Datasets in Driverless AI
The Datasets Overview page is the Driverless AI home page. It displays the datasets that have been imported into Driverless AI. Data Connectors can be used to connect to various data sources.
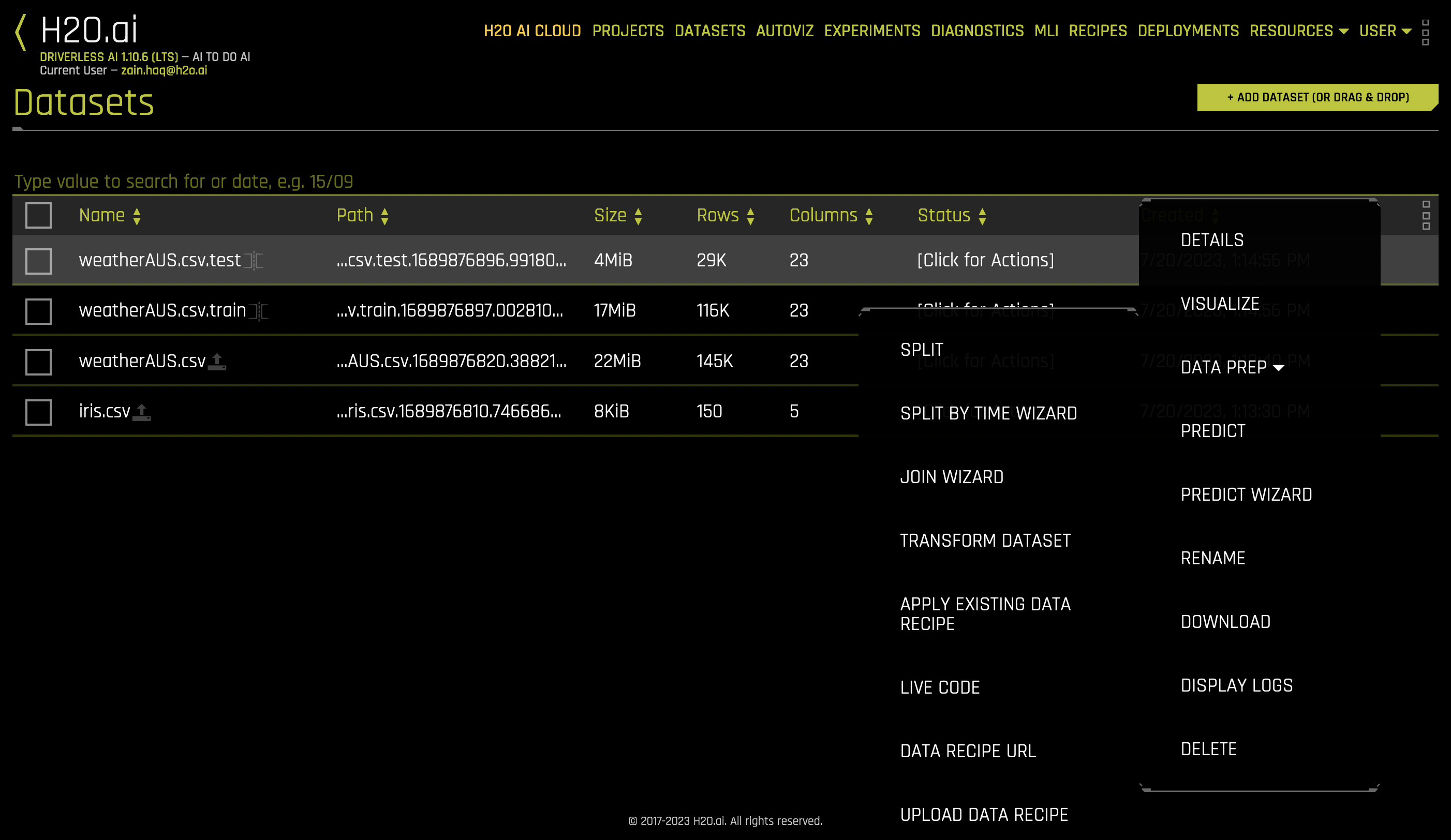
The Datasets Overview page is the Driverless AI home page. It displays the datasets that have been imported into Driverless AI. Data Connectors can be used to connect to various data sources.