了解“模型解释”页面¶
本文档介绍非时间序列实验的机器学习可解释性 (MLI)“解释”页中提供的各种解释。
“解释”页面有四个选项卡:
使用 仪表板 按钮可显示一个仪表板,其中概述了使用替代模型构建的解释。MLI 页面中的 Action button 可用于下载 原因码 、用于生产环境的 评分管道 以及 MLI 日志 。
task bar 中列出了 MLI explainers 的状态和日志。
“摘要”选项卡¶
“摘要”选项卡提供了解释概述,包括用于解释的数据集和 Driverless AI 实验名称(如适用)以及特征空间(原始特征或转换后特征)、目标列、问题类型和 k-Lime 信息。如果解释由 Driverless AI 模型创建,则还将包括带有 Driverless AI 模型摘要的表格以及此模型的主要变量。
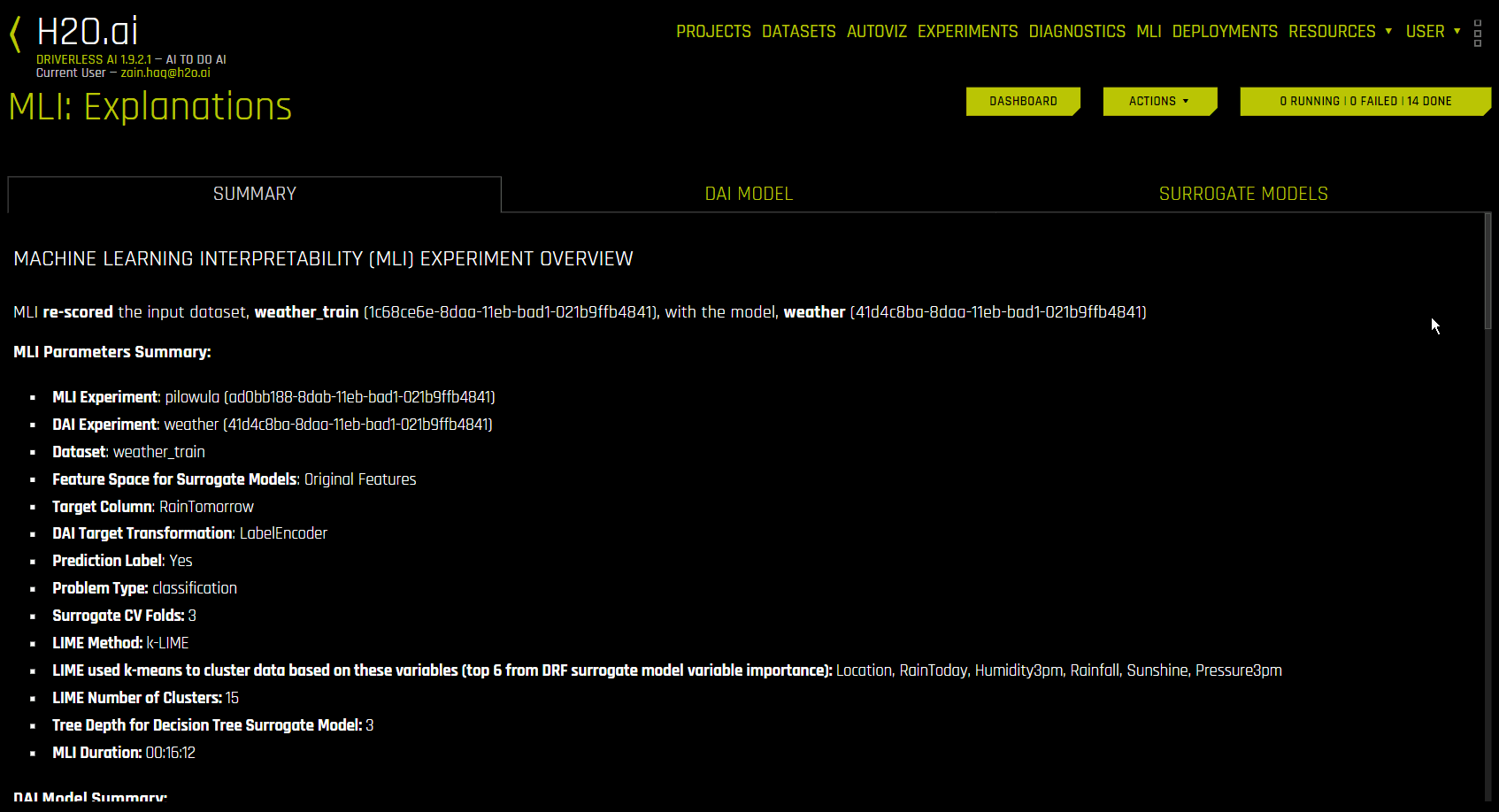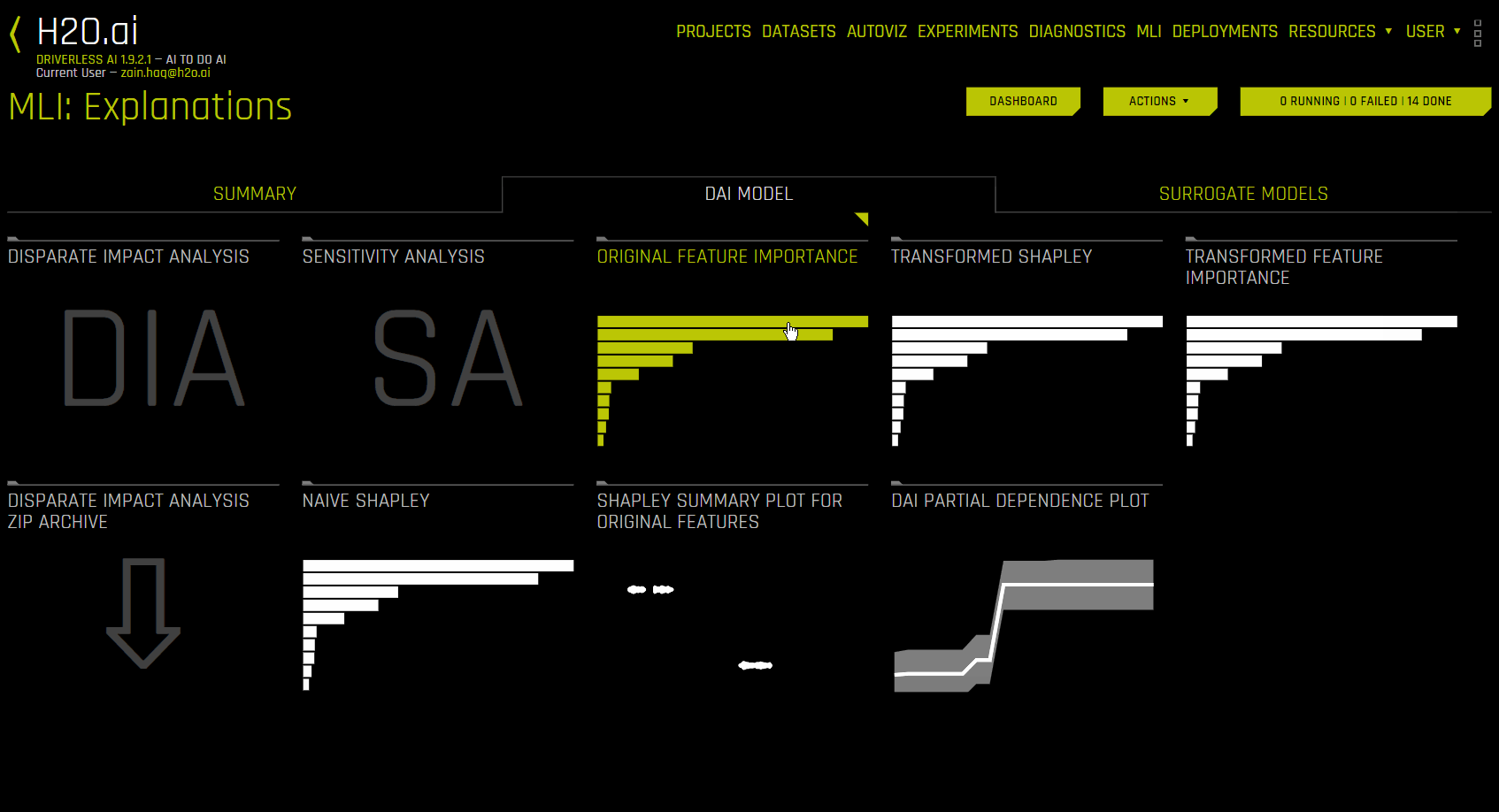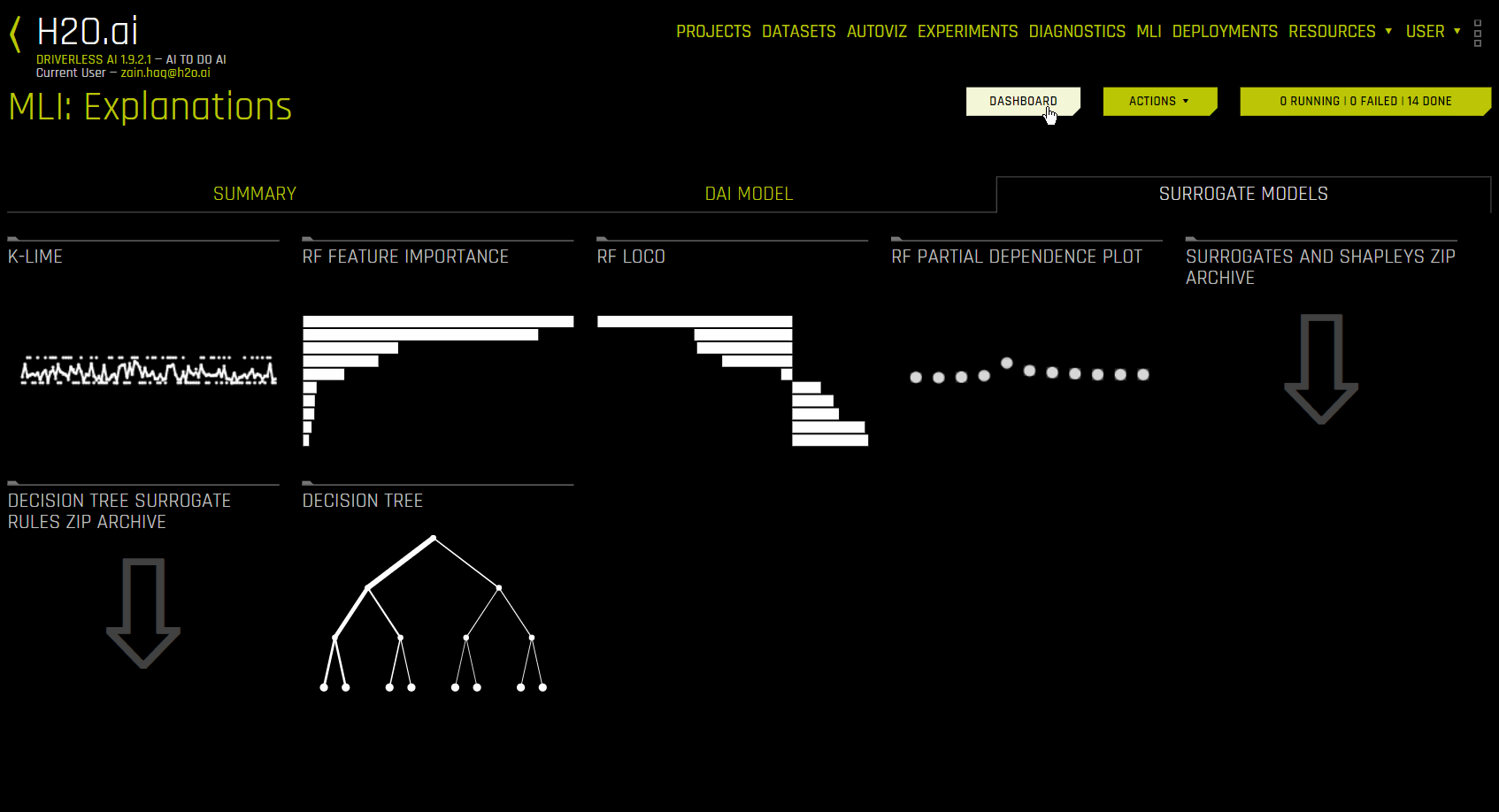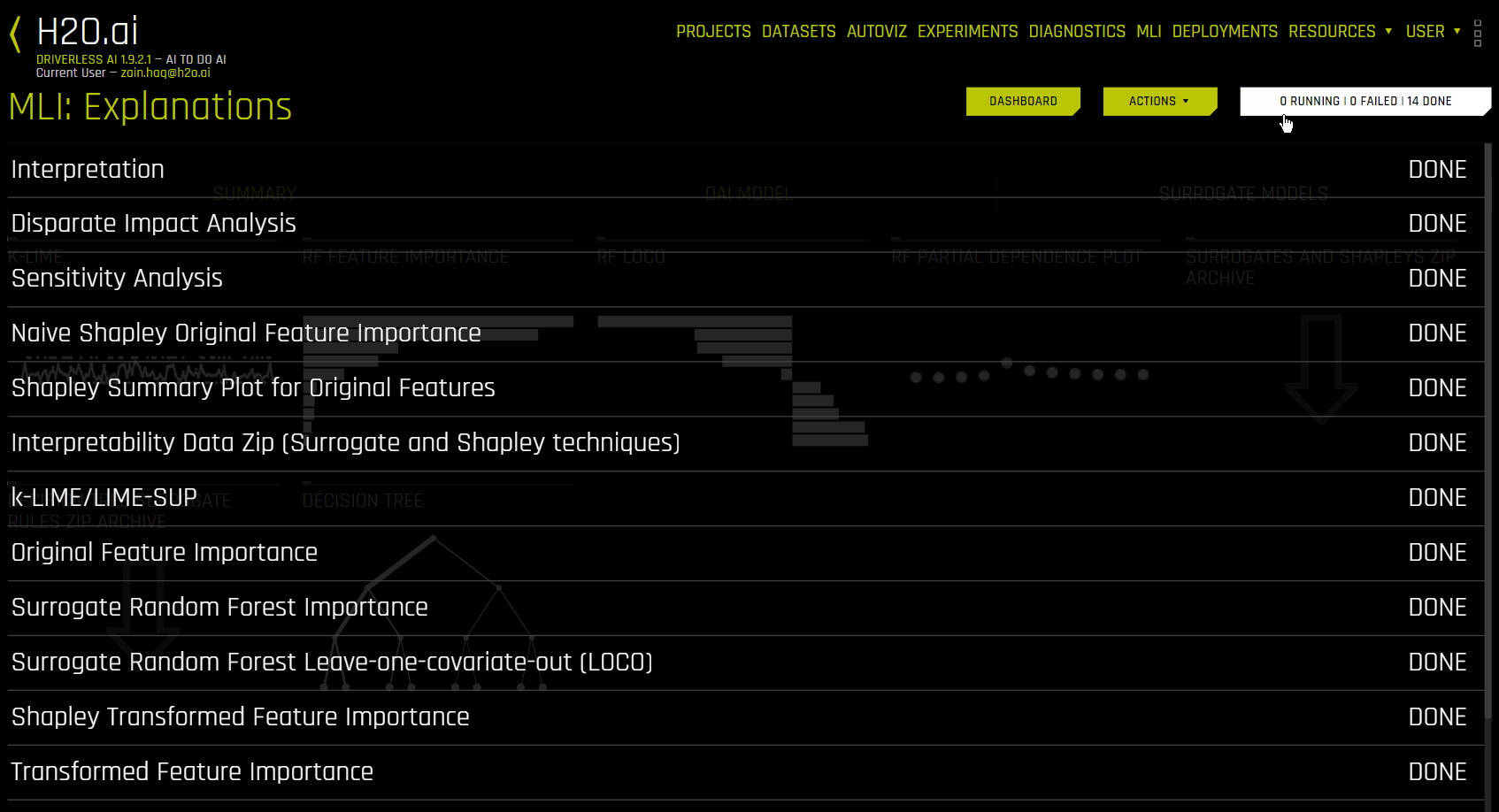
使用 Driverless AI 模型的解释(“DAI 模型”选项卡)¶
“DAI 模型”选项卡分成多个用于表示每种解释方法的磁贴。若需查看特定绘图,可点击对应的磁贴。
对于二元分类和回归实验,此选项卡包含原始特征和转换特征的特征重要性和 Shapley 图(RuleFit 和 TensorFlow 模型不支持)以及部分依赖性/ICE、差异影响分析 (DIA)、敏感性分析、NLP 标记和 NLP LOCO(适用于文本实验),以及排列特征重要性(如果启用 autodoc_include_permutation_feature_importance 配置选项)绘图。对于多类分类实验,此选项卡包含原始特征和转换特征的特征重要性和 Shapley 图。
以下解释图列表可从 Driverless AI“模型”选项卡中获取。
请注意:
RuleFit、FTRL 和 TensorFlow 模型不支持 Shapley 图。
默认会使用 朴素 Shapley 方法 (请参阅 notes)对原始特征的 Shapley 值。若需启用使用 内核解释器 的计算,可在 recipes 中启用原始内核 SHAP 解释。
Shapley 图仅支持用于实施
has_pred_contribs方法(并返回True)并在预测方法中正确处理参数pred_contribs=True的 BYOR(自定义)模型。仅当在启动 Driverless AI 或启动 MLI 实验的过程中启用
autodoc_include_permutation_feature_importance配置选项时,方可使用基于排列的特征重要性图(启动 MLI 作业时从“插件”选项卡启用 AutoDoc 并从 MLI AutoDoc 专家设置启用 include_permutation_feature_importance)。在特征重要性和 Shapley 图中,转换特征的名称将按以下方式编码:
<transformation/gene_details_id>_<transformation_name>:<orig>:<…>:<orig>.<extra>
因此在
32_NumToCatTE:BILL_AMT1:EDUCATION:MARRIAGE:SEX.0中,例如:
32_为用于特定转换参数的转换指数。
NumToCatTE是转换类型。
BILL_AMT1:EDUCATION:MARRIAGE:SEX表示使用的原始特征。
0表示在按特征进行分组(此处显示为BILL_AMT1、EDUCATION、MARRIAGE和SEX)和进行折外估算后 target[0] 的似然编码。对于多类实验,此值 > 0。对于二元实验,此值始终为 0。
使用替代模型的解释(“替代模型”选项卡)¶
替代模型是一项数据挖掘和工程技术,使用一个通常较为简单的模型来解释另一个通常更为复杂的模型或现象。例如,决策树替代模型经过训练,可使用原始模型输入来预测更为复杂的 Driverless AI 模型的预测结果。经过训练的替代模型能够获得对高度复杂的非线性 Driverless AI 模型机制的启发式理解(即非数学方面的精确理解)。
“替代模型”选项卡分成多个用于表示每种解释方法的磁贴。若需查看特定绘图,可点击您对应的磁贴。对于二元分类和回归实验,此选项卡包括 K-LIME/LIME-SUP 和决策树图,以及随机森林替代模型的特征重要性、部分依赖性和 LOCO 图。请参阅 替代模型图,了解更多关于这些绘图的信息。
以下是替代模型的解释图列表:
请注意:对于多类分类实验,此选项卡中仅有决策树和随机森林特征重要性图可用。
使用 NLP 数据集的解释(NLP 选项卡)¶
NLP 选项卡仅对自然语言处理 (NLP) 问题可见,它分成多个用于表示每种解释方法的磁贴。若需查看特定绘图,可点击对应的磁贴
以下解释图列表可从 NLP 选项卡中获取:
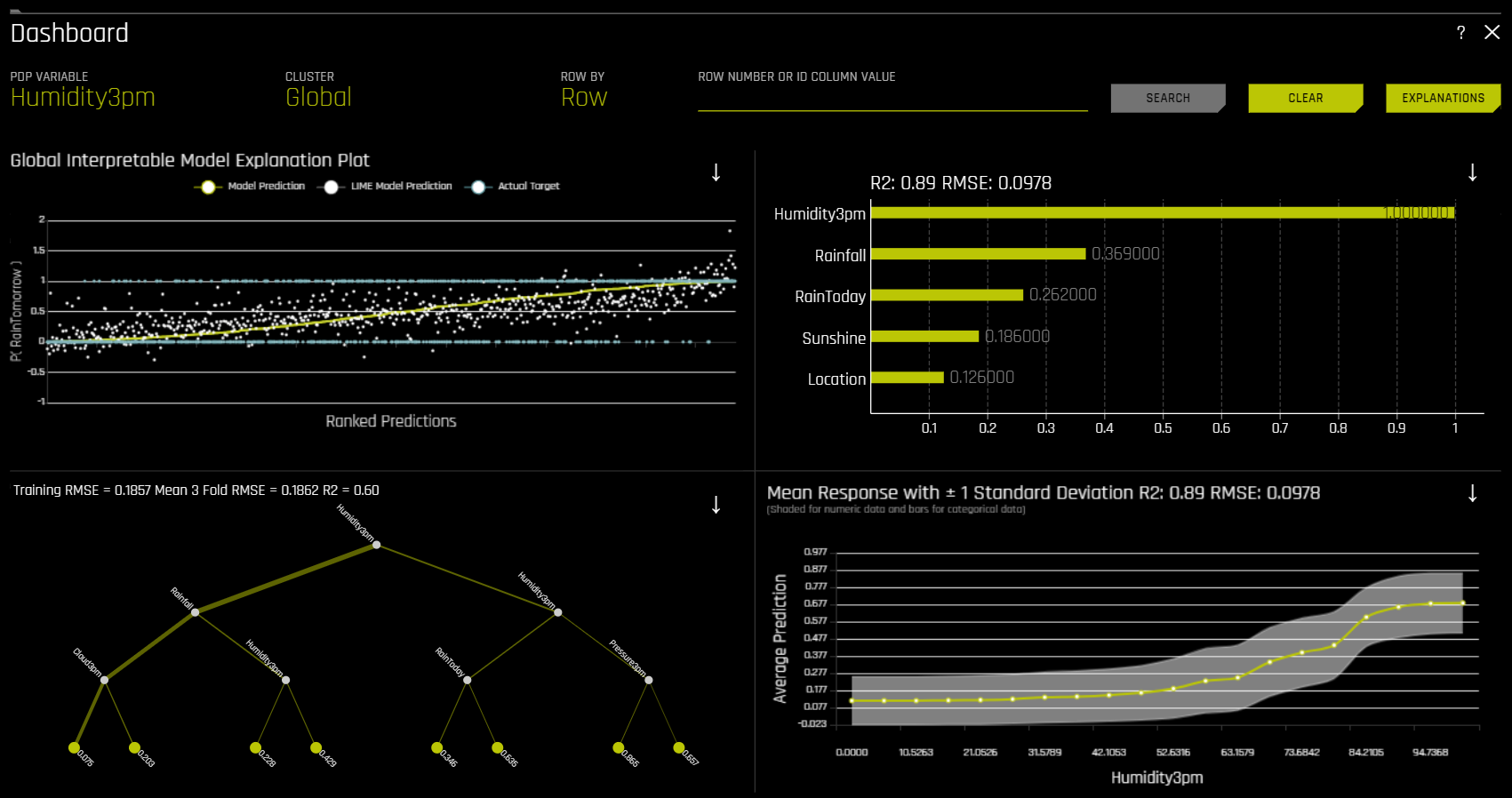
仪表板¶
点击 仪表板 按钮以显示仪表板,其中概述了使用替代模型构建的解释。此按钮位于“解释”页面的右上角。

对于二元分类和回归实验,“仪表板”页面提供包含以下替代模型绘图的单一页面。请注意,此页面上的 PDP 和特征重要性图均基于随机森林替代模型。
全局可解释模型解释
特征重要性
决策树
部分依赖性
您还可通过点击位于右上角的 解释 按钮来查看此页面中的解释。更多信息,请参阅 查看解释 一节。
请注意:此仪表板仅适用于二元分类和回归实验。
操作按钮¶
操作按钮可用于下载 原因码 、用于生产环境的 评分管道 和 日志 。点击此按钮可查看以下选项:
MLI Docs:查看 Driverless AI 文档中的“机器学习可解释性”部分。
下载 MLI 日志:下载解释过程中生成的日志 ZIP 文件。
评分管道:对于二元和回归实验,下载 Python 评分管道以进行解释。此选项不适用于多类实验。
下载 k-LIME MOJO 原因码管道:下载 k-LIME MOJO 原因码管道。更多信息,请参阅 Driverless AI k-LIME MOJO 原因码管道 – Java 运行时.
