Generalized Linear Model (GLM)¶
Introduction¶
Generalized Linear Models (GLM) estimate regression models for outcomes following exponential distributions. In addition to the Gaussian (i.e. normal) distribution, these include Poisson, binomial, and gamma distributions. Each serves a different purpose, and depending on distribution and link function choice, can be used either for prediction or classification.
The GLM suite includes:
Gaussian regression
Poisson regression
Binomial regression (classification)
Fractional binomial regression
Quasibinomial regression
Multinomial classification
Gamma regression
Ordinal regression
Negative Binomial regression
Tweedie distribution
Additional Resources¶
Defining a GLM Model¶
Parameters are optional unless specified as required.
Algorithm-specific parameters¶
build_null_model: If set, will build a model with only the intercept. This option defaults to
False.calc_like: Specify whether to return likelihood function value for HGLM or normal GLM. Setting this option to
Truewhile disablingHGLMwill enable the calculation of the full log likelihood and full AIC. This option defaults toFalse(disabled).control_variables: Specify control variables which will be disabled for metric calculation and during scoring. This feature is experimental.
custom_metric_func: Specify a custom evaluation function.
dispersion_epsilon: If changes in dispersion parameter estimation or loglikelihood value is smaller than
dispersion_epsilon, this will break out of the dispersion parameter estimation loop using maximum likelihood. This option defaults to0.0001.dispersion_learning_rate: (Applicable only when
dispersion_parameter_method="ml") This value controls how much the dispersion parameter estimate will be changed when the calculated loglikelihood actually decreases with the new dispersion. In this case, instead of setting dispersion = dispersion + change, it is dispersion + dispersion_learning_rate \(\times\) change. This option must be > 0 and defaults to0.5.dispersion_parameter_method: Method used to estimate the dispersion factor for Tweedie, Gamma, and Negative Binomial only. Can be one of
"pearson"(default),"deviance", or"ml".fix_dispersion_parameter: Only used for Tweedie, Gamma and Negative Binomial GLM. If enabled, this option will use the dispsersion parameter in
init_dispersion_parameteras the standard error and use it to calculate the p-values. This option defaults toFalse.generate_scoring_history: Generate the scoring history for the GLM model when enabled. This may significantly slow down the algorithm. When enabled, you will also be able to fetch the average objective and the negative log likelihood using their accessor functions:
average_objectiveandnegative_log_likelihood. This option defaults toFalse(disabled).generate_variable_inflation_factors: If enabled, this option generates the variable inflation factors for numerical predictors. This option defaults to
False(disabled).init_dispersion_parameter: Initial value of disperion factor before being estimated using either
"pearson"or"ml". This option defaults to1.0.interactions: Specify a list of predictor column indices to interact. All pairwise combinations will be computed for this list.
interaction_pairs: When defining interactions, use this option to specify a list of pairwise column interactions (interactions between two variables). Note that this is different than
interactions, which will compute all pairwise combinations of specified columns.
max_iterations: For GLM, must be \(\geq\) 1 to obtain a proper model (or -1 for unlimited which is the default setting). Setting it to 0 will only return the correct coefficient names and an empty model.
max_iterations_dispersion: Control the maximum number of iterations in the dispersion parameter estimation loop using maximum likelihood. This option defaults to
1000000.rand_family: The Random Component Family specified as an array. You must include one family for each random component. Currently only
rand_family=["gaussisan"]is supported.upload_custom_metric: Upload a custom metric into a running H2O cluster.
Shared GLM family parameters¶
GLM Family:  Generalized Additive Models (GAM)
Generalized Additive Models (GAM)  ModelSelection
ModelSelection  ANOVA GLM
ANOVA GLM  Hierarchical Generalized Linear Model (HGLM)
Hierarchical Generalized Linear Model (HGLM)
alpha:
Specify the regularization distribution between L1 and L2. A value of 1produces LASSO regression; a value of0produces Ridge regression. The default value ofalphais0whenSOLVER = 'L-BFGS'; otherwise it is0.5to specify a mixing between LASSO and Ridge regression.beta_constraints:
Specify a dataset to use beta constraints. The selected frame is used to constrain the coefficient vector to provide upper and lower bounds. The dataset must contain a “names” column with valid coefficient names.beta_epsilon:
Converge if beta changes less than this value (using L-infinity norm). This only applies to IRLSMsolver, and the value defaults to0.0001.cold_start:
Specify whether the model should be built from scratch. This parameter is only applicable when building a GLM model with multiple alpha/lambdavalues. IfFalseand for a fixedalphavalue, the next model with the nextlambdavalue out of thelambdaarray will be built using the coefficients and the GLM state values of the current model. IfTrue, the next GLM model will be built from scratch. The default value isFalse.note If an
alphaarray is specified and for a brand newalpha, the model will be built from scratch regardless of the value ofcold_start.compute_p_values:
Request computation of p-values. P-values can be computed with or without regularization. Setting remove_collinear_columnsis recommended. H2O will return an error if p-values are requested and there are collinear columns andremove_collinear_columnsflag is not enabled. Note that this option is not available forfamily="multinomial"orfamily="ordinal";IRLSMsolver requried. This option defaults toFalse(disabled).family:
Specify the model type.If the family is
gaussian, the response must be numeric (Real or Int).If the family is
binomial, the response must be categorical 2 levels/classes or binary (Enum or Int).If the family is
fractionalbinomial, the response must be a numeric between 0 and 1.If the family is
multinomial, the response can be categorical with more than two levels/classes (Enum).If the family is
ordinal, the response must be categorical with at least 3 levels.If the family is
quasibinomial, the response must be numeric.If the family is
poisson, the response must be numeric and non-negative (Int).If the family is
negativebinomial, the response must be numeric and non-negative (Int).If the family is
gamma, the response must be numeric and continuous and positive (Real or Int).If the family is
tweedie, the response must be numeric and continuous (Real) and non-negative.If the family is
AUTO(default),and the response is Enum with cardinality = 2, then the family is automatically determined as
binomial.and the response is Enum with cardinality > 2, then the family is automatically determined as
multinomial.and the response is numeric (Real or Int), then the family is automatically determined as
gaussian.
gradient_epsilon:
(For solver="L_BFGS"only) Specify a threshold for convergence. If the objective value (using the L-infinity norm) is less than this threshold, the model is converged. Iflambda_search=True, then this value defaults to.0001. Iflambda_search=Falseandlambdais equal to zero, then this value defaults to.000001. For any other value oflambda, this value defaults to.0001. This value defaults to-1.intercept:
Specify whether to include a constant term in the model. This option defaults to True(enabled).lambda:
Specify the regularization strength.lambda_min_ratio:
Specify the minimum lambda to use for lambda search (specified as a ratio of lambda_max, which is the smallest \(\lambda\) for which the solution is all zeros). This value defaults to -1which indicates that if the number of observations is greater than the number of variables, thenlambda_min_ratiois set to 0.0001; if the number of observations is less than the number of variables, thenlambda_min_ratiois set to 0.01.lambda_search:
Specify whether to enable lambda search, starting with lambda max (the smallest \(\lambda\) that drives all coefficients to zero). If you also specify a value for lambda_min_ratio, then this value is interpreted as lambda min. If you do not specify a value forlambda_min_ratio, then GLM will calculate the minimum lambda. This option defaults toFalse(disabled).link:
Specify a link function (one of: Identity,Family_Default(default),Logit,Log,Inverse,Tweedie, orOlogit).If the family is
Gaussian, thenIdentity,Log, andInverseare supported.If the family is
Binomial, thenLogitis supported.If the family is
Fractionalbinomial, thenLogitis supported.If the family is
Poisson, thenLogandIdentityare supported.If the family is
Gamma, thenInverse,Log, andIdentityare supported.If the family is
Tweedie, then onlyTweedieis supported.If the family is
Multinomial, then onlyFamily_Defaultis supported. (This defaults tomultinomial.)If the family is
Quasibinomial, then onlyLogitis supported.If the family is
Ordinal, then onlyOlogitis supportedIf the family is
Negative Binomial, thenLogandIdentityare supported.If the family is
AUTO,and a link is not specified, then the link is determined as
Family_Default(defaults to the family to whichAUTOis determined).and a link is specified, the link is used so long as the specified link is compatible with the family to which
AUTOis determined. Otherwise, an error message is thrown stating thatAUTOfor underlying data requires a different link and gives a list of possible compatible links.The list of supported links for
family = AUTOis:If the response is Enum with cardinality = 2, then
Logitis supported.If the response is Enum with cardinality > 2, then only
Family_Defaultis supported (this defaults tomultinomial).If the response is numeric (Real or Int), then
Identity,Log, andInverseare suported.
max_active_predictors:
Specify the maximum number of active predictors during computation. This value is used as a stopping criterium to prevent expensive model building with many predictors. This value defaults to -1.nlambdas:
(Applicable only if lambda_search=True) Specify the number of lambdas to use in the search. Whenalpha> 0, the default value forlambda_min_ratiois \(1e^{-4}\), then the default value fornlambdasis 100. This gives a ratio of 0.912. (For best results when using strong rules, keep the ratio close to this default.) Whenalpha=0, the default value fornlamdasis set to30because fewer lambdas are needed for ridge regression. This value defaults to-1.non_negative:
Specify whether to force coefficients to have non-negative values. This option defaults to False(disabled).obj_reg:
Specifies the likelihood divider in objective value computation. This defaults to 1/nobs.objective_epsilon:
If the objective value is less than this threshold, then the model is converged. If lambda_search=True, then this value defaults to.0001. Iflambda_search=Falseandlambdais equal to zero, then this value defaults to.000001. For any other value oflambda, the default value ofobjective_epsilonis set to.0001. The default value is-1.plug_values:
(Applicable only if missing_values_handling="PlugValues") Specify a single row frame containing values that will be used to impute missing values of the training/validation frame.prior:
Specify prior probability for \(p(y==1)\). Use this parameter for logistic regression if the data has been sampled and the mean of response does not reflect reality. This value defaults to -1and must be a value in the range (0,1).Note: This is a simple method affecting only the intercept. You may want to use weights and offset for a better fit.
remove_collinear_columns:
Specify whether to automatically remove collinear columns during model-building. When enabled, collinear columns will be dropped from the model and will have 0 coefficient in the returned model. This option defaults to False(disabled).score_iteration_interval:
Perform scoring for every score_iteration_intervaliteration. This option defaults to-1.solver:
Specify the solver to use. One of:IRLSM: fast on problems with a small number of predictors and for lambda search with L1 penaltyL_BFGS: scales better for datasets with many columns; read more on L_BFGSCOORDINATE_DESCENT:IRLSMwith the covariance updates version of cyclical coordinate descent in the innermost loopCOORDINATE_DESCENT_NAIVE:IRLSMwith the naive updates version of cyclical coordinate descent in the innermost loopGRADIENT_DESCENT_LH: can only be used with theordinalfamilyGRADIENT_DESCENT_SQERR: can only be used with theordinalfamilyAUTO(default): will set the solver based on the given data and other parameters
theta:
Theta value (equal to \(\frac{1}{r}\)) for use when family="negativebinomial. This value must be > 0 and defaults to1e-10.tweedie_link_power:
(Only applicable if family="tweedie") Specify the Tweedie link power. This option defaults to1.tweedie_variance_power:
(Only applicable if family="tweedie") Specify the Tweedie variance power. This option defaults to0.
Common parameters¶
auc_type: Set the default multinomial AUC type. Must be one of:
"AUTO"(default)"NONE""MACRO_OVR""WEIGHTED_OVR""MACRO_OVO""WEIGHTED_OVO"
checkpoint: Enter a model key associated with a previously trained model. Use this option to build a new model as a continuation of a previously generated model.
