Automatic Feature Engineering
Driverless AI performs automatic feature engineering as part of an experiment’s model building process. New features are created by performing transformations and/or interactions on the dataset columns. The default transformers picked up by Driverless depends on interpretability settings of an experiment. For more interpretable models, simpler transformations are applied. This can be seen in the preview of the experiment. Feature engineering expert settings like include/exclude transformers can be used to control the applied transformations. Transformers like binning, target encoding, weight of evidence, clustering, dimensionality reduction, autoencoders, TensorFlow, NLP BERT models, lags, aggregates, can be used to create Feature interactions.
Feature creation and selection is evolutionary (based on variable importance of previous iteration) in nature and uses genetic algorithm to find the best set of feature transformations and model parameters for an experiment/dataset.
The details about features created (transformations applied) and used by the experiment can be obtained from the Autodoc of an experiment.
The feature engineering effort and evolution can be controlled from the the expert panel of an experiment. For more information on expert settings in DAI, refer to Understanding Expert Settings.
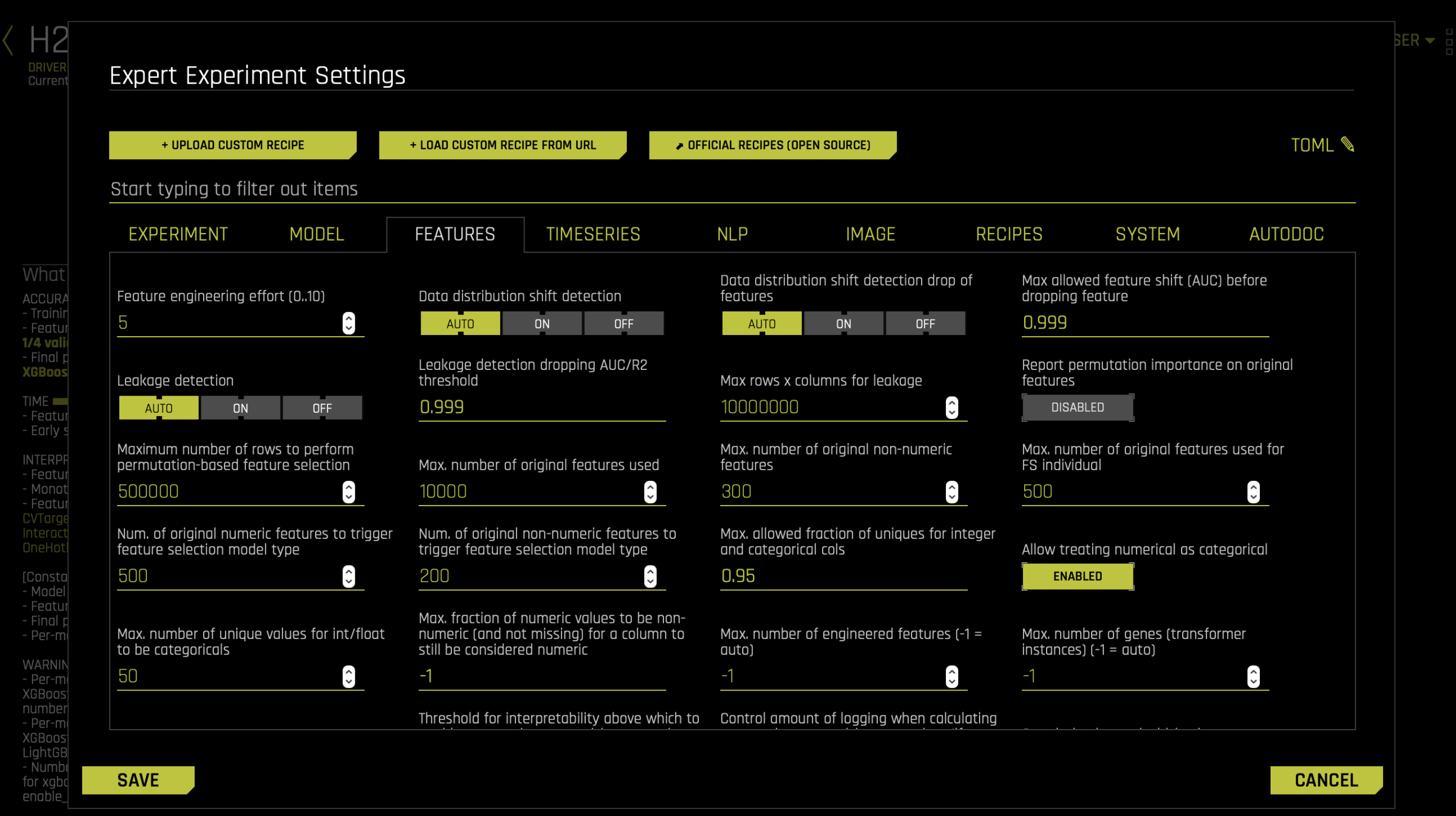
You can also upload your own custom transformers to be included in addition to the Driverless AI built in transformers. Some open-source custom transformers can be obtained from Driverless AI open-source custom recipes.