下载格式化 LIME 原因码:对于二元实验,下载格式化 LIME 原因码的 CSV 文件。
下载 LIME 原因码:对于二元实验,下载 LIME 原因码的 CSV 文件。
下载格式化的转换后 Shapley 原因码:对于回归、二元和多类实验,下载转换后数据的格式化 Shapley 原因码 CSV 文件。
下载格式化的原始 Shapley 原因码(朴素 Shapley):对于对于回归、二元和多类实验,下载原始数据的格式化 Shapley 原因码 CSV 文件。
显示 MLI Java 日志:查看解释的 MLI Java 日志。
显示 MLI Python 日志:查看解释的 MLI Python 日志。
实验:查看用于生成解释的实验。

DAI 模型图¶
本节介绍 DAI 模型选项卡中可供使用的绘图。
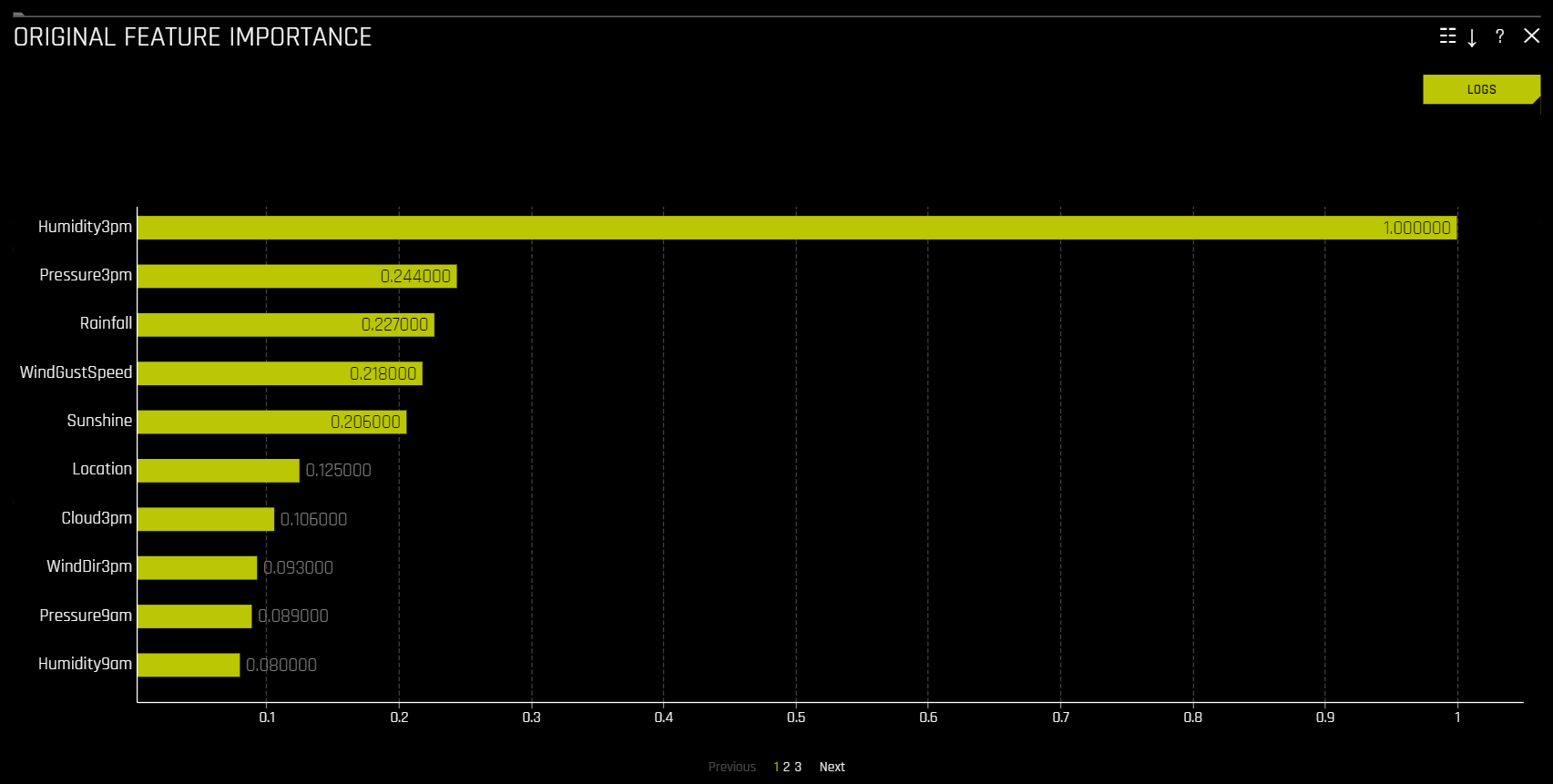
特征重要性(原始特征和转换特征)¶
此图适用于二元分类、多类分类和回归实验的所有模型。
此图展示了 Driverless AI 特征重要性。Driverless AI 特征重要性可用于度量输入变量对 Driverless AI 模型的整体预测结果的贡献。
Shapley(原始特征和转换特征)¶
此图不适用于 RuleFit 或 TensorFlow 模型。对于所有其他模型,此图适用于二元分类、多类分类和回归实验。
Shapley 解释是一种具有可靠理论支持的方法,可提供一致的全局和局部变量贡献。通过在经过训练的树集成中跟踪单行数据并在此行数据进行训练集成时聚合每个输入变量的贡献,可计算局部数值 Shapley 值。对于回归任务,Shapley 值总和为 Driverless AI 模型的预测结果。对于分类问题,在应用链接函数之前,Shapley 值总和为 Driverless AI 模型的预测结果。全局 Shapley 值是数据集中每一行的绝对 Shapley 值的平均值。
通过在经过训练的树集成中跟踪单行数据并在此行数据进行训练集成时聚合每个输入变量的贡献,可计算 转换特征 的 Shapley 值。请访问 https://arxiv.org/abs/1706.06060,以进一步了解基于树的模型的 Shapley 值。Driverless AI 直接调用 XGBoost 和 LightGBM SHAP 函数获取转换特征的贡献值。
原始特征 的 Shapley 值通过 朴素 Shapley (平均拆分)方法根据转换特征的相应 Shapley 值进行近似计算得出。此方法假设输入至转换器的特征是独立的,且在贡献特征中平均拆分贡献。例如,如果转换特征 CVTE:age:income.0 的 Shapley 值为 5,则原始特征 age 和 income 的 Shapley 值将分别为 2.5。对于集成,Shapley 值(在链接空间)按集成中的模型权重进行混合。
用于生产化的 Driverless AI MOJO 支持原始特征使用朴素 Shapley(平均拆分)方法。
原始特征的 Shapley 值还可使用 内核解释器 方法进行计算,此方法使用特殊的加权线性回归来计算每个特征的重要性。可使用 recipe 原始内核 SHAP 解释器启用此方法。请访问 http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf,了解更多关于内核 SHAP 的信息。
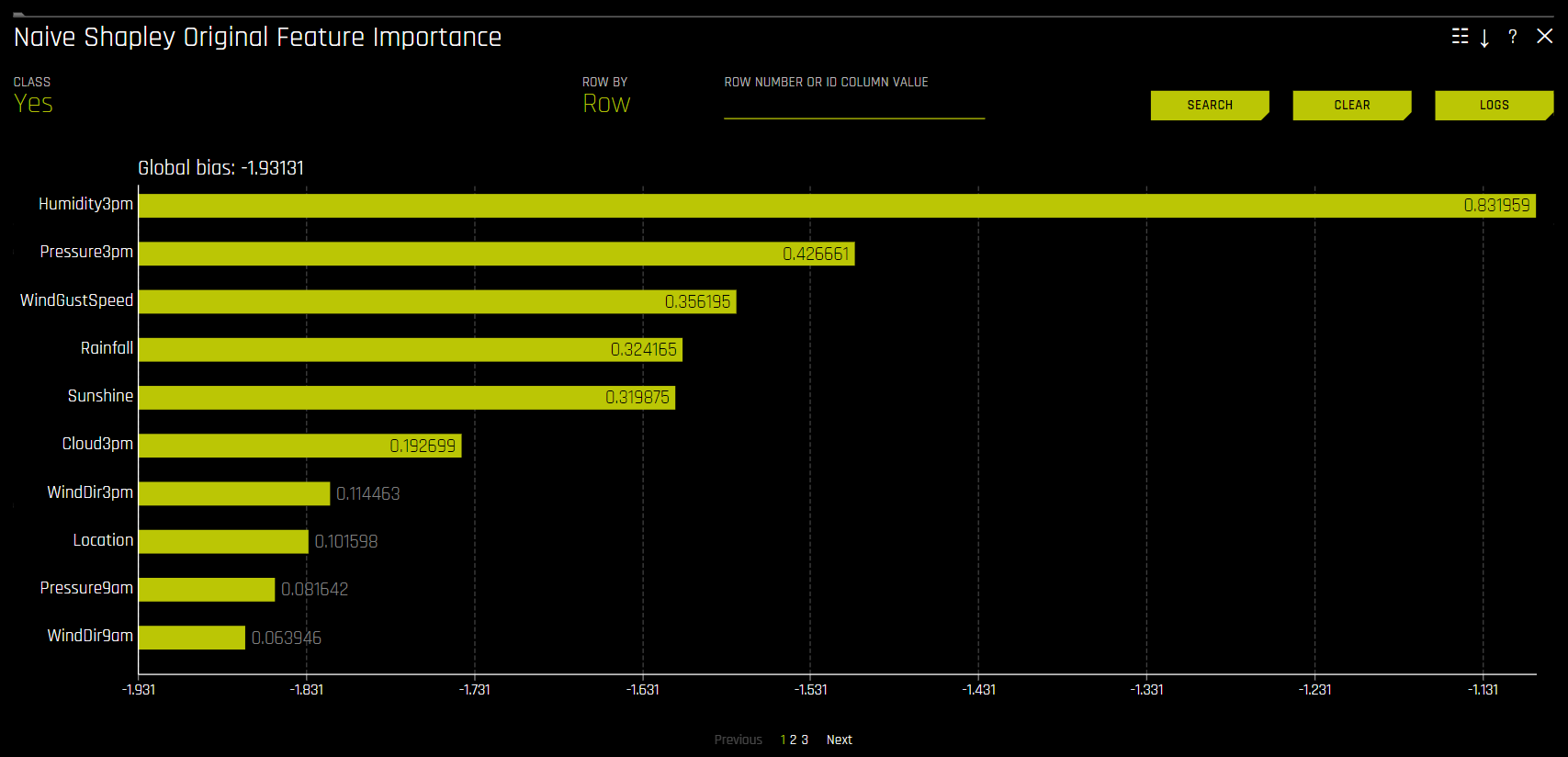
朴素 Shapley 原始特征重要性¶
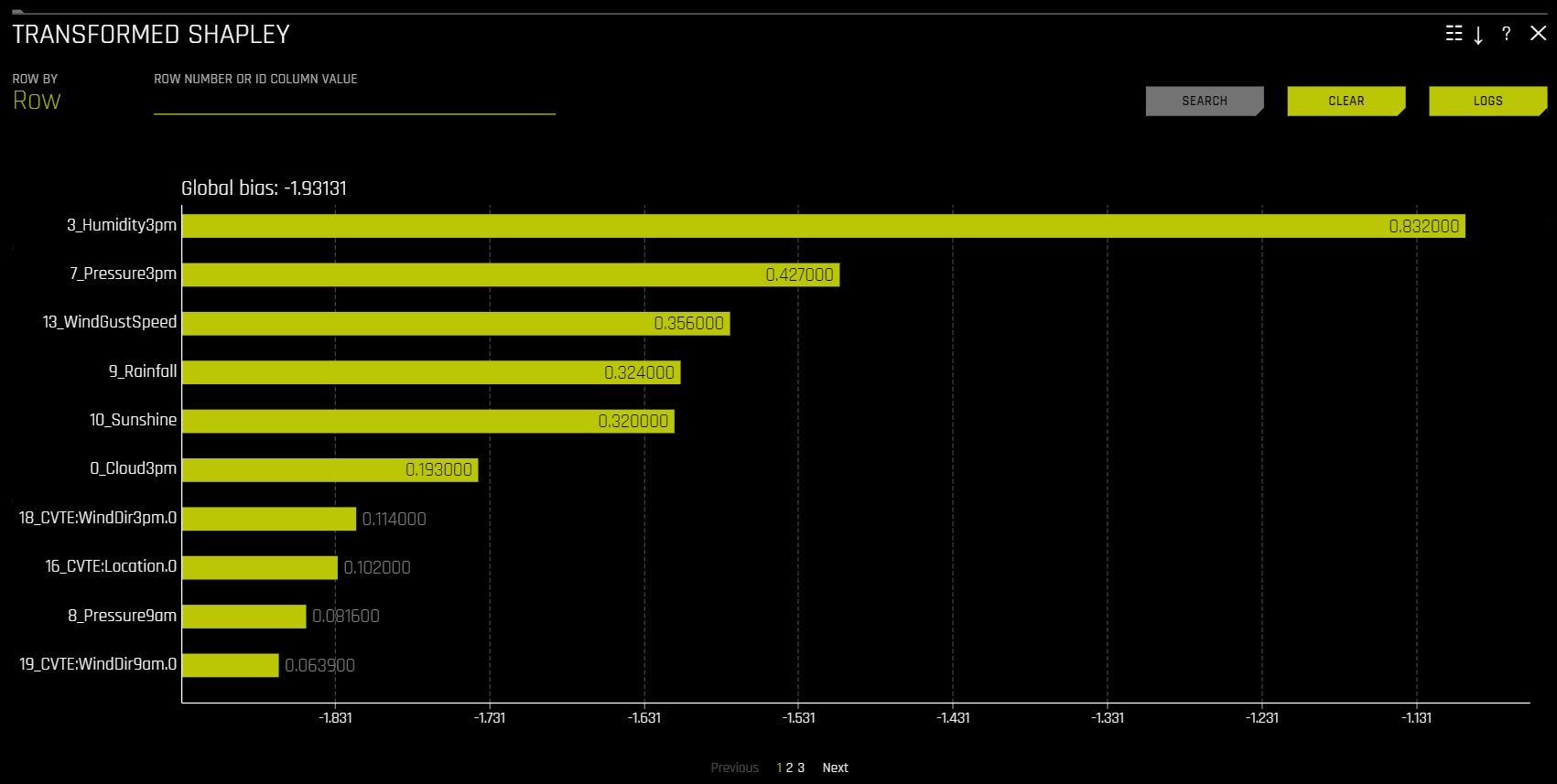
转换特征的 Shapley 值¶
特征重要性和 Shapley 图的 显示 \(n\) 个 特征 下拉列表让您能在原始特征和转换特征之间进行选择。如果其中有大量特征,则这些特征将被划分至可以单独查看的带编号页面中。请注意 :所提供的原始特征值是通过相应转换值中得到的近似值。例如,如果转换特征 \(feature1\_feature2\) 的值为 0.5,则原始特征的值(\(feature1\) 和 \(feature2\))将为 0.25。
Shapley 摘要图(原始特征)¶
Shapley 摘要图显示了数据集样本的原始特征与局部 Shapley 值的对比结果。特征值按 Shapley 值进行分箱,并将每个分箱的平均归一化特征值绘制成图。若需查看特定特征分箱的 Shapley 值、行数和平均归一化特征值,可将指针悬停在分箱上方。图例与数值特征相对应,并映射至其归一化特征值。黄色表示最低值,深橙色表示最高值。您可以点击数值特征,以查看实际特征值和对应 Shapley 值的散点图。分类特征显示为灰色,并且不提供实际值散点图。
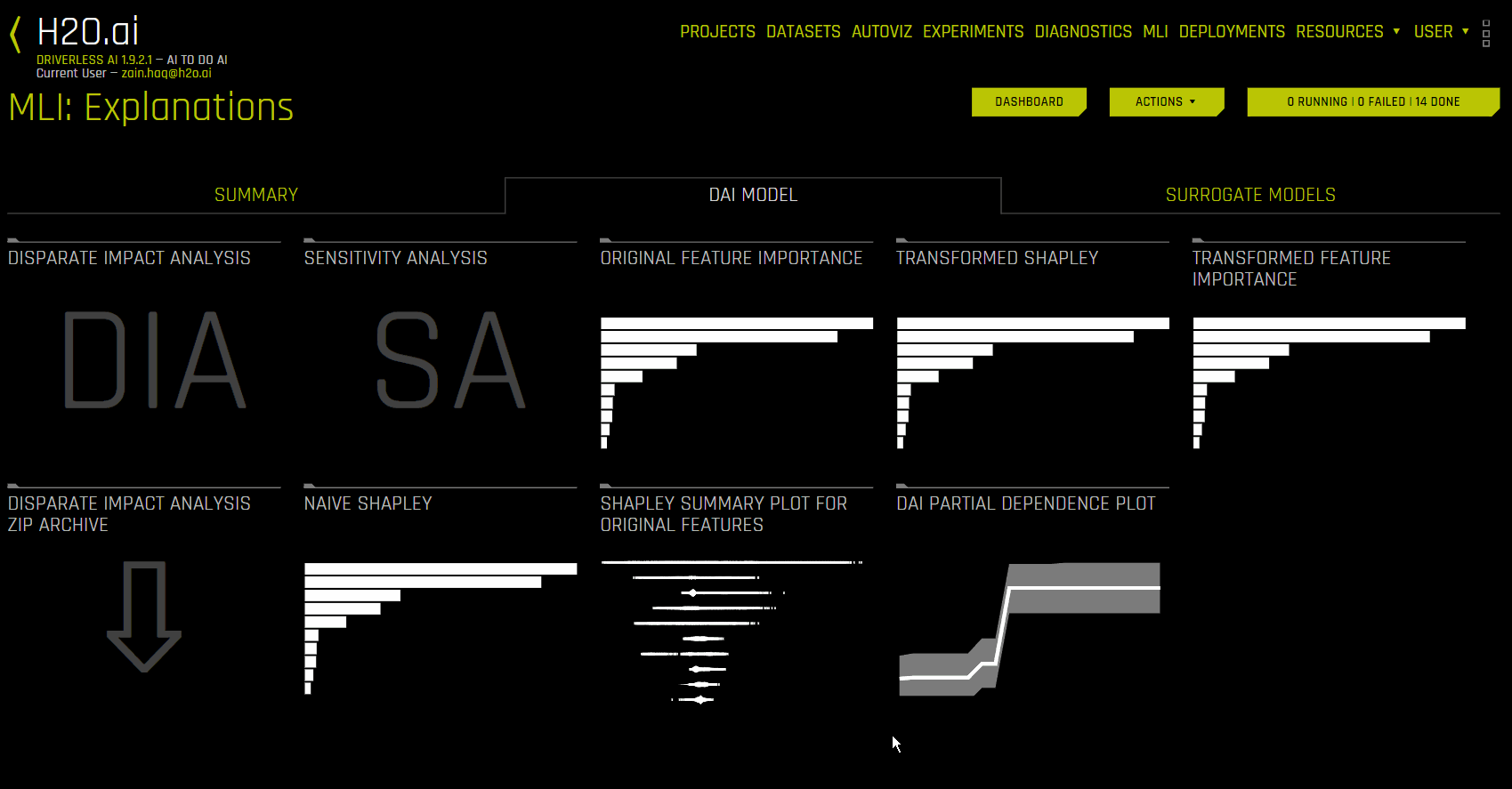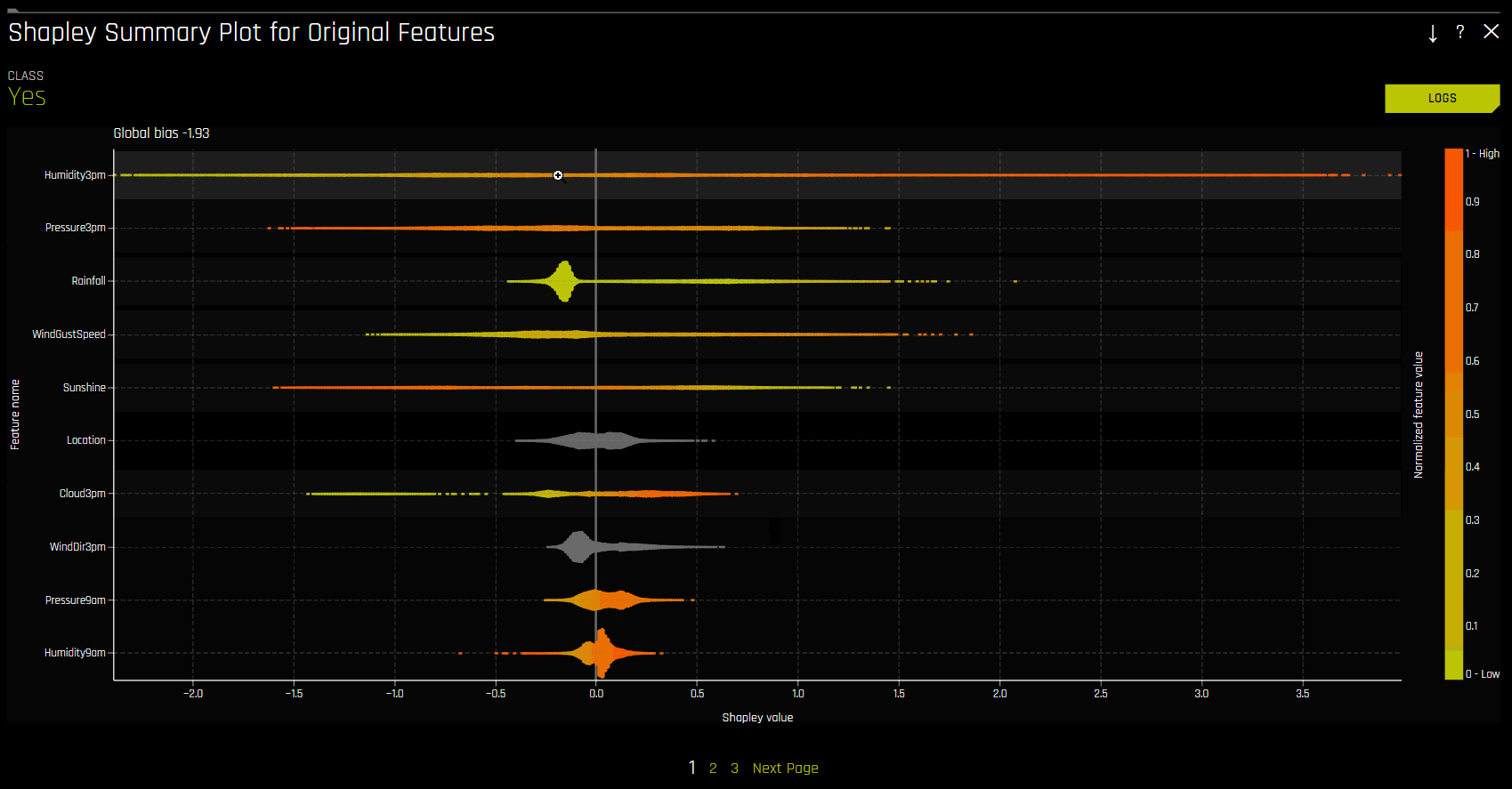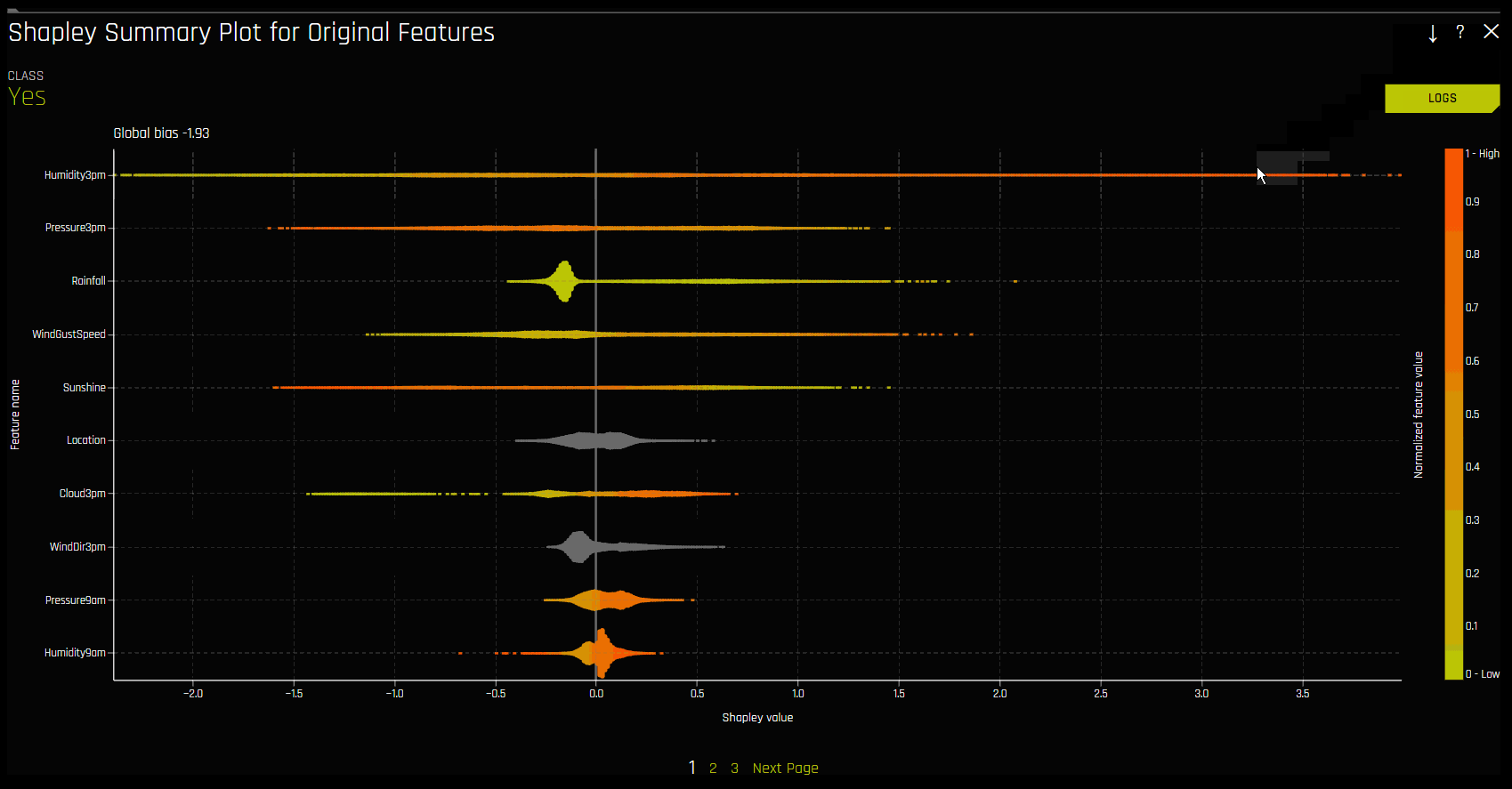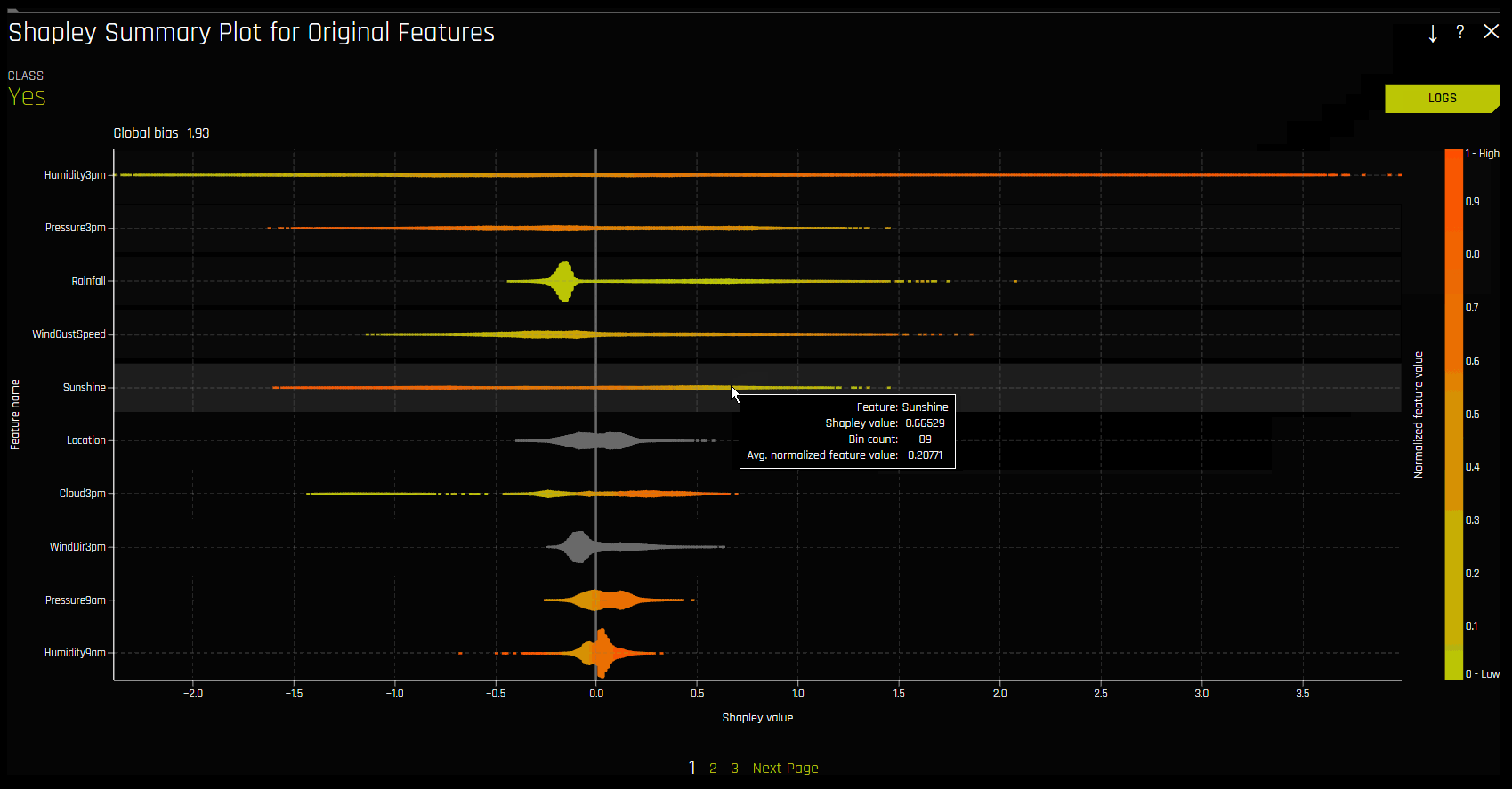
请注意:
Shapley 摘要图仅显示 Driverless AI 模型中使用的原始特征。
数据集大小和分箱数可在“解释”专家设置中进行更新。
请参阅 Shapley 摘要图解释器设置,获取“Shapley 摘要图”解释器专家设置列表。
部分依赖性图 (PDP) 和个体条件期望图 (ICE)¶
部分依赖性图和 ICE 图适用于 Driverless AI 模型和替代模型。
部分依赖性方法¶
部分依赖性用于衡量输入变量的平均模型预测结果。部分依赖性图显示机器学习响应函数如何随相关输入变量的值发生变化,同时还考虑非线性并平均所有其他输入变量的影响。《Elements of Statistical Learning》(Hastie 等,2001 年)中对部分依赖性图进行了介绍。通过将变量在其域中的平均预测结果与已知标准、领域知识和合理预期进行比较,部分依赖性图可以提高 Driverless AI 模型的透明度,并能够验证以及调试 Driverless AI 模型。
ICE 方法¶
此图适用于二元分类和回归模型。
通过使用与部分依赖性图相同的基本理念,可利用一种被称为个体条件期望图的新型部分依赖性图来为单个模型创建更具局部性的解释。Goldstein 等(2015 年)对 ICE 图进行了介绍。ICE 值是分解的部分依赖性,但是 ICE 图也是一种非线性的敏感性分析,在此图中,对单行的模型预测结果进行了度量,同时相关变量会在其域内发生变化。ICE 图使用户能够确定:模型对单行数据的处理是否超出平均模型性能一个标准偏差;与平均模型性能、已知标准、领域知识和合理期望相比,对特定行的处理是否有效;在所选行中的一个变量在其域内发生变化时,模型将如何运行。
给定输入数据行及对应的 Driverless AI 和 K-LIME 预测结果:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
以 Driverless AI 模型为 F(X),假设信用评分在训练数据中在 500 到 800 的范围内变化,并假设以 30 为增量绘制 ICE 曲线,可按照以下方法计算 ICE:
\(\text{ICE}_{credit\_score, 500} = F(30, 500, 1000)\)
\(\text{ICE}_{credit\_score, 530} = F(30, 530, 1000)\)
\(\text{ICE}_{credit\_score, 560} = F(30, 560, 1000)\)
\(...\)
\(\text{ICE}_{credit\_score, 800} = F(30, 800, 1000)\)
此处显示的一维部分依赖性图未考虑交互作用。部分依赖性图和 ICE 图之间的巨大差异表明可能存在较强的变量交互作用。在这种情况下,部分依赖性图可能会具有误导性,因为平均模型性能可能无法准确反映局部性能。
部分依赖性图 (PDP)¶
此图适用于二元分类和回归模型。
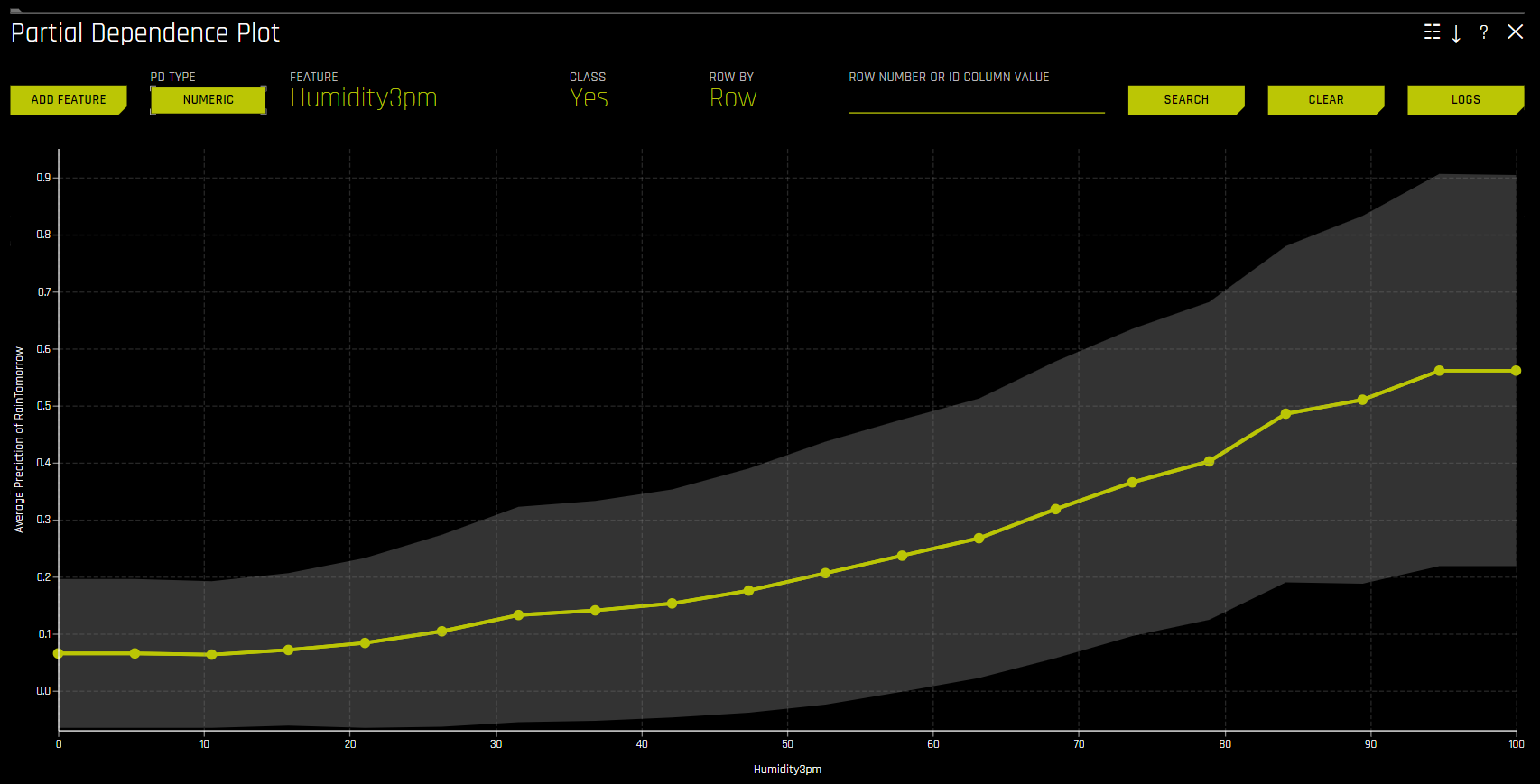
将 ICE 图叠加到部分依赖性图上,以允许将 Driverless AI 模型对某些示例或单个模型的处理与模型在相关输入变量域上的平均预测结果进行比较。
此图显示选择变量时的部分依赖性以及选择特定行时的 ICE 值。用户可以选择图表上的一点来查看此点的具体值。部分依赖性(黄色)描述了 Driverless AI 模型在输入变量域内及 +/-1 标准偏差范围内的平均预测性能。ICE(灰色)显示输入变量在其域中进行切换时单行数据的预测性能。目前,部分依赖性图和 ICE 图仅适用于最重要的十个原始输入变量。具有 20 个或更多唯一值的分类变量绝不会包含在这些绘图中。
