모델 해석 페이지 이해¶
본 문서에서는 non-time-series 실험에 대한 기계학습 해석 가능성(MLI) 설명 페이지에서 사용할 수 있는 다양한 해석에 관해 설명합니다.
설명 페이지는 네 개의 탭으로 구성됩니다.
대시보드 버튼은 대리 모델을 사용하여 작성된 해석의 개요를 포함한 대시보드를 나타냅니다. MLI 페이지의 Action button 을 사용하여 reason codes, 생산을 위한 scoring pipelines 및 MLI logs 를 다운로드할 수 있습니다.
task bar 는 MLI explainers 의 상태와 로그를 나열합니다.
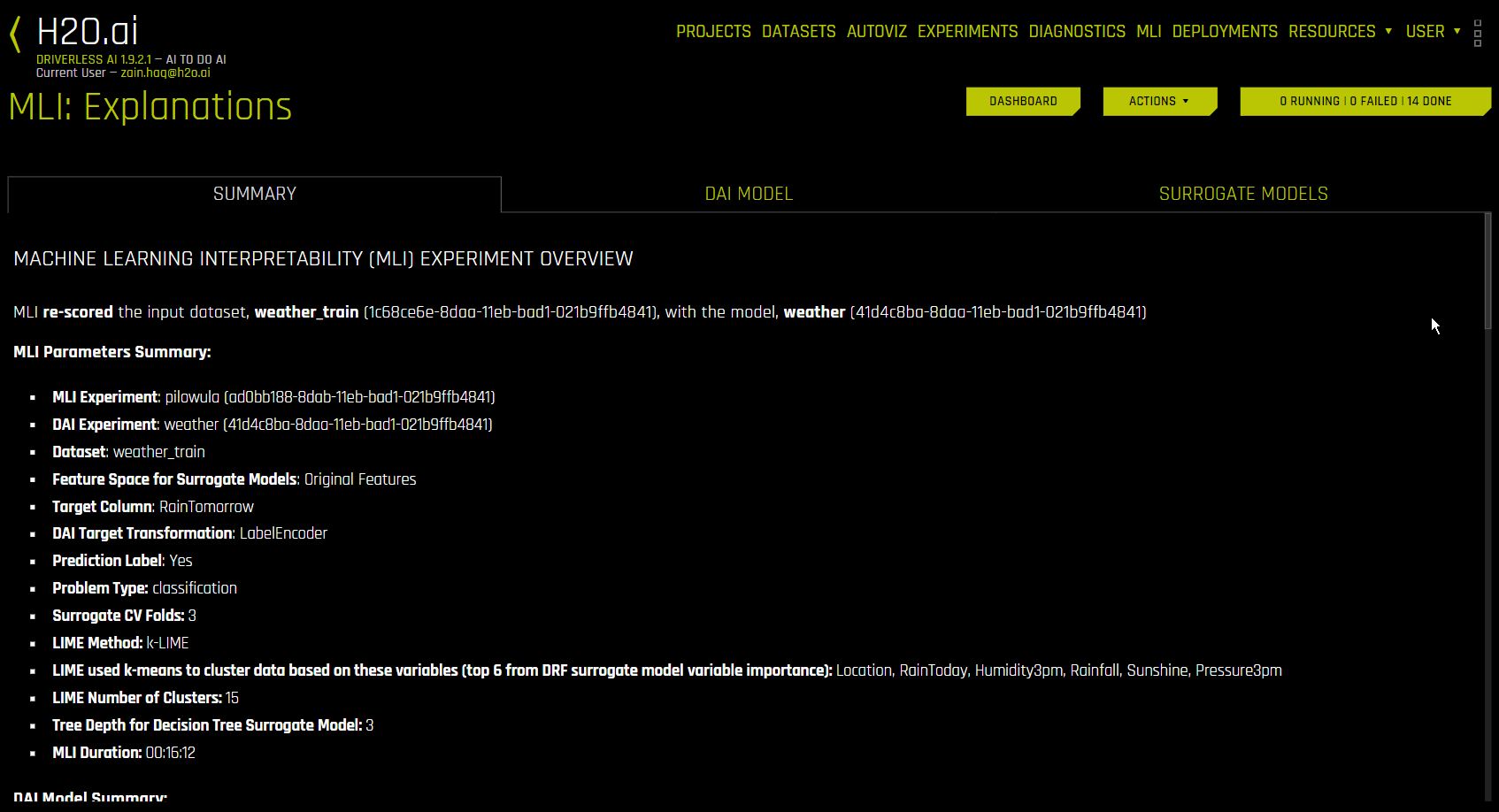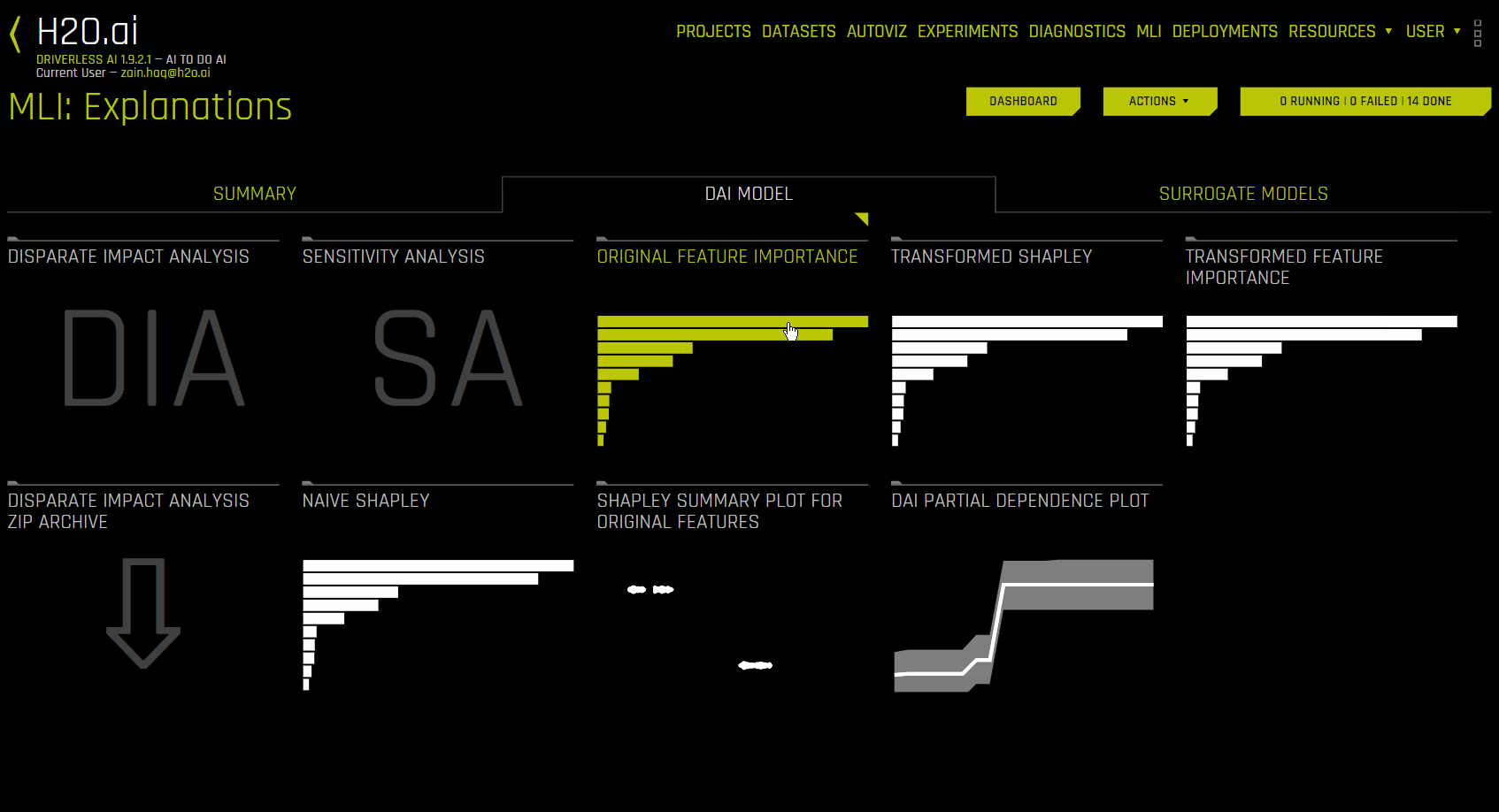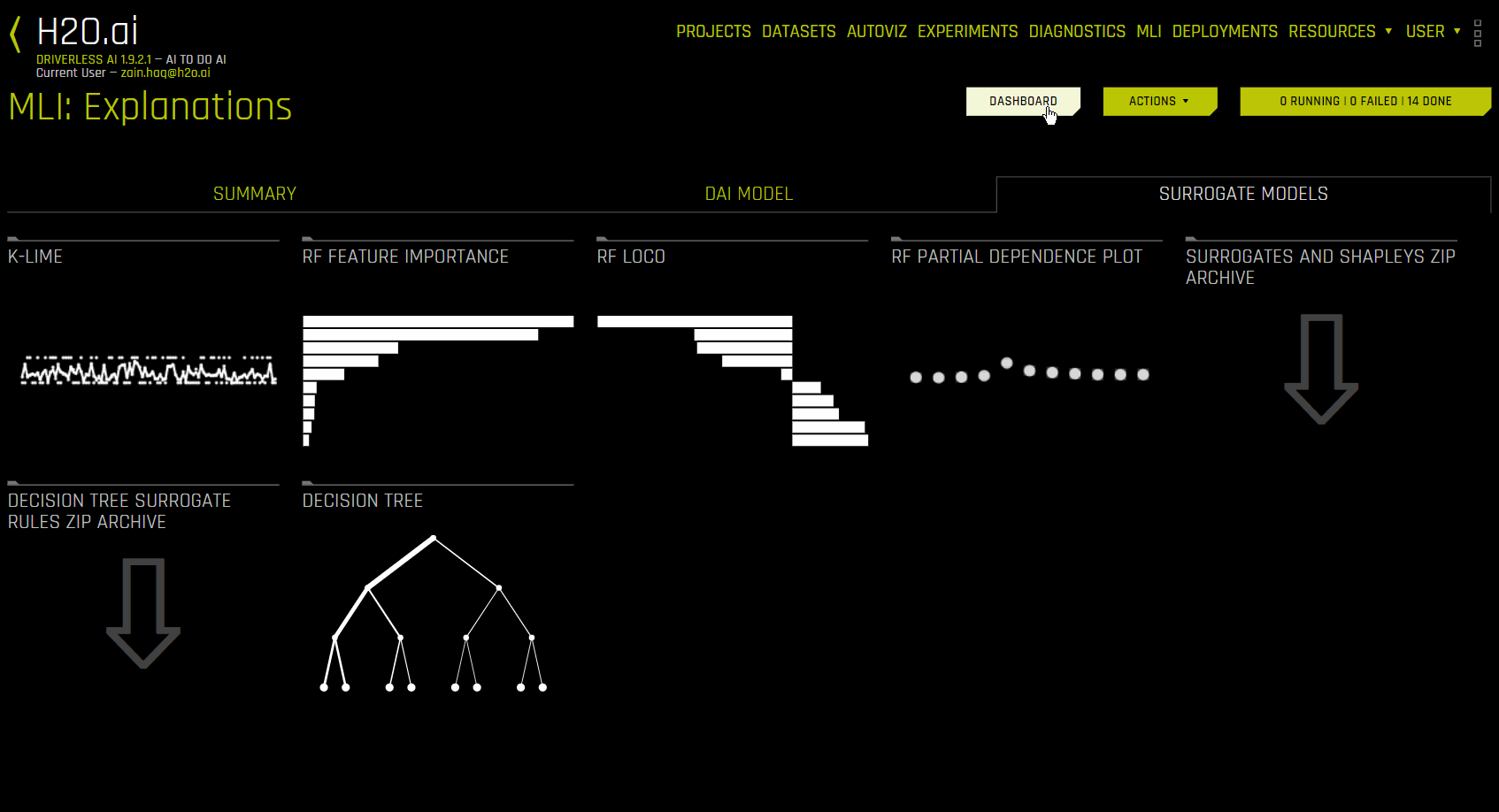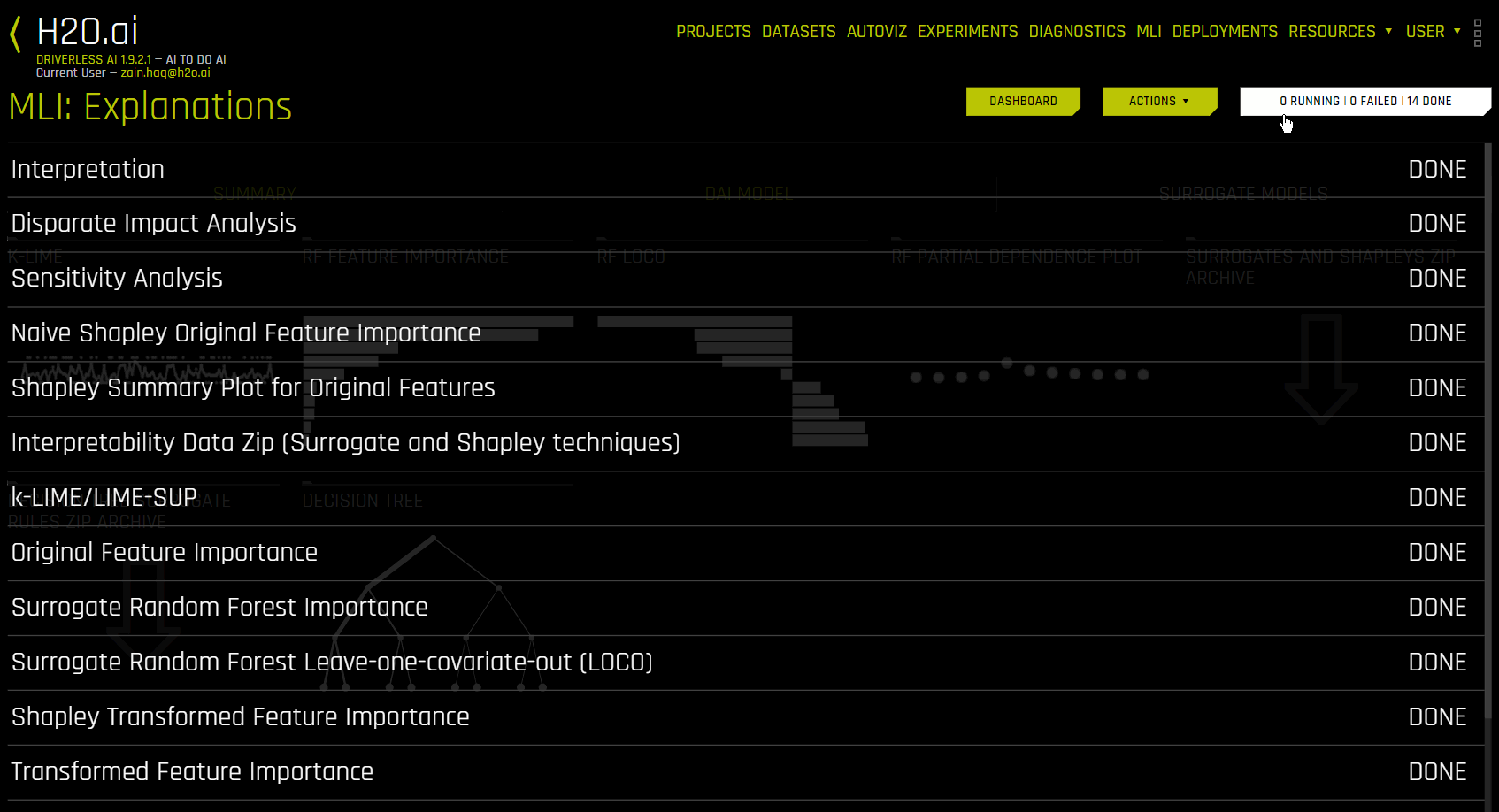
요약 탭¶
요약 탭은 해석에 사용된 데이터 세트 및 Driverless AI 실험 이름(사용 가능 시)과 함께 해석에 사용된 해석의 개요를 특성 공간(원본 또는 변형), 대상 열, 문제 유형 및 k-Lime 정보와 함께 제공합니다. 이 해석이 Driverless AI 모델로부터 생성된 경우 Driverless AI 모델 요약 테이블은 모델의 상위 변수와 함께 포함됩니다.
Driverless AI 모델을 사용한 해석(DAI 모델 탭)¶
DAI 모델 탭은 각각의 해석 방법에 대한 타일로 구성됩니다. 특정 플롯을 보려면 보려고 하는 플롯의 타일을 클릭하십시오.
이진 분류 및 회귀 분석 실험의 경우, 해당 탭에는 Partial Dependence/ICE, Disparate Impact Analysis (DIA), Sensitivity Analysis, NLP 토큰 및 NLP LOCO (텍스트 실험용) 및 Permutation Feature Importance (autodoc_include_permutation_feature_importance 구성 옵션이 활성화된 경우) 플롯뿐만 아니라 기존 및 변환된 특성에 대한 Feature Importance 및 Shapley(RuleFit 및 TensorFlow 모델에는 지원되지 않음) 플롯이 포함됩니다. 다중 클래스 분류 실험의 경우, 해당 탭에는 원본 및 변환된 특성에 대한 Feature Importance 및 Shapley 플롯이 포함됩니다.
다음은 Driverless AI Model 탭에서 사용할 수 있는 해석 플롯의 목록입니다.
Notes:
Shapley 플롯은 RuleFit, FTRL 및 TensorFlow 모델의 경우에는 지원되지 않습니다.
기본적으로 기존 특성에 대한 Shapley는 Naive Shapley method 를 사용하여 계산됩니다( notes 참조). Kernel Explainer 방법을 사용하여 계산을 활성화하려면 recipes 에서 Original Kernel SHAP Explainer를 활성화하십시오.
Shapley 플롯은
has_pred_contribs방법을 구현하고(True를 반환하고) 예측 방법에서pred_contribs=True인자의 적절한 처리를 구현하는 BYOR(사용자 정의) 모델에만 지원됩니다.Permutation-based feature importance 플롯은 Driverless AI 시작 시 또는 MLI 실험 시작 시
autodoc_include_permutation_feature_importance구성 옵션이 활성화된 경우에만 사용할 수 있습니다(레시피 탭에서 AutoDoc를 활성화하고 MLI 작업 시작 시 MLI AutoDoc 상세 설정에서 include_permutation_feature_importance를 활성화합니다).Feature Importance 및 Shapley 플롯에서 변환된 특성 이름은 아래와 같이 인코딩됩니다.
<transformation/gene_details_id>_<transformation_name>:<orig>:<…>:<orig>.<extra>
따라서
32_NumToCatTE:BILL_AMT1:EDUCATION:MARRIAGE:SEX.0에서, 예를 들면 다음과 같습니다.
32_는 특정 변환 매개변수에 대한 변환 지수입니다.
NumToCatTE는 변환 유형입니다.
BILL_AMT1:EDUCATION:MARRIAGE:SEX는 원래 사용된 특성을 나타냅니다.
0은 특성(여기서는BILL_AMT1,EDUCATION,MARRIAGE및SEX로 표시됨)별로 그룹화하고 폴드 외 추정을 만든 후 대상[0]에 대한 가능한 인코딩을 나타냅니다. 멀티 클래스 실험의 경우, 이 값은 0보다 큽니다. 이진 실험의 경우, 이 값은 항상 0입니다.
대리 모델을 사용한 해석(대리 모델 탭)¶
일반적으로 대리 모델은 더 복잡한 모델 또는 현상을 설명하기 위해 더 단순한 모델을 사용하는 데이터 마이닝 및 가공 기술입니다. 예를 들어, decision tree 대리 모델은 기존 모델 입력값을 사용하여 더 복잡한 Driverless AI 모델의 예측값을 예측하도록 학습되었습니다. 학습된 대리 모델을 이용하면 고도로 복잡하고 비선형인 Driverless AI 모델의 메커니즘에 대한 추론적 이해(즉, 수학적인 정확한 이해는 아님)가 가능합니다.
대리 모델 탭은 각각의 해석 방법에 대한 타일로 구성됩니다. 특정 플롯을 확인하려면 확인하고자 하는 플롯의 타일을 클릭하십시오. 이진 분류 및 회귀 분석 실험의 경우, 해당 탭에는 Random Forest 대리 모델에 대한 Feature Importance, Partial Dependence 및 LOCO 플롯뿐만 아니라 K-LIME/LIME-SUP 및 Decision Tree 트리 플롯이 포함됩니다. 이러한 플롯에 대한 더 자세한 내용은 대리 모델 플롯 를 참조하십시오.
