What's new in h2oGPTe v1.5
We are excited to announce the release of h2oGPTe 1.5! Read on to learn about the new features in the 1.5.x series which will improve your ability to find answers and generate new content based on your private data.
Chat First
The GUI has been revamped to lead with chat first. You can start chatting immediately, and add documents or collections to the chat.
New Connectors
New connectors in v1.5:
- Amazon S3
- Google Cloud Storage
- Azure BLOB
- Sharepoint
- Upload Plain Text (automatically triggered if large text is copy & pasted into the chat)
Choice of OCR models
The v1.5 release brings support for more languages by introducing a new set of OCR model choices (for conversion of documents to text), including the auto-detection of the language for each page of every document.
- Automatic (default)
- Tesseract (over 60 different languages)
- DocTR
- PaddleOCR
- PaddleOCR-Chinese
- PaddleOCR-Arabic
- PaddleOCR-Japanese
- PaddleOCR-Korean
- PaddleOCR-Cyrillic
- PaddleOCR-Devanagari
- PaddleOCR-Telugu
- PaddleOCR-Kannada
- PaddleOCR-Tamil
Model Comparison Page
A new models page offers easy comparison between all LLMs
- Tabular view of all metrics such as cost, accuracy, speed, latency, context lengths, vision capabilities, guided generation features and chat template
- Graphical scatter plot to compare models across 2 dimensions, with optional log-scale
- Usage and performance stats are now shown as a tab on the models page
- A self-test button shows green or red lights for each LLM within secons to confirm that all LLMs are operational with "quick" and "rag" benchmark modes exposed to all users that test chat and RAG modes.
- Admins have access to "full" and "stress" tests as well, to make sure LLMs are configured to handle large contexts properly.
Model Routing with Cost Controls
Automatically chooses the best LLM for the task given cost constraints such as:
- Max cost per LLM call
- Willingness to pay for extra accuracy (how much to pay for +10% accuracy for this LLM call?)
- Willingness to wait for extra accuracy (how long to wait for +10% accuracy for this LLM call?)
- Max cost per million tokens for LLMs to be considered
- Fixed list of models to choose from
Any of these cost controls can be combined. The GUI exposes the first 3 cost constraints.
Guardrails
Fully customizable Guardrails:
- Prompt Guard (fine-tuned DeBERTa v3 model), Jailbreak and Prompt Injection
- Llama Guard (fine-tuned LLM), 14 classes of unsafe content
- Custom Guardrails, arbitrary LLM and prompting
Guardrails are applied to:
- All user prompts
If unsafe content is detected, the following action is performed:
- fail
Redaction of PII or regular expressions
These PII detection methods are combined for maximum precision and recall:
- regular expressions
- Presidio model: 5 languages (en, es, fr, de, zh), 36 different PII entities
- Custom PII model: 59 different PII entities
Personally identifiable information (PII) is checked for in these places:
- Parsing of documents
- LLM input
- LLM output
If PII is detected in any of the above places, one of the following actions is performed:
- allow
- redact
- fail
You have full control over the list of entities to flag, via JSON spec, controllable per collection.
Document Metadata
You can now choose what information from the document is provided to the LLM.
- Filename
- Page Number
- Document Text
- Document Age
- Last Modification Date
- Retrieval Score
- Ingestion Method
- URI
Multimodal Vision Capabilities
v1.5.x brings support for multimodal vision capabilities, including state-of-the-art open-source vision models. This allows processing of flowcharts, images, diagrams and more.
- GPT-4o/GPT-4o-mini
- Gemini-1.5-Pro/Flash
- Claude-3/Claude-3.5
- InternVL-Chat
- InternVL2-26B/76B
Support for upcoming LLMs via Chat Templates
v1.5.x can support yet unreleased future LLMs using Hugging Face chat templates.
Guided Generation
A powerful new feature in v1.5 is the guided generation. For example, the LLM can be instructed to create perfect JSON that adheres to a provided schema. Or it can be instructed to create output that matches a regular expression, or follows a certain grammar, or contains only output from a provided list of choices.
All these powerful options are exposed in the API:
- guided_json
- guided_regex
- guided_choice
- guided_grammar
- guided_whitespace_pattern
Note that guided generation also works for vision models. For most (proprietary) models not hosted by vLLM (such as OpenAI, Claude, etc.), only guided_json is supported for now.