请注意:
在实验将特征同时用作数值特征和分类特征的情况下,若需在 PDP 数值和分类分箱和 UI 图表之间进行动态切换,则启用
mli_pd_numcat_num_chartconfig.toml 设置。(默认会启用此项设置。)启用此项设置时,您可以使用mli_pd_numcat_threshold设置指定 PDP 分箱和图表选择的阈值,默认值为 11。超出范围/隐藏的 PD 或 ICE 分箱的数量可通过 PDP 解释器 oor_grid_resolution 专家设置进行指定:
请参阅 部分依赖性图解释器设置,获取 PDP 解释器专家设置列表。
按需的部分依赖性图¶
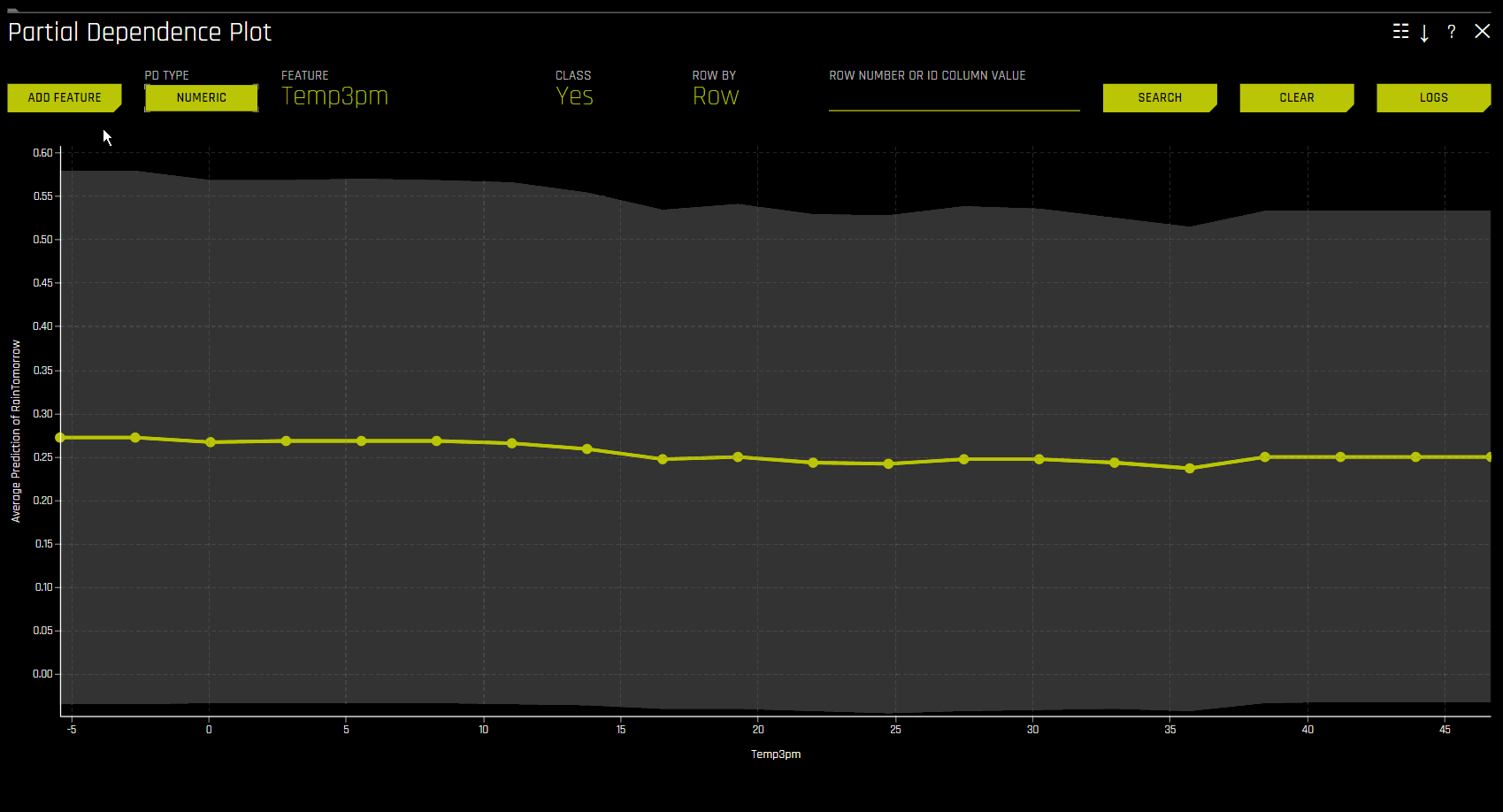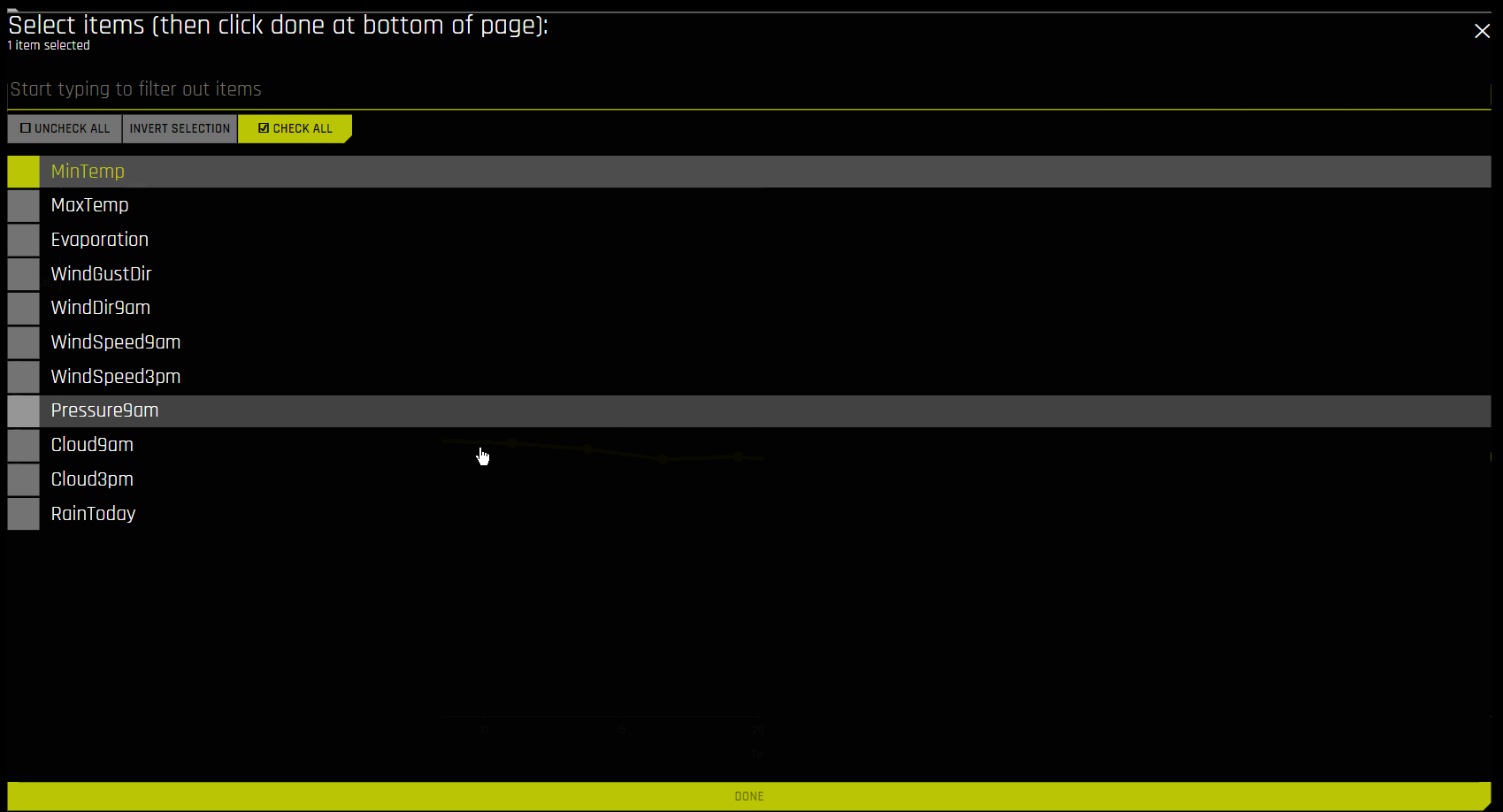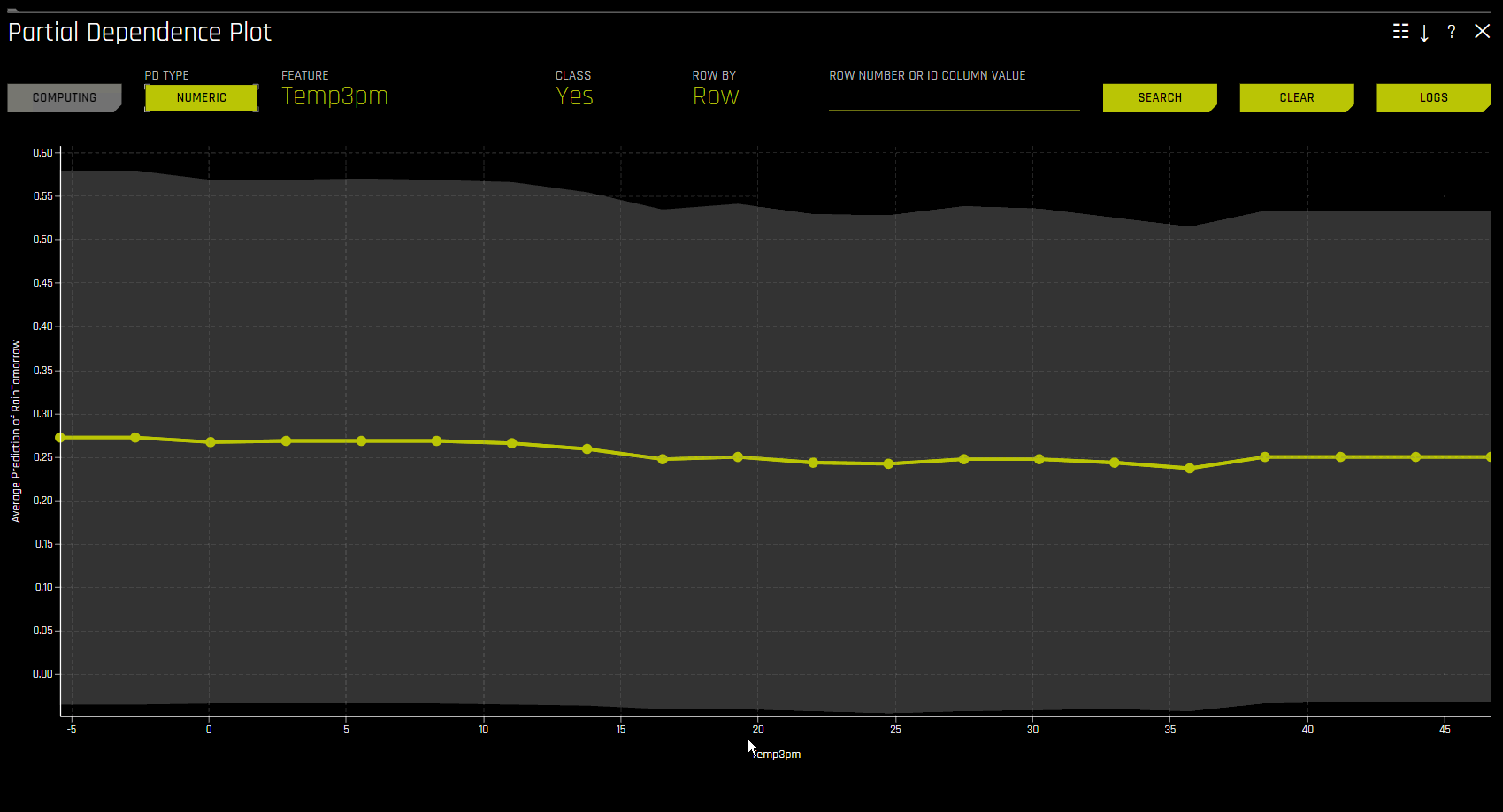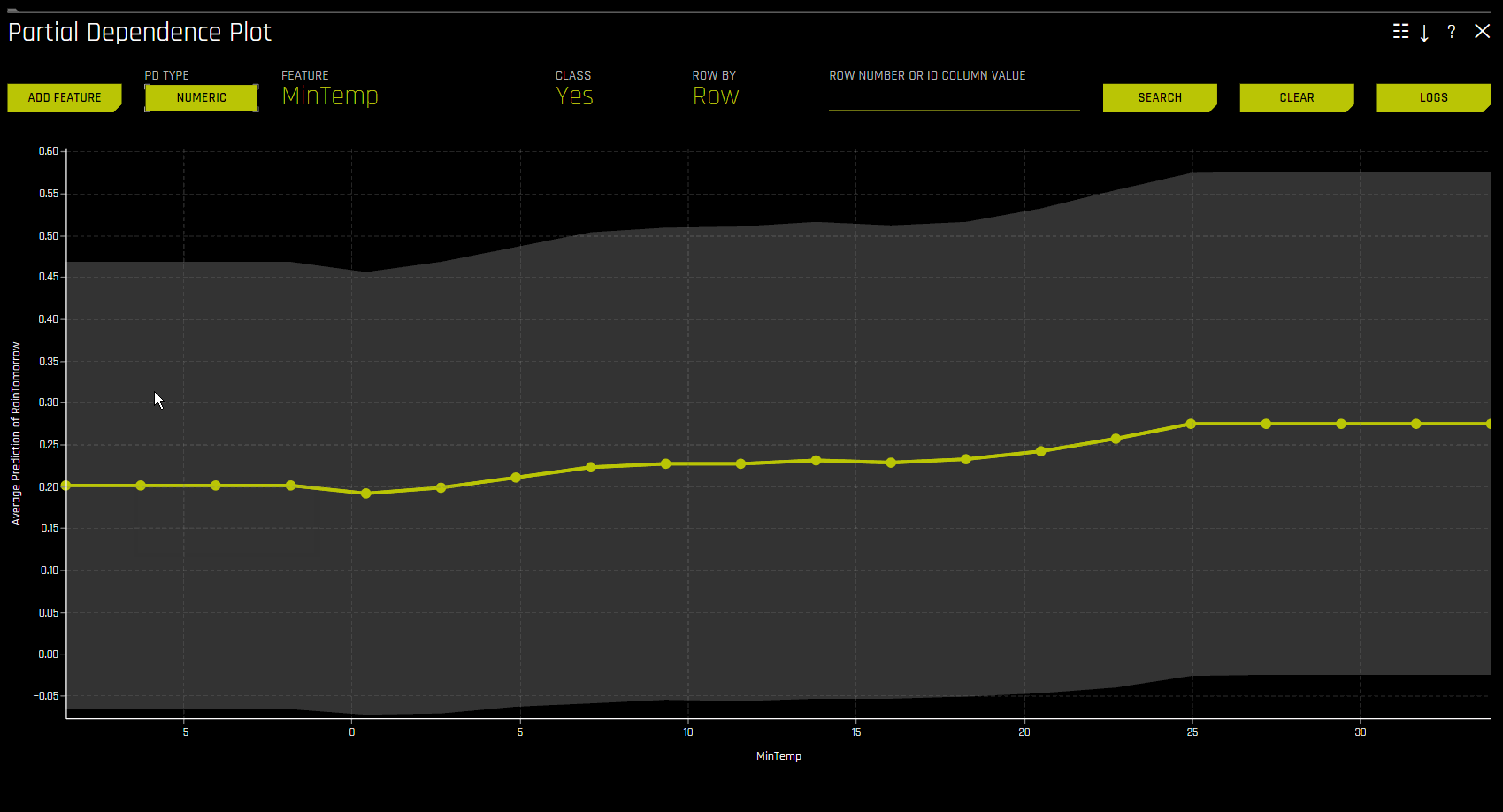
PD 按需选项让您可以选择现有特征或新特征,以根据现有解释为其计算 Driverless AI PD/ICE。通过此种方法,可使用 ad hoc 解释器计算 PD/ICE,然后运行并合并至原始 DAI PD/ICE 表示形式中。
若需使用 PD 按需选项,可点击您想要使用的解释,然后点击 DAI 模型 选项卡中的 DAI 部分依赖性图 。在 PD 图页面,点击 添加特征 按钮并选择需要计算 PD 的特征。点击 完成 以确认您的选择。Driverless AI 完成按需计算后,屏幕底部会显示一条通知。若需查看计算出的特定特征的 PD 值,可在 PD 图页面点击 特征,然后选择您想要查看其 PD 值的特征。
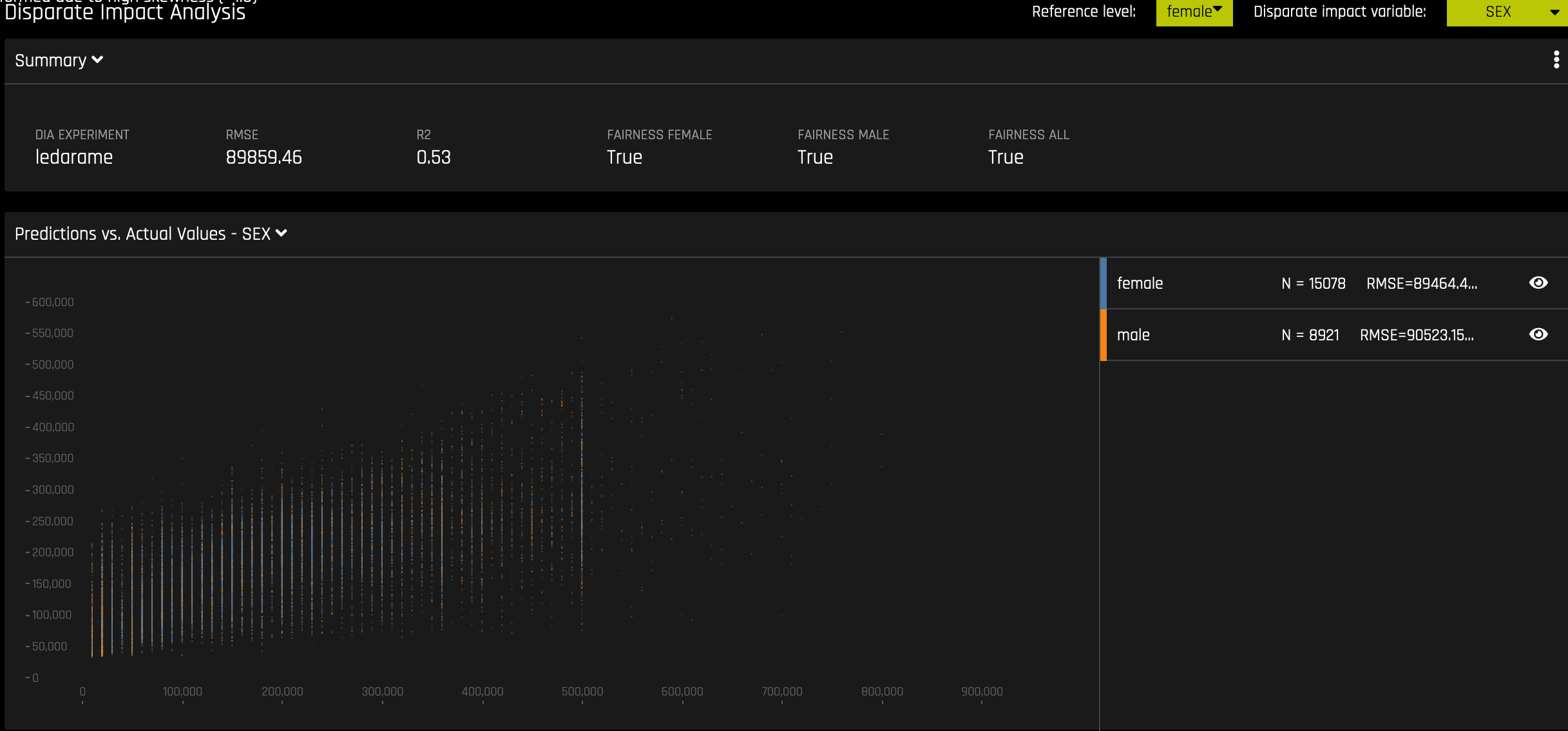
差异影响分析 (DIA)¶
此图适用于二元分类和回归模型。
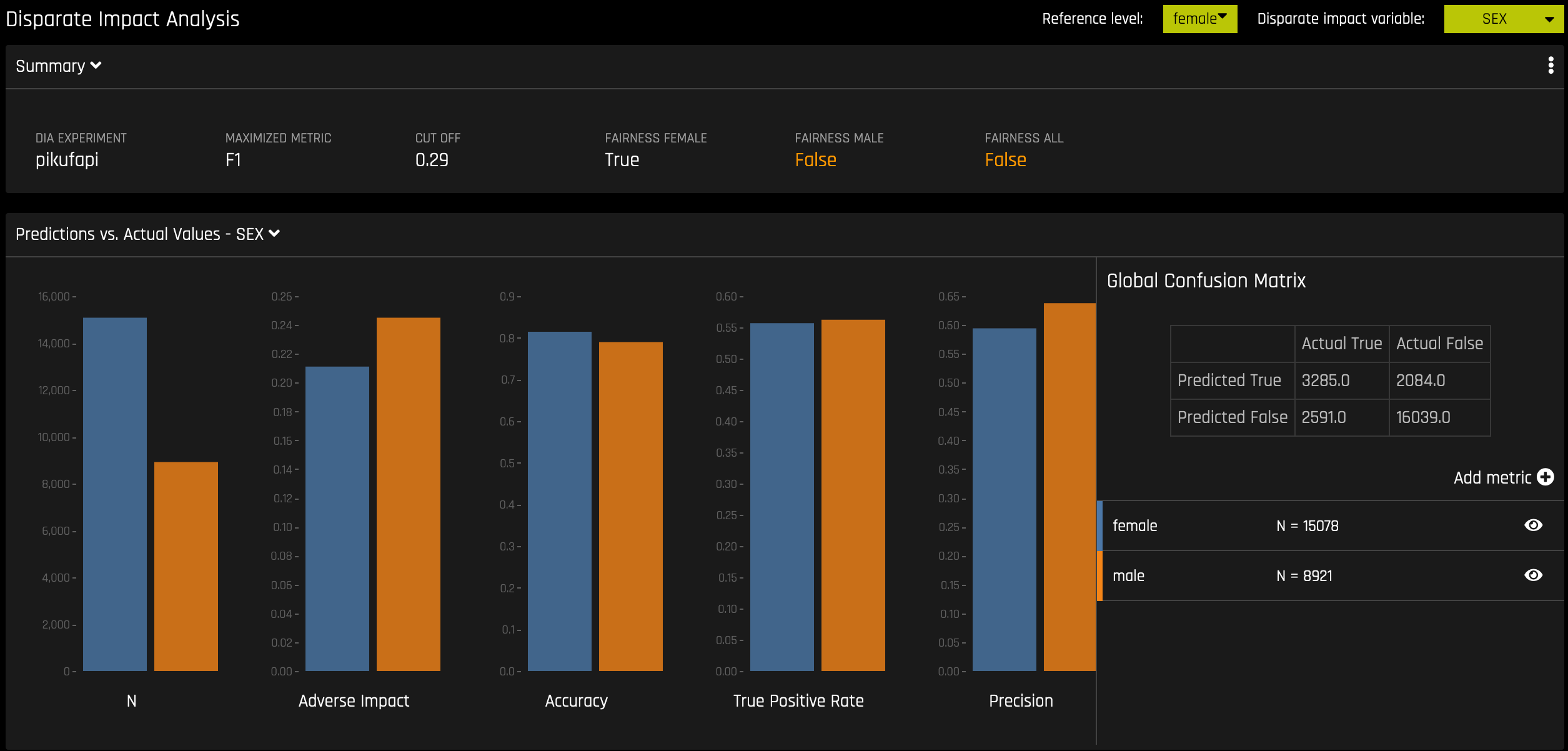
DIA 技术可用于评估公平性。在收集、处理和标记数据的过程中,模型中可能会出现偏差,因此,务必要确定模型是否会做出大量有偏差的决策,从而对某些用户造成损害。
DIA 通常通过比较非特权组和特权组的聚合度量来运行。例如,将接受潜在有害结果的非特权比例除以接受相同结果的特权组比例 – 然后将得到的比例用于确定模型是否有偏差。请参阅 概述 一节,确定与指定参考级别和用户定义的阈值相比,分类级别(例如,针对女性的公平性)是否公平。整体公平性 选项值为 True 或 False,只有当与参考级别相比,所有类别都公平时,此值才为 True。
差异影响测试最适合用于 Driverless AI 中受约束的模型,例如线性模型、单调 GBM 模型或 RuleFit 模型。DIA 在大多数情况下报告的平均组指标可能会遗漏局部判别的情况,特别是在复杂、不受约束的模型中,这些模型可以根据数据属性的细微变化以非常不同的方式处理单个模型。
DIA 让您能指定 差异影响变量 (所分析的组变量)、 参考级别 (与其他组进行比较的组级别),以及 用户定义的差异阈值 。作为分析的一部分,提供了多份表格:
组指标:每组计算出的聚合指标。例如,每组的真正例率。
组差别:通过将
metric_for_group除以reference_group_metric计算得出。如果此数值超出用户指定的阈值,则会观测到差异。组奇偶校验:通过将用户定义的阈值应用于差别值,可将上述计算转换为 True 值或 False 值,从而在组差异的基础上进行组奇偶校验。
根据既定的五分之四规则,用户定义的阈值默认设置为 0.8 和 1.25。这些阈值通常会检测模型对非参照组的处理是否比对参照组的处理更顺利或更不顺利(相差 20% 左右)(平均而言)。建议用户设置用户定义的阈值,以符合其组织对公平性阈值的指示。
指标 – 二元分类¶
以下是二元分类 DIA 所使用的误差指标和奇偶校验的公式。请注意,在下表中:
tp = 真正例
fp = 假正例
tn= 真负例
fn = 假负例
误差指标/奇偶校验指标 |
公式 |
不利影响 |
(tp + fp) / (tp + tn + fp + fn) |
准确度 |
(tp + tn) / (tp + tn + fp + fn) |
真正例率 |
tp / (tp + fn) |
精确率 |
tp / (tp + fp) |
特异性 |
tn / (tn + fp) |
负例预测值 |
tn / (tn + fn) |
假正例率 |
fp / (tn + fp) |
错误发现率 |
fp / (tp + fp) |
假负例率 |
fn / (tp + fn) |
错误遗漏率 |
fn / (tn + fn) |
奇偶校验 |
说明 |
|
|---|---|---|
I 型奇偶校验 |
FDR 奇偶校验和 FPR 奇偶校验中的公平性 |
|
II 型奇偶校验 |
FOR 奇偶校验和 FNR 奇偶校验中的公平性 |
|
均等几率 |
FPR 奇偶校验和 TPR 奇偶校验中的公平性 |
|
监督式公平性 |
I 型和 II 型奇偶校验中的公平性 |
|
整体公平性 |
所有指标的所有奇偶校验的公平性,其中:
|
|
指标 – 回归¶
以下是回归 DIA 所使用的指标:
均值预测:所有预测结果的平均值
标准偏差预测:所有预测结果的标准偏差
最大值预测:具有最高值的预测结果
最小值预测:具有最低值的预测结果
R2:表示由一个或多个自变量解释的因变量方差比例
RMSE:表示模型预测值与实际观测值之间的差异
公平性指标¶
DIA 计算二元模型的边际误差 (ME)、不良影响率 (AIR) 和标准化均数差 (SMD) 以及回归模型的标准化均数差。
ME 表示获得有利结果的对照组成员百分比与获得有利结果的受保护组成员百分比之间的差值:
\[\text{ME} \equiv 100 \cdot (\text{PR} (\hat{y} = 1 \vert X_c = 1) - \text{Pr}(\hat{y} = 1 \vert X_p = 1))\]
其中:
\(\hat{y}\) 是模型决策数。
\(X_c\) 和 \(X_p\) 是根据某些人口统计属性创建的二元标记。
\(c\) 是对照组。
\(p\) 是受保护组。
\(Pr(\cdot)\) 是条件概率运算符。
AIR 等于获得有利结果的受保护组比例与获得有利结果的对照组比例之比。
\[\text{AIR} \equiv \frac{Pr(\hat{y} \; = 1 \vert X_p = 1)}{Pr(\hat{y} \; = 1 \vert X_c = 1)}\]
其中:
\(\hat{y}\) 是模型决策数。
\(X_p\) 和 \(X_c\) 是根据某些人口统计属性创建的二元标记。
\(c\) 是对照组。
\(p\) 是受保护组。
\(Pr(·)\) 是条件概率运算符。
SMD 用于评估连续特征的差异,例如就业分析中的收入差异或贷款的利率差异:
\[\text{SMD} \equiv \frac{\bar{\hat y_p} - \bar{\hat y_c}}{\sigma_{\hat y}}\]
其中:
\(\bar{\hat y_p}\) 是受保护组平均结果的差异。
\(\bar{\hat y_c}\) 是对照组的结果。
\(\sigma_{\hat y}\) 表示群体的标准偏差。
注解
更多关于如何在 Driverless AI 中实现 DIA 的信息,请参见 https://www.frontiersin.org/articles/10.3389/frai.2021.695301/full。
尽管分类实验和回归实验的 DIA 过程相同,但返回的信息将因所解释的实验类型而异。回归实验的分析返回实际值与预测值对比图,而二元分类实验的分析返回混淆矩阵。
建议用户考虑使用解释仪表板来理解和增广差异影响分析中的结果。除了作为公平性工具的既定用途外,用户可能还想要考虑将差异影响分析用于更为广泛的模型调试。例如,用户可以分析所提供的混淆矩阵和组指标,以获取 Driverless AI 中重要的非人口统计型特征。
请参阅 差异影响分析解释器设置,获取“DIA 摘要图”解释器专家设置列表。
平均预测差异为被考虑组的平均预测值除以参照组的平均预测值。
更多关于组差异和奇偶校验的信息,请参阅 https://h2oai.github.io/tutorials/disparate-impact-analysis/#5。
分类实验¶
回归实验¶
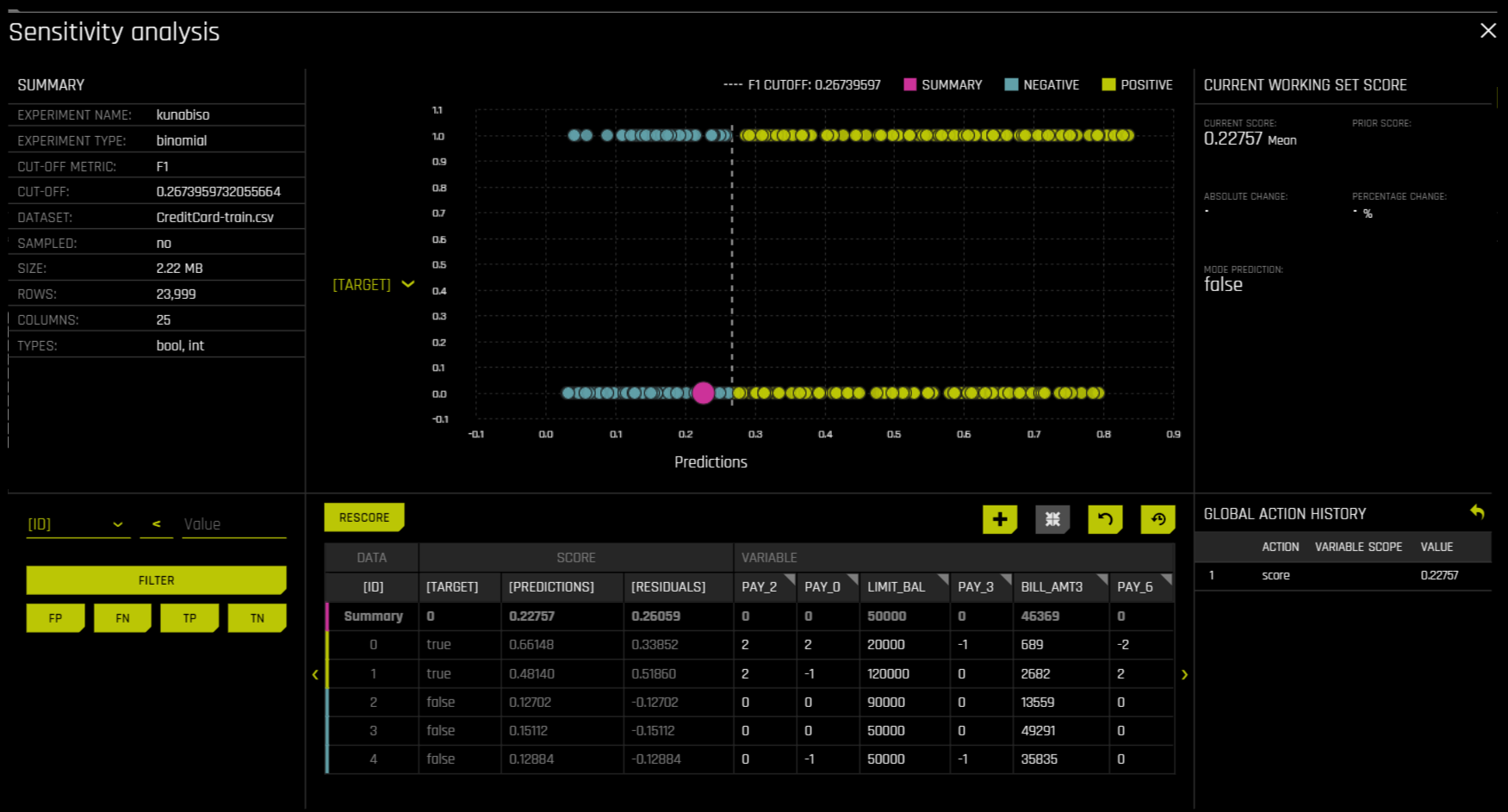
