解释器(插件)专家设置¶
以下是解释器特定专家设置列表,可在设置新解释时使用。从 MLI page 的 recipes 选项卡运行解释时,可访问这些设置。关于常规 MLI 专家设置的信息,请参见 解释专家设置.
绝对排列特征重要性解释器设置¶
mli_sample_size¶
Sample size
指定绝对排列特征重要性解释器的样本大小。默认值为 100000。
missing_values¶
List of values that should be interpreted as missing values
指定数据导入期间应被解释为缺失值的值列表。适用于数字列和字符串列。注意,’nan’ 始终被解释为数字列的缺失值。
示例:""\"[''、'?'、'None'、'nan'、'N/A'、'unknown'、'inf']\""
autodoc_feature_importance_num_perm¶
Number of Permutations for Feature Importance
指定计算特征重要性时每项特征的排列数。默认值为 1。
autodoc_feature_importance_scorer¶
Feature Importance Scorer
指定计算特征重要性时需使用的评分器名称。将此项设置保留未指定状态,即可为实验使用默认评分器。
MLI AutoDoc 解释器设置¶
autodoc_report_name¶
AutoDoc Name
指定 AutoDoc 的名称。
autodoc_template¶
AutoDoc Template Location
指定 AutoDoc 模板路径。提供自定义 AutoDoc 模板的完整路径。若需生成标准 AutoDoc,则将此字段保留为空白。
autodoc_output_type¶
AutoDoc File Output Type
指定 AutoDoc 文件输出类型。从 docx (默认值)和 md 中选择。
autodoc_subtemplate_type¶
AutoDoc Sub-Template Type
指定要使用的子模板类型。从以下类型中选择:
auto(默认)
md
docx
autodoc_max_cm_size¶
Confusion Matrix Max Number of Classes
指定混淆矩阵中的最大类别数。默认值为 10。
autodoc_num_features¶
Number of Top Features to Document
指定要在文档中显示的主要特征数量。若需禁用此设置,则指定 -1 。默认值为 50。
autodoc_min_relative_importance¶