Note: GLM only supports checkpoint for the
IRLSMsolver. The solver option must be set explicitly toIRLSMand cannot be set toAUTO. In addition, checkpoint for GLM does not work when cross-validation is enabled.
early_stopping: Specify whether to stop early when there is no more relative improvement on the training or validation set. This option defaults to
True(enabled).export_checkpoints_dir: Specify a directory to which generated models will automatically be exported.
fold_assignment: (Applicable only if a value for
nfoldsis specified andfold_columnis not specified) Specify the cross-validation fold assignment scheme. One of:AUTO(default; usesRandom)RandomModulo(read more about Modulo)Stratified(which will stratify the folds based on the response variable for classification problems)
fold_column: Specify the column that contains the cross-validation fold index assignment per observation.
ignore_const_cols: Enable this option to ignore constant training columns, since no information can be gained from them. This option defaults to
True(enabled).keep_cross_validation_fold_assignment: Enable this option to preserve the cross-validation fold assignment. This option defaults to
False(disabled).keep_cross_validation_models: Specify whether to keep the cross-validated models. Keeping cross-validation models may consume significantly more memory in the H2O cluster. This option defaults to
True(enabled).keep_cross_validation_predictions: Specify whether to keep the cross-validation predictions. This option defaults to
False(disabled).max_iterations: Specify the number of training iterations. This options defaults to
-1.max_runtime_secs: Maximum allowed runtime in seconds for model training. Use
0(default) to disable.missing_values_handling: Specify how to handle missing values. One of:
Skip,MeanImputation(default), orPlugValues.model_id: Specify a custom name for the model to use as a reference. By default, H2O automatically generates a destination key.
nfolds: Specify the number of folds for cross-validation. The value can be
0(default) to disable or \(\geq\)2.offset_column: Specify a column to use as the offset; the value cannot be the same as the value for the
weights_column.Note: Offsets are per-row “bias values” that are used during model training. For Gaussian distributions, they can be seen as simple corrections to the response (
y) column. Instead of learning to predict the response (y-row), the model learns to predict the (row) offset of the response column. For other distributions, the offset corrections are applied in the linearized space before applying the inverse link function to get the actual response values.score_each_iteration: Enable this option to score during each iteration of the model training. This option defaults to
False(disabled).seed: Specify the random number generator (RNG) seed for algorithm components dependent on randomization. The seed is consistent for each H2O instance so that you can create models with the same starting conditions in alternative configurations. This option defaults to
-1(time-based random number).standardize: Specify whether to standardize the numeric columns to have a mean of zero and unit variance. Standardization is highly recommended; if you do not use standardization, the results can include components that are dominated by variables that appear to have larger variances relative to other attributes as a matter of scale, rather than true contribution. This option defaults to
True(enabled).startval:
Specify a double array to initialize the GLM coefficients. If standardizeisTrue, provide standardized coefficient values. Otherwise, provide regular coefficient values.stopping_metric: Specify the metric to use for early stopping. The available options are:
AUTO(default): (This defaults tologlossfor classification anddeviancefor regression)devianceloglossMSERMSEMAERMSLEAUC(area under the ROC curve)AUCPR(area under the Precision-Recall curve)lift_top_groupmisclassificationmean_per_class_error
stopping_rounds: Stops training when the option selected for
stopping_metricdoesn’t improve for the specified number of training rounds, based on a simple moving average. To disable this feature, specify0(default).Note: If cross-validation is enabled:
All cross-validation models stop training when the validation metric doesn’t improve.
The main model runs for the mean number of epochs.
N+1 models may be off by the number specified for
stopping_roundsfrom the best model, but the cross-validation metric estimates the performance of the main model for the resulting number of epochs (which may be fewer than the specified number of epochs).
stopping_tolerance: Specify the relative tolerance for the metric-based stopping to stop training if the improvement is less than this value. Defaults to
0.001.training_frame: Required Specify the dataset used to build the model. NOTE: In Flow, if you click the Build a model button from the
Parsecell, the training frame is entered automatically.validation_frame: Specify the dataset used to evaluate the accuracy of the model.
weights_column: Specify a column to use for the observation weights, which are used for bias correction. The specified
weights_columnmust be included in the specifiedtraining_frame.Python only: To use a weights column when passing an H2OFrame to
xinstead of a list of column names, the specifiedtraining_framemust contain the specifiedweights_column.Note: Weights are per-row observation weights and do not increase the size of the data frame. This is typically the number of times a row is repeated, but non-integer values are supported as well. During training, rows with higher weights matter more due to the larger loss function pre-factor.
x: Specify a vector containing the names or indices of the predictor variables to use when building the model. If
xis missing, then all columns exceptyare used.y: Required Specify the column to use as the dependent variable.
For a regression model, this column must be numeric (Real or Int).
For a classification model, this column must be categorical (Enum or String). If the family is
Binomial, the dataset cannot contain more than two levels.
Interpreting a GLM Model¶
By default, the following output displays:
Model parameters (hidden)
A bar chart representing the standardized coefficient magnitudes (blue for negative, orange for positive). Note that this only displays is standardization is enabled.
A graph of the scoring history (objective vs. iteration)
Output (model category, validation metrics, and standardized coefficients magnitude)
GLM model summary (family, link, regularization, number of total predictors, number of active predictors, number of iterations, training frame)
Scoring history in tabular form (timestamp, duration, iteration, log likelihood, objective)
Training metrics (model, model checksum, frame, frame checksum, description, model category, scoring time, predictions, MSE, r2, residual deviance, null deviance, AIC, null degrees of freedom, residual degrees of freedom)
Coefficients
Standardized coefficient magnitudes (if standardization is enabled)
Classification and Regression¶
GLM can produce two categories of models: classification and regression. Logistic regression is the GLM performing binary classification.
Handling of Categorical Variables¶
GLM supports both binary and multinomial classification. For binary classification, the response column can only have two levels; for multinomial classification, the response column will have more than two levels. We recommend letting GLM handle categorical columns, as it can take advantage of the categorical column for better performance and memory utilization.
We strongly recommend avoiding one-hot encoding categorical columns with any levels into many binary columns, as this is very inefficient. This is especially true for Python users who are used to expanding their categorical variables manually for other frameworks.
Handling of Numeric Variables¶
When GLM performs regression (with factor columns), one category can be left out to avoid multicollinearity. If regularization is disabled (lambda = 0), then one category is left out. However, when using a the default lambda parameter, all categories are included.
The reason for the different behavior with regularization is that collinearity is not a problem with regularization. And it’s better to leave regularization to find out which level to ignore (or how to distribute the coefficients between the levels).
Regression Influence Diagnostics¶
Regression influence diagnostics reveal the influence of each data row on the GLM parameter determination for IRLSM. This shows the parameter value change for each predictor when a data row is included and excluded in the dataset used to train the GLM model.
To find the regression diagnostics for the Gaussian family, the output is:
For the whole dataset, there is:
where:
\(Y\) is a column vector with \(N\) elements and \(Y = \begin{bmatrix} y_0 \\ y_1 \\ y_2 \\ \vdots \\ y_{N-1} \\\end{bmatrix}\);
\(X\) is a \(N \times p\) matrix containing \(X = \begin{bmatrix} x_0^T \\ x_1^T \\ x_2^T \\ \vdots \\ x_{N-1}^T \\\end{bmatrix}\);
\(x_i\) is a column vector with \(p\) elements: \(x_i = \begin{bmatrix} x_{i0} \\ x_{i1} \\ \vdots \\ x_{ip -2} \\ 1 \\\end{bmatrix}\) where \(1\) is added to represent the term associated with the intercept term.
The least square solution for \(\beta\) is:
The residual is defined as:
The projection matrix is:
The residual in equation 1 is good at pointing out ill-fitting points. However, if does not adequately reveal which observations unduly influence the fit of \(\beta\). The diagonal of \(M\) can direct to those points. Influential points tend to have small values of \(m_{ii}\) (much smaller than the average value of \(1 - \frac{m}{N}\) where \(m\) is the number of predictors and \(N\) is the number of rows of data in the dataset).
The GLM model is then fitted with all the data to find \(\hat{\beta}\). Data row \(l\) is then deleted and the GLM model is fitted again to find \(\hat{\beta}(l)\) as the model coefficients. The influence of data row \(l\) can be found by looking at the parameter value change:
The DFBETAS for the \(k\text{th}\) coefficient due to the absence of data row \(l\) is calculated as:
where:
\(s_{(l)}^2 = \frac{1}{N-1-p} \sum_{i = 0 \text{ & } i \neq l}^{N-1} \big( y_i - x_i^T \hat{\beta}(l) \big)^2\) is for a non-weighted dataset. We have implemented the version of \(s_{(l)}^2\) that works with both weighted and non-weighted datasets.
\((X^TX)_{kk}^{-1}\) is the diagonal of the gram matrix inverse.
To find the regression diagnostics for the Binomial family, the output is
where \(\mu_i = \frac{1}{1 + exp(- \beta^T x_i -\beta_0)}\) and \(y_i = 1 \text{ or } 0\). The iterative coefficient update can be written as:
where:
\(V\) is a diagonal matrix with diagonal value \(v_{ii} = \mu_i (1-\mu_i)\);
\(s_i = y_i - \mu_i\).
The formula for DFBETAS for the \(k\text{th}\) coefficient due to the ansence of data row \(l\) is defined as:
where:
\(\hat{\sigma}_k\) is the standard error of the \(k\text{th}\) coefficient;
\(\Delta_l \hat{\beta}_k\) is the \(k\text{th}\) element of the vector \(\Delta_l \hat{\beta}\) which is approximated as:
\(w_l\) is the weight assigned to the data row;
\(h_{ll}\) is the diagonal of a hat matrix which is calculated as:
Family and Link Functions¶
GLM problems consist of three main components:
A random component \(f\) for the dependent variable \(y\): The density function \(f(y;\theta,\phi)\) has a probability distribution from the exponential family parametrized by \(\theta\) and \(\phi\). This removes the restriction on the distribution of the error and allows for non-homogeneity of the variance with respect to the mean vector.
A systematic component (linear model) \(\eta\): \(\eta = X\beta\), where \(X\) is the matrix of all observation vectors \(x_i\).
A link function \(g\): \(E(y) = \mu = {g^-1}(\eta)\) relates the expected value of the response \(\mu\) to the linear component \(\eta\). The link function can be any monotonic differentiable function. This relaxes the constraints on the additivity of the covariates, and it allows the response to belong to a restricted range of values depending on the chosen transformation \(g\).
Accordingly, in order to specify a GLM problem, you must choose a family function \(f\), link function \(g\), and any parameters needed to train the model.
Families¶
The family option specifies a probability distribution from an exponential family. You can specify one of the following, based on the response column type:
gaussian: (See Linear Regression (Gaussian Family).) The response must be numeric (Real or Int). This is the default family.binomial: (See Logistic Regression (Binomial Family)). The response must be categorical 2 levels/classes or binary (Enum or Int).fractionalbinomial: See (Fractional Logit Model (Fraction Binomial)). The response must be a numeric between 0 and 1.ordinal: (See Logistic Ordinal Regression (Ordinal Family)). Requires a categorical response with at least 3 levels. (For 2-class problems, use family=”binomial”.)quasibinomial: (See Pseudo-Logistic Regression (Quasibinomial Family)). The response must be numeric.multinomial: (See Multiclass Classification (Multinomial Family)). The response can be categorical with more than two levels/classes (Enum).poisson: (See Poisson Models). The response must be numeric and non-negative (Int).gamma: (See Gamma Models). The response must be numeric and continuous and positive (Real or Int).tweedie: (See Tweedie Models). The response must be numeric and continuous (Real) and non-negative.negativebinomial: (See Negative Binomial Models). The response must be numeric and non-negative (Int).AUTO: Determines the family automatically for the user.
Note: If your response column is binomial, then you must convert that column to a categorical (.asfactor() in Python and as.factor() in R) and set family = binomial. The following configurations can lead to unexpected results.
If you DO convert the response column to categorical and DO NOT to set
family=binomial, then you will receive an error message.If you DO NOT convert response column to categorical and DO NOT set the family, then GLM will assume the 0s and 1s are numbers and will provide a Gaussian solution to a regression problem.
Linear Regression (Gaussian Family)¶
Linear regression corresponds to the Gaussian family model. The link function \(g\) is the identity, and density \(f\) corresponds to a normal distribution. It is the simplest example of a GLM but has many uses and several advantages over other families. Specifically, it is faster and requires more stable computations. Gaussian models the dependency between a response \(y\) and a covariates vector \(x\) as a linear function:
The model is fitted by solving the least squares problem, which is equivalent to maximizing the likelihood for the Gaussian family.