敏感性分析 (SA)¶
请注意:敏感性分析 (SA) 仅适用于二元分类实验和回归实验。
敏感性分析(或”What If 假设分析”)是一种简易而强大的工具,可用于模型调试、解释、公平性和安全。SA 背后的概念直接而简单:使用单行、多行或可能相关的模拟值的整个数据集对经过训练的模型进行评分,并将模型的新结果与使用原始数据得到的预测结果进行比较。
除了传统的评估方法,对机器学习模型预测结果的敏感性分析可能是机器学习模型中最重要的验证方法。敏感性分析研究在有意干扰数据时或在数据中模拟其他变化时,模型性能和输出是否保持稳定。机器学习模型可能对输入变量值的微小变化做出截然不同的预测。例如,当查看决定财务决策的预测结果时,SA 可帮助您理解在模型中更改最重要的输入变量所带来的影响以及更改社会敏感变量(如性别、年龄、种族等)所带来的影响。当重要变量值发生变化时,如果模型以合理且符合预期的方式发生变化,则可增强对模型的信任。同样,如果敏感变量值的变化对模型的影响很小,则可表明模型预测结果的公平性。
此页面使用 What If 工具 来显示 SA 信息。
此页面的顶部包括:
实验摘要
指定列的预测结果。更改 Y 轴上的列以查看此列的预测结果。
当前运行的评分集。每次重新评分时,此评分集将随之更新。
此页面的底部包括:
用于筛选分析的筛选工具。选择不同的列、预测结果或残差。设置筛选器类型(
<,>, 等)。选择按假正例、假负例、真正例或真负例进行筛选。评分表。在应用筛选器后,点击 资源 按钮以更新评分表。此图表还让您能添加或移除变量、切换主图表聚合、重置数据以及在重置数据时删除全局历史记录。
在此页面上所执行操作的当前历史记录。选择操作农民画点击所显示的“删除”按钮,即可删除各个操作。
用例 1:对单行或一小组行使用 SA
本节介绍在使用单行或一小组行对经过训练的模型进行评分时,如何将 SA 用于解释、调试、安全或公平性。
解释:更改变量的值,然后对模型进行重新评分。查看原始预测结果与新模型预测结果之间的差异。如果变化很大,则更改后的变量将具有局部重要性。
调试:更改变量的值,然后对模型进行重新评分。查看原始预测结果与新模型预测结果之间的差异,并确定变量值的变化是否使模型更准确或更不准确。
安全:更改变量的值,然后对模型进行重新评分。查看原始预测结果与新模型预测结果之间的差异。如果变化很大,则用户可以进行以下操作:例如,通知其 IT 部门此变量可能被对抗攻击利用,或通知模型制作者应使此变量更加正则化。
公平性:更改人口统计型变量的值,然后对模型进行重新评分。查看原始预测结果与新模型预测结果之间的差异。如果变化很大,则用户可以考虑使用其他模型、使模型更加正则化或应用事后偏差修正方法。
随机:将变量设置为随机值,然后对模型进行重新评分。此操作可帮助您发现之前可能没有想到的方面。
用例 2:对整个数据集和经过训练的模型使用 SA
本节介绍在对整个数据集经过训练的模型和经过训练的预测模型进行评分时,如何将 SA 用于解释、调试、安全或公平性。
财务压力测试:假设用户希望了解当更改整个数据集以模拟所有客户均处于更大财务压力之下的情况(例如较低的 FICO 分数、较低的存款余额、较高的失业率等)时,贷款违约率将如何变化(根据他们所训练的违约概率模型)。更改整个数据集中变量的值,并查看原始数据和新数据的平均模型评分(违约概率)中的 变化百分比 。然后,用户可以使用所发现的这些信息和外部信息及流程来了解机构是否拥有足够的现金来应对所模拟的危机。
随机 :将变量设置为随机值,然后对模型进行重新评分。此操作让用户发现他们之前可能没有考虑到的方面。
其他资源¶
Driverless AI 模型的敏感性分析 :此 ipynb 使用 UCI 信用卡默认数据 来执行敏感性分析和测试模型性能。
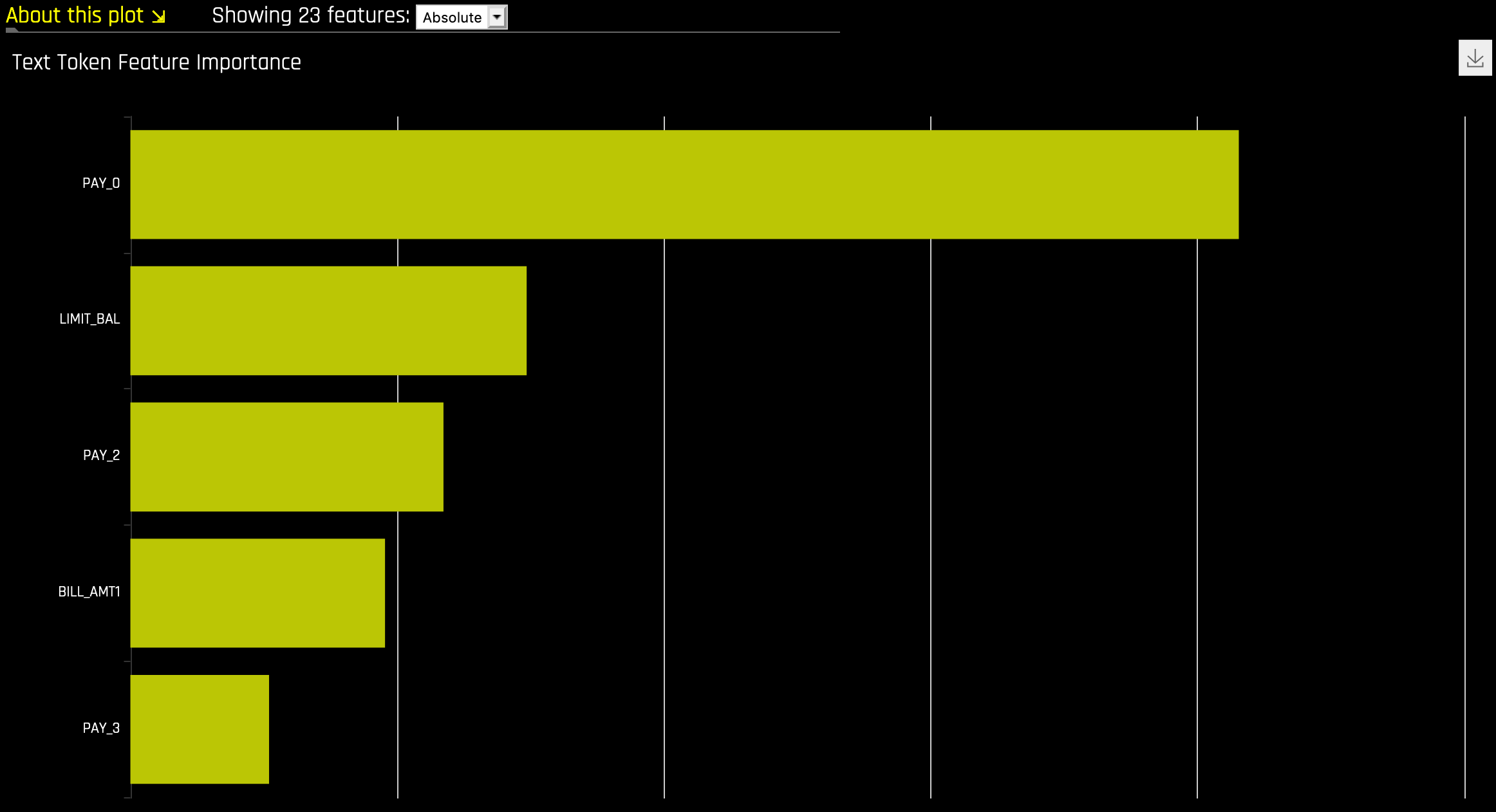
排列特征重要性¶
注解
此图仅适用于二元分类和回归实验。
为解释启用排列重要性时,无论是为原始实验还是为 AutoDoc 运行,排列重要性都将作为解释过程的一部分运行。
基于排列的特征重要性显示如果对某个特征的值进行排列,模型的性能会发生多大变化。如果特征的预测能力很小,则混排此特征的值应该对模型性能几乎没有影响。但是,如果特征的预测能力很高,则混排此特征的值应该会降低模型性能。排列特征前后的模型性能差异可提供此特征的绝对排列重要性。
替代模型图¶
本节介绍“替代模型”选项卡中可供使用的绘图。
K-LIME 和 LIME-SUP¶
MLI 屏幕包括 K-LIME (K 局部可解释模型不可知解释)或 LIME-SUP (基于监督分区的局部可解释模型和影响)图表。当您从实验页面解释模型时,默认可使用 K-LIME 图表。创建新解释时,可以选择使用 LIME-SUP 作为 LIME 方法。请注意,这些图表本质上是相同的,但是 K-LIME/LIME-SUP 的区别可提供对模型解释过程中使用的 LIME 方法的见解。
K-LIME 方法¶
此图适用于二元分类和回归模型。
K-LIME 是 Ribeiro 等人(2016 年)提出的 LIME 方法的变体。K-LIME 会生成可提高 Driverless AI 模型透明度的全局和局部解释,并允许通过分析所提供的绘图、比较全局和局部解释、与已知标准、领域知识和合理期望进行比较,从而验证和调试模型性能。
K-LIME 将使用所有训练数据创建全局替代 GLM 模型,并在由训练数据中的 k-means 聚类形成的样本上创建多个局部替代 GLM 模型。k-means 所使用的特征从随机森林替代模型的变量重要性中选择。k-means 所使用的特征数量是随机森林替代模型的变量重要性中前 25% 变量的最小值,以及可用于 k-means 的最大变量数量(由用户在 config.toml 设置中为 mli_max_number_cluster_vars 设定)。(请注意,如果数据集中的特征数量小于或等于 6,则所有特征均被用于 k-means 聚类。)通过在 config.toml 文件中将 use_all_columns_klime_kmeans 设置为 true,可关闭之前的设置,从而将所有特征用于 k-means。所有受到罚分的 GLM 替代模型均已经过训练,可对 Driverless AI 模型的预测结果进行建模。可通过网格搜索选择局部解释所使用的聚类数量,在搜索过程中,Driverless AI 模型预测结果和所有局部 K-LIME 模型预测结果之间的 \(R^2\) 值、准确度和预测结果均可用于调试和开发对 Driverless AI 模型性能的解释。
全局 K-LIME 模型的参数可表明整体线性特征重要性和整体平均方向,输入变量会以此方向影响 Driverless AI 模型预测结果。全局模型还用于为非常小的聚类 (\(N < 20\)) 生成解释,在这些聚类中,不适合拟合局部线性模型。
聚类内的线性模型参数可用于描述局部区域,给出局部区域中重要变量的平均描述,以及了解输入变量影响 Driverless AI 模型预测结果的平均方向。对于聚类内的某个点,局部线性模型截距和各系数与其各自输入变量值的乘积之和即为 K-LIME 预测结果。通过将 K-LIME 预测结果分解为单个系数与输入变量值的乘积,可以确定变量的局部线性影响。此乘积有时被称为原因码,可用于为 Driverless AI 模型性能创建解释。
在以下示例中,通过评估和分解局部线性模型来创建原因码。
给定输入数据行及对应的 Driverless AI 和 K-LIME 预测结果:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
局部线性模型:
\(\small{y_\text{K-LIME} = 0.1 + 0.01 * debt\_to\_income\_ratio + 0.0005 * credit\_score + 0.0002 * savings\_account\_balance}\)
可以看到,每个变量的局部线性贡献为:
debt_to_income_ratio: 0.01 * 30 = 0.3
credit_score: 0.0005 * 600 = 0.3
savings_acct_balance: 0.0002 * 1000 = 0.2
每个局部贡献均为正数,因此使得 Driverless AI 模型对 H2OAI_predicted_default 的预测为正数,即 0.85。考虑到每个贡献的值,可以推导出 Driverless AI 决策的原因码。debt_to_income_ratio 和 credit_score 将是两个最大的负例原因码,其次是 savings_acct_balance.