Minimum Relative Feature Importance Threshold
指定相对特征重要性的最小值,以显示特征。此值必须是大于或等于 0 且小于或等于 1 的浮点数。默认值为 0.003。
autodoc_include_permutation_feature_importance¶
Permutation Feature Importance
指定是否计算基于排列的特征重要性。默认会禁用此设置。
autodoc_feature_importance_num_perm¶
Number of Permutations for Feature Importance
指定计算特征重要性时每项特征的排列数。默认值为 1。
autodoc_feature_importance_scorer¶
Feature Importance Scorer
指定计算特征重要性时需使用的评分器名称。将此项设置保留未指定状态,即可为实验使用默认评分器。
autodoc_pd_max_rows¶
PDP and Shapley Summary Plot Max Rows
指定在 AutoDoc 中为部分依赖性图 (PDP) 和 Shapley 值摘要图显示的行数。对于超过 autodoc_pd_max_rows 限制的数据集,将进行随机抽样。默认值为 10000。
autodoc_pd_max_runtime¶
PDP Max Runtime in Seconds
指定生成报告时计算部分依赖性需要的最大秒数值。将此数值设置为 -1,即表示无时间限制。
autodoc_out_of_range¶
PDP Out of Range
指定部分依赖性图包含的列范围之外的标准偏差数。这显示了模型会对之前未曾处理过的数据作出何种反应。默认值为 3。
autodoc_num_rows¶
ICE Number of Rows
如果未指定单独的行,则指定 PDP 和 ICE 图中的行数。默认值为 0。
autodoc_population_stability_index¶
Population Stability Index
如果实验属于二元分类或回归问题,则指定是否包含群体稳定性指标。默认会禁用此设置。
autodoc_population_stability_index_n_quantiles¶
Population Stability Index Number of Quantiles
指定用于群体稳定性指标的分位点数量。默认值为 10。
autodoc_prediction_stats¶
Prediction Statistics
