Driverless AI MOJO 评分管道 - Java 运行时(有 Shapley 贡献值)¶
对于已完成的实验,Driverless AI 自动将模型转换为 MOJO(优化的模型对象)。MOJO 评分管道 是一种评分引擎,可在任意 Java 环境中部署,以实现实时评分。(关于带有 Python 和 R 包装器的 C++ 运行时的信息,请参阅 H2O MOJO c++ scoring pipeline. )有关部署选项,请参阅 H2O Mojo Deployment.
MOJO 与实验关联。当升级 Driverless AI 时,实验和 MOJO 不会自动升级。
请注意:
此评分管道目前不可用于 TensorFlow、BERT、RuleFit 或 Image 模型。C++ 运行时支持 TensorFlow/Bert。
若要禁止自动创建此评分管道,在构建实验时将 构建 MOJO 评分管道 专家设置设置为 关 。
您可以尝试使用 Driverless AI,以通过启用 Reduce MOJO Size 专家设置和 see ,在构建实验时减小 MOJO 评分管道 。
已下载的实验 MOJO 评分管道 (Java 运行时) 中带有 Shapely 贡献值。
转换特征 和 原始特征 的 Shapley contributions 目前 可用 于 XGBoost (GBM、GLM、RF、DART)、LightGBM、零膨胀、不平衡和 DecisionTree 模型(以及它们的集成)。对于需集成 ExtraTrees 元学习器 (ensemble_meta_learner=’extra_trees’) 的模型,我们建议使用 MLI Python 评分包。
快速运行¶
对于示例测试集,若要通过控制台中已下载的 MOJO 评分管道获取快速输出:
确保已安装 Java7 或更高版本。
将 Driverless AI 许可证文件(比如 license.file)复制到已下载的 mojo-pipeline 文件夹中。
将目录更改为 mojo-pipeline 文件夹
利用实验中创建的 pipeline.mojo 文件(带有 mojo2-runtime)对 example.csv 文件中的多行进行评分,以获取预测结果。
java -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar pipeline.mojo example.csv若要获取 转换特征 的 Shapley 贡献值 ,使用标志
--show-contributions运行java -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar --show-contributions pipeline.mojo example.csv若要获取 原始特征 的 Shapley 贡献值 ,使用标志
--show-contributions-original运行java -Xmx5g -Dai.h2o.mojos.runtime.license.file=license.file -jar mojo2-runtime.jar --show-contributions-original pipeline.mojo example.csv
参考 run-example.sh。更大的测试文件/MOJO 可能要求更大的存储空间 (Xmx) 来进行评分。
请注意:
目前,转换特征 的 Shapley contributions 可用 于 XGBoost (GBM、GLM、RF、DART)、LightGBM、零膨胀、不平衡和 DecisionTree 模型(以及它们的集成)。对于需集成 ExtraTrees 元学习器 (ensemble_meta_learner=’extra_trees’) 的模型,我们建议使用 MLI Python 评分包。
目前,原始特征 的 Shapley contributions 仅 可用 于单一模型,即集成级别 1 或 0。
在 MOJO 中,原始特征 的 Shapley 值通过朴素 Shapley (even split) 方法根据转换特征的相应 Shapley 值进行近似计算得出。
Shapley fast approximation 仅使用一个最多不超过前 50 个树的模型(在第一折叠中)。详情请参见
fast_approx_num_trees和fast_approx_do_one_fold_one_modelconfig.toml settings.
