Pump data
This example demonstrates how you can get information about all deployments in a specified project and start sending data to those deployments for scoring using the payload of their sample requests. This uses asynchronous scoring calls which makes it a good tool for testing a large number of deployments simultaneously.
- Install aiohttp
- You will need the values for the following constants in order to successfully carry out the task. Contact your administrator to obtain deployment specific values.
| Constant | Value | Description |
|---|---|---|
MLOPS_API_URL | Usually: https://api.mlops.my.domain | Defines the URL for the MLOps Gateway component. |
TOKEN_ENDPOINT_URL | https://mlops.keycloak.domain/auth/realms/[fill-in-realm-name]/protocol/openid-connect/token | Defines the token endpoint URL of the Identity Provider. This uses Keycloak as the Identity Provider. Keycloak Realm should be provided. |
REFRESH_TOKEN | <your-refresh-token> | Defines the user's refresh token. |
CLIENT_ID | <your-client-id> | Sets the client id for authentication. This is the client you will be using to connect to MLOps. |
PROJECT_NAME | StandardFlow | Defines a project name that the script will be using. This example uses the project created in Driverless AI example. |
SEND_INTERVAL | 2.0 | Defines the time interval to send requests. This example sends sample requests every 2 seconds. |
MAX_CONSECUTIVE_ERRORS | 5 | Stops sending requests to an endpoint after the defined number of errors. This example stops sending requests after 5 consecutive errors. |
