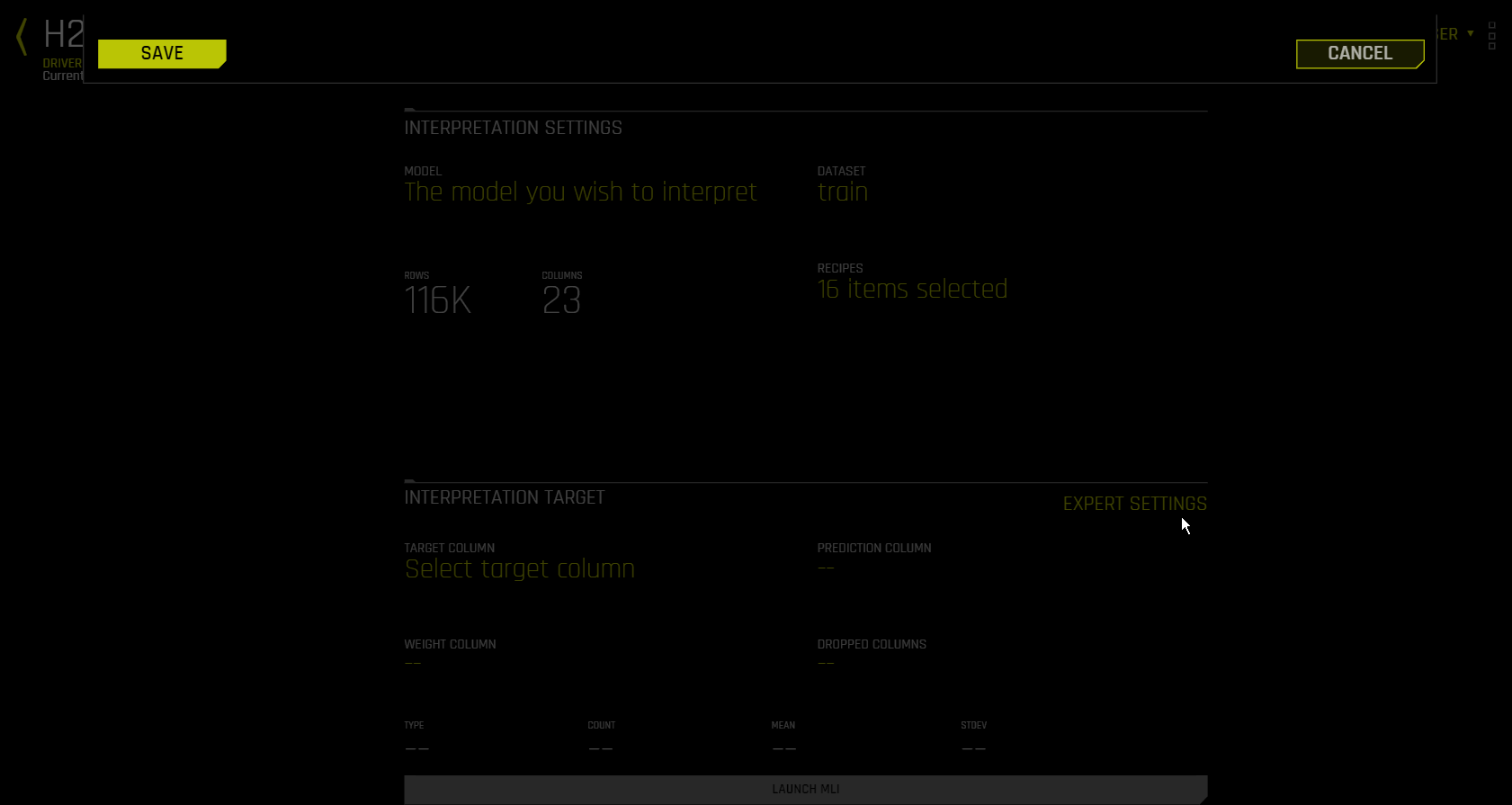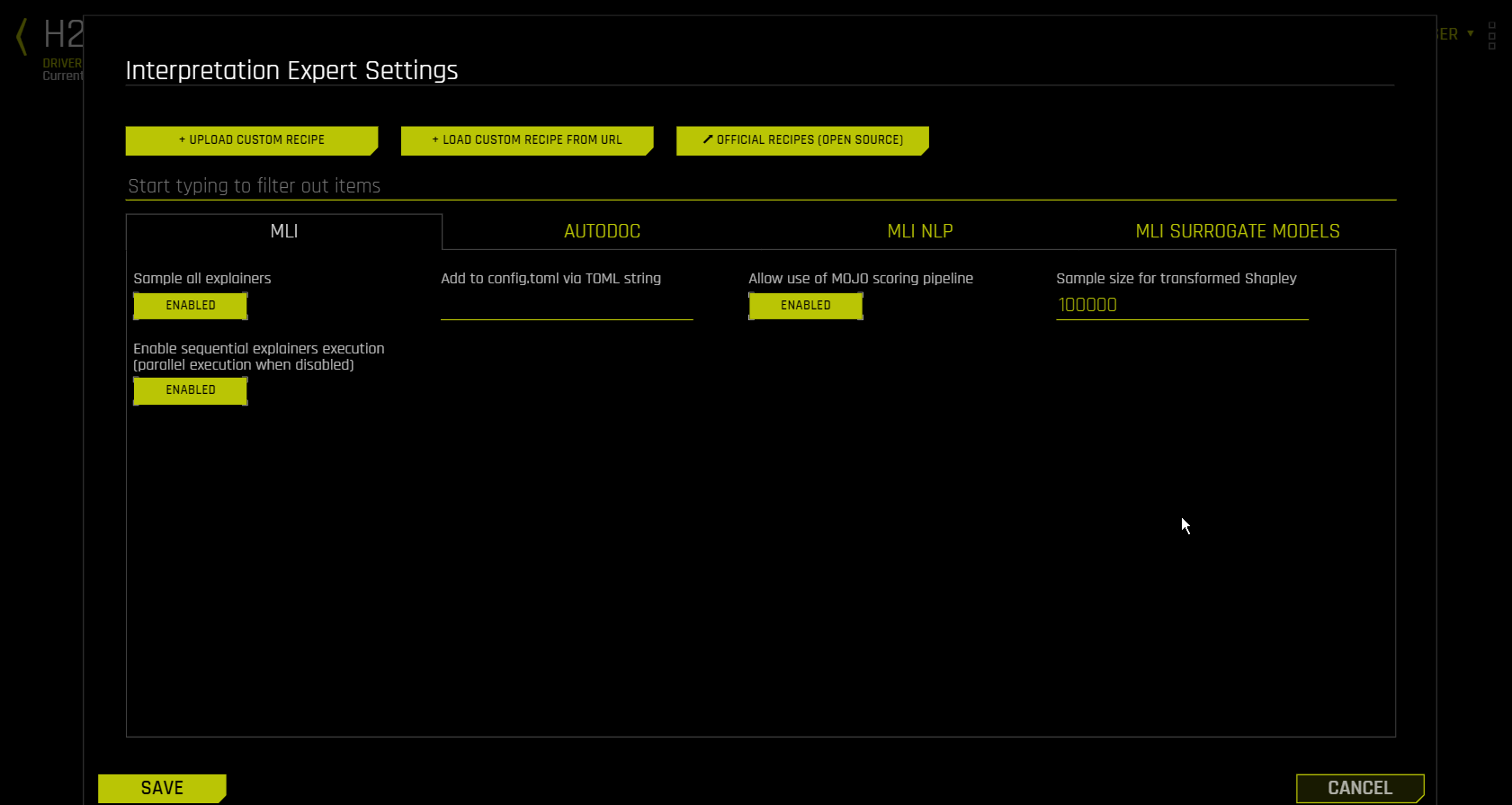
MLI 选项卡¶
mli_sample¶
Sample All Explainers
指定是否对训练数据样本执行解释。默认情况下,如果训练数据集大于 10 万行,则 MLI 将对其进行抽样。(等效的 config.toml 设置为 mli_sample_size. )默认会启用此项设置。关闭此切换开关即可对整个数据集运行 MLI。
mli_enable_mojo_scorer¶
Allow Use of MOJO Scoring Pipeline
使用此选项可禁用 MOJO 评分管道。默认会自动选择评分管道(从 MOJO 和 Python 管道中选择)。对于某些模型,选择 MOJO 还是 Python 可能会影响管道的性能和可靠性。
mli_fast_approx¶
Speed up predictions with a fast approximation
指定是否使用快速近似来加快预测。启用时,此设置可以减少树数或交叉验证折叠数,最终缩短完成解释所需的时间。默认启用此设置。
mli_custom¶
Add to config.toml via TOML String
在此输入字段中填入 TOML 字符串以添加至 Driverless AI 服务器的 config.toml 配置文件中。
MLI NLP 选项卡¶
mli_nlp_top_n¶
Number of Tokens Used for MLI NLP Explanations
指定用于 MLI NLP 解释的标记数。要使用所有可用标记,将此值设置为 -1。此值默认设置为 20。
mli_nlp_sample_limit¶
Sample Size for NLP Surrogate Models
指定 MLI NLP 解释器使用的最大记录数。默认值为 10000。
mli_nlp_min_df¶
Minimum Number of Documents in Which Token Has to Appear
指定必须显示标记的最小文档数量。使用整数值表示绝对计数,使用浮点值表示百分比。默认情况下,此值设置为 3。
mli_nlp_max_df¶
Maximum Number of Documents in Which Token Has to Appear
指定必须显示标记的最大文档数量。使用整数值表示绝对计数,使用浮点值表示百分比。默认情况下,此值设置为 3。
mli_nlp_min_ngram¶
Minimum Value in n-gram Range
指定 n 元语法范围中的最小值。记号赋予器生成 mli_nlp_min_ngram 和 mli_nlp_max_ngram 指定范围内的所有可能标记。默认情况下,此值设置为 1。
