GAM Thin Plate Regression Spline¶
Introduction¶
While we have already implemented GAM using smoothers with only one predictor, thin plate regression splines are used to implement smoothers with one or more predictors. We follow the implementation in [1] closely here. For more theoretical treatments on the subject, please refer to [1] and [2].
The following information is on regression. However, the translation to other families is straight-forward. For regression, we aim to approximate the response \(Y_i\) with \(f(x_i)\). For the binomial family, we aim to approximate the log-odds \(p(x_i)\) with \(f(x_i)\).
A Simple Linear GAM Model Built Using Smoothers from Multiple Predictors¶
Thin plate splines are used to estimate smooth functions of multiple predictor variables from noisy observations of the function at particular values of those predictors. Consider:
\[Y_i = g(x_i) + \epsilon_i\]
where:
\(x_i\epsilon R^d\),
\(d\) is the number of predictors in the smooth function \(g\).
Thin plate spline smoothing estimates \(g\) by finding function \(f\) by minimizing:
\[{\parallel{y-f}\parallel}^2 + \lambda J_{md}(f) {\text{ }}{\text{ Equation 1}}\]
where:
\(y = [y_1,y_2,...,y_n]^T\),
\(f = [f(x_1),f(x_2),...,f(x_n)]^T\),
\(J_{md}(f)\) is a penalty measure of wiggliness of \(f\),
\(\lambda\) is the smoothing parameter (scale parameter) controlling the tradeoff between data fitting and smoothness of \(f\),
\(J_{md}(f) = {\int_{R^d}{\sum_{\gamma_1+\gamma_2+...+\gamma_d=m}{\frac{m!}{\gamma_1! \gamma_2!...\gamma_d!}{({\frac{d^mf}{dx_1dx_2...dx_d}})}^2}}}dx_1 dx_2...dx_d\),
\(m = floor(\frac{d+1}{2})+1\).
The function \(f\) that minimizes Equation 1 has the following form:
\[{\hat{f}}(x) = {\sum_{i=1}^n}\delta_i \eta_{md}({\parallel{x-x_i}\parallel}) + {\sum_{j=1}^M}\alpha_j \phi_j (x) {\text{ }}{\text{ Equation 2}}\]
which is subject to the constraint \(T^T\delta = 0\) where each element of \(T\) is \(T_{ij} = \phi_j (x_i)\) and where:
\(M = {\frac{(m+d-1)!}{d!(m-1)!}}\);
\(\phi_j\) are the polynomial basis functions with order = 0,1,…,m-1;
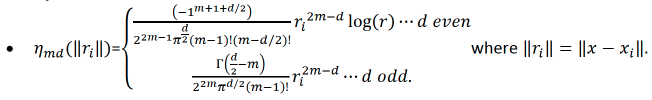
\(\Gamma ({\frac{1}{2}}-n) = {\frac{(-4)^nn!}{(2n)!}}{\sqrt \pi}\).
However, Equation 2 cannot be implemented due to the fact that all the rows of the dataset are used in generating the function \({\hat{f}}(x)\).
Knot-based Approximation of \({\hat{f}}(x)\)¶
Instead of using all the data points in the training set, only a subset of knots are used in the approximation of \({\hat{f}}(x)\) as follows:
\[{\hat{f}}(x) = {\sum_{i=1}^k}\delta_i \eta_{md}({\parallel{x-x_i}\parallel})+{\sum_{j=1}^M}\alpha_j \phi_j (x) {\text{ }}{\text{ Equation 3}}\]
where \(k\) is the number of knots. The coefficients \(\delta = (\delta_1,\delta_2,...,\delta_k)^T\), \(\alpha = (\alpha_1, \alpha_2,..., \alpha_M)^T\) can be obtained by minimizing the following objective function:
\[{\parallel{Y-X\beta}\parallel}^2 + \lambda \beta^T S\beta {\text{ Subject to }} C\beta = 0\]
where:
\(\beta^T = (\delta^T , \alpha^2)\);
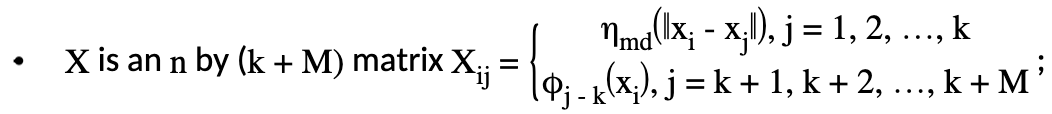
\(S\) is a \((k+M)\) by \((k+M)\) matrix with zeros everywhere except in its upper left \(k\) by \(k\) blocks where \(S_{ij} = \eta_{md} ({\parallel{x_i^*-x_j^*}\parallel})\) and \(x_i^*,x_j^*\) are knots.