The deviance is the sum of the squared prediction errors:
Logistic Regression (Binomial Family)¶
Logistic regression is used for binary classification problems where the response is a categorical variable with two levels. It models the probability of an observation belonging to an output category given the data (for example, \(Pr(y=1|x)\)). The canonical link for the binomial family is the logit function (also known as log odds). Its inverse is the logistic function, which takes any real number and projects it onto the [0,1] range as desired to model the probability of belonging to a class. The corresponding s-curve is below:
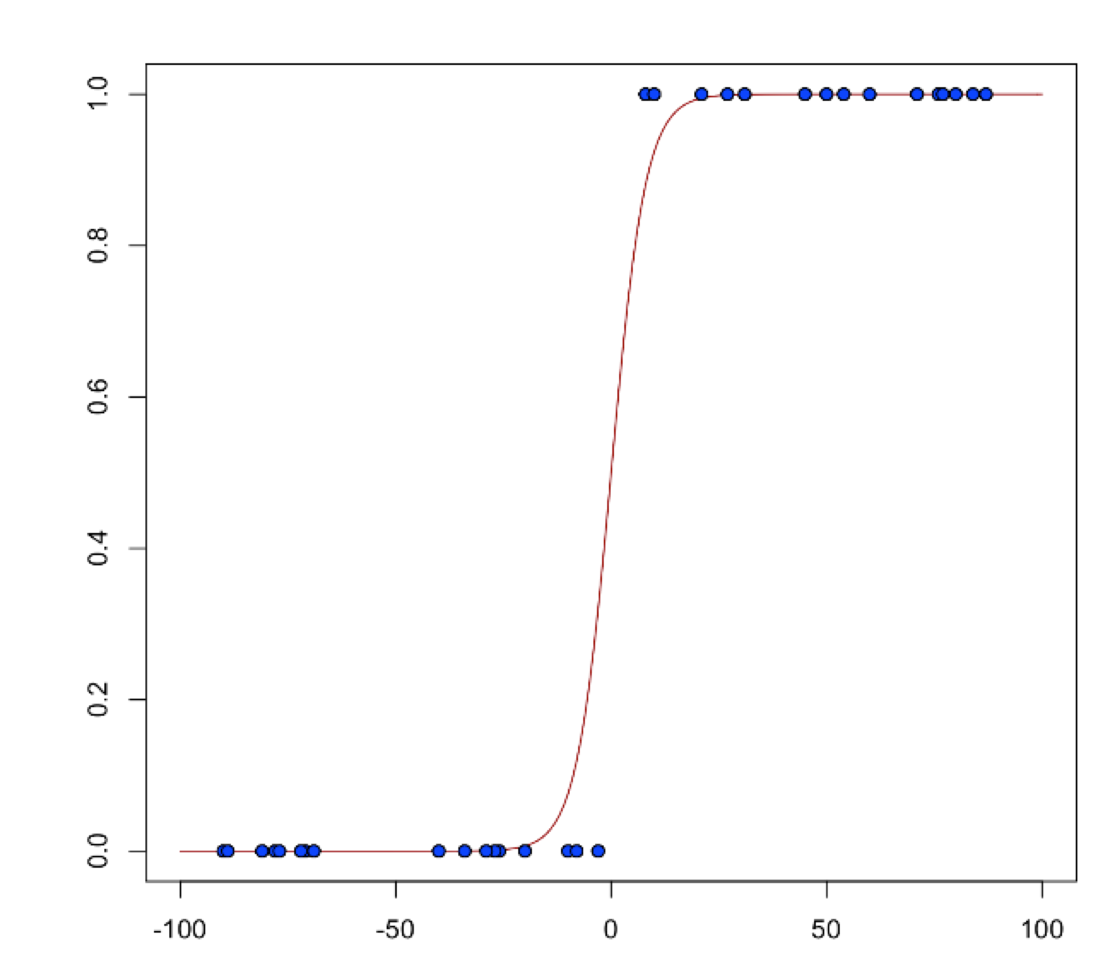
The fitted model has the form:
This can alternatively be written as:
The model is fitted by maximizing the following penalized likelihood:
The corresponding deviance is equal to:
Fractional Logit Model (Fraction Binomial)¶
In the financial service industry, there are many outcomes that are fractional in the range of [0,1]. For example, LGD (Loss Given Default in credit risk) measures the proportion of losses not recovered from a default borrower during the collection process, and this can be observed to be in the closed interval [0, 1]. The following assumptions are made for this model.
\(\text{Pr}(y=1|x) = E(y) = \frac{1}{1 + \text{exp}(-\beta^T x-\beta_0)}\)
The likelihood function = \(\text{Pr}{(y=1|x)}^y (1-\text{Pr}(y=1|x))^{(1-y)}\) for \(1 \geq y \geq 0\)
\(var(y) = \varphi E(y)(1-E(y))\) and \(\varphi\) is estimated as \(\varphi = \frac{1}{n-p} \frac{\sum {(y_i - E(y))}2} {E(y)(1-E(y))}\)
Note that these are exactly the same as the binomial distribution. However, the values are calculated with the value of \(y\) in the range of 0 and 1 instead of just 0 and 1. Therefore, we implemented the fractional binomial family using the code of binomial. Changes are made when needed.
Logistic Ordinal Regression (Ordinal Family)¶
A logistic ordinal regression model is a generalized linear model that predicts ordinal variables - variables that are discreet, as in classification, but that can be ordered, as in regression.
Let \(X_i\in\rm \Bbb I \!\Bbb R^p\), \(y\) can belong to any of the \(K\) classes. In logistic ordinal regression, we model the cumulative distribution function (CDF) of \(y\) belonging to class \(j\), given \(X_i\) as the logistic function:
Compared to multiclass logistic regression, all classes share the same \(\beta\) vector. This adds the constraint that the hyperplanes that separate the different classes are parallel for all classes. To decide which class will \(X_i\) be predicted, we use the thresholds vector \(\theta\). If there are \(K\) different classes, then \(\theta\) is a non-decreasing vector (that is, \(\theta_0 \leq \theta_1 \leq \ldots \theta_{K-2})\) of size \(K-1\). We then assign \(X_i\) to the class \(j\) if \(\beta^{T}X_i + \theta_j > 0\) for the lowest class label \(j\).
We choose a logistic function to model the probability \(P(y \leq j|X_i)\) but other choices are possible.
To determine the values of \(\beta\) and \(\theta\), we maximize the log-likelihood minus the same Regularization Penalty, as with the other families. However, in the actual H2O-3 code, we determine the values of \(\alpha\) and \(\theta\) by minimizing the negative log-likelihood plus the same Regularization Penalty.
Conventional ordinal regression uses a likelihood function to adjust the model parameters. However, during prediction, GLM looks at the log CDF odds.
As a result, there is a small disconnect between the two. To remedy this, we have implemented a new algorithm to set and adjust the model parameters.
Recall that during prediction, a dataset row represented by \(X_i\) will be set to class \(j\) if
and
Hence, for each training data sample \((X_{i}, y_i)\), we adjust the model parameters \(\beta, \theta_0, \theta_1, \ldots, \theta_{K-2}\) by considering the thresholds \(\beta^{T}X_i + \theta_j\) directly. The following loss function is used to adjust the model parameters:
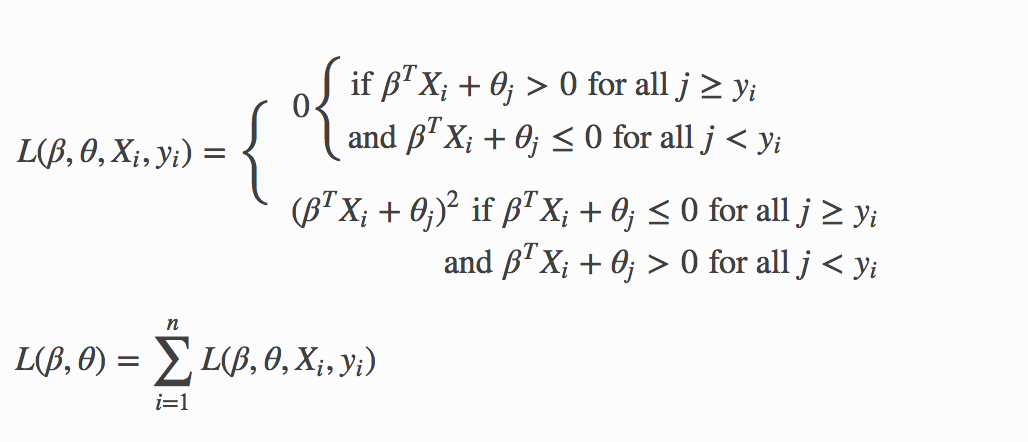
Again, you can add the Regularization Penalty to the loss function. The model parameters are adjusted by minimizing the loss function using gradient descent. When the Ordinal family is specified, the solver parameter will automatically be set to GRADIENT_DESCENT_LH and use the log-likelihood function. To adjust the model parameters using the loss function, you can set the solver parameter to GRADIENT_DESCENT_SQERR.
Because only first-order methods are used in adjusting the model parameters, use Grid Search to choose the best combination of the obj_reg, alpha, and lambda parameters.
In general, the loss function methods tend to generate better accuracies than the likelihood method. In addition, the loss function method is faster as it does not deal with logistic functions - just linear functions when adjusting the model parameters.
Pseudo-Logistic Regression (Quasibinomial Family)¶
The quasibinomial family option works in the same way as the aforementioned binomial family. The difference is that binomial models only support 0/1 for the values of the target. A quasibinomial model supports “pseudo” logistic regression and allows for two arbitrary integer values (for example -4, 7). Additional information about the quasibinomial option can be found in the “Estimating Effects on Rare Outcomes: Knowledge is Power” paper.
Multiclass Classification (Multinomial Family)¶
Multinomial family generalization of the binomial model is used for multi-class response variables. Similar to the binomail family, GLM models the conditional probability of observing class “c” given “x”. A vector of coefficients exists for each of the output classes. (\(\beta\) is a matrix.) The probabilities are defined as:
The penalized negative log-likelihood is defined as:
where \(\beta_c\) is a vector of coefficients for class “c”, and \(y_{i,k}\) is the \(k\text{th}\) element of the binary vector produced by expanding the response variable using one-hot encoding (i.e., \(y_{i,k} == 1\) iff the response at the \(i\text{th}\) observation is “k”; otherwise it is 0.)
Poisson Models¶
Poisson regression is typically used for datasets where the response represents counts, and the errors are assumed to have a Poisson distribution. In general, it can be applied to any data where the response is non-negative. It models the dependency between the response and covariates as:
The model is fitted by maximizing the corresponding penalized likelihood:
The corresponding deviance is equal to:
Note in the equation above that H2O-3 uses the negative log of the likelihood. This is different than the way deviance is specified in https://onlinecourses.science.psu.edu/stat501/node/377/. In order to use this deviance definition, simply multiply the H2O-3 deviance by -1.
Gamma Models¶
The gamma distribution is useful for modeling a positive continuous response variable, where the conditional variance of the response grows with its mean, but the coefficientof variation of the response \(\sigma^2(y_i)/\mu_i\) is constant. It is usually used with the log link \(g(\mu_i) = \text{log}(\mu_i)\) or the inverse link \(g(\mu_i) = \dfrac {1} {\mu_i}\), which is equivalent to the canonical link.
The model is fitted by solving the following likelihood maximization:
The corresponding deviance is equal to:
Tweedie Models¶
Tweedie distributions are a family of distributions that include gamma, normal, Poisson, and their combinations. Tweedie distributions are especially useful for modeling positive continuous variables with exact zeros. The variance of the Tweedie distribution is proportional to the \(p\)-{th} power of the mean \(var(y_i) = \phi\mu{^p_i}\), where \(\phi\) is the dispersion parameter and \(p\) is the variance power.