다음은 대리 모델의 해석 플롯 목록입니다.
Note: 다중 클래스 분류 실험의 경우, 해당 탭에서는 Decision Tree 및 Random Forest Feature Importance 플롯만 사용할 수 있습니다.
NLP 데이터 세트를 사용한 해석(NLP 탭)¶
NLP 탭은 자연어 처리(NLP) 문제에 대해서만 표시되며 각각의 해석 방법에 대한 타일로 구성됩니다. 특정 플롯을 보려면, 보려고 하는 플롯의 타일을 클릭하십시오.
다음은 NLP 탭에서 사용할 수 있는 해석 플롯의 목록입니다.
대시보드¶
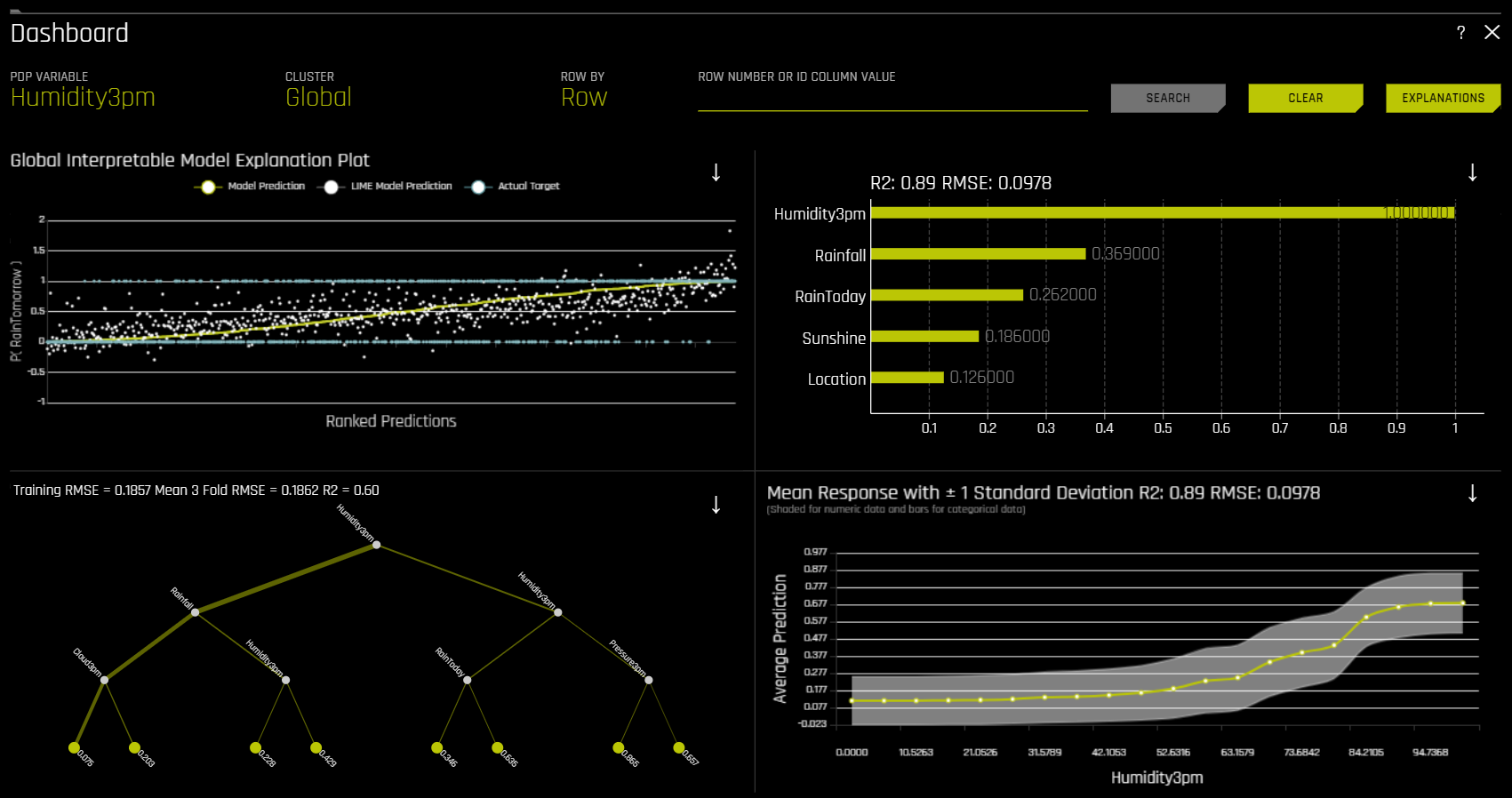
Dashboard 버튼을 클릭하면 대리 모델을 사용하여 작성된 해석에 대한 개요를 포함한 대시보드가 나타납니다. 해석 페이지의 우측 상단 모서리에 위치합니다.

이진 분류 및 회귀 분석 실험의 경우, 해당 대시보드 페이지에서는 다음과 같은 대리 플롯을 포함한 단일 페이지가 제공됩니다. 이 페이지의 PDP 및 Feature Importance 플롯은 Random Forest 대리 모델에 기초합니다.
글로벌 해석 가능 모델 설명
Feature Importance
Decision Tree
Partial Dependence
우측 상단 모서리에 위치한 Explanations 버튼을 클릭하여 해당 페이지에서 설명을 확인할 수도 있습니다. 자세한 내용은 설명 보기 섹션을 참조하십시오.
Note: 대시보드는 이진 분류 및 회귀 분석 실험에만 사용할 수 있습니다.
Action 버튼¶
Action 버튼을 사용하여 reason codes, productionization을 위한 scoring pipelines 및 logs 를 다운로드할 수 있습니다. 다음 옵션을 보려면 이 단추를 클릭합니다.
MLI Docs: Driverless AI 문서의 기계학습 해석 가능성 섹션을 확인하십시오.
Download MLI Logs: 해석 중에 생성된 로그의 ZIP 파일을 다운로드하십시오.
Scoring Pipeline: 이항 및 회귀 분석 실험의 경우, 해석을 위한 Python Scoring Pipeline을 다운로드하십시오. 해당 옵션은 다중 클래스 실험에는 사용할 수 없습니다.
Download k-LIME MOJO Reason Code Pipeline: k-LIME MOJO 사유 코드 파이프라인을 다운로드하십시오. 자세한 내용은 Driverless AI k-LIME MOJO Reason Code Pipeline - Java 런타임 를 참조하십시오.
Download Formatted LIME Reason Codes: 이항 실험의 경우, 형식이 정해진 LIME 사유 코드의 CSV 파일을 다운로드하십시오.
Download LIME Reason Codes: 이항 실험의 경우, LIME 사유 코드의 CSV 파일을 다운로드하십시오.
Download Formatted Transformed Shapley Reason Codes: 회귀 분석, 이진 및 다중 클래스 실험의 경우, 변환된 데이터에 대한 형식이 정해진 Shapley 사유 코드의 CSV 파일을 다운로드하십시오.
Download Formatted Original Shapley Reason Codes (Naive Shapley): 회귀 분석, 이진 및 다중 클래스 실험의 경우, 기존 데이터에 대한 형식이 정해진 Shapley 사유 코드의 CSV 파일을 다운로드하십시오.
Display MLI Java Logs: 해석을 위해 MLI Java 로그를 확인하십시오.
Display MLI Python Logs: 해석을 위해 MLI Python 로그를 확인하십시오.
Experiment: 해석 생성에 사용된 실험을 확인하십시오.

DAI 모델 플롯¶
본 섹션에서는 DAI 모델 탭에서 사용할 수 있는 플롯에 관해 설명합니다.
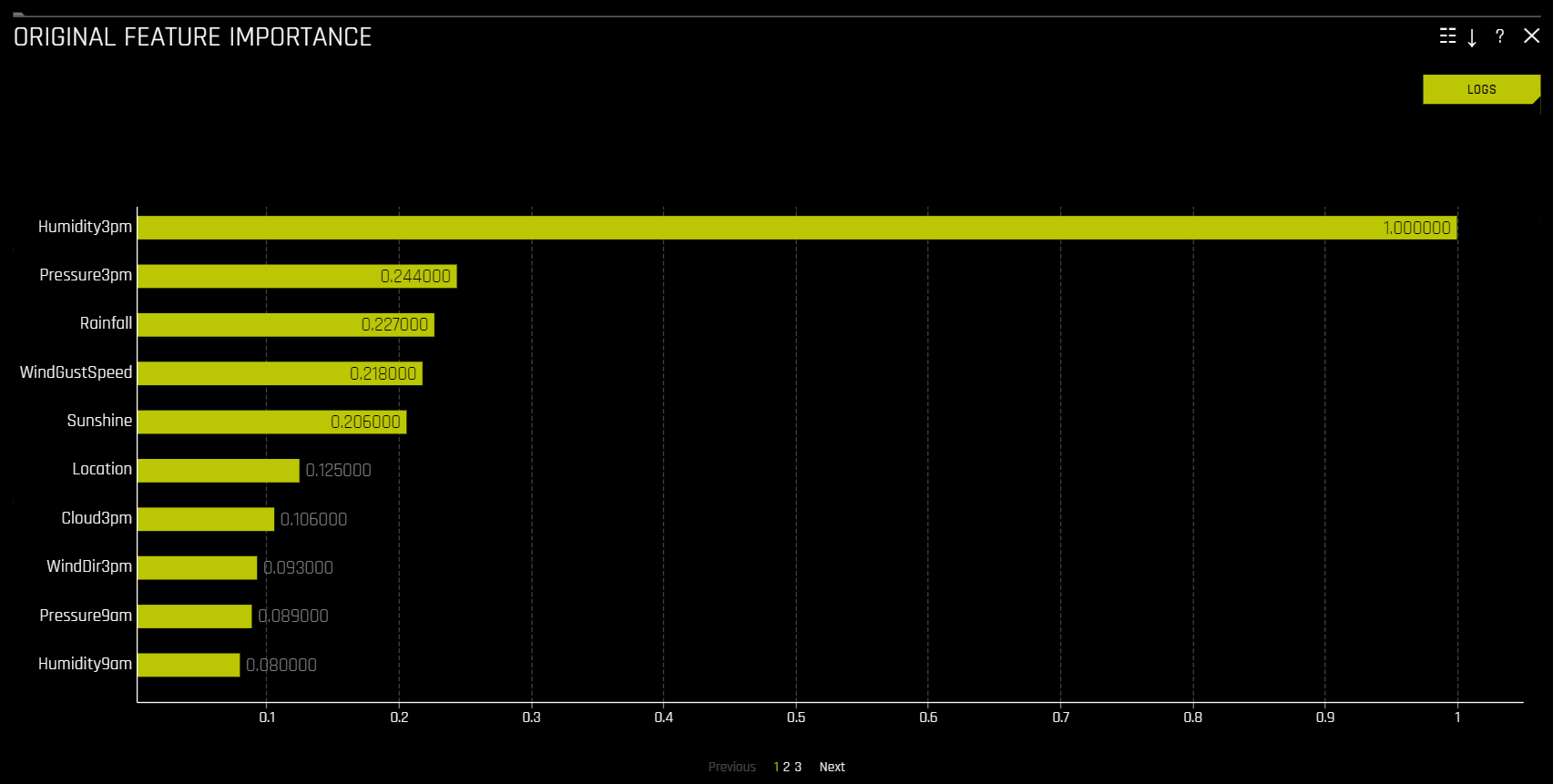
Feature Importance (Original and Transformed Features)¶
해당 플롯은 이진 분류, 다중 클래스 분류 및 회귀 분석 실험의 모든 모델에 사용할 수 있습니다.
이 플롯에서는 Driverless AI feature importance를 보여줍니다. Driverless AI feature importance는 Driverless AI 모델의 전체적인 예측에 대한 입력 변수의 기여도를 측정한 것입니다.
Shapley (Original and Transformed Features)¶
이 플롯은 RuleFit 또는 TensorFlow 모델에는 사용할 수 없습니다. 기타 모든 모델의 경우, 이 플롯은 이진 분류, 다중 클래스 분류 및 회귀 분석 실험에 사용할 수 있습니다.
Shapley 설명은 일관된 글로벌 및 로컬 변수 기여를 제공하는 신뢰할 수 있는 이론적 지원을 포함한 기술입니다. 로컬 수 Shapley 값은 학습된 트리 앙상블을 통해 단일 데이터 행을 추적하고 학습된 앙상블을 통해 데이터 행이 이동할 때 각각의 입력 변수의 기여도를 집계하여 계산됩니다. 회귀 분석 작업의 경우, Shapley 값은 Driverless AI 모델의 예측에 합산됩니다. 분류 문제의 경우, Shapley 값은 링크 함수를 적용하기 전에 Driverless AI 모델의 예측에 합산됩니다. 글로벌 Shapley 값은 데이터 세트의 모든 행에 대한 절대 Shapley 값의 평균입니다.
transformed features 에 대한 Shapley values는 학습된 트리 앙상블을 통해 데이터의 개별 행을 추적한 후, 학습된 앙상블을 통해 데이터 행이 이동할 때 각 입력 변수의 기여도를 집계하여 계산됩니다. 트리 기반 모델용 Shapley에 대한 자세한 내용은 https://arxiv.org/abs/1706.06060 에서 확인하십시오. Driverless AI는 XGBoost 및 LightGBM SHAP 함수를 호출하여 변형된 기능에 대한 기여를 가져옵니다.
original features 에 대한 Shapley 값은 Naive Shapley (균등 분할) 방법을 사용하여 변환된 기능에 대한 Shapley 값으로부터의 근사치입니다. 해당 방법은 트랜스포머에 대한 입력 기능이 독립적이고 기여하는 기능 간에 기여를 균등하게 분할한다고 가정합니다. 예를 들어 변환된 기능 CVTE:age: income.0 의 Shapley value가 5인 경우 원래 기능인 age 와 income 의 Shapley value는 각각 2.5가 됩니다. 앙상블의 경우 Shapley value(링크 공간 내)은 앙상블에서 모델 가중치에 따라 혼합됩니다.
생산을 위한 Driverless AI MOJO 는 원래 기능에 대한 Naive Shapley (균등 분할) 접근 방식을 지원합니다.
원래 기능의 Shapley value는 Kernel Explainer 방법으로 계산할 수도 있습니다. 이 방법은 각 기능의 중요성을 계산하기 위해 특수 가중치 선형 회귀를 사용합니다. 이는 recipe Original Kernel SHAP explainer를 사용하여 활성화할 수 있습니다. Kernel SHAP에 대한 자세한 정보는 http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf 에서 얻을 수 있습니다.
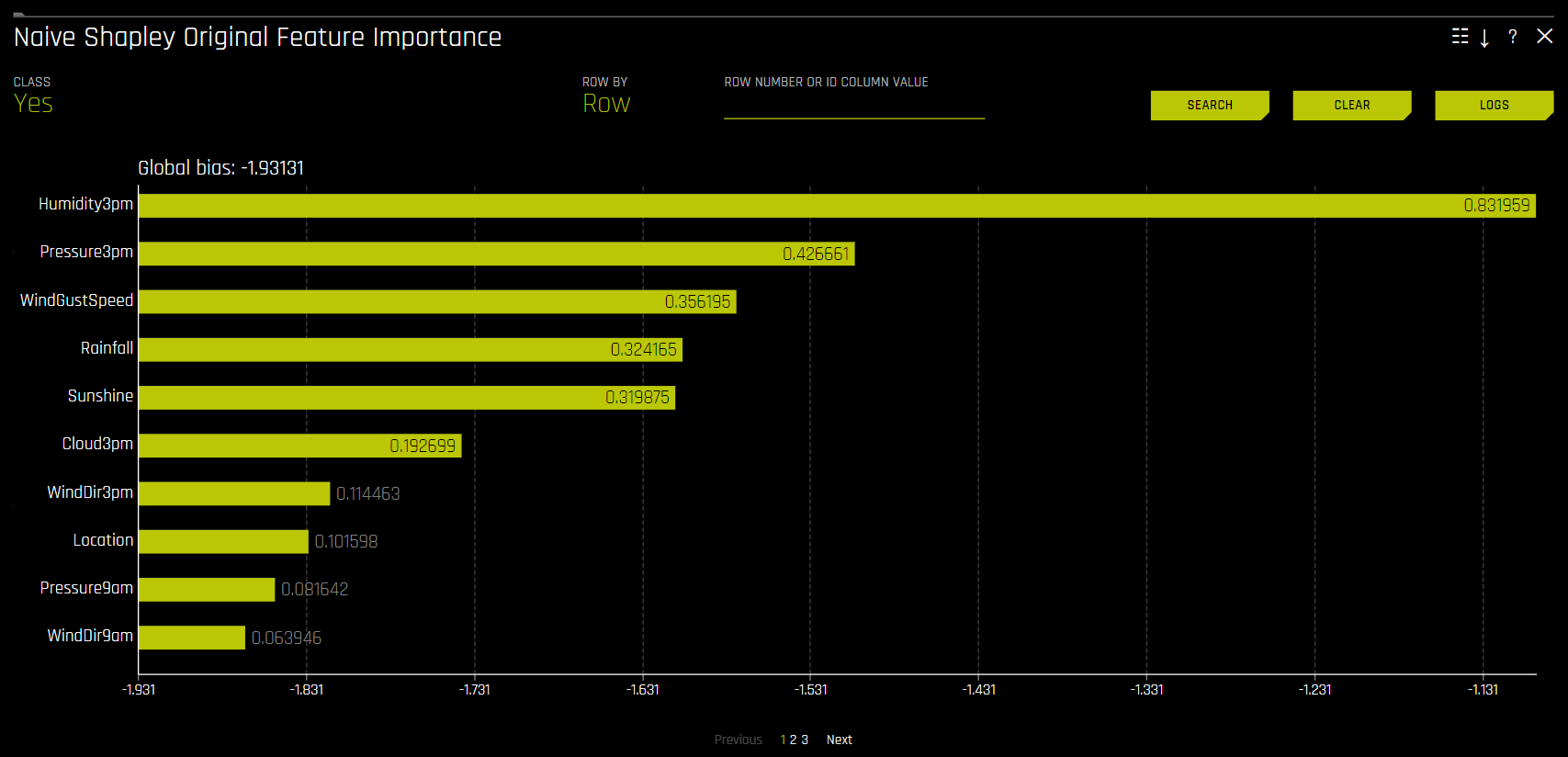
Naive Shapley Original Feature Importance¶
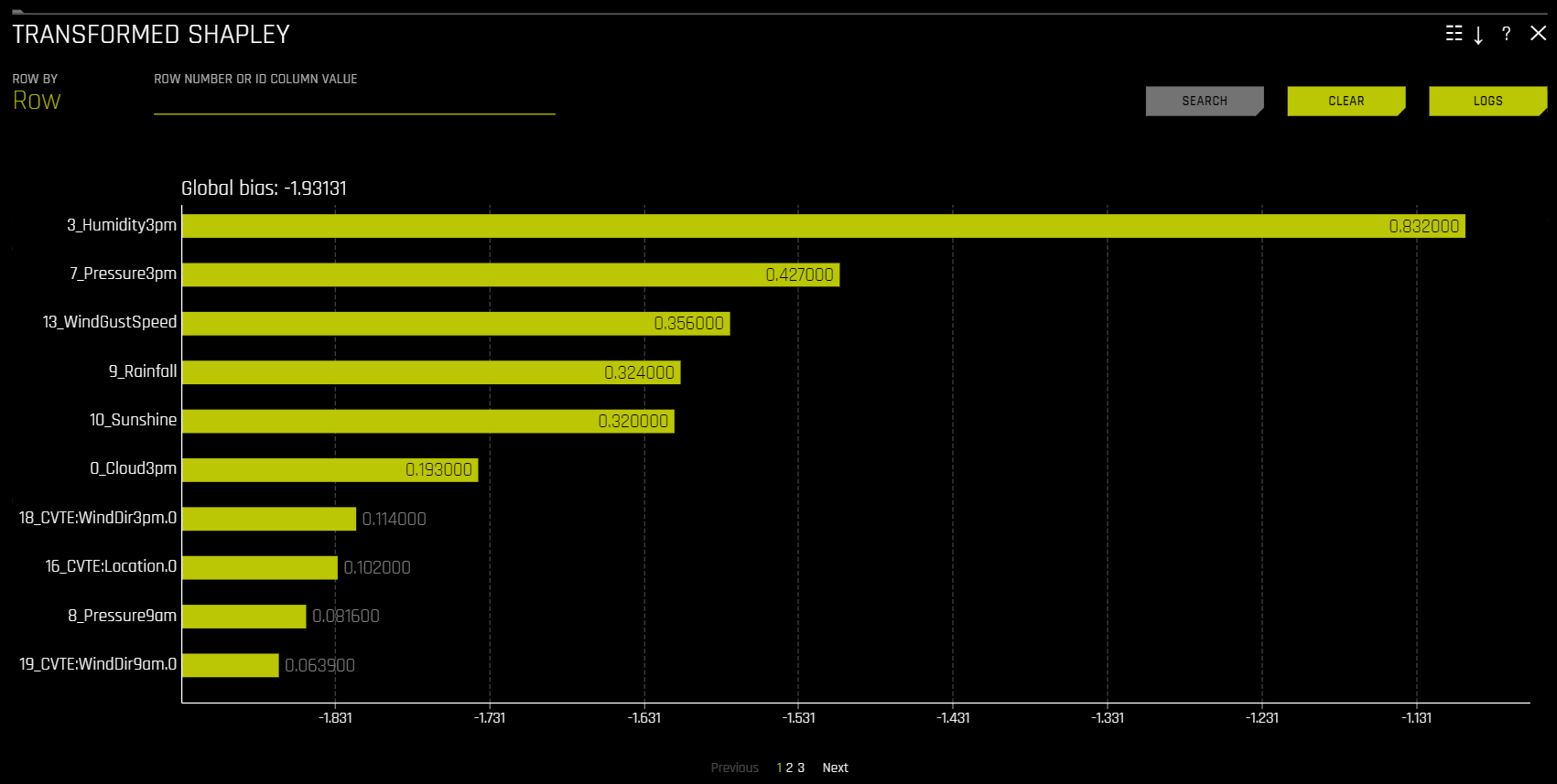
Transformed Shapley¶
Feature Importance 및 Shapley 플롯에 대한 Showing \(n\) Features 드롭다운을 사용하면 원래 기능과 변형된 기능 중에서 선택할 수 있습니다. 많은 양의 기능이 있는 경우, 개별적으로 확인할 수 있는 번호가 매겨진 페이지로 구성됩니다. Note: 제공된 원래 값은 수반되는 변형된 값에서 파생된 근사값입니다. 예를 들어, 변형된 기능 \(feature1\_feature2\) 의 값이 0.5인 경우 원래 기능(\(feature1\) and \(feature2\) )의 값은 0.25가 됩니다.