局部线性模型截距和各系数与相应值的乘积之和即为 K-LIME 预测结果。此外可以看到,这些线性解释合理地表示了此单个模型的非线性模型性能,因为 K-LIME 预测结果在 Driverless AI 模型预测结果的 5.5% 以内。这些信息已编码为英语语言规则,可通过点击 解释 按钮进行查看。
与所有基于线性模型的 LIME 解释一样,局部解释本质上是线性的,并与基线预测或截距有偏移,其表示惩罚线性模型残差的平均值。当然,复杂的非线性相应函数的线性近似并不总是能创建合适的解释,需敦促用户检查 K-LIME 图、局部模型 \(R^2\) 以及 K-LIME 预测结果的准确度,以了解 K-LIME 局部解释的有效性。当给定点或点集的 K-LIME 准确度相当低时,这可能表明极度非线性的性能或在 Driverless AI 响应函数的此局部区域中存在强烈或高度的交互。在 K-LIME 线性模型不能很好地拟合 Driverless AI 模型的情况下,对于局部模型性能而言,非线性的 LOCO 特征重要性值可能是更好的解释工具。由于 K-LIME 局部解释依赖于 k-means 聚类的创建,因此极为广泛的输入数据或输入变量之间较强的相关性也可能会降低 K-LIME 局部解释的质量。
LIME-SUP 方法¶
此图适用于二元分类和回归模型。
LIME-SUP 从原始变量方面解释已训练的 Driverless AI 模型的局部区域。局部区域由决策树替代模型的每个叶节点路径决定,而不是由原始 LIME 中被模拟、被干扰的观测值样本决定。对于每个局部区域,使用原始输入数据和 Driverless AI 模型的预测结果训练局部 GLM 模型。随后,此局部 GLM 模型的参数可被用于生成 Driverless AI 模型的近似局部解释。
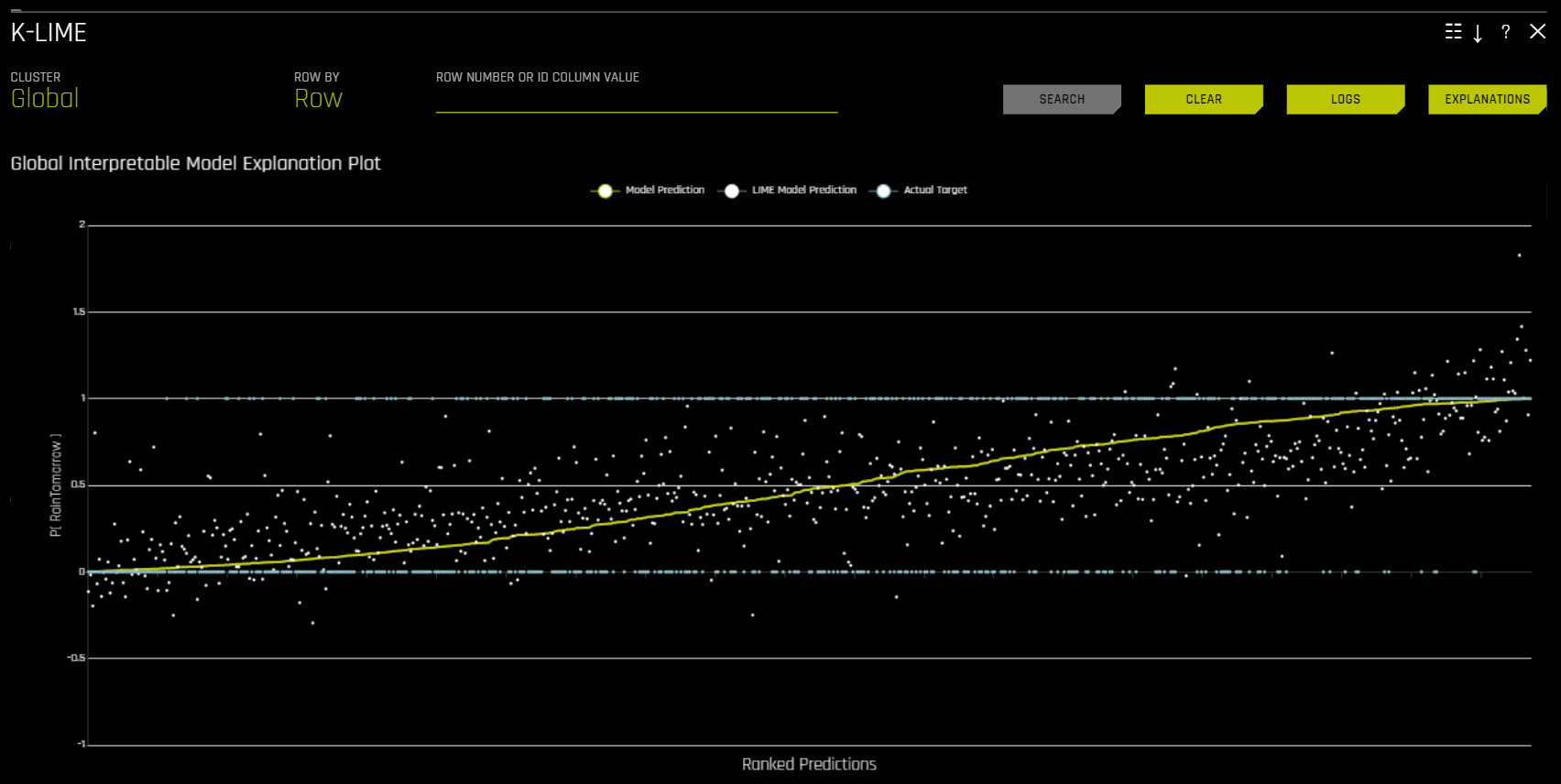
全局可解释模型解释图
此图按照 Driverless AI 模型预测结果的排序顺序显示 Driverless AI 模型预测结果和 LIME 模型预测结果。此图为交互式图表。将鼠标悬停在 模型预测结果、LIME 模型预测结果 或 实际目标 单选按钮上,可放大显示所选择的预测结果。也可点击这些单选按钮来禁用此图表中的视图。您还可将鼠标悬停在图表的任一点上,以查看此值的 LIME 原因码。默认情况下,此图会显示全局 LIME 模型的信息,但是您可以更改视图以显示特定聚类的局部模型结果。LIME 图还可直观地显示 Driverless AI 模型的线性度和 LIME 解释的可信度。局部线性模型的近似估算越接近于 Driverless AI 模型预测结果,Driverless AI 模型的线性度就越高,LIME 局部线性模型生成的解释就越准确。
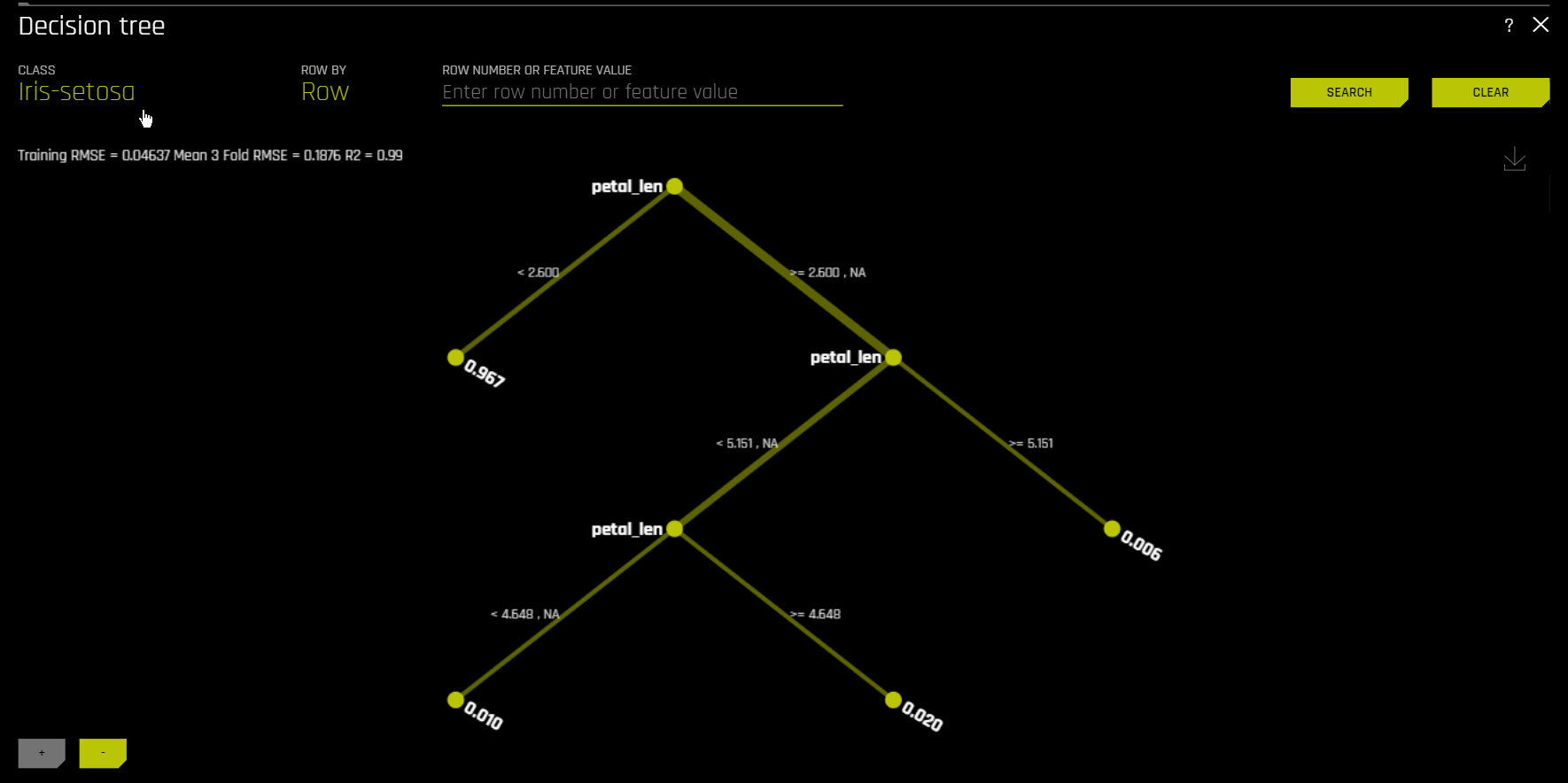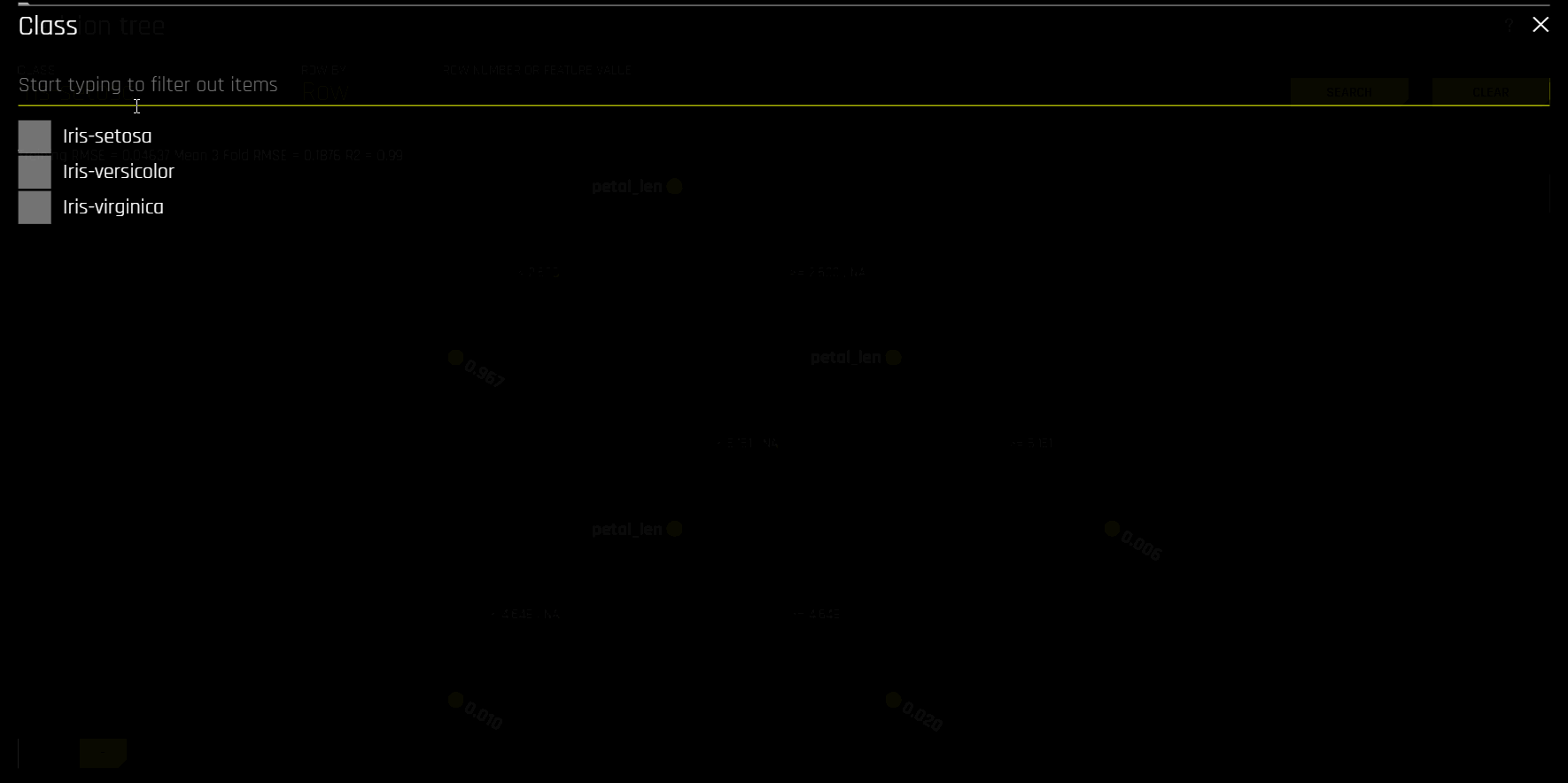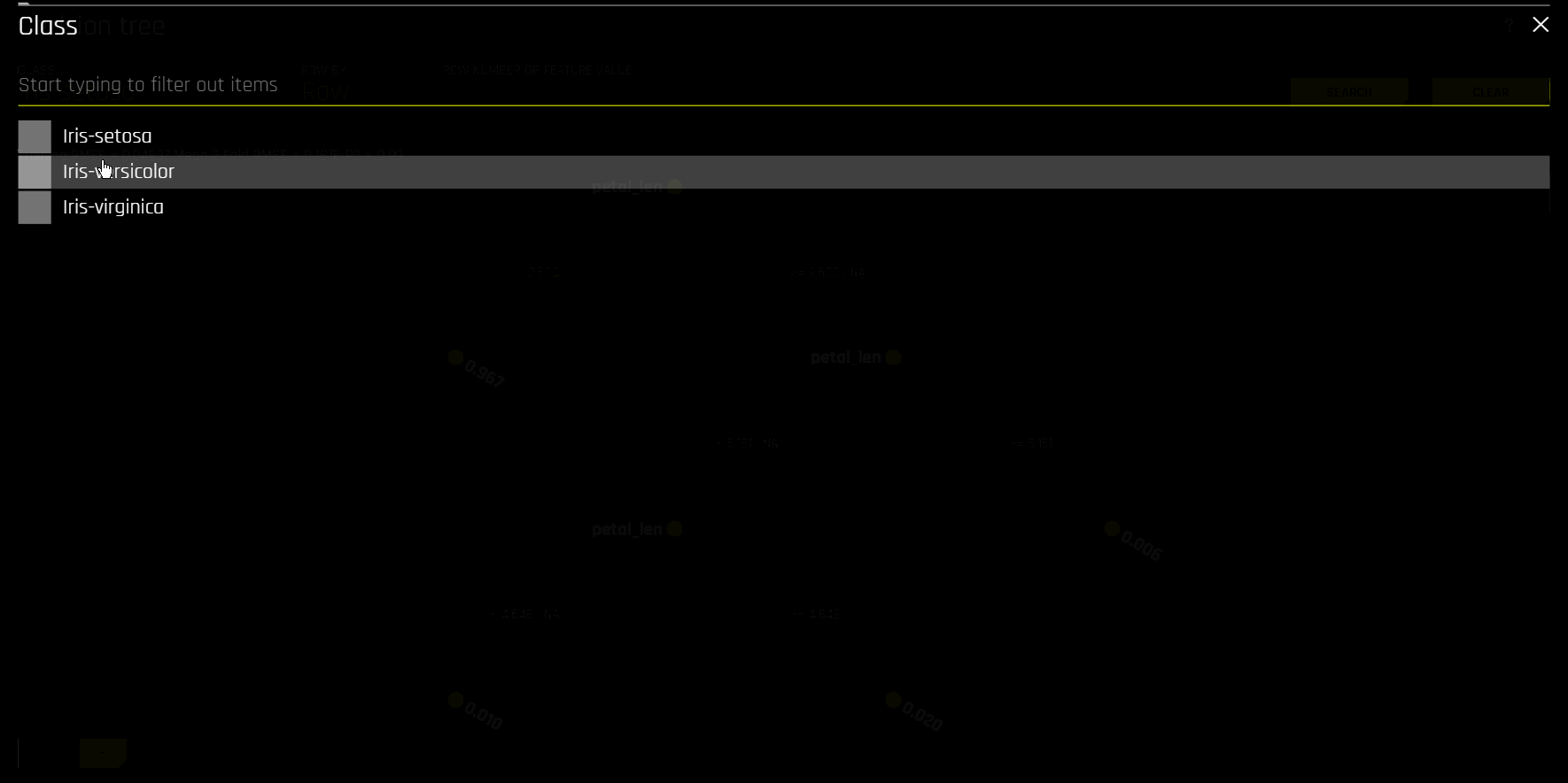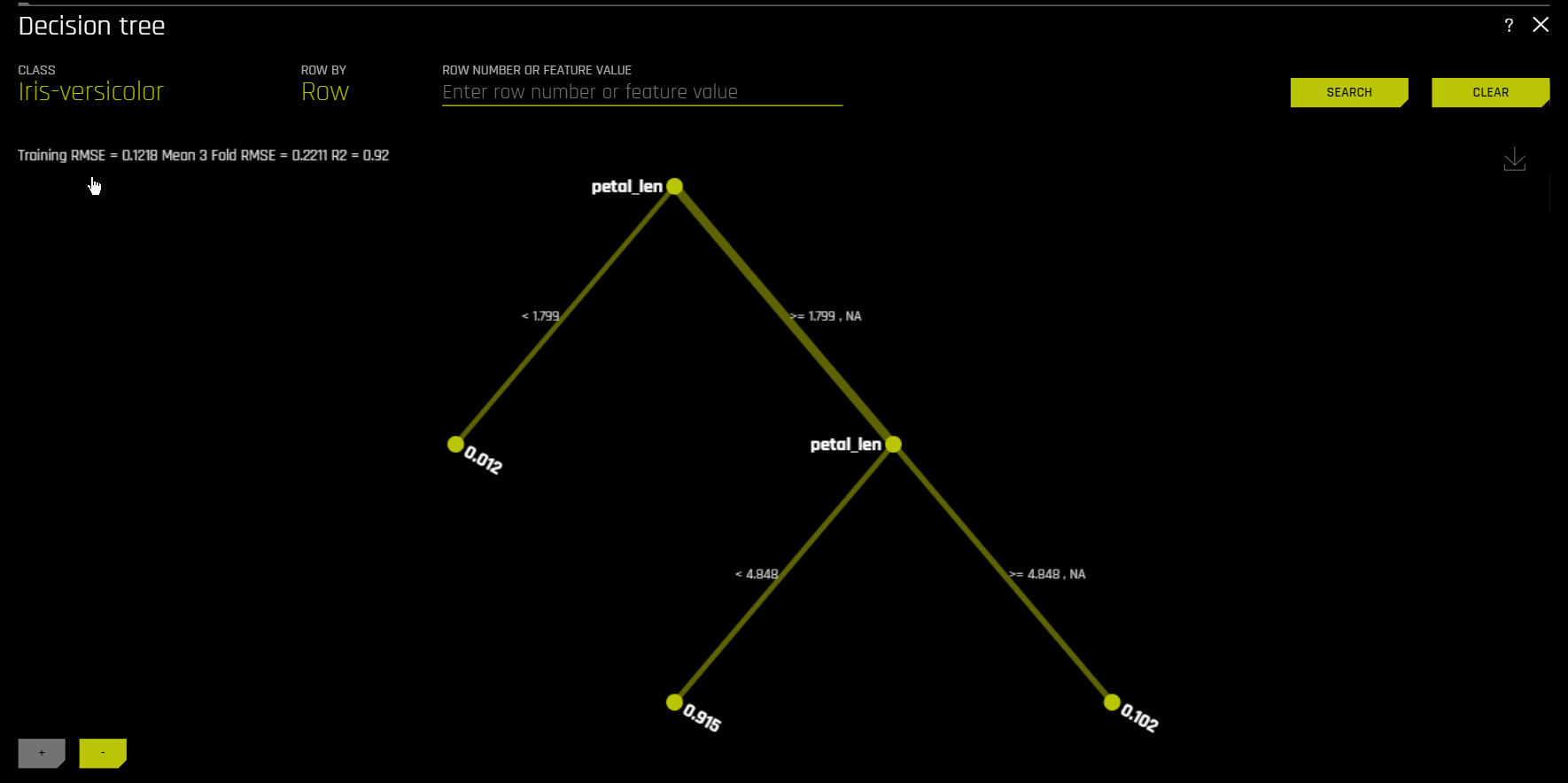
替代决策树¶
通过显示复杂 Driverless AI 模型决策过程的 近似 流程图,决策树替代模型可提高 Driverless AI 模型的透明度。此模型还显示 Driverless AI 模型中最重要的变量以及最重要的交互。通过将显示的决策过程、重要变量和重要交互与已知标准、领域知识和合理期望进行比较,决策树模型可用于对 Driverless AI 模型进行可视化处理、验证和调试。已知此模型至少可以追溯至 1996 年(Craven 和 Shavlik)。
替代模型是一项数据挖掘和处理技术,在此模型中,用一个通常较为简单的模型来解释另一个通常更为复杂的模型或现象。对于我们学习过的函数 \(g\) 和预测结果集 \(g(X) = \hat{Y}\),我们可以训练一个替代模型 \(h\): \(X,\hat{Y} \xrightarrow{\mathcal{A}_{\text{surrogate}}} h\),使得 \(h(X)\) 近似等于 \(g(X)\). 为保持可解释性,\(h\) 的假设集通常仅限用于线性模型或决策树。
为了在 Driverless AI 中提供解释,将考虑 \(g\) 以表示整个管道,包括特征转换和模型,并且替代模型为决策树 (\(h_{\text{tree}}\))。用户还必须注意,很难保证 \(h_{\text{tree}}\) 能准确表示 \(g\). 系统将显示 \(h_{\text{tree}}\) 的 RMSE,以评估 \(h_{\text{tree}}\) 和 \(g\) 之间的拟合程度。
通过显示 \(g\) 决策过程(如下图所示)的近似流程图,\(h_{\text{tree}}\) 可用于提高 \(g\) 的透明度。
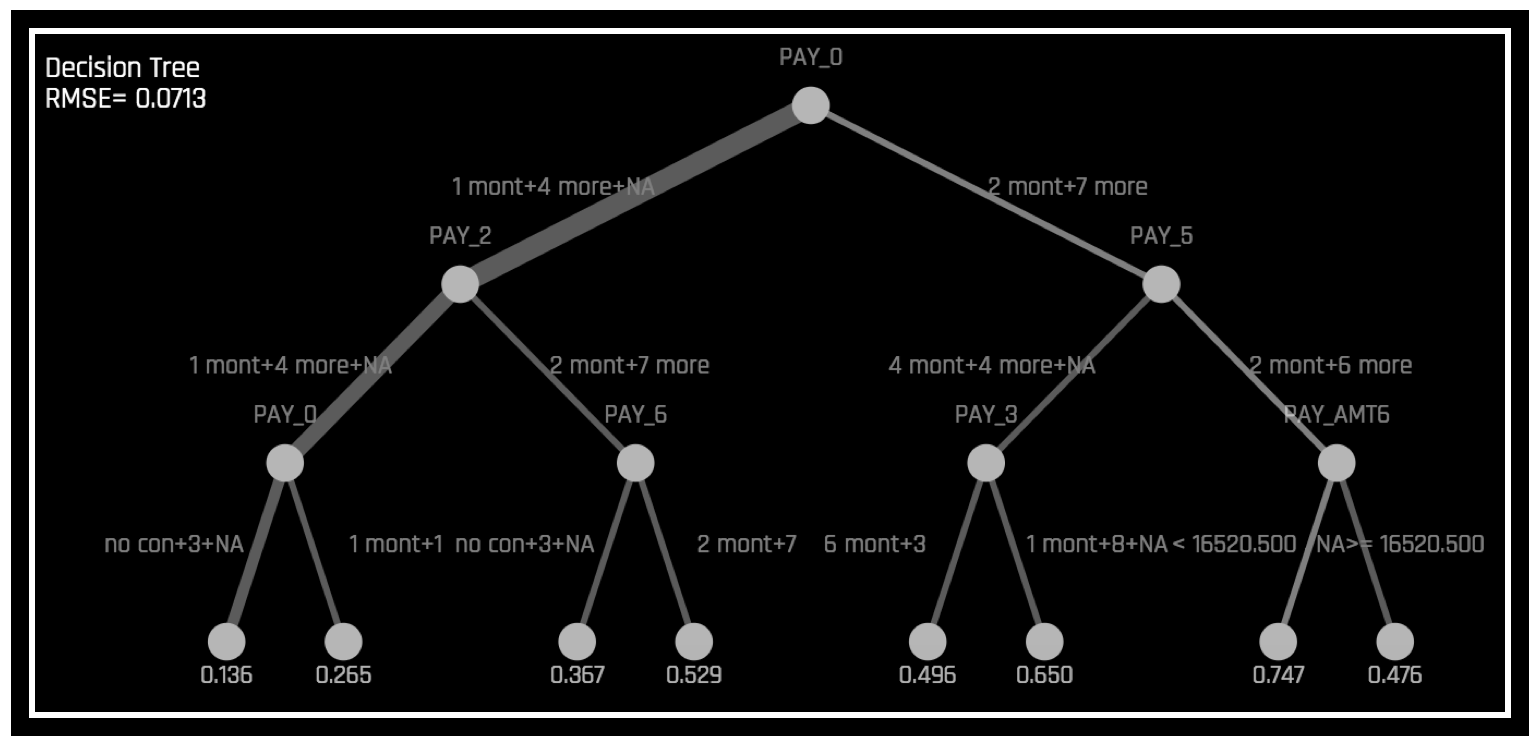
\(h_{\text{tree}}\) 还可显示 \(g\) 中可能较为重要的特征和最为重要的交互。通过将显示的决策过程、重要特征和重要交互与已知标准、领域知识和合理期望进行比较,\(h_{\text{tree}}\) 可用于对 \(g\) 进行可视化处理、验证和调试。