CONNECTION_LIMIT | 100 | Defines the maximum open TCP connections. This example defines a connection limit of 100. |
The following steps demonstrate how you can use MLOps Python client to send data to the deployments of a specified project for scoring.
-
Change the values of the following constants in your
PumpData.pyfile as given in the preceding data table.- Format
- Sample
PumpData.py### Constants
MLOPS_API_URL = <MLOPS_API_URL>
TOKEN_ENDPOINT_URL = <TOKEN_ENDPOINT_URL>
REFRESH_TOKEN = <REFRESH_TOKEN>
CLIENT_ID = <CLIENT_ID>
PROJECT_NAME = <PROJECT_NAME>
SEND_INTERVAL = <SEND_INTERVAL>
MAX_CONSECUTIVE_ERRORS = <MAX_CONSECUTIVE_ERRORS>
CONNECTION_LIMIT = <CONNECTION_LIMIT>PumpData.py### Constants
MLOPS_API_URL = "https://api.mlops.my.domain"
TOKEN_ENDPOINT_URL="https://mlops.keycloak.domain/auth/realms/[fill-in-realm-name]/protocol/openid-connect/token"
REFRESH_TOKEN="<your-refresh-token>"
CLIENT_ID="<your-mlops-client>"
PROJECT_NAME = "PumpDataExample"
SEND_INTERVAL = "2.0
MAX_CONSECUTIVE_ERRORS = 5
CONNECTION_LIMIT = 100 -
Run the
PumpData.pyfile.python3 PumpData.py -
Navigate to MLOps and click the project name
StandardFlowunder Projects. Then click the name of the project to open the Deployment Overview side panel, and click view monitoring to see the monitoring details.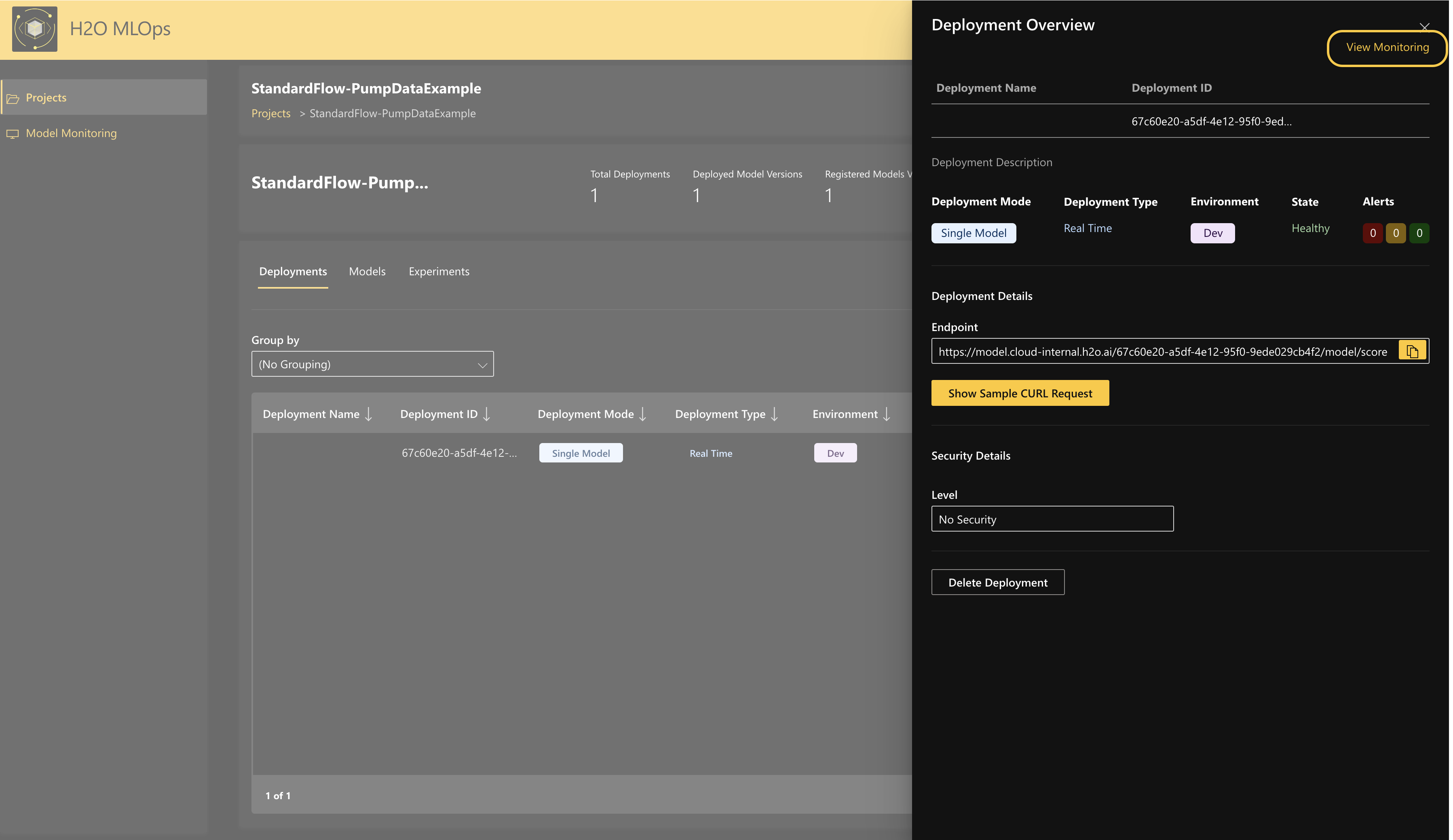 Note
NoteFor more information about deployments in MLOps, see Understand deployments in MLOps.
-
Under the Health panel you will be able to see the predictions made for the scoring data sent by the script.
