Transform datasets
When a training dataset is used in an experiment, Driverless AI transforms the data into an improved, feature engineered dataset. (For more information on the transformations that are provided in Driverless AI, see Driverless AI Transformations.) But what happens when new rows are added to your dataset? In this case, you can specify to transform the new dataset after adding it to Driverless AI, and the same transformations that Driverless AI applied to the original dataset are applied to these new rows.
The following sections describe the two options for transforming datasets that are available in Driverless AI:
Notes:
To avoid leakage, the result of transformations should not be used for training unless
enable_target_encoding='off'.

Transform dataset
The following steps describe how to transform a dataset with the Transform dataset option, which transforms the dataset without fitting.
Notes:
Don’t use this option for training unless
enable_target_encoding='off'.This transformation uses the experiment’s full model pipeline, except instead of generating predictions, it generates the transformation before the model is applied.
For ensembles of folds or models, for each row, numeric values are averaged, and one (last) value is taken for non-numeric values.
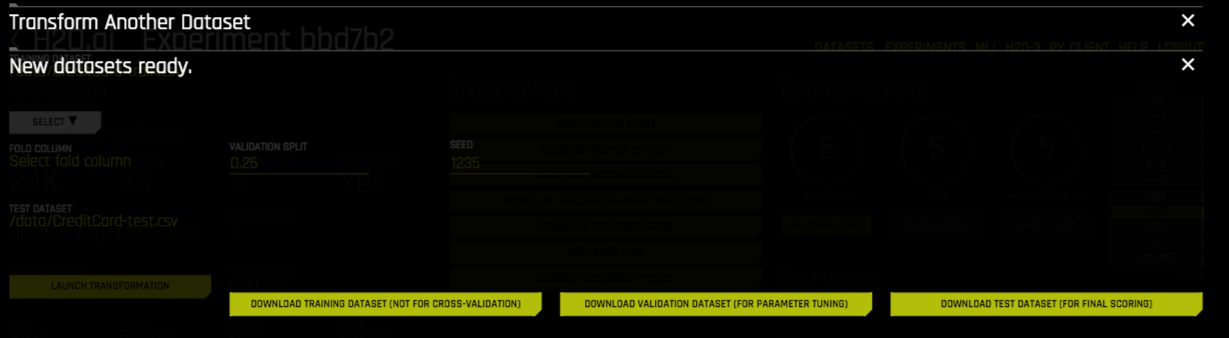
Select the dataset that you want to transform.
Select the columns you want to include in the transformation frame. To confirm your selection, click Done. The dataset transformation job is added to the pending jobs queue.
When the transformed dataset is ready, click Download transformed dataset. Specify a filename for the dataset, then click the Download button to download the transformed dataset.
Fit and transform dataset
The following steps describe how to transform a dataset with the Fit & Transform dataset option, which both fits and transforms the dataset.
Notes:
Don’t use this option for training unless
enable_target_encoding='off'.This functionality is not available for Time Series experiments when
time_series_recipe=true. (That is, when the lag-based recipe is used.)This functionality provides the pipeline (engineered features) of the best individual model of the experiment, not the full pipeline of all models and folds.
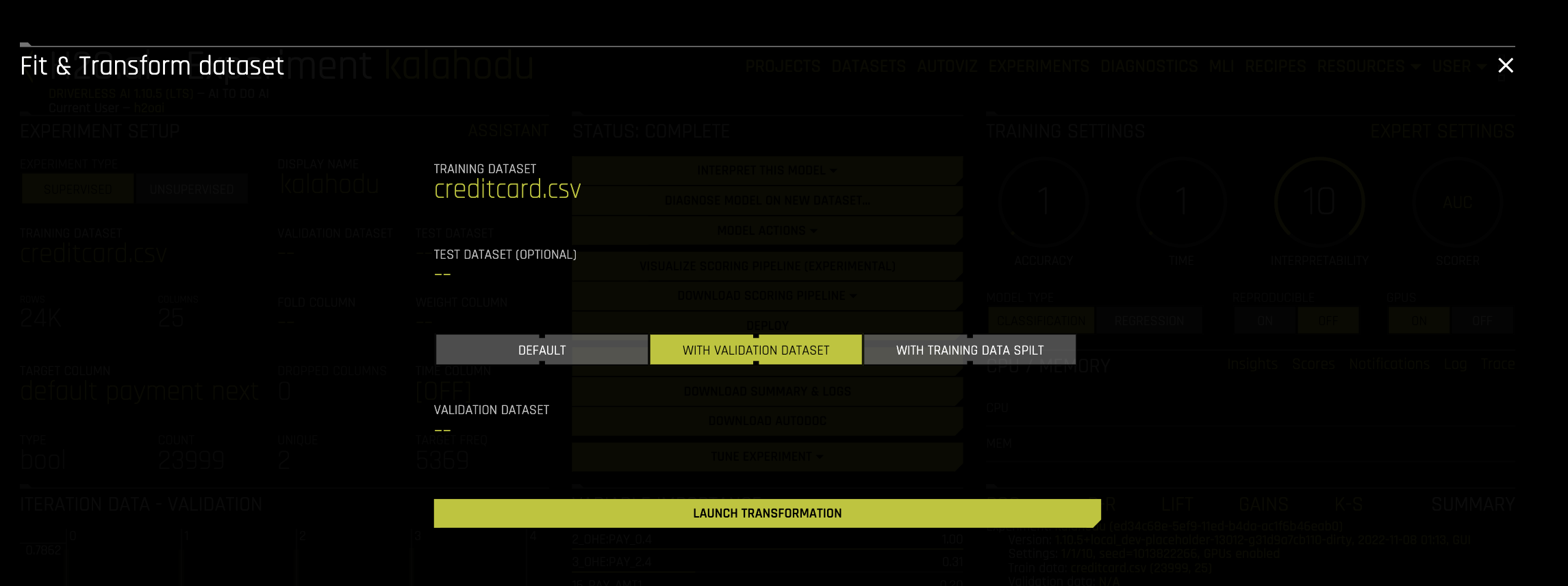
On the completed experiment page for the original dataset, click Model Actions -> Fit & Transform Dataset.
Select the new training dataset that you want to transform. Note that this must have the same number of columns as the original dataset.
Select one of the following options:
Default: The validation split ratio is set to 0.
With validation dataset: Specify a validation dataset to use with this dataset. The validation split ratio is set to 0.2.
With training data split: Split the training data. The validation split ratio is set to 0.2.
Note: To ensure that the transformed dataset respects the row order, choose a validation dataset instead of splitting the training data. Splitting the training data results in a shuffling of the row order.
Optionally specify a test dataset. If specified, then the output also includes the final test dataset for final scoring.
Click Launch Transformation.
The following datasets are made available for download upon successful completion:
Training dataset (not for cross validation)
Validation dataset for parameter tuning
Test dataset for final scoring. This option is available if a test dataset was used.