上图显示违约概率模型 \(g\) 示例的决策树替代模型,\(h_{\text{tree}}\),此模型通过 Driverless AI 使用 UCI 存储库信用卡违约数据创建(请参阅 https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset)。由于在 \(h_{\text{tree}}\) 初始拆分中的位置以及其在 \(h_{\text{tree}}\) 第三层中第二次出现,PAY_0 特征可能是 \(g\) 中最重要的特征。PAY_0 和 PAY_2 之间以及 PAY_0 和 PAY_5 之间的第一级交互以及多个第二级交互均具有可见性。\(h_{\text{tree}}\) 中最低概率叶节点的决策路径(上图左下角)显示以下信息:根据 \(h_{\text{tree}}\),按时偿还第一 (PAY_0) 和第二个月 (PAY_2) 账单的客户最不可能违约。此路径边缘厚度表明这是 \(h_{\text{tree}}\) 中十分常见的一条决策路径。\(h_{\text{tree}}\) 中最高概率叶节点的决策路径(上图右数第二个)显示以下信息:根据 \(h_{\text{tree}}\),逾期偿还第一 (PAY_0) 和第五 (PAY_5) 个月账单的客户以及第六次还款 (PAY_AMT6) 少于 16520 的客户最有可能违约。此路径边缘厚度表明这是 \(h_{\text{tree}}\) 中相对罕见的一条决策路径。当使用 k-LIME 图选择数据的观测值时,\(h_{\text{tree}}\) 还可提供一定程度的局部可解释性。当选择单个观测值 \(x^{(i)}\) 时,其在 \(h_{\text{tree}} 中的路径会突出显示。当分析 :math:\) 的逻辑或有效性时,\(x^{(i)}\) 在 \(h_{\text{tree}}\) 中的路径可能会有所帮助。
MLI 分类法:决策树替代模型¶
可解释性范围:
决策树替代模型一般提供全局可解释性。
决策树的属性用于解释复杂的 Driverless AI 模型的全局属性,例如重要特征、交互和决策过程。
适当的响应函数复杂性:决策树替代模型可以为具有几乎任何程度复杂性的模型创建解释。
理解与信任:
决策树替代模型促进了理解和透明度,因为此模型可提供对复杂模型内部机制的见解。
当重要特征、交互和决策路径符合人类领域知识和合理期望时,它们会增进信任、责任和公平性。
应用领域:决策树替代模型为不可知模型。
决策树替代模型图例¶
此图适用于二元分类模型、多类分类模型以及回归模型。
在决策树图中,高亮行显示最高概率叶节点的路径,并表明影响 Driverless AI 模型对此行的预测结果的全局重要变量和交互。点击此路径的终端节点,可以查看特定路径的规则。
请注意:请参阅 替代决策树解释器设置,获取“替代决策树”解释器专家设置列表。
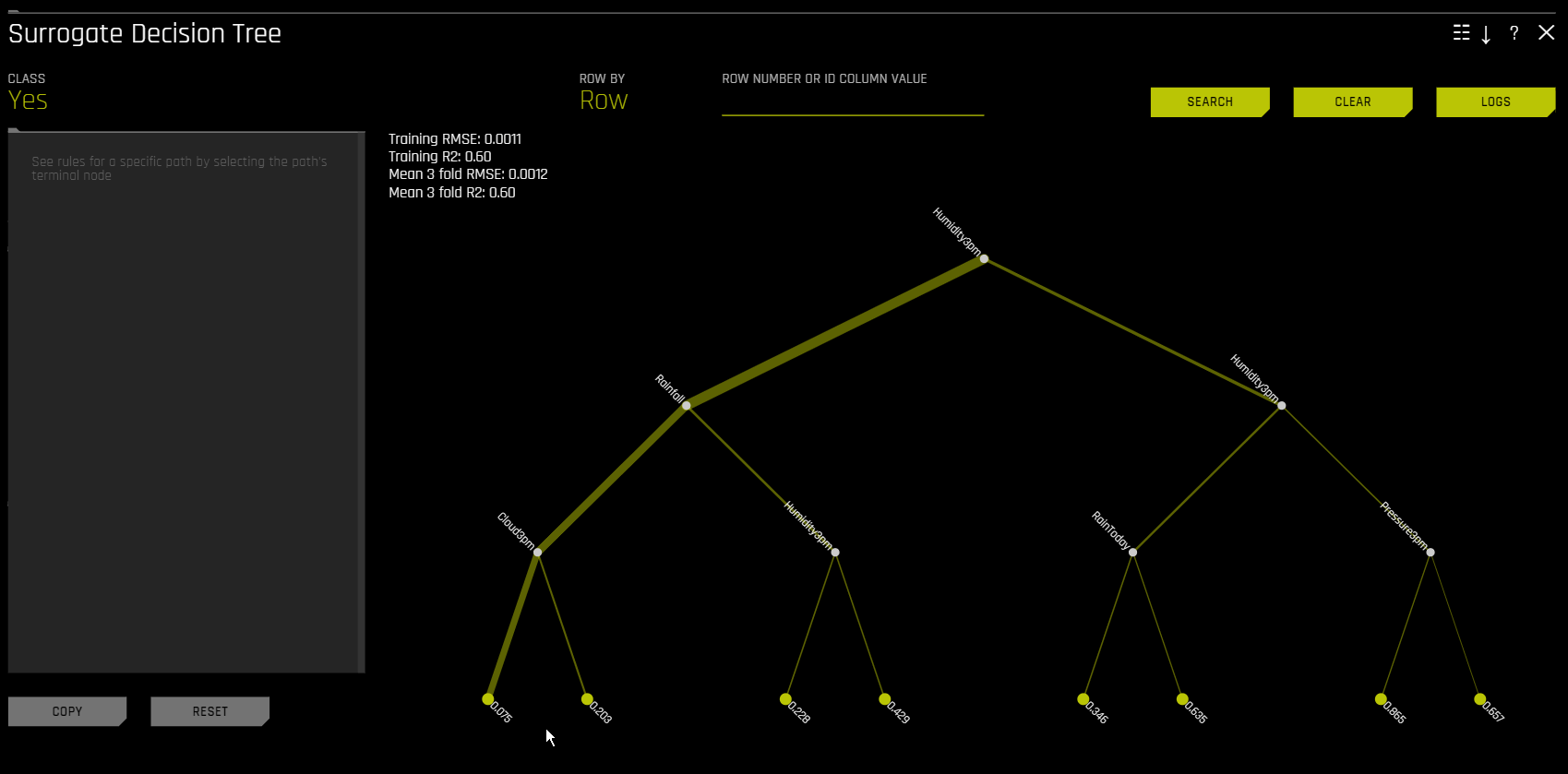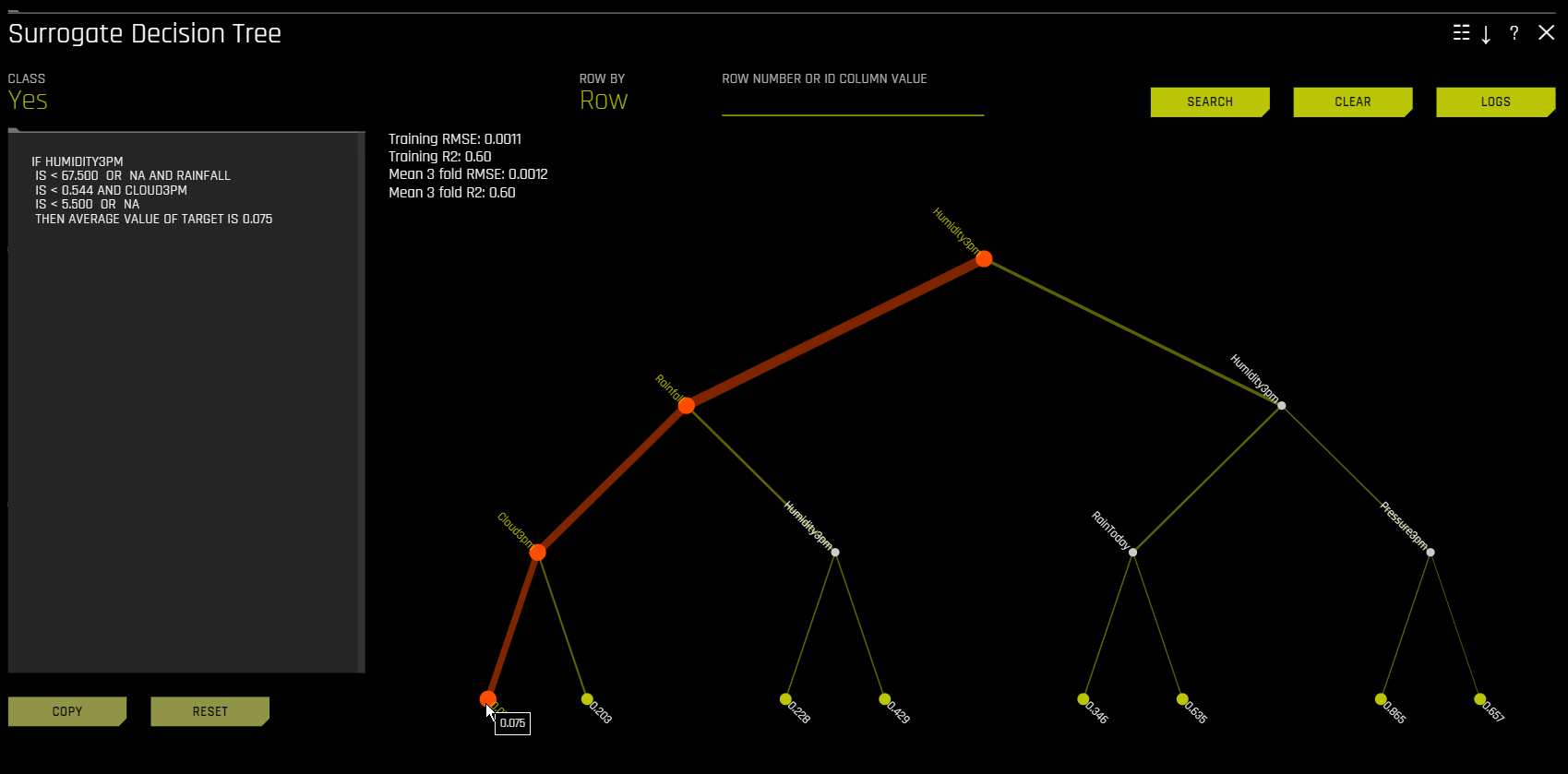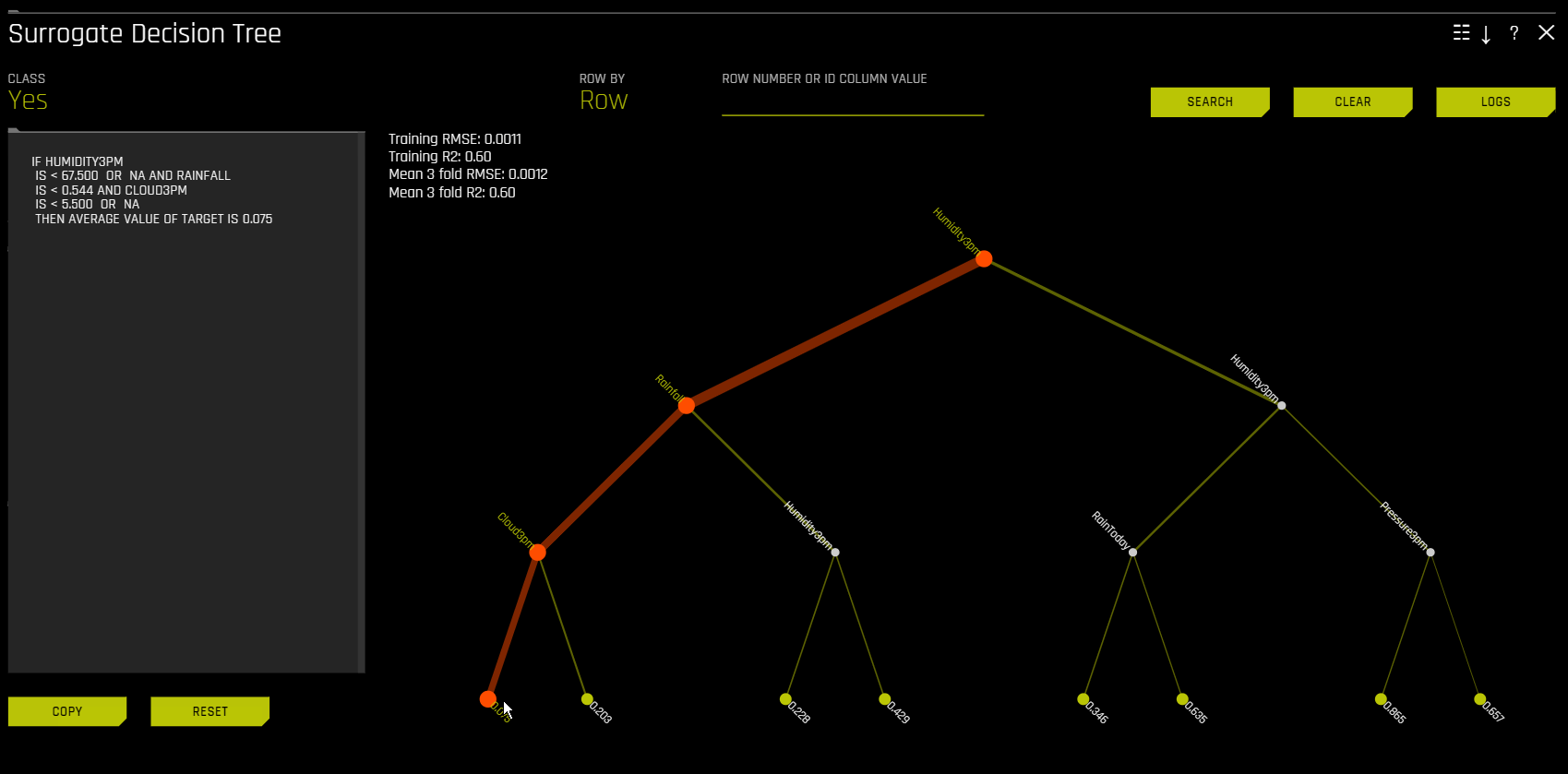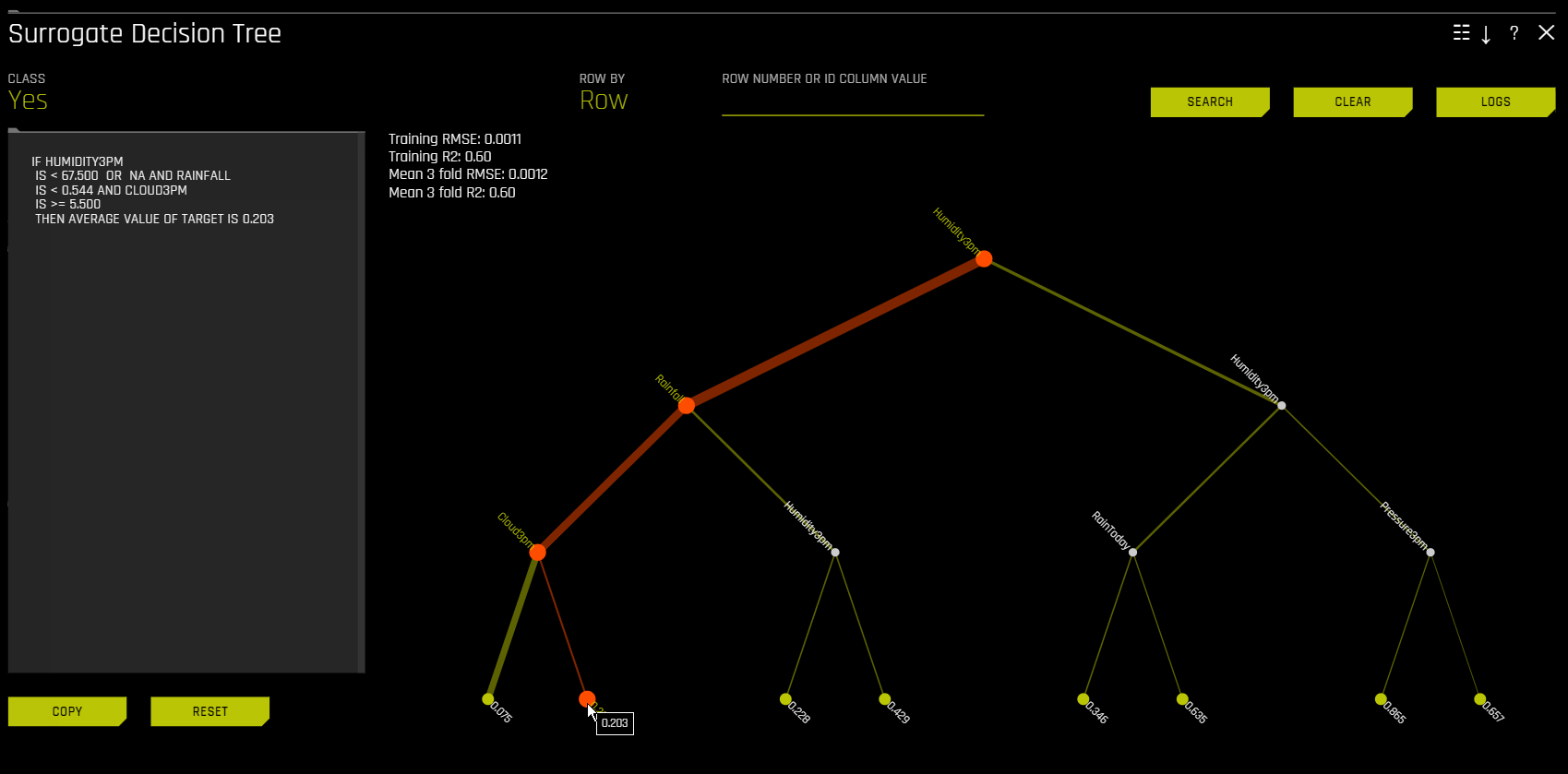
对于多类模型,会为每个类构建决策树模型。若需查看特定类的决策树模型,可点击页面左上角的 类 ,然后选择您想要查看决策树模型的类。
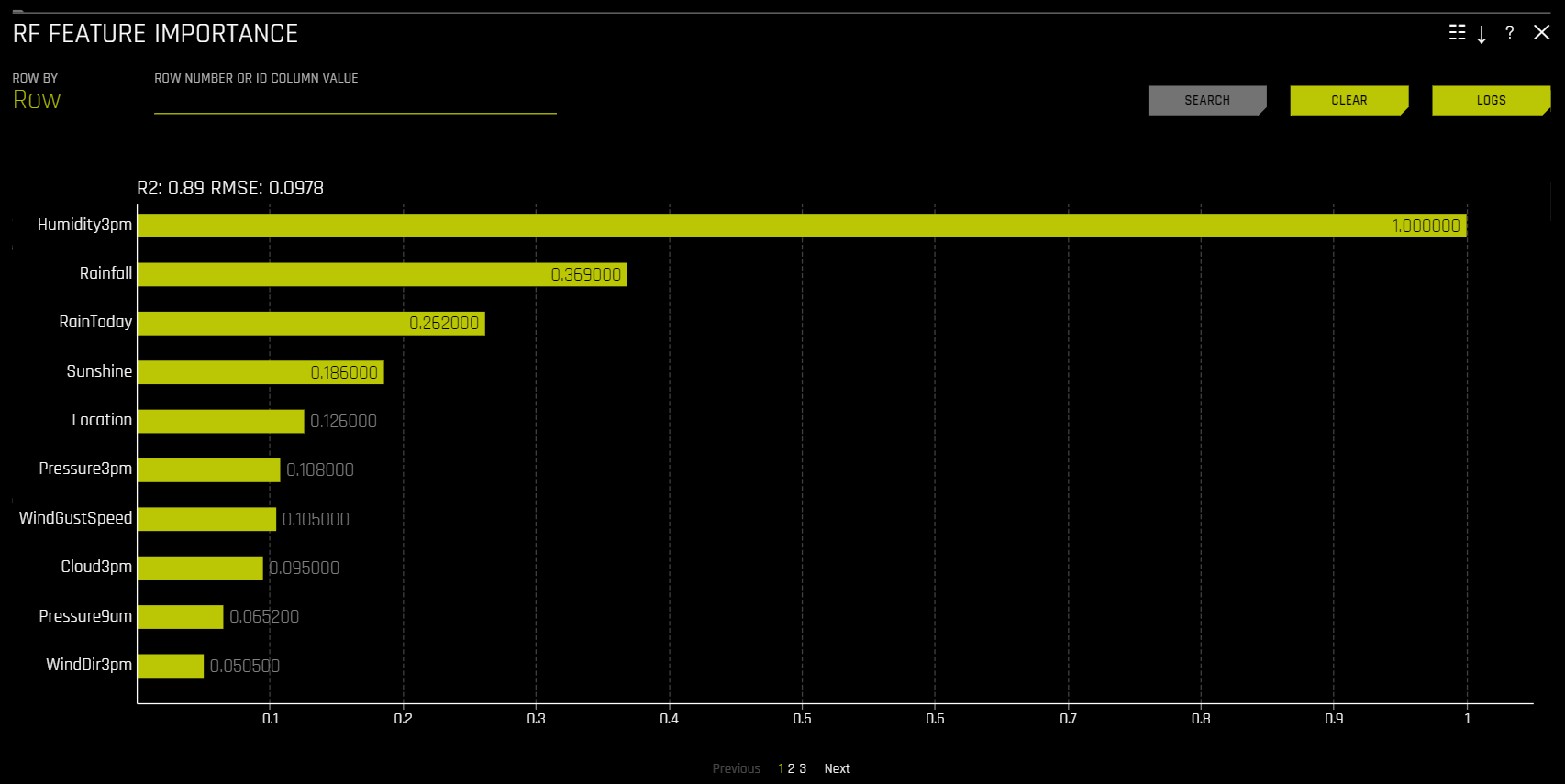
随机森林特征重要性¶
此图适用于二元分类、多类分类和回归实验的所有模型。
全局特征重要性 vs 局部特征重要性
全局特征重要性(黄色)可衡量输入变量对 Driverless AI 模型整体预测结果的贡献。通过聚合随机森林替代模型中所有决策树上由单个变量带来的拆分标准提升,可计算全局特征重要性。
局部特征重要性(灰色)可衡量输入变量对 Driverless AI 模型单个预测结果的贡献。通过随机森林替代模型跟踪单行数据并返回绝对 LOCO 值,计算回归和二项情况下的局部特征重要性值。对于多类情况,则通过对经过训练的监督模型进行重新评分并衡量将每个变量设置为缺失所带来的影响,计算局部特征重要性值。然后为每个被删除或替换的列计算各类间差异的绝对值。
全局变量重要性和局部变量重要性均进行了缩放,以使最大贡献变量的值为 1。
请注意:在构建时间序列实验时,会将处理过的特征用于 MLI。这是因为对于 MLI 而言,处理过的时间序列特征比原始时间序列特征更为有用,因为原始时间序列特征不是 IID(独立同分布)。
随机森林部分依赖性图和个体条件期望图¶
部分依赖性图和 ICE 图适用于 Driverless AI 模型和替代模型。请参阅前述 部分依赖性图 (PDP) 和个体条件期望图 (ICE) 一节,了解更多关于此图的信息。
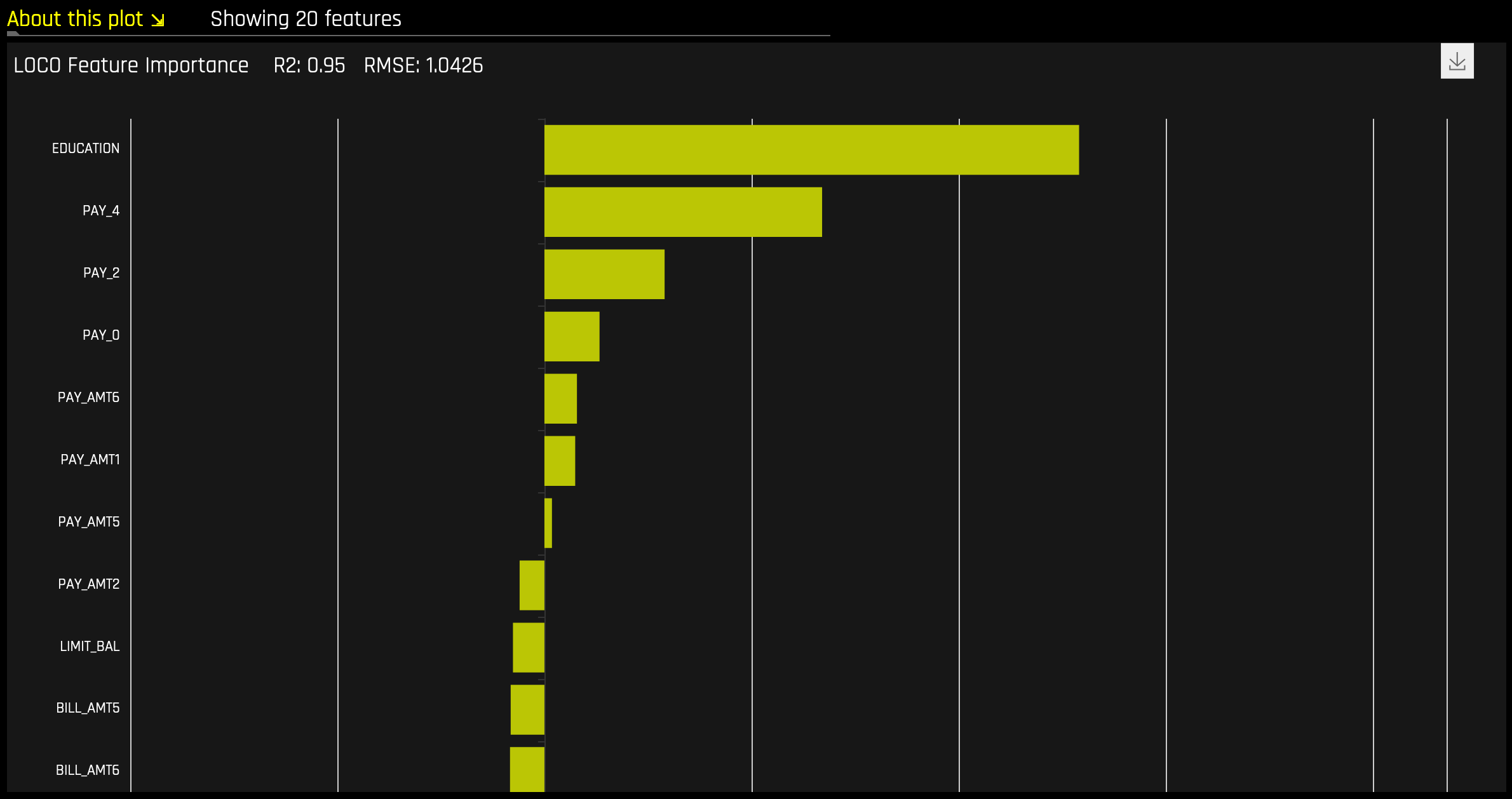
随机森林 LOCO¶
此图适用于二元分类模型、多类分类模型以及回归模型。
局部特征重要性描述了已学习的模型规则或参数与各行属性的组合如何影响模型对该行的预测结果,同时使非线性和交互生效。此图中报告的局部特征重要性值基于留一协变量输出 (LOCO) 方法的变体(Lei 等,2017 年)。
计算二元和回归模型的 LOCO 变体方法时,需要遍历随机森林替代模型,并从原始预测中移除包含每棵树相关变量的任何规则的预测贡献。局部 LOCO 值是通过随机森林替代模型跟踪单行数据来计算的。全局 LOCO 值是数据集每一行上的 LOCO 值的平均值。