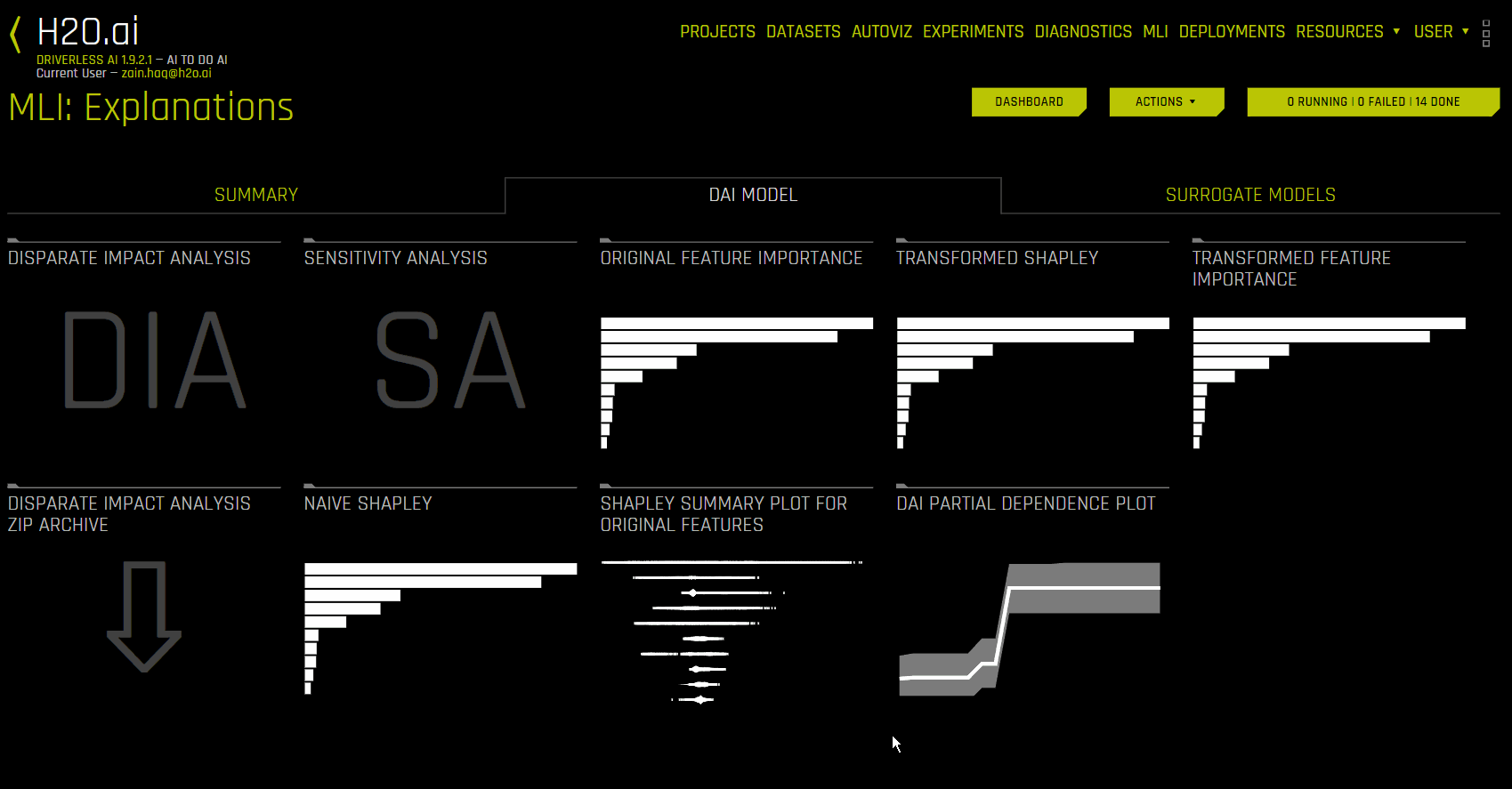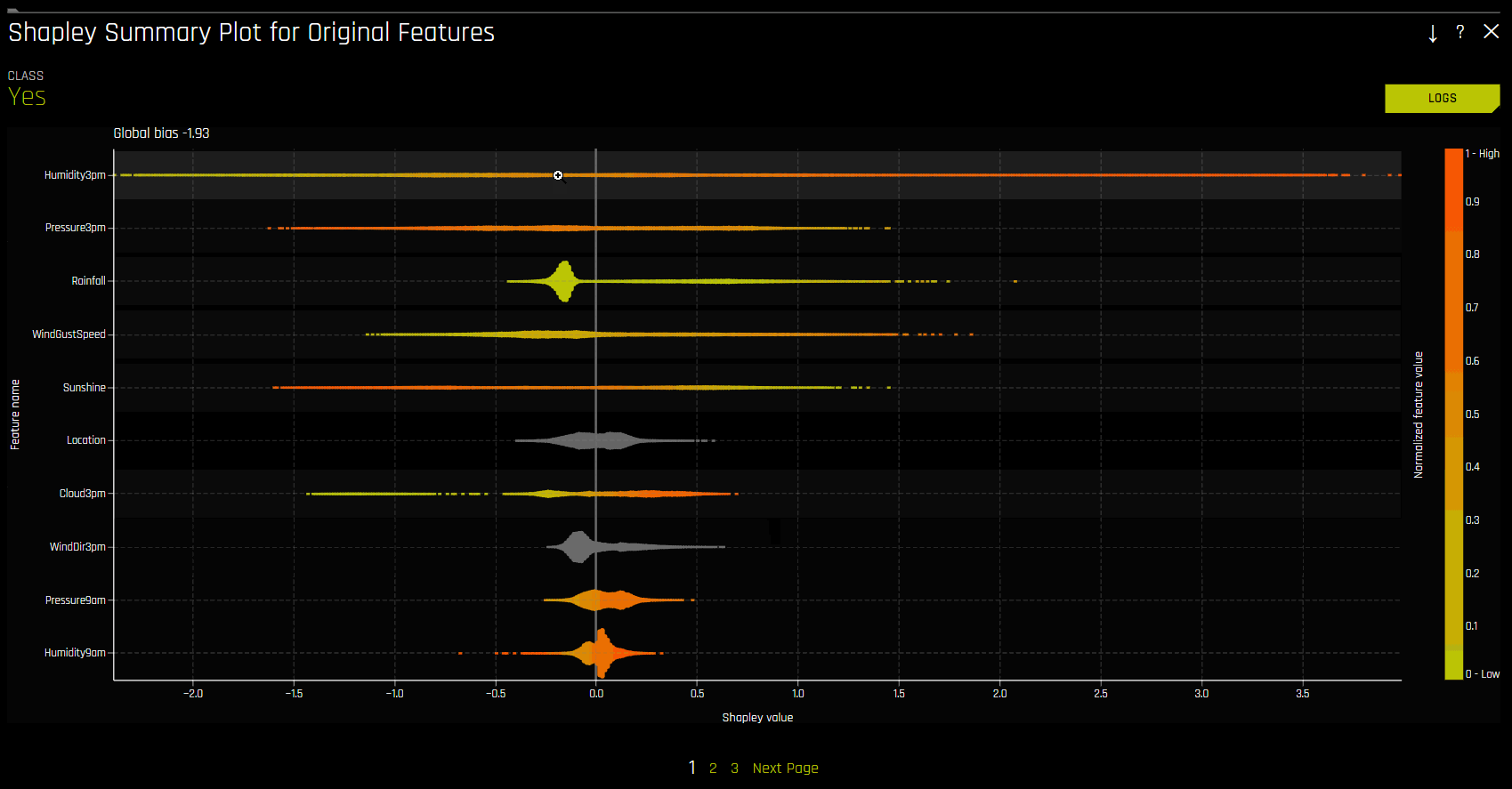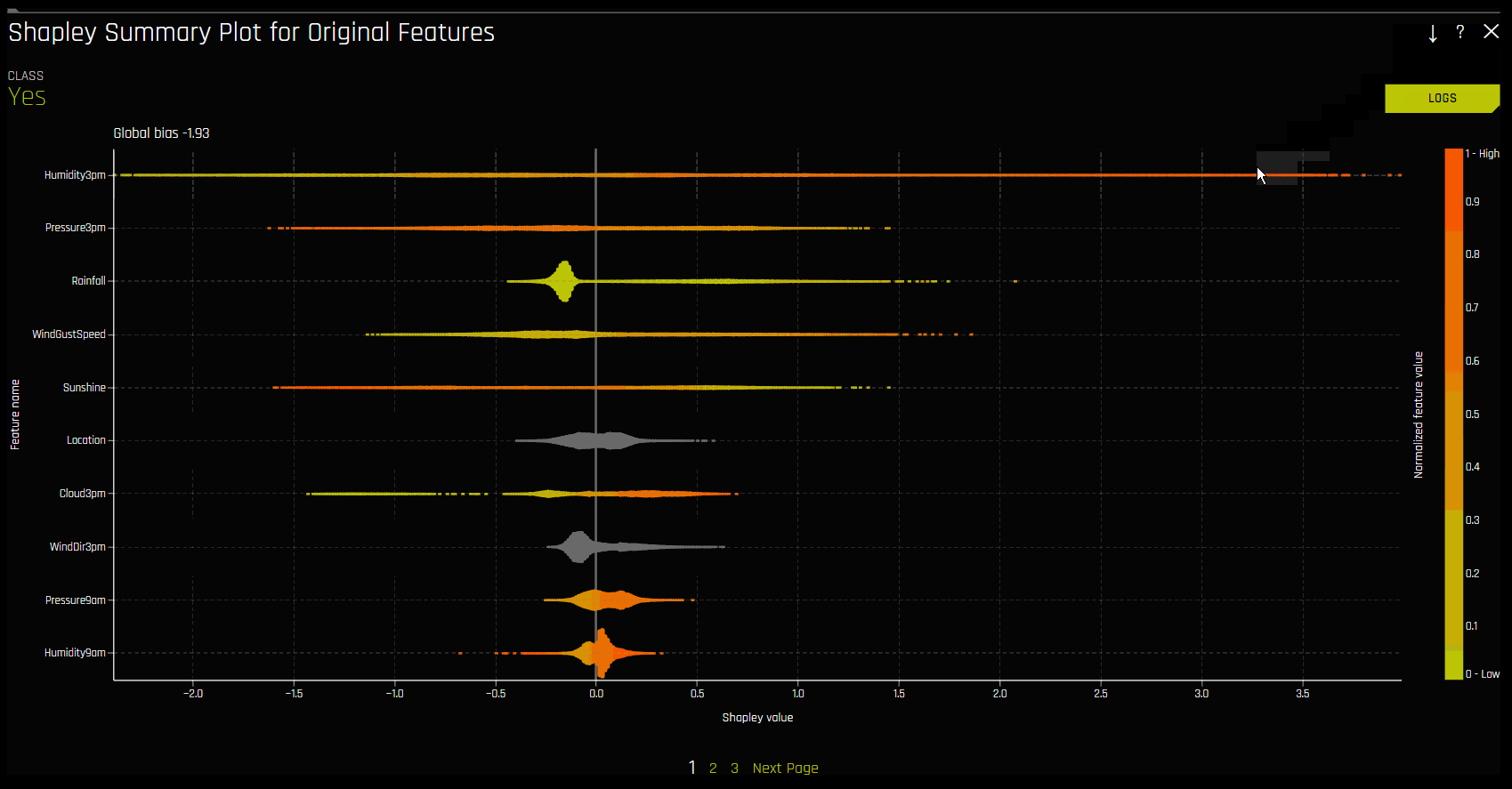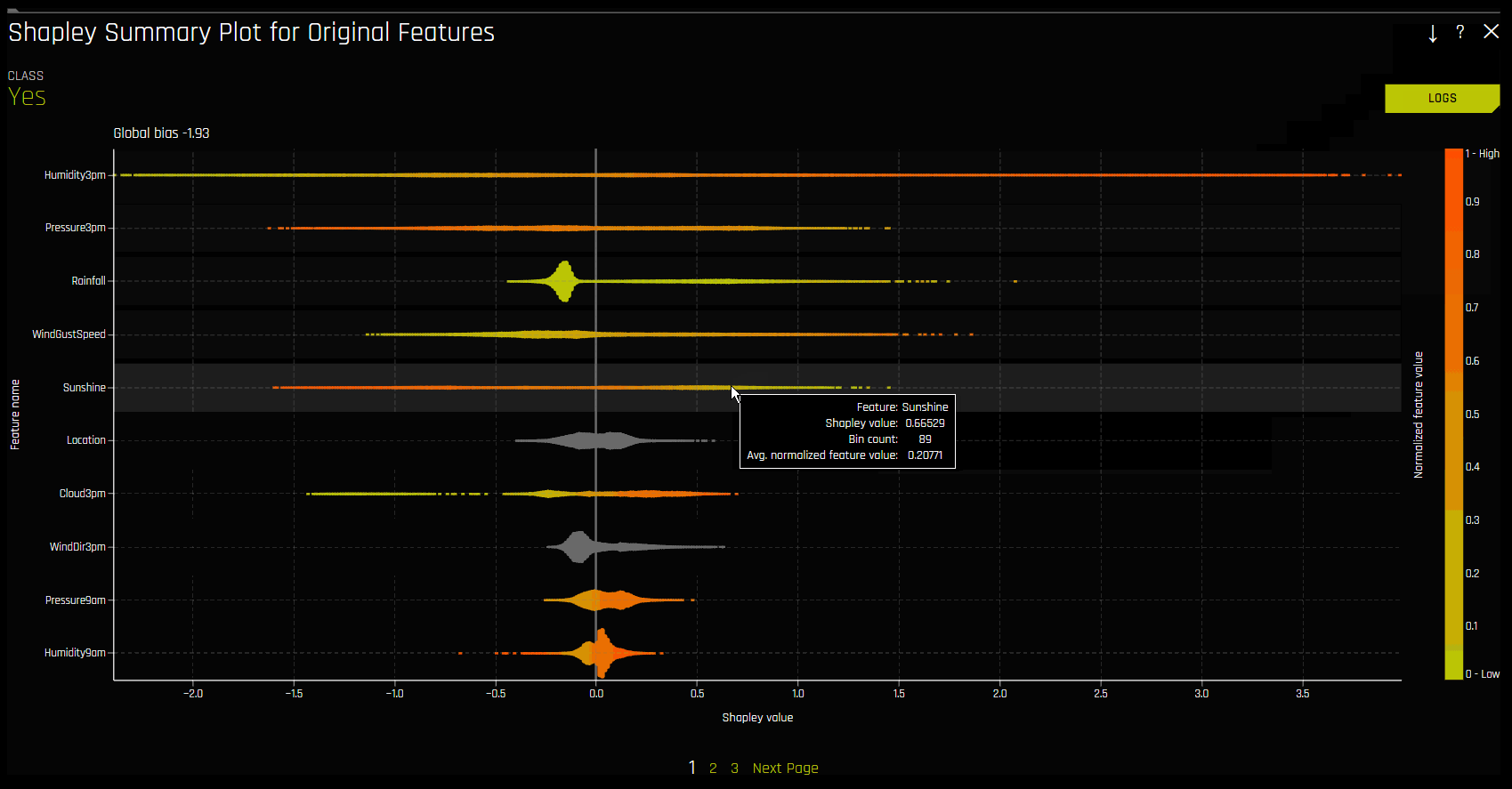
Shapley Summary Plot (Original Features)¶
Shapley Summary Plot은 데이터 세트 샘플에서 원래 특성과 로컬 Shapley 값을 보여줍니다. 특성값은 Shapley 값으로 비닝되고, 각 bin에 대해 평균 정규화된 특성값이 플로팅됩니다. 특정 특성 bin에 대한 Shapley 값, 행 수 및 평균 정규화된 특성값을 확인하려면 해당 bin 위에 포인터를 놓으십시오. 범례는 수 특성에 해당하며 정규화된 값에 매핑됩니다. 노란색이 가장 낮은 값이고 짙은 주황색이 가장 높은 값입니다. 수 특성을 클릭하면 실제 특성값 및 해당 Shapley 값의 산점도를 확인할 수 있습니다. 범주형 특성은 회색으로 표시되며 실제값 산점도는 제공하지 않습니다.
Notes:
Shapley Summary Plot은 Driverless AI 모델에서 사용되는 기존의 특성을 보여줍니다.
데이터 세트 샘플 크기 및 bin 수는 해석 상세 설정에서 업데이트가 가능합니다.
Shapley Summary Plot explainer 상세 설정 목록은 Shapley Summary Plot Explainer 설정 를 참조하십시오.
Partial Dependence (PDP) 및 Individual Conditional Expectation (ICE)¶
Partial Dependence 및 ICE 플롯은 Driverless AI 및 대리 모델 모두에 사용 가능합니다.
Partial Dependence 테크닉¶
부분 의존도는 입력 변수에 대한 평균 모델 예측의 기준입니다. 부분 의존도 플롯은 비선형성을 고려하고 기타 모든 입력 변수 효과를 평균화하면서 관심 있는 입력 변수의 값을 기초로 머신 러닝 응답 함수가 어떻게 변경되는지를 보여줍니다. 부분 의존도 플롯은 Elements of Statistical Learning(Hastie et al, 2001)에 설명되어 있습니다. 부분 의존도 플롯은 Driverless AI 모델의 투명성을 높이고 해당 도메인에서 변수의 평균 예측을 알고 있는 표준, 도메인 지식 및 합리적인 기대와 비교하여 Driverless AI 모델 검증 및 디버깅할 수 있게 합니다.
ICE 테크닉¶
이 플롯은 이진 분류 및 회귀 분석 모델에 사용이 가능합니다.
Individual Conditional Expectation (ICE) 플롯이라고도 불리는 partial dependence plot의 새로운 적응화는 partial dependence plot과 동일한 기본 아이디어를 사용하여 단일 개체에 대해 더 로컬화된 설명 생성에 사용할 수 있습니다. ICE 플롯은 Goldstein et al(2015)에 의해 설명되었습니다. ICE 값은 분리된 partial dependence이지만, ICE는 관심 변수가 해당 도메인에 따라 달라지는 동안 단일 행에 대한 모델 예측이 측정되는 유형의 비선형 sensitivity analysis이기도 합니다. ICE 플롯을 통해 사용자는 개별 데이터 행에 대한 모델 처리가 평균 모델 행동의 표준 편차를 벗어나는지 여부, 특정 행의 처리가 평균 모델 행동, 알려진 표준, 도메인 지식과 비교하여 유효한지 아닌지를 확인할 수 있고 합리적인 기대치, 그리고 선택된 행의 한 개의 변수가 도메인 전체에 걸쳐 달라지는 가정의 상황에서 모델이 어떻게 작동하는지에 대해 설명할 수 있습니다.
