Return to docs
What's new in h2oGPTe v1.4.13
We are excited to announce the release of h2oGPTe 1.4.13! Read on to learn about the new features in the 1.4.x series which will improve your ability to find answers and generate new content based on your private data.
Create non-English embeddings
Your data isn't always in English. In fact, your documents, audio files, and images may span many languages, and now, h2oGPTe can help you answer questions on any language.
v1.4.x brings support for a new embedding model, bge-m3. This embedding model is best in class for multi-lingual data and supports more than 100 languages.
We recommend using bge-large-en-v1.5 for English use cases and this is the default embedding model used in the environment.
Customize the Embedding Model per Collection
You may want to customize the embedding model used for each collection of documents or use case, and now you can when creating a new collection.
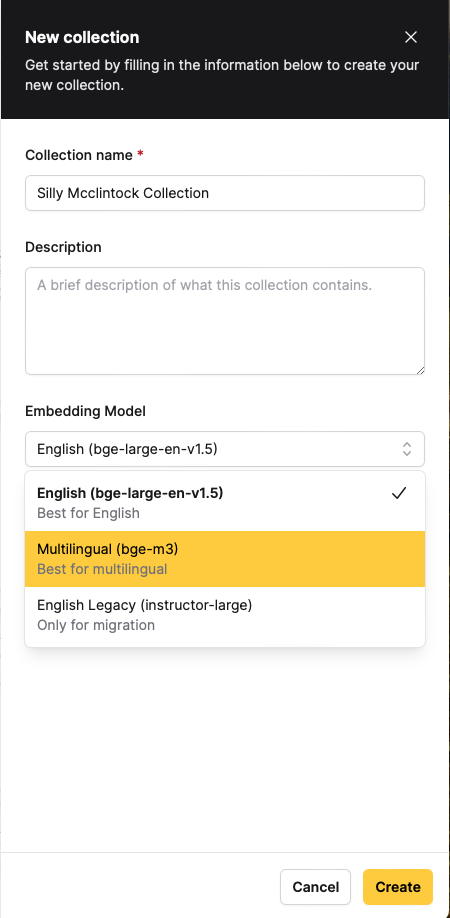
All documents added to this collection will be embedded using that model, and all queries to this collection will use that embedding model. Please note that you cannot change the emedding model of a collection after the fact, it is only editable while creating the collection.
Embedding Model options
The generative AI space is moving fast and there are new technologies every week. H2O.ai is regularly adding support for new embedding and language models. Today, you can enable the following embedding models in your environment:
- bge-large-en-v1.5
- bge-m3
- instructor-large
- bge-large-zh-v1.5
- multilingual-e5-large
- instructor-xl
Support for new LLMs
The v1.4 release series brings support for many new LLMs including H2O.ai's small language models H2O Danube. Working with Southeast Asia? You may want to use SeaLLM-7B-v2 or sea-lion-7b-instruct.
The full list has 18+ types of LLMs supported with the latest and greatest regularly being added.