如果实验属于二元分类或回归问题,则指定是否包含预测统计数据信息。默认会禁用此设置。
autodoc_prediction_stats_n_quantiles¶
Prediction Statistics Number of Quantiles
指定用于预测统计数据的分位点数量。默认值为 20。
autodoc_response_rate¶
Response Rates Plot
如果实验属于二元分类问题,则指定是否包含响应率信息。默认会禁用此设置。
autodoc_response_rate_n_quantiles¶
Response Rates Plot Number of Quantiles
指定用于响应率信息的分位点数量。默认值为 10。
autodoc_gini_plot¶
Show GINI Plot
指定是否显示 GINI 图。默认会禁用此设置。
autodoc_enable_shapley_values¶
Enable Shapley Values
指定是否在 AutoDoc 中显示 Shapley 值结果。默认会启用此设置。
autodoc_global_klime_num_features¶
Global k-LIME Number of Features
指定要在 k-LIME 全局 GLM 系数表中显示的特征数量。此数值必须为大于 0 或 -1 的整数。若需显示所有特征,则将此值设置为 -1。
autodoc_global_klime_num_tables¶
Global k-LIME Number of Tables
指定要在 AutoDoc 中显示的 k-LIME 全局 GLM 系数表的数量。将此数值设置为 1,可显示一个按绝对值排序的系数表。将此数值设置为 2,则可显示两个表格 – 一个为最高正系数表,另一个为最高负系数表。默认值为 1。
autodoc_data_summary_col_num¶
Number of Features in Data Summary Table
指定要在数据摘要表中显示的特征数量。此值必须是整数。若要显示所有列,则指定任何小于 1 的值。默认值为 -1。
autodoc_list_all_config_settings¶
List All Config Settings
指定是否显示所有配置设置。如果禁用此设置,则仅列出已更改的设置。启用时将列出所有设置。默认会禁用此设置。
autodoc_keras_summary_line_length¶
Keras Model Architecture Summary Line Length
指定 Keras 模型架构摘要的行长度。此值必须是大于 0 或 -1 的整数。若要使用默认行长度,则将此值设置为 -1(默认值)。