해당하는 Driverless AI 및 K-LIME 예측과 함께 입력 데이터 행이 주어짐:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
Driverless AI 모델을 F( X)로 취하고, 신용 점수가 학습 데이터에서 500에서 800까지 다양하며 30의 증분이 ICE 곡선을 그리는 데 사용된다고 가정할 경우, ICE는 다음과 같이 계산됩니다.
\(\text{ICE}_{credit\_score, 500} = F(30, 500, 1000)\)
\(\text{ICE}_{credit\_score, 530} = F(30, 530, 1000)\)
\(\text{ICE}_{credit\_score, 560} = F(30, 560, 1000)\)
\(...\)
\(\text{ICE}_{credit\_score, 800} = F(30, 800, 1000)\)
여기에 표시된 1차원 partial dependence plot은 상호 작용을 고려하지 않습니다. partial dependence와 ICE 사이의 큰 차이는 강력한 변수 상호 작용 존재의 가능성을 나타냅니다. 이 경우 평균 모델 행동이 로컬 행동을 정확하게 반영하지 않을 수도 있기 때문에 partial dependence plot이 잘못된 것일 수도 있습니다.
부분 의존도 플롯(PDP)¶
이 플롯은 이진 분류 및 회귀 분석 모델에 사용이 가능합니다.
Partial Dependence Plot에 ICE 플롯을 overlaying하면 특정 사례 또는 개체에 대한 Driverless AI 모델의 처리를 관심 있는 입력 변수의 도메인에 대한 모델의 평균 예측과 비교할 수 있습니다.
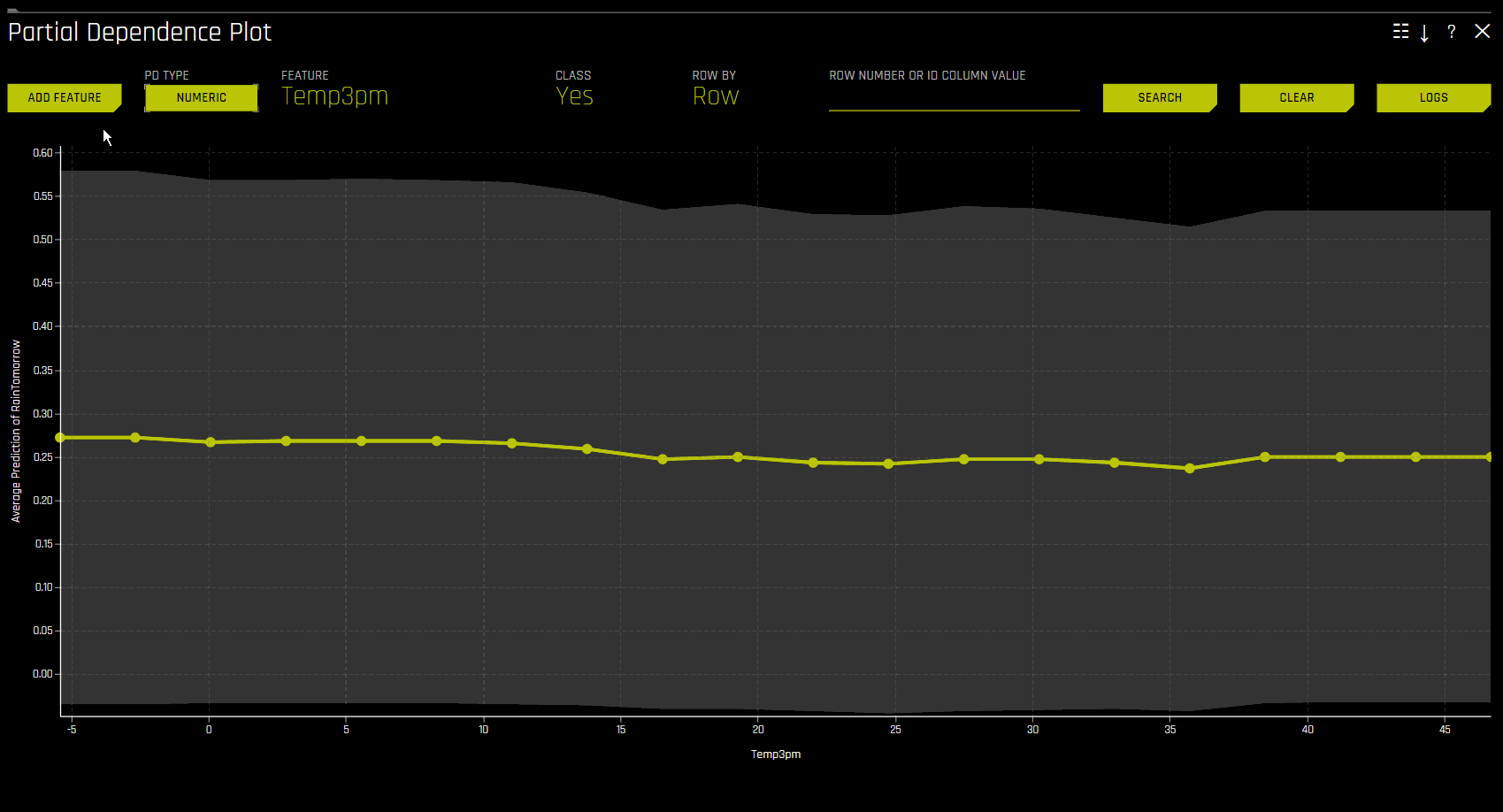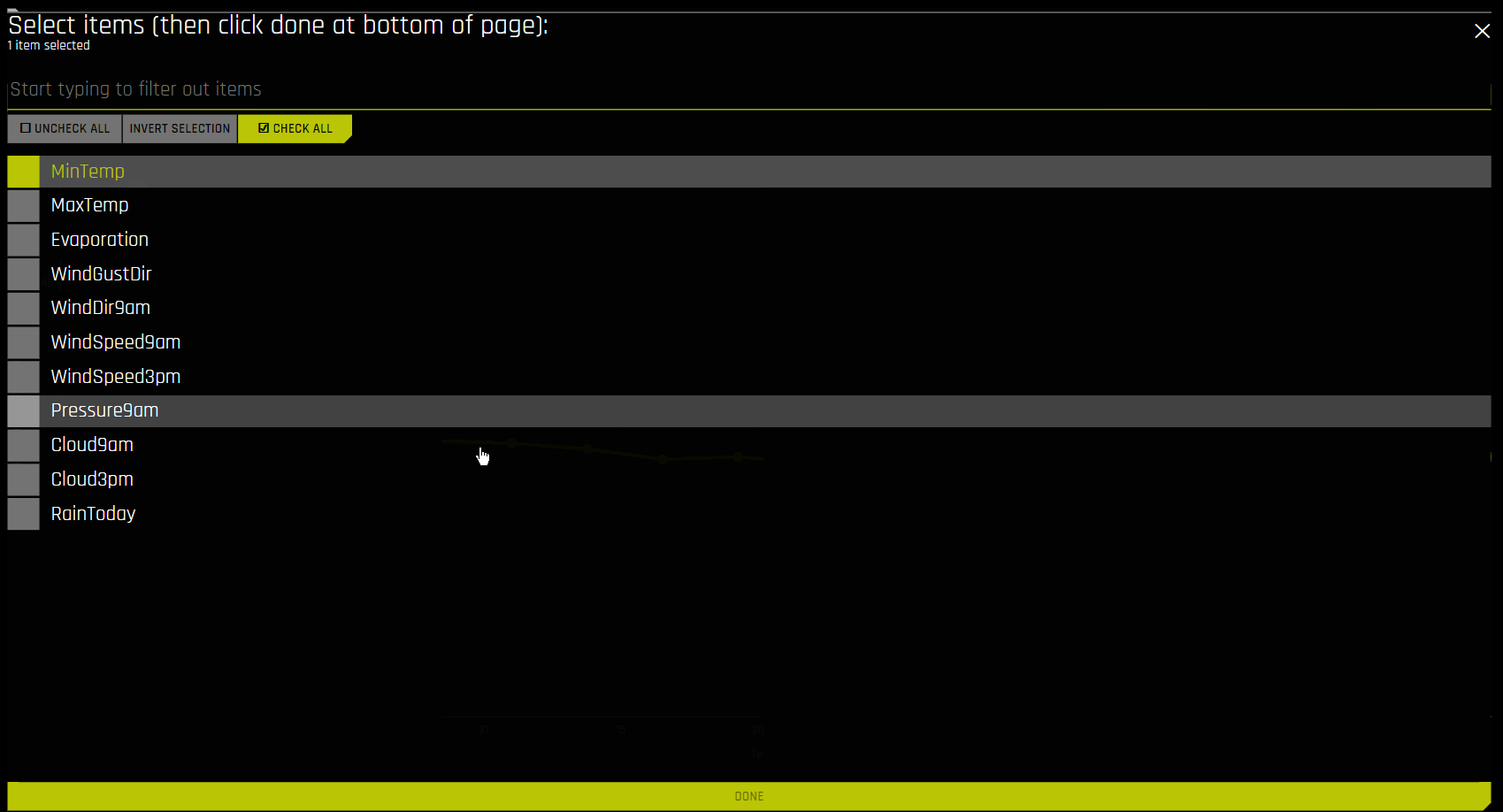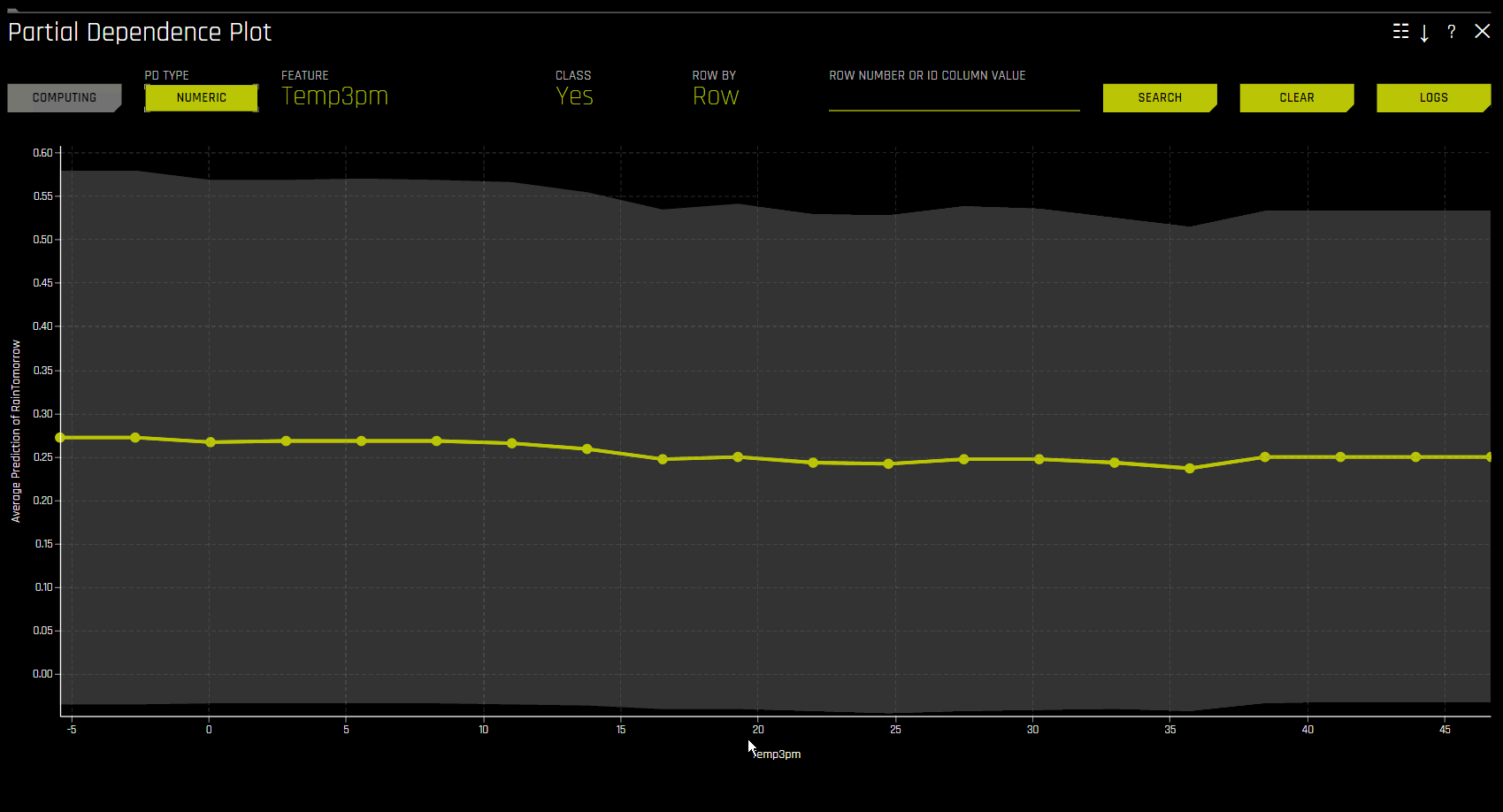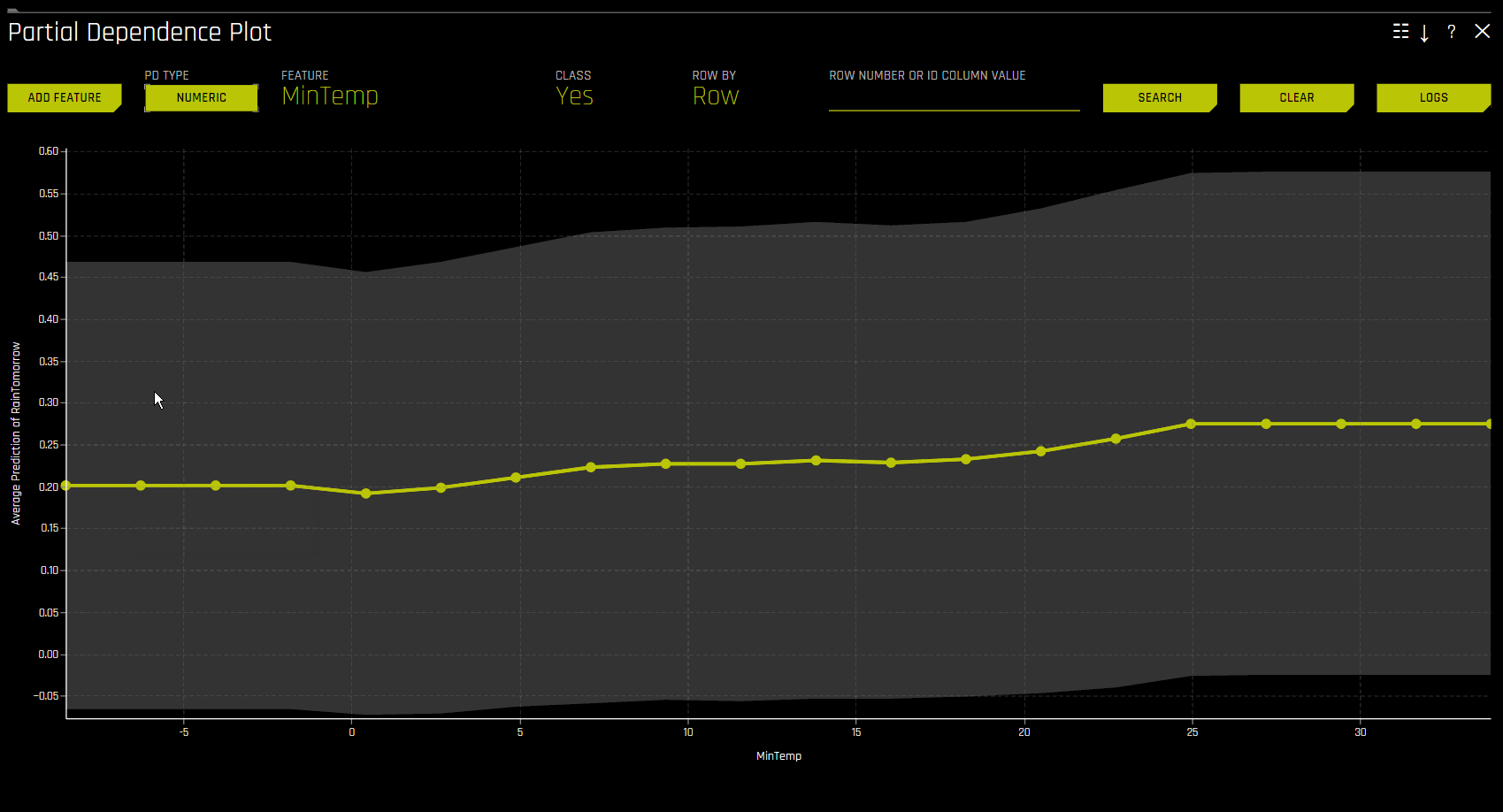
이 플롯은 변수 선택 시, partial dependence을 보여주고 특정 행 선택 시 ICE의 값을 보여줍니다. 사용자는 그래프에서 한 포인트를 선택하여 해당 포인트의 특정값을 확인할 수 있습니다. partial dependence(노란색)는 +/- 1 표준 편차 대역을 사용하여 입력 변수 도메인 전체에서 Driverless AI 모델의 평균 예측 행동을 보여줍니다. ICE(회색)는 입력 변수가 도메인 전체에 걸쳐서 전환될 때 데이터의 개별 행에 대한 예측 행동을 나타냅니다. 현재 partial dependence 및 ICE 플롯은 가장 중요한 상위 10개 기존 입력 변수에만 사용할 수 있습니다. 고유값이 20개 이상인 범주형 변수는 이러한 플롯에 포함되지 않습니다.
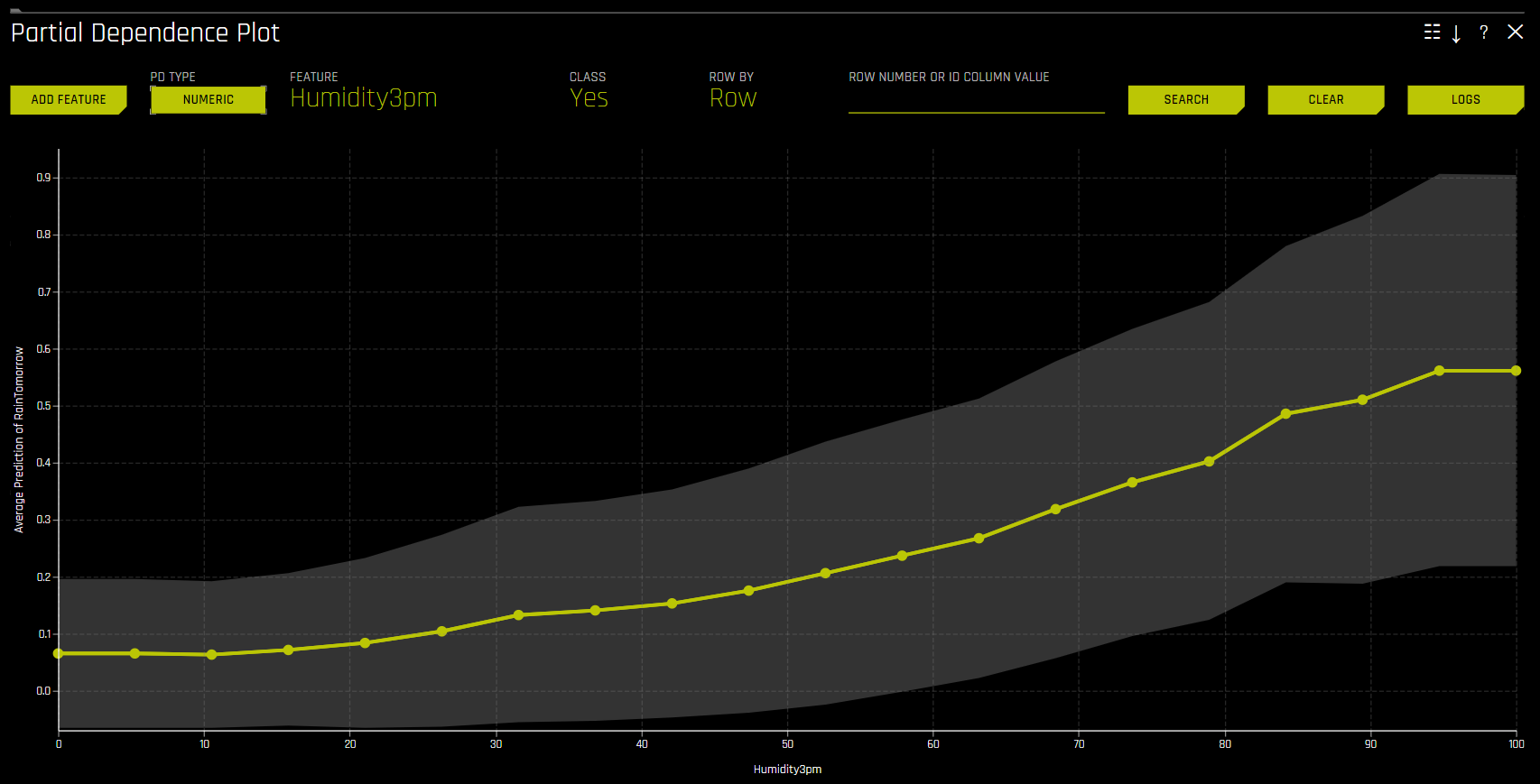
Notes:
실험에서 특성이 숫자 및 범주로 모두 사용된 경우 PDP 수 및 범주 비닝 및 UI 차트 선택 사이의 동적 전환을 사용하려면
mli_pd_numcat_num_chartconfig.toml 설정을 활성화하십시오(이 설정은 기본적으로 활성화됩니다). 해당 설정의 활성화를 통해mli_pd_numcat_threshold설정(기본값 11)으로 PDP 비닝 및 차트 선택에 대한 임계값을 지정할 수 있습니다.범위를 벗어난/보이지 않는 PD 또는 ICE bin의 수는 PDP explainer oor_grid_resolution 상세 설정을 통해 지정할 수 있습니다.