mli_nlp_max_ngram¶
Maximum Value in n-gram Range
指定 n 元语法范围中的最大值。记号赋予器生成 mli_nlp_min_ngram 和 mli_nlp_max_ngram 指定范围内的所有可能标记。默认情况下,此值设置为 1。
mli_nlp_min_token_mode¶
Mode Used to Choose N Tokens for MLI NLP
指定用于选择 N 个标记的模式。从以下选项中选择:
顶部 - 选择 N 个顶部标记
底部 - 选择 N 个底部标记
顶部-底部 -选择 math.floor (N/2) 个顶部标记和 math.ceil (N/2) 底部标记
linspace - 选择 N 个等间距的标记
mli_nlp_tokenizer_max_features¶
Number of Top Tokens to Use as Features (Token-based Feature Importance)
在构建基于标记的特征重要性时指定要用作特征的顶部标记数量。默认情况下,此值设置为 -1。
mli_nlp_loco_max_features¶
Number of Top Tokens to Use as Features (LOCO)
在计算文本 LOCO 时指定要用作特征的顶部标记数量。默认情况下,此值设置为 -1。
mli_nlp_surrogate_tokens¶
Number of Top Tokens to Use as Features (Surrogate Model)
在构建替代模型时指定要用作特征的顶部标记数量。注意,此设置仅适用于 NLP 模型。默认情况下,此值设置为 100。
mli_nlp_use_stop_words¶
Stop Words for MLI NLP
指定 MLI NLP 是否使用停用词。默认启用此设置。
mli_nlp_stop_words¶
List of Words to Filter Before Generating Text Tokens
在生成文本标记之前指定要过滤掉的单词列表,这些列表将被传递给 MLI NLP LOCO 和替代模型(如已启用)。输入一个自定义停用词列表。例如,您可以输入 ['great', 'good'] 来过滤掉 great 和 good 这两个词。
mli_nlp_append_to_english_stop_words¶
Append List of Custom Stop Words to Default Stop Words
指定是否将 mli_nlp_stop_words 指定的停用词列表附加到停用词默认列表中。默认禁用此设置。
MLI 替代模型选项卡¶
mli_lime_method¶
LIME Method