autodoc_transformer_architecture_max_lines¶
NLP/Image Transformer Architecture Max Lines
指定为“特征”一节中高级转换器架构显示的最大行数。请注意,完整的架构可在附录中找到。
autodoc_full_architecture_in_appendix¶
Appendix NLP/Image Transformer Architecture
指定是否在附录中显示完整的 NLP/图像转换器架构。默认会禁用此设置。
autodoc_coef_table_appendix_results_table¶
Full GLM Coefficients Table in the Appendix
指定是否在附录中显示完整的 GLM 系数表。默认会禁用此设置。
autodoc_coef_table_num_models¶
GLM Coefficient Tables Number of Models
指定在 AutoDoc 中显示了 GLM 系数表的模型数量。此值必须为 -1 或 >= 1 的整数。将此值设置为 -1 即可显示所有模型的系数表。默认值为 1。
autodoc_coef_table_num_folds¶
GLM Coefficient Tables Number of Folds Per Model
指定在 AutoDoc 中显示了 GLM 系数表的每个模型的折叠数。此值必须为 -1(默认值)或 >= 1 的整数(设置为 -1 时,将显示每个模型的所有折叠)。
autodoc_coef_table_num_coef¶
GLM Coefficient Tables Number of Coefficients
指定要在 AutoDoc 内的 GLM 系数表中显示的系数数量。默认值为 50。设置为 -1 时,将显示所有系数。
autodoc_coef_table_num_classes¶
GLM Coefficient Tables Number of Classes
指定要在 AutoDoc 内的 GLM 系数表中显示的类别数量。设置为 -1 时,将显示所有类别。默认值为 9。
autodoc_num_histogram_plots¶
Number of Histograms to Show
指定要显示直方图的主要特征数量。默认值为 10。
差异影响分析解释器设置¶
关于 Driverless AI 中的差异影响分析的信息,请参阅 差异影响分析 (DIA). 以下是运行新解释时可在 MLI 页面的“插件”选项卡中切换的参数列表。