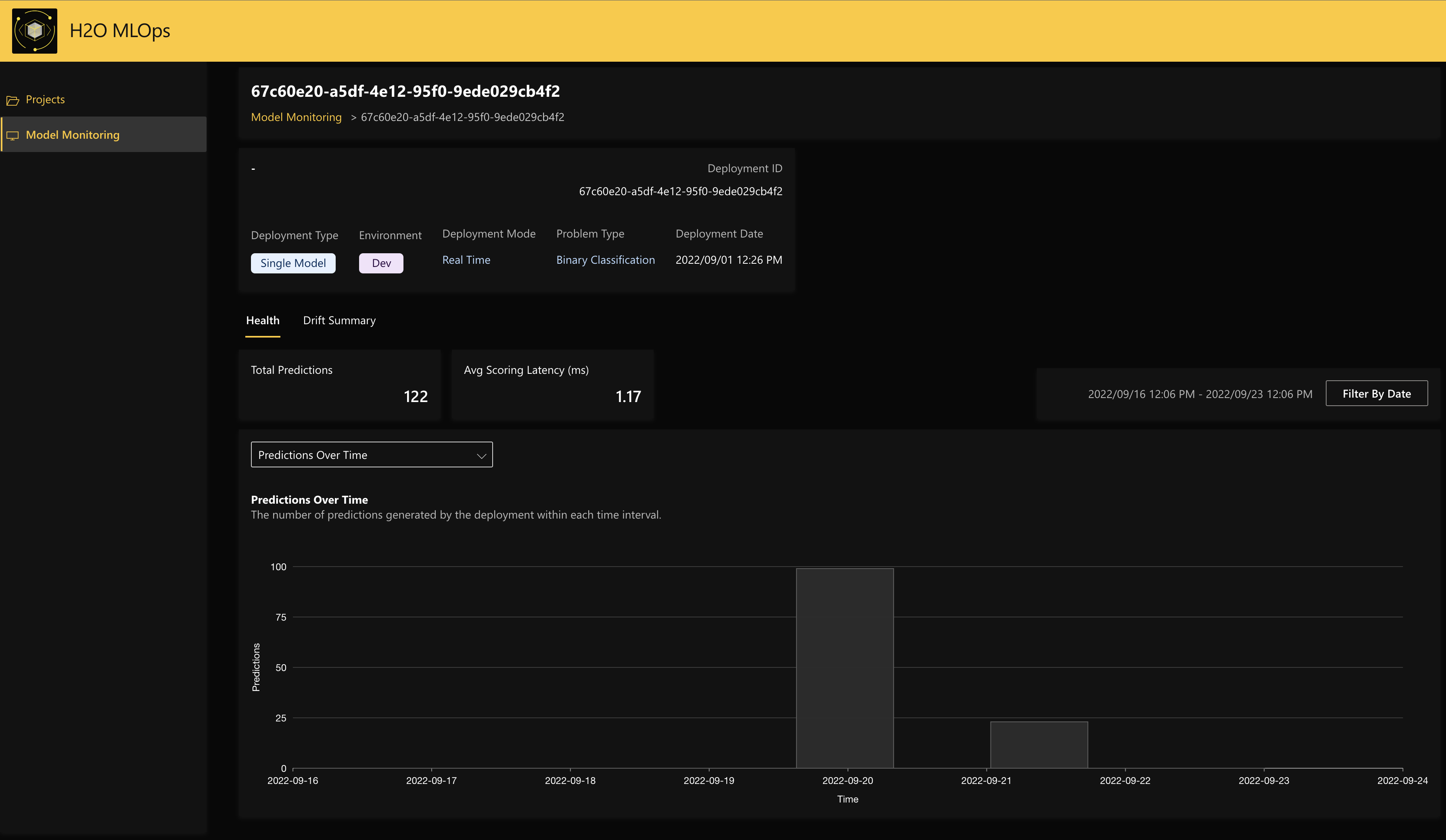
Example walkthrough
This section provides a walkthrough of the PumpData.py file.