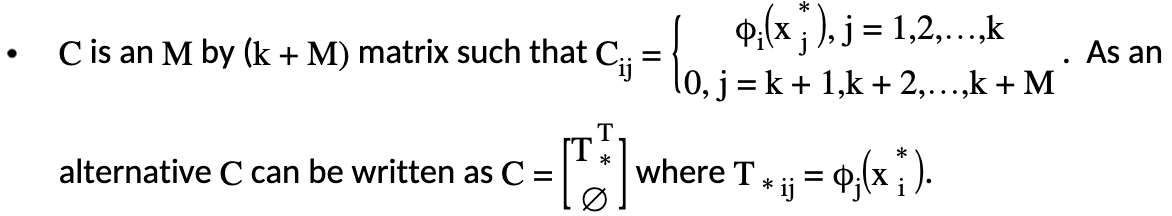
Generation of \(X_{n_{md}}\)¶
The data matrix \(X\) consists of two parts: \(X = [X_{n_{md}}:T]\). First, we will generate \(X_{n_{md}}\), which consists of the distance measure part. \(X_{n_{md}}\) is \(n\) by \(k\) in dimension, and the \(ij^{th}\) element is calculated as:
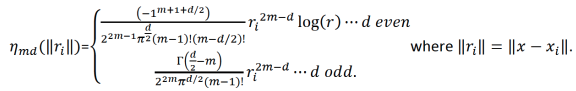
Generation of Penalty Matrix \(S\)
Note that the penalty matrix \(S=X_{n_{md}}^*\). It is the distance measure calculated using only the knot points.
Generation of the Polynomial Basis¶
Let \(d\) be the number of predictors included in the thin plate regression smoother, and let \(m-1\) be the highest degree of the polynomial basis function used. We can calculate \(m\) from \(d\) by using the formula \(m=floor(\frac{d+1}{2})+1\). The total number of polynomial basis function \(M\) is determined by the formula \(M={{d+m-1} \choose {d}} = {\frac{(d+m-1)}{d!(m-1)!}}\). We will illustrate how this is done with two examples:
Polynomial Basis for \(d=2\)
In this case, \(m=floor({\frac{2+1}{2}})+1=2\) and \(M={{2+2-1} \choose {2}} = 3\). The size of the polynomial basis is 3, and the polynomial basis consists of polynomials of degrees 0 and 1. When the two predictors are set as \(x_1,x_2\), the polynomial basis will consist of \(1,x_1,x_2\). \(T\) consists of one column of ones, predictor \(x_1\), and predictor \(x_2\). The size of \(T\) is \(n\) by \(3\).
Polynomial Basis for \(d=4\)
In this case, \(m=floor({\frac{4+1}{2}})+1=3\) and \(M={{4+3-1} \choose {4}}=15\). The size of the polynomial basis is 15, and the polynomial basis consists of polynomials of degrees 0, 1, and 2. The four predictors are \(x_1,x_2,x_3,x_4\). \(T\) consists of:
one zero degree polynomial: one column of ones;
four degree one polynomials: \(x_1,x_2,x_3,x_4\);
ten degree 2 polynomials: \(x_1^2, x_2^2, x_3^2, x_4^2, x_1x_2, {x_1}{x_3}, {x_1}{x_4}, {x_2}{x_3}, {x_2}{x_4}, {x_3}{x_4}\).
The size of \(T\) is \(n\) by \(15\). The size of the polynomial basis grows rapidly as the number of predictors increase in the thin plate regression smoother.