The Tweedie distribution is parametrized by variance power \(p\) while \(\phi\) is an unknown constant. It is defined for all \(p\) values except in the (0,1) interval and has the following distributions as special cases:
\(p = 0\): Normal
\(p = 1\): Poisson
\(p \in (1,2)\): Compound Poisson, non-negative with mass at zero
\(p = 2\): Gamma
\(p = 3\): Inverse-Gaussian
\(p > 2\): Stable, with support on the positive reals
The model likelood to maximize has the form:
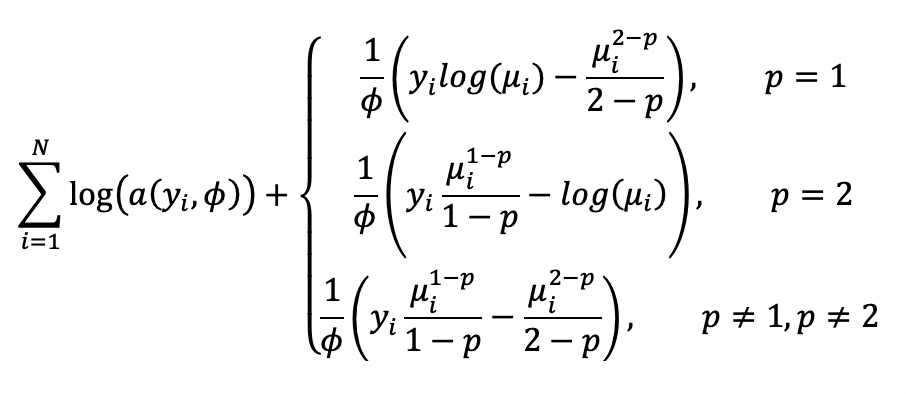
where the function \(a(y_i,\phi)\) is evaluated using an infinite series expansion and does not have an analytical solution. However, because \(\phi\) is an unknown constant, \(\sum_{i=1}^N\text{log}(a(y_i,\phi))\) is a constant and will be ignored. Hence, the final objective function to minimize with the penalty term is:
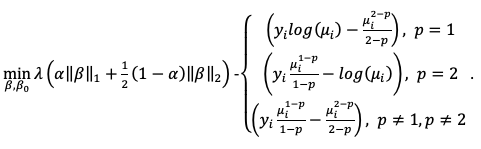
The link function in the GLM representation of the Tweedie distribution defaults to:
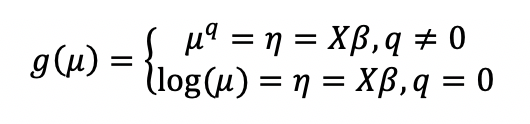
And \(q = 1 - p\). The link power \(q\) can be set to other values as well.
The corresponding deviance is equal to:
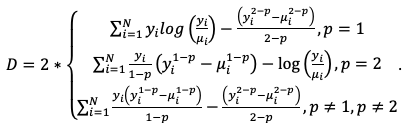
Negative Binomial Models¶
Negative binomial regression is a generalization of Poisson regression that loosens the restrictive assumption that the variance is equal to the mean. Instead, the variance of negative binomial is a function of its mean and parameter \(\theta\), the dispersion parameter.
Let \(Y\) denote a random variable with negative binomial distribution, and let \(\mu\) be the mean. The variance of \(Y (\sigma^2)\) will be \(\sigma^2 = \mu + \theta\mu^2\). The possible values of \(Y\) are non-negative integers like 0, 1, 2, …
The negative binomial regression for an observation \(i\) is:
where \(\Gamma(x)\) is the gamma function, and \(\mu_i\) can be modeled as:
The negative log likelihood \(L(y_i,\mu_i)\) function is:
The final penalized negative log likelihood is used to find the coefficients \(\beta, \beta_0\) given a fixed \(\theta\) value:
The corresponding deviance is:
Note: Future versions of this model will optimize the coefficients as well as the dispersion parameter. Please stay tuned.
Links¶
As indicated previously, a link function \(g\): \(E(y) = \mu = {g^-1}(\eta)\) relates the expected value of the response \(\mu\) to the linear component \(\eta\). The link function can be any monotonic differentiable function. This relaxes the constraints on the additivity of the covariates, and it allows the response to belong to a restricted range of values depending on the chosen transformation \(g\).
H2O’s GLM supports the following link functions: Family_Default, Identity, Logit, Log, Inverse, Tweedie, and Ologit.
The following table describes the allowed Family/Link combinations.
Family |
Link Function |
||||||
Family_Default |
Identity |
Logit |
Log |
Inverse |
Tweedie |
Ologit |
|
Binomial |
X |
X |
|||||
Fractional Binomial |
X |
X |
|||||
Quasibinomial |
X |
X |
|||||
Multinomial |
X |
||||||
Ordinal |
X |
X |
|||||
Gaussian |
X |
X |
X |
X |
|||
Poisson |
X |
X |
X |
||||
Gamma |
X |
X |
X |
X |
|||
Tweedie |
X |
X |
|||||
Negative Binomial |
X |
X |
X |
||||
AUTO |
X*** |
X* |
X** |
X* |
X* |
||
For AUTO:
X*: the data is numeric (
RealorInt) (family determined asgaussian)X**: the data is
Enumwith cardinality = 2 (family determined asbinomial)X***: the data is
Enumwith cardinality > 2 (family determined asmultinomial)
Dispersion Parameter Estimation¶
Regularization is not supported when you use dispersion parameter estimation with maximum likelihood.
Tweedie¶
The density for the maximum likelihood function for Tweedie can be written as:
where:
\(a (y, \phi, p), k(\theta)\) are suitable known functions
\(\phi\) is the dispersion parameter and is positive
\(\theta = \begin{cases} \frac{\mu ^{1-p}}{1-p} & p \neq 1 \\ \log (\mu) & p = 1 \\\end{cases}\)
\(k(\theta) = \begin{cases} \frac{\mu ^{2-p}}{2-p} & p \neq 2 \\ \log (\mu) & p=2 \\\end{cases}\)
the value of \(\alpha (y,\phi)\) depends on the value of \(p\)
If there are weights introduced to each data row, equation 1 will become:
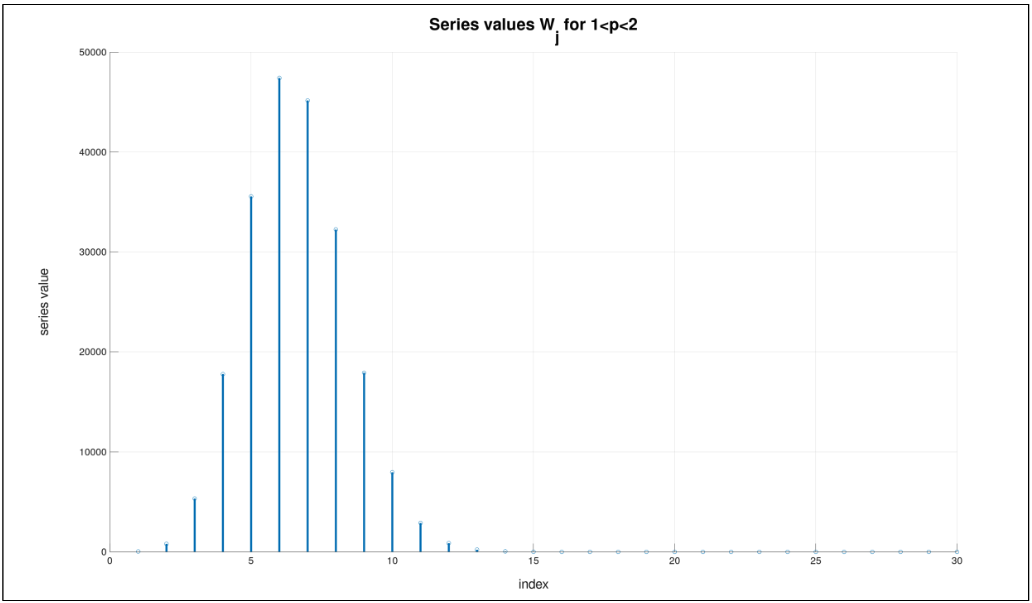
\(\alpha (y,\phi)\) when \(1 < p < 2\)¶
For \(Y=0\),
For \(Y>0\),
with \(W(y, \phi, p) = \sum^{\infty}_{j=1} W_j\) and
If weight is applied to each row, equation 4 becomes:
The \(W_j\) terms are all positive. The following figure plots for \(\mu = 0.5, p=1.5, \phi =1. y=0.1\).
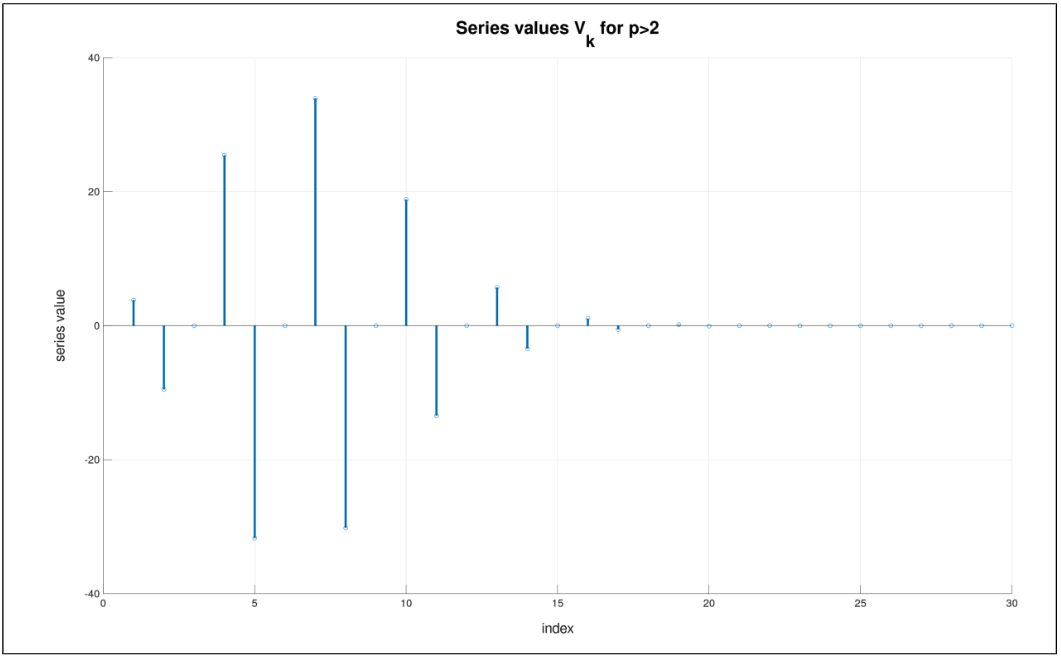
\(\alpha (y,\phi)\) when \(p > 2\)¶
Here, you have
and \(V = \sum^{\infty}_{k=1} V_k\) where
Note that \(0 < \alpha < 1\) for \(p>2\). The \(V_k\) terms are both positive and negative. This will limit the numerical accuracy that is obtained in summing it as shown in the following image. Again, if weights are applied to each row of the dataset, equation 6 becomes:
In the following figure, we use \(\mu =0.5,p=2.5,\phi =1, y=0.1\).
Warnings¶
Accuracy and Limitation
While the Tweedie’s probability density function contains an infinite series sum, when \(p\) is close to 2, the response (\(y\)) is large, and \(\phi\) is small the common number of terms that are needed to approximate the infinite sum grow without bound. This causes an increase in computation time without reaching the desired accuracy.
Multimodal Densities
As \(p\) closes in on 1, the Tweedie density function becomes multimodal. This means that the optimization procedure will fail since it will not be able to find the global optimal point. It will instead arrive at a local optimal point.
As a conservative condition, to ensure that the density is unimodal for most values of \(y,\phi\), we should have \(p>1.2\).