多类模型的 LOCO 变体方法略有不同,因为它通过对经过训练的监督模型进行重新评分并度量将每个变量设置为缺失所带来的影响,计算行式局部特征重要性值。然后为每个被删除或替换的列计算各类间差异的绝对值总和。
给定输入数据行及对应的 Driverless AI 和 K-LIME 预测结果:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
以 Driverless AI 模型为 F(X),LOCO 变体的特征重要性值计算如下。
首先,计算修正后的预测结果:
\(F_{~debt\_to\_income\_ratio} = F(NA, 600, 1000) = 0.99\)
\(F_{~credit\_score} = F(30, NA, 1000) = 0.73\)
\(F_{~savings\_acct\_balance} = F(30, 600, NA) = 0.82\)
其次,从每个修正后的预测结果中减去原始预测结果,以生成未缩放的局部特征重要性值:
\(\text{LOCO}_{debt\_to\_income\_ratio} = F_{~debt\_to\_income\_ratio} - 0.85 = 0.99 - 0.85 = 0.14\)
\(\text{LOCO}_{credit\_score} = F_{~credit\_score} - 0.85 = 0.73 - 0.85 = -0.12\)
\(\text{LOCO}_{savings\_acct\_balance} = F_{~savings\_acct\_balance} - 0.85 = 0.82 - 0.85 = -0.03\)
最后,通过将行中的每个值除以此行的最大值并取此商的绝对量,从而使 LOCO 值在缩放到 0 到 1 之间。
\(\text{Scaled}(\text{LOCO}_{debt\_to\_income\_ratio}) = \text{Abs}(\text{LOCO}_{~debt\_to\_income\_ratio}/0.14) = 1\)
\(\text{Scaled}(\text{LOCO}_{credit\_score}) = \text{Abs}(\text{LOCO}_{~credit\_score}/0.14) = 0.86\)
\(\text{Scaled}(\text{LOCO}_{savings\_acct\_balance}) = \text{Abs}(\text{LOCO}_{~savings\_acct\_balance} / 0.14) = 0.21\)
这些 LOCO 变体特征重要性值的一个缺点是,不同于 K-LIME,它很难生成数学意义上的错误率来指示 LOCO 值何时可能有问题。
NLP 替代模型¶
这些图适用于自然语言处理 (NLP) 模型。
对于 NLP 替代模型,Driverless AI 会通过将所有文本特征标识化来创建 TF-IDF 矩阵。生成的帧会被附加到训练数据集的数值列或分类列中,并且原始文本列会被删除。此帧随后将用于训练替代模型,这些模型中具有由标识符和原始数值特征或分类特征组成的预测列。
请注意:
MLI 对 NLP 的支持仅适用于二元分类实验和回归实验。
TF-IDF 矩阵中的每一行包含 \(N\) 列,其中 \(N\) 是语料库中值与该行相适合的标识符总数(如果没有,则为 0)。
Driverless AI 目前不会为 MLI NLP 问题生成 K-LIME 评分管道。
对残差运行替代模型¶
在 Driverless AI 中,残差(观测值与预测值的差)可作为 MLI 替代模型中用于调试模型的目标。根据问题类型,用于计算残差的方法将有所区别。对于分类问题,计算指定类别的对数损失残差。对于回归问题,通过计算目标值与预测值之差的平方值来确定残差。
若需对残差运行替代模型,可启用 调试模型残差 解释专家设置。对于分类实验,请使用 用于调试分类模型对数损失残差的类 解释专家设置(对回归问题不可见)来指定一个类作为相关结果。在实验完成后,点击 残差替代模型 选项卡,即可查看模型。

NLP 绘图¶
本节介绍 NLP 选项卡中可供使用的绘图。
注解
这些绘图仅适用于自然语言处理 (NLP) 模型。
NLP 留一协变量输出 (LOCO)¶
此图适用于二项、多类和回归自然语言处理 (NLP) 模型,位于“模型解释”页面的 NLP 选项卡中(仅对 NLP 模型可见)。
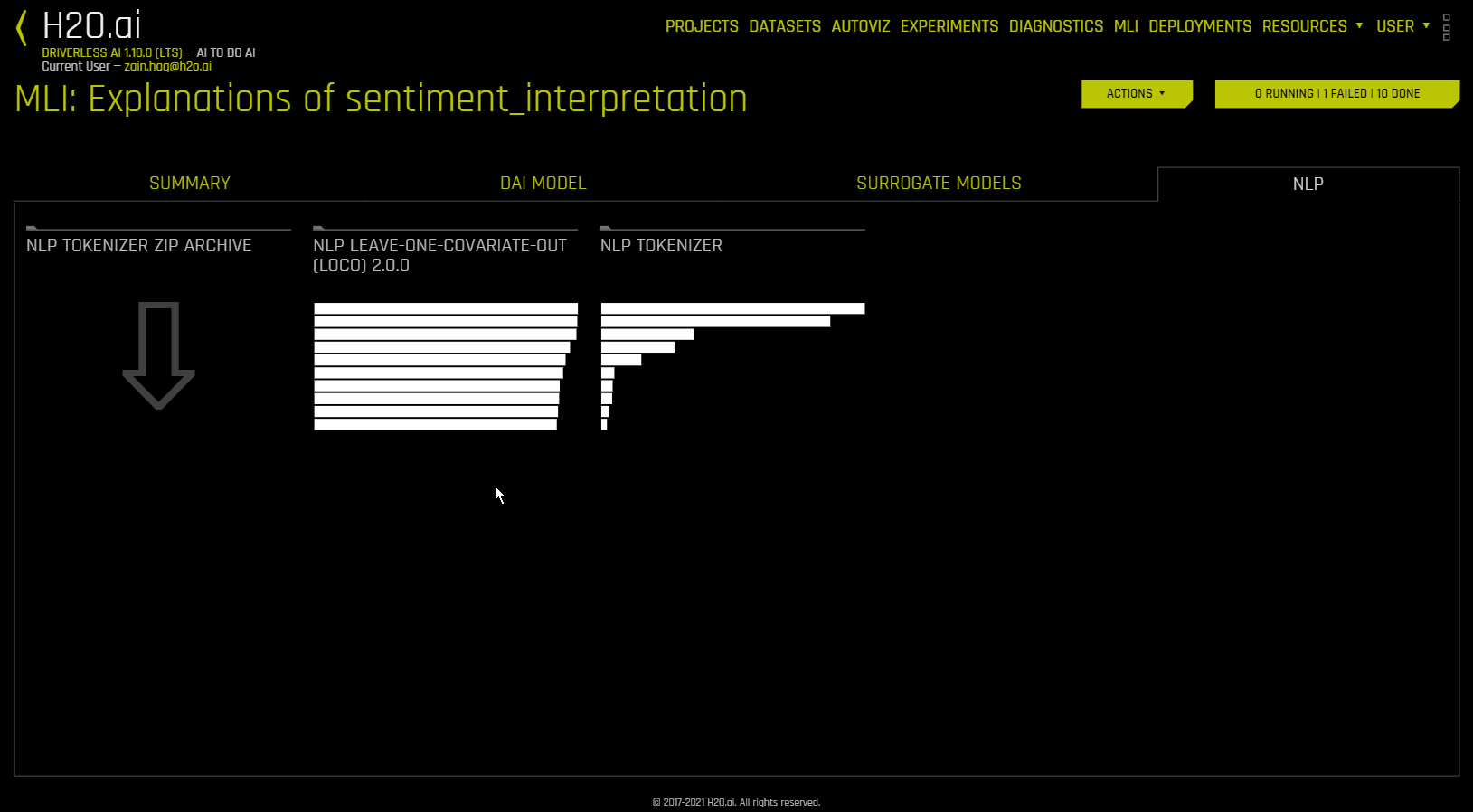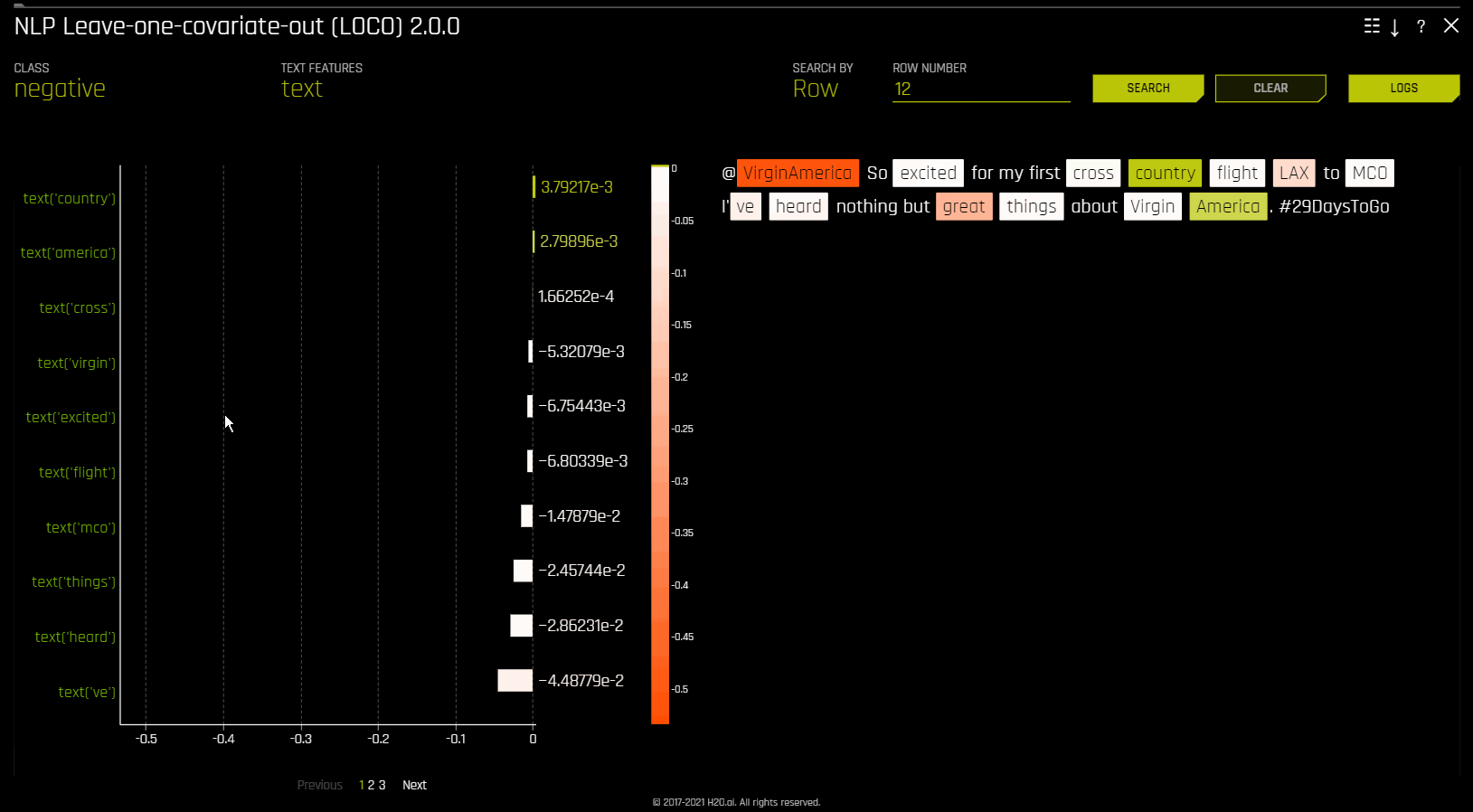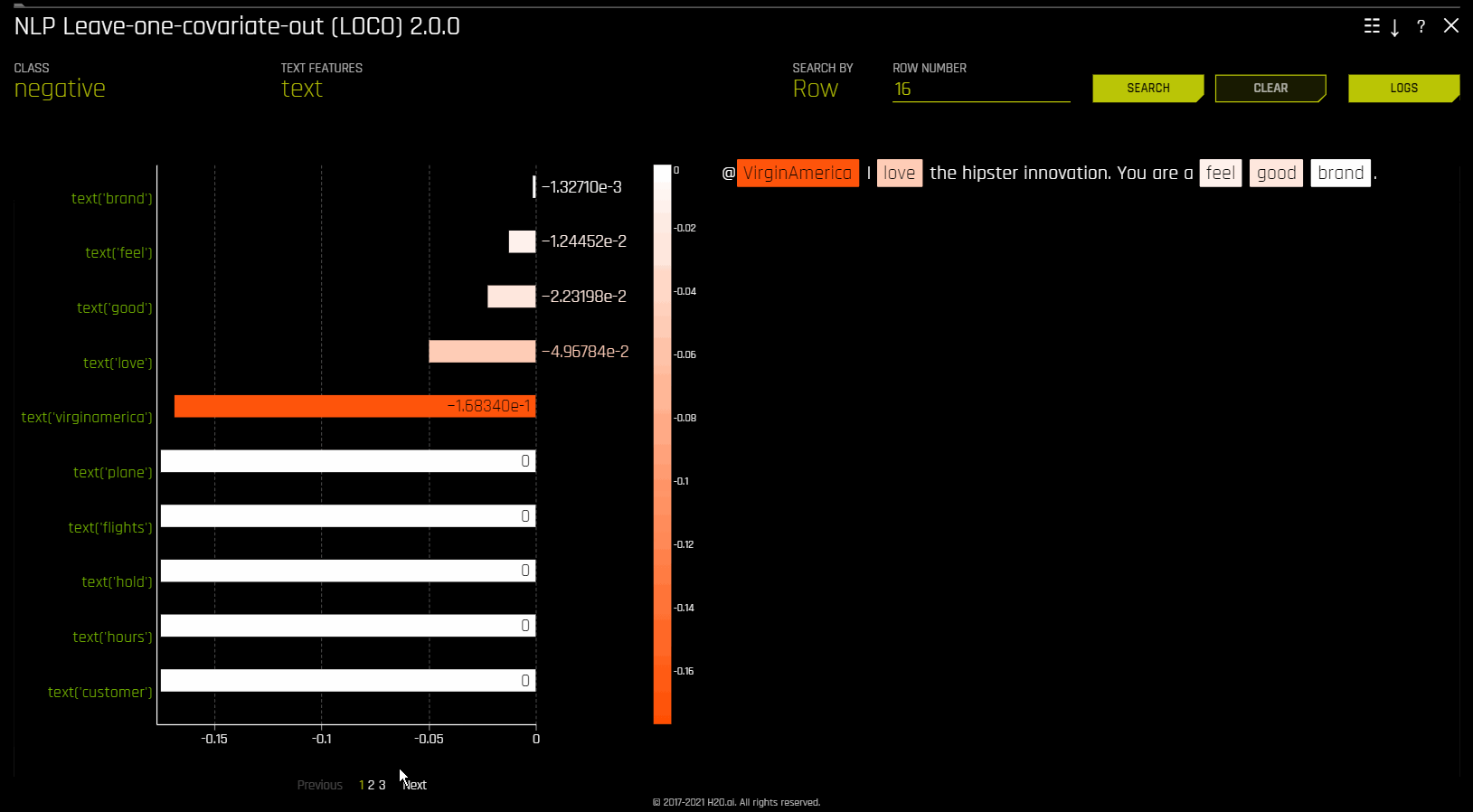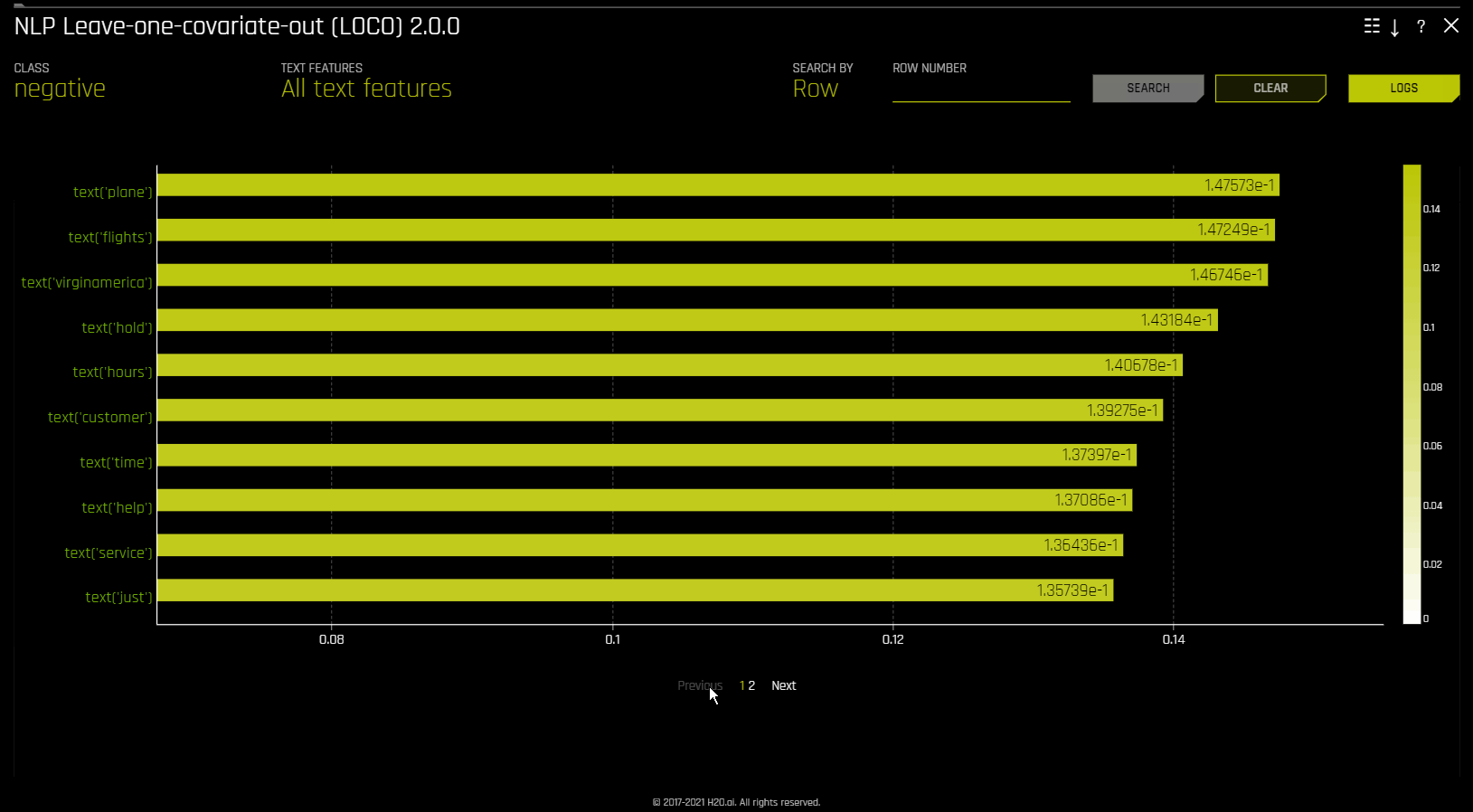
此图通过仅从出现标识符的单个列中移除特定标识符,将留一协变量输出 (LOCO) 类型的方法应用于 NLP 模型。例如如果在 column1 和 column2 中均有标识符 foo,即使标识符相同,也会分别为这两列计算 LOCO。请注意,此标识符在两列中具有不同的 TF-IDF。当尝试确定对文本特征的特定更改会如何更改模型所做出的预测时,所得到的评分和原始评分(包括标识符)之间的差异非常有用。Driverless AI 将为每个个体列拟合不同的 TF-IDF 向量化器并连接得到的结果。然后用列名称包装所生成的重要性帧中的词(标识符):