-
Include the following
_get_project_idfunction to get the project id of the defined project name.PumpData.pydef _get_project_id(projects: List[mlops.StorageProject]) -> str:
"""Gets the ID of the selected project."""
for p in projects:
if p.display_name == PROJECT_NAME:
return p.id
else:
raise LookupError("Requested project not found") -
Include the
_get_sample_payloadfunction to get a sample payload from the sample request deployment endpoint.PumpData.pyasync def _get_sample_payload(
sample_request_url: str, deployment_id: str, http_session: aiohttp.ClientSession
) -> Dict[str, dict]:
"""Gets sample request payload from the sample request deployment endpoint."""
async with http_session.get(sample_request_url) as r:
sample_payload = await r.json()
return {deployment_id: sample_payload} -
Include the
get_deployment_statusesfunction to get the deployment statuses of the project. This first gets all the projects of the user and then gets the deployment statuses of the project the user has specified in the script.PumpData.pydef get_deployment_statuses(client: mlops.Client) -> List[mlops.DeployDeploymentStatus]:
"""Gets deployment metada."""
# Getting all user's projects.
projects: mlops.StorageListProjectsResponse = client.storage.project.list_projects(
mlops.StorageListProjectsRequest()
)
prj_id = _get_project_id(projects.project)
# Getting all deployment statuses for the selected project.
statuses: mlops.DeployListDeploymentStatusesResponse = (
client.deployer.deployment_status.list_deployment_statuses(
mlops.DeployListDeploymentStatusesRequest(project_id=prj_id)
)
)
return statuses.deployment_status -
Include the
get_sample_payloadsfunction to get sample payloads from a collection of deployments metadata.PumpData.pyasync def get_sample_payloads(
deployment_statuses: List[mlops.DeployDeploymentStatus],
http_session: aiohttp.ClientSession,
) -> dict:
"""Gets sample payloads from a collection of deployments metadata."""
requests_futures = []
for ds in deployment_statuses:
sample_payload_awaitable = _get_sample_payload(
ds.scorer.sample_request.url, ds.deployment_id, http_session
)
sample_payload_future = asyncio.ensure_future(sample_payload_awaitable)
requests_futures.append(sample_payload_future)
sample_payloads_nested = await asyncio.gather(*requests_futures)
sample_payloads = {}
for payload in sample_payloads_nested:
sample_payloads.update(payload)
return sample_payloads -
Include the
send_sample_requestfunction to continuously sends sample requests to the specified scoring URL.PumpData.pyasync def send_sample_request(
scoring_url: str, payload: dict, http_session: aiohttp.ClientSession
) -> None:
"""Continously sends sample requests to the specified scoring URL."""
error_count = 0
while error_count < MAX_CONSECUTIVE_ERRORS:
async with http_session.post(scoring_url, json=payload) as r:
if r.status != 200:
error_count += 1
print(
f"Failed sending data to: {scoring_url} with status: {r.status}, response: {await r.text()}"
)
await asyncio.sleep(SEND_INTERVAL)
print(f"Stopped sending requests to: {scoring_url}") -
In the main function,
-
Set up the TCP connection limit.
PumpData.pyconn = aiohttp.TCPConnector(limit=CONNECTION_LIMIT) -
Get the deployment metadata by calling the
get_deployment_statusesfunction.PumpData.pydeployment_statuses = get_deployment_statuses(mlops_client) -
Include the client session.
PumpData.pyasync with aiohttp.ClientSession(connector=conn) as sessions:
sample_payloads = await get_sample_payloads(deployment_statuses, sessions)
sample_requests_futures = []
for ds in deployment_statuses:
send_request_awaitable = send_sample_request(
ds.scorer.score.url, sample_payloads[ds.deployment_id], sessions
)
send_request_future = asyncio.ensure_future(send_request_awaitable)
sample_requests_futures.append(send_request_future)
await asyncio.gather(*sample_requests_futures)NoteAlthough having a single client session is uncommon, this context manager is actually a connection pool and should be treated as such. Having multiple client sessions here can cause race condition issues. For more information, see Client session in aiohttp.
-
-
Finally, include the below code to run the main function.
PumpData.pyif __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
- Submit and view feedback for this page
- Send feedback about H2O MLOps to cloud-feedback@h2o.ai