Introducing the Prompt Catalog
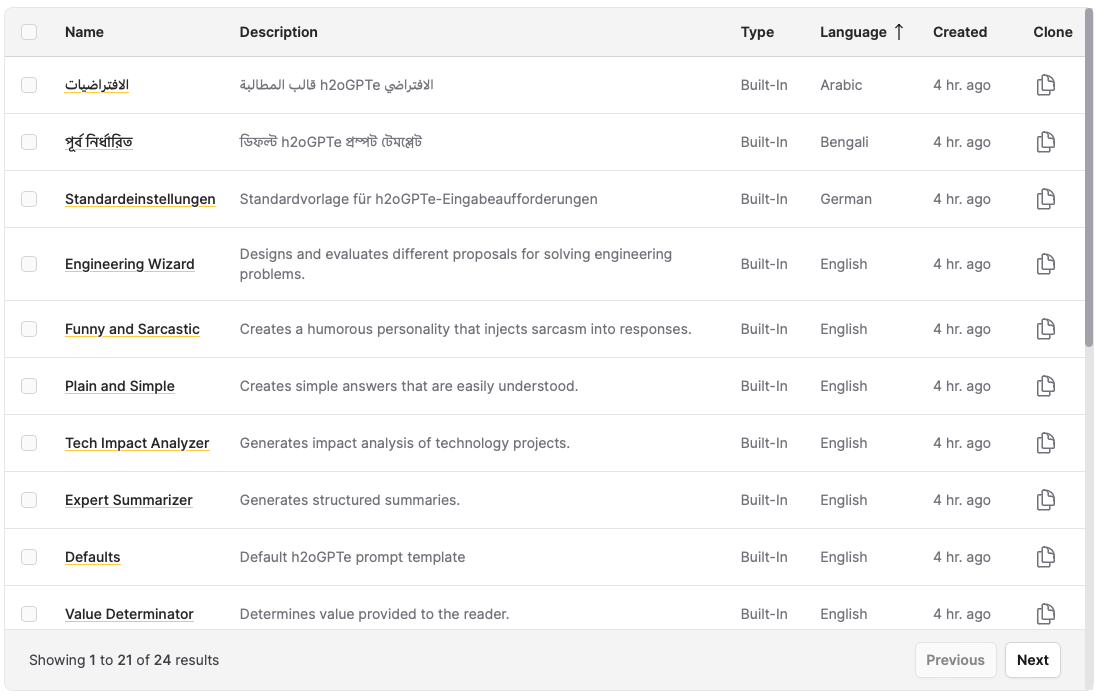
Gone are the days of having a collection of really good System Prompts saved in a file on your desktop! The new Prompt Catalog comes with 18+ out of the box prompts for common tasks like Question Answering (in many languages) and Expert Summarizing and tones like Funny or Simple.
You can explore all of the available prompts and create your own on the new Prompts page.
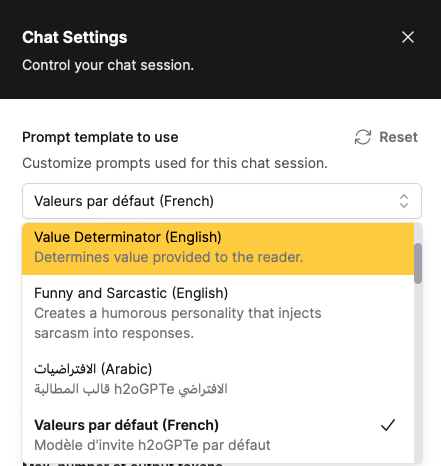
When chatting, click the Settings button down near where you chat to chate the prompt template you're using.
Out of the Box Language Prompts
The following languages are supported for RAG out of the box by selecting the right prompt template, remember to also use the multi-language embedding model:
- Chinese
- Turkish
- Russian
- Portuguese
- Malay
- Japanese
- Indonesian
- Hindi
- French
- Persian
- Spanish Castilian
Out of the Box English Use Cases
While users can create their own prompt templates, there are also 9 common use cases supported out of the box.
- Retrieval Augmented Generation (this is the default)
- Expert Summarizer: Generates structured summaries
- Plain and Simple: Creates simple answers that are easily understood
- Funny and Sarcastic: Creates a humorous personality that injects sarcasm into responses
- Citations: Provide citations and references to end users
- Keynote Presentation: Generates TED-quality keynote presentations
- Tech Impact Analyzer: Generates impact analysis of technology projects
- Value Determinator: Determines the value provided to the reader
- Engineering Wizard: Designs and evaluates different proposals for solving engineering problems
When creating your own prompt template, you can choose to use any of these as the starting point if you would like to slightly alter them.
Example: Citation Prompt Template
As an example, we have uploaded the h2oGPTe documentation into the h2oGPTe product and asked "How can I add a new document into a collection?". With the default prompt template, which is optimized for Retrieval Augmented Generation, we get the following helpful answer:
To add a new document into a collection, follow these steps according to the information provided in the document context:
1. Navigate to the Enterprise h2oGPTe navigation menu.
2. Click on 'Collections'.
3. Select the name of the Collection you want to add a document to.
4. Click on '+ Add documents'.
5. Choose a method to import the document, such as Upload documents or Import from system.
6. Browse for the document you want to add.
7. Click 'Add'.
Please note that the exact wording of the navigation menu items and buttons might vary slightly depending on the specific version of Enterprise h2oGPTe you are using.