dia_cols¶
List of Features for Which to Compute DIA
指定要计算 DIA 的特定特征列表。
cut_off¶
Cut Off
指定执行 DIA 时的截止点。
maximize_metric¶
Maximize Metric
指定计算 DIA 时要使用的指标。从以下指标中选择:
F1
F05
F2
MCC
use_holdout_preds¶
Use Internal Holdout Predictions
指定是否在计算 DIA 时使用内部保持预测结果。默认会启用此项设置。
sample_size¶
Sample Size for Disparate Impact Analysis
指定差异影响分析的样本大小。默认情况下,此值设置为 100000。
max_card¶
Max Cardinality for Categorical Variables
指定分类变量的最大基数。默认情况下,此值设置为 10。
min_card¶
Minimum Cardinality for Categorical Variables
指定分类变量的的最小基数。默认情况下,此值设置为 2。
num_card¶
Max Cardinality for Numeric Variables to be Considered Categorical
指定将被视为分类的数值变量的最大基数。默认情况下,此值设置为 25。
fast_approx¶
Speed Up Predictions With a Fast Approximation
指定是否使用快速近似来提高预测速度。默认会启用此设置。
NLP 部分依赖性图解释器设置¶
max_tokens¶
Number of text tokens
指定 NLP 部分依赖性图的文本标记数量。默认值为 20。
custom_tokens¶
List of custom text tokens
指定要计算 NLP 部分依赖性的自定义文本标记列表。例如, [\”text_feature(’word_1’)\”] ,其中 text_feature 为模型文本特征名称。
NLP 向量化器 + 线性模型文本特征重要性解释器设置¶
txt_cols¶
Text feature for which to compute explanation
指定要计算解释的文本特征。
cut_off¶
Cut off for deciphering binary class outcome
指定基于 DAI 模型预测解译二进制类结果的截止点。任何大于截止点的 DAI 预测即为目标标签,任何小于截止点的 DAI 预测即为非目标标签。