Tweedie Dispersion Example¶
# Import the training data:
training_data <- h2o.importFile("http://h2o-public-test-data.s3.amazonaws.com/smalldata/glm_test/tweedie_p3_phi1_10KRows.csv")
# Set the predictors and response:
predictors <- c('abs.C1.', 'abs.C2.', 'abs.C3.', 'abs.C4.', 'abs.C5.')
response <- 'x'
# Build and train the model:
model <- h2o.glm(x = predictors,
y = response,
training_frame = training_data,
family = 'tweedie',
tweedie_variance_power = 3,
lambda = 0,
compute_p_values = TRUE,
dispersion_parameter_method = "pearson",
init_dispersion_parameter = 0.5,
dispersion_epsilon = 1e-4,
max_iterations_dispersion = 100)
# Retrieve the estimated dispersion:
model@model$dispersion
[1] 0.7599965
# Import the training data:
training_data = h2o.import_file("http://h2o-public-test-data.s3.amazonaws.com/smalldata/glm_test/tweedie_p3_phi1_10KRows.csv")
# Set the predictors and response:
predictors = ["abs.C1.", "abs.C2.", "abs.C3.", "abs.C4.", "abs.C5.""]
response = "x"
# Build and train the model:
model = H2OGeneralizedLinearEstimator(family="tweedie",
lambda_=0,
compute_p_values=True,
dispersion_parameter_method="pearson",
init_dispersion_parameter=0.5,
dispersion_epsilon=1e-4,
tweedie_variance_power=3,
max_iterations_dispersion=100)
model.train(x=predictors, y=response, training_frame=training_data)
# Retrieve the estimated dispersion:
model._model_json["output"]["dispersion"]
0.7599964835351135
Negative Binomial¶
GLM dispersion estimation using the maximum likelihood method for the negative binomial family is available when you set dispersion_parameter_method=“ml”.
The coefficients, or betas, are estimated using IRLSM. The dispersion parameter theta is estimated after each IRLSM iteration. After the first beta update, the initial theta estimate is made using the method of moments as a starting point. Then, theta is updated using the maximum likelihood in each iteration.
While not converged:
Estimate coefficients (betas)
Estimate dispersion (theta)
If it is the first iteration:
Theta \(\gets\) Method of Moments estimate
Otherwise:
Theta \(\gets\) Maximum Likelihood estimate using Newton’s method with learning rate estimated using Golden section search
Regularization¶
Regularization is used to attempt to solve problems with overfitting that can occur in GLM. Penalties can be introduced to the model building process to avoid overfitting, to reduce variance of the prediction error, and to handle correlated predictors. The two most common penalized models are ridge regression and LASSO (least absolute shrinkage and selection operator). The elastic net combines both penalties using both the alpha and lambda options (i.e., values greater than 0 for both).
LASSO and Ridge Regression¶
LASSO represents the \(\ell{_1}\) penalty and is an alternative regularized least squares method that penalizes the sum of the absolute coefficents \(||\beta||{_1} = \sum{^p_{k=1}} \beta{^2_k}\). LASSO leads to a sparse solution when the tuning parameter is sufficiently large. As the tuning parameter value \(\lambda\) is increased, all coefficients are set to zero. Because reducing parameters to zero removes them from the model, LASSO is a good selection tool.
Ridge regression penalizes the \(\ell{_2}\) norm of the model coefficients \(||\beta||{^2_2} = \sum{^p_{k=1}} \beta{^2_k}\). It provides greater numerical stability and is easier and faster to compute than LASSO. It keeps all the predictors in the model and shrinks them proportionally. Ridge regression reduces coefficient values simultaneously as the penalty is increased without setting any of them to zero.
Variable selection is important in numerous modern applications wiht many covariates where the \(\ell{_1}\) penalty has proven to be successful. Therefore, if the number of variables is large or if the solution is known to be sparse, we recommend using LASSO, which will select a small number of variables for sufficiently high \(\lambda\) that could be crucial to the inperpretability of the mode. The \(\ell{_2}\) norm does not have this effect; it shrinks the coefficients but does not set them exactly to zero.
The two penalites also differ in the presence of correlated predictors. The \(\ell{_2}\) penalty shrinks coefficients for correlated columns toward each other, while the \(\ell{_1}\) penalty tends to select only one of them and sets the other coefficients to zero. Using the elastic net argument \(\alpha\) combines these two behaviors.
The elastic net method selects variables and preserves the grouping effect (shrinking coefficients of correlated columns together). Moreover, while the number of predictors that can enter a LASSO model saturates at min \((n,p)\) (where \(n\) is the number of observations, and \(p\) is the number of variables in the model), the elastic net does not have this limitation and can fit models with a larger number of predictors.
Elastic Net Penalty¶
As indicated previously, elastic net regularization is a combination of the \(\ell{_1}\) and \(\ell{_2}\) penalties parametrized by the \(\alpha\) and \(\lambda\) arguments (similar to “Regularization Paths for Genarlized Linear Models via Coordinate Descent” by Friedman et all).
\(\alpha\) controls the elastic net penalty distribution between the \(\ell_1\) and \(\ell_2\) norms. It can have any value in the [0,1] range or a vector of values (via grid search). If \(\alpha=0\), then H2O solves the GLM using ridge regression. If \(\alpha=1\), then LASSO penalty is used.
\(\lambda\) controls the penalty strength. The range is any positive value or a vector of values (via grid search). Note that \(\lambda\) values are capped at \(\lambda_{max}\), which is the smallest \(\lambda\) for which the solution is all zeros (except for the intercept term).
The combination of the \(\ell_1\) and \(\ell_2\) penalties is beneficial because \(\ell_1\) induces sparsity, while \(\ell_2\) gives stability and encourages the grouping effect (where a group of correlated variables tend to be dropped or added into the model simultaneously). When focusing on sparsity, one possible use of the \(\alpha\) argument involves using the \(\ell_1\) mainly with very little \(\ell_2\) (\(\alpha\) almost 1) to stabilize the computation and improve convergence speed.
Regularization Parameters in GLM¶
To get the best possible model, we need to find the optimal values of the regularization parameters \(\alpha\) and \(\lambda\). To find the optimal values, H2O allows you to perform a grid search over \(\alpha\) and a special form of grid search called “lambda search” over \(\lambda\).
The recommended way to find optimal regularization settings on H2O is to do a grid search over a few \(\alpha\) values with an automatic lambda search for each \(\alpha\).
Alpha
The
alphaparameter controls the distribution between the \(\ell{_1}\) (LASSO) and \(\ell{_2}\) (ridge regression) penalties. A value of 1.0 foralpharepresents LASSO, and analphavalue of 0.0 produces ridge reguression.
Lambda
The
lambdaparameter controls the amount of regularization applied. Iflambdais 0.0, no regularization is applied, and thealphaparameter is ignored. The default value forlambdais calculated by H2O using a heuristic based on the training data. If you allow H2O to calculate the value forlambda, you can see the chosen value in the model output.
Lambda Search¶
If the lambda_search option is set, GLM will compute models for full regularization path similar to glmnet. (See the glmnet paper.) Regularization path starts at lambda max (highest lambda values which makes sense - i.e. lowest value driving all coefficients to zero) and goes down to lambda min on log scale, decreasing regularization strength at each step. The returned model will have coefficients corresponding to the “optimal” lambda value as decided during training.
When looking for a sparse solution (alpha > 0), lambda search can also be used to efficiently handle very wide datasets because it can filter out inactive predictors (noise) and only build models for a small subset of predictors. A possible use case for lambda search is to run it on a dataset with many predictors but limit the number of active predictors to a relatively small value.
Lambda search can be configured along with the following arguments:
alpha: Regularization distribution between \(\ell_1\) and \(\ell_2\).validation_frameand/ornfolds: Used to select the best lambda based on the cross-validation performance or the validation or training data. If available, cross-validation performance takes precedence. If no validation data is available, the best lambda is selected based on training data performance and is therefore guaranteed to always be the minimal lambda computed since GLM cannot overfit on a training dataset.
Note: If running lambda search with a validation dataset and cross-validation disabled, the chosen lambda value corresponds to the lambda with the lowest validation error. The validation dataset is used to select the model, and the model performance should be evaluated on another independent test dataset.
lambda_min_ratioandnlambdas: The sequence of the \(\lambda\) values is automatically generated as an exponentially decreasing sequence. It ranges from \(\lambda_{max}\) (the smallest \(\lambda\) so that the solution is a model with all 0s) to \(\lambda_{min} =\)lambda_min_ratio\(\times\) \(\lambda_{max}\).
H2O computes \(\lambda\) models sequentially and in decreasing order, warm-starting the model (using the previous solutin as the initial prediction) for \(\lambda_k\) with the solution for \(\lambda_{k-1}\). By warm-starting the models, we get better performance. Typically models for subsequent \(\lambda\) values are close to each other, so only a few iterations per \(\lambda\) are needed (two or three). This also achieves greater numerical stability because models with a higher penalty are easier to compute. This method starts with an easy problem and then continues to make small adjustments.
Note:
lambda_min_ratioandnlambdasalso specify the relative distance of any two lambdas in the sequence. This is important when applying recursive strong rules, which are only effective if the neighboring lambdas are “close” to each other. The default value forlambda_min_ratiois \(1e^{-4}\), and the default value fornlambdasis 100. This gives a ratio of 0.912. For best results when using strong rules, keep the ratio close to this default.
max_active_predictors: This limits the number of active predictors. (The actual number of non-zero predictors in the model is going to be slightly lower.) It is useful when obtaining a sparse solution to avoid costly computation of models with too many predictors.
Full Regularization Path¶
It can sometimes be useful to see the coefficients for all lambda values or to override default lambda selection. Full regularization path can be extracted from both R and python clients (currently not from Flow). It returns coefficients (and standardized coefficients) for all computed lambda values and also the explained deviances on both train and validation. Subsequently, the makeGLMModel call can be used to create an H2O GLM model with selected coefficients.
To extract the regularization path from R or python:
Solvers¶
This section provides general guidelines for best performance from the GLM implementation details. The optimal solver depends on the data properties and prior information regarding the variables (if available). In general, the data are considered sparse if the ratio of zeros to non-zeros in the input matrix is greater than 10. The solution is sparse when only a subset of the original set of variables is intended to be kept in the model. In a dense solution, all predictors have non-zero coefficients in the final model.
In GLM, you can specify one of the following solvers:
IRLSM: Iteratively Reweighted Least Squares Method (default)
L_BFGS: Limited-memory Broyden-Fletcher-Goldfarb-Shanno algorithm
AUTO: Sets the solver based on given data and parameters.
COORDINATE_DESCENT: Coordinate Decent (not available when
family=multinomial)COORDINATE_DESCENT_NAIVE: Coordinate Decent Naive
GRADIENT_DESCENT_LH: Gradient Descent Likelihood (available for Ordinal family only; default for Ordinal family)
GRADIENT_DESCENT_SQERR: Gradient Descent Squared Error (available for Ordinal family only)
IRLSM and L-BFGS¶
IRLSM (the default) uses a Gram Matrix approach, which is efficient for tall and narrow datasets and when running lambda search via a sparse solution. For wider and dense datasets (thousands of predictors and up), the L-BFGS solver scales better. If there are fewer than 500 predictors (or so) in the data, then use the default solver (IRLSM). For larger numbers of predictors, we recommend running IRLSM with a lambda search, and then comparing it to L-BFGS with just one \(\ell_2\) penalty. For advanced users, we recommend the following general guidelines:
For a dense solution and a dense dataset, use IRLSM if there are fewer than 500 predictors in the data; otherwise, use L-BFGS. Set
alpha=0to include \(\ell_2\) regularization in the elastic net penalty term to avoid inducing sparsity in the model.For a dense solution with a sparse dataset, use IRLSM if there are fewer than 2000 predictors in the data; otherwise, use L-BFGS. Set
alpha=0.For a sparse solution with a dense dataset, use IRLSM with
lambda_search=TRUEif fewer than 500 active predictors in the solution are expected; otherwise, use L-BFGS. Setalphato be greater than 0 to add in an \(\ell_1\) penalty to the elastic net regularization, which induces sparsity in the estimated coefficients.For a sparse solution with a sparse dataset, use IRLSM with
lambda_search=TRUEif you expect less than 5000 active predictors in the solution; otherwise, use L-BFGS. Setalphato be greater than 0.
If you are unsure whether the solution should be sparse or dense, try both along with a grid of alpha values. The optimal model can be picked based on its performance on the validation data (or alternatively, based on the performance in cross-validation when not enough data is available to have a separate validation dataset).