Generation of \(T\)
Remember that \(T\) is defined as \(T_{ij} = \phi_j (x_i)\). Therefore, \(T\) is of size \(n\) by \(M\). However, \(T_*\) is only evaluated at the knots chosen by the user. Hence, by using the example of \(d=2\) and letting the two predictors be \(x_1,x_2\), \(T\) contains:
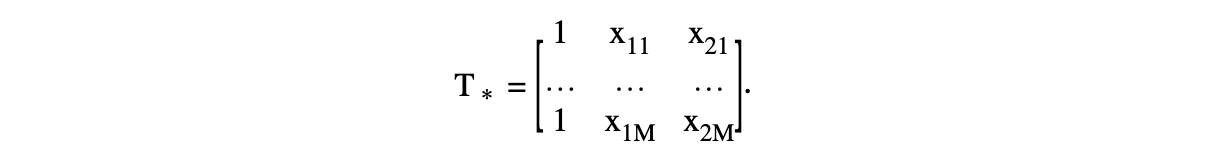
Absolving the Constraint via Matrix Transformation¶
The constraint \(C\beta =0\) is equivalent to \(T_*^T\delta =0\) and is \(M\) by \(k\). The following transformations are applied:
Generate the QR decomposition of \(C^T\) (which is equivalent to the QR decomposition of \(T_*\)). Therefore, rewrite \(T_* =UP\) where \(U\) is \(k\) by \(M\), and \(P\) is \(M\) by \(M\);
Next, generate an orthogonal basis \(Z_{cs}\) which is \(k\) by \((k-M)\), and \(Z_{cs}\) is orthogonal to \(U\). This will force the condition that \(k>M+1\) in setting the number of knots.
\(Z_{cs}\) is easily generated by first generating the \((k-M)\) random vector. Next, use Gram-Schmidt to make the random vectors orthogonal to \(U\) and to each other.
Set \(\delta =Z_{cs}\delta_{cs}\) and rewrite \(\beta^T =((Z_{cs}\delta_{cs})^T,\alpha^T)\).
Let’s also:
decompose \(X\) into two parts as \(X=[X_{n_{md}}:T]\) where \(X_{n_{md}}\) is \(n\) by \(k\) and \(T\) is \(n\) by \(M\);
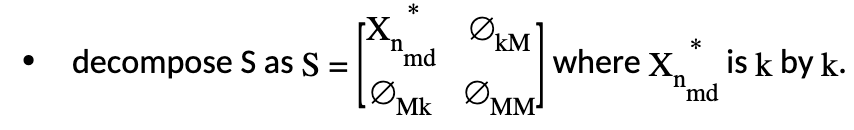
Let’s rewrite the new objective with this decomposition:
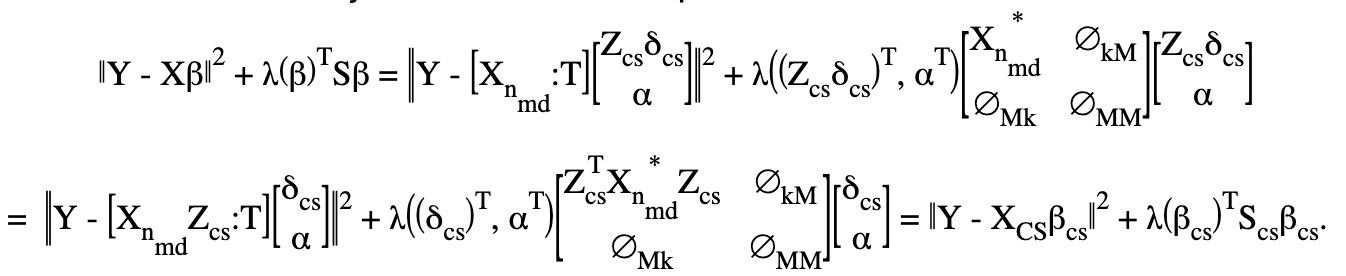
Note that \(Z_{cs}^TX_{n_{md}}^*Z_{cs}\) is \((k-M)\) by \((k-M)\).
