상세 설정¶
본 섹션은 실험 시작 시, 사용할 수 있는 상세 설정에 관한 내용입니다. Driverless AI는 실험을 맞춤화할 수 있는 상세 설정의 다양한 옵션을 제공합니다. 검색 창을 사용하여 설정 목록을 구체화하거나 특정 설정을 찾을 수 있습니다.
해당 옵션의 기본값은 config.toml 파일의 구성 옵션에서 유래합니다. 이러한 각 옵션에 대한 자세한 내용은 샘플 config.toml 파일 섹션을 참조하십시오. 설정이 기본값으로부터 변경되면 인터페이스에서 강조 표시되어 현재 기본값이 선택되지 않았음을 표시합니다.
Note about Feature Brain Level: 기본적으로 특성 브레인은 새로운 모델이 해당 특성을 비활성화하더라도 특성과 관계 없이 더 나은 모델을 가져옵니다. 이러한 상세 설정의 변경을 통해 가져온 기능을 완전하게 제어하려면 사용자가 Feature Brain Level 옵션을 0으로 설정해야 합니다.
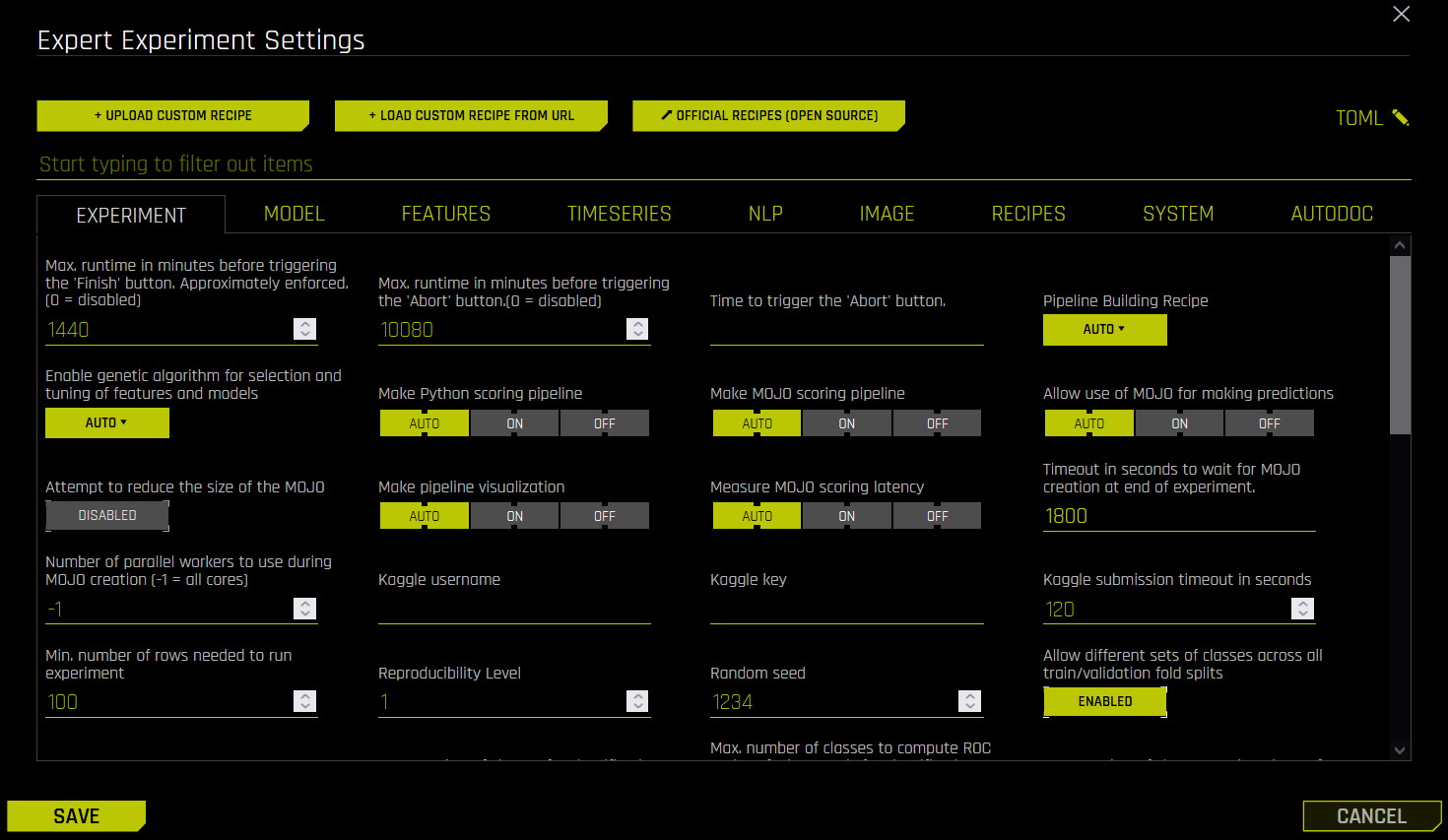
- 사용자 정의 레시피 업로드
- 사용자 정의 레시피를 URL에서 로드
- 공식 레시피(오픈 소스)
- TOML 구성 편집하기
- 실험 설정
max_runtime_minutesmax_runtime_minutes_until_aborttime_abortpipeline-building-recipeenable_genetic_algorithmtournament_stylemake_python_scoring_pipelinemake_mojo_scoring_pipelinemojo_for_predictionsreduce_mojo_sizemake_pipeline_visualizationbenchmark_mojo_latencymojo_building_timeoutmojo_building_parallelismkaggle_usernamekaggle_keykaggle_timeoutmin_num_rowsreproducibility_levelseedallow_different_classes_across_fold_splitssave_validation_splitsmax_num_classesmax_num_classes_compute_rocmax_num_classes_client_and_guiroc_reduce_typemax_rows_cm_gause_feature_brain_new_experimentsfeature_brain_levelfeature_brain2feature_brain3feature_brain4feature_brain5force_model_restart_to_defaultsmin_dai_iterationstarget_transformerfixed_num_folds_evolutionfixed_num_foldsfixed_only_first_fold_modelfeature_evolution_data_sizefinal_pipeline_data_sizemax_validation_to_training_size_ratio_for_final_ensembleforce_stratified_splits_for_imbalanced_threshold_binarymli_customlast_recipefeature_brain_reset_scorefeature_brain_save_every_iterationwhich_iteration_brainrefit_same_best_individualrestart_refit_redo_origfs_shift_leakbrain_add_features_for_new_columnsforce_model_restart_to_defaultsdump_modelparams_every_scored_indivfast_approx_num_treesfast_approx_do_one_foldfast_approx_do_one_modelfast_approx_contribs_num_treesfast_approx_contribs_do_one_foldfast_approx_contribs_do_one_modelautoviz_recommended_transformation
- 모델 설정
enable_constant_modelenable_decision_treeenable_glmenable_xgboost_gbmenable_lightgbmenable_xgboost_dartenable_xgboost_rapidsenable_xgboost_rfenable_xgboost_gbm_daskenable_xgboost_dart_daskenable_lightgbm_daskenable_hyperopt_dasknum_inner_hyperopt_trials_prefinalnum_inner_hyperopt_trials_finalnum_hyperopt_individuals_finaloptuna_pruneroptuna_samplerenable_xgboost_hyperopt_callbackenable_lightgbm_hyperopt_callbackenable_tensorflowenable_grownetenable_ftrlenable_rulefitenable_zero_inflated_modelsenable_lightgbm_boosting_typesenable_lightgbm_cat_supportenable_lightgbm_cuda_supportshow_constant_modelparams_tensorflowmax_nestimatorsn_estimators_list_no_early_stoppingmin_learning_rate_finalmax_learning_rate_finalmax_nestimators_feature_evolution_factormax_abs_score_delta_train_validmax_rel_score_delta_train_validmin_learning_ratemax_learning_ratemax_epochsmax_max_depthmax_max_binrulefit_max_num_rulesensemble_meta_learnerfixed_ensemble_levelcross_validate_meta_learnercross_validate_single_final_modelparameter_tuning_num_modelsimbalance_sampling_methodimbalance_sampling_threshold_min_rows_originalimbalance_ratio_sampling_thresholdheavy_imbalance_ratio_sampling_thresholdimbalance_sampling_number_of_bagsimbalance_sampling_max_number_of_bagsimbalance_sampling_max_number_of_bags_feature_evolutionimbalance_sampling_max_multiple_data_sizeimbalance_sampling_target_minority_fractionftrl_max_interaction_terms_per_degreeenable_bootstraptensorflow_num_classes_switchprediction_intervalsprediction_intervals_alphadump_modelparams_every_scored_indiv
- 특성 설정
feature_engineering_effortcheck_distribution_shiftcheck_distribution_shift_dropdrop_features_distribution_shift_threshold_auccheck_leakagedrop_features_leakage_threshold_aucleakage_max_data_sizemax_features_importanceenable_wide_rulesorig_features_fs_reportmax_rows_fsmax_orig_cols_selectedmax_orig_nonnumeric_cols_selectedfs_orig_cols_selectedfs_orig_numeric_cols_selectedfs_orig_nonnumeric_cols_selectedmax_relative_cardinalitynum_as_catmax_int_as_cat_uniquesmax_fraction_invalid_numericnfeatures_maxngenes_maxfeatures_allowed_by_interpretabilitymonotonicity_constraints_interpretability_switchmonotonicity_constraints_correlation_thresholdmonotonicity_constraints_log_levelmonotonicity_constraints_drop_low_correlation_featuresmonotonicity_constraints_dictmax_feature_interaction_depthfixed_feature_interaction_depthenable_target_encodingcvte_cv_in_cvenable_lexilabel_encodingenable_isolation_forestenable_one_hot_encodingisolation_forest_nestimatorsdrop_constant_columnsdrop_id_columnsno_drop_featurescols_to_dropcols_to_force_incols_to_group_bysample_cols_to_group_byagg_funcs_for_group_byfolds_for_group_bymutation_modedump_varimp_every_scored_indivdump_trans_timingscompute_correlationinteraction_finder_gini_rel_improvement_thresholdinteraction_finder_return_limitenable_rapids_transformersvarimp_threshold_at_interpretability_10stabilize_fs
- Time Series 설정
time_series_recipetime_series_leaderboard_modetime_series_leaderboard_periods_per_modeltime_series_merge_splitsmerge_splits_max_valid_ratiofixed_size_splitstime_series_validation_fold_split_datetime_boundariestimeseries_split_suggestion_timeoutholiday_featuresholiday_countriesoverride_lag_sizesoverride_ufapt_lag_sizesoverride_non_ufapt_lag_sizesmin_lag_sizeallow_time_column_as_featureallow_time_column_as_numeric_featuredatetime_funcsfilter_datetime_funcsallow_tgc_as_featuresallowed_coltypes_for_tgc_as_featuresenable_time_unaware_transformerstgc_only_use_all_groupstgc_allow_target_encodingtime_series_holdout_predstime_series_validation_splitstime_series_splits_max_overlaptime_series_max_holdout_splitsmli_ts_fast_approxmli_ts_fast_approx_contribsmli_ts_holdout_contribstime_series_min_interpretabilitylags_dropoutprob_lag_non_targetsrolling_test_methodfast_tta_internalprob_default_lagsprob_lagsinteractionprob_lagsaggregatests_target_trafots_target_trafo_epidemic_params_dictts_target_trafo_epidemic_targetts_lag_target_trafots_target_trafo_lag_size
