자주 하는 질문¶
H2O Driverless AI는 자동 기계학습을 위한 인공 지능(AI) 플랫폼입니다. Driverless AI는 변수 가공, 모델 검증, 모델 튜닝, 모델 선택 및 모델 배포와 같은 매우 까다로운 데이터 과학 및 기계학습 워크플로우를 자동화합니다. 전문 데이터 사이언티스트와 비교할 수 있는 최고의 예측 accuracy 달성을 목표로 하지만 종단간 자동화 덕분에 훨씬 더 짧은 시간 내에 이를 가능케 합니다. 또한, Driverless AI는 자동 시각화 및 MLI(기계학습 해석 가능성)를 제공합니다. 특히 규제를 받는 산업군에서는 모델 투명성과 설명이 예측 성능만큼 중요합니다. 모델링 파이프라인(변수 가공 및 모델)은 Python 모듈 및 Java 독립형 스코어링 아티팩트 모두로 내보내집니다(근사치 없는 완전한 충실도로).
본 섹션에서는 자주 하는 질문에 대한 답변을 제공합니다. Driverless AI 사용에 대한 추가 질문이 있는 경우 http://stackoverflow.com/questions/tagged/driverless-ai 에서 driverless-ai 태그를 사용해서 Stack Overflow에 게시하십시오. #driverlessai 채널의 H2O.ai Community Slack workspace 에 질문을 게시할 수도 있습니다. H2O.ai Community Slack workspace에 등록하지 않은 경우 https://www.h2o.ai/community/ 에서 등록하십시오.
General
Installation/Upgrade/Authentication
설치 중에 《package dai-<version>.x86_64 does not verify: no digest》 오류가 발생하는 이유는 무엇인가요?
《Must have exactly one OpenCL platform 〈NVIDIA CUDA〉》 오류가 발생했습니다. 어떻게 고칠 수 있나요?
Data
Connectors
JDBC 연결 선택 시도 시, ClassNotFoundException 오류가 발생합니다. 어떻게 해야 하나요?
I get a 《Permission Denied》 error during Hive import. How do I fix this?
Recipes
Experiments
Driverless AI는 범주형 변수를 어떻게 처리하나요? 정수 열을 실제 범주형으로 처리해야 한다면 어떻게 되나요?
학습 데이터 세트에서 여러 열을 삭제하면 Driverless AI는 테스트 데이터 세트에서 동일한 열을 삭제해야 한다는 것을 알게 되나요?
서로 다른 시드를 사용해서 다수의 실험 실행 시, 실험 목록 페이지에서 디스크 상에 서로 다른 점수, 런타임 및 크기가 표시되는 이유는 무엇인가요?
Feature Transformations
Predictions
Deployment
Time Series
time series 문제에 대해 왜 검증 데이터 세트를 지정할 수 없나요? time series 문제에 대한 테스트 세트를 보는 이유는 무엇인가요
학습 및 테스트 사이의 gap이 중요한 이유는 무엇인가요? 테스트 세트에 lag 특성을 생성하기 때문인가요?
내 월마트 데이터 세트에서 모든 매장은 주 단위로 데이터를 제공했지만, 한 상점은 일 단위로 데이터를 제공했다고 가정합니다. Driverless AI는 어떻게 처리하나요?
Logging
일반¶
How is Driverless AI different than any other black box ML algorithm?
Driverless AI는 시스템이 만드는 모든 예측에 대한 사유 코드의 생성을 포함하여 블랙 박스 모델 해석을 위해 많은 테크닉(일부 예전 테크닉 및 일부 첨단 테크닉)을 사용합니다. 우리는 또한 이러한 테크닉에 관해 설명하는 수많은 오픈 소스 코드 예제 및 무료 출판물을 제작했습니다. 해당 리소스에 대한 링크 및 해석 가능성 기술에 관한 자료는 아래 목록을 참조하십시오.
오픈 소스 해석 가능성 예제:
무료 기계학습 해석 가능성 출판물:
Driverless AI에 already 포함된 기계학습 테크닉
Tree-기반 변수 중요도: https://web.stanford.edu/~hastie/ElemStatLearn/printings/ESLII_print12.pdf
Partial Dependence: https://web.stanford.edu/~hastie/ElemStatLearn/printings/ESLII_print12.pdf
LIME: http://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf
LOCO: http://www.stat.cmu.edu/~ryantibs/papers/conformal.pdf
대리 모델:
How often do new versions come out?
새로운 주요 Driverless AI 출시 빈도는 지금까지 대략 매 2개월이었습니다.
설치/업그레이드/인증¶
사용자 이름과 비밀번호는 어떻게 바꾸나요?
사용자 이름 및 비밀번호는 귀하가 생성한 실험과 연결되어 있습니다. 예를 들어, 사용자 이름/비밀번호를 megan/megan을 사용해서 로그인하여 실험을 시작하는 경우, 해당 실험을 확인하려면 같은 사용자 이름 및 비밀번호로 재로그인하십시오. 그러나 사용자 이름 및 비밀번호가 Driverless AI에 대한 액세스를 제한하지는 않습니다. 새로운 사용자 이름 및 비밀번호를 사용하려는 경우, 새로운 사용자 이름 및 비밀번호로 재로그인은 가능하지만 이전 실험은 표시되지 않습니다.
CPU 전용 머신에서 Driverless AI의 실행이 가능한가요?
예, 가능합니다. Driverless AI에는 GPU를 권장하지만, CPU만 가진 컴퓨터에서도 실행이 가능합니다. GPU 및 CPU 시스템에 대한 설치 지침을 참고하십시오. 자세한 내용은 시작하기 전 을 참조하십시오.
최신 버전의 Driverless AI로 업그레이드하려면 어떻게 해야 하나요?
업그레이드 지침은 사용자 환경에 따라 달라집니다. 귀하의 사용자 환경에 맞는 설치 섹션을 참조하십시오. 해당 섹션에 업그레이드 지침이 포함되어 있습니다.
Driverless AI는 어떤 종류의 인증을 지원하나요?
Driverless AI는 클라이언트 인증서, LDAP, 로컬, mTLS, OpenID, none 및 검증되지 않은(기본값) 인증을 지원합니다. config.toml 파일에서 적절한 환경 변수를 설정하거나 또는 Driverless AI 시작 시, 환경 변수의 지정을 통해 구성이 가능합니다. 자세한 내용은 인증 방법 를 참조하십시오.
GPU 시스템 재부팅 시마다 자동으로 퍼시스턴스를 켜려면 어떻게 해야 하나요?
GPU 머신의 경우, 재부팅 시마다
sudo nvidia-persistenced --user dai명령을 실행하여 퍼시스턴스를 활성화할 수 있습니다. systemd를 포함한 시스템의 경우 nvidia-persistenced.service에서--no-persistence-mode플래그를 제거하여 재부팅할 때마다 퍼시스턴스를 자동으로 활성화할 수 있습니다. 아래 단계를 실행하기 전에, 다음을 검토하고 자세한 정보를 확인하십시오.
https://docs.nvidia.com/deploy/driver-persistence/index.html#persistence-daemon
https://docs.nvidia.com/deploy/driver-persistence/index.html#installation
다음을 실행하여 nvidia-persistenced.service를 중지하십시오.
sudo systemctl stop nvidia-persistenced.service
/lib/systemd/system/nvidia-persistenced.service 파일을 여십시오. 해당 파일에는 《ExecStart=/usr/bin/nvidia-persistenced –user nvidia-persistenced –no-persistence-mode –verbose》 줄이 포함됩니다.
해당 줄에서
--no-persistence-mode플래그를 제거하면 다음과 같이 읽힙니다.ExecStart=/usr/bin/nvidia-persistenced --user nvidia-persistenced --verbose
다음을 명령을 실행하여 nvidia-persistenced.service를 시작하십시오.
sudo systemctl start nvidia-persistenced.service
12345가 아닌 다른 포트에서 Driverless AI를 시작하려면 어떻게 해야 하나요?
Docker에서 Driverless AI 시작 시,
-p옵션은 Driverless AI가 실행될 포트를 지정해줍니다. 12345 이외의 포트에서 실행해야 할 경우 시작 스크립트에서 해당 옵션을 변경하십시오. 다음 예제는 포트 22345에서 실행하는 방법에 관해 설명합니다.(필요 시nvidia-docker run을docker-run으로 변경합니다.) priviliged ports will require root access 를 기억하십시오.nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ -u `id -u`:`id -g` \ -p 22345:12345 \ -v `pwd`/data:/data \ -v `pwd`/log:/log \ -v `pwd`/license:/license \ -v `pwd`/tmp:/tmp \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx12345 이외의 포트에서 실행하기 위해서는 config.toml 파일에서 포트 값을 업데이트하십시오. 다음 예제는 포트 22345에서 Driverless AI를 실행하는 방법을 보여줍니다. priviliged ports will require root access 를 기억하십시오.
# Export the Driverless AI config.toml file (or add it to ~/.bashrc) export DRIVERLESS_AI_CONFIG_FILE=“/config/config.toml” # IP address and port for Driverless AI HTTP server. ip = "127.0.0.1" port = 22345Driverless AI 재시작 시, 이 업데이트된 구성 파일을 지정합니다.
Driverless AI에서 TLS/SSL을 설정할 수 있나요?
예, Driverless AI는 HTTPS/TLS/SSL을 설정할 수 있게 해주는 구성 옵션을 제공합니다. 자체 SSL 인증서가 필요하거나 직접 서명한 인증서를 생성할 수도 있습니다.
Driverless AI 서버에서 HTTPS/TLS/SSL을 활성화하려면 config.toml 파일에 다음을 추가하십시오.
enable_https = true ssl_key_file = "/etc/dai/private_key.pem" ssl_crt_file = "/etc/dai/cert.pem"아래 명령을 사용하여 테스트에 대한 직접 서명한 인증서를 만들 수 있습니다.
umask 077 openssl req -x509 -newkey rsa:4096 -keyout private_key.pem -out cert.pem -days 20 -nodes -subj '/O=Driverless AI' sudo chown dai:dai cert.pem private_key.pem sudo mv cert.pem private_key.pem /etc/dai특정 버전의 TLS/SSL을 구성하려면 config.toml 파일에서 다음 설정을 활성화하거나 비활성화하십시오.
ssl_no_sslv2 = true ssl_no_sslv3 = true ssl_no_tlsv1 = true ssl_no_tlsv1_1 = true ssl_no_tlsv1_2 = false ssl_no_tlsv1_3 = false
AWS에서 Driverless AI에 TLS/SSL을 설정할 수 있나요?