Document AI: Summarize, Extract, Process
The document summarization API was generalized to full document processing using the map/reduce paradigm for LLMs. In combination with the new connectors, custom OCR models, document metadata, PII redaction, guided generation, multimodal vision models, prompt templates, powerful Document AI workflows are now possible.
Example use cases:
- Custom summaries
- Convert flow charts to custom JSON
- Extract all financial information
- Classify documents or images with custom labels
Tagging Documents and Chatting with a subset of the Collection
You can now tag documents (via the Python client), and provide a list of tags to include when chatting with a collection.
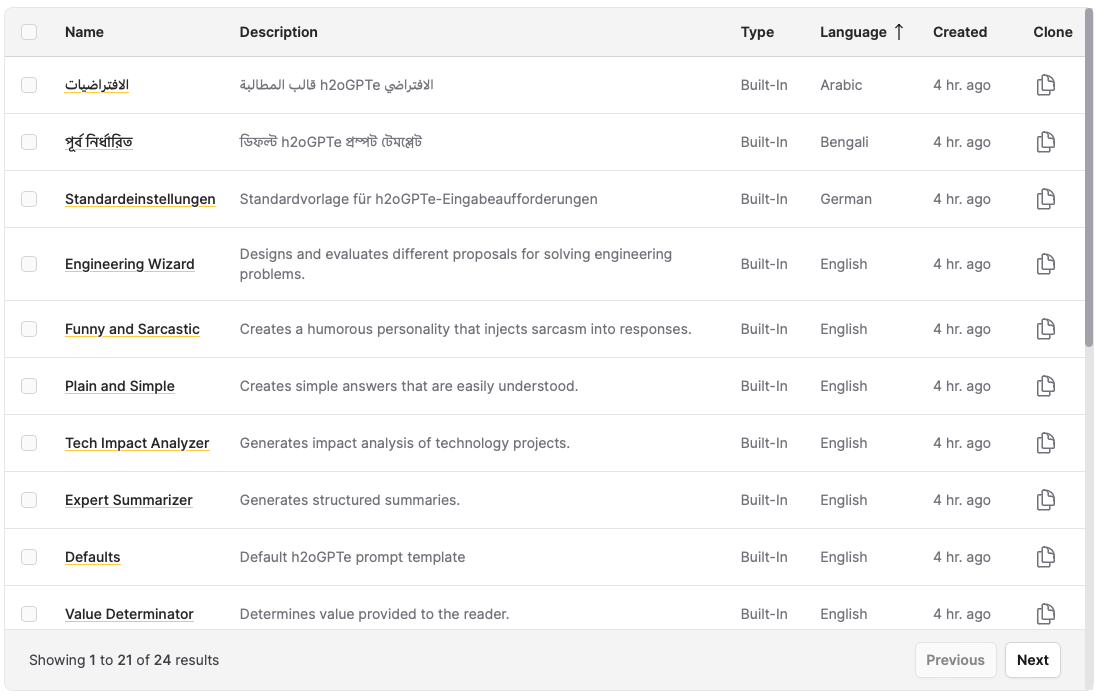
Out of the box prompt templates
Multiple new prompt templates were added for convenience.
Improved Scalability and Speed
Several improvements to improve the responsiveness of the application have been made.
Eval Studio integration
H2O Eval Studio is now integrated into h2oGPTe.
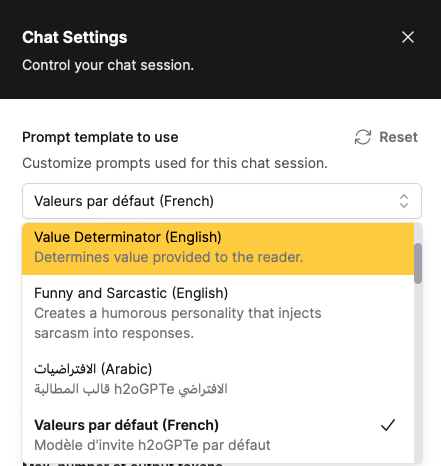
Sharing of Prompt Templates
Prompt templates can now be shared with selected users.
Improved Cloud integration
Minio backend for storage can be replaced with S3. GCS/Azure storage backend is upcoming.
Security Vulnerability Fixes
No critical or high CVEs at the time of release.
Live logs for admins
Real-time logs for core/crawl/chat services for administrator users.