maximize_metric¶
Cut off based on a metric to maximize
基于一个最大化的指标计算截止点,它将基于 DAI 模型预测解译二进制类结果。任何大于截止点的 DAI 预测即为目标标签,任何小于截止点的 DAI 预测即为非目标标签。需注意,在指定截止点和最大化指标之间,将优先指定截止点。
部分依赖性图解释器设置¶
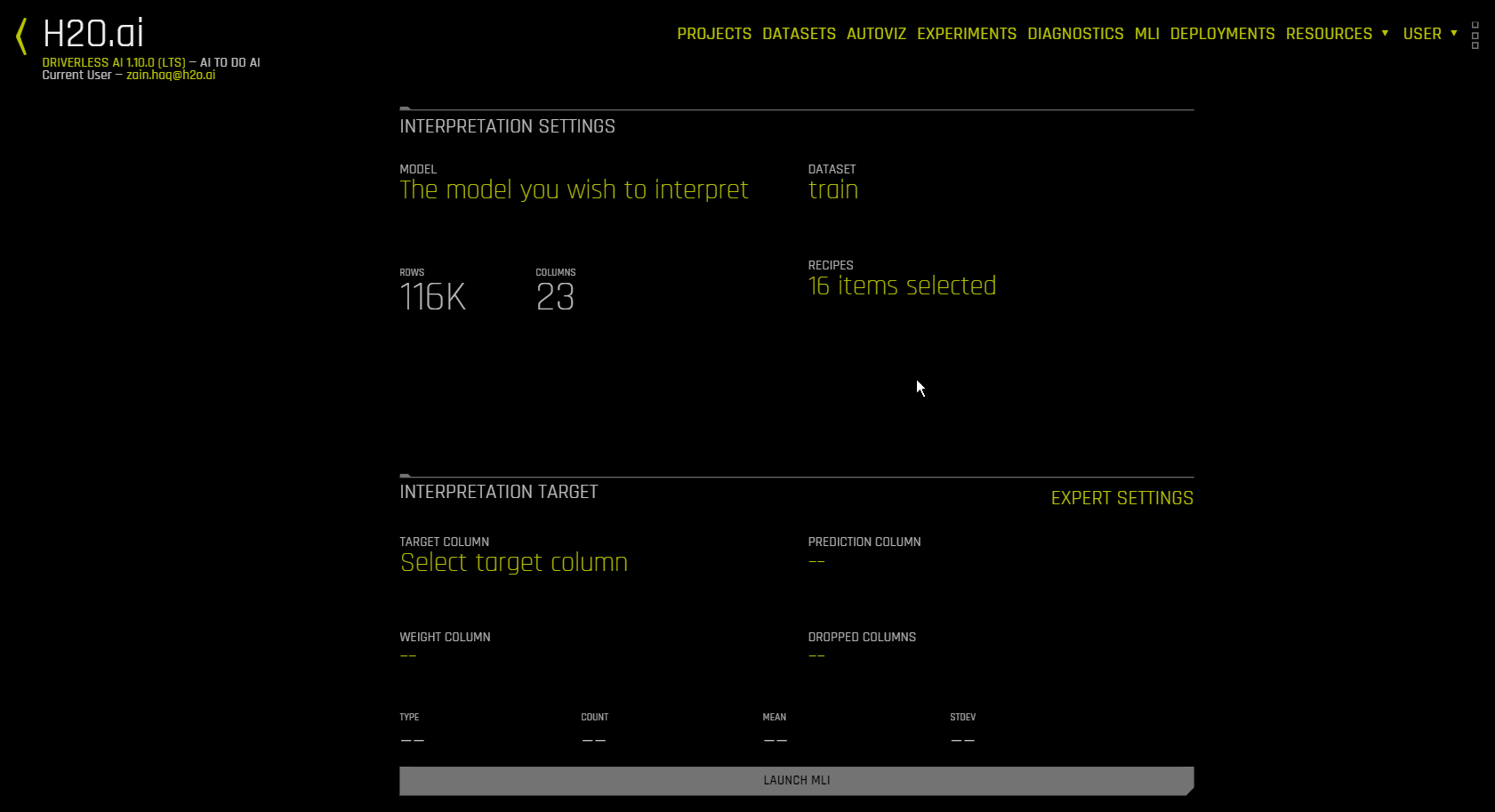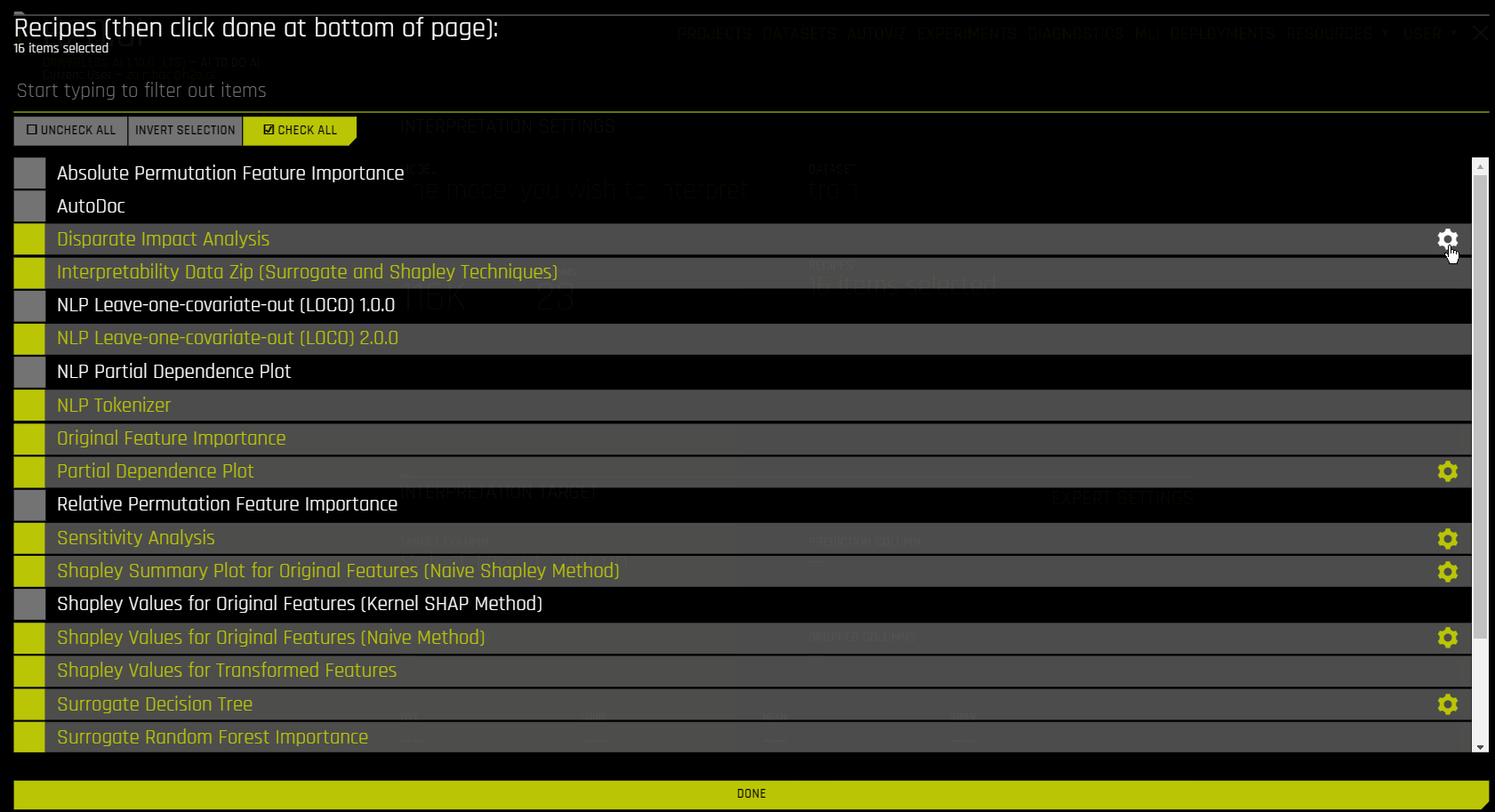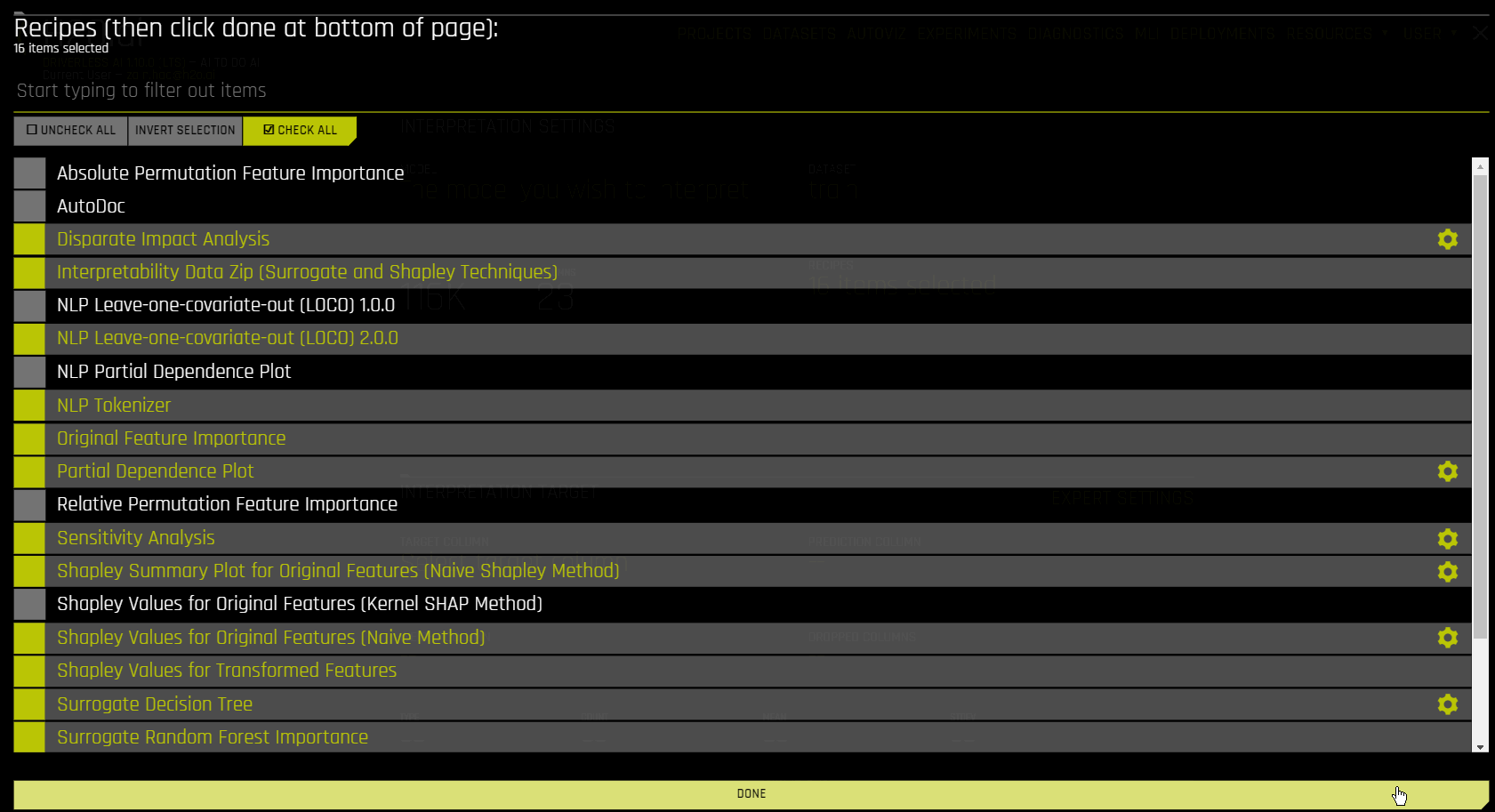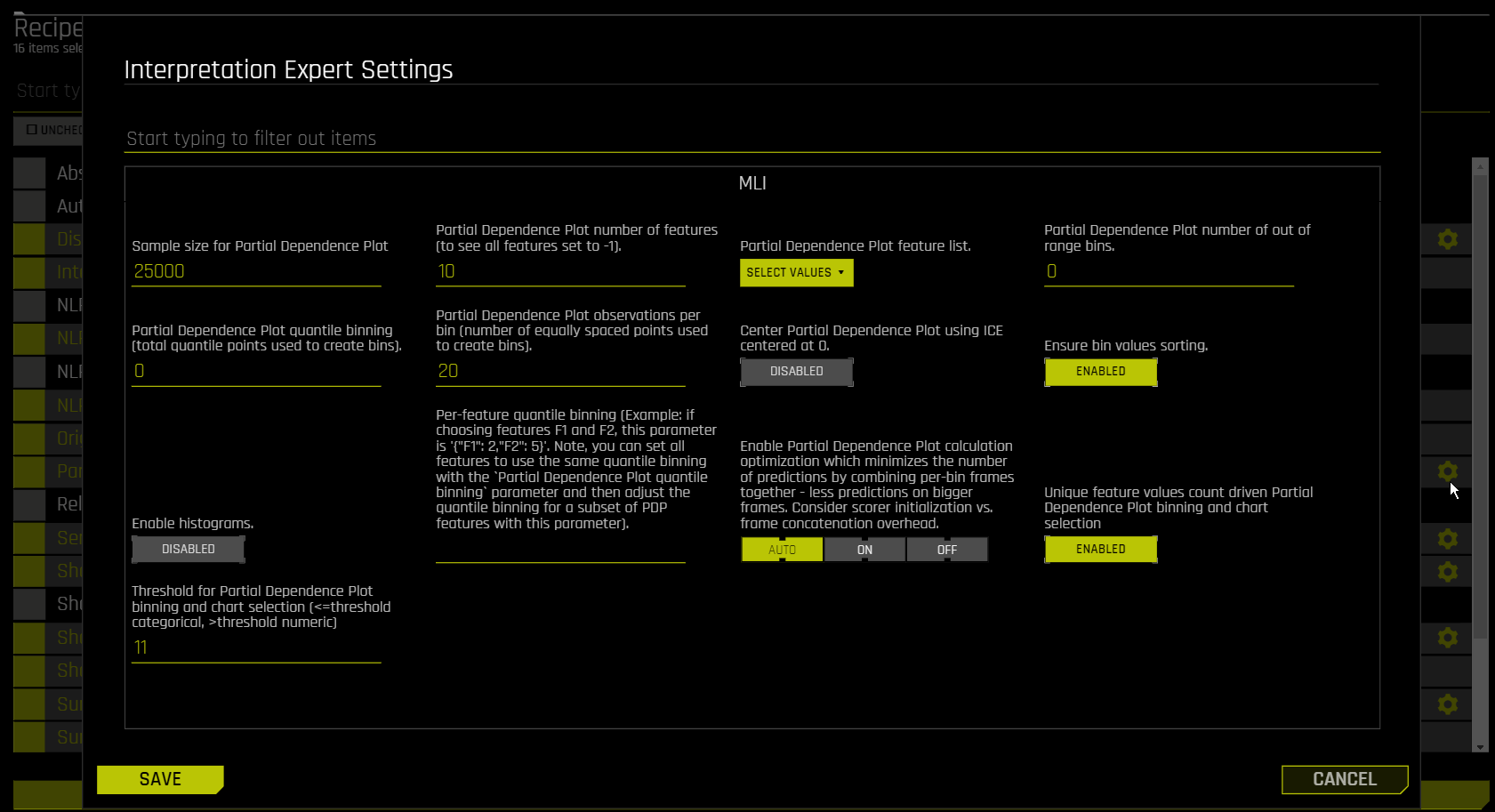
关于 Driverless AI 中的部分依赖性图的信息,请参阅 部分依赖性图 (PDP). 以下是运行新解释时可在 MLI 页面的“插件”选项卡中切换的参数列表。
sample_size¶
Sample Size for Partial Dependence Plot
当行数超出此限制时,将为 Driverless AI 部分依赖性图进行抽样。
max_features¶
Partial Dependence Plot Number of Features
指定可在部分依赖性图中查看的特征数量。默认值为 10。若需查看所有特征,则将此值设置为 -1。
features¶
Partial Dependence Plot Feature List
指定部分依赖性图的特征列表。
oor_grid_resolution¶
PDP Number of Out of Range Bins
指定部分依赖性图范围外的分箱数量。默认值为 0。
qtile_grid_resolution¶
PDP Quantile Binning
指定用于创建分箱的分位数点总数。默认值为 0。
grid_resolution¶
PDP Observations Per Bin
指定用于创建分箱的等距点数量。默认值为 20。
center¶
Center PDP Using ICE Centered at 0
指定是否使用以 0 为中心的 ICE 来使部分依赖性图居中。默认会禁用此项设置。
sort_bins¶
Ensure Bin Values Sorting
指定是否确保按分箱值排序。默认会启用此项设置。
histograms¶
Enable Histograms
指定是否启用部分依赖性图的直方图。默认会禁用此项设置。
qtile-bins¶
Per-Feature Quantile Binning