예, AWS 환경에서 실행되는 Driverless AI 상에 HTTPS/TLS/SSL을 설정할 수 있습니다. HTTPS/TLS/SSL은 호스트 머신에서 구성되어야 하고, 필요한 포트는 AWS 측에서 열려야 합니다. 자체 TLS/SSL 인증서가 필요하거나 직접 서명한 인증서를 만들 수 있습니다.
다음은 /etc/nginx/에 위치한 키를 사용하여 컨테이너 12345의 포트에 대한 프록시 패스를 통해 HTTPS를 구성하는 방법에 관해 설명하는 매우 간단한 예제입니다. <server_name>를(을) 서버 이름으로 바꾸십시오.
server { listen 80; return 301 https://$host$request_uri; } server { listen 443; # Specify your server name here server_name <server_name>; ssl_certificate /etc/nginx/cert.crt; ssl_certificate_key /etc/nginx/cert.key; ssl on; ssl_session_cache builtin:1000 shared:SSL:10m; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers HIGH:!aNULL:!eNULL:!EXPORT:!CAMELLIA:!DES:!MD5:!PSK:!RC4; ssl_prefer_server_ciphers on; access_log /var/log/nginx/dai.access.log; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; # Fix the “It appears that your reverse proxy set up is broken" error. proxy_pass http://localhost:12345; proxy_read_timeout 90; # Specify your server name for the redirect proxy_redirect http://localhost:12345 https://<server_name>; } }Ubuntu 16.04의 Nginx용 SSL에 관한 더 자세한 내용은 https://www.digitalocean.com/community/tutorials/how-to-create-a-self-signed-ssl-certificate-for-nginx-in-ubuntu-16-04 에서 확인하십시오.
설치 중에 《package dai-<version>.x86_64 does not verify: no digest》 오류가 발생했습니다. 어떻게 해결해야 하나요?
4.11.3보다 최신 RPM 버전을 사용하여 rpm을 설치하면 《package dai-<version>.x86_64 does not verify: no digest》 오류가 발생합니다. 다음을 실행하여
<version>를(을) DAI 버전으로 대체하여 해결할 수 있습니다.rpm --nodigest -i dai-<version>.x86_64.rpm
《Must have exactly one OpenCL platform 〈NVIDIA CUDA〉》 오류가 발생했습니다. 어떻게 해야 하나요?
서버 시간에 opencl 오류 관련 문제 발생 시, 다음 메시지가 표시될 수 있습니다.
2018-11-08 14:26:15,341 C: D:452.2GB M:246.0GB 21603 ERROR : Must have exactly one OpenCL platform 'NVIDIA CUDA', but got: Platform #0: Clover Platform #1: NVIDIA CUDA +-- Device #0: GeForce GTX 1080 Ti +-- Device #1: GeForce GTX 1080 Ti +-- Device #2: GeForce GTX 1080 Ti Uninstall all but 'NVIDIA CUDA' platform.Ubuntu의 경우, 솔루션으로 다음을 실행하십시오.
sudo apt-get remove mesa-opencl-icd
다수의 사용자가 단일 Driverless AI 인스턴스를 공유할 수 있나요?
Driverless AI는 여러 사용자를 지원하며 Driverless AI는 단일 지정 사용자마다 라이선스가 부여됩니다. 따라서 서로 다른 사용자가 동시에 실험을 실행하려면 별도의 라이선스가 필요합니다. Driverless AI는 제공된 GPU를 관리하고 서로 다른 사용자의 여러 실험이 동시에 안전하게 실행되고 서로 간섭되지 않도록 합니다. 따라서 두 명의 라이선스를 가진 사용자가 서로 다른 라이선스를 통해 로그인하면 이 두 명의 사용자는 다른 사람의 실험을 볼 수 없습니다. 마찬가지로 라이선스를 보유한 사용자가 다른 라이선스를 사용하여 로그인하는 경우 해당 사용자는 이전에 수행했던 실험을 볼 수 없습니다.
예, 단일 GPU 박스에 다수의 사용자를 할당할 수 있습니다. 예를 들어, 4개의 GPU를 포함한 단일 박스는 User1에 2개의 GPU가 있고 User2에 다른 2개의 GPU가 있는 것으로 할당할 수 있습니다. 이는 동일한 서버에서 두 개의 분리된 Driverless AI 인스턴스를 실행하여 수행할 수 있습니다.
Driverless AI에 특정 GPU를 할당하는 두 가지 방법이 있습니다. 그리고 4개의 GPU(2명의 사용자에게 할당된 2개의 GPU)를 포함한 시나리오에서 이 두 가지 옵션 모두 각각의 Docker 컨테이너가 오직 2개의 GPU만 확인할 수 있도록 허용합니다.
CUDA_VISIBLE_DEVICES환경 변수를 사용하십시오. Docker 배포의 경우,-e CUDA_VISIBLE_DEVICES="0,1"을nvidia-docker run명령에 패스하는 것으로 변환합니다.
nvidia-docker run명령의 시작부에NV_GPU옵션을 패스합니다(아래 예제 참조).#Team 1 NV_GPU='0,1' nvidia-docker run --pid=host --init --rm --shm-size=256m -u id -u:id -g -p port-to-team:12345 -e DRIVERLESS_AI_CONFIG_FILE="/config/config.toml" -v /data:/data -v /log:/log -v /license:/license -v /tmp:/tmp -v /config:/config h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx #Team 2 NV_GPU='0,1' nvidia-docker run --pid=host --init --rm --shm-size=256m -u id -u:id -g -p port-to-team:12345 -e DRIVERLESS_AI_CONFIG_FILE="/config/config.toml" -v /data:/data -v /log:/log -v /license:/license -v /tmp:/tmp -v /config:/config h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx하지만 Driverless AI 인스턴스는 할당된 GPU를 완전히 활용하고 공유하지 않을 것으로 기대합니다. 다른 Driverless AI 인스턴스 또는 실행 중인 다른 프로그램과 GPU 공유 시, 메모리 부족이 발생할 수 있습니다.
Driverless AI 사용자 목록 검색은 어떻게 하나요?
사용자 목록은 Python client를 통해 검색할 수 있습니다.
h2o = Client(address='http://<client_url>:12345', username='<username>', password='<password>') h2o.get_users()
Ubuntu 18/RHEL 7.6 상의 ``Segmentation fault (core dumped)`` 메시지에서 Driverless AI 시작이 실패합니다. 어떻게 해결하나요?
해당 문제는 〈〉NotoColorEmoji.ttf 〈〉 글꼴로 인해 발생하며, Python matplotlib 라이브러리에서 처리할 수 없습니다. 해결하려면 글꼴 이름을 변경하여 비활성화하면 됩니다(fontconfig를 사용하지 마십시오. 이것은 matplotlib에서 무시됩니다). 다음을 통해 실행해야 할 명령을 인쇄합니다.
sudo find / -name "NotoColorEmoji.ttf" 2>/dev/null | xargs -I{} echo sudo mv {} {}.backup
Driverless AI가 지원하는 Linux 시스템은 무엇인가요?
지원되는 Linux 시스템에는 x86_64 RHEL 7, RHEL 8, CentOS 7 및 CentOS 8가 있습니다.
데이터¶
데이터 세트의 파일 크기 제한이 있나요?
GBM의 경우, 데이터 세트의 파일 크기는 시스템상의 군집 CPU 또는 GPU 메모리에 의해 제한되지만, TensorFlow 스트리밍을 통해 임의의 큰 데이터 세트로 스트리밍하는 것과 같이 실험에 더 많은 데이터를 가져오기 위해 지속해서 최적화합니다.
UTF-8 인코딩을 사용하는 CSV 파일을 Excel로 가져오려면 어떻게 해야 하나요?
Excel에서 UTF-8 인코딩을 사용하는 CSV 파일을 제대로 확인하려면 바이트 순서 표시(BOM)가 필요합니다. 데이터 테이블을 사용하여 CSV 파일 작성 시, BOM 사용법에 관한 더 자세한 내용은 다음 FAQ entry 를 참조하십시오.
데이터 테이블을 사용하여 CSV 파일 작성 시 바이트 순서 표시를 사용할 수 있나요?
예, Driverless AI 시작 시, config.toml 파일에서
datatable_bom_csv의 활성화를 통해 데이터 테이블을 포함한 CSV 파일을 작성할 때 바이트 순서 표시(BOM)를 사용할 수 있습니다.Note: Excel에서 UTF-8 인코딩을 지원하려면 BOM을 사용해야 합니다.
어떤 버전의 Longhorn이 Driverless AI에 의해 지원되나요?
Driverless AI는 Longhorn v1.1.0 이상을 지원합니다.
Driverless AI에서 변형된 테스트 데이터 세트를 다운로드할 수 있나요?
예, 변형된 테스트 데이터 세트는 Driverless AI에서 다운로드할 수 있습니다. 이렇게 하려면 완료된 실험 페이지에서 Model Actions > Transform Dataset 를 클릭한 후 변형에 사용할 학습 및 테스트 데이터 세트를 모두 지정합니다. 이 프로세스가 통합되면 변형된 테스트 데이터 세트를 다운로드할 수 있습니다.
커넥터¶
Windows에서 데이터 커넥터 사용 시, 폴더를 파일로 가져올 수 없는 이유는 무엇인가요?
Windows에서 데이터 커넥터를 통해 Import Folder as File 옵션을 사용할 때 폴더에 파일 확장자가 없는 파일이 포함되어 있으면 가져오기에 실패합니다. 예를 들어, 폴더에 file1.csv, file2.csv, file3.csv 및 _SUCCESS 파일이 포함되어 있는 경우, _SUCCESS 파일의 존재 때문에 해당 함수는 실패합니다.