PDP explainer 상세 설정 목록은 partial dependence plot Explainer 설정 를 참조하십시오.
Partial Dependence 온디맨드¶
온디맨드 PD 옵션을 사용하면 원래 해석으로부터 Driverless AI PD/ICE를 계산할 기존 또는 새로운 특성의 선택이 가능합니다. 이 방법을 통해 PD/ICE가 임시 explainer에 의해 계산된 후 실행되고 기존의 DAI PD/ICE 표현에 병합됩니다.
PD 온디맨드 옵션을 사용하려면 사용하려는 해석을 클릭한 후, DAI Model 탭의 DAI Partial Dependence Plot 을 클릭하십시오. PD 플롯 페이지에서 Add Feature 버튼을 클릭하고 PD를 계산할 특성을 선택하십시오. Done 을 클릭하여 선택을 확인하십시오. Driverless AI가 온디맨드 계산을 완료하면 화면 밑에 알림이 나타납니다. 특정 특성에 대해 계산된 PD 값을 확인하려면 PD 플롯 페이지에서 Feature 를 클릭한 후 PD 값을 확인하려는 특성을 선택하십시오.
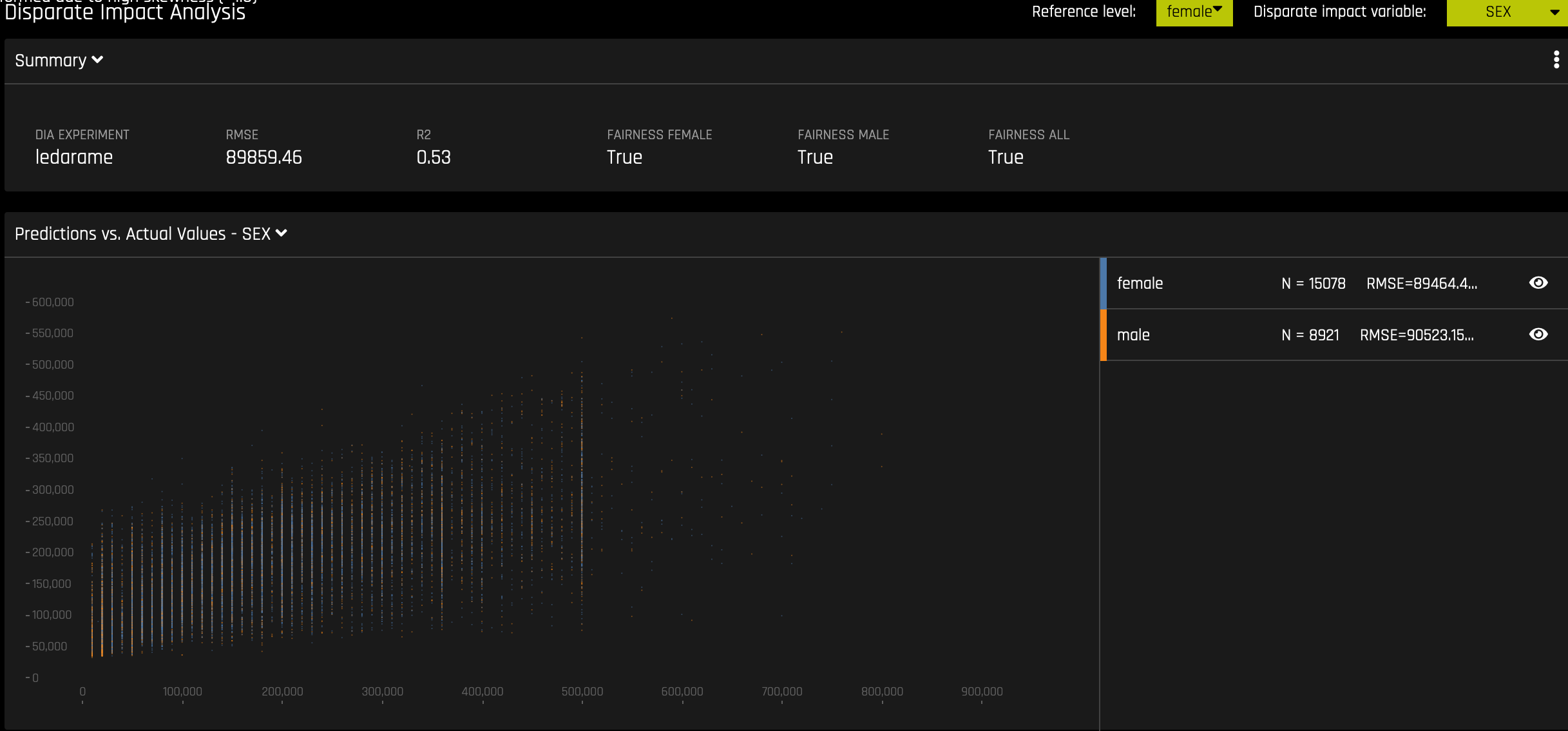
Disparate Impact Analysis(DIA)¶
이 플롯은 이진 분류 및 회귀 분석 모델에 사용이 가능합니다.
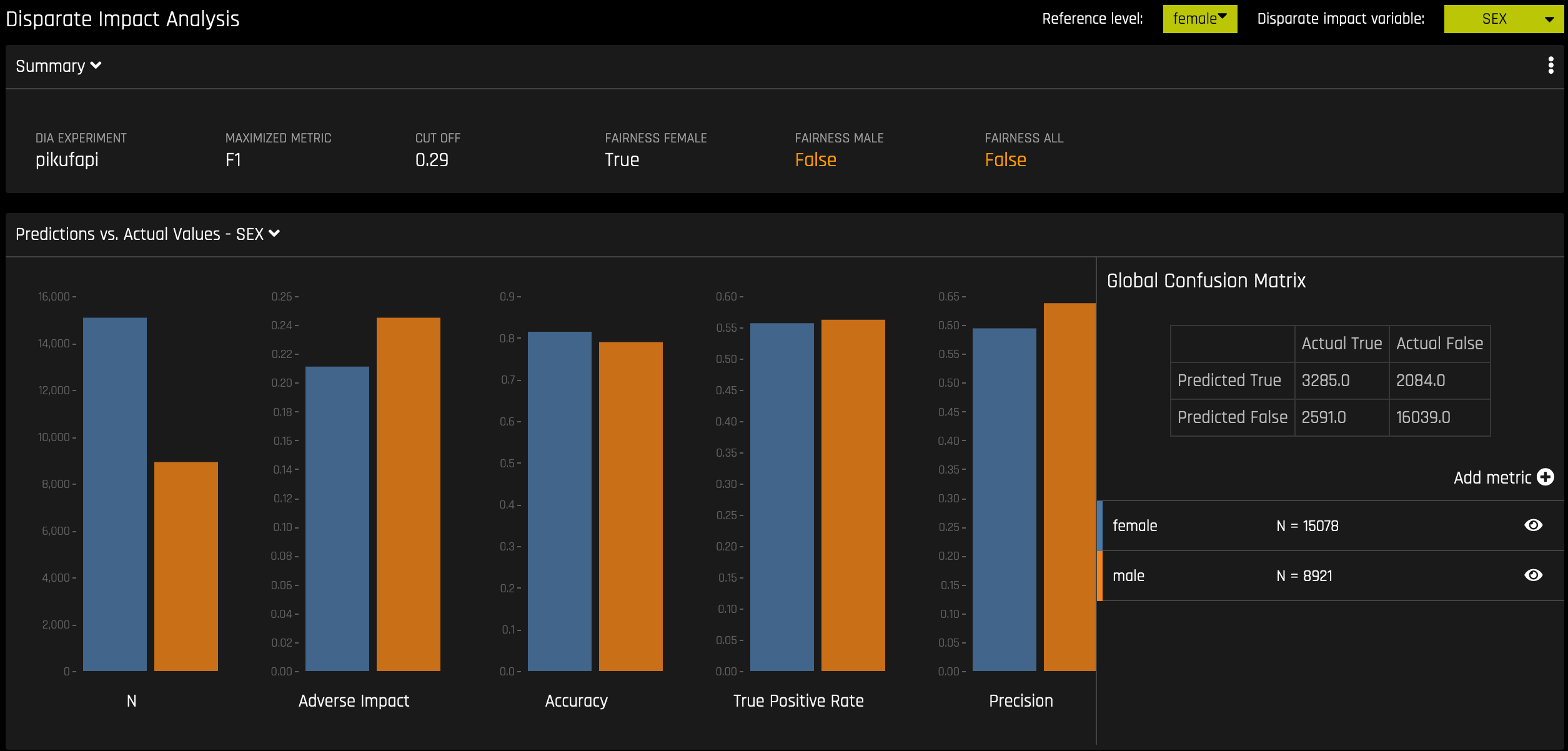
DIA는 공정성 평가에 사용되는 기술입니다. 데이터의 수집, 처리 및 레이블을 지정하는 과정에서 모델에 편향성이 생길 수 있습니다. 그 결과, 모델이 많은 수의 편향된 결정을 내림으로써 특정 사용자에게 해를 끼치는지 아닌지의 여부를 확인하는 것이 중요합니다.
DIA는 보통 unprivileged 그룹의 집계 측정값과 privileged 그룹을 비교하여 작동합니다. 예를 들어, 잠재적으로 유해한 결과를 받는 unprivileged 그룹의 비율을 동일한 결과를 받는 privileged 그룹의 비율로 나눈 후, 결과 비율을 통해 모델의 편향 여부를 결정합니다. Summary 섹션을 참조하여 범주 레벨(예: Fairness Female)이 지정된 참조 레벨 및 사용자 정의 임계값과의 비교를 통해 공정 여부를 확인합니다. Fairness All 은 참 또는 거짓 값으로 모든 범주가 참조 레벨과 비교하여 공정한 경우에만 참입니다.
Disparate impact 테스트는 선형 모델, 단조 GBM 또는 RuleFit와 같은 Driverless AI의 제한된 모델과 함께 사용하는 데 가장 적합합니다. DIA에 의해 대부분의 사례에 보고된 평균 그룹 메트릭은 특히 데이터 속성의 작은 변화에 따라 개체를 매우 다르게 취급할 수 있는 복잡하고 제약 없는 모델의 경우 로컬 차별 사례를 놓칠 수도 있습니다.
DIA를 통해 disparate impact variable (분석되는 그룹 변수), reference level (다른 그룹이 비교되는 그룹 레벨) 및 user-defined thresholds for disparity 를 지정할 수 있습니다. 분석의 일부로 여러 테이블이 제공됩니다.
Group metrics: 그룹별로 계산된 집계 메트릭입니다. 예를 들어, 그룹당 참 양성 비율입니다.
Group disparity: 이것은
metric_for_group을reference_group_metric으로 나누어서 계산합니다. 이 값이 사용자 정의 임계값을 벗어나면 불균형이 관찰됩니다.Group parity: 이것은 사용자 정의 임계값을 불균형 값에 적용하여 상기의 계산을 참 또는 거짓 값으로의 변환에 의한 그룹 불일치에 기반을 둡니다.
설정된 four-fifths rule에 따라, 사용자 정의 임계값은 기본적으로 0.8 및 1.25로 설정됩니다. 해당 임계값은 보통 모델이 비참조 그룹을 참조 그룹보다 20% 더 호의적으로 취급하는지(평균적으로) 감지합니다. 사용자는 공정성 임계값에 대한 조직의 지침에 맞도록 사용자 정의 임계값을 설정하도록 권장됩니다.
메트릭 - 이진 분류¶
다음은 이진 DIA에서 사용하는 오류 메트릭 및 parity check에 대한 공식입니다. 아래 표를 참고하십시오..
tp = 참 양성
fp = 거짓 양성
tn = 참 음성
fn = 거짓 음성
Error Metric / Parity Metric |
Formula |
부작용 |
(tp + fp) / (tp + tn + fp + fn) |
Accuracy |
(tp + tn) / (tp + tn + fp + fn) |
참 양성 비율 |
tp / (tp + fn) |
정밀도 |
tp / (tp + fp) |
특이도 |
tn / (tn + fp) |
거짓 예측값 |
tn / (tn + fn) |
거짓 양성 비율 |
fp / (tn + fp) |
거짓 발견 비율 |
fp / (tp + fp) |
거짓 음성 비율 |
fn / (tp + fn) |
거짓 누락 비율 |
fn / (tn + fn) |
Parity Check |
Description |
|
|---|---|---|
유형 I 패리티 |
FDR 패리티 및 FPR 패리티에서의 공정성 |
|
유형 II 패리티 |
FOR 패리티 및 FNR 패리티에서의 공정성 |
|
균등 확률 |
FPR 패리티 및 TPR 패리티에서의 공정성 |
|
지도 공정성 |
유형 I 및 유형 II 패리티에서의 공정성 |
|
전체 공정성 |
모든 메트릭에 대한 모든 패리티에 대한 공정성:
|
|
메트릭 - 회귀 분석¶
다음은 회귀 분석 DIA에서 사용하는 메트릭입니다.
Mean Prediction: 모든 예측의 평균값
Std.Dev Prediction: 모든 예측의 표준 편차
Maximum Prediction: 가장 높은 값을 가진 예측
Minimum Prediction: 가장 낮은 값을 가진 예측
R2: 독립 변수 또는 변수로 설명되는 종속 변수에 대한 분산의 비율을 나타내는 측정
RMSE: 모델에 의해 예측된 값 및 실제로 관찰된 값 사이의 차이 측정
공정성 메트릭¶
DIA는 이진 모델의 경우 한계 오류 (ME), Adverse Impact Ratio (AIR) 및 표준화된 평균차 (SMD), 회귀 분석 모델의 경우 SMD를 계산합니다.
ME 는 좋은 결과를 받은 통제 그룹 구성원의 비율과 좋은 결과를 받은 보호받는 클래스 구성원의 비율 사이의 차이입니다.
\[\text{ME} \equiv 100 \cdot (\text{PR} (\hat{y} = 1 \vert X_c = 1) - \text{Pr}(\hat{y} = 1 \vert X_p = 1))\]
여기서,
\(\hat{y}\) 는 모델 결정입니다.
\(X_c\) 및 \(X_p\) 는 일부 인구통계학적 속성으로부터 생성된 이진 마커입니다.
\(c\) 는 통제 그룹입니다.
\(c\) 는 보호받는 그룹입니다.
\(Pr(\cdot)\) 는 조건부 확률에 대한 오퍼레이터입니다.
AIR 는 좋은 결과를 받는 보호받는 클래스의 비율과 유리한 결과를 받은 통제 클래스의 비율과 같습니다.
\[\text{AIR} \equiv \frac{Pr(\hat{y} \; = 1 \vert X_p = 1)}{Pr(\hat{y} \; = 1 \vert X_c = 1)}\]
여기서,
\(\hat{y}\) 는 모델 결정입니다.
\(X_c\) 및 \(X_p\) 는 일부 인구통계학적 속성에서 생성된 이진 마커입니다.
\(c\) 는 통제 그룹입니다.
\(c\) 는 보호받는 그룹입니다.
\(Pr(·)\) 는 조건부 확률에 대한 오퍼레이터입니다.
SMD 는 고용 분석의 소득 차이 또는 대출의 이자율 차이와 같은 연속 특성의 불균형 평가에 사용됩니다.
\[\text{SMD} \equiv \frac{\bar{\hat y_p} - \bar{\hat y_c}}{\sigma_{\hat y}}\]
여기서,
\(\bar{\hat y_p}\) 는 평균적으로 보호받는 클래스 결과의 차이입니다.
\(\bar{\hat y_p}\) 는 통제 클래스의 결과입니다.
\(\sigma_{\hat y}\) 는 모집단의 표준 편차 측정입니다.
참고
Driverless AI에서 DIA를 구현하는 방법에 대한 자세한 정보는 아래를 참조하십시오. https://www.frontiersin.org/articles/10.3389/frai.2021.695301/full
DIA 프로세스는 모든 분류 및 회귀 분석 실험에서 같지만, 반환되는 정보는 해석 실험 유형에 따라 달라집니다. 회귀 분석 실험의 분석은 실제 대 예측 플롯을 반환하는 반면, 이진 분류 실험의 분석은 혼동 행렬을 반환합니다.
사용자가 설명 대시보드를 감안하여 disparate impact analysis의 결과를 이해하고 보완하는 것을 권장합니다. 공정성 도구로서의 확립된 사용뿐만 아니라 사용자는 더 광범위한 모델 디버깅 목적을 위해 disparate impact를 감안할 수 있습니다. 예를 들어, 사용자는 Driverless AI 모델의 중요한 비인구통계학적 특성에 대해 제공된 혼동 행렬 및 그룹 메트릭을 분석할 수 있습니다.
DIA Summary Plot explainer 상세 설정 목록은 Disparate Impact Analysis Explainer 설정 를 참조하십시오.
평균 예측 불일치는 고려 중인 그룹에 대한 평균 예측을 참조 그룹에 대한 평균 예측으로 나눈 것입니다.
그룹 불일치 및 일치에 대한 자세한 정보는 다음을 참조하십시오. https://h2oai.github.io/tutorials/disparate-impact-analysis/#5
Classification Experiment¶
Regression Experiment¶
Sensitivity Analysis (SA)¶
Note: Sensitivity Analysis (SA)는 이진 분류 및 회귀 분석 실험에만 사용이 가능합니다.
