Deploy Driverless AI models
This page describes how to deploy models in Driverless AI.
Note: AWS Lambda and REST server deployment options are no longer supported, and have been replaced by Triton Inference Server deployment.
Overview
Deploy from the UI
The following deployment options are available directly from the UI:
H2O MLOps deployment (Note that to use this deployment option, you must specify
h2o_mlops_ui_urlin theconfig.tomlfile.)
Additional deployment options
By default, each completed Driverless AI experiment (unless explicitly disabled or not available due to modified expert settings) creates at least one scoring pipeline for scoring in Python, C++, Java, and R.
The following is a list of deployment options and examples for deploying Driverless AI MOJO (Java and C++ with Python/R wrappers) and Python Scoring pipelines for production purposes. The deployment template documentation** can be accessed from here. For more customized requirements, contact support@h2o.ai.
H2O MLOps deployment
H2O MLOps is an open, interoperable platform for model deployment, management, governance, and monitoring that features integration with Driverless AI. The following steps describe how you can create H2O MLOps deployments directly from the completed experiment page in Driverless AI.
Note: To use this deployment option, you must specify h2o_mlops_ui_url in the config.toml file.
On the completed experiment page, click Deploy.
Click the H2O MLOps button. This action results in one of the following outcomes:
The experiment is assigned to a single Project: You are redirected to the Project detail page in the H2O MLOps app.
The experiment is assigned to multiple Projects: Select a project to go to in the H2O MLOps app. Alternatively, create a new Project to assign the experiment to. If you choose to create a new Project, you are prompted to enter a name and description for the Project. Once the new Project has been created and the experiment has been linked to it, you can click the Go to MLOps page button to navigate to the Project detail page in the H2O MLOps app.
The experiment isn’t assigned to any Project: Select a Project to link the experiment to. Alternatively, create a new Project and link the experiment to it.
Triton Inference Server deployment
Description of relevant configuration options
Connect to external Triton inference server
To connect Driverless AI to an external Triton Inference Server, configure the following expert settings:
triton_host_remote: Specify the hostname or IP address of a remote Triton inference service outside of Driverless AI. This setting is used whenauto_deploy_triton_scoring_pipelineandmake_triton_scoring_pipelineare not disabled. If set, ensure thattriton_model_repository_dir_remoteandtriton_server_params_remoteare also configured.triton_host_remotecan only be set throughconfig.tomlor as a global environment variable.triton_model_repository_dir_remote: Define the path to the model repository directory for a remote Triton inference server outside of Driverless AI. This directory is used to store all Triton deployments for all users. Write access to this directory from Driverless AI is required (shared file system). This setting is optional; if not specified, models are uploaded over gRPC (limited to those smaller than 2GB due to protobuf constraints). For larger models, use the Export functionality and place the file contents directly on the remote Triton server.triton_server_params_remote: Provide the connection parameters for the remote Triton server. This setting is necessary only when bothtriton_host_remoteandtriton_model_repository_dir_remoteare configured.
There are multiple ways to deploy Triton. For detailed deployment instructions and performance tuning using Triton, refer to the NVIDIA Triton Inference Server User Guide.
Note: DAI supports Triton Inference Server container images up to version 25.07
Example: Starting Triton and DAI with Docker
Start DAI with remote Triton deployment enabled:
mkdir -p tmp/triton-model-repository && \
docker run --gpus all \
--pid=host \
--rm \
--shm-size=2g \
--cap-add=SYS_NICE \
--ulimit nofile=131071:131071 \
--ulimit nproc=16384:16384 \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-e "DAI_AUTO_DEPLOY_TRITON_SCORING_PIPELINE=remote" \
-e "DAI_MAKE_TRITON_SCORING_PIPELINE=on" \
-e "DAI_TRITON_HOST_REMOTE=$TRITON_HOST" \
-e "DAI_TRITON_MODEL_REPOSITORY_DIR_REMOTE=/tmp/triton-model-repository" \
$DAI_IMAGE
Start the Triton Inference Server:
docker run --gpus=1 --rm \
-p 8000:8000 -p 8001:8001 -p 8002:8002 \
-v `pwd`/tmp/triton-model-repository:/models \
-e "DRIVERLESS_AI_LICENSE_KEY=$LICENSE" \
nvcr.io/nvidia/tritonserver:25.07-py3 tritonserver \
--model-repository=/models \
--model-control-mode=explicit
DAI Deployment Wizard
The following steps describe how to use the DAI Deployment Wizard to create and manage Triton Inference Server deployments.
On the completed experiment page, click the Deploy button.

Click the Triton button. (Note that this step may not be required on standalone DAI.)