이것은 데이터가
-v /path/to/windows/filesystem:/path/in/docker/container플래그를 통해 Windows 파일 시스템에서 Docker 컨테이너로 마운트된 볼륨으로부터 가져올 때만 발생합니다. 해당 오류는 파일 확장자가 없는 파일이 Windows 및 Docker 컨테이너(CentOS Linux)에서 처리되는 방식에 차이가 있기 때문에 발생합니다.
JDBC 연결 선택 시, ClassNotFoundException 오류가 발생합니다. 어떻게 해야 하나요
JDBC jar 파일을 저장하는 폴더는 dai 프로세스 사용자가 보거나 읽을 수 있어야 합니다.
Oracle에서 JDBC jar 파일 다운로드 시, 다음 명령을 사용하여 패키지를 해제할 수 있는 tar.gz 파일을 제공받을 수 있습니다.
tar --no-same-permissions --no-same-owner -xzvf <my-jdbc-driver.tar>.gz또는 다음을 실행하여 파일에 대한 권한이 일반적으로 올바른지 확인할 수 있습니다.
chmod -R o+rx /path/to/folder_containing_jar_file마지막으로 사용 권한만 확인하려면
ls -altr명령을 사용하고 사용 권한 출력에서 최종 3개의 값을 확인하십시오.
하이브에 연결 시도 시, ‘org.datanucleus.exceptions.NucleusUserException: CLASSPATH 및 플러그인 사양 오류를 확인하십시오’ 메시지가 뜹니다. 어떻게 해야 하나요?
Hive-site.xml이/etc/hadoop/conf가 아닌/etc/hive/conf에 구성되어 있는지 확인하십시오.
Hive를 가져오는 중 I》Permission Denied》 오류가 발생합니다.어떻게 해결할 수 있나요?
다음 오류가 표시되면 Driverless AI 인스턴스가 파일 시스템 사용 권한 제한 때문에 임시 Hive 폴더를 생성하지 못할 수 있습니다.
ERROR HiveAgent: Error during execution of query: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied; org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied;이 오류를 수정하려면 다음 이름-값 쌍을
hive-site.xml파일에 추가하여 Driverless AI가 액세스할 수 있는 위치(즉, Driverless AI/tmp디렉터리)를 지정하십시오.<property> <name>hive.exec.local.scratchdir</name> <value>/path/to/dai/tmp</value> </property>
레시피¶
** H2O의 사용자 정의 레시피는 어디에서 검색하나요? **
H2O 사용자 저의 레시피는 공식 Recipes for Driverless AI repository 에서 획득할 수 있습니다.
나만의 사용자 정의 레시피를 생성하려면 어떻게 해야 하나요?
사용자 정의 레시피의 생성 방법에 관한 더 자세한 내용은 How to Write a Recipe 가이드를 참조하십시오.
사용자 정의 레시피를 사용하는 실험에 MOJO가 지원되나요?
대부분의 경우에 MOJO는 사용자 정의 레시피에 사용할 수 없습니다. 레시피가 간단하지 않은 경우 MOJO 생성은 추가 MOJO 런타임 지원을 통해서만 가능합니다. 사용자 정의 레시피에 대한 MOJO 생성에 관한 더 자세한 내용은 support@h2o.ai 에 문의하십시오( Note: Python Scoring Pipeline은 사용자 정의 레시피를 완벽하게 지원합니다).
airgapped 설치에서 BYOR를 어떻게 사용할 수 있나요?
Driverless AI 환경이 인터넷이 연결되지 않아 GitHub에서 Driverless AI의 《Bring Your Own Recipes》 에 액세스할 수 없을 때는 H2O support 에 문의하십시오. 레시피에 액세스할 수 있도록 저희가 도와드릴 수 있습니다.
실험¶
실험을 실행하려면 Driverless AI에 얼마나 많은 메모리가 필요한가요?
현재 Driverless AI의 시스템 메모리에 있는 데이터의 약 10배가 필요합니다.
Driverless AI가 처리할 수 있는 열은 몇 개인가요?
Driverless AI는 10,000개의 열을 포함한 데이터 세트에서 테스트되었습니다. 광범위한 데이터에 대한 실험 실행 시, Driverless AI는 메모리 부족 여부를 자동으로 확인하고, 메모리 부족 시 메모리에 적합할 때까지 특성의 수를 줄입니다. 이것으로 인해 모델이 더 안 좋아질 수 있지만, 데이터가 광범위해서 Driverless AI가 충돌해서는 안 됩니다.
대용량의 데이터를 가지고 있는 경우 Driverless AI를 어떻게 사용해야 하나요?
Driverless AI는 대량의 데이터 세트를 즉시 처리할 수 있습니다. 굉장히 큰 데이터 세트(100억 개 이상의 행 x 열)의 경우에는 Driverless AI용 데이터의 샘플링을 권장합니다. Driverless AI의 목표는 원시 데이터에 대한 몇 가지 모델을 학습시키는 것이 아니라 다양한 특성 및 모델을 사용해서 최상의 모델링 파이프라인을 찾는 것임을 명심하십시오(이 경우에는 H2O-3이 이상적임).
대량의 데이터 세트의 경우에는 다음의 단계가 권장됩니다.
권장 accuracy/시간/해석 가능성 설정, 특히 accuracy <= 7을 사용해서 우선 실행하십시오.
accuracy 설정을 점진적으로 7로 상승시키고, accuracy<= 7에서 실행시키고 관측한 후에만 accuracy 9 또는 10을 선택하십시오.
Driverless AI는 ID 열을 어떻게 감지하나요?
ID 열 논리는 다음 중 하나입니다.
해당 열의 이름은 정확히 〈id〉, 〈Id〉, 〈ID’ 또는 〈iD’입니다.
해당 열은 많은 수의 고유값을 포함하고 있습니다(config.toml 파일의
max_relative_cardinality초과 또는 Max. allowed fraction of uniques for integer and categorical cols).
Driverless AI는 결츨값/null을 포함한 데이터를 처리할 수 있나요?
예, Driverless AI로 가져온 데이터는 결측값을 포함할 수 있습니다. 변수 가공은 결측값을 완벽하게 인식하고 결측값은 정보(특수 범주 레벨 또는 특수 번호로)로 처리됩니다. 예를 들어, 대상 인코딩의 경우 특정 특성이 누락된 행은 같은 그룹에 속합니다. 그룹화된 범주형 열에 대해 숫자 열의 집계가 계산되는 범주형 인코딩의 경우, 결측값이 유지됩니다. 평균을 계산하기 위한 공식은 비결측값의 합계를 모든 비결측값의 개수로 나누는 것입니다. 클러스터링의 경우, 결측값을 대체합니다. 그리고 빈도 인코딩의 경우, 특정 특성이 누락된 행 수를 카운트합니다.
대체 전략은 다음과 같습니다.
XGBoost/LightGBM은 결측값 대체가 필요치 않고, 사용자가 데이터에 관해 실질적으로 제대로 이해하고 있지 않으면 특정 기타 전략으로 인해 성능이 저하될 수 있습니다.
Driverless AI는 GLM 평균을 사용하여 결측값을 자동으로 대체합니다.
Driverless AI는 config.toml 파일:
tf_nan_impute_value post-normalization에서 TensorFlow에 대한 대체 설정을 제공합니다. 해당 옵션을 0으로 설정하면, 결측값이 대체됩니다. 예를 들어, +5로 설정 시 해당 분포 외부에 5개의 표준 편차가 지정됩니다. TensorFlow의 기본값은 -5이며, 이를 통해 TensorFlow가 NA를 결측값으로 처리하도록 지정합니다. 평균이 더 좋은 경우 0을 지정하는 것을 권장합니다.더 자세한 정보는 Missing and Unseen Values Handling 섹션에서 확인하십시오.
Driverless AI는 범주형 변수를 어떻게 처리하나요? 정수 열을 실제 범주 형으로 처리해야 한다면 어떻게 되나요?
열이 문자열 값을 포함하는 경우, Driverless AI는 이것을 범주 특성으로 처리합니다. Driverless AI가 범주형 변수를 숫자로 변환하는 방법은 다양합니다. 여기에는 다음이 포함됩니다.
원-핫 인코딩: 각각의 값에 대한 더미 변수 생성
빈도 인코딩: 범주를 데이터에 얼마나 자주 보여지는지로 대체
대상 인코딩: 범주를 평균 대상 값으로 대체(과적합 방지를 위한 추가 단계가 포함됨)
증거 가중치: 각 범주에 대한 증거 가중치를 계산(http://ucanalytics.com/blogs/information-value-and-weight-of-evidencebanking-case/)
Driverless AI는 열을 나타내기 위해 다양한 방법을 시도하고 어떤 표현이 가장 좋은지 결정합니다.
열이 정수를 포함한 경우, Driverless AI는 열을 범주형 열 및 숫자 열로 처리합니다. 고유값의 수가 50개 미만일 때는 정수 열을 범주 및 숫자로 처리합니다.
이것은 config.toml 파일에서 구성이 가능합니다.
# Whether to treat some numerical features as categorical # For instance, sometimes an integer column may not represent a numerical feature but # represents different numerical codes instead. num_as_cat = true # Max number of unique values for integer/real columns to be treated as categoricals (test applies to first statistical_threshold_data_size_small rows only) max_int_as_cat_uniques = 50( Note: 또한, Driverless AI는 벤포드의 법칙을 사용하여 모든 숫자 열의 분포가 일반적인 수치 데이터의 분포와 크게 다른지의 여부를 확인합니다. 해당 열 분포가 벤포드의 법칙을 따르지 않는 경우에도, 50개 이상의 고유값이 있어도 범주형으로 처리하려고 시도합니다.)
** outliers는 어떻게 처리되나요? **
Outliers는 데이터에서 제거되지 않습니다. 대신 Driverless AI는 outliers를 사용해서 데이터를 나타내는 최선의 방법을 찾습니다. 예를 들어, Driverless AI는 변수를 outliers를 사용해서 비닝하면 성능이 향상된다는 것을 알 수 있습니다.
대상 열의 경우, Driverless AI가 먼저 해당 열의 최고의 표현을 결정합니다. outliers를 포함한 대상 열의 경우, 열의 로그를 예측하는 것이 가장 좋습니다.