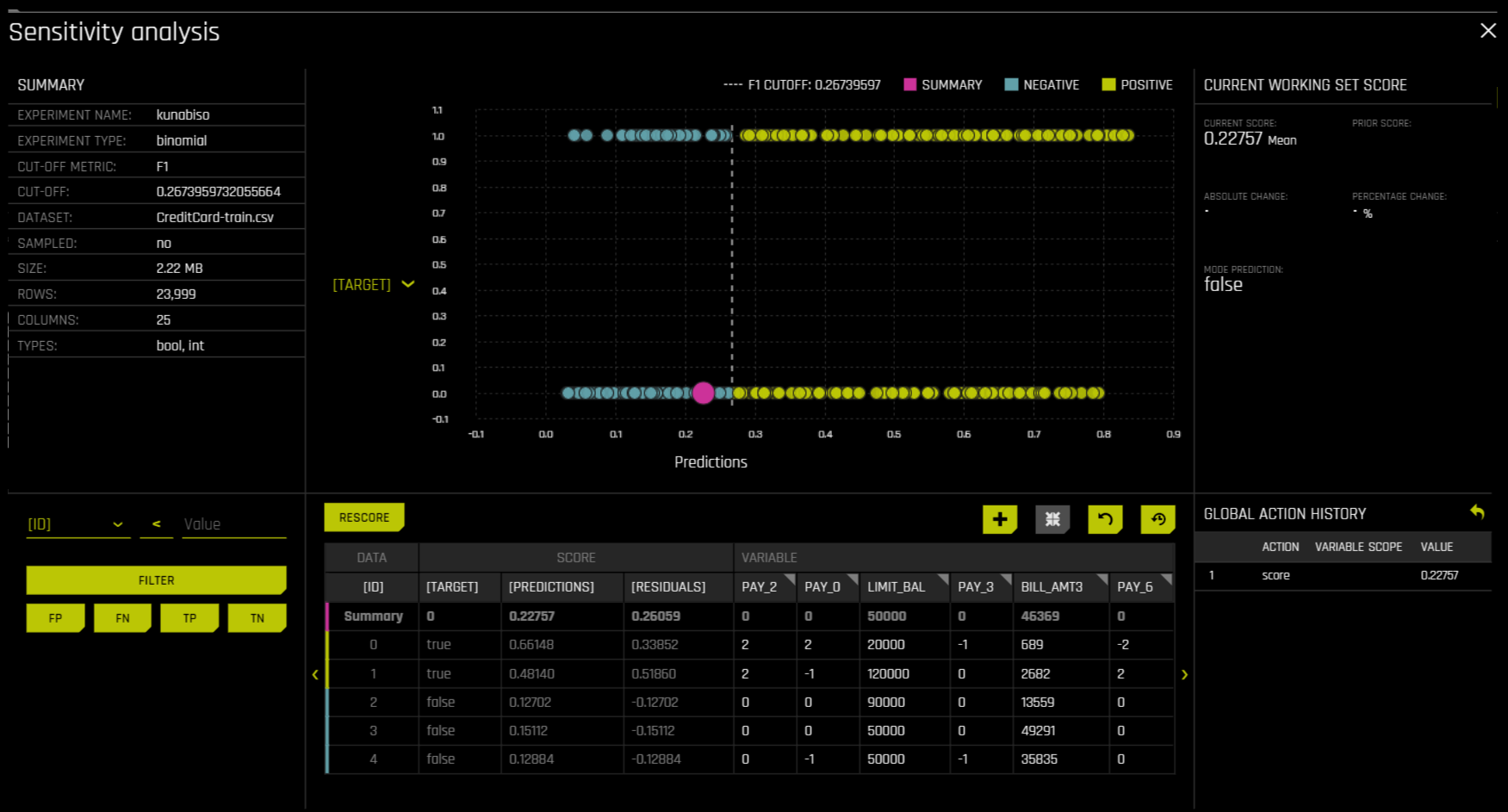
Sensitivity Analysis(또는 《What if?》)는 간단하고 강력한 모델 디버깅, 설명, 공정성 및 보안 도구입니다. SA의 기본 개념은 직접적이고 간단합니다. 학습된 모델을 단일 행, 여러 행 또는 잠재적으로 흥미로운 시뮬레이션 값의 전체 데이터 세트를 스코어링하고 모델의 새로운 결과를 기존 데이터의 예측 결과와 비교합니다.
전통적인 평가 방식을 뛰어넘어, 기계학습 모델 예측의 Sensitivity Analysis는 기계학습 모델에 대해 가장 중요한 검증 기술로 생각됩니다. Sensitivity Analysis는 데이터가 의도적으로 교란되거나 데이터에서 기타 변동에 대해 시뮬레이션 될 때 모델 행동 및 출력이 안정적인지를 조사합니다. 기계학습 모델은 입력 변수 값의 작은 변동에 대해서만 완전히 다른 예측을 할 수 있습니다. 예를 들어, 재정적 결정에 관한 예측을 확인할 때 SA는 가장 중요한 입력 변수의 변경에 따른 영향 및 사회적으로 민감한 변수(예 : 성별, 연령, 인종 등)의 변경에 따른 영향을 이해하는 데 도움을 줄 수 있습니다. 모델. 중요한 변수값이 변경될 때 모델이 합리적이고 예측 가능한 방식으로 변경되면 모델에 대한 신뢰가 상승합니다. 마찬가지로 민감한 변수에 대한 모델 변경이 모델에 최소한의 영향만을 미치는 경우 이는 모델 예측의 공정성을 나타냅니다.
이 페이지에서는 SA 정보 표시를 위해 What If Tool 을 사용합니다.
이 페이지의 상단에는 다음이 포함됩니다.
실험 요약
지정된 열에 대한 예측. Y 축의 열 변경을 통해 해당 열에 대한 예측을 확인할 수 있습니다.
현재 작업 점수 세트. 다시 스코어링할 때마다 업데이트됩니다.
이 페이지의 하단에는 다음이 포함됩니다.
분석 필터링을 위한 필터 도구. 다른 열, 예측 또는 잔차를 선택합니다. 필터 유형(
<,>, etc.)을 설정하십시오. 거짓 양성, 거짓 음성, 참 양성 또는 참 음성으로 필터링하도록 선택하십시오.채점 차트. 채점 차트를 업데이트하려면 필터 적용 후 Rescore 버튼을 클릭하십시오. 이 차트를 사용하면 변수 추가 또는 제거, 기본 차트 집계 전환, 데이터 재설정, 데이터를 재설정하는 동안 글로벌 기록 삭제 등을 수행할 수 있습니다.
이 페이지에서 수행된 현재 작업 기록입니다. 작업 선택 후 나타나는 삭제 버튼을 클릭하여 개별 작업을 삭제할 수 있습니다.
Use Case 1: Using SA on a Single Row or on a Small Group of Rows
본 섹션에서는 단일 행 또는 소규모 행 그룹에서 학습된 모델을 스코어링할 때, 설명, 디버깅, 보안 또는 공정성에 대해 SA를 사용하는 시나리오를 설명합니다.
Explanation: 변수값 변경 후, 모델을 다시 스코어링합니다. 기존 예측 및 새로운 모델 예측의 차이를 확인하십시오. 변경이 클 경우, 변경된 변수는 로컬에서 중요합니다.
Explanation: 변수값 변경 후, 모델을 다시 스코어링하십시오. 기존 예측 및 새로운 모델 예측의 차이를 확인하십시오. 그리고 변수 변경으로 인해 모델이 더 정확했는지 또는 덜 정확했는지의 여부를 결정하십시오.
Security: 변수값을 변경한 후 모델을 다시 스코어링하십시오. 기존의 예측과 새로운 모델 예측의 차이를 확인하십시오. 예를 들어, 변동이 큰 경우 사용자는 IT 부서에 해당 변수가 적대적인 공격에 사용될 수 있다고 알리거나 모델 메이커에게 해당 변수가 더 정규화되어야 한다고 전달할 수 있습니다.
Fairness: 인구통계학적 변수값을 변경한 후 모델을 다시 스코어링하십시오. 기존의 예측과 새로운 모델 예측의 차이를 확인하십시오. 변동이 큰 경우 사용자는 다른 모델을 사용하거나 모델을 더 정규화하거나 사후 편향 치료 기술의 적용을 고려해 볼 수 있습니다.
Random: 변수를 임의값으로 설정한 후 모델을 다시 스코어링하십시오. 이것은 귀하가 고려하지 못했던 것을 찾는 데 도움이 될 수 있습니다.
Use Case 2: Using SA on an Entire Dataset and Trained Model
본 섹션에서는 전체 데이터 세트 및 학습된 예측 모델에 대해 학습된 모델을 스코어링할 때 설명, 디버깅, 보안 또는 공정성을 위해 SA를 사용하는 시나리오에 관해 설명합니다.
Financial Stress Testing: 사용자가 모든 고객이 더 많은 재정적 스트레스(예: 낮은 FICO 점수, 낮은 저축 잔고, 높은 실업률 등)를 받고 있다는 것을 시뮬레이션하기 위한 전체 데이터 세트의 변경 시(학습된 기본 모델 확률을 따름) 대출 부도율이 어떻게 바뀌는지 확인하기를 원한다고 가정하십시오. 전체 데이터 세트의 변수값을 변경하고 원본 데이터 및 새로운 데이터에 대한 평균 모델 점수(기본 확률)의 Percentage Change 를 확인하십시오. 그 후, 찾아낸 정보를 외부 정보 및 프로세스와 함께 사용하여 해당 기관이 시뮬레이션 된 위기 상황에 대처할 수 있는 충분한 현금의 보유 유무를 파악할 수 있습니다.
Random: 변수를 임의의 값으로 설정한 후 모델을 다시 스코어링하십시오. 이를 통해 사용자는 자신이 고려하지 못했던 요소를 발견할 수 있습니다.
추가 리소스¶
Sensitivity Analysis on a Driverless AI Model: 이 ipynb는 UCI credit card default data 를 사용하여 sensitivity analysis 및 테스트 모델 성능을 수행합니다.
Permutation Feature Importance¶
참고
이 플롯은 이진 분류 및 회귀분석 실험에만 사용이 가능합니다.
해석에 순열 중요성이 활성화되면 원래 실험 또는 AutoDoc에 대한 실행 여부에 관계없이 해석 프로세스의 일부로 실행됩니다.
Permutation-based feature importance는 특성값이 순열에 따라 배치될 경우 모델의 성능이 얼마나 변경되는지를 보여줍니다. 특성에 예측력이 거의 없을 경우에는 값의 순서를 바꾸어도 모델의 성능에 거의 영향을 주지 않습니다. 하지만 특성의 예측 가능성이 높은 경우에는 해당 값의 순서가 바뀌면 모델의 성능이 저하됩니다. 특성에 대한 순열 전후에 걸친 모델의 성능 차이는 특성의 절대 순열 중요성을 제시합니다.
대리 모델 플롯¶
본 섹션에서 대리 모델 탭에서 사용할 수 있는 플롯에 관해 설명합니다.
K-LIME 및 LIME-SUP¶
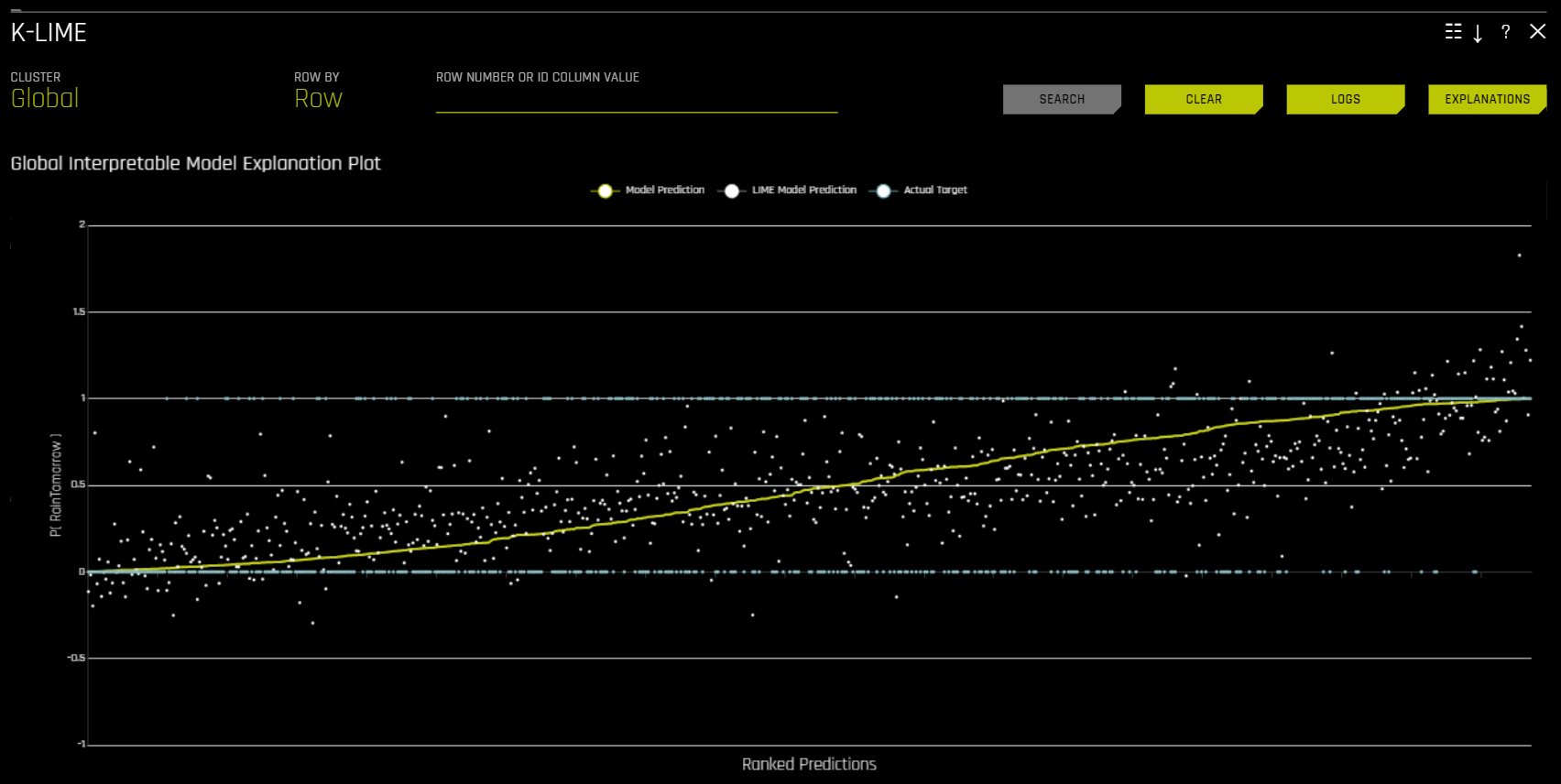
MLI 화면에는 K-LIME (K local interpretable model-agnostic) 또는 LIME-SUP (Locally Interpretable Models and Effects based on Supervised Partitioning) 그래프가 포함됩니다. K-LIME 그래프는 실험 페이지에서 모델 해석 시, 기본적으로 사용할 수 있습니다.. 새로운 해석 생성 시, LIME-SUP 대신 LIME 방법을 사용하도록 선택할 수 있습니다. 이 그래프들은 본질적으로 같지만 K-LIME/LIME-SUP 구분은 모델 해석 중에 사용된 LIME 방법에 대한 인사이트를 제공합니다.
K-LIME 테크닉¶
이 플롯은 이진 분류 및 회귀 분석 모델에 사용이 가능합니다.
K-LIME은 Ribeiro at al(2016)에서 제안한 LIME 기법의 변종입니다. K-LIME은 Driverless AI 모델의 투명성을 높이는 글로벌 및 로컬 설명의 생성 및 제공된 플롯에 대한 분석, 그리고 글로벌 및 로컬 설명을 서로 비교하거나 알려진 표준, 도메인 지식 및 합리적인 기대에 대해 서로 비교하여 모델 행동을 검증 및 디버깅할 수 있게 해줍니다.
K-LIME은 전체 학습 데이터에 하나의 글로벌 대리 GLM을 생성하고, 학습 데이터의 k-평균 클러스터에서 형성된 샘플에 많은 로컬 대리 GLM을 생성합니다. k-평균에 사용되는 특성은 Random Forest 대리 모델의 변수 중요도에서 선택됩니다. k-평균에 사용되는 특성의 수는 Random Forest 대리 모델의 변수 중요도에 있는 변수의 상위 25% 중 최솟값이며 k-평균에 사용할 수 있는 변수의 최댓값이며, 이는 mli_max_number_cluster_vars 에 대한 config.toml 설정에서 사용자에 의해 설정됩니다(참고로, 데이터 세트의 특성 수가 6 이하일 경우, 모든 특성이 k-평균 클러스터링에 사용됩니다). config.toml 파일의 use_all_columns_klime_kmeans 를 true 로 설정하여 k-평균에 대한 모든 특성을 사용할 수 있도록 이전 설정을 끌 수 있습니다. 모든 벌점 GLM 대리는 Driverless AI 모델의 예측을 모델링하도록 학습됩니다. 로컬 설명을 위한 클러스터의 수는 Driverless AI 모델 예측과 모든 로컬 K-LIME 모델 예측 사이의 \(R^2\) 값, accuracy, 예측은 모두 Driverless AI 모델의 행동에 대한 설명의 디버그 및 개발에 사용할 수 있습니다.
글로벌 K-LIME 모델의 매개변수는 입력 변수가 Driverless AI 모델 예측에 영향을 미치는 전체적인 선형 feature importance와 전체 평균 방향을 나타냅니다. 글로벌 모델은 또한 로컬 선형 모델이 적합하지 않은 매우 작은 클러스터(\(N < 20\))에 대한 설명의 생성에 사용됩니다.
클러스터 내 선형 모델 매개변수는 로컬 영역을 프로파일링하고 로컬 영역의 중요한 변수에 대한 평균 설명 제공 및 입력 변수가 Driverless AI 모델 예측에 영향을 미치는 평균 방향의 이해에 사용할 수 있습니다. 클러스터 내의 한 포인트에 대한 로컬 선형 모델 절편 및 해당 입력 변수값을 사용한 각 계수의 곱의 합이 K-LIME 예측입니다. K-LIME 예측을 개별 계수와 입력 변수 곱으로 분해하여 변수의 로컬 선형 영향을 결정할 수 있습니다. 이 곱은 때때로 사유 코드라고도 하며 Driverless AI 모델의 행동에 관한 설명 생성에 사용됩니다.
다음 예제에서는 로컬 선형 모델 평가 및 분리를 통해 사유 코드를 생성합니다.
해당하는 Driverless AI 및 K-LIME 예측과 함께 입력 데이터 행이 주어짐:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
그리고 로컬 선형 모델은 다음과 같습니다.
\(\small{y_\text{K-LIME} = 0.1 + 0.01 * debt\_to\_income\_ratio + 0.0005 * credit\_score + 0.0002 * savings\_account\_balance}\)
각 변수에 대한 로컬 선형 기여도는 다음과 같습니다.
debt_to_income_ratio: 0.01 * 30 = 0.3
credit_score: 0.0005 * 600 = 0.3
savings_acct_balance: 0.0002 * 1000 = 0.2
각 로컬 기여도는 양성이고 따라서 H2OAI_predicted_default 에 대한 Driverless AI 모델의 예측 0.85에 양성적으로 기여합니다. 각 기여의 값을 고려하여 Driverless AI 결정 사유 코드를 도출할 수 있습니다. debt_to_income_ratio 및 credit_score 는 가장 큰 두 개의 음성적인 사유 코드이고, 그 뒤에는 savings_acct_balance 가 있습니다.
로컬 선형 모델 절편 및 각 계수의 곱과 해당 값의 합이 K-LIME 예측에 포함됩니다. 또한, 이러한 선형 설명은 K-LIME 예측이 Driverless AI 모델 예측의 5.5% 내에 있기 때문에 이 개체에 대한 비선형 모델의 행동을 합리적으로 나타낸다는 것을 알 수 있습니다. 이 정보는 Explanations 버튼을 클릭하여 확인할 수 있는 영어 규칙으로 인코딩됩니다.
선형 모델을 기초로 한 모든 LIME 설명처럼, 로컬 설명은 본질적으로 선형이며 기준 예측 또는 벌점을 받은 선형 모델 잔차의 평균을 나타내는 절편으로부터 오프셋됩니다. 물론 복잡한 비선형 응답 함수에 대한 선형 근사값이 항상 적절한 설명을 만들어내는 것은 아니고, 사용자가 K-LIME 플롯, 로컬 모델 \(R^2\) 및 K-LIME 로컬 설명의 검증을 위한 K-LIME 예측의 정확성을 확인하도록 강력하게 권고합니다. 주어진 포인트 또는 포인트 세트에 대한 K-LIME accuracy가 매우 낮은 경우, 이는 극도의 비선형적 행동 또는 Driverless AI 응답 기능의 해당 로컬 영역에서 강력하거나 높은 수준의 상호 작용이 있음을 가리키는 것일 수도 있습니다. K-LIME 선형 모델이 Driverless AI 모델에 적합하지 않은 경우, 비선형 LOCO feature importance 값이 로컬 모델 행동에 대해 더 좋은 설명 도구가 될 수 있습니다. K-LIME 로컬 설명은 k-평균 클러스터 생성에 의존하기 때문에 매우 넓은 입력 데이터 또는 입력 변수 사이의 강력한 상관관계 또한 K-LIME 로컬 설명의 품질을 저해할 수 있습니다.
LIME-SUP 테크닉¶
이 플롯은 이진 분류 및 회귀 분석 모델에 사용이 가능합니다.
LIME-SUP 원래 변수 측면에서 학습된 Driverless AI 모델의 로컬 영역을 설명합니다. 로컬 영역은 원래 LIME에서와같이 시뮬레이션되고 혼란을 주기 위한 관찰 샘플 대신 decision tree 대리 모델의 각 리프 노드 경로에 의해 정의됩니다. 각 영역에 대해 로컬 GLM 모델은 원래 입력값 및 Driverless AI 모델의 예측에 대해 학습됩니다. 그 후, 이 로컬 GLM의 매개변수를 사용하여 Driverless AI 모델에 대한 대략적인 로컬 설명의 생성이 가능합니다.