先决条件¶
若要运行 MOJO 评分管道,必须满足以下条件。
Java 7 运行时 (JDK 1.7) 或更高版本。请注意:由于 Java 中有漏洞,建议使用 Java 11+。(请访问 https://bugs.openjdk.java.net/browse/JDK-8186464。)
有效的 Driverless AI 许可证。您可以通过托管 Driverless AI 的主机下载
license.sig文件(通常位于 license 文件夹内)。将许可证文件复制到已下载的mojo-pipeline文件夹中。mojo2-runtime.jar 文件。可通过 Driverless AI UI 上的顶部导航菜单获取该文件,也可以在为实验下载的 mojo-pipeline.zip 文件中找到该文件。
指定许可证¶
Driverless AI 需要指定许可证方可运行 MOJO 评分管道。可通过以下方式指定许可证:
通过环境变量:
DRIVERLESS_AI_LICENSE_FILE: Driverless AI 许可证文件的路径,或DRIVERLESS_AI_LICENSE_KEY: Driverless AI 许可证密钥(Base64 编码字符串)
通过 JVM 的系统属性(
-D选项):ai.h2o.mojos.runtime.license.file: Driverless AI 许可证文件的路径,或ai.h2o.mojos.runtime.license.key: Driverless AI 许可证密钥(Base64 编码字符串)
通过应用程序 classpath:
通过名称为
/license.sig的资源加载许可证。可通过 JVM 系统属性
ai.h2o.mojos.runtime.license.filename更改默认的资源名称。
例如:
# Specify the license via a temporary environment variable
export DRIVERLESS_AI_LICENSE_FILE="path/to/license.sig"
MOJO 评分管道文件¶
mojo-pipeline 文件夹中包含以下文件:
run_example.sh:用于对样本测试集进行评分的 Bash 脚本。
pipeline.mojo:MOJO 格式的独立评分管道。
mojo2-runtime.jar:MOJO Java 运行时。
example.csv:样本测试集(具有正确格式的综合测试集)。
DOT 文件:可被渲染为图表的文本文件,其中显示了 MOJO 评分管道的视图(可进行编辑以更改所渲染图表的外观和结构)。
PNG 文件:以视图的方式显示 MOJO 评分管道的图像文件。
快速入门¶
在运行快速入门实例之前,确保已经下载并解压 MOJO 评分管道文件:
在“已完成的实验”页面上,点击 下载 MOJO 评分管道 按钮。
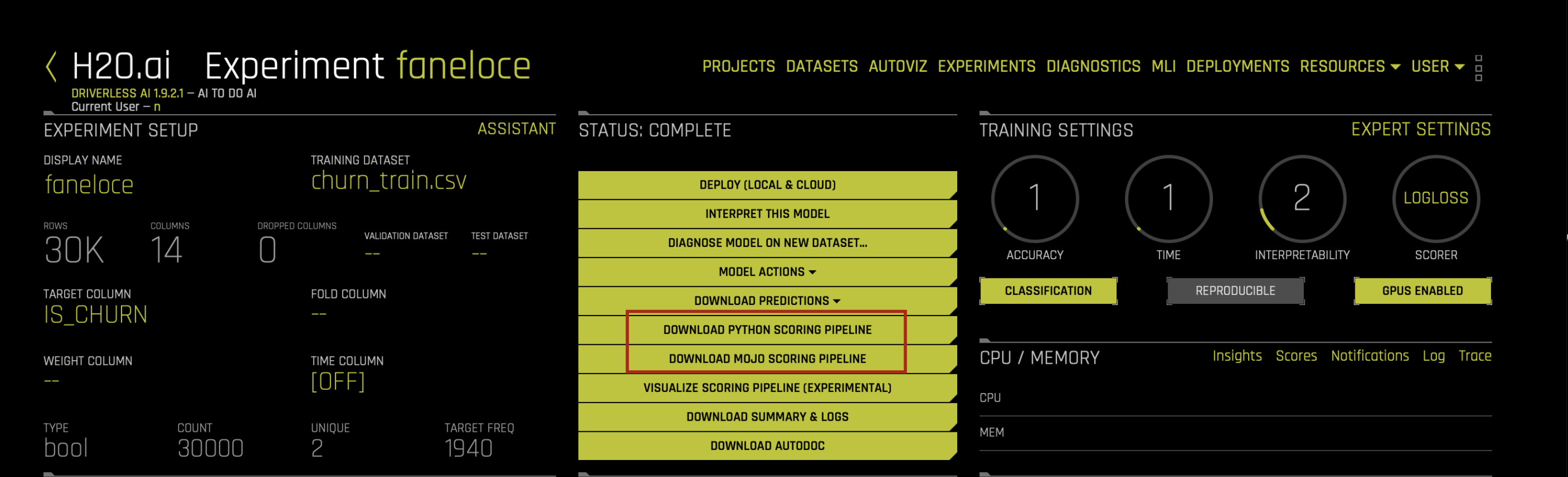
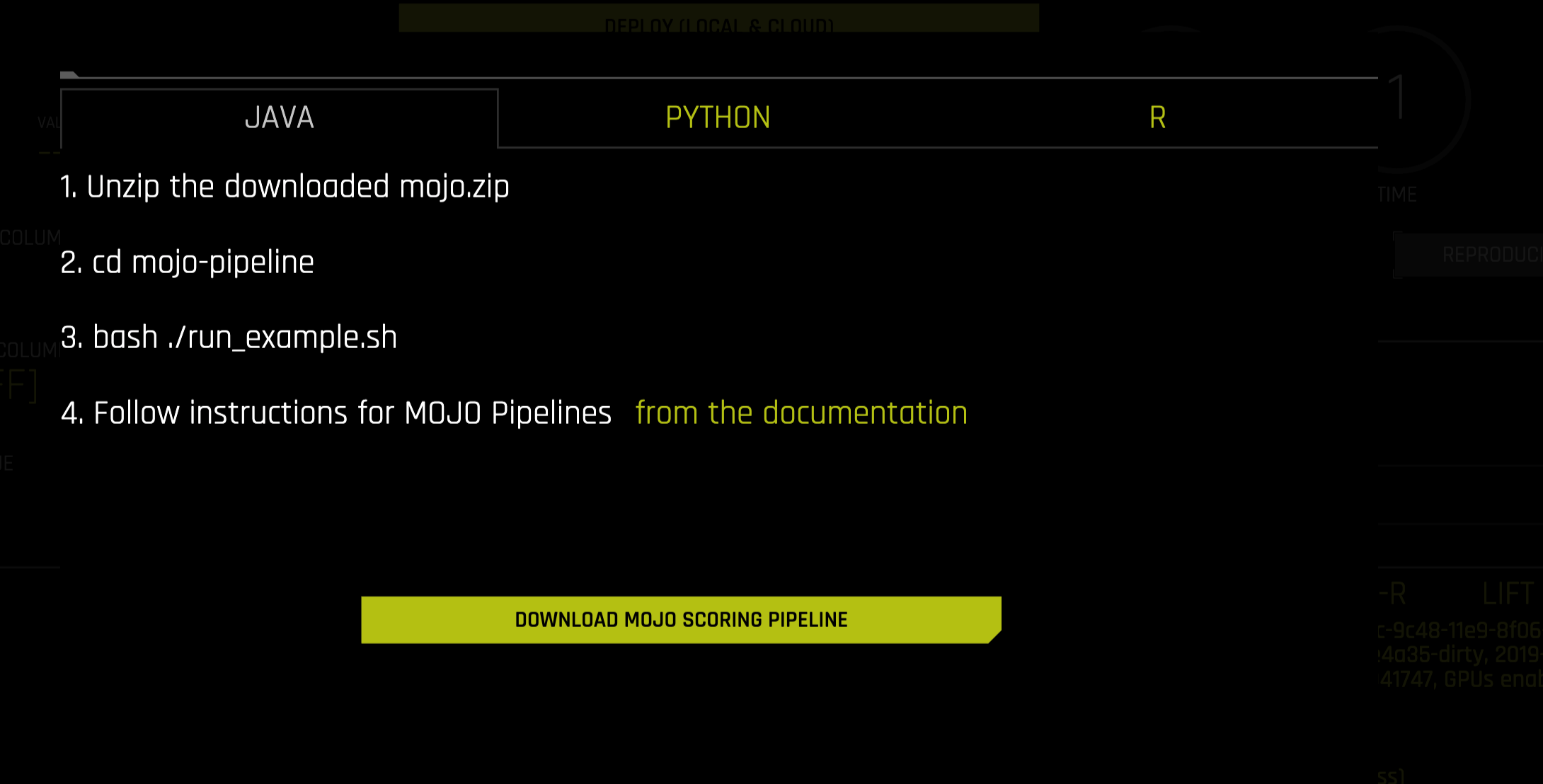
在弹出的菜单中,再次点击 下载 MOJO 评分管道 按钮,以将此实验的 scorer.zip 文件下载到本地的计算机中。请参考与 Java、Python 或 R 相关的说明。
运行以下命令,以对样本测试集中的所有行进行评分,通过这些路径,测试集 (example.csv)、MOJO 管道 (pipeline.mojo) 和许可证 (license.sig) 的路径分别存储在环境变量
TEST_SET_FILE、MOJO_PIPELINE_FILE、DRIVERLESS_AI_LICENSE_KEY中:
bash run_example.sh
运行以下命令,以对带有 MOJO 管道 (pipeline.mojo) 和许可证文件 (license.sig) 的特定测试集 (example.csv) 进行评分:
bash run_example.sh pipeline.mojo example.csv license.sig
若要直接运行用于数据转换的 Java 应用程序:
java -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv请注意:对于非常大的模型,在运行用于数据转换的 Java 应用程序时,可能需要提高存储空间限值。这可以通过在运行以上命令时指定
-Xmx25g来实现。
MOJO 评分命令行选项¶
执行 Java 运行时¶