학습 데이터 세트에서 다수의 열을 삭제하면, Driverless AI도 테스트 데이터 세트에서 동일한 열을 삭제해야 한다는 것을 이해하고 있나요?
학습 데이터 세트에서 열을 삭제하면 Driverless AI는 검증 및 테스트 데이터 세트에 대해 동일한 작업을 수행합니다(열이 있는 경우). 이러한 열은 특성이 생성되지 않으므로 불필요합니다.
Driverless AI는 숫자 변수를 범주형 변수로 다루나요?
특정한 경우에는 그렇습니다. 설치를 위한 config.toml 파일에서
num_as_cat변수를false로 설정하여 이 행동의 방지가 가능합니다.Numeric to Categorical Target Encoding Transformer,Numeric To Categorical Weight of Evidence Transformer및 설치를 위한 config.toml 파일에서 해당 gene을 제외하여 이 행동을 보다 정밀하게 제어할 수 있습니다. config.toml 파일에 관한 자세한 내용은 config.toml 파일 사용 섹션을 참조하십시오.
Driverless AI에는 무슨 알고리즘이 사용되나요?
변수는 grouping, 집계 및 조인을 기초로 한 가장 정교한 대상 인코딩 및 우도측정을 포함하여 Kaggle-winning statistical approach의 상표 스택을 사용하여 가공되지만, 선형 모델, 신경망, 클러스터링 및 차원축소 모델과 원-핫 인코딩처럼 다양한 전통적인 접근 방식도 사용합니다.
가공된 변수에 더해, XGBoost (기존 XGBoost 및 〈lossguide〉(LightGBM) 모드 모두), Decision Tree, GLM, TensorFlow (CNN Deeplearning 기반 TensorFlow NLP 레시피 포함), RuleFit, FTRL(Follow the Regularized Leader), Isolation Forest 및 상수 모델을 포함하되 이에 국한되지 않는 정교한 모델이 적합합니다(자세한 내용은 지원되는 알고리즘 를 참조하십시오). 그리고 추가 알고리즘은 Recipes 를 통해 추가할 수 있습니다.
일반적으로 GBM은 최고의 single-shot 알고리즘입니다. 2006년 이래로 부스팅 방법은 이미지 및 사운드의 패턴 인식뿐만 아니라 노이즈 예측 모델링 작업에 가장 정확하다는 것이 입증되었습니다(https://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml06.pdf). XGBoost 및 Kaggle의 등장을 통해 이러한 입지가 더욱 확고해졌습니다.
선택한 알고리즘이 실험 미리보기에 표시되지 않는 이유는 무엇인가요?
Expert Settings > Model 및 Expert Settings > Recipes 를 통해 사용되는 알고리즘 변경 시, 실험 미리보기에서 해당 변경 사항이 적용되지 않는 것을 확인할 수 있습니다. Driverless AI는 데이터 유형(숫자, 범주, 텍스트, 이미지 등) 및 시스템 속성(GPU, 다중 GPU 등)은 물론 상세 설정의 계층 구조를 기반으로 모델 및/또는 레시피의 포함 여부를 결정합니다.
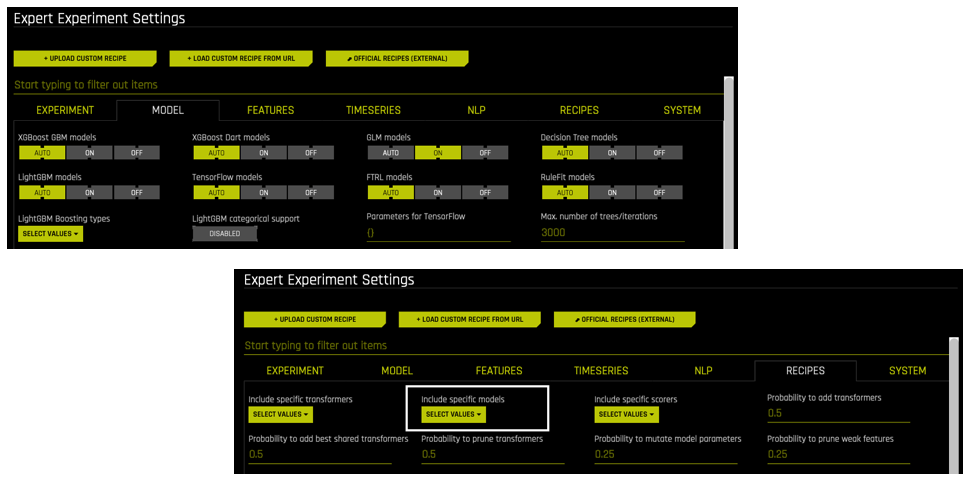
상세 설정에서 알고리즘을 《OFF》로 설정: 실행 시, 상세 설정(예: GLM Models)에서 알고리즘이 꺼져 있으면, 해당 알고리즘이 실험에 포함되지 않습니다.
레시피에 포함되지 않은 알고리즘(BYOR): Include specific models 옵션의 실험에 대해 사용자 정의 레시피로부터 알고리즘이 선택되지 않으면, Expert Settings > Model 페이지에서 동일한 알고리즘이 AUTO 또는 ON으로 설정되어 있는지에 관계없이 해당 알고리즘은 실험에 포함되지 않습니다.
《OFF》로 지정되지 않고 레시피에 포함된 알고리즘: Driverless AI 알고리즘이 《AUTO》 또는 《ON》으로 지정되고, Include specific models 옵션에서 실험을 위해 추가 모델이 선택된 경우, 해당 알고리즘은 실험에 포함될 수도 있고 포함되지 않을 수도 있습니다. Driverless AI는 데이터 및 실험 유형에 따라 사용할 알고리즘을 결정합니다.
어떤 모델이 사용되지 않았는지에 대한 미리보기에서 경고를 표시하려면
show_inapplicable_models_preview = truein config.toml을 설정하십시오.
선택된 트랜스포머가 실험 미리보기에 표시되지 않는 이유는 무엇인가요?
Expert Settings > Transformers 및 Expert Settings > Recipes 를 통해 사용되는 트랜스포머 변경 시, 실험 미리보기에서 해당 변경 사항이 적용되지 않는 것을 확인할 수 있습니다. Driverless AI는 데이터 유형(숫자, 범주, 텍스트, 이미지 등) 및 시스템 속성(GPU, 다중 GPU 등)에 따라 트랜스포머의 사용 여부를 결정합니다.
레시피에 포함되지 않은 트랜스포머(BYOR): Include specific transformers 옵션 실험에 대한 사용자 정의 레시피 트랜스포머를 선택하지 않은 경우, 해당 트랜스포머는 실험에 포함되지 않습니다.
어떤 모델이 사용되지 않았는지에 대한 미리보기에서 경고를 표시하려면
show_inapplicable_transformers_preview = truein config.toml을 설정하십시오.
TensorFlow Neural Networks를 켜고 평가하려면 어떻게 해야 하나요?
신경망은 기본적으로 평가되지 않지만 Driverless AI에서는 고려됩니다. 신경망이 시도되는지 확인하려면 상세 설정에서 TensorFlow를 켜십시오.

TensorFlow를 ON으로 설정하면. 좌측에 실험 미리보기가 변경되고 TensorFlow 모델을 평가할 것이라고 언급하는 것을 확인할 수 있어야 합니다.
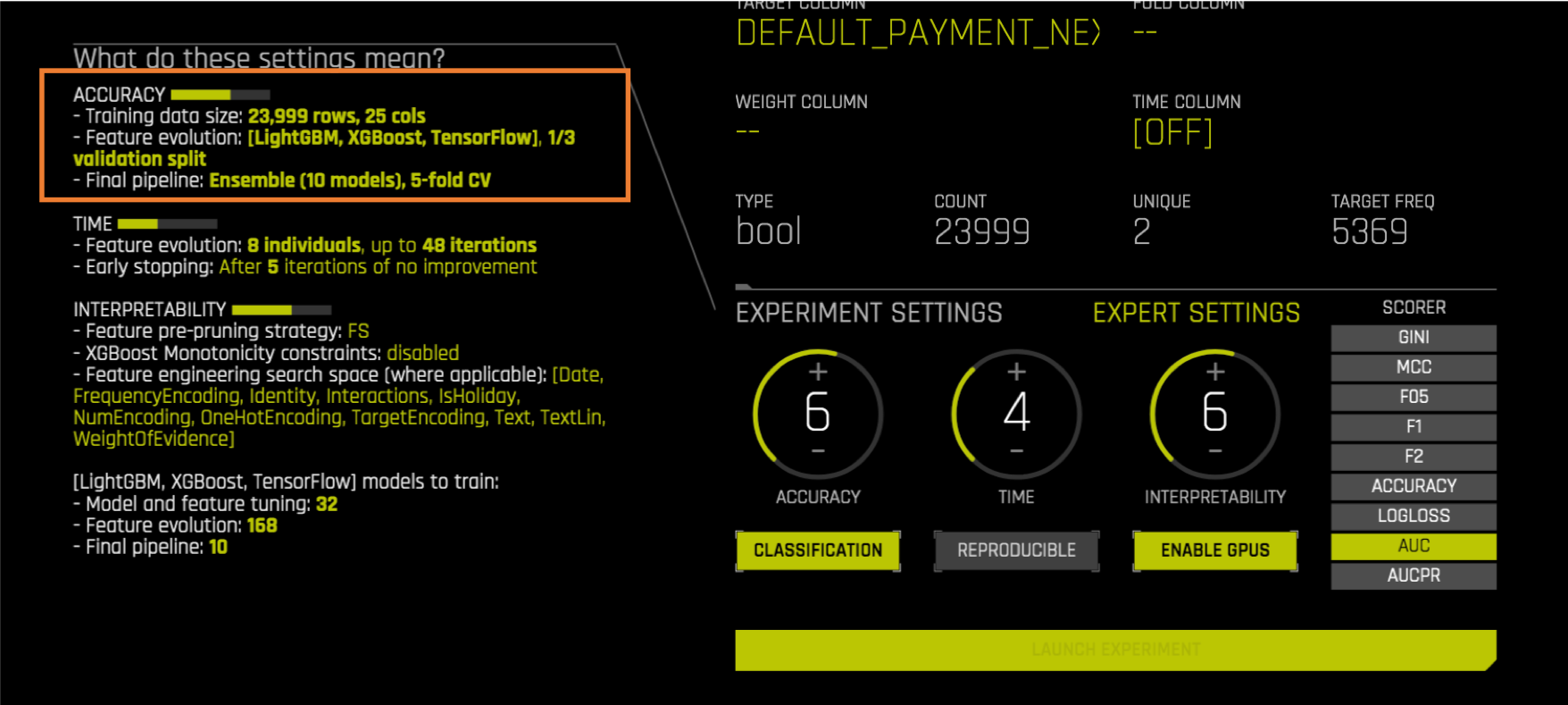
고유값이 5개 이상인 다중 유스케이스가 있는 경우 TensorFlow 신경망 사용을 권장합니다.