选择 K-LIME(默认)或 LIME-SUP 作为 LIME 方法。
K-LIME (默认):使用所有训练数据创建全局替代 GLM 模型,并在由训练数据中的 k-means 聚类形成的样本上创建多个局部替代 GLM 模型。k-means 所使用的特征从 Random Forest 替代模型的变量重要性中选择。k-means 所使用的特征数量是 Random Forest 替代模型的变量重要性中前 25% 变量的最小值,以及可用于 k-means 的最大变量数量(由用户在 config.toml 设置中为
mli_max_number_cluster_vars设定)。(请注意,如果数据集中的特征数量小于或等于 6,则所有特征均被用于 k-means 聚类。)通过在 config.toml 文件中将use_all_columns_klime_kmeans设置为true,可关闭之前的设置,从而将所有特征用于 k-means。所有受到罚分的 GLM 替代模型均已经过训练,可对 Driverless AI 模型的预测结果进行建模。可通过网格搜索选择局部解释所使用的聚类数量,在搜索过程中,Driverless AI 模型预测结果和所有局部 K-LIME 模型预测结果之间的 \(R2\) 将被最大化。全局和局部线性模型的截距、系数、\(R2\) 值、准确度和预测结果均可用于调试和开发对 Driverless AI 模型性能的解释。LIME-SUP:从原始变量方面解释已训练的 Driverless AI 模型的局部区域。局部区域由决策树替代模型的每个叶节点路径决定,而不是由原始 LIME 中被模拟、被干扰的观测值样本决定。对于每个局部区域,使用原始输入数据和 Driverless AI 模型的预测结果训练局部 GLM 模型。随后,此局部 GLM 模型的参数可被用于生成 Driverless AI 模型的近似局部解释。
mli_use_raw_features¶
Use Original Features for Surrogate Models
:open:
指定在替代模型中是使用原始特征还是使用转换特征来执行新解释。默认会启用此项设置。
请注意:禁用此项设置后,K-LIME 聚类列和分位数分箱选项将无法使用。
mli_vars_to_pdp¶
Number of Features for Partial Dependence Plot
指定构建部分依赖性图时要使用的特征的最大数量。使用 -1 可计算所有特征的部分依赖性图。默认值为 10。
mli_nfolds¶
Cross-validation Folds for Surrogate Models
指定要使用的替代交叉验证折叠数量(0 到 10)。运行实验时,Driverless AI 会自动拆分训练数据并使用验证数据来确定模型参数调优和特征工程步骤的性能。对于新解释,Driverless AI 默认使用 3 个交叉验证折叠来进行解释。