The Global Interpretable Model Explanation Plot
이 플롯은 Driverless AI 모델 예측을 통해 정렬된 순서로 Driverless AI 모델 예측 및 LIME 모델 예측을 나타냅니다. 해당 그래프는 대화형입니다. Model Prediction, LIME Model Prediction 또는 Actual Target 라디오 버튼 위로 마우스의 커서를 옮기면 선택된 예측이 확대됩니다. 또는 해당 라디오 버튼을 클릭하여 그래프에서 보기를 비활성화합니다. 그래프의 아무 포인트에 마우스의 커서를 옮겨서 해당 값의 LIME 사유 코드를 확인할 수도 있습니다. 기본적으로 해당 플롯은 글로벌 LIME 모델에 대한 정보를 나타내지만, 특정 클러스터의 로컬 결과를 표시하도록 플롯 보기의 변경도 가능합니다. 또한, LIME 플롯은 Driverless AI 모델의 선형성 및 LIME 설명의 신뢰성을 시각적으로 표시합니다. 로컬 선형 모델이 Driverless AI 모델 예측에 가까울수록 Driverless AI 모델이 더 선형적이고 LIME 로컬 선형 모델에 의해 생성된 설명이 더 정확해집니다.
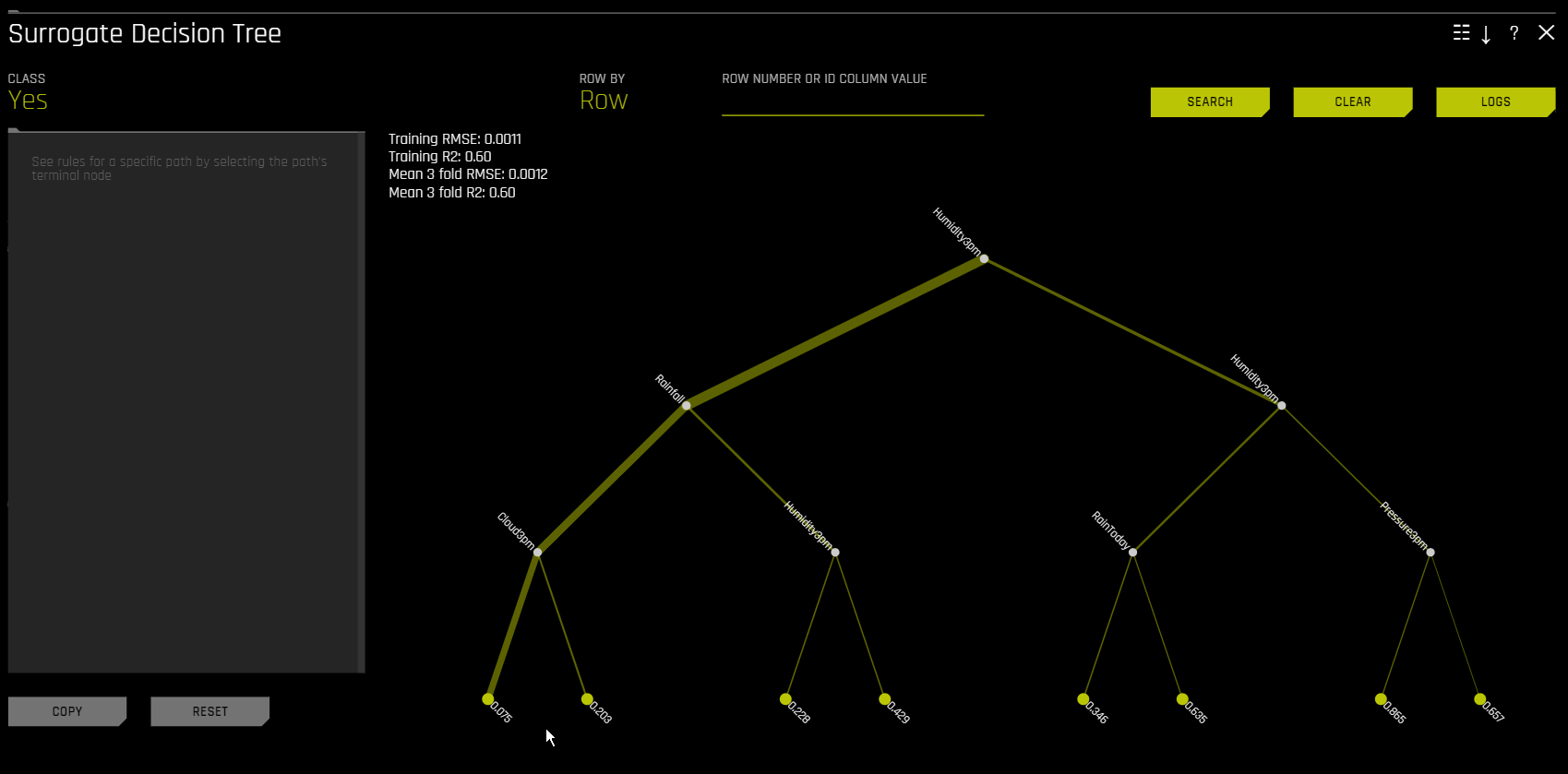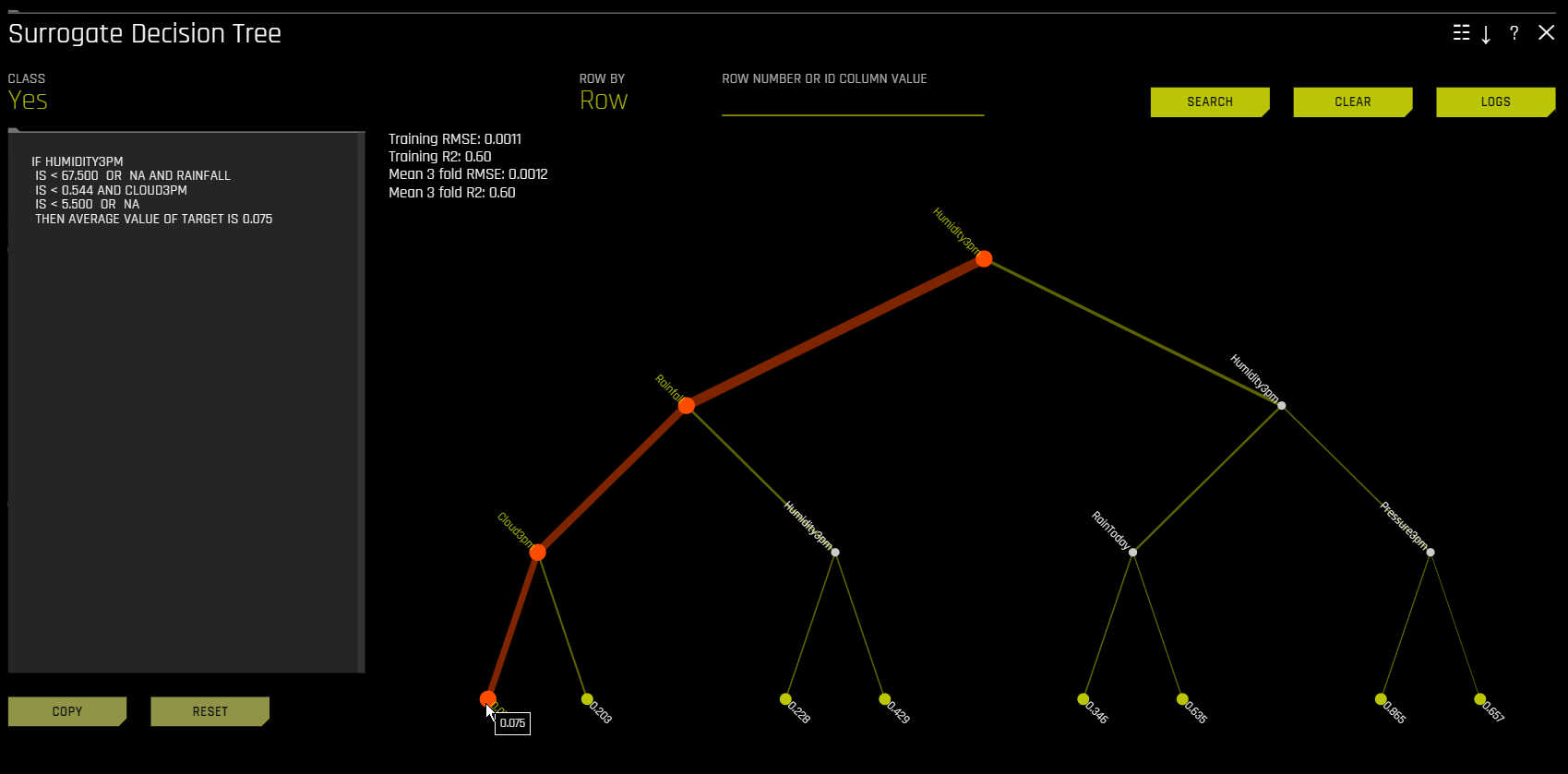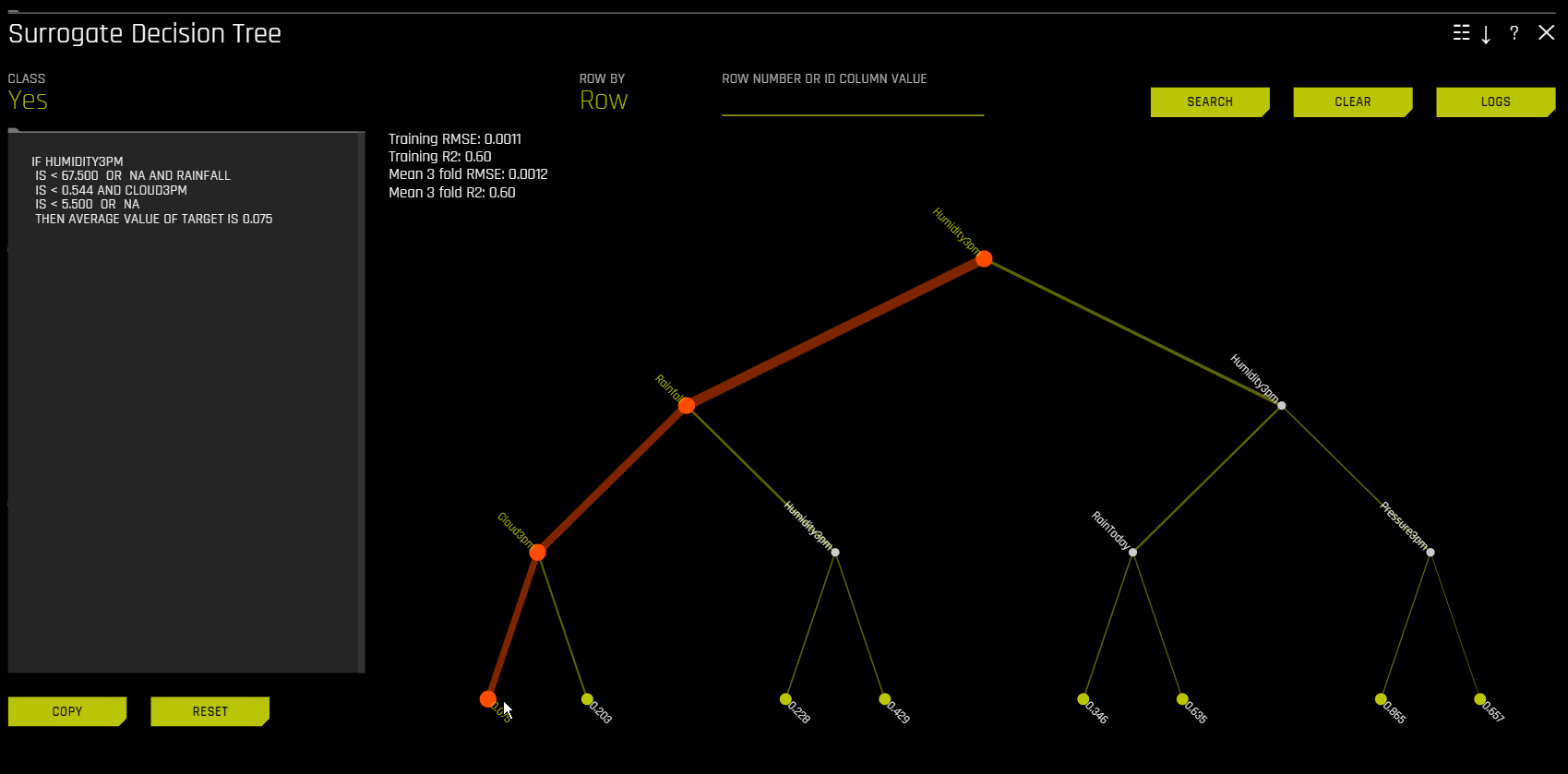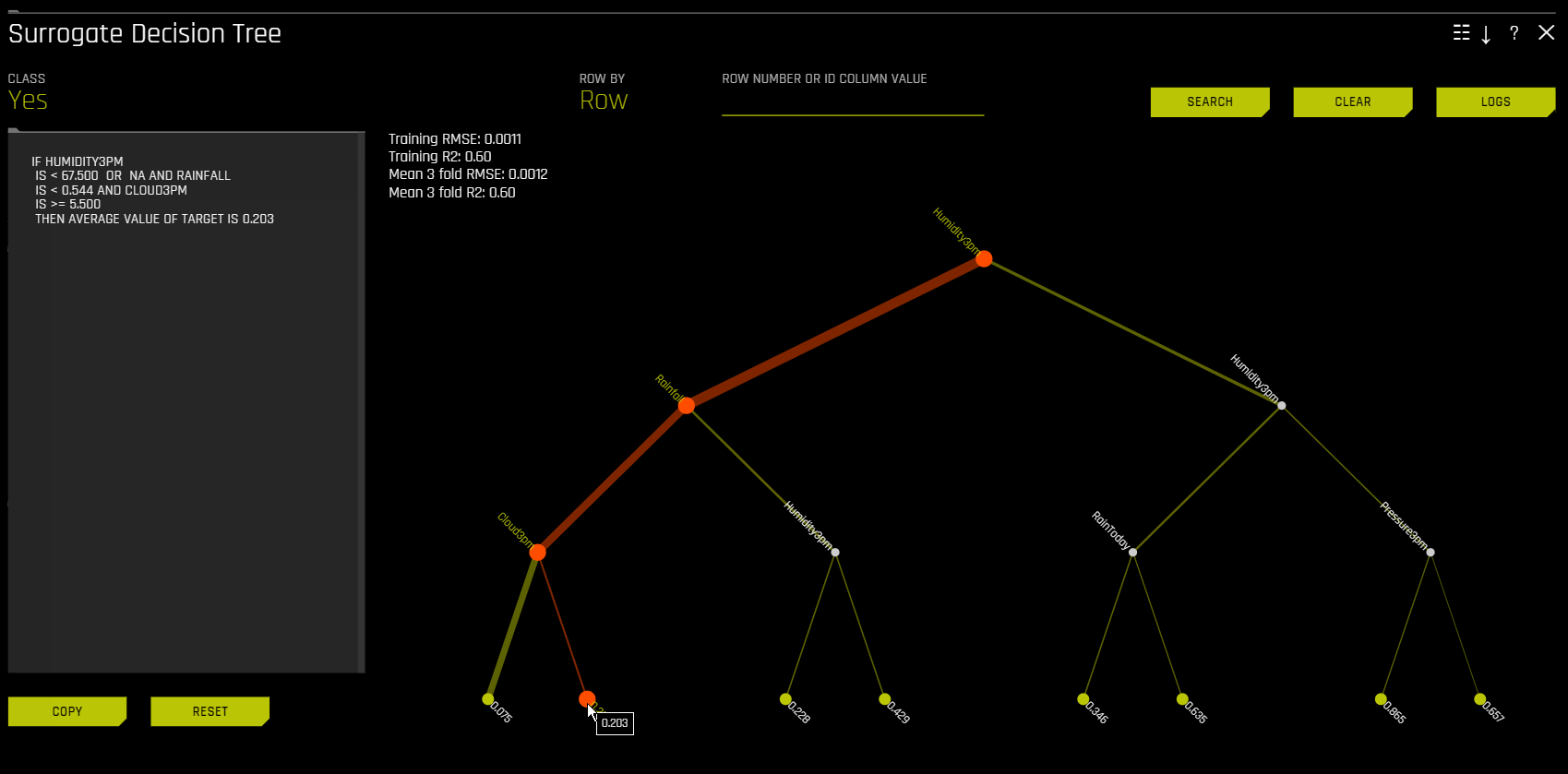
Surrogate Decision Tree¶
Decision Tree 대리 모델은 복잡한 Driverless AI 모델의 의사 결정 프로세스에 대한 approximate 흐름도를 표시하여 Driverless AI 모델의 투명성을 높입니다. 또한 Driverless AI 모델에서 가장 중요한 변수와 Driverless AI 모델에서 가장 중요한 상호 작용을 표시합니다. Decision Tree 대리 모델은 나타낸 의사 결정 프로세스, 중요한 변수 및 중요한 상호 작용을 알려진 표준, 도메인 지식 및 합리적인 기대와 비교하여 Driverless AI 모델의 시각화, 검증 및 디버깅에 사용할 수 있습니다. 이것은 최소한 1996년으로 거슬러 올라가야 하는 것으로 알려져 있습니다(Craven 및 Shavlik).
대리 모델은 보통 더 복잡한 다른 모델 또는 현상을 설명하기 위해 일반적으로 더 간단한 모델을 사용하는 데이터 마이닝 및 데이터 가공 기술입니다. 학습된 함수 \(g\), 예측 세트 그리고 \(g(X)가 주어지면 :math:\) 가 \(g(X)\) 와 거의 같도록 대리 모델 \(h\): \(X,\hat{Y} \xrightarrow{\mathcal{A}_{\text{surrogate}}} h\), such that \(h(X)\) 을 학습시키 수 있습니다. 해석 가능성의 유지를 위해 \(h\) 에 설정된 가설은 종종 선형 모델 또는 decision tree로 제한됩니다.
Driverless AI의 해석을 위해 \(g\) 는 특성 변환 및 모델을 모두 포함하는 전체 파이프라인을 대표하는 것으로 간주되며, 대리 모델은 decision tree (\(h_{\text{tree}}\))입니다. 또한, 사용자는 : math \(h_{\text{tree}}\) 가 \(g\) 를 정확하게 대표한다는 보장이 거의 없다는 점에 유의해야 합니다. \(h_{\text{tree}}\) 에 대한 RMSE는 \(h_{\text{tree}}\) 및 \(g\) 사이의 적합성 평가를 위해 표시됩니다.