Driverless AI는 데이터를 표준화하나요?
Driverless AI는 특정 알고리즘에 대해서는 변수 표준화를 자동으로 수행합니다. 예를 들어, 선형 모델 및 신경망을 사용할 때는 데이터가 자동으로 표준화됩니다. 하지만 decision tree 알고리즘의 경우, 해당 알고리즘이 표준화를 통해 이점을 얻지 못하기 때문에 표준화를 수행하지 않습니다.
XGBoost에서는 어떠한 목적 함수가 사용되나요?
XGBoost에서 사용되는 목적 함수는 다음과 같습니다.
reg:squarederror및 회귀 분석을 위한 사용자 정의 절대 오차 목적 함수분류를 위한
binary:logistic또는multi:softprob선택된 scorer에 따라 목적 함수가 바뀌지는 않습니다. scorer는 매개변수 조정에만 영향을 줍니다. 회귀 분석의 경우 Tweedie, Gamma 및 Poisson 회귀 목표가 지원됩니다.
XGBoost 생성에 관한 더 자세한 정보는 로그 및 모델 요약에서 확인할 수 있고, 둘 다 GUI에서 다운로드하거나 서버의 /tmp/h2oai_experiment_<name>/ 폴더에서 확인할 수 있습니다.
Driverless AI는 내부 또는 외부 검증을 수행하나요?
Driverless AI는 학습 데이터만 제공되는 경우 내부 검증을 수행합니다. 학습 및 검증 데이터가 제공되는 경우에는 외부 검증을 수행합니다. 두 시나리오에서 검증 데이터는 특성 선택뿐만 아니라 모든 매개변수 튜닝(모델 및 특성)에 사용됩니다. 매개변수 튜닝에는 대상 변환, 모델 선택, 변수 가공, 특성 선택, 스태킹 등이 포함됩니다.
구체적으로는,
내부 검증(주어진 학습 데이터만):
데이터가 i.i.d.에 가깝거나 또는 time series 문제일 경우에 이상적임
내부 홀드아웃은 매개변수 튜닝에 사용되며 time series 문제에 대해서는 시간적 인과성을 가지고 있습니다.
accuracy 설정에 따라 단일 홀드아웃 분할에서 5-폴드 CV까지의 전체 스펙트럼을 수행합니다.
학습 데이터 수동 분할이 필요 없습니다.
최종 모델은 학습 데이터에 대한 CV를 사용하여 학습됩니다.
외부 검증(학습 + 검증 데이터가 주어짐)
데이터에 약간의 드리프트가 있고, 검증 세트가 학습 데이터보다 테스트 세트 데이터를 더 잘 모방하는 경우에 이상적임
학습 데이터가 매개변수 튜닝에 사용되지 않기 때문에 학습 도중에 낭비되는 학습 데이터가 없음
검증 데이터는 매개변수 튜닝에만 사용되며 학습 데이터의 일부분이 아님
학습 데이터에 대해서는 명시적으로 과적합을 원하지 않기 때문에 CV가 불가능함
time series 문제에는 허용되지 않음(다음 Time Series FAQ 섹션 참조)
Tip: 매개변수 튜닝(학습 프로세스)에 학습 및 검증 데이터를 모두 사용하기 위해서는 데이터 세트를 함께 연결하고 둘 모두를 “internal validation》 방법을 위한 학습 데이터로 전환하십시오.
Driverless AI는 과적합을 어떻게 방지하나요?
Driverless AI는 과적합 방지를 위해 다양한 검사를 수행합니다. 예를 들어, 특정 변환 중에 Driverless AI는 교차 검증을 사용하여 폴드 외 데이터의 평균을 계산합니다. 또한 Driverless AI는 빌드된 모든 모델에 대해 조기 중지를 수행하여 홀드아웃 데이터 개선이 중단되면 모델 빌드가 중지되도록 합니다. 과적합 방지를 위한 추가 단계에는 i.i.d. 검사 및 변수 가공 중 유출 방지가 포함됩니다.
Driverless AI overfitting protection에 대해 더 자세한 내용을 설명하는 블로그 게시물은 https://www.h2o.ai/blog/driverless-ai-prevents-overfitting-leakage/ 에서 확인하십시오.
Driverless AI는 다중 가설(MH)문제를 어떻게 회피하나요?
Driverless AI는 재사용이 가능한 홀드아웃 테크닉의 변형을 통해 다중 가설 문제를 해결합니다. 자세한 내용은 https://pdfs.semanticscholar.org/25fe/96591144f4af3d8f8f79c95b37f415e5bb75.pdf 를 참조하십시오.
Driverless AI는 어떻게 실험 설정을 제안하나요?
데이터 세트에서 실험 실행 시, 실험 설정(accuracy, 시간 및 해석 가능성)은 Driverless AI에 의해 자동으로 제안됩니다. 예를 들어, Driverless AI는 데이터에 기반하여 accuracy = 7, 시간 = 3, 해석 가능성 = 6의 매개변수를 제안할 수 있습니다.
Driverless AI는 데이터 세트의 열 수 및 행 수를 기반으로 실험 설정을 자동으로 제안합니다. 데이터가 작을 경우, 최상의 처리를 보장하기 위한 설정이 제안됩니다. 데이터가 작으면 Driverless AI가 과적합을 방지하는 설정을 제안하고 전체 데이터 세트가 활용되도록 합니다.
행 수 및 열 수가 각각의 특정 임계값 미만일 경우 다음을 수행합니다.
accuracy가 최대 8까지 증가합니다.
accuracy가 증가하여 교차 검증이 수행됩니다(내부 검증 목적으로 데이터를 《throw away》하지 않습니다).
해석 가능성이 최대 8까지 증가합니다.
해석 가능성 설정이 높을수록 최종 모델의 특성 수가 적습니다.
더 복잡한 특성은 허용되지 않습니다.
이것은 과적합을 방지합니다.
시간이 2로 줄어듭니다.
과적합 방지를 위해 변수 가공의 반복이 줄어듭니다.
해석 가능성과 accuracy를 동일한 숫자로 설정하면 어떻게 되나요?
그에 대한 대답은 현재 해석 가능성이 어떤 특성이 생성되고 어떤 특성이 유지되는지를 통제하냐는 것입니다(또한 위의 해석 가능성 = 6, monotonicity constraints 조건이 XGBoost GBM, XGBoost Dart, LightGBM 및 Decision Tree 모델에서 사용됩니다). accuracy는 Driverless AI가 이러한 특성을 가장 정확한 모델로 만드는 것이 얼마나 어려운지를 나타냅니다.
Driverless AI 실행 시, 사용할 GPU 수를 지정할 수 있나요?
실험 실행 시, 상세 설정을 통해 Driverless AI가 사용할 시작 GPU ID의 지정이 가능합니다. 모델별 그리고 실험별로 사용할 최대 GPU 수를 지정할 수도 있습니다. 자세한 내용은 상세 설정 섹션을 참조하십시오.
Driverless AI에서 가장 간단한 모델은 어떻게 만드나요?
Driverless AI에서 가장 간단한 모델을 만들려면 다음과 같이 실험 설정을 지정하십시오.
accuracy를 1로 설정하십시오. 샘플을 사용하기 때문에 성능이 저하될 수 있습니다. 필요 시, 미리보기에 샘플링이 표시되지 않을 때까지 노브를 조정하십시오.
시간을 1로 설정하십시오.
해석 가능성을 10으로 설정하십시오.
그런 다음, 다음과 같이 상세 설정을 구성하십시오.
GLM을 제외한 모든 알고리즘을 OFF로 돌리십시오.
GLM models 을 ON으로 설정하십시오.
Ensemble level 을 0으로 설정하십시오.
Select target transformation of the target for regression problems 을 Identity로 설정하십시오.
Data distribution shift detection 을 비활성화하십시오.
Target Encoding 을 비활성화하십시오.
또는 Pipeline Building Recipe 를 Compliant로 설정할 수도 있습니다. Compliant는 다음의 실험 및 상세 설정을 자동으로 구성합니다.
해석 가능성 = 10(복잡성을 피하기 위해. 이것은 해석 가능성에 대한 GUI 또는 Python client 설정을 오버라이드합니다.)
enable_glm=〉on’(복잡성을 방지하고 MLI 지원 알고리즘과 호환되도록 Remaing 알고리즘은 〈off〉 되어 있습니다.)
num_as_cat=true: 일부 숫자 특성을 범주형으로 취급하십시오. 예를 들어, 때때로 정수 열은 숫자 특성을 나타내지 않고 대신 다른 숫자 코드를 나타낼 수 있습니다.
fixed_ensemble_level=0: (복잡성 회피를 위해)앙상블을 사용하지 마십시오.
feature_brain_level=0: 특정 브레인이 사용되지 않음(모든 재시작이 동일하도록).
max_feature_interaction_depth=1: 상호 작용 깊이는 1로 설정됩니다(복잡성을 피하기 위해서 다중 특성 상호 작용 없음).
target_transformer=》identity》: 회귀 분석용(복잡성을 피하기 위해).
check_distribution_shift=》off》: 학습, 검증 및 테스트 사이의 분포 이동을 사용하여 특성을 삭제하지 마십시오(미세 조정 없이는 약간 위험함).
내 실험이 갑자기 느려지는 이유는 무엇인가요?