The inclusion of the transformers can be controlled from the Recipe tab of the expert panel of an experiment.
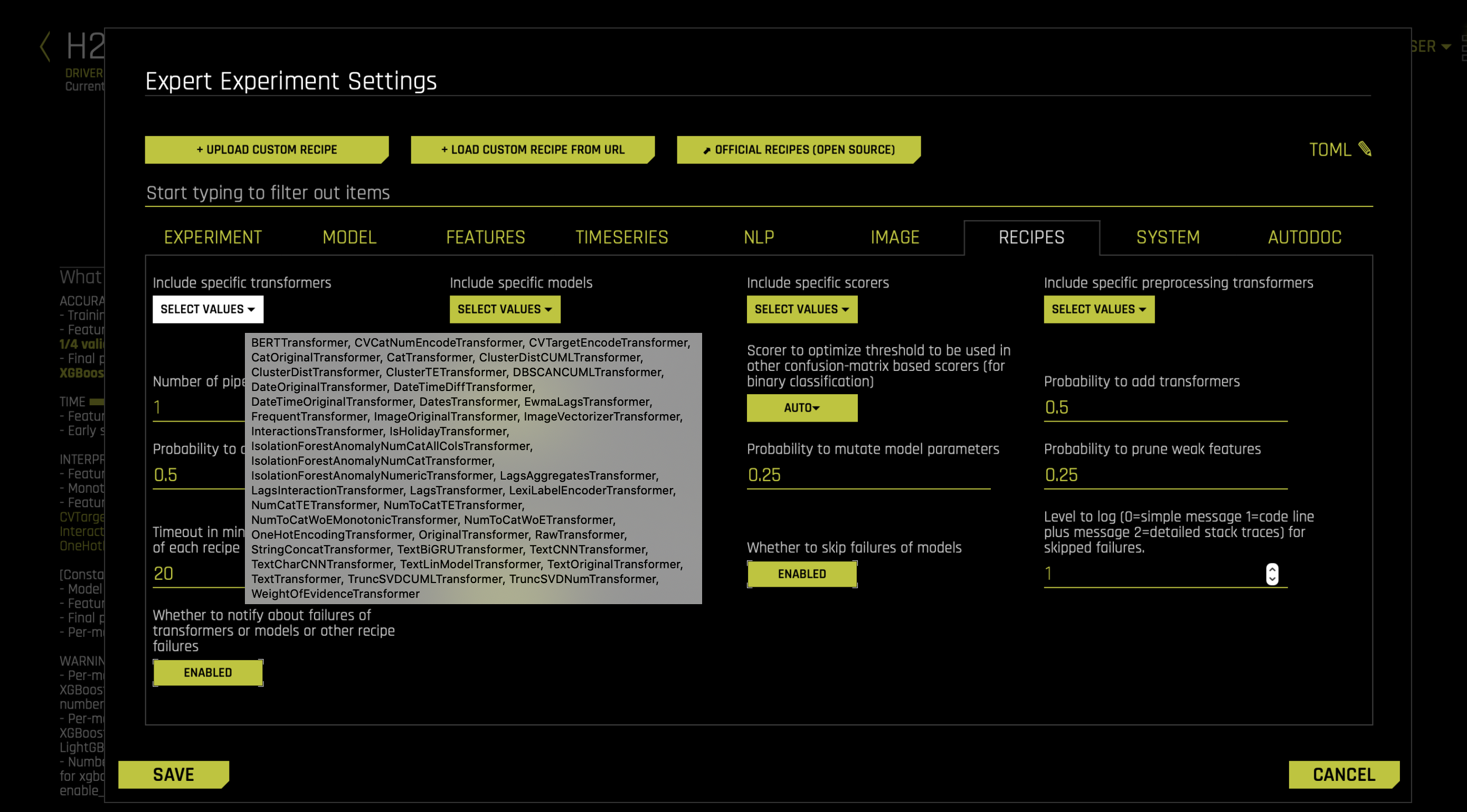
Preprocessing transformers can be used to control the features fed into the evolutionary transformer layer.