Coordinate Descent¶
In addition to IRLSM and L-BFGS, H2O’s GLM includes options for specifying Coordinate Descent. Cyclical Coordinate Descent is able to handle large datasets well and deals efficiently with sparse features. It can improve the performance when the data contains categorical variables with a large number of levels, as it is implemented to deal with such variables in a parallelized way.
Coordinate Descent is IRLSM with the covariance updates version of cyclical coordinate descent in the innermost loop. This version is faster when \(N > p\) and \(p\) ~ \(500\).
Coordinate Descent Naive is IRLSM with the naive updates version of cyclical coordinate descent in the innermost loop.
Coordinate Descent provides much better results if lambda search is enabled. Also, with bounds, it tends to get higher accuracy.
Coordinate Descent cannot be used with
family=multinomial.
Both of the above method are explained in the glmnet paper.
Gradient Descent¶
For Ordinal regression problems, H2O provides options for Gradient Descent. Gradient Descent is a first-order iterative optimization algorithm for finding the minimum of a function. In H2O’s GLM, conventional ordinal regression uses a likelihood function to adjust the model parameters. The model parameters are adjusted by maximizing the log-likelihood function using gradient descent. When the Ordinal family is specified, the solver parameter will automatically be set to GRADIENT_DESCENT_LH. To adjust the model parameters using the loss function, you can set the solver parameter to GRADIENT_DESCENT_SQERR.
Coefficients Table¶
A Coefficients Table is outputted in a GLM model. This table provides the following information: Column names, Coefficients, Standard Error, z-value, p-value, and Standardized Coefficients.
Coefficients are the predictor weights (i.e. the weights used in the actual model used for prediction) in a GLM model.
Standard error, z-values, and p-values are classical statistical measures of model quality. p-values are essentially hypothesis tests on the values of each coefficient. A high p-value means that a coefficient is unreliable (insiginificant) while a low p-value suggest that the coefficient is statistically significant.
The standardized coefficients are returned if the
standardizeoption is enabled (which is the default). These are the predictor weights of the standardized data and are included only for informational purposes (e.g. to compare relative variable importance). In this case, the “normal” coefficients are obtained from the standardized coefficients by reversing the data standardization process (de-scaled, with the intercept adjusted by an added offset) so that they can be applied to data in its original form (i.e. no standardization prior to scoring). Note: These are not the same as coefficients of a model built on non-standardized data.
Extracting Coefficients Table Information¶
You can extract the columns in the Coefficients Table by specifying names, coefficients, std_error, z_value, p_value, standardized_coefficients in a retrieve/print statement. (Refer to the example that follows.) In addition, H2O provides the following built-in methods for retrieving standard and non-standard coefficients:
coef(): Coefficients that can be applied to non-standardized datacoef_norm(): Coefficients that can be fitted on the standardized data (requiresstandardized=TRUE, which is the default)
For an example, refer here.
GLM Likelihood¶
Maximum Likelihood Estimation¶
For an initial rough estimate of the parameters \(\hat{\beta}\) you use the estimate to generate fitted values: \(\mu_{i}=g^{-1}(\hat{\eta_{i}})\)
Let \(z\) be a working dependent variable such that \(z_{i}=\hat{\eta_{i}}+(y_{i}-\hat{\mu_{i}})\frac{d\eta_{i}}{d\mu_{i}}\),
where \(\frac{d\eta_{i}}{d\mu_{i}}\) is the derivative of the link function evaluated at the trial estimate.
Calculate the iterative weights: \(w_{i}=\frac{p_{i}}{[b^{\prime\prime}(\theta_{i})\frac{d\eta_{i}}{d\mu_{i}}^{2}]}\)
where \(b^{\prime\prime}\) is the second derivative of \(b(\theta_{i})\) evaluated at the trial estimate.
Assume \(a_{i}(\phi)\) is of the form \(\frac{\phi}{p_{i}}\). The weight \(w_{i}\) is inversely proportional to the variance of the working dependent variable \(z_{i}\) for current parameter estimates and proportionality factor \(\phi\).
Regress \(z_{i}\) on the predictors \(x_{i}\) using the weights \(w_{i}\) to obtain new estimates of \(\beta\).
\(\hat{\beta}=(\mathbf{X}^{\prime}\mathbf{W}\mathbf{X})^{-1}\mathbf{X}^{\prime}\mathbf{W}\mathbf{z}\)
where \(\mathbf{X}\) is the model matrix, \(\mathbf{W}\) is a diagonal matrix of \(w_{i}\), and \(\mathbf{z}\) is a vector of the working response variable \(z_{i}\).
This process is repeated until the estimates \(\hat{\beta}\) change by less than the specified amount.
Likelihood and AIC¶
During model training, simplified formulas of likelihood and AIC are used. After the model is built, the full formula is used to calculate the output of the full log likelihood and full AIC values. The full formula is used to calculate the output of the full log likelihood and full AIC values if the parameter calc_like is set to True.
Note
The log likelihood value is not available in the cross-validation metrics. The AIC value is available and is calculated using the original simplified formula independent of the log likelihood.
The following are the supported GLM families and formulae (the log likelihood is calculated for the i th observation).
Gaussian:
where
\(\phi\) is the dispersion parameter estimation
\(\mu_i\) is the prediction
\(y_i\) is the real value of the target variable
Note
For Gaussian family, you need the dispersion parameter estimate in order to calculate the full log likelihood and AIC. Hence, when calc_like is set to True, the parameters compute_p_values and remove_collinear_columns are set to True. The parameter dispersion_parameter_method is set to "pearson" by default. However, you can set the dispersion_parameter_method to deviance if you prefer.
Binomial:
where
\(\mu_i\) is the probability of 1
\(y_i\) is the real value of the target variable
Quasibinomial:
If the predicted value equals \(y_i\), log likelihood is 0
If \(\mu_i >1\) then \(l(\mu_i (\beta); y_i) = y_i \log \{ \mu_i \}\)
Otherwise, \(l(\mu_i (\beta); y_i) = y_i \log \{ \mu_i \} + (1-y_i) \log \{ 1- \mu_i \}\) where
\(\mu_i\) is the probability of 1
\(y_i\) is the real value of the target variable
Fractional Binomial:
where
\(\mu_i\) is the probability of 1
\(y_i\) is the real value of the target variable
Poisson:
where
\(\mu_i\) is the prediction
\(y_i\) is the real value of the target variable
Negative Binomial:
where
\(\mu_i\) is the prediction
\(y_i\) is the real value of the target variable
\(k = \frac{1}{\phi}\) is the dispersion parameter estimation
Note
For Negative Binomial family, you need the dispersion parameter estimate. When the parameter calc_like is set to True, the parameters compute_p_values and remove_collinear_columns are set to True for you. By default, the parameter dispersion_parameter_method is set to "pearson". However, you can set dispersion_parameter_method to "deviance" or "ml" if you prefer.
Gamma:
where
\(\mu_i\) is the prediction
\(y_i\) is the real value of the target variable
\(\phi\) is the dispersion parameter estimation
Note
For Gamma family, you need the dispersion parameter estimate. When the parameter calc_like is set to True, the parameters compute_p_values and remove_collinear_columns are set to True for you. By default, the parameter dispersion_parameter_method is set to "pearson". However, you can set dispersion_parameter_method to "deviance" or "ml" if you prefer.
Multinomial:
where \(\mu_i\) is the predicted probability of the actual class \(y_i\)
Tweedie:
The Tweedie calculation is located in the section Tweedie Likelihood Calculation.
Note
For Tweedie family, you need the dispersion parameter estimate. When the parameter calc_like is set to True, the dispersion_parameter_method is set to "ml" which provides you with the best log likelihood estimation.
Final AIC Calculation¶
The final AIC in the output metric is calculated using the standard formula, utilizing the previously computed log likelihood.
where
\(p\) is the number of estimated coefficients (i.e. including dispersion etc). When using regularization \(p\) is the number of non-zero coefficients.
\(LL\) is the log likelihood
To manage computational intensity, calc_like is used. This parameter was previously only used for HGLM models, but its utilization has been expanded. By default, calc_like=False, but you can set it to True and the parameter HGLM to False to enable the calculation of the full log likelihood and full AIC. This computation is performed during the final scoring phase after the model finishes building.
Note
For ridge regression and elastic net, the AIC is approximated without calculating the actual effective degrees of freedom, i.e., the estimate is the same as for LASSO. Therefore, the AIC values for ridge regression and elastic net should be used with caution.
Tweedie Likelihood Calculation¶
There are three different estimations you calculate Tweedie likelihood for:
when you fix the variance power and estimate the dispersion parameter;
when you fix the dispersion parameter and estimate the variance power; or
when you estimate both the variance power and dispersion parameter.
The calculation in this section is used to estimate the full log likelihood. When you fix the Tweedie variance power, you will use a simpler formula (unless you are estimating dispersion). When fixing the Tweedie variance power for dispersion estimation, you use the Series method.
When you fix the variance power and estimate the dispersion parameter, the Series method is used to perform the estimation. In this case, you can actually separate the GLM coefficient estimation and the dispersion parameter estimation at the end of the GLM model building process. Standard Newton’s method is used to estimate the dispersion parameter using the Series method which is an approximation of the Tweedie likelihood function.
Depending on \(p\), \(y\), and \(\phi\), different methods are used for this log likelihood estimation. To start, let:
If \(p=2\), then it will use the log likelihood of the Gamma distribution:
If \(p=3\), then it will use the inverse Gaussian distribution:
If \(p<2\) and \(\xi \leq 0.01\), then it will use the Fourier inversion method.
If \(p>2\) and \(\xi \geq 1\), then it will also use the Fourier inversion method.
Everything else will use the Series method. However, if the Series method fails (output of NaN), then it will try the Fourier inversion method instead.
If both the Series method and Fourier inversion method fail, or if the Fourier inversion method was chosen based on the \(\xi\) criterium and it failed, it will then estimate the log likelihood using the Saddlepoint approximation.
Here are the general usages for Tweedie variance power and dispersion parameter estimation using maximum likelihood:
fix_tweedie_variance_power = Trueandfix_dispersion_parameter = Falseas it will use the Tweedie variance power set in parametertweedie_variance_powerand estimate the dispersion parameter starting with the value set in parameterinit_dispersion_parameter;fix_tweedie_variance_power = Falseandfix_dispersion_parameter = Trueas it will use the dispersion parameter value in parameterinit_dispersion_parameterand estimate the Tweedie variance power starting with the value set in parametertweedie_variance_power;fix_tweedie_variance_power = Falseandfix_dispersion_parameter = Falseas it will estimate both the variance power and dispersion parameter using the values set intweedie_variance_powerandinit_dispersion_parameterrespectively.
Optimization Procedure
When estimating just the Tweedie variance power, it uses the golden section search. Once a small region is found, then it switches to Newton’s method. If Newton’s method fails (i.e. steps out of the bounds found by the golden section search), it uses the golden section search until convergence. When you optimize both Tweedie variance power and dispersion, it uses the Nelder-Mead method with constraints so that Tweedie variance power \(p>1+10^{-10}\) and dispersion \(\phi >10^{-10}\). If the Nelder-Mead seems to be stuck in local optimum, you might want to try increasing the dispersion_learning_rate.
Note
(Applicable for Gamma, Tweedie, and Negative Binomial families) If you set dispersion_parameter_method="ml", then solver must be set to "IRLSM".
Variable Inflation Factors¶
The variable inflation factor (VIF) quantifies the inflation of the variable. Variables are inflated due to their correlation with other predictor variables within the model. For each predictor in a multiple regression model, there is a VIF. This process can be calculated with cross validation turned on.
The VIF is constructed by:
setting a numerical predictor x as the response while using the remaining predictors except for y,
building a GLM regression model,
calculating the VIF as \(\frac{1.0}{(1.0-R^2)}\) where \(R^2\) is taken from the GLM regression model built in the prior step, and
repeating this process for all remaining numerical predictors to retrieve their VIF.