- NLP 설정
enable_tensorflow_textcnnenable_tensorflow_textbigruenable_tensorflow_charcnnenable_pytorch_nlppytorch_nlp_pretrained_modelstensorflow_max_epochs_nlpenable_tensorflow_nlp_accuracy_switchpytorch_nlp_fine_tuning_num_epochspytorch_nlp_fine_tuning_batch_sizepytorch_nlp_fine_tuning_padding_lengthpytorch_nlp_pretrained_models_dirtensorflow_nlp_pretrained_embeddings_file_pathtensorflow_nlp_pretrained_s3_access_key_idtensorflow_nlp_pretrained_s3_secret_access_keytensorflow_nlp_pretrained_embeddings_trainabletext_fraction_for_text_dominated_problemtext_transformer_fraction_for_text_dominated_problemstring_col_as_text_thresholdtext_transformers_max_vocabulary_size
- 이미지 설정
enable_tensorflow_imagetensorflow_image_pretrained_modelstensorflow_image_vectorization_output_dimensiontensorflow_image_fine_tunetensorflow_image_fine_tuning_num_epochstensorflow_image_augmentationstensorflow_image_batch_sizeimage_download_timeoutstring_col_as_image_max_missing_fractionstring_col_as_image_min_valid_types_fractiontensorflow_image_use_gpu
- 레시피 설정
included_transformersincluded_modelsincluded_scorersincluded_pretransformersnum_pipeline_layersincluded_datasthreshold_scorerprob_add_genesprob_addbest_genesprob_prune_genesprob_perturb_xgbprob_prune_by_featuresskip_transformer_failuresskip_model_failuresdetailed_skip_failure_messages_levelnotify_failuresacceptance_test_timeout
- 시스템 설정
exclusive_modemax_coresmax_fit_coresuse_dask_clustermax_predict_coresmax_predict_cores_in_daibatch_cpu_tuning_max_workerscpu_max_workersnum_gpus_per_experimentmin_num_cores_per_gpunum_gpus_per_modelnum_gpus_for_predictiongpu_id_startassumed_simultaneous_dt_forks_mungingmax_max_dt_threads_mungingmax_dt_threads_mungingmax_dt_threads_readwritemax_dt_threads_stats_openblasallow_reduce_features_when_failurereduce_repeats_when_failurefraction_anchor_reduce_features_when_failurexgboost_reduce_on_errors_listlightgbm_reduce_on_errors_listnum_gpus_per_hyperopt_daskdetailed_tracesdebug_loglog_system_info_per_experiment
- AutoDoc 설정
make_autoreportautodoc_report_nameautodoc_templateautodoc_output_typeautodoc_subtemplate_typeautodoc_max_cm_sizeautodoc_num_featuresautodoc_min_relative_importanceautodoc_include_permutation_feature_importanceautodoc_feature_importance_num_permautodoc_feature_importance_scorerautodoc_pd_max_rowsautodoc_pd_max_runtimeautodoc_out_of_rangeautodoc_num_rowsautodoc_population_stability_indexautodoc_population_stability_index_n_quantilesautodoc_prediction_statsautodoc_prediction_stats_n_quantilesautodoc_response_rateautodoc_response_rate_n_quantilesautodoc_gini_plotautodoc_enable_shapley_valuesautodoc_data_summary_col_numautodoc_list_all_config_settingsautodoc_keras_summary_line_lengthautodoc_transformer_architecture_max_linesautodoc_full_architecture_in_appendixautodoc_coef_table_appendix_results_tableautodoc_coef_table_num_modelsautodoc_coef_table_num_foldsautodoc_coef_table_num_coefautodoc_coef_table_num_classesautodoc_num_histogram_plots