The DAI Deployment Wizard is displayed. This Wizard lets you deploy Driverless AI experiments to a remote inference server to get low-latency scoring capabilities for development, prototyping, demos, or benchmarking.
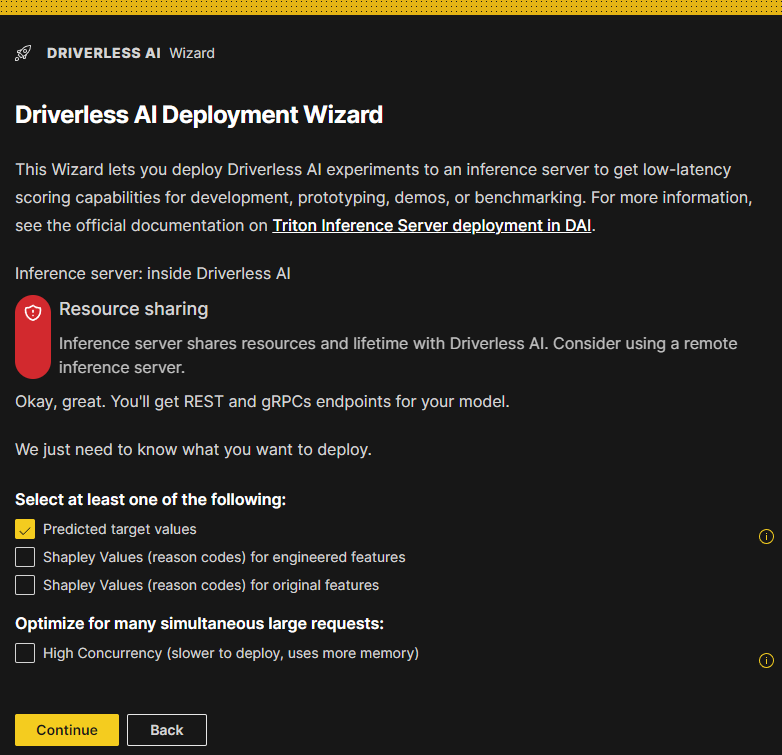
Select at least one of the following:
Predicted target values
Shapley values (reason codes) for engineered features
Shapley values (reason codes) for original features
(Optional) If you want to optimize the deployment for many simultaneous large requests, select the High Concurrency (slower to deploy, uses more memory) option. For more information, see the following subsection.
Confirm your selections and click the Continue button to proceed.
High concurrency
Note: P99 Latency and Throughput numbers are not affected by the high concurrency setting because the built-in simple benchmark is not performing simultaneous requests.
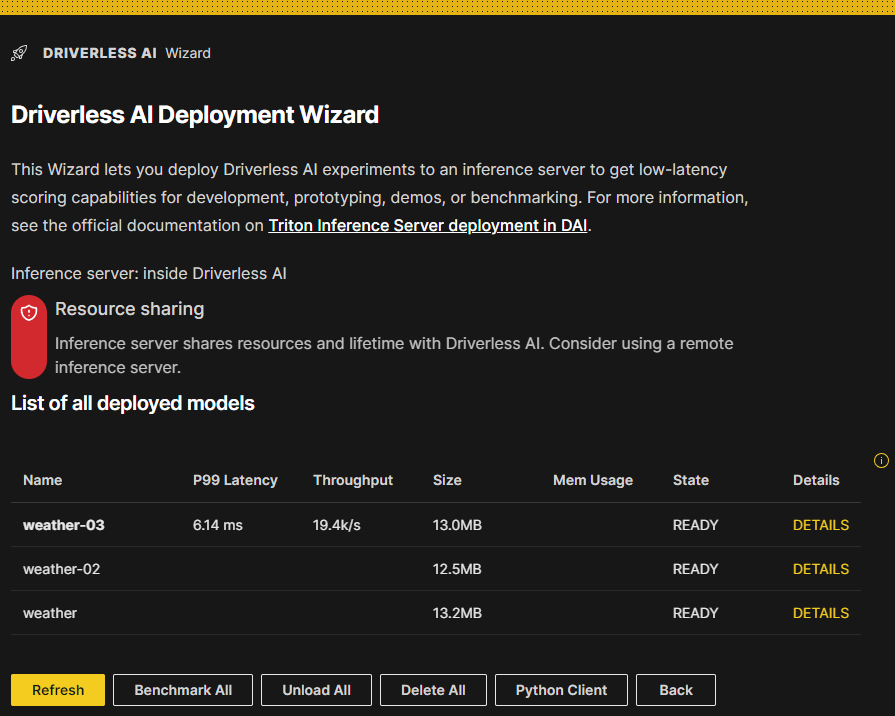
Deployed models list
A list of all models that have been previously deployed is displayed. They can be active (ready) or inactive (unavailable) deployments. A deployment can be unloaded if it is not being used temporarily to free up resources.