Variable Inflation Factor Example¶
# Import the training data:
training_data <- h2o.importFile("http://h2o-public-test-data.s3.amazonaws.com/smalldata/glm_test/gamma_dispersion_factor_9_10kRows.csv")
# Set the predictors and response:
predictors <- c('abs.C1.','abs.C2.','abs.C3.','abs.C4.','abs.C5.')
response <- 'resp'
# Build and train the model:
vif_glm <- h2o.glm(x = predictors,
y = response,
training_frame = training_data,
family = 'gamma',
lambda = 0,
generate_variable_inflation_factors = TRUE,
fold_assignment = 'modulo',
nfolds = 3,
keep_cross_validation_models = TRUE)
# Retrieve the variable inflation factors:
h2o.get_variable_inflation_factors(vif_glm)
abs.C1. abs.C2. abs.C3. abs.C4. abs.C5.
1.000334 1.000173 1.000785 1.000539 1.000535
# Import the GLM estimator:
from h2o.estimators import H2OGeneralizedLinearEstimator
# Import the training data:
training_data = h2o.import_file("http://h2o-public-test-data.s3.amazonaws.com/smalldata/glm_test/gamma_dispersion_factor_9_10kRows.csv")
# Set the predictors and response:
predictors = ["abs.C1.","abs.C2.","abs.C3.","abs.C4.","abs.C5.""]
response = "resp"
# Build and train the model:
vif_glm = H2OGeneralizedLinearEstimator(family="gamma",
lambda_=0,
generate_variable_inflation_factors=True,
fold_assignment="modulo",
nfolds=3,
keep_cross_validation_models=True)
vif_glm.train(x=predictors, y=response, training_frame=training_data)
# Retrieve the variable inflation factors:
vif_glm.get_variable_inflation_factors()
{'Intercept': nan, 'abs.C1.': 1.0003341467438167, 'abs.C2.': 1.0001734204183244, 'abs.C3.': 1.0007846189027745, 'abs.C4.': 1.0005388379729434, 'abs.C5.': 1.0005349427184604}
Constrained GLM¶
We’ve implemented the algorithm from Bierlaire’s Optimization: Priciples and Algorithms, Chapter 19 [8] where we’re basically trying to solve the following optimization problem:
where:
\(f: R^n \to R,h: R^n \to R^m,g: R^n \to R^p\)
the constraints \(h,g\) are linear.
However, the actual problem we are solving is:
The inequalities constraints can be easily converted to equalities constraints through simple reasoning and using active constraints. We solve the constrained optimization problem by solving the augmented Lagrangian function using the quadratic penalty:
The basic ideas used to solve the constrained GLM consist of:
transforming a constrained problem into a sequence of unconstrained problems;
penalizing more and more the possible violation of the constraints during the sequence by continuously increasing the value of \(c\) at each iteration.
Converting to standard form¶
A standard form of \(g(x) \leq 0\) is the only acceptable form of inequality constraints. For example, if you have a constraint of \(2x_1 - 4x_2 \geq 10\) where \(x_1 \text{ and } x_4\) are coefficient names, then you must convert it to \(10-2x_1 + 4x_2 \leq 0\).
Example of constrained GLM¶
# Import the Gaussian 10,000 rows dataset:
h2o_data <- h2o.importFile("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/gaussian_20cols_10000Rows.csv")
# Set the predictors, response, and enum columns:
enum_columns = c("C1", "C2", "C3", "C4", "C5", "C6", "C7", "C8", "C9", "C10")
for (cname in enum_columns) {
h2o.asfactor(h2o_data[cname])
}
myY = "C21"
col_names <- names(h2o_data)
myX <- col_names[1:20]
# Set the constraints:
constraints <- data.frame(names <- c("C1.2", "C11", "constant", "C5.2", "C12", "C15", "constant"),
values <- c(1, 1, 13.56, 1, 1, 1, -5),
types <- c("Equal", "Equal", "Equal", "LessThanEqual", "LessThanEqual", "LessThanEqual", "LessThanEqual"),
constraint_numbers <- c(0, 0, 0, 1, 1, 1, 1))
constraints_h2o <- as.h2o(constraints)
# Set the beta constraints:
bc <- data.frame(names <- c("C1.1", "C5.2", "C11", "C15"),
lower_bounds <- c(-36, -14, 25, 14),
upper_bounds <- c(-35, -13, 26, 15))
bc_h2o <- as.h2o(bc)
# Build and train your model:
m_sep <- h2o.glm(x=myX,
y=myY,
training_frame=h2o.data,
family='gaussian',
linear_constraints=constraints,
solver="irlsm",
lambda=0.0,
beta_constraints=bc_h2o,
constraint_eta0=0.1,
constraint_tau=10,
constraint_alpha=0.01,
constraint_beta=0.9,
constraint_c0=100)
# Find your coefficients:
h2o.coef(m_sep)
# Import the Gaussian 10,000 rows dataset:
h2o_data = h2o.import_file("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/gaussian_20cols_10000Rows.csv")
# Set the predictors, response, and enum columns:
enum_columns = ["C1", "C2", "C3", "C4", "C5", "C6", "C7", "C8", "C9", "C10"]
ffor cname in enum_columns:
h2o_data[cname] = h2o_data[cname].asfactor()
myY = "C21"
myX = h2o_data.names.remove(myY)
# Set the linear constraints:
linear_constraints = [] # this constraint is satisfied by default coefficient initialization
name = "C1.2"
values = 1
types = "Equal"
contraint_numbers = 0
linear_constraints.append([name, values, types, contraint_numbers])
name = "C11"
values = 1
types = "Equal"
contraint_numbers = 0
linear_constraints.append([name, values, types, contraint_numbers])
name = "constant"
values = 13.56
types = "Equal"
contraint_numbers = 0
linear_constraints.append([name, values, types, contraint_numbers])
name = "C5.2"
values = 1
types = "LessThanEqual"
contraint_numbers = 1
linear_constraints.append([name, values, types, contraint_numbers])
name = "C12"
values = 1
types = "LessThanEqual"
contraint_numbers = 1
linear_constraints.append([name, values, types, contraint_numbers])
name = "C15"
values = 1
types = "LessThanEqual"
contraint_numbers = 1
linear_constraints.append([name, values, types, contraint_numbers])
name = "constant"
values = -5
types = "LessThanEqual"
contraint_numbers = 1
linear_constraints.append([name, values, types, contraint_numbers])
linear_constraints2 = h2o.H2OFrame(linear_constraints)
linear_constraints2.set_names(["names", "values", "types", "constraint_numbers"])
# Set the beta constraints:
bc = []
name = "C1.1"
c1p1LowerBound = -36
c1p1UpperBound=-35
bc.append([name, c1p1LowerBound, c1p1UpperBound])
name = "C5.2"
c5p2LowerBound=-14
c5p2UpperBound=-13
bc.append([name, c5p2LowerBound, c5p2UpperBound])
name = "C11"
c11LowerBound=25
c11UpperBound=26
bc.append([name, c11LowerBound, c11UpperBound])
name = "C15"
c15LowerBound=14
c15UpperBound=15
bc.append([name, c15LowerBound, c15UpperBound])
beta_constraints = h2o.H2OFrame(bc)
beta_constraints.set_names(["names", "lower_bounds", "upper_bounds"])
# Build and train your model:
m_sep = glm(family='gaussian',
linear_constraints=linear_constraints2,
solver="irlsm",
lambda_=0.0,
beta_constraints=beta_constraints,
constraint_eta0=0.1,
constraint_tau=10,
constraint_alpha=0.01,
constraint_beta=0.9,
constraint_c0=100)
m_sep.train(training_frame=h2o_data,x=myX, y=myY)
# Find your coefficients:
coef_sep = m_sep.coef()
Treatment of strict inequalities¶
To convert a strict inequality, just add a small number to it. For example, \(2x_1 - 4x_2 < 0\) can be converted to \(2x_1 - 4x_2 - 10^{-12} \leq 0\).
Transforming inequality constraints to equality constraints¶
This transformation is going to use slack variables which are introduced to replace an inequality constraint by an equality constraint. The slack variable should be non-negative. To transform inequality constraints to equality constraints, we proceed as follows:
For each inequality constraint of \(g(x)\), a slack variable is added to it such that you will have: \(g_i(x) - s_i^2 = 0\);
Let \(s = \begin{bmatrix} s_1^2 \\ \vdots \\ s_p^2 \\\end{bmatrix}\) and \(g_{aug}(x) = g(x) - s\);
When \(g_i(x) \leq 0\), the constraint is satisfied and can therefore be ignored and declared inactive;
The inequality constraints are violated only when \(g_i(x) - s_i^2 \geq 0\). This is because it implies that \(g_i(x) \geq s_i^2 \geq 0\) and this isn’t allowed. Therefore, \(geq(x)\) only includes the \(g_i(x)\) when you have \(g_i(x) \geq 0\);
Therefore, you have \(h_a(x) = \begin{bmatrix} h(x) \\ geq(x) \\\end{bmatrix}\), where \(h(x)\) is the original equality constraint and \(geq(x)\) contains the inequality constraints that satisfied the condition \(g_i(x) \geq 0\);
The optimization problem in equation 1 can now be rewritten as:
The augmented Lagrangian function you will solve from equation 4 becomes:
Modifying or Creating a Custom GLM Model¶
In R and Python, the makeGLMModel call can be used to create an H2O model from given coefficients. It needs a source GLM model trained on the same dataset to extract the dataset information. To make a custom GLM model from R or Python:
R: call
h2o.makeGLMModel. This takes a model, a vector of coefficients, and (optional) decision threshold as parameters.Python:
H2OGeneralizedLinearEstimator.makeGLMModel(static method) takes a model, a dictionary containing coefficients, and (optional) decision threshold as parameters.
Examples¶
Below is a simple example showing how to build a Generalized Linear model.
library(h2o)
h2o.init()
df <- h2o.importFile("https://h2o-public-test-data.s3.amazonaws.com/smalldata/prostate/prostate.csv")
df$CAPSULE <- as.factor(df$CAPSULE)
df$RACE <- as.factor(df$RACE)
df$DCAPS <- as.factor(df$DCAPS)
df$DPROS <- as.factor(df$DPROS)
predictors <- c("AGE", "RACE", "VOL", "GLEASON")
response <- "CAPSULE"
prostate_glm <- h2o.glm(family = "binomial",
x = predictors,
y = response,
training_frame = df,
lambda = 0,
compute_p_values = TRUE
generate_scoring_history = TRUE)
# Coefficients that can be applied to the non-standardized data
h2o.coef(prostate_glm)
Intercept RACE.1 RACE.2 AGE VOL GLEASON
-6.67515539 -0.44278752 -0.58992326 -0.01788870 -0.01278335 1.25035939
# Coefficients fitted on the standardized data (requires standardize=TRUE, which is on by default)
h2o.coef_norm(prostate_glm)
Intercept RACE.1 RACE.2 AGE VOL GLEASON
-0.07610006 -0.44278752 -0.58992326 -0.11676080 -0.23454402 1.36533415
# Print the coefficients table
prostate_glm@model$coefficients_table
Coefficients: glm coefficients
names coefficients std_error z_value p_value standardized_coefficients
1 Intercept -6.675155 1.931760 -3.455478 0.000549 -0.076100
2 RACE.1 -0.442788 1.324231 -0.334373 0.738098 -0.442788
3 RACE.2 -0.589923 1.373466 -0.429514 0.667549 -0.589923
4 AGE -0.017889 0.018702 -0.956516 0.338812 -0.116761
5 VOL -0.012783 0.007514 -1.701191 0.088907 -0.234544
6 GLEASON 1.250359 0.156156 8.007103 0.000000 1.365334
# Print the standard error
prostate_glm@model$coefficients_table$std_error
[1] 1.931760363 1.324230832 1.373465793 0.018701933 0.007514354 0.156156271
# Print the p values
prostate_glm@model$coefficients_table$p_value
[1] 5.493181e-04 7.380978e-01 6.675490e-01 3.388116e-01 8.890718e-02
[6] 1.221245e-15
# Print the z values
prostate_glm@model$coefficients_table$z_value
[1] -3.4554780 -0.3343734 -0.4295143 -0.9565159 -1.7011907 8.0071033
# Retrieve a graphical plot of the standardized coefficient magnitudes
h2o.std_coef_plot(prostate_glm)
# Since you generated the scoring history, you can retrieve the average objective and the negative log likelihood:
print(h2o.average_objective(prostate_glm))
[1] 0.540688
print(h2o.negative_log_likelihood(prostate_glm))
[1] 205.4614
import h2o
h2o.init()
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
prostate = h2o.import_file("https://h2o-public-test-data.s3.amazonaws.com/smalldata/prostate/prostate.csv")
prostate['CAPSULE'] = prostate['CAPSULE'].asfactor()
prostate['RACE'] = prostate['RACE'].asfactor()
prostate['DCAPS'] = prostate['DCAPS'].asfactor()
prostate['DPROS'] = prostate['DPROS'].asfactor()
predictors = ["AGE", "RACE", "VOL", "GLEASON"]
response_col = "CAPSULE"
prostate_glm = H2OGeneralizedLinearEstimator(family= "binomial",
lambda_ = 0,
compute_p_values = True,
generate_scoring_history = True)
prostate_glm.train(predictors, response_col, training_frame= prostate)