以下是两个关于如何通过命令行执行 Java 运行时的一般示例:
有附加库:
java <JVM options> [options...] -cp mojo2-runtime.jar:your-other.jar:many-more-libs.jar ai.h2o.mojos.ExecuteMojo path-to/pipeline.mojo path-to/input.csv path-to/output.csv
无附加库:
java <JVM options> -jar mojo2-runtime.jar path-to/pipeline.mojo path-to/input.csv path-to/output.csv
因此,可通过以下方式传递 sys.ai.h2o.mojos.parser.csv.separator 选项:
java -Dsys.ai.h2o.mojos.parser.csv.separator='|' -Dai.h2o.mojos.runtime.license.file=../license.sig -jar mojo2-runtime.jar pipeline.mojo input.csv output.csv
类似地,可在通过以下方式传递 sys.ai.h2o.mojos.exposedInputs 选项:
java -Xmx5g -Dsys.ai.h2o.mojos.exposedInputs=ALL -Dai.h2o.mojos.runtime.license.file= -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv
请注意:可通过将输入和输出 CSV 参数替换为 `-` 将数据从 stdin 传输到 stdout。
Java 虚拟机 (JVM) 选项¶
sys.ai.h2o.mojos.parser.csv.keepCarriageReturn(布尔值)- 指定是否在解析后保留回车。默认值为 True。sys.ai.h2o.mojos.parser.csv.stripCrFromLastColumn(布尔值)- 与 OpenCSV 解析器相关问题的解决方法。默认值为 True。sys.ai.h2o.mojos.parser.csv.quotedHeaders(布尔值)- 指定是否在输出的 CSV 文件中引用标头名称。默认值为 False。sys.ai.h2o.mojos.parser.csv.separator(字符)- 指定 CSV 字段之间使用的分隔符。特殊值 `TAB` 可用于制表符分隔的值。默认值为 `,`.sys.ai.h2o.mojos.parser.csv.escapeChar(字符)- 指定用于解析 CSV 字段的转义字符。如果没有指定此值,则不会尝试转义。默认值为空字符串。Sys.ai.h2o.mojos.parser.csv.batch(整数)- 指定引入内存以进行批处理的输入记录数量(决定了占用的内存)。默认值为 1000。sys.ai.h2o.mojos.pipelineFormats(字符)- 当识别到多种格式时,此选项将指定格式的尝试顺序。默认值为 `pbuf,toml,klime,h2o3`.Sys.ai.h2o.mojos.parser.csv.date.formats(字符串)- 指定日期格式。默认值为空字符串。sys.ai.h2o.mojos.exposedInputs(字符串)- 指定输出时需要的输入列的逗号分隔列表。特殊值 `ALL` 表示接受所有输入。默认值为空值。sys.ai.h2o.mojos.useWeakHash(布尔值)- 指定是否使用 WeakHashMap。此值默认设置为 False。启用此设置可缩短 MOJO 加载时间。
用于访问控制的 JVM 选项
ai.h2o.mojos.runtime.license.key- 指定许可证密钥。ai.h2o.mojos.runtime.license.file- 指定许可证密钥的位置。ai.h2o.mojos.runtime.license.filename- 覆盖默认许可证文件名。ai.h2o.mojos.runtime.signature.filename- 覆盖默认签名文件名。ai.h2o.mojos.runtime.watermark.filename- 覆盖默认水印文件名。
通过 Java 执行 MOJO¶
打开新的终端窗口、创建实验文件夹,并更改该新文件夹的目录:
mkdir experiment && cd experiment
通过创建名为 DocsExample.java 的新文件,在 实验 文件夹中创建您的主程序(例如,使用
vim DocsExample.java创建主程序)。包括以下内容。
import ai.h2o.mojos.runtime.MojoPipeline; import ai.h2o.mojos.runtime.api.MojoPipelineService; import ai.h2o.mojos.runtime.frame.MojoFrame; import ai.h2o.mojos.runtime.frame.MojoFrameBuilder; import ai.h2o.mojos.runtime.frame.MojoRowBuilder; import ai.h2o.mojos.runtime.lic.LicenseException; import ai.h2o.mojos.runtime.utils.CsvWritingBatchHandler; import com.opencsv.CSVWriter; import java.io.BufferedWriter; import java.io.IOException; import java.io.OutputStreamWriter; import java.io.Writer; public class DocsExample { public static void main(String[] args) throws IOException, LicenseException { // Load model and csv final MojoPipeline model = MojoPipelineService.loadPipeline(new File("pipeline.mojo")); // Get and fill the input columns final MojoFrameBuilder frameBuilder = model.getInputFrameBuilder(); final MojoRowBuilder rowBuilder = frameBuilder.getMojoRowBuilder(); rowBuilder.setValue("AGE", "68"); rowBuilder.setValue("RACE", "2"); rowBuilder.setValue("DCAPS", "2"); rowBuilder.setValue("VOL", "0"); rowBuilder.setValue("GLEASON", "6"); frameBuilder.addRow(rowBuilder); // Create a frame which can be transformed by MOJO pipeline final MojoFrame iframe = frameBuilder.toMojoFrame(); // Transform input frame by MOJO pipeline final MojoFrame oframe = model.transform(iframe); // `MojoFrame.debug()` can be used to view the contents of a Frame // oframe.debug(); // Output prediction as CSV final Writer writer = new BufferedWriter(new OutputStreamWriter(System.out)); final CSVWriter csvWriter = new CSVWriter(writer); CsvWritingBatchHandler.csvWriteFrame(csvWriter, oframe, true); } }
使用复制到实验中的 MOJO 运行时文件 (mojo2-runtime.jar) 和 MOJO 管道 (pipeline.mojo) 编译源代码:
javac -cp mojo2-runtime.jar -J-Xms2g -J-XX:MaxPermSize=128m DocsExample.java
使用复制到到实验中的许可证 (license.sig) 运行 MOJO 示例:
# Linux and OS X users java -Dai.h2o.mojos.runtime.license.file=license.sig -cp .:mojo2-runtime.jar Main # Windows users java -Dai.h2o.mojos.runtime.license.file=license.sig -cp .;mojo2-runtime.jar Main
将显示以下输出:
CAPSULE.True 0.5442205910902282
使用带有 Spark/Sparkling Water 的 MOJO 评分管道¶
请注意:Driverless AI 1.5 版本将是最后一个采用基于 TOML 的 MOJO2 的版本。1.5 以后的版本将采用基于 protobuf 的 MOJO2。
在 Spark 中,可使用 MOJO 评分管道工件,通过使用 Sparkling Water API 以并行的方式部署预测。本节展示如何通过使用 Scala 和 Python API 在 Spark 中的 MOJO 评分管道上加载和运行预测。
如果您升级 H2O Driverless AI,那么我们会为您带来好消息!Sparkling Water 向后兼容使用较低版本的 Driverless AI 生成的 MOJO 版本。
要求¶
您必须拥有 Spark 聚类,并已将 Sparkling Water JAR 文件传递给 Spark。
若要使用 PySparkling 运行,您必须有 PySparkling 压缩文件。
如果您只想通过使用 Spark 在 MOJO 上运行预测,则不用创建 H2OContext,因为评分与 H2O 运行时无关。
准备您的环境¶
若要使用 MOJO 评分管道,必须将 Driverless AI 许可证传递给 Spark。可以通过 Spark 启动器脚本的 --jars 参数来实现。
请注意:在“本地 Spark”模式下,使用 --driver-class-path 指定许可证文件的路径。
PySparkling¶
首先,通过 PySparkling Python 包和 Driverless AI 许可证启动 PySpark。
./bin/pyspark --jars license.sig --py-files pysparkling.zip
或者,您可以通过 H2O Download page. 下载官方 Sparkling Water 分发版。请按照 Sparkling Water 下载页面上提示的步骤操作。一旦进入 Sparkling Water 目录,您就可以调用:
./bin/pysparkling --jars license.sig
此时,您应该可以使用 PySpark 交互式终端,在该终端上,您可以尝试预测。如果您想在生产环境中执行评分流程,可以使用相同的配置,只是在向聚类提交作业时,不使用 ./bin/pyspark,而使用 ./bin/spark-submit.
# First, specify the dependencies
from pysparkling.ml import H2OMOJOPipelineModel, H2OMOJOSettings
# The 'namedMojoOutputColumns' option ensures that the output columns are named properly.
# If you want to use old behavior when all output columns were stored inside an array,
# set it to False. However we strongly encourage users to use True which is defined as a default value.
settings = H2OMOJOSettings(namedMojoOutputColumns = True)
# Load the pipeline. 'settings' is an optional argument. If it's not specified, the default values are used.
mojo = H2OMOJOPipelineModel.createFromMojo("file:///path/to/the/pipeline.mojo", settings)