For each deployed model in this list, the following details are provided:
Model name: Click the name of a model to go to the completed experiment page for that model.
P99 latency: The 99-th percentile (that is, the estimate of worst case) of the latency in milliseconds when scoring one row (sequentially, one row at a time).
Throughput: The approximate number of rows that can be scored in one second when scoring many rows at a time in a batch request.
Size: The size of the MOJO pipeline on disk.
Memory usage: The size of the MOJO pipeline in memory during scoring (at the
time the MOJO was created). Note that this number may change as newer MOJO runtimes are released.
State: The following list descibes the various possible states of a deployment.
READY: The deployment is loaded and active (ready to make predictions).
UNLOADING: This indicates a transition state between READY and UNAVAILABLE.
UNAVAILABLE: This indicates an unloaded deployment that can be loaded again when needed.
Details: Displays the name, description, platform, model version, input columns, output columns, P99 latency, throughput, and state of the deployed model.
Actions available from the deployed models listing page
The following list describes the actions that are available from the deployed models listing page.
Load all: Loads all deployed models that are not in “READY” state, and run a very quick benchmark test. In the context of the Triton Inference Server, loading and unloading refer to the process of adding or removing a model to or from the server’s model repository. Once a model is loaded, it is ready to serve inference requests.
Benchmark all: Run a benchmark for all of the listed deployed models. Note that Shapley values are noticeably slower than regular predictions.
Unload all: Unloads all of the deployed models. Unloading a model from the Triton Inference Server involves removing the model from the server’s model repository, which frees up resources that can be used by other models. This lets you save memory without having to delete models. Models that have been unloaded can be loaded again.
Python client: Displays instructions for downloading, installing, and using the Driverless AI Triton Python Client for Python 3.x.
Back: Return to the completed experiment page.
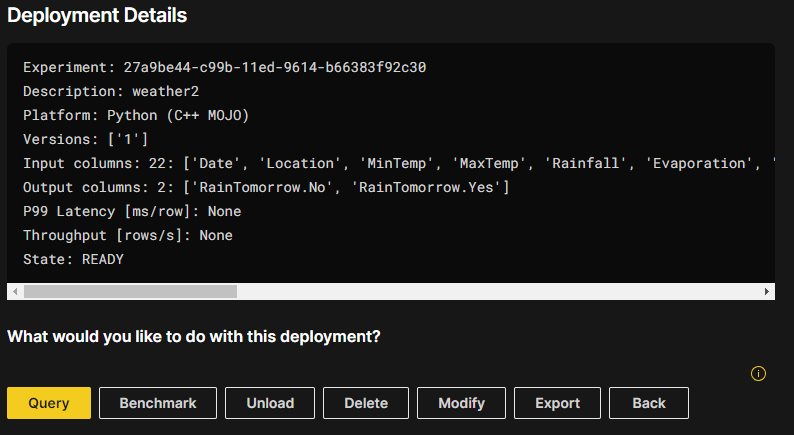
Actions available from the deployment Details page
The following list describes the actions that are available from the deployment Details page. You can access these actions by clicking DETAILS next to a specific deployed model in the list of deployed models.
Query: Creates a simple single-row query with curl that can be used to score the model with the HTTP REST API.
Benchmark: Performs simple runtime characterization of the endpoint.
Load / Unload: In the context of the Triton Inference Server, loading and unloading refer to the process of adding or removing a model to or from the server’s model repository. You can use this button to load or unload a specific model.
Modify: Redeploys the model. You can choose to deploy any combination of Target Predictions/Shapley Values/Original Shapley Values.
Export: Lets you download a zip file of the contents of the folder inside any Triton repository, anywhere.
Back: Return to the deployed models listing page.
MOJO With Java Runtime deployment options
The following are several options for deploying Driverless AI MOJO with Java Runtime. The links in the diagram lead to code examples and templates.
Driverless AI MOJO Java Runtime Deployment Options
The Java MOJO scoring pipelines can also be deployed from within the Driverless AI GUI. For more information, see Deployment options from within Driverless AI GUI.
MOJO With C++ Runtime deployment options
Here we list some example scenarios and platforms for deploying Driverless AI MOJO with C++ Runtime. MOJO C++ runtime can also be run directly from R/Python terminals. For more information, see Driverless AI MOJO Scoring Pipeline - C++ Runtime with Python (Supports Shapley) and R Wrappers.
Driverless AI MOJO C++ Runtime Deployment Options