Sum-to-zero Constraints Implementation¶
This will follow the Identifiability Constraints rules for GAM. Let \(X\) be the model matrix that contains the basis functions of one predictor variable; the sum-to-zero constraints require that \(1^Tf_p=0=1^TX\beta\) where \(\beta\) contains the coefficients relating to the basis functions of that particular predictor column. The idea is to create a \(k\) by \((k-1)\) matrix \(Z\) such that \(\beta =Z\beta_z\), then \(1^TX\beta =0\) for any \(\beta_z\). \(Z\) is generated by using the Householder transform. Please refer to [3] for details. Therefore, we have \(\beta_{CS}=Z\beta_Z\). Rewrite the objective function again and we will have
\[{\parallel{Y-X_{CS}\beta_{CS}}\parallel}^2+\lambda(\beta_{CS})^TS\beta_{CS} = {\parallel{Y-X_{CS}Z\beta_z}\parallel}^2+\]\[\lambda(\beta_Z)^TZ^TS_{CS}Z\beta_Z = {\parallel{Y-X_Z\beta_z}\parallel}^2+\lambda (\beta_Z)^TS_Z\beta_Z\]
and we will be solving for \(\beta_Z\). Then, we will obtain \(\beta_{CS}=Z\beta_z\). Last, we will obtain the original \(\beta\) by multiplying the part of the coefficeints not corresponding to the polynomial basis with \(Z_{CS}\) like \(\beta^T =((Z_{CS}\delta_{CS})^T,\alpha^T)\).
Specifying GAM Columns¶
There are two ways to specify GAM columns for thin plate regression. Following the below example, gam_columns can be specified as:
For R:
gam_col1 <- list("C11", c("C12","C13"), c("C14", "C15", "C16"), "C17", "C18")orgam_col1 <- list(c("C11"), c("C12","C13"), c("C14", "C15", "C16"), c("C17"), c("C18"))
For Python:
gam_col1 = ["C11",["C12","C13"],["C14","C15","C16"],"C17","C18"]orgam_col1 = [["C11"],["C12","C13"],["C14","C15","C16"],["C17"],["C18"]]
When using a grid search, the GAM columns are specified inside of the subspaces hyperparameter. Otherwise, the gam_column parameter is entered on its own when building a GAM model.
Normal GAM¶
#Import the train and test datasets:
train <- h2o.importFile("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/gaussian_20cols_10000Rows.csv")
test <- h2o.importFile("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/gaussian_20cols_10000Rows.csv")
# Set the factors:
train$C1 <- h2o.asfactor(train$C1)
train$C2 <- h2o.asfactor(train$C2)
test$C1 <- h2o.asfactor(test$C1)
test$C2 <- h2o.asfactor(test$C2)
# Set the predictors, response, & GAM columns:
predictors <- c("C1", "C2")
response = "C21"
gam_col1 <- list("C11", c("C12","C13"), c("C14", "C15", "C16"), "C17", "C18")
# Build and train the model:
gam_model <- h2o.gam(x = predictors, y = response,
gam_columns = gam_col1, training_frame = train,
validation_frame = test, family = "gaussian",
lambda_search = TRUE)
# Retrieve the coefficients:
coefficients <- h2o.coef(gam_model)
from h2o.estimators import H2OGeneralizedAdditiveEstimator
# Import the train dataset and set the factors:
train = h2o.import_file("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/multinomial_10_classes_10_cols_10000_Rows_train.csv")
train["C11"] = train["C11"].asfactor()
train["C1"] = train["C1"].asfactor()
train["C2"] = train["C2"].asfactor()
# Import the test dataset and set the factors:
test = h2o.import_file("https://s3.amazonaws.com/h2o-public-test-data/smalldata/glm_test/multinomial_10_classes_10_cols_10000_Rows_train.csv")
test["C11"] = test["C11"].asfactor()
test["C1"] = test["C1"].asfactor()
test["C2"] = test["C2"].asfactor()
# Set the predictors, response, and gam_cols:
x = ["C1", "C2"]
y = "C11"
gam_cols1 = ["C6", ["C7","C8"], "C9", "C10"]