Driverless AI의 통제를 벗어난 호스트 시스템의 변경 때문에 실험이 GPU 사용에서 CPU 사용으로 전환되었을 가능성이 있습니다. 다음 방법 중 하나를 사용해서 이를 확인하십시오.
Driverless AI 실험 페이지로 이동하여 실험의 우측 아래 사분면에 위치한 GPU 사용 탭을 클릭하고 GPU 사용량을 확인하십시오.
터미널에서
nvidia-smi를 실행하여 프로세스가 예상하지 못한 방식으로 GPU 리소스를 사용하는지를 확인하십시오(예: 프로세스가 많은 양의 메모리를 사용하는지 여부).시스템/GPU 메모리가 이전 작업 또는 다른 작업에 사용되고 있는지 또는 이전 작업이 여전히 일부 작업을 실행하고 있는지를 확인하십시오.
시스템에서 자동 NVIDIA 드라이버 업데이트를 확인하고 비활성화하십시오(실험 실행을 방해할 수 있기 때문에).
이러한 종류의 갑작스러운 속도 저하 문제에 대한 일반적인 해결책은 재시작입니다.
Docker를 사용하고 있다면 Docker를 재시작하십시오.
Native 설치 방법을 사용하는 경우
pkill --signal 9 h2oai
Nvidia-smi가 기대한 것처럼 작동하지 않을 경우(예: 드라이버 업데이트 후) 시스템을 재시작하십시오.느려진 실험을 초래할 수 있는 더 많은 ML 관련 문제는 다음과 같습니다.
메모리가 충분하지 않은 시스템에서 높은 accuracy 설정 선택
낮은 해석 가능성 설정 선택(메모리 사용량을 증가시키는 더 변수 가공으로 이어질 수 있음)
많은 열을 포함한 데이터 세트 사용(> 500)
대상 클래스가 많을 때(> 5) GBM 모델을 사용하여 다중 클래스 분류 수행
서로 다른 시드를 사용해서 다수의 실험 실행 시, 실험 목록 페이지에서 디스크 상에 서로 다른 점수, 런타임 및 크기가 표시되는 이유는 무엇인가요?
시드를 제외한 모든 같은 설정을 사용해서 다양한 실험을 실행할 때 특성 브레인 레벨이 0보다 클 경우, 디스크 상의 모델, 특성, 타이밍 및 크기가 달라질 수 있다는 것을 기억해야 합니다(기본값=2). 이러한 변형은 상세 설정 또는 config.toml 파일에서 Feature Brain Level 을 0으로 설정하여 비활성화할 수 있습니다.
또한, 각각의 실험에 다른 시드를 사용할 때는 최상의 특성 및 모델 매개변수를 검색하는 유전 알고리즘의 무작위성으로 인해 각각의 실험이 달라질 수 있습니다. Reproducible 이 동일한 시드를 사용하여 설정되고 특성 브레인 레벨이 0인 경우에만 사용자는 동일한 결과를 기대할 수 있습니다. 다른 시드가 설정되면 디스크 상의 모델, 특성, 타이밍 및 크기가 모두 해당 실험에 대해 선택한 제약 조건 내에서 달라질 수 있습니다(즉, accuracy, 시간, 해석 가능성, 상세 설정 등이 모두 결과를 제한하고 다른 시드가 이러한 제한 내에서 상황을 변경할 수 있다는 뜻입니다).
최종 모델 성능이 이전 반복보다 나쁘게 나타나는 이유는 무엇인가요?
기억해야 할 사항이 몇 가지 있습니다.
Driverless AI는 지금까지 확인된 최고의 모델링 파이프라인의 generalization performance 을 estimate 합니다.
성능 추정은 항상 홀드아웃 데이터(모델에서 볼 수 없는 데이터)에 기초합니다.
만약 검증 데이터 세트가 제공되지 않으면 학습 데이터가 내부에서 분할되어 internal validation 홀드아웃 데이터를 생성합니다 (accuracy 설정에 따라 한 번 또는 다수의 교차 검증).
유효성 검사 데이터 세트가 제공되지 않을 때는, accuracy가 <= 7인 경우, 단일 홀드아웃 분할이 사용되고 《lucky》 또는 《unlucky》분할로 작은 데이터 세트 또는 분산이 큰 데이터 세트에 대한 추정치가 편향될 수 있습니다.
검증 데이터 세트가 제공되는 경우, 모든 성능 추정치는 오직 전체 검증 데이터 세트에만 기초합니다(accuracy 설정과 무관).
보고된 모든 점수는 부트스트랩 기반 통계 방법에 기초하며 추정 불확도의 범위를 나타내는 error bars 와 함께 제공됩니다.
최종 반복 후에는 best 최종 모델이 가공된 최종 특성 세트에 대해 학습됩니다. accuracy 설정에 따라 교차 검증을 사용하여 일반화 성능의 보다 정확한 측정이 가능합니다. 또한 최종 모델은 다양한 기본 모델로 구성된 스택형 앙상블일 수도 있기 때문에 보통 성능이 향상됩니다. 따라서, 드문 경우에 성능 추정 방법의 차이 때문에 최종 모델의 추정 성능이 이전 반복 성능보다 저하된 것처럼 나타날 수도 있습니다(즉, 최종 모델의 추정 점수가 마지막 반복 점수보다 훨씬 나쁘고 오차 막대가 겹치지 않습니다). 이러한 경우 최종 모델 성능 추정이 더 정확하고, 이전 추정은 《lucky》 분할로 인해 편향성을 갖고 있을 가능성이 매우 높습니다. 이를 확인하려면 실험을 여러 번 재실행하십시오(복제 가능한 플래그 설정 없이).
최종 모델 성능이 이전 반복보다 나빠질 가능성을 최소화하기 위해서는 다음의 몇 가지 recommendations를 참조하십시오.
accuracy 설정을 높이십시오
검증 데이터 세트를 제공하십시오
더 많은 데이터를 제공하십시오
Driverless AI 모델에서 데이터 유출 가성성이 있는 특성은 어떻게 찾아야 하나요?
유출을 초래하는 기존 특성을 찾으려면 실험 요약 다운로드에서 features_orig.txt를 확인하십시오. 유출을 초래하는 특성이 여기서 매우 중요합니다. 유출을 초래할 수 있는 파생된 특성에 대한 힌트를 얻으려면 다이얼을 2/2/8로 설정하고 새로운 실험을 생성하고 모든 특성 및 응답을 사용해서 데이터에 대한 새로운 실험을 실행합니다. 그 후, 모델 변수 중요도의 상위 1~2개의 특성을 분석하십시오. 데이터 유출이 발생할 경우 이러한 상위 특성이 데이터 유출의 주요 원인일 가능성이 높습니다.
테스트 데이터에 대한 성능 메트릭을 어떻게 확인할 수 있나요?
테스트 세트에 대상 열을 제공하는 한, Driverless AI는 실험 종료 시, 테스트 세트에서 최종 모델의 성능에 대한 최상의 추정치를 표시합니다. 테스트 세트는 매개변수의 조정에는 사용되지 않기 때문에(Kaglers가 자주 하는 것과는 다르게) 굉장히 편리합니다. 물론 선택한 방법을 통해 테스트 세트를 예측하고 자체 측정 항목도 계산할 수 있습니다.
내 실험에 대해 가능한 모든 성능 측정 항목을 확인하려면 어떻게 해야 하나요?
실험 종료 시, 대상 열을 포함한 제공된 모든 데이터 세트에 대한 모델의 예상 성능이 실험 로그에 기록됩니다. 예를 들어 테스트 세트의 경우는 다음과 같습니다.
Final scores on test (external holdout) +/- stddev: GINI = 0.87794 +/- 0.035305 (more is better) MCC = 0.71124 +/- 0.043232 (more is better) F05 = 0.79175 +/- 0.04209 (more is better) F1 = 0.75823 +/- 0.038675 (more is better) F2 = 0.82752 +/- 0.03604 (more is better) ACCURACY = 0.91513 +/- 0.011975 (more is better) LOGLOSS = 0.28429 +/- 0.016682 (less is better) AUCPR = 0.79074 +/- 0.046223 (more is better) optimized: AUC = 0.93386 +/- 0.018856 (more is better)
학습/검증 및 테스트 데이터 세트가 다른 분포에서 온 경우는 어떻게 되나요?
보통 Driverless AI는 학습 데이터를 사용하여 특성을 가공하고 모델 및 검증 데이터 학습을 통해 모든 매개변수를 튜닝합니다. 외부 검증 데이터가 제공되지 않으면 학습 데이터가 내부 홀드아웃 생성에 사용됩니다. 홀드아웃이 내부에서 생성되는 방식은 시간 의존성이 강한지 아닌지에 따라 다릅니다. 아래 항목을 참조하십시오. 데이터에 명백한 시간 의존성이 없는 경우(예: 암묵적이든 명시적이든 시간 열을 포함하지 않은 경우) 또는 데이터의 임의 정렬이 가능하고 이것이 결과에 영향을 미치지 않는 경우(예: 홍채 데이터, 측정값으로부터 꽃의 종 예측), 테스트 데이터 세트가 다른 경우(예: 새로운 꽃 또는 커다란 꽃의 경우에만)에는 학습 도중에 측정된 검증(내부 또는 외부)에 대한 모델 성능은 모델의 명확한 일반화가 불가능하기 때문에 최종 테스트 도중에 달성되지 않습니다.
Driverless AI는 가중 데이터를 처리하나요?
예. 비음성 관측 가중치를 사용하여 학습(및 검증) 데이터에 추가 가중치 열의 선택적인 제공이 가능합니다. 이것은 시간 또는 클래스 가중치의 지수가중법과 같은 도메인별 효과의 구현에 유용할 수 있습니다. Driverless AI의 모든 알고리즘 및 메트릭은 관측 가중치를 지원하지만, 이로 인해 예상 가능도가 왜곡될 수 있습니다.
Driverless AI는 가중치 데이터에 대한 폴드 할당을 어떻게 처리하나요?