This helps our end users, but maybe would would like to also provide citation to users so they can go read the full documentation themselves. We will click Settings and select Citation from the dropdown list of Prompt Templates. Asking the same question, we get the same answer, except now we have a list of the exact documentation pages that the answer came from.
To add a new document into a collection, follow these steps according to the document sources provided:
1. Navigate to the Enterprise h2oGPTe interface.
2. Click on 'Collections' in the navigation menu.
3. Select the specific collection where you want to add a document.
4. Click on '+ Add documents'.
5. Choose a method to import the document, such as 'Upload documents' or 'Import from system'.
6. Browse and select the document you wish to add.
7. Click 'Add'.
Remember, you can only select an embedding model once when creating a new collection. Also, you can toggle the 'Create short document summaries' button to auto-generate a summary of your document, and the 'Create sample questions for documents' button to receive auto-suggested sample questions based on your document.
[1] Guide - Collections - Add a Document(s) to a Collection - Version: v1.4.11 - Enterprise h2oGPTe documentation
[2] Create a Collection - Version: v1.3.11 - Enterprise h2oGPTe documentation
[3] Add a Document(s) to a Collection - Version: v1.3.11 - Enterprise h2oGPTe documentation
[4] Add a Document(s) to a Collection - Version: v1.1.7 - Enterprise h2oGPTe documentation
[5] Add a Document(s) to a Collection - Version: v1.4.9 - Enterprise h2oGPTe documentation
We can see that we have access to multiple version of the documentation. As a user, we might then ask the same question but clarify which versions we are using.
Chat redesign
There are many changes to the feel and functionality of the Chat sessions in the 1.4 release:
- Settings can now be found in the chat tool bar
- Customize the LLM tempurature to make more creative or deterministic answers
- Set the maximum lenght of responses
- Set the number of neighbor chunks for RAG+ to add additional context from the source documents
- New controls for each part of the conversation can be found to the right of the user's message
- Copy the response
- Provide feedback if the response was good or bad
- View the entire prompt and context sent to the LLM
- View usage and cost information about the LLM interaction
- Delete this Q&A
- Ask questions with audio using the Listen function of the chat toolbar
- Easily start chatting with LLMs from the UI without using a collection of data using the
New Chatbutton from the Chat Sessions page
H2O AI Cloud integration
Users of the H2O AI Cloud can now authenticate to their h2oGPTe environment using the Platform Token improving the end-to-end Predictive and Generative workflow.
This is especially helpful when building custom UIs on top of h2oGPTe using Wave. The below code can be used to authenticate to h2oGPTe in your Wave app deployed in the App Store making it so that all users who use your app are logging in to h2oGPTe as themselves.
from h2ogpte import H2OGPTE
import h2o_authn
token_provider = h2o_authn.TokenProvider(
refresh_token=q.auth.refresh_token,
token_endpoint_url=f"{os.getenv('H2O_WAVE_OIDC_PROVIDER_URL')}/protocol/openid-connect/token",
client_id=os.getenv("H2O_WAVE_OIDC_CLIENT_ID"),
client_secret=os.getenv("H2O_WAVE_OIDC_CLIENT_SECRET"),
)
client = H2OGPTE(address=os.getenv("H2OGPTE_URL"), token_provider=token_provider)
Enhanced Jobs experience
When doing document analytics and chat, many of the steps can take some time, such as ingesting a large website or deleting old files. Long running tasks, or Jobs, can be found by clicking the server icon in the top right hand corner. This will open a queue of any running tasks including the ability to easily read error messages if anything went wrong.
General Improvements
- Search and filter documents by name
- View the retrieval and LLM response name for each query in the Chat Session Usage
- Improved quality of generated example questions
- Less steps needed to customize LLM parameters from the Python API
- Chat sharing is now available for air-gapped installs