# Load the data as Spark's Data Frame
dataFrame = spark.read.csv("file:///path/to/the/data.csv", header=True)
# Run the predictions. The predictions contain all the original columns plus the predictions
# added as new columns
predictions = mojo.transform(dataFrame)
# You can easily get the predictions for a desired column using the helper function as
predictions.select(mojo.selectPredictionUDF("AGE")).collect()
Sparkling Water¶
首先,使用 Sparkling Water Scala 组件和 Driverless AI 许可证启动 Spark。
./bin/spark-shell --jars license.sig,sparkling-water-assembly.jar
或者,您可以通过 H2O Download page. 下载官方 Sparkling Water 分发版。请按照 Sparkling Water 下载页面上提示的步骤操作。一旦进入 Sparkling Water 目录,您就可以调用:
./bin/sparkling-shell --jars license.sig
此时,您应该可以使用 Sparkling Water 交互式终端,在该终端上,您可以尝试预测。如果您想在生产环境中执行评分流程,可以使用相同的配置,只是在向聚类提交作业时,不使用 ./bin/spark-shell,而使用 ./bin/spark-submit 。
// First, specify the dependencies
import ai.h2o.sparkling.ml.models.{H2OMOJOPipelineModel, H2OMOJOSettings}
// The 'namedMojoOutputColumns' option ensures that the output columns are named properly.
// If you want to use old behavior when all output columns were stored inside an array,
// set it to false. However we strongly encourage users to use true which is defined as a default value.
val settings = H2OMOJOSettings(namedMojoOutputColumns = true)
// Load the pipeline. 'settings' is an optional argument. If it's not specified, the default values are used.
val mojo = H2OMOJOPipelineModel.createFromMojo("file:///path/to/the/pipeline.mojo", settings)
// Load the data as Spark's Data Frame
val dataFrame = spark.read.option("header", "true").csv("file:///path/to/the/data.csv")
// Run the predictions. The predictions contain all the original columns plus the predictions
// added as new columns
val predictions = mojo.transform(dataFrame)
// You can easily get the predictions for desired column using the helper function as follows:
predictions.select(mojo.selectPredictionUDF("AGE")).show()