현재 Driverless AI는 폴드 생성 도중에 가중치를 고려하지 않지만, 폴드 열의 제공을 통해 스스로의 그룹화를 적용할 수 있습니다. 즉, 같은 그룹에 속하는 행을 함께 유지하기 위해(학습 또는 검증 내에서). 폴드 열은 각 행에 그룹 ID를 할당하는 범주형 열(정수 가능)이어야 합니다(최대 5-폴드의 CV를 수행하기 때문에 최소 5개의 그룹이 필요합니다).
데이터 세트에 새로운 특성을 추가하면 왜 모델 성능이 저하되나요?
데이터 세트에 하나 이상의 새로운 특성을 추가하면 Driverless AI 모델의 성능이 저하된다는 것을 확인할 수 있습니다. Driverless AI에서 변수 가공 시퀀스는 상당히 무작위적이고, 새로운 열을 사용해서 완전히 새롭게 재시작하면 원래 특성과 동일한 작업을 수행하지 않을 수도 있습니다.
Driverless AI v1.4.0부터, 이제 Restart from Last Checkpoint 옵션을 이용할 수 있습니다. 이를 통해, 더 많은 열을 포함한 새로운 데이터 세트를 가져올 수 있고 Driverless AI는 새로운 열을 더 반복적으로 활용하게 됩니다.
Driverless AI는 이진 분류 실험에 대한 불균형 데이터를 어떻게 처리하나요?
불균형 데이터를 가지고 있는 경우, 이진 불균형 모델은 다양한 불균형 샘플링 방법으로 스코어링 향상에 도움을 줄 수 있습니다. 불균형 모델은 샘플링 도중에 불균형 데이터 세트의 양의 값 대부분(또는 전부)을 활용할 수 있는 반면, 일반 모델은 양수 값의 모집단을 크게 제한합니다. 하지만 불균형 모델은 예측에 더 많은 시간이 소요되고 일반 모델에 비해 항상 정확하지는 않습니다. 데이터가 불균형한 경우 불균형 모델을 통해 스코어링이 일반 모델보다 개선되었는지 확인할 것을 권장합니다. 해당 정보는 이진 모델에만 적용됩니다.
Driverless AI에서 기능 중요성을 어떻게 계산하나요?
XGBoost 또는 LightGBM 모델과 같은 대부분의 모델에서 Driverless AI는 정규화된 information gain 사용하여 기능 중요성을 계산합니다. 특정 모델에는 때때로 다른 중요성 추정치를 사용합니다.
파이프라인에서 한 개의 LightGBM 모델만 가지고 싶습니다. 어떻게 해야 하나요?
앙상블 레벨 를 사용하여 이를 수행할 수 있습니다. 앙상블 수준을 변경하려면 Model 탭에 있는 Ensemble Level for Final Modeling Pipeline 상세 설정(config.toml의
fixed_ensemble_level)을 사용하십시오. 단일 모델을 원하는 경우 레벨 0을 사용하십시오. 하이퍼파라미터가 있는 동일한 모델을 사용해도 괜찮지만 다중 교차 검증 폴드로 훈련된 경우 레벨 1을 사용하십시오.하나의 모델 유형만 사용하려면 Recipes 탭에 있는 Include Specific Models 상세 설정을 사용하십시오.
자세한 정보는 Driverless AI의 앙상블 학습 를 참조하십시오.
참고
fixed_ensemble_level = 0설정 시 CV가 있는 단일 모델 유형이 아니라 100% 데이터에 대해 훈련한 단일 모델을 반환합니다.Cross-validate Single Final Model 상세 설정이 활성화된 경우(기본값)
fixed_ensemble_level = 0단일 모델은 CV로 튜닝되므로 최적의 트리 수를 갖습니다.fixed_ensemble_level = 0인 경우 이 설정을 비활성화하지 않는 것을 권장합니다.
FE 없이 한 개의 LightGBM 모델만 가지고 싶습니다. 어떻게 해야 하나요?
허용된 변환 세트를 OriginalTransformer에 대해서만 추가로 제한하여 이를 수행할 수 있습니다. 이렇게 하면 숫자 기능은 원래 형식으로 유지하고 숫자가 아닌 기능을 모두 삭제합니다. Driverless AI 환경에서 특정 트랜스포머를 포함하거나 제외하려면 Recipes 탭에 있는 Include Specific Transformers 상세 설정(config.toml의
included_transformers)을 사용하십시오. Feature Engineering Effort 상세 설정(config.toml의feature_engineering_effort)을 0으로 설정하면 동일한 효과를 얻을 수도 있습니다.자세한 정보는 Driverless AI 변환 를 참조하십시오.
Driverless AI에서 빠른 근사가 무엇입니까?
빠른 근사는 일반 및 Shapley 예측 모두에 사용할 수 있습니다. MLI/AutoDoc에서는 기본적으로 활성화되어 있고 다른 클라이언트에서는 기본적으로 꺼져 있습니다. 근사의 범위는 빠른 근사 상세 설정으로 완전히 구성하거나 끌 수 있습니다. 빠른 근사를 활성화하면 부분 의존도 플롯 및 기타 MLI 관련 작업 생성과 같은 대규모 예측 작업의 속도를 크게 향상힐 수 있습니다.
참고
다음은 빠른 근사를 구성하기 위해 사용되는 상세 설정의 목록입니다.
Regular predictions:
Shapley predictions:
MLI:
언제 빠른 근사를 꺼야 하나요?
더 자세한 부분 의존도 플롯 또는 해석이 필요한 상황에서는 빠른 근사를 비활성화할 수 있습니다.
특성 변환¶
실험에서 수행된 다양한 변환에 대한 세부 내용은 어디서 얻을 수 있나요?
GUI에서 실험 로그 .zip 파일을 다운로드하십시오. 해당 zip 파일에는 요약 정보, 로그 정보 및 실험에 사용된 변환의 세부 정보를 포함한 gene_summary.txt 파일이 포함되어 있습니다. 특히 모든 하위 프로세스 로그를 포함한 details 폴더가 있습니다.
서버에서 실험 관련 파일은 실험 완료 후, /tmp/h2oai_experiment_<name>/ 폴더 안에 위치합니다. 특히 h2oai_experiment_logs_<name>.zip 및 h2oai_experiment_summary_<name>.zip 에 있습니다.
예측¶
Driverless AI가 실행되고 있는 시스템에 예측을 다운로드하려면 어떻게 해야 하나요?
Score on Another Dataset 선택 시, 예측은 Driverless AI가 실행되는 머신에 자동으로 저장되며 위치는 다음과 같습니다(.csv 및 .bin 모두에 대해 Driverless AI에 의해 다시 열릴 수 있음).
학습 데이터 예측: tmp/h2oai_experiment_<name>/train_preds.csv (.bin 으로도 저장됨)
학습 데이터 예측: tmp/h2oai_experiment_<name>/test_preds.csv (.bin 으로도 저장됨)
신규 데이터 예측: tmp/h2oai_experiment_<name>/automatically_generated_name.csv. 자동으로 생성된 이름은 로컬 컴퓨터에 다운로드한 파일의 이름과 같습니다.
앙상블링 없이 실험을 실행할 때 예측 확률을 사용할 수 없는 이유는 무엇인가요?
Driverless AI는 실험 완료 후, 사전 계산된 예측 제공 시 예측이 수행되는 특정 행에서 학습되지 않은 모델링 파이프라인 부분만을 사용합니다. 즉, Driverless AI는 해당 모델이 학습 데이터에 대해서만 학습되는 검증 또는 테스트 세트와 같은 예측의 생성을 위해 홀드아웃 데이터를 필요로 합니다. 앙상블의 경우, Driverless AI는 교차 검증을 사용하여 훈련 데이터에 대한 홀드아웃 폴드를 생성하기 때문에 학습 데이터의 모든 행에 대한 폴드 외 추정치를 제공할 수 있어서 학습 홀드아웃 예측(일반화 성능에 대한 훌륭한 추정치를 제공합니다)도 제공이 가능합니다. 하지만 단일 모델의 경우, 학습 데이터의 100%에 대하여 학습됩니다. 학습 데이터의 모든 행에 대해 편향 없는 추정치 생성은 불가능합니다. DAI는 내부 검증 데이터 세트를 사용하지만 재사용 가능한 홀드아웃이기 때문에 전체 학습 데이터 세트에 대한 홀드아웃 예측을 포함하지 않습니다. 폴드 외 추정치를 얻기 위해서는 교차 검증이 필요하고, 이것은 더 이상 단일 모델이 아닙니다. 단일 모델에 대한 학습 데이터의 예측을 지속해서 얻으려면 스코어링 API를 사용하여 학습 세트에 대한 예측을 생성해야 합니다. GUI로부터 완료된 실험의 Score on Another Dataset 버튼을 통해 해당 작업을 수행할 수 있습니다. 그러나 결과가 지나치게 낙관적이고 말도 안 될 정도로 훌륭하기 때문에 사실상 쓸모가 없습니다.
배포¶
MOJO의 크기 결정 요인은 무엇인가요?
MOJO의 크기는 최종 모델링 파이프라인의 복잡성(예: 변수 가공 및 모델)에 기초합니다. 가장 큰 요인 중 하나는 학습 데이터에서 관측된 가능한 모든 조합에 대한 lookup 테이블을 저장해야 하는 특성, 특히 대상 인코딩 및 관련 특성 사이의 higher-order 상호 작용의 양입니다. 상세 설정에서 Max. feature interaction depth 및/또는 Feature engineering effort 값을 줄이거나 실험의 해석 가능성 설정을 증가시켜 이러한 변환의 양을 줄일 수 있습니다. 또한, Ensembles 은 각각의 모델이 자체 파이프라인을 가지고 있기 때문에 최종 모델링 파이프라인의 복잡성에 기여합니다. accuracy 설정을 낮추거나 ensemble level 을 더 낮은 숫자로 설정합니다. 특성 수 Max. pipeline features 는 MOJO의 크기에도 영향을 줍니다. 텍스트 트랜스포머도 부피가 상당히 커서 MOJO 크기를 늘릴 수 있습니다.
한 번의 클릭으로 모델 구축 도중에 더 작은 mojo로 전환하려면, 실험의 실험 설정에서 - Reduce mojo size 를 참조하십시오.
MOJO 스레드는 안전한가요?