column1(‘and’) |
column1(‘apple’) |
column2(‘and’) |
|---|---|---|
0.1 |
0.0005 |
0.412512 |
NLP LOCO 绘图让您能通过指定行号来查看特定行的文本。行中的每个标记都按重要性突出显示。您可以在不同的文本特征之间切换,并查看其各自在全局和局部的重要性。
注解
由于计算的复杂性,仅计算 \(N\) 个(默认为 20 个)标识符的全局重要性值。此值可以使用
mli_nlp_top_n配置选项进行更改。通过为``mli_nlp_min_token_mode``配置选项指定以下选项之一,可以使用特定的标识符选择方法:
linspace: 根据 TF-IDF 评分选择 \(N\) 个间隔均匀的标识符(默认)top: 根据 TF-IDF 评分选择前 \(N\) 个标识符bottom: 根据 TF-IDF 评分选择后 \(N\) 个标识符
根据硬件的规格,NLP LOCO 的局部值可能需要花费大量时间来进行计算。
Driverless AI 目前不会为 MLI NLP 问题生成 K-LIME 评分管道。
NLP 部分依赖性图¶
此图适用于二项、多类和回归自然语言处理 (NLP) 模型,位于“模型解释”页面的 NLP 选项卡中(仅对 NLP 模型可见)。
NLP 部分依赖性(黄色)描述了 Driverless AI 模型在输入文本标记保留在相应文本中和不包含在相应文本以及 +/-1 标准偏差范围内时的平均预测行为。ICE(灰色)显示单行数据在输入文本标记保留在相应文本中和不包含在相应文本中时的预测行为。文本标记是从 TF-IDF 生成的。
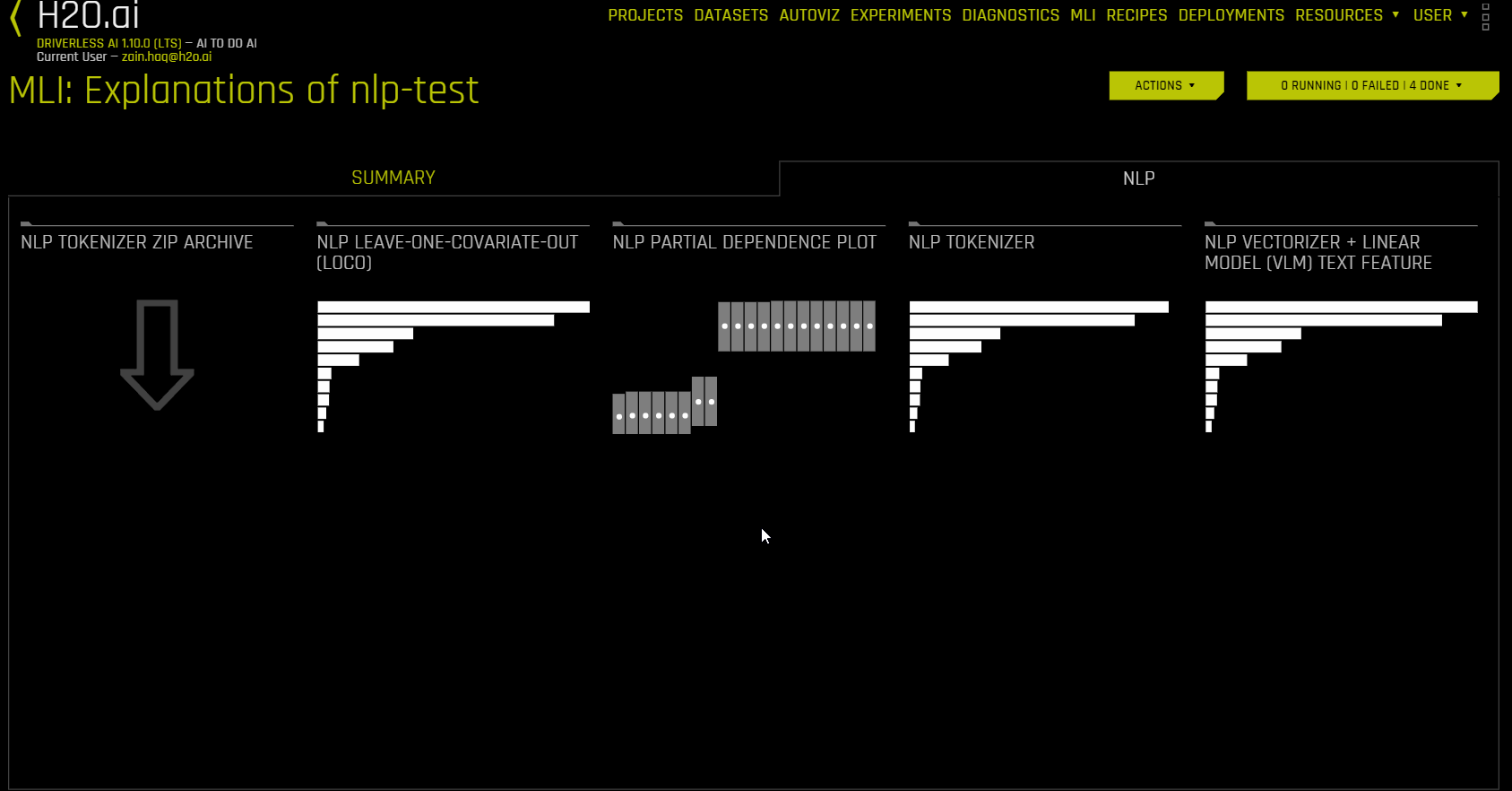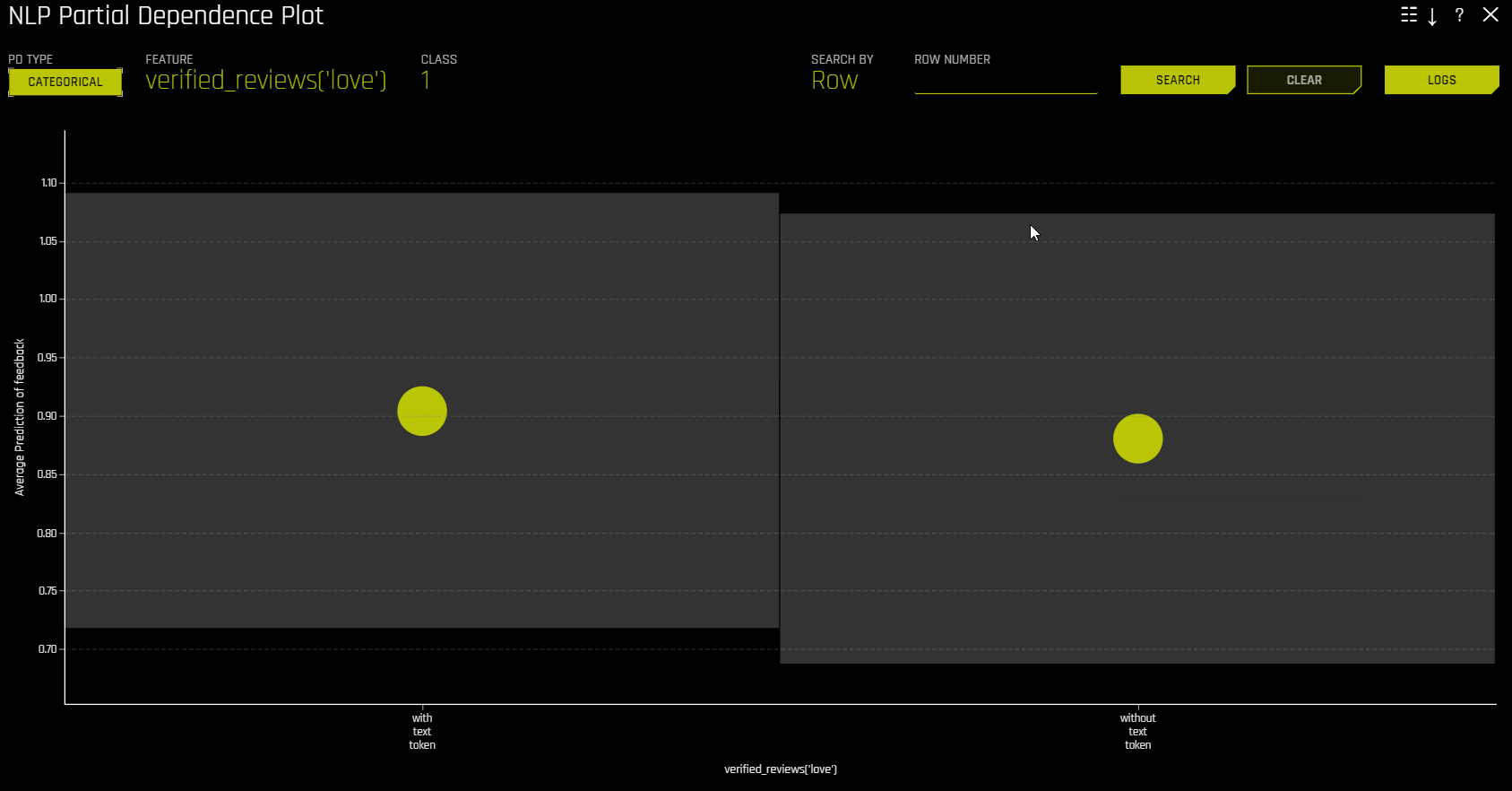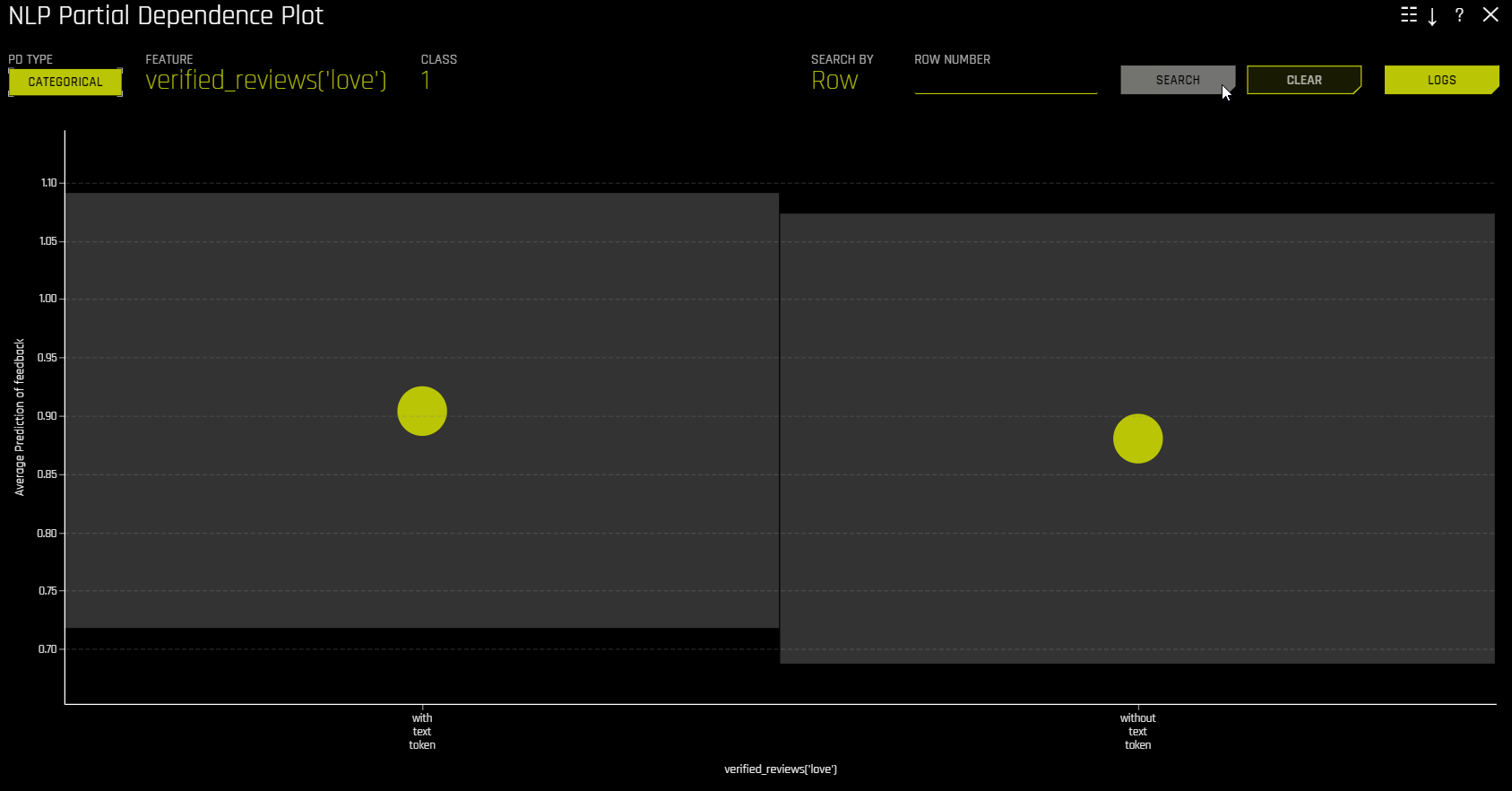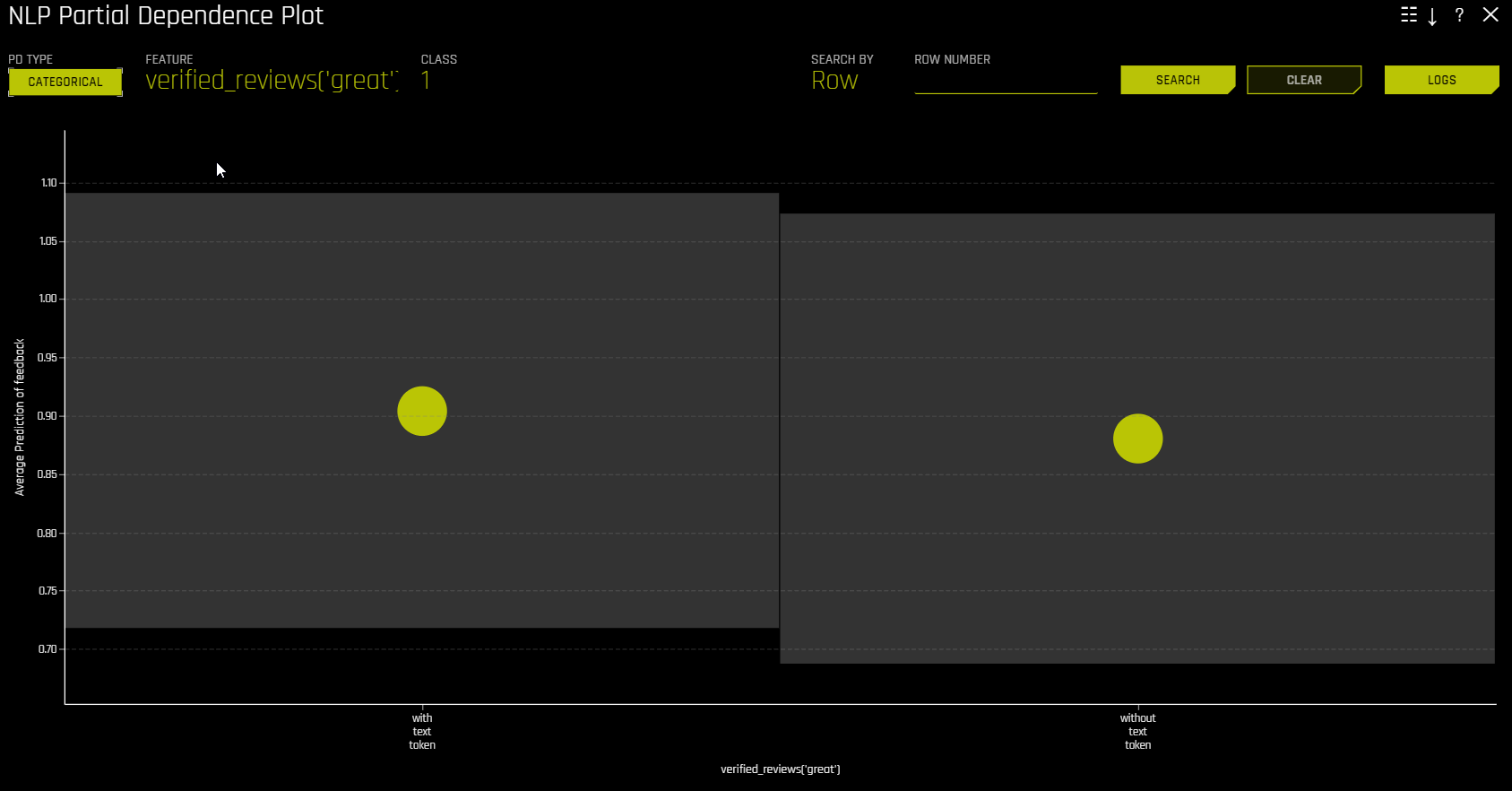
NLP 记号赋予器¶
此图适用于自然语言处理 (NLP) 模型,位于“模型解释”页面的 NLP 选项卡中(仅对 NLP 模型可见)。
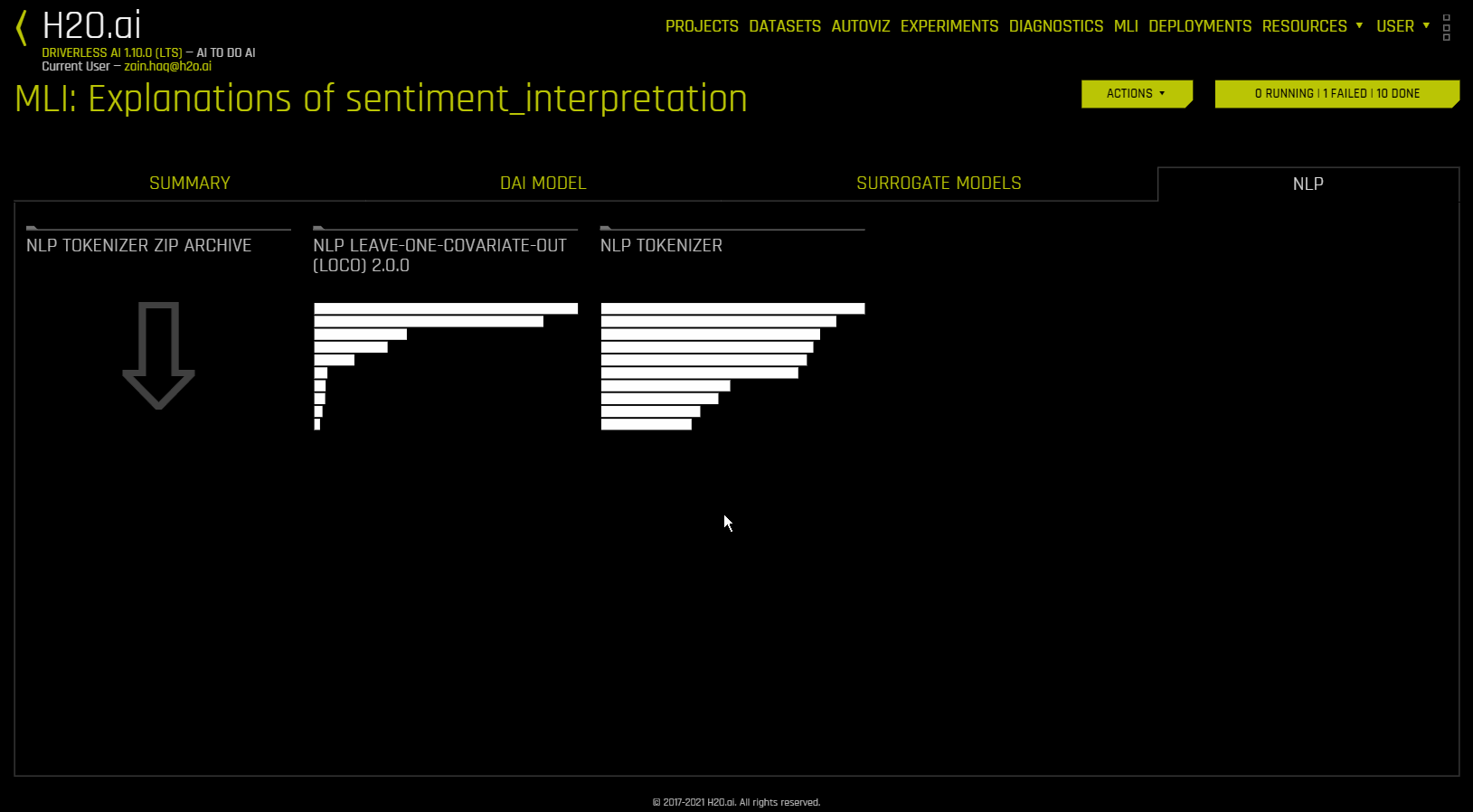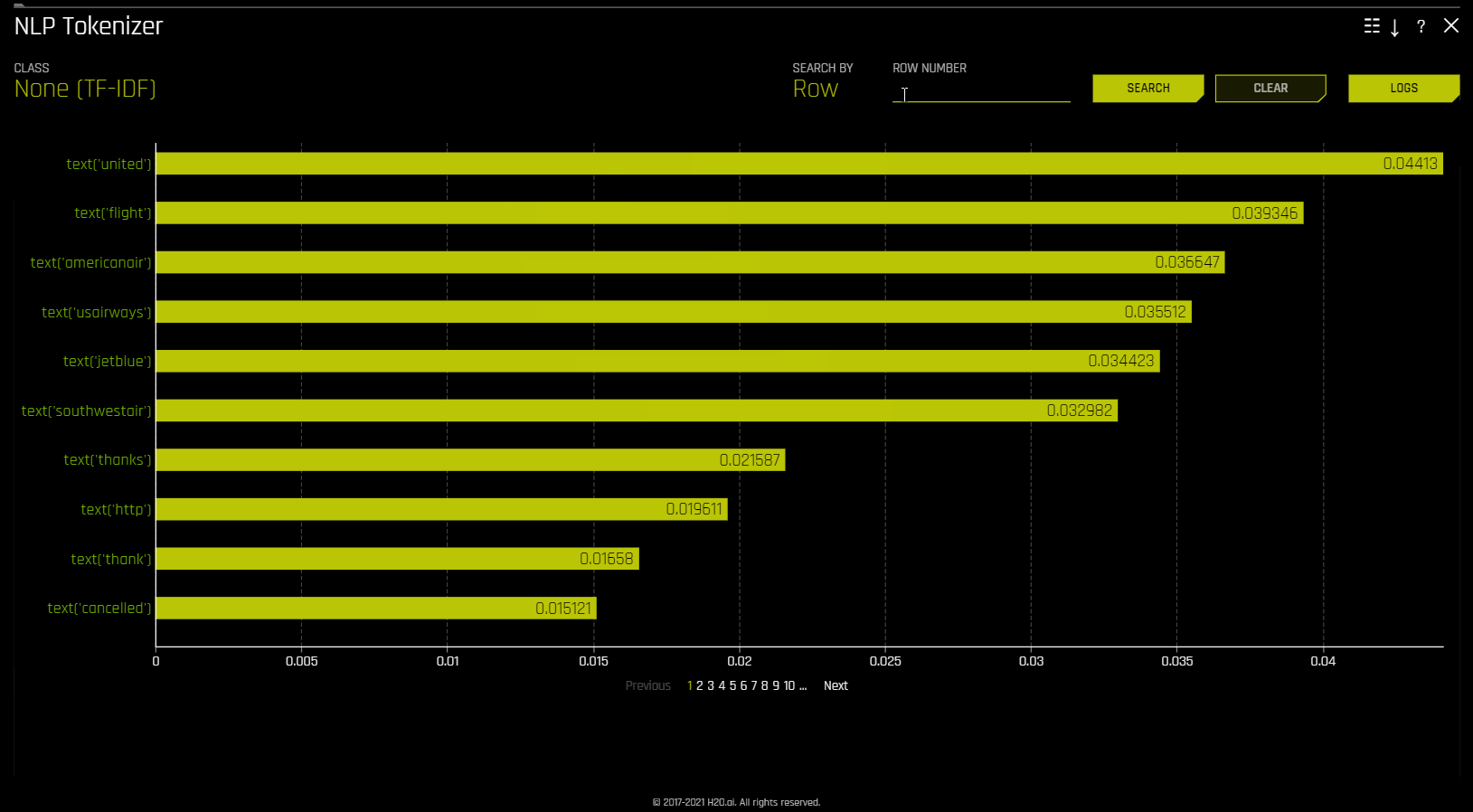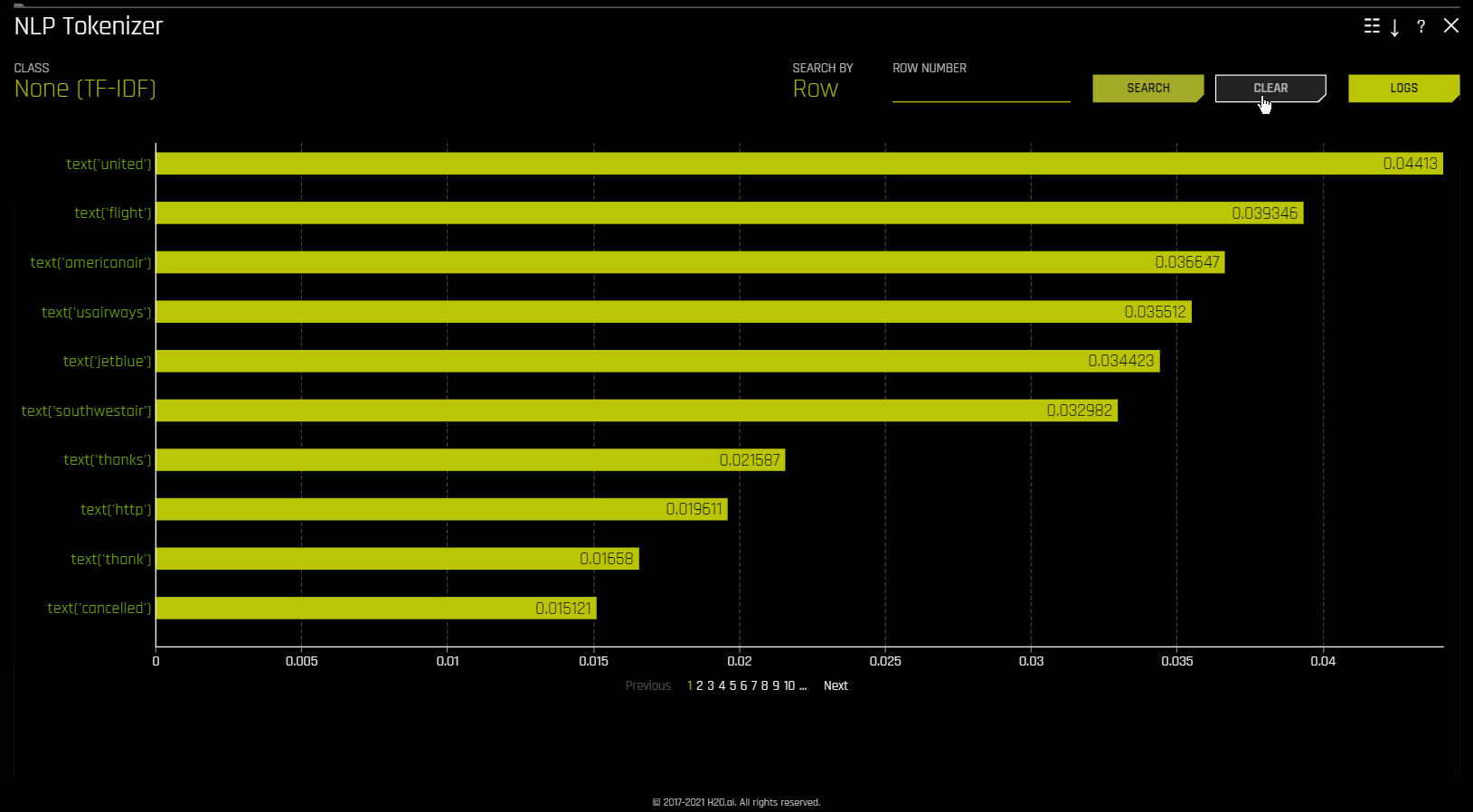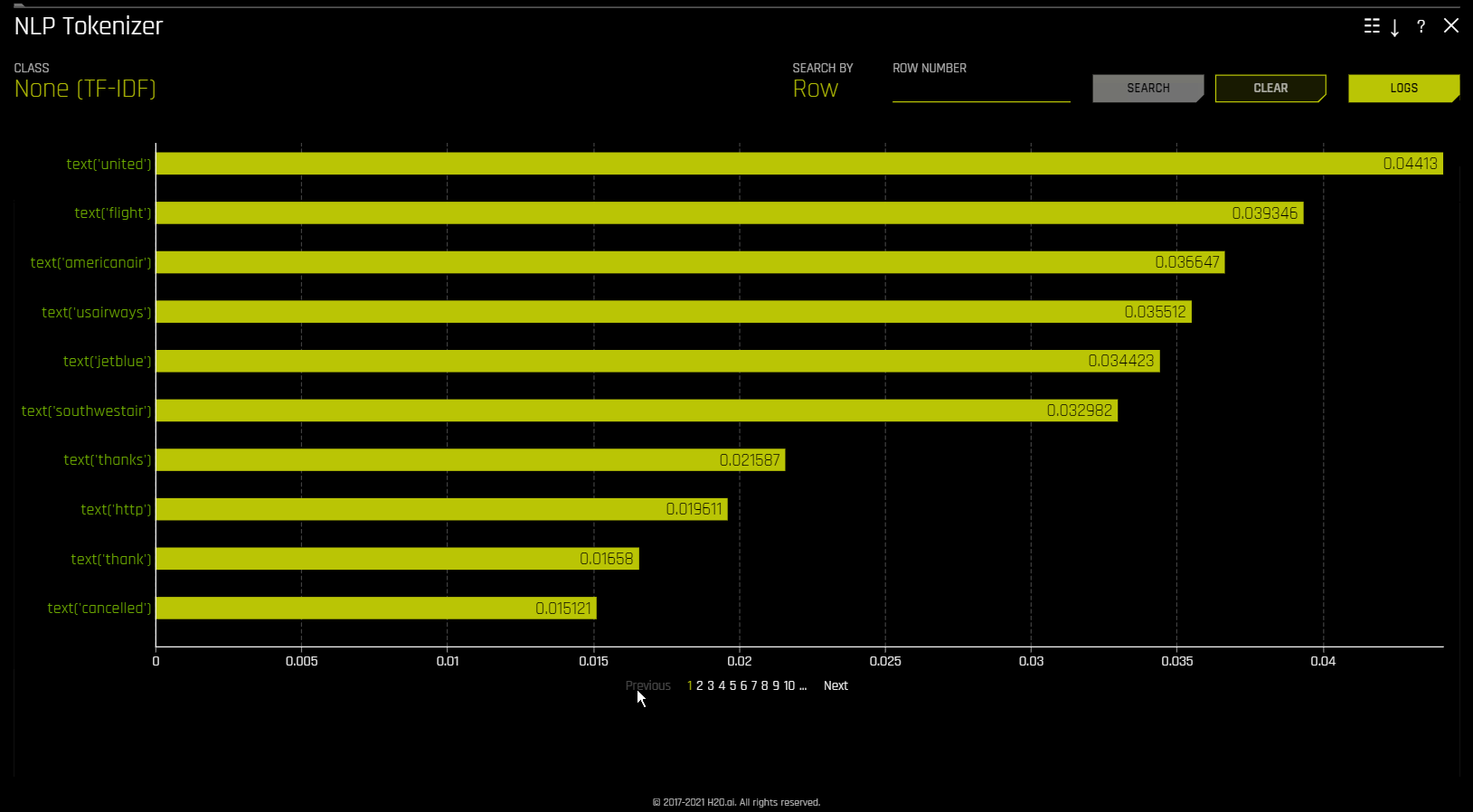
此图显示语料库(大型结构化文本集)中每个标识符的全局和局部重要性值。此语料库在分词过程之前根据 Driverless AI 所使用的文本特征自动生成。
局部重要性值通过将词频-逆文档频率 (TF-IDF) 用作每行中每个标识符的加权因子计算得出。TF-IDF 随标识符在给定文档中出现的次数成比例增加,并被语料库中包含此标识符的文档数所抵消。指定您想要查看的行,然后点击 搜索 按钮以查看此行中每个标识符的局部重要性。
全局重要性值通过使用逆文档频率 (IDF) 计算得出,逆文档频率用于衡量给定标识符在所有文档中的常见程度或罕见程度。(默认视图)
您可以通过点击 NLP 选项卡中的 “NLP 记号赋予器 ZIP 存档” 下载与 NLP 记号赋予器绘图相关的文件存档。
注解
NLP 的 MLI 目前没有移除停用词的选项。
默认情况下,在分词过程中最多可创建 10,000 个标识符。此值可在配置中进行更改。
默认情况下,Driverless AI 使用多达 10,000 份文档来从中提取标识符。此值可使用
config.mli_nlp_sample_limit参数进行更改。对于大于默认样本限制的数据集,将使用降采样。Driverless AI 目前不会为 MLI NLP 问题生成 K-LIME 评分管道。
使用 LOCO 方法,仅从出现标识符的单个列中移除特定标识符。例如,如果在
column1和column2中均有标识符foo,即使标识符相同,也会分别为这两列计算 LOCO。此标识符在两列中具有不同的 TF-IDF。
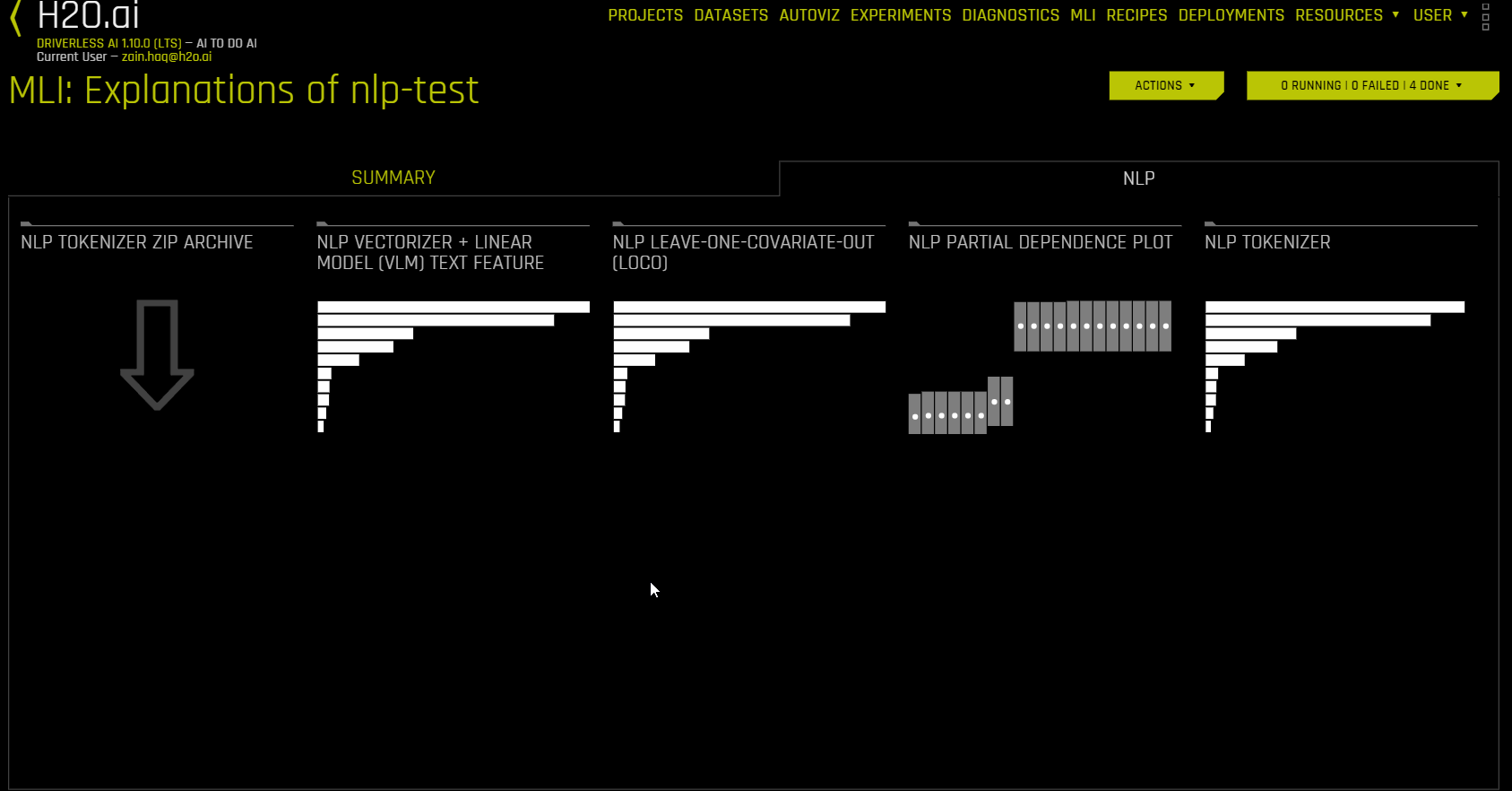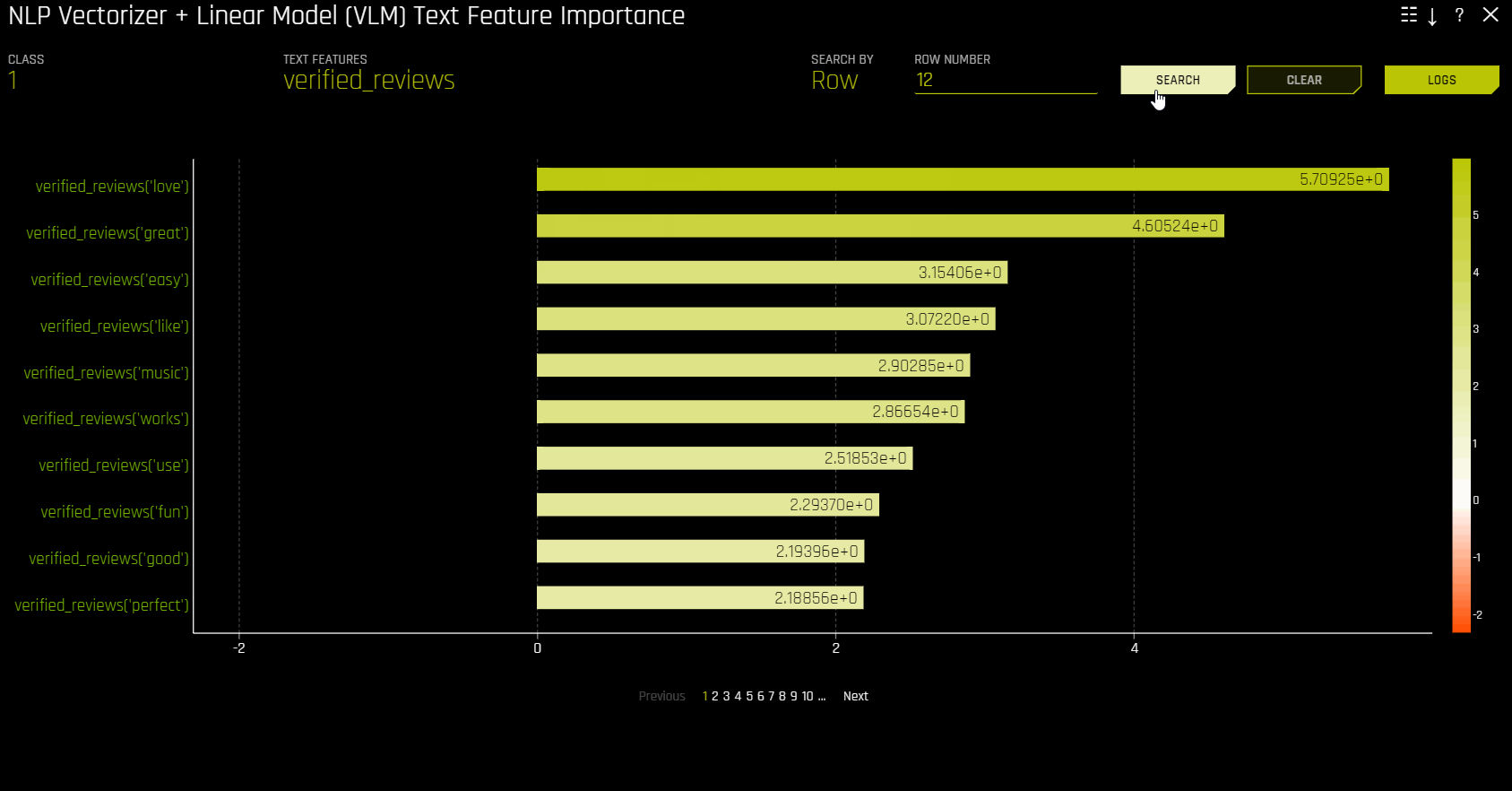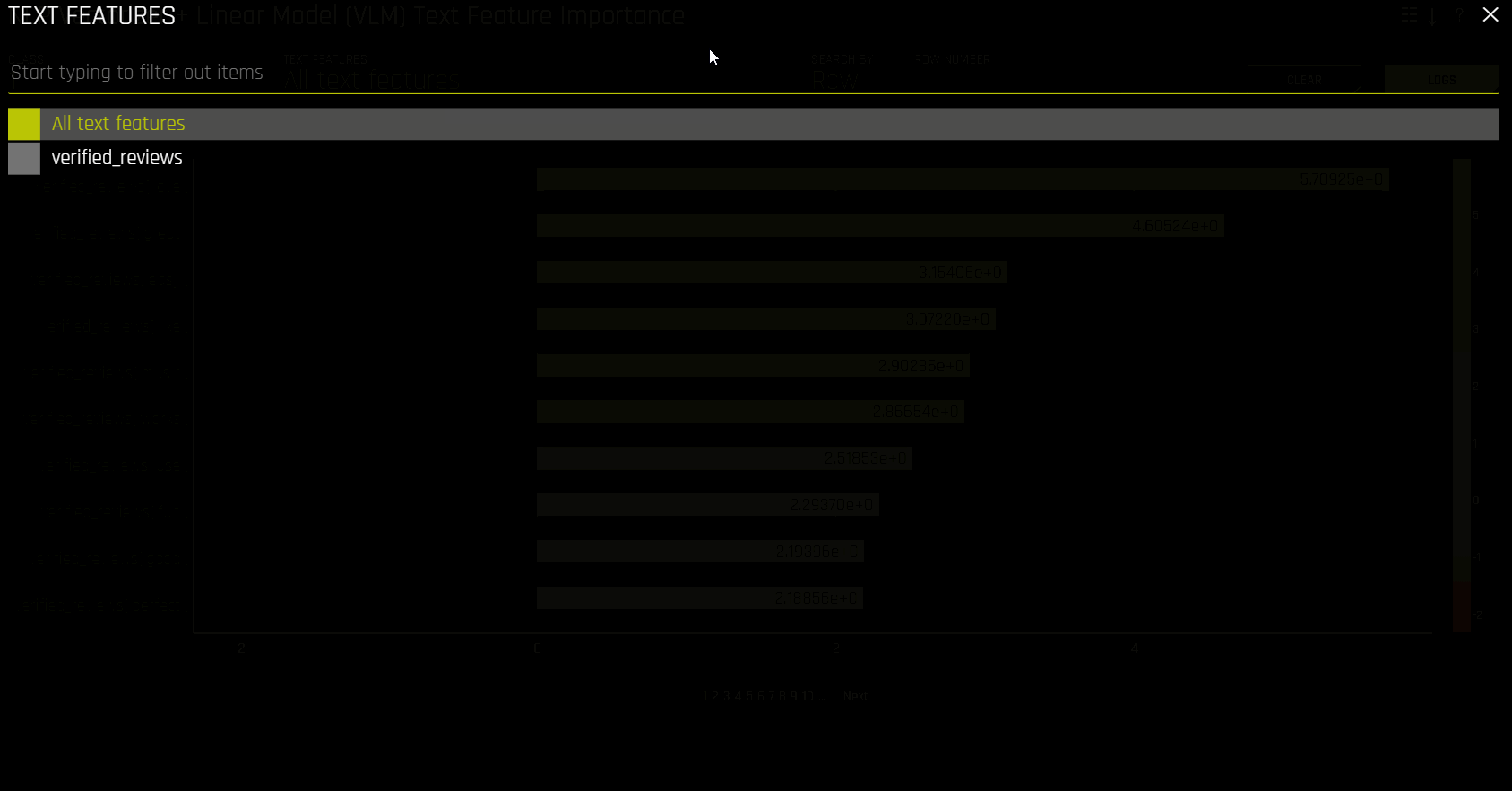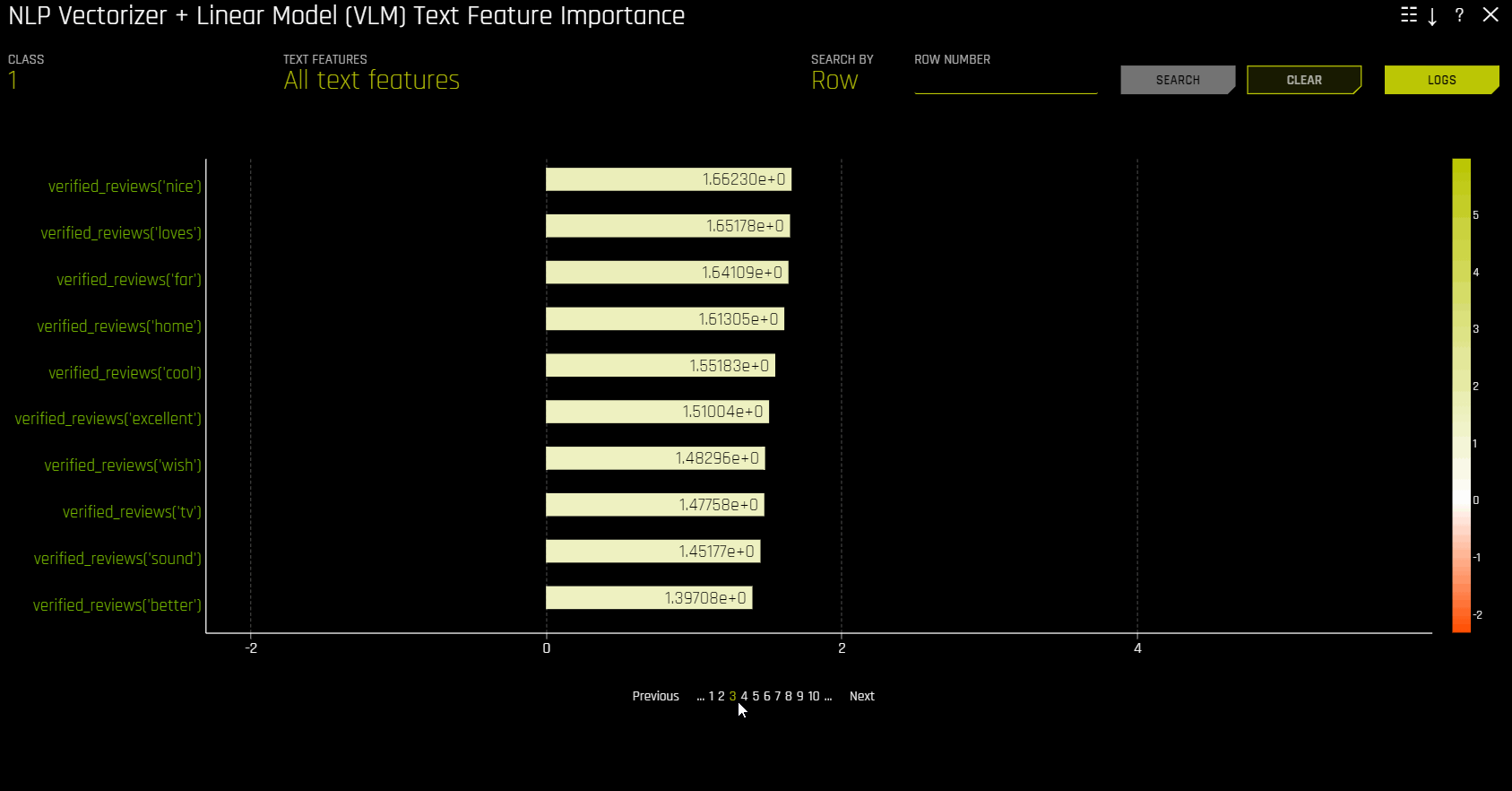
NLP 向量化器 + 线性模型 (VLM) 文本特征重要性¶
此图适用于二项和回归自然语言处理 (NLP) 模型,位于“模型解释”页面的 NLP 选项卡中(仅对 NLP 模型可见)。
NLP 向量化器 + 线性模型 (VLM) 文本特征重要性将单个单词的 TF-IDF 用作相关文本列中的特征,使用这些特征构建一个线性模型(目前为 GLM),然后将其拟合成 Driverless AI 模型的预测类(二元分类)或连续预测(回归)。线性模型的系数给出单词的重要性。注意,此解释器默认按字母顺序使用第一个文本列。