mli_qbin_count¶
Number of Columns to Bin for Surrogate Models
指定替代模型要进行分箱的列数。默认值为 0。
mli_sample_size¶
Sample Size for Surrogate Models
当行数超出此限制时,将为替代模型进行抽样。默认值为 100000。
mli_num_quantiles¶
Number of Bins for Quantile Binning
指定分位数分箱的分箱数。默认情况下,此值设置为 -10。
mli_dia_sample_size¶
Sample Size for Disparate Impact Analysis
当行数超出此限制时,将为差异影响分析 (DIA) 进行抽样。默认值为 100000。
mli_pd_sample_size¶
Sample Size for Partial Dependence Plot
当行数超出此限制时,将为 Driverless AI 部分依赖性图进行抽样。默认值为 25000。
mli_pd_numcat_num_chart¶
Unique Feature Values Count Driven Partial Dependence Plot Binning and Chart Selection
指定在实验将特征同时用作数值特征和分类特征的情况下,是否动态切换 PDP 数值和分类分箱与 UI 图表。默认会启用此项设置。
mli_pd_numcat_threshold¶
Threshold for PD/ICE Binning and Chart Selection
如果启用 mli_pd_numcat_num_chart ,且唯一特征值的数量大于阈值,则将使用数值分箱和图表。否则,将使用分类分箱和图表。默认阈值为 11。
mli_sa_sampling_limit¶
Sample Size for Sensitivity Analysis (SA)
当行数超出此限制时,将为敏感性分析 (SA) 进行抽样。默认值为 500000。
klime_cluster_col¶
k-LIME Clustering Columns
对于 k-LIME 解释,可指定要应用 k-LIME 聚类的列。
请注意:在 config.toml 文件中没有此项设置。
qbin_cols¶
Quantile Binning Columns
对于 k-LIME 解释,指定一列或多列以生成十分位数分箱(均匀分布),从而帮助提高 MLI 准确度。所选择的列会被添加至前 n 列中,用于选择分位数分箱。如果某个列不是数值列或不在数据集(转换特征)中,则将跳过此列。
请注意:在 config.toml 文件中没有此项设置。