예, 모든 Driverless AI MOJO는 thread safe입니다.
내 MOJO의 스코어링 파이프라인을 실행하는 데 몇 시간이나 걸립니다, 실행 시간을 단축하려면 어떻게 해야 하나요?
example.sh 실행 시, Driverless AI는 대부분의 유스케이스에 적합한 메모리 설정을 구현합니다. 하지만 굉장히 큰 모델의 경우, 데이터 변환을 위한 Java 애플리케이션 실행 시, 메모리 제한을 늘려야 할 수도 있습니다. 이것은
-Xmx25g매개변수를 사용하여 수행이 가능합니다. 예를 들면:java -Xmx25g -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv
《Best Score is not finite》 오류 발생 이유는 무엇인가요?
Driverless AI는 기본적으로 32-bit float를 사용합니다. 데이터값이 1E38을 초과하거나 1천만 분의 1이상의 해결할 경우, 해당 오류가 발생할 수 있습니다. 다음 방법 중 하나를 사용해서 이 오류를 해결할 수 있습니다.
실험의 상세 설정에서 Force 64-bit Precision 옵션을 활성화하십시오.
또는
config.toml에서
data_precision="float64"및transformer_precision="float64"를 설정하십시오.
Time Series¶
내 데이터에 시간 의존성이 있는 경우 어떻게 해야 하나요?
데이터가 강력한 시간 의존성을 가지고 있다는 것을 알고 있는 경우, 실험 시작 전에 시간 열을 선택하십시오. 시간 열은 《2017-11-06 14:32:21》, 《Monday, June 18, 2012》 또는 《Jun 18 2018 14:34:00》 등과 같은 panda를 사용해서 분석될 수 있는 날짜 시간 형식이거나 정수만 포함해야 합니다.
시간 의존성의 강도가 확실하지 않은 경우,다음 두 가지 실험을 실행하십시오. 하나는 시간 열이 《[OFF]》로 설정되고 다른 하나는 시간 열이 《[AUTO]》로 설정됩니다(또는 시간 열을 직접 선택하십시오).
lag란 무엇이며, 왜 도움이 되나요?
lag는 이전 시점의 특성값입니다. lag는 현재(미상)의 목표값이 종종 이전(알려진)의 목표값과 관련되어 있다는 사실의 활용하는 데 유용합니다. 따라서, 시간 축을 따라 대상 패턴을 더 잘 포착할 수 있습니다.
time series 문제에 대해 왜 검증 데이터 세트를 지정할 수 없나요? time series 문제에 대한 테스트 세트를 보는 이유는 무엇인가요
time series 설정에서 검증 대 테스트의 문제점은 분할을 정의하는 유효한 방법이 오직 하나라는 것입니다. 테스트 세트가 제공될 경우, 시간의 길이가 검증 분할을 정의하며, 검증 데이터는 학습의 일부여야 합니다. 그렇지 않으면 time series 검증이 유용하지 않습니다.
예를 들어, train = [1,2,3,4,5,6,7,8,9,10] 및 test = [12,13]을 가정합니다. 여기서 정수는 기간(예: 주)으로 정의됩니다. 이 예에서 테스트 시나리오를 모방한 가장 자연스러운 학습/유효 분할은 다음과 같습니다. train = [1,2,3,4,5,6,7] 및 valid = [9,10]이고 8번째 월은 차이를 허용하기 위해 학습 세트에 포함되지 않습니다. 테스트 데이터의 내용(특성도 대상도 아님)이 아닌 테스트 세트의 시작 시간 및 기간(제공된 경우)만을 살펴봅니다. 사용자가 테스트 데이터 대신 validation = [8,9,10]을 제공하면 질이 낮은 검증 전략 및 악화된 일반화로 이어질 수 있습니다. 따라서, 우리는 사용자가 제공한 테스트 세트를 이용하여 최적의 내부 학습/검증 분할을 생성합니다. 테스트 세트가 제공되지 않으면 사용자는 테스트 세트의 길이(기간 단위), 학습/테스트 gap 사이의 길이(기간 단위) 및 기간 자체의 길이(초 단위)를 제공할 수 있습니다.
학습 및 테스트 사이의 gap이 중요한 이유는 무엇인가요? 테스트 세트에 lag 특성을 생성하기 때문인가요?
실제 오류에 대한 지나친 낙관적 추정을 피하고 학습 및 검증 데이터(결측된 정보로 인해 테스트 데이터에 대해 생성 불가)에 대한 lag와 같은 이력 기반 특성을 생성하지 않으려면 gap을 고려해야 합니다.
시간 그룹 열의 다른 서브셋에 대상 lag를 적용하는 것에 대해서 Driverless AI가 time series의 《levels》에서 자기상관성을 수행한다고 이야기하는 건가요? 예를 들어, 내가 매월마트 데이터 세트를 고려한다고 했을 때, Driverless AI가 매장만, 부서만 또는 매장과 부서 모두를 기준으로 주간 판매에서 자기상관성을 확인한다는 뜻인가요?
현재, 자기상관성은 최초에 학습 데이터 세트 관계의 감지된 슈퍼키(전체 TGC)에만 적용됩니다. lag 특성 선택을 담당하는 GA 최적화 프로세스를 위한 검색 공간을 가지치기하는 것을 목표로 잠재적 lag 크기의 순위를 매기는 데 사용됩니다.
Driverless AI는 기간을 어떻게 감지하나요?
Driverless AI는 각각의 time series를 일부 주파수 1/ns를 포함한 함수로 취급합니다. 실제값은 최대 길이 TGC 하위 그룹에 걸친 time delta의 중앙값에 의해 추정됩니다. 선택된 SI 단위는 사용 가능한 모든 SI 단위와의 거리를 최소화합니다.
forecast horizon 길이에 대해 선택 가능한 숫자의 논리는 무엇인가요?
나타낸 forecast horizon 옵션은 유효 분할의 분위수에 기초합니다. 이것은 Driverless AI가 일반적으로 가능한 모든 옵션을 표시할 수 없기 때문에 필요합니다.
내 월마트 데이터 세트에서 모든 매장은 주 단위로 데이터를 제공했지만, 한 상점은 일 단위로 데이터를 제공했다고 가정합니다. Driverless AI는 어떻게 처리하나요?
대부분의 매장이 이 속성을 산출하기 때문에 Driverless AI는 이 경우에도 《weekly data》를 가정합니다. 《daily》 매장은 감지된 전체 빈도로 재샘플링됩니다.
내 월마트 데이터 세트에서 모든 매장 및 부서가 주간 단위로 데이터를 제공했지만 특정 매장의 한 부서는 격주로 주간 판매 데이터를 제공했다고 가정합니다. Driverless AI는 어떻게 처리하나요?
이것은 결측 데이터를 가지는 것과 유사합니다. 적절한 리샘플링으로 인해 Driverless AI는 문제없이 이것을 처리할 수 있습니다.
예측을 시작하려는 주 수가 중요한 이유는 무엇인가요?
테스트 데이터를 사용할 수 없는 경우에 학습 테스트 gap을 제공하는 옵션입니다. 즉, 《I don’t have my test data yet, but I know it will have a gap to train of x.》
time series의 스코어링 구성 요소는 새로운 데이터의 도착 순서에 민감한가요? 즉, 각 행은 스코어링 시간에 독립적인가요, 아니면 스코어링 조각에서 실시간 윈도잉 효과가 있나요?
각 행은 스코어링 시점에 독립적입니다.
만약 사용자가 예측 시간에 너무 작거나 너무 큰 시간 값을 포함한 행을 제공하면 어떻게 되나요?
내부적으로 《out-of bounds》 시간 값은 특수값으로 인코딩됩니다. 샘플은 여전히 스코어링되지만 예측은 신뢰할 수 없게 됩니다.
time series 레시피의 최소 데이터 크기는 얼마인가요?
실제 오류를 신뢰성 있게 추정하기 위해서는 약 10,000개의 검증 샘플을 사용할 것을 권장합니다. 더 작은 양의 데이터에 time series 레시피를 지속해서 적용할 수는 있지만, 검증 오류가 정확하지 않을 수 있습니다.
학습 데이터를 테스트 데이터와 얼마나 오래 비교해야 하나요?
최소한 학습 데이터는 시간 축을 따라 테스트 데이터보다 두 배 이상 길어야 합니다. 하지만 학습 데이터는 테스트 데이터의 3배 이상의 길이가 권장됩니다.
time series 레시피는 결측값을 어떻게 처리하나요?
결측값은 특수값으로 변환되는데 이것은 모든 비결측 특성값과 다릅니다. 명시적 대치 테크닉은 적용되지 않습니다.
입력 데이터의 다수 열에 시간 정보(예: [년, 일, 월])를 배포할 수 있나요?
현재 Driverless AI는 데이터에 단일 열에 주어진 타임 스탬프를 가지고 있어야 합니다. Driverless AI는 유용하다고 판단할 경우, 자체적으로[년, 일, 월]과 같은 추가 시간 기능을 생성합니다.
Driverless AI는 time series에 대하여 어떤 유형의 모델링 접근 방식을 사용합니까?
Driverless AI는 lag, 이동 평균 등과 같은 이력 기반 특성의 생성을 i.i.d. 데이터에도 적용할 수 있는 모델링 기술과 결합합니다기본 선택 모델은 XGBoost입니다.
이동 평균의 지수가중법에 대한 기본 개념은 무엇인가요?
지수가중법은 더 최신의 관측치가 이전 관측치보다 현재를 설명하는 데 있어서 더 적합할 가능성에 대해 설명합니다.
로깅¶
Audit Logger의 크기를 줄이려면 어떻게 해야 하나요?
Audit Logger 파일은 Driverless AI 사용 중에는 매일 생성됩니다.
audit_log_retention_periodconfig 변수를 이용하면 audit.log를 덮어쓸 일수를 지정할 수 있습니다. 해당 옵션의 기본값은 5일입니다. 즉, Driverless AI는 지난 5일간 Audit Logger 파일을 유지하고, 5일 이전의 audit.log 파일은 제거되고 최신 로그 파일로 대체됩니다. 해당 옵션을0으로 설정하면 audit.log 파일에 덮어 쓰이지 않습니다.