# Coefficients that can be applied to the non-standardized data.
print(prostate_glm.coef())
{u'GLEASON': 1.2503593867263176, u'VOL': -0.012783348665664449, u'AGE': -0.017888697161812357, u'Intercept': -6.6751553940827195, u'RACE.2': -0.5899232636956354, u'RACE.1': -0.44278751680880707}
# Coefficients fitted on the standardized data (requires standardize = True, which is on by default)
print(prostate_glm.coef_norm())
{u'GLEASON': 1.365334151581163, u'VOL': -0.2345440232267344, u'AGE': -0.11676080128780757, u'Intercept': -0.07610006436753876, u'RACE.2': -0.5899232636956354, u'RACE.1': -0.44278751680880707}
# Print the Coefficients table
prostate_glm._model_json['output']['coefficients_table']
Coefficients: glm coefficients
names coefficients std_error z_value p_value standardized_coefficients
--------- -------------- ----------- --------- ----------- ---------------------------
Intercept -6.67516 1.93176 -3.45548 0.000549318 -0.0761001
RACE.1 -0.442788 1.32423 -0.334373 0.738098 -0.442788
RACE.2 -0.589923 1.37347 -0.429514 0.667549 -0.589923
AGE -0.0178887 0.0187019 -0.956516 0.338812 -0.116761
VOL -0.0127833 0.00751435 -1.70119 0.0889072 -0.234544
GLEASON 1.25036 0.156156 8.0071 1.22125e-15 1.36533
# Print the Standard error
print(prostate_glm._model_json['output']['coefficients_table']['std_error'])
[1.9317603626604352, 1.3242308316851008, 1.3734657932878116, 0.01870193337051072, 0.007514353657915356, 0.15615627100850296]
# Print the p values
print(prostate_glm._model_json['output']['coefficients_table']['p_value'])
[0.0005493180609459358, 0.73809783692024, 0.6675489550762566, 0.33881164088847204, 0.0889071809658667, 1.2212453270876722e-15]
# Print the z values
print(prostate_glm._model_json['output']['coefficients_table']['z_value'])
[-3.4554779791058787, -0.3343733631736653, -0.42951434726559384, -0.9565159284557886, -1.7011907141473064, 8.007103260414265]
# Retrieve a graphical plot of the standardized coefficient magnitudes
prostate_glm.std_coef_plot()
# Since you generated the scoring history, you can access the average objective and negative log likelihood:
print("average objective: {0}.".format(prostate_glm.average_objective()))
average objective: 0.5406879877388551.
print("negative log likelihood: {0}.".format(prostate_glm.negative_log_likelihood()))
negative log likelihood: 205.46143534076492.
Calling Model Attributes¶
While not all model attributes have their own callable APIs, you can still retrieve their information. Using the previous example, here is how to call a model’s attributes:
# Retrieve all model attributes:
prostate_glm@model$model_summary
GLM Model: summary
family link regularization number_of_predictors_total
1 binomial logit None 5
number_of_active_predictors number_of_iterations training_frame
1 5 4 RTMP_sid_8b2d_6
# Retrieve a specific model attribute (for example, the number of active predictors):
prostate_glm@model$model_summary['number_of_active_predictors']
number_of_active_predictors
1 5
# Retrieve all model attributes:
prostate_glm._model_json["output"]['model_summary']
GLM Model: summary
family link regularization number_of_predictors_total number_of_active_predictors number_of_iterations training_frame
-- -------- ------ ---------------- ---------------------------- ----------------------------- ---------------------- ----------------
binomial logit None 5 5 4 py_4_sid_9981
# Retrieve a specific model attribute (for example, the number of active predictors):
prostate_glm._model_json["output"]['model_summary']['number_of_active_predictors']
['5']
FAQ¶
How does the algorithm handle missing values during training?
Depending on the selected missing value handling policy, they are either imputed mean or the whole row is skipped. The default behavior is Mean Imputation. Note that unseen categorical levels are replaced by the most frequent level present in training (mod). Optionally, GLM can skip all rows with any missing values.
How does the algorithm handle missing values during testing?
Same as during training. If the missing value handling is set to Skip and we are generating predictions, skipped rows will have Na (missing) prediction.
What happens if the response has missing values?
The rows with missing responses are ignored during model training and validation.
What happens during prediction if the new sample has categorical levels not seen in training?
The value will be filled with either 0 or replaced by the most frequent level present in training (if
missing_value_handlingwas set to MeanImputation).
How are unseen categorical values treated during scoring?
Unseen categorical levels are treated based on the missing values handling during training. If your missing value handling was set to Mean Imputation, the unseen levels are replaced by the most frequent level present in training (mod). If your missing value treatment was Skip, the variable is ignored for the given observation.
Does it matter if the data is sorted?
No.
Should data be shuffled before training?
No.
How does the algorithm handle highly imbalanced data in a response column?
GLM does not require special handling for imbalanced data.
What if there are a large number of columns?
IRLS will get quadratically slower with the number of columns. Try L-BFGS for datasets with more than 5-10 thousand columns.
What if there are a large number of categorical factor levels?
GLM internally one-hot encodes the categorical factor levels; the same limitations as with a high column count will apply.
When building the model, does GLM use all features or a selection of the best features?
Typically, GLM picks the best predictors, especially if lasso is used (
alpha = 1). By default, the GLM model includes an L1 penalty and will pick only the most predictive predictors.
When running GLM, is it better to create a cluster that uses many smaller nodes or fewer larger nodes?
A rough heuristic would be:
\(nodes ~=M *N^2/(p * 1e8)\)
where \(M\) is the number of observations, \(N\) is the number of columns (categorical columns count as a single column in this case), and \(p\) is the number of CPU cores per node.
For example, a dataset with 250 columns and 1M rows would optimally use about 20 nodes with 32 cores each (following the formula \(250^2 *1000000/(32* 1e8) = 19.5 ~= 20)\).
How is variable importance calculated for GLM?
For GLM, the variable importance represents the coefficient magnitudes.
How does GLM define and check for convergence during logistic regression?
GLM includes three convergence criteria outside of max iterations:
beta_epsilon: beta stops changing. This is used mostly with IRLSM.
gradient_epsilon: gradient is too small. This is used mostly with L-BFGS.
objective_epsilon: relative objective improvement is too small. This is used by all solvers.The default values below are based on a heuristic:
The default for
beta_epsilonis 1e-4.The default for
gradient_epsilonis 1e-6 if there is no regularization (lambda = 0) or you are running withlambda_search; 1e-4 otherwise.The default for
objective_epsilonis 1e-6 iflambda = 0; 1e-4 otherwise.The default for
max_iterationsdepends on the solver type and whether you run with lambda search:
for IRLSM, the default is 50 if no lambda search; 10* number of lambdas otherwise
for LBFGS, the default is number of classes (1 if not classification) * max(20, number of predictors /4 ) if no lambda search; it is number of classes * 100 * n-lambdas with lambda search.
You will receive a warning if you reach the maximum number of iterations. In some cases, GLM can end prematurely if it can not progress forward via line search. This typically happens when running a lambda search with IRLSM solver. Note that using CoordinateDescent solver fixes the issue.
Why do I receive different results when I run R’s glm and H2O’s glm?
H2O’s glm and R’s glm do not run the same way and, thus, will provide different results. This is mainly due to the fact that H2O’s glm uses H2O math, H2O objects, and H2O distributed computing. Additionally, H2O’s glm by default adds regularization, so it is essentially solving a different problem.
How can I get H2O’s GLM to match R’s `glm()` function?
There are a few arguments you need to set in order to get H2O’s GLM to match R’s GLM because by default, they do not function the same way. To match R’s GLM, you must set the following in H2O’s GLM:
solver = "IRLSM" lambda = 0 remove_collinear_columns = TRUE compute_p_values = TRUENote:
beta_constraintsmust not be set.
GLM Algorithm¶
Following the definitive text by P. McCullagh and J.A. Nelder (1989) on the generalization of linear models to non-linear distributions of the response variable Y, H2O fits GLM models based on the maximum likelihood estimation via iteratively reweighed least squares.
Let \(y_{1},…,y_{n}\) be n observations of the independent, random response variable \(Y_{i}\).
Assume that the observations are distributed according to a function from the exponential family and have a probability density function of the form:
\(f(y_{i})=exp[\frac{y_{i}\theta_{i} - b(\theta_{i})}{a_{i}(\phi)} + c(y_{i}; \phi)]\) where \(\theta\) and \(\phi\) are location and scale parameters, and \(a_{i}(\phi)\), \(b_{i}(\theta{i})\), and \(c_{i}(y_{i}; \phi)\) are known functions.
\(a_{i}\) is of the form \(a_{i}= \frac{\phi}{p_{i}}\) where \(p_{i}\) is a known prior weight.
When \(Y\) has a pdf from the exponential family:
\(E(Y_{i})=\mu_{i}=b^{\prime} var(Y_{i})=\sigma_{i}^2=b^{\prime\prime}(\theta_{i})a_{i}(\phi)\)
Let \(g(\mu_{i})=\eta_{i}\) be a monotonic, differentiable transformation of the expected value of \(y_{i}\). The function \(\eta_{i}\) is the link function and follows a linear model.
\(g(\mu_{i})=\eta_{i}=\mathbf{x_{i}^{\prime}}\beta\)
When inverted: \(\mu=g^{-1}(\mathbf{x_{i}^{\prime}}\beta)\)
Cost of computation¶
H2O can process large data sets because it relies on parallel processes. Large data sets are divided into smaller data sets and processed simultaneously and the results are communicated between computers as needed throughout the process.
In GLM, data are split by rows but not by columns, because the predicted Y values depend on information in each of the predictor variable vectors. If O is a complexity function, N is the number of observations (or rows), and P is the number of predictors (or columns) then
\(Runtime \propto p^3+\frac{(N*p^2)}{CPUs}\)
Distribution reduces the time it takes an algorithm to process because it decreases N.
Relative to P, the larger that (N/CPUs) becomes, the more trivial p becomes to the overall computational cost. However, when p is greater than (N/CPUs), O is dominated by p.
\(Complexity = O(p^3 + N*p^2)\)
References¶
Breslow, N E. “Generalized Linear Models: Checking Assumptions and Strengthening Conclusions.” Statistica Applicata 8 (1996): 23-41.
Peter K. Dunn, Gordon K. Symth, “Series evaluation of Tweedie exponential dispersion model densities”, Statistics and Computing, Volume 15 (2005), pages 267-280.
Frome, E L. “The Analysis of Rates Using Poisson Regression Models.” Biometrics (1983): 665-674.
Lee, Y and Nelder, J. A. Hierarchical generalized linear models with discussion. J. R. Statist.Soc. B, 58:619-678, 1996.
Lee, Y and Nelder, J. A. and Y. Pawitan. Generalized linear models with random effects. Chapman & Hall/CRC, 2006.
Snee, Ronald D. “Validation of Regression Models: Methods and Examples.” Technometrics 19.4 (1977): 415-428.
Michel Bierlaire, Optimization: Principles and Algorithms, Chapter 19, EPEL Press, second edition, 2018