데이터 세트 분할¶
Driverless AI를 사용하면 모델링 중에 데이터 세트를 학습 및 검증/테스트 데이터 세트로 사용할 수 있는 두 개의 서브세트로 분할이 가능합니다. 모델링을 위한 데이터 세트의 분할 시, 각 분할은 학습 세트에 과적합되지 않도록 비슷한 분포를 가져야 합니다. 사용 사례에 따라 데이터 세트를 randomly 분할하거나, target column 을 기반으로 stratified sampling 을 수행하거나, fold column 기반 분할을 수행하여 같은 그룹에 속한 행을 유지하거나, time column 기반 분할을 수행하여 과거 데이터를 학습하고 미래 데이터를 검증/테스트할 수 있습니다.
다음 단계를 수행하여 데이터 세트를 분할하십시오.
데이터 세트를 클릭하거나 분할하려는 데이터 세트 옆에 위치한 [Click for Actions] 버튼을 선택하고, 표시되는 하위 메뉴에서 Split 를 선택하십시오.
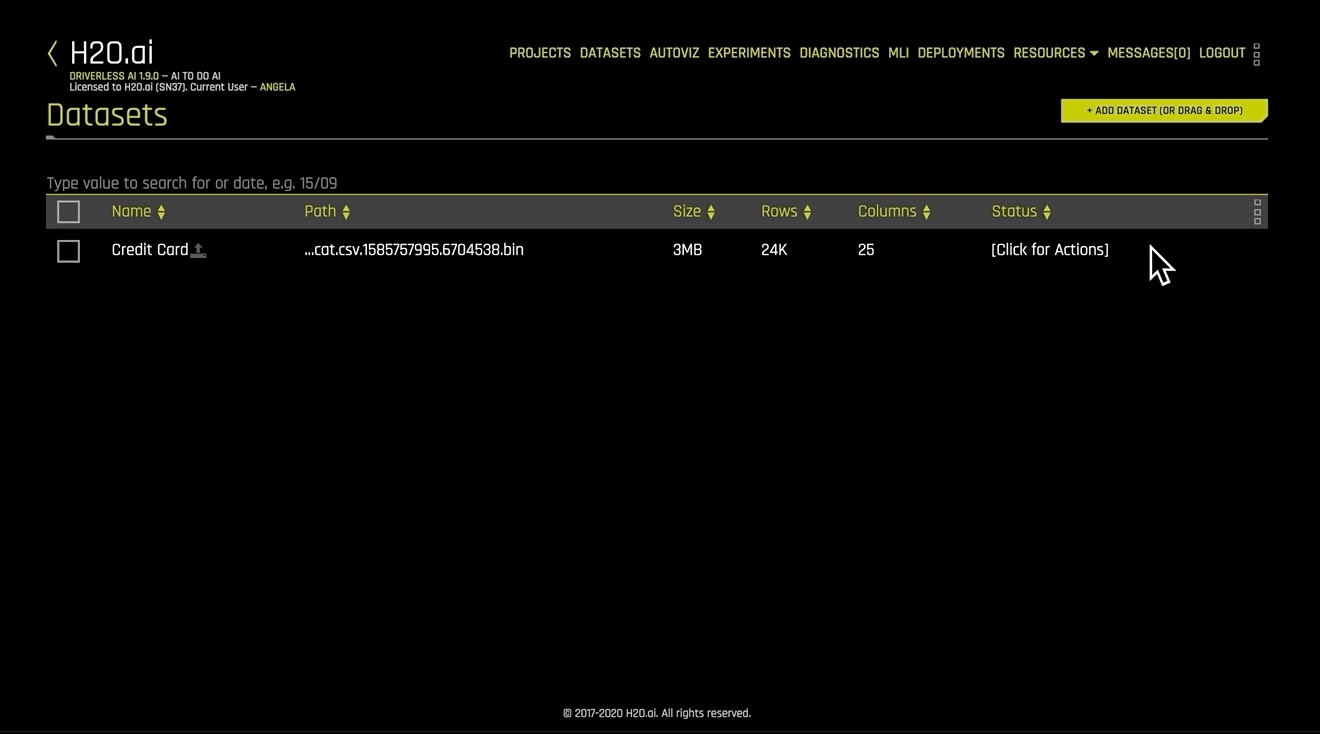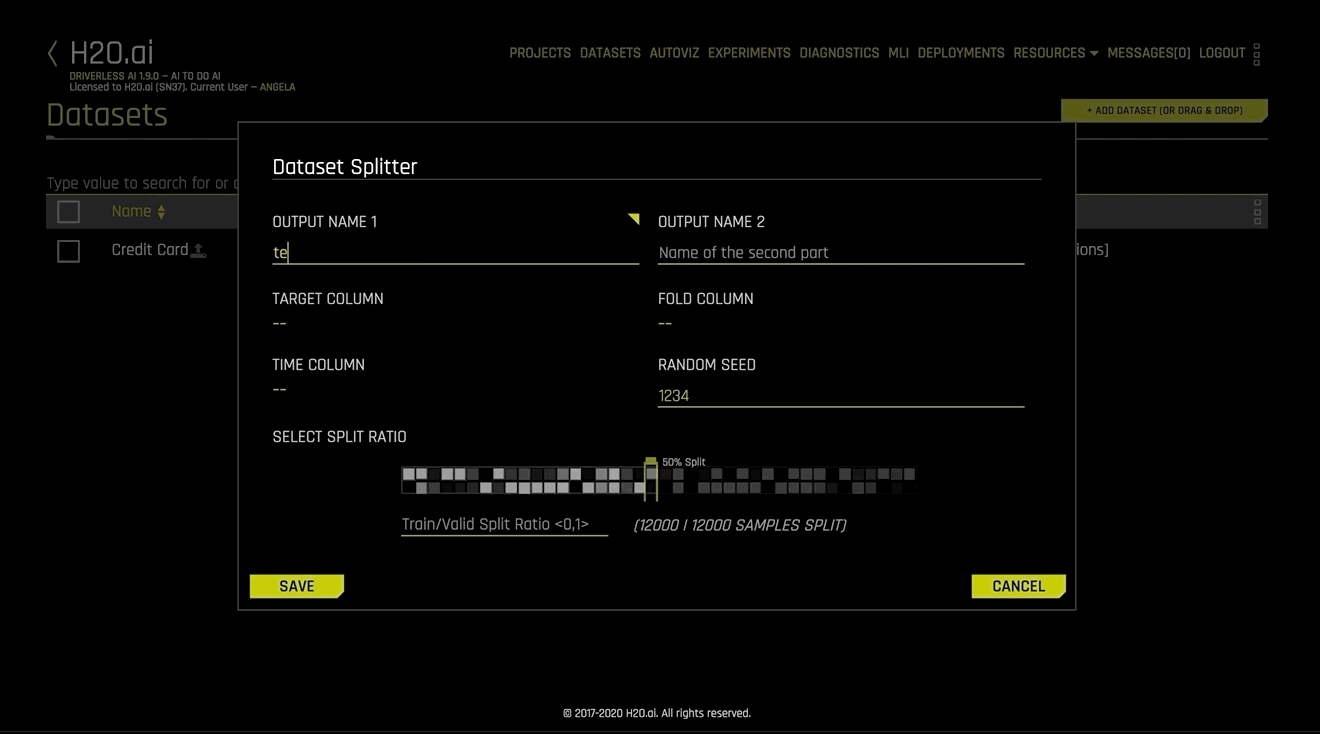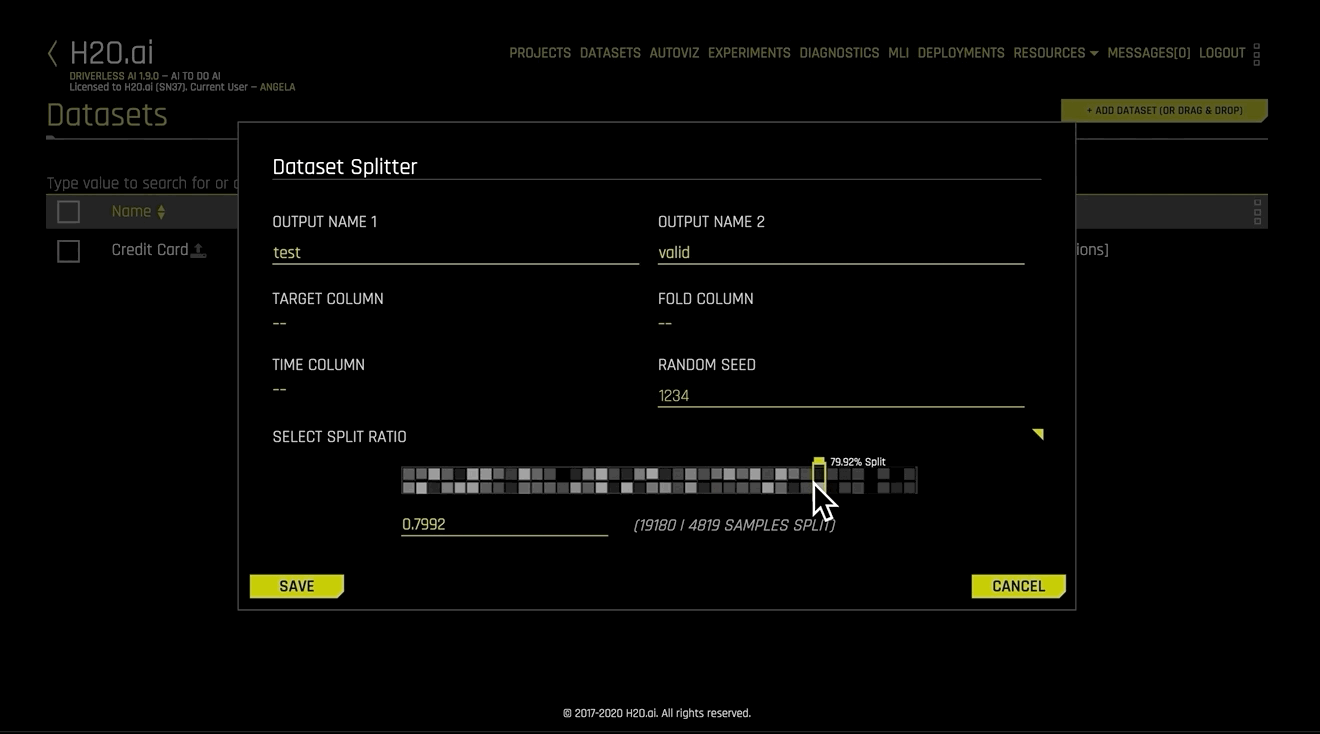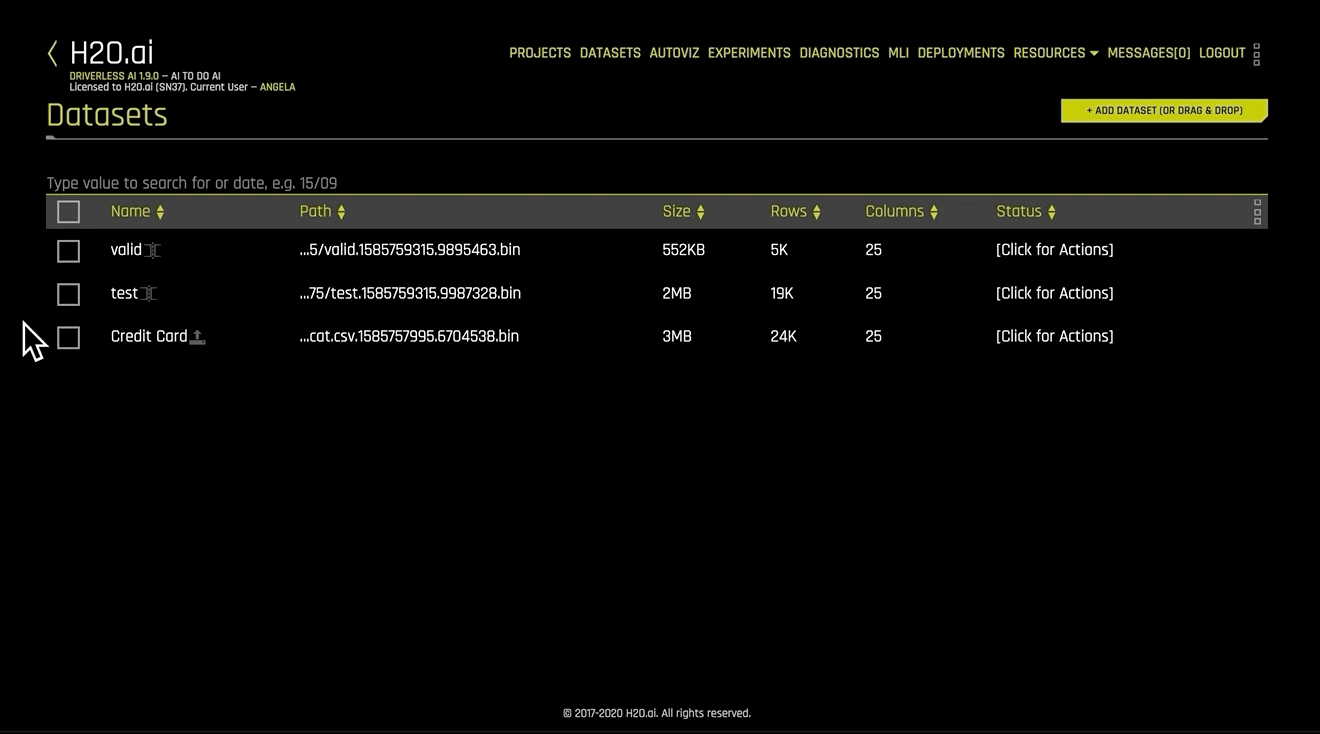
데이터 세트 스플리터 양식이 표시됩니다. 분할의 각 세그먼트에 대해 출력 이름 1 및 출력 이름 2를 지정하십시오(예를 들어 한 세그먼트는 test 로 다른 세그먼트는 validation 으로 지정합니다)
대상 열(계층화된 샘플링의 경우), 폴드 열(동일한 그룹에 속한 행을 함께 유지), 시간 열 및/또는 랜덤 시드(기본값: 1234)를 선택적으로 지정하십시오.
슬라이더를 사용하여 분할 비율을 선택하거나 Train/Valid Split Ratio 필드에 값을 입력하십시오.
완료되면 Save 를 클릭하십시오.
해당 프로세스 완료 시, Datasets 페이지에서 분할된 데이터 세트를 사용할 수 있습니다.