gam_cols2 = [["C6"], ["C7", "C8"], ["C9"], ["C10"]]
# Build and train the two models:
h2o_model1 = H2OGeneralizedAdditiveEstimator(family='multinomial', gam_columns=gam_cols1, bs=[1,1,0,0], max_iterations=2)
h2o_model1.train(x=x, y=y, training_frame=train, validation_frame=test)
h2o_model2 = H2OGeneralizedAdditiveEstimator(family='multinomial', gam_columns=gam_cols2, bs=[1,1,0,0], max_iterations=2)
h2o_model2.train(x=x, y=y, training_frame=train, validation_frame=test)
# Retrieve the coefficients:
print(h2o_model1.coef())
print(h2o_model2.coef())
Grid Search¶
# Import the train dataset:
h2o_data <- h2o.importFile("https://s3.amazonaws.com/h2o-public-test-data/smalldata/gam_test/synthetic_20Cols_gaussian_20KRows.csv")
# Set the factors:
h2o_data$response <- h2o.asfactor(h2o_data$response)
h2o_data$C3 <- h2o.asfactor(h2o_data$C3)
h2o_data$C7 <- h2o.asfactor(h2o_data$C7)
h2o_data$C8 <- h2o.asfactor(h2o_data$C8)
h2o_data$C10 <- h2o.asfactor(h2o_data$C10)
# Set the predictors and response:
xL <- c("c_0", "c_1", "c_2", "c_3", "c_4", "c_5", "c_6", "c_7", "c_8",
"c_9", "C1", "C2", "C3", "C4", "C5", "C6", "C7", "C8", "C9", "C10")
yR = "response"
# Set up the search criteria and hyperparameters:
search_criteria <- list()
search_criteria$strategy <- 'RandomDiscrete'
search_criteria$seed <- 1
hyper_parameters <- list()
hyper_parameters$lambda = c(1, 2)
subspace <- list()
subspace$scale <- list(c(0.001, 0.001, 0.001), c(0.002, 0.002, 0.002))
subspace$num_knots <- list(c(5, 10, 12), c(6, 11, 13))
subspace$bs <- list(c(1, 1, 1), c(0, 1, 1))
subspace$gam_columns <- list(list("c_0", c("c_1", "c_2"), c("c_3", "c_4", "c_5")), list("c_1", c("c_2", "c_3"), c("c_4", "c_5", "c_6")))
hyper_parameters$subspaces <- list(subspace)
# Build and train the grid:
gam_grid = h2o.grid("gam", grid_id="GAMModel1", x=xL, y=yR,
training_frame=trainGaussian, family='binomial',
hyper_params=hyper_parameters, search_criteria=search_criteria)
# Retrieve the coefficients:
coefficients <- h2o.coef(gam_grid)
from h2o.estimators import H2OGeneralizedAdditiveEstimator
from h2o.grid.grid_search import H2OGridSearch
# Import the train dataset:
h2o_data <- h2o.import_file("https://s3.amazonaws.com/h2o-public-test-data/smalldata/gam_test/synthetic_20Cols_gaussian_20KRows.csv")
# Set the factors:
h2o_data['response'] = h2o_data['response'].asfactor()
h2o_data['C3'] = h2o_data['C3'].asfactor()
h2o_data['C7'] = h2o_data['C7'].asfactor()
h2o_data['C8'] = h2o_data['C8'].asfactor()
h2o_data['C10'] = h2o_data['C10'].asfactor()
# Set the predictors and response:
names = h2o_data.names
myY = "response"
myX = names.remove(myY)
# Set the search criteria and hyperparameters:
search_criteria = {'strategy': 'RandomDiscrete', "seed": 1}
hyper_parameters = {'lambda': [1, 2],
'subspaces': [{'scale': [[0.001], [0.0002]], 'num_knots': [[5], [10]], 'bs':[[1], [0]], 'gam_columns': [[["c_0"]], [["c_1"]]]},
{'scale': [[0.001, 0.001, 0.001], [0.0002, 0.0002, 0.0002]],
'bs':[[1, 1, 1], [0, 1, 1]],
'num_knots': [[5, 10, 12], [6, 11, 13]],
'gam_columns': [[["c_0"], ["c_1", "c_2"], ["c_3", "c_4", "c_5"]],
[["c_1"], ["c_2", "c_3"], ["c_4", "c_5", "c_6"]]]}]}
# Build and train the grid:
gam_grid = H2OGridSearch(H2OGeneralizedAdditiveEstimator(family="binomial", keep_gam_cols=True),
hyper_params=hyper_parameters,
search_criteria=search_criteria)
gam_grid.train(x = myX, y = myY, training_frame = h2o_data)
# Check the coefficients:
coefficeints = gam_grid.coef()