데이터 세트 가져오기¶
지원 파일 유형¶
Driverless AI는 다음dml 데이터 세트 파일 형식을 지원합니다.
arff
avro
bin
bz2
csv (아래 참고 참조)
dat
feather
gz
jay (아래 참고 참조)
orc (아래 참고 참조)
parquet (아래 참고 참조)
pickle / pkl (아래 참고 참조)
tgz
tsv
txt
xls
xlsx
xz
zip
참고
압축된 Parquet 파일은 Driverless AI와 함께 사용하기에 가장 효율적인 파일 유형입니다.
UTF-16 인코딩의 CSV는 BOM(바이트 순서 표시)으로 구현된 경우에만 지원됩니다. BOM이 없으면 데이터 세트는 UTF-8로 읽습니다.
ORC 및 Parquet 파일 형식의 경우, 여러 파일 가져오기를 선택하면 해당 파일을 여러 데이터 세트로 가져옵니다. ORC 또는 Parquet 파일의 폴더를 선택하면 폴더를 단일 데이터 세트로 가져옵니다. Spark/Hive와 같은 도구는 사용자 정의된 이름으로 디렉터리에 저장된 여러 ORC 또는 Parquet 파일로 데이터를 내보냅니다. 예를 들어,
Spark dataFrame.write.parquet("/data/big_parquet_dataset")로 데이터를 내보내면 Spark는 여러 개의 Parquet 파일(입력 데이터 세트의 파티션 수에 따라) 및 메타데이터를 포함시킬 /data/big_parquet_dataset 폴더를 생성합니다. ORC 파일을 내보내면 비슷한 결과가 생성됩니다.ORC 및 Parquet 파일 형식의 경우, 배열의 요소로 구조체를 가진 ORC 또는 Parquet 파일의 수집 시, 《Failed to ingest binary file with ORC / Parquet: lists with structs are not supported》 오류가 표시될 수 있습니다. 이는 PyArrow cannot handle a struct that’s an element of an array 때문입니다.
Parquet 파일을 flatten하는 해결책은 Sparkling Water에서 제공됩니다. 자세한 내용은 our Sparkling Water solution 을 참조하십시오.
목록 유형을 갖는 열이 있는 Parquet 파일을 사용하려면
data_import_explode_list_type_columns_in_parquetconfig.toml option 을true로 설정해야 합니다. (이 설정은 기본적으로 비활성화되어 있습니다.) 이 옵션이 활성화되면 목록 유형의 열이 별도의 새로운 열로 《exploded》 됩니다. 즉, 셀의 각 목록이 별도 항목으로 분할된 다음, 이를 사용하여 새 열을 생성합니다. 이 프로세스의 시각적 표현은 다음 이미지를 참조하십시오.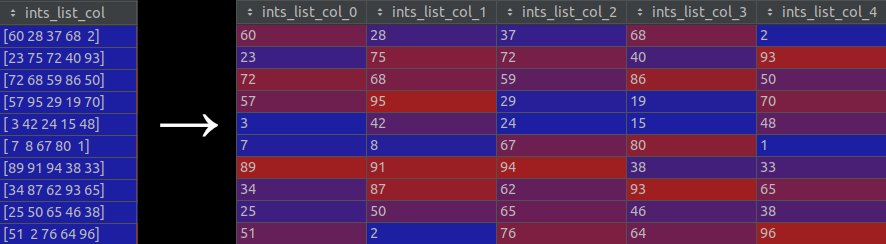
Add Dataset (or Drag & Drop) 드롭다운 메뉴에서 Data Recipe URL 또는 Upload Data Recipe 를 선택하여 Python 스크립트 파일(사용자 정의 레시피)에서 새로운 데이터 세트를 만들 수 있습니다. Data Recipe URL 옵션 선택 시, URL은 반드시 파일의 HTML 또는 원시 버전, GitHub 리포지터리 또는 tree 또는 로컬 파일을 가리켜야 합니다. 또한, 사용자 정의 레시피로 기존 데이터 세트를 수정하여 새로운 데이터 세트를 만들 수도 있습니다. 자세한 내용은 사용자 정의 데이터 레시피로 수정 를 참조하십시오. 레시피에서 생성되거나 추가된 데이터 세트는 .jay 파일로 저장됩니다.
잠재 오류를 방지하기 위해서 pickle 파일을 CSV 또는 .jay 파일로 변환하는 것을 권장합니다. 다음은 Datatable을 사용하여 pickle 파일을 CSV 파일로 변환하는 방법에 관한 예제입니다.
import datatable as dt import pandas as pd df = pd.read_pickle("test.pkl") dt = dt.Frame(df) dt.to_csv("test.csv")
데이터 세트 추가¶
다음 방법 중 하나를 사용하여 데이터 세트를 추가할 수 있습니다.
로컬 컴퓨터에서 이 페이지로 파일을 직접 끌어다 놓으십시오. 이 방법은 현재 10GB 미만의 파일에 대해서 가능합니다.
또는
Add Dataset (or Drag & Drop) 버튼을 클릭하여 데이터 세트를 업로드하거나 추가하십시오.
Notes:
파일 업로드, 파일 시스템, HDFS, S3, Data Recipe URL 및 데이터 레시피 업로드는 기본적으로 활성화되어 있습니다. config.toml 파일의
enabled_file_systems설정에서 이를 제거하여 비활성화가 가능합니다(자세한 내용은 Using the config.toml file 섹션을 참조하십시오).파일 시스템이 비활성화되면 Driverless AI는 로컬 파일 브라우저를 엽니다.
Azure Blob Store, BlueData Datatap, Google Big Query, Google Cloud Storage, KDB +, Minio, Snowflake 또는 JDBC에 대해 활성화된 데이터 커넥터를 사용하여 Driverless AI가 시작된 경우, 해당 옵션은 Add Dataset (or Drag & Drop) 드롭다운 메뉴에 나타납니다. 자세한 내용은 Enabling Data Connectors 섹션을 참조하십시오.
Data Recipe URL 을 통해 데이터 세트의 추가를 지정할 때, URL은 파일의 HTML 또는 원시 버전, GitHub 리포지터리 또는 tree 또는 로컬 파일을 가리켜야 합니다. 레시피를 통한 데이터 세트의 추가 및 업로드 시, 데이터 세트는 .jay 파일로 저장됩니다.
데이터 세트는 반드시 구분된 텍스트 형식이어야 합니다.
Driverless AI는 다음 구분자를 감지할 수 있습니다.,|;t
폴더를 가져올 때 전체 폴더 및 모든 내용이 Driverless AI에 하나의 파일로 읽혀집니다.
폴더를 가져올 때 폴더의 모든 파일은 반드시 동일한 열을 가져야 합니다.
Windows상에서 데이터 커넥터를 통해 폴더를 가져오려고 할 때, 폴더에 파일 확장자가 없는 파일이 포함되어 있는 경우에는 가져오기가 실패합니다(결과적인 오류는 일반적으로 상기의 참고 사항과 관련이 있음).
완료 시, 데이터 세트가 데이터 세트의 개요 페이지에 나타납니다. 데이터 세트를 클릭하여 하위 메뉴를 여십시오. 해당 메뉴에서 데이터 세트의 이름 바꾸기, 세부 내용 확인, 시각화, 분할, 다운로드 또는 삭제의 지정이 가능합니다. Note: 활성화된 실험에 사용된 데이터 세트는 삭제할 수 없습니다. 먼저 실험을 삭제하십시오.