指定每个特征的分位数分箱。例如,如果您选择了特征 F1 和 F2,则可将此参数指定为 '{"F1": 2,"F2": 5}'.
请注意:您可以使用 qtile_grid_resolution 参数将所有特征设置为使用相同的分位数分箱,然后使用此参数调整 PDP 特征子集的分位数分箱。
1_frame¶
Enable PDP Calculation Optimization
指定是否启用 PDP 计算优化,从而通过组合每个箱子的所有帧来使预测数量最小化。此项设置默认设置为’自动’。
numcat_num_chart¶
Unique Feature Values Count-Driven PDP Binning and Chart Selection
指定在实验将特征同时用作数值特征和分类特征的情况下,是否动态切换 PDP 数值和分类分箱与 UI 图表。默认会启用此项设置。
numcat_threshold¶
Threshold for PD/ICE Binning and Chart Selection
如果启用 mli_pd_numcat_num_chart ,且唯一特征值的数量大于阈值,则将使用数值分箱和图表。否则,将使用分类分箱和图表。默认阈值为 11。
敏感性分析解释器设置¶
sample_size¶
Sample Size for Sensitivity Analysis (SA)
当行数超出此限制时,将为敏感性分析 (SA) 进行抽样。默认值为 500000。
Shapley 摘要图解释器设置¶
关于 Driverless AI 中的 Shapley 摘要图的信息,请参阅 Shapley 摘要图(原始特征). 以下是运行新解释时可在 MLI 页面的“插件”选项卡中切换的参数列表。
max_features¶
Maximum Number of Features to be Shown
指定此图中所显示特征的最大数量。默认值为 50。
sample_size¶
Sample Size
指定绘图的样本大小。默认值为 20000。
x_resolution¶
X-Axis Resolution
指定 Shapley 值分箱的数量。默认值为 500。
drilldown_charts¶
Enable Creation of Per-Feature Shapley / Feature Value Scatter Plots
指定是否允许创建每个特征的 Shapley 值或特征值散点图。默认会启用此项设置。
fast_approx¶
Speed Up Predictions With a Fast Approximation
指定是否使用快速近似来提高预测速度。默认会启用此设置。