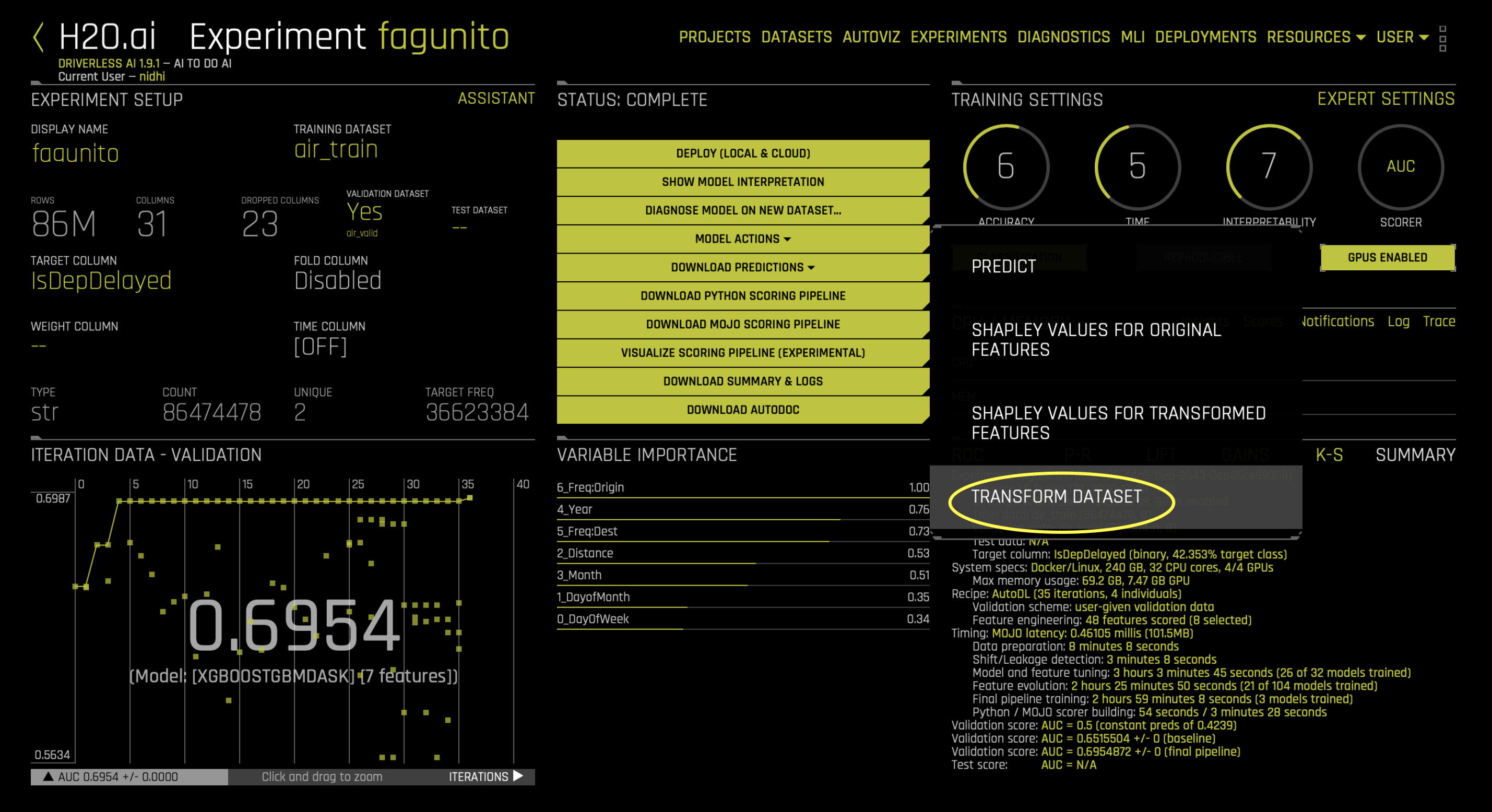
You can obtain the dataset with (engineered) features by clicking Transform Dataset from Model Actions of a finished experiment. This provides the pipeline of the best individual model of the experiment.
In Driverless AI, the process of tuning pipelines involves tuning feature engineering and model parameters simultaneously by applying the genetic algorithm’s evolutionary strategy and blending and stacking at the end of the evolution cycle to get an optimal scoring pipeline.