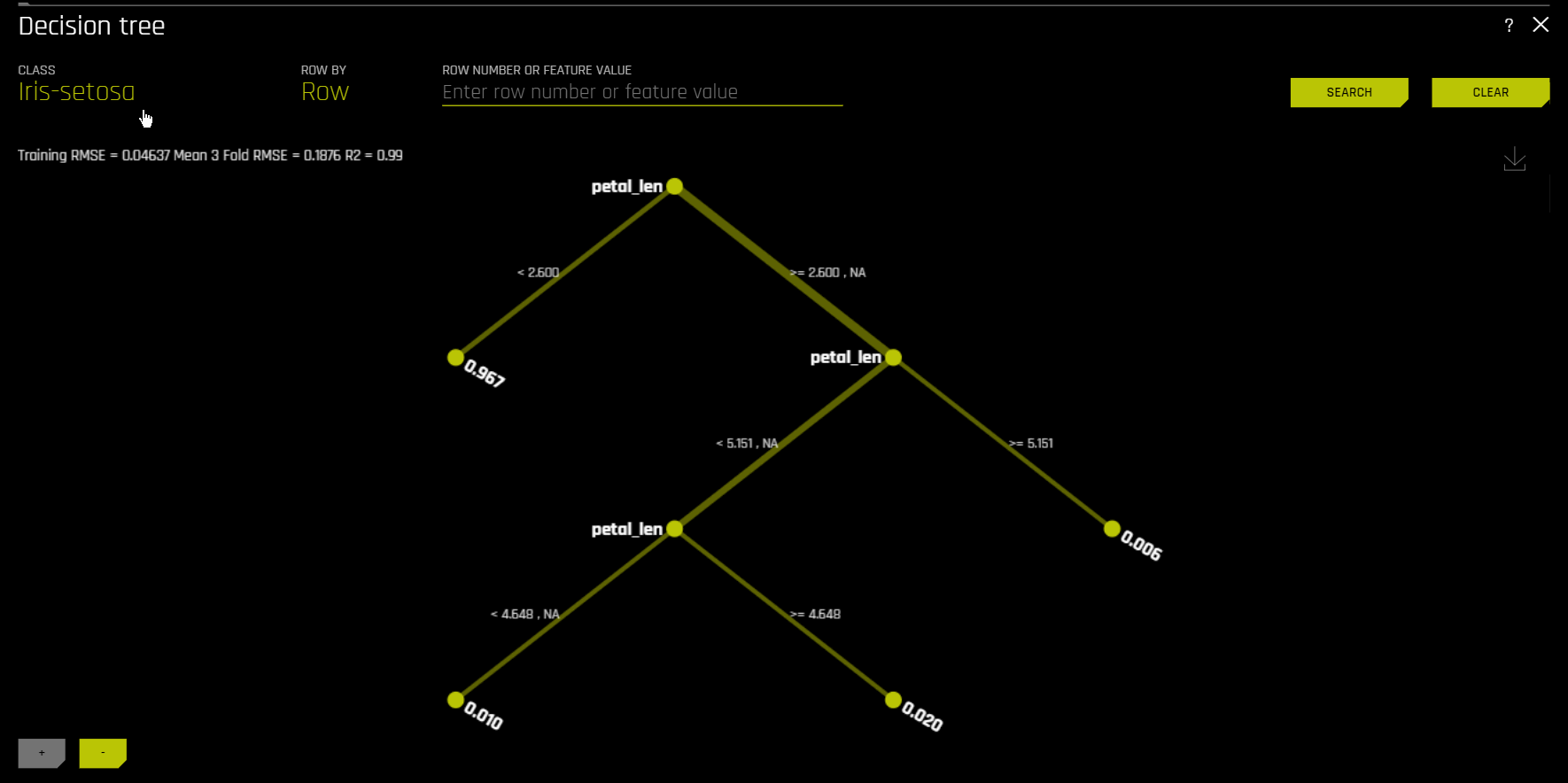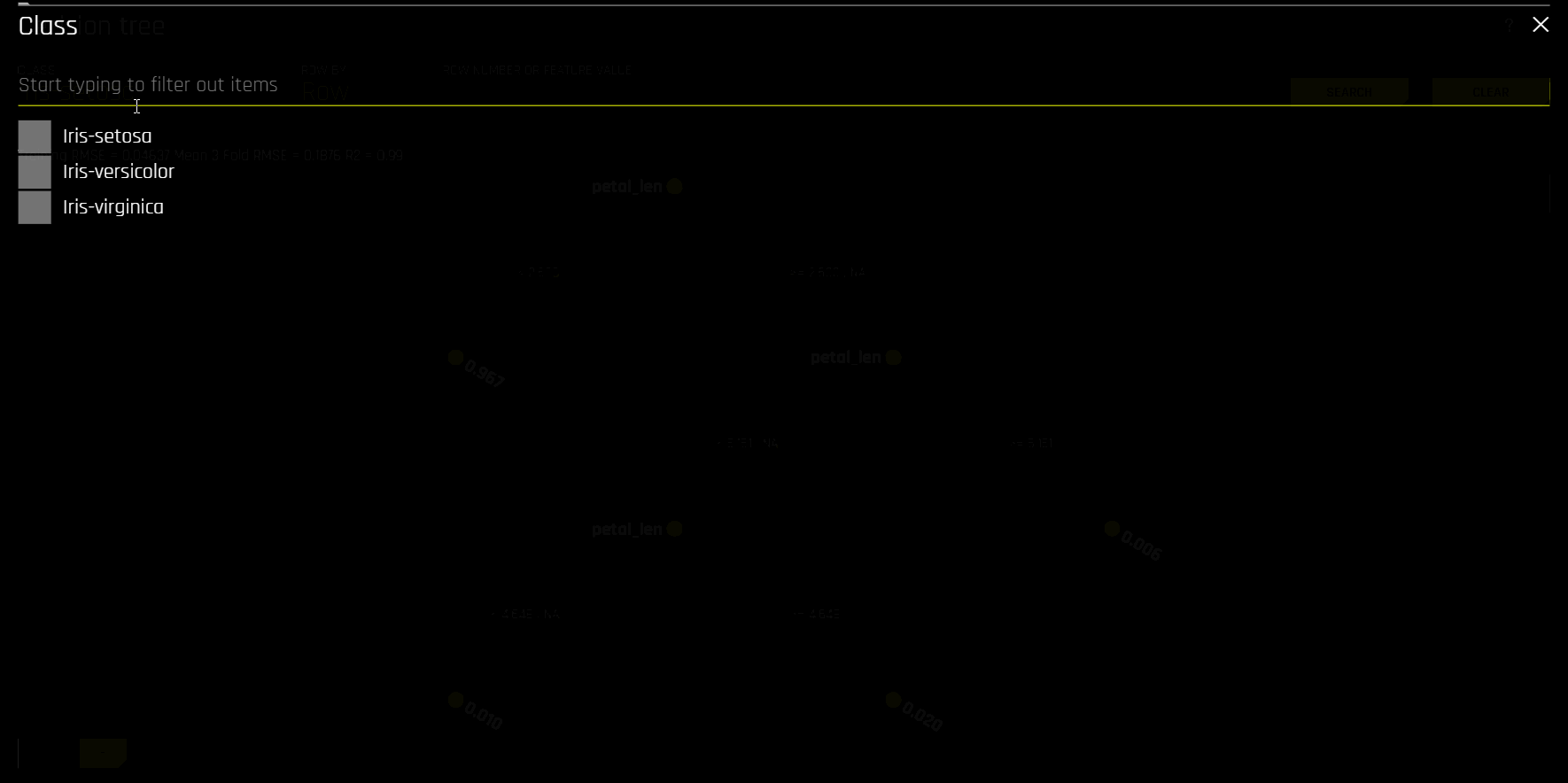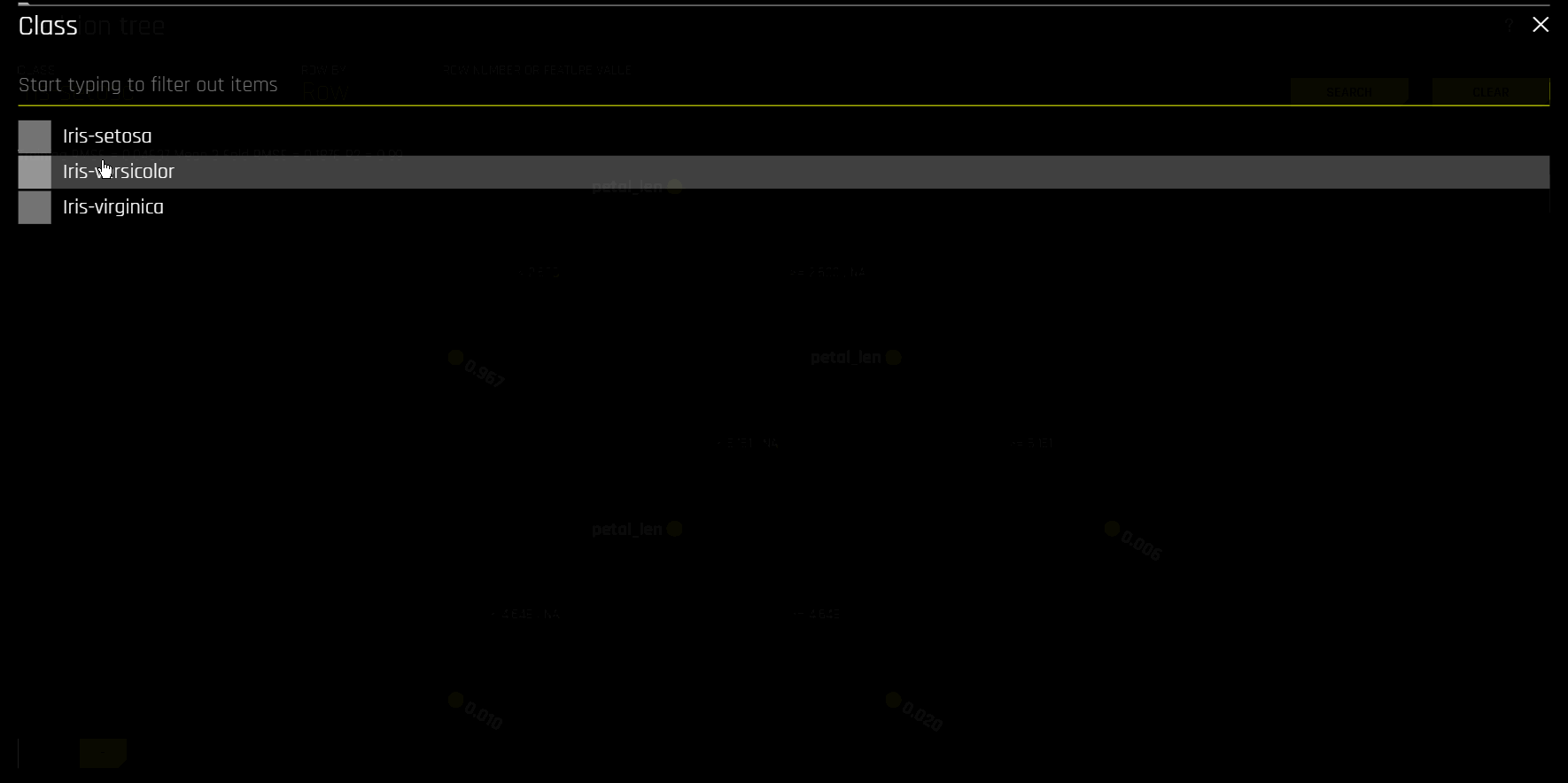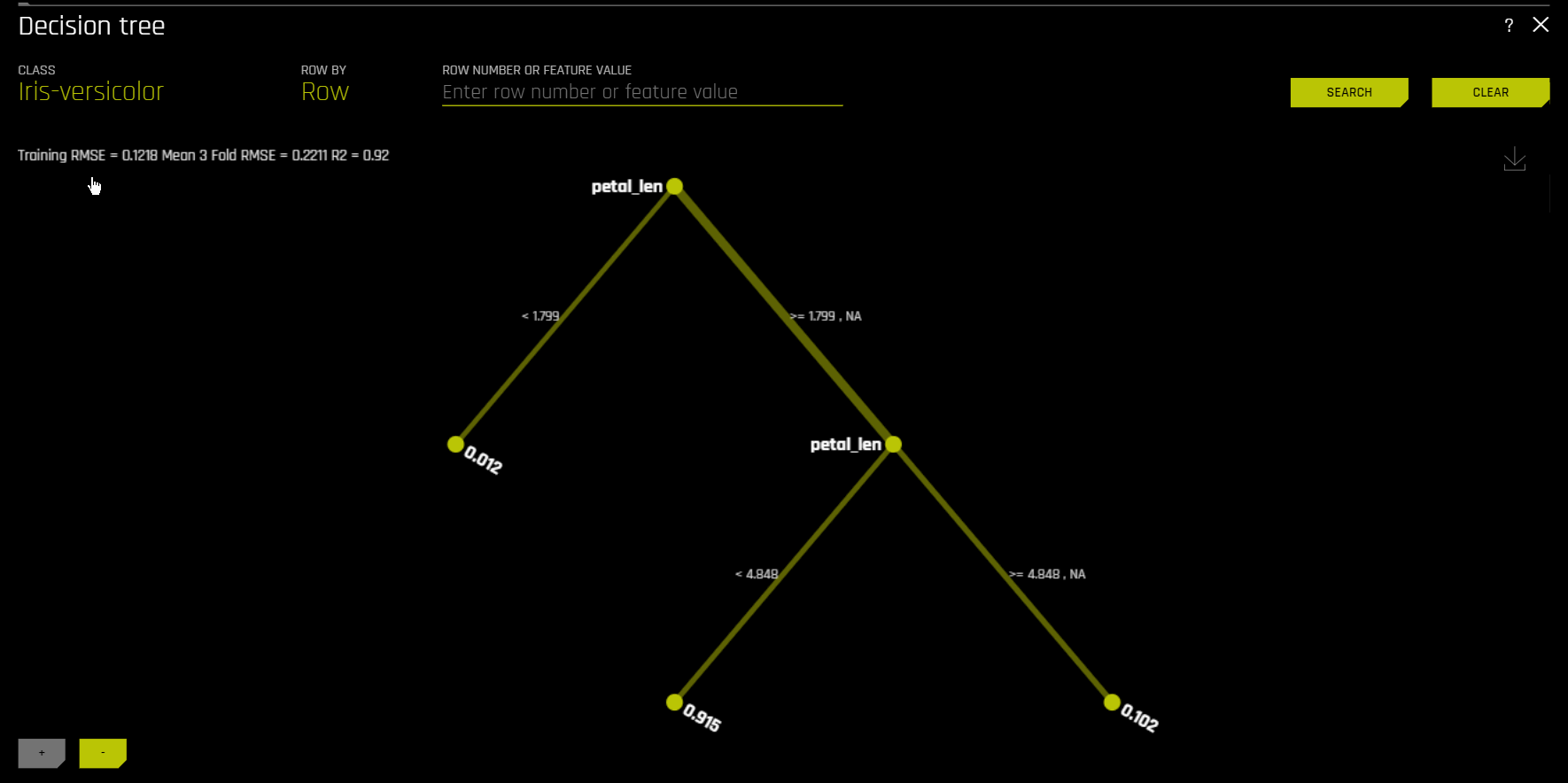
\(h_{\text{tree}}\) 는 다음 그림과 같이 \(g\) 의 의사 결정 과정에 대한 대략적인 순서도를 나타내어 \(g\) 의 투명성을 높이는 데 사용됩니다.
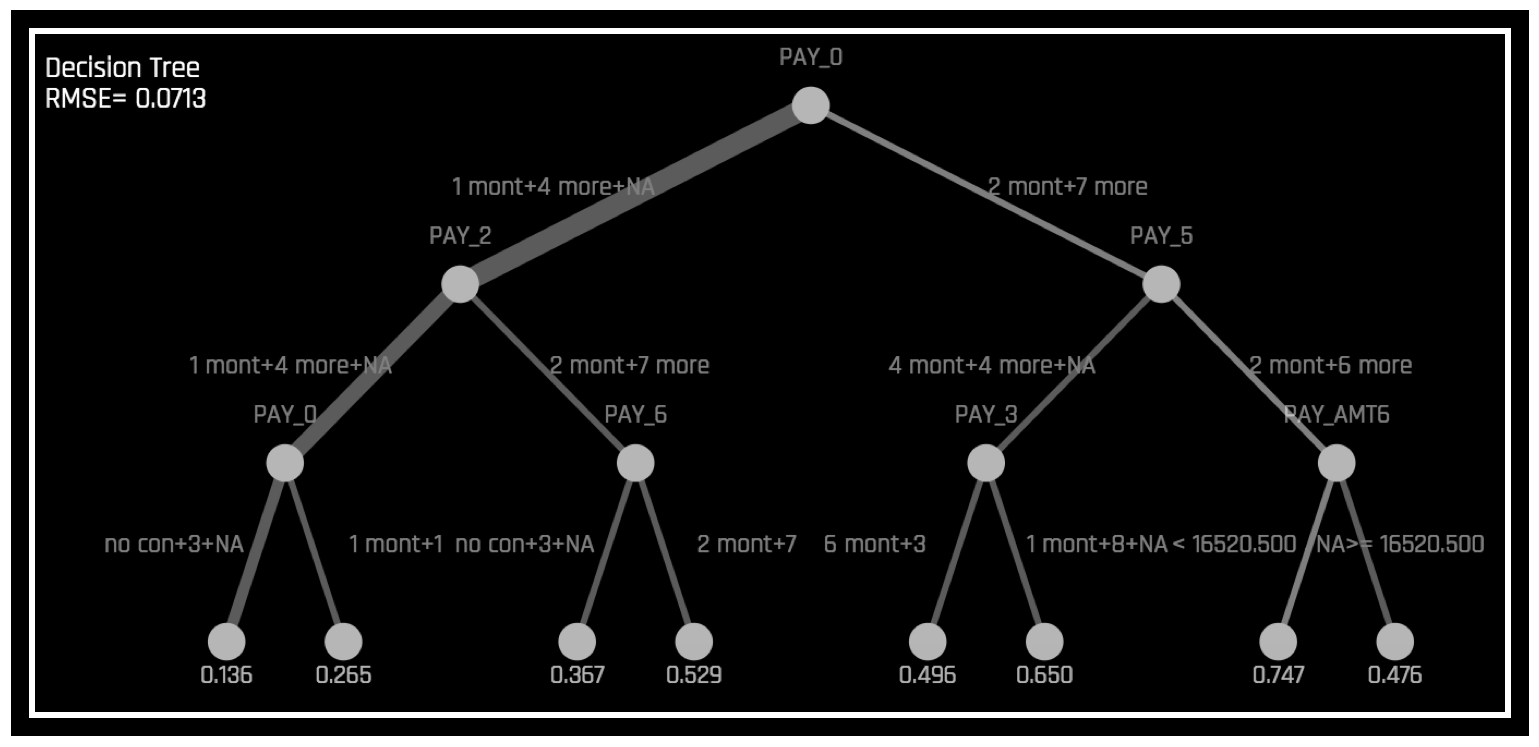
또한, \(h_{\text{tree}}\) 의 중요한 특성 및 가장 중요한 상호 작용을 보여줍니다. \(h_{\text{tree}}\) 는 표시된 의사 결정 프로세스, 중요한 특성 및 중요한 상호 작용을 알려진 표준, 도메인 지식 및 합리적인 기대치와 비교하여 \(g\) 를 시각화, 검증 및 디버깅하는 데 사용할 수 있습니다.
앞의 이미지는 UCI 리포지터리 신용 카드 기본값 데이터를 사용하여 Driverless AI로 생성된 기본 모델 확률 예제인 \(g\) 의 decision tree 대리 \(h_{\text{tree}}\) 를 표시합니다(https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset 참조). PAY_0 특성은 \(h_{\text{tree}}\) 의 초기 분할 위치 및 \(h_{\text{tree}}\) 의 세 번째에서의 두 번째 발생으로 인해 \(g\) 에서 가장 중요한 특성일 가능성이 높습니다. PAY_0 및 PAY_2 사이의 첫 번째 수준 상호 작용과 PAY_0 과 PAY_5 사이의 첫 번째 레벨의 상호 작용은 몇 가지의 두 번째 레벨 상호 작용과 함께 표시됩니다. \(h_{\text{tree}}\) (이전 이미지의 좌측 아래)에서 확률이 가장 낮은 리프 노드에 대한 결정 경로를 따르면 첫 번째 (PAY_0) 및 두 번째 (PAY_2) 월 청구서는 \(h_{\text{tree}}\) 에 따라 기본값이 될 가능성은 제일 낮습니다. 이 경로의 가장자리 두께는 이것이 \(h_{\text{tree}}\) 를 통해 매우 일반적인 결정 경로임을 나타냅니다. \(h_{\text{tree}}\) (이전 이미지 우측에서 두 번째)에서 가장 가능성이 높은 리프 노드에 대한 결정 경로를 따라가면 첫 번째 (PAY_0) 에 늦는 고객이 표시됩니다. 그리고 다섯 번째(PAY_5) 월의 청구서 및 여섯 번째 지급액 (PAY_AMT6) 에서 16520 미만을 지불하는 사람은 아래와 같이 \(h_{\text{tree}}\) 에 따라 기본값이 될 가능성이 가장 높습니다. 이 경로의 가장자리가 얇은 것은 이것이 \(h_{\text{tree}}\) 를 통해 상대적으로 드문 결정 경로임을 나타냅니다. k-LIME 플롯을 통해 데이터 관찰을 선택하면 math:h_{text{tree}} 도 일정 정도의 로컬 해석 가능성의 제공이 가능합니다. 단일 관측치인 \(x^{(i)}\) 를 선택하면 \(h_{\text{tree}}\) 를 통과하는 경로가 강조 표시됩니다. \(x^{(i)}\) 에서 \(h_{\text{tree}}까지의 경로는 :math:\) 의 논리 또는 검증 분석 시 유용할 수 있습니다.
MLI 분류: Decision Tree 대리 모델¶
Scope of Interpretability:
보통 Decision Tree 대리는 글로벌 해석 가능성을 제공합니다.
Decision Tree의 속성은 중요한 특성, 상호 작용 및 의사 결정 프로세스와 같은 복잡한 Driverless AI 모델의 글로벌 속성의 설명에 사용됩니다.
Appropriate Response Function Complexity: Decision Tree 대리 모델은 거의 모든 복잡한 모델에 관한 설명을 만들어 낼 수 있습니다.
Understanding and Trust:
Decision Tree 대리 모델은 복잡한 모델의 내부 메커니즘에 대한 인사이트를 제공하기 때문에 이해와 투명성을 발전시킵니다.
이것은 중요한 특성, 상호 작용 및 의사 결정 경로가 인간 도메인 지식 및 합리적인 기대와 맞물릴 때 신뢰, 책임 및 공정성을 향상시킵니다.
Application Domain: Decision Tree 대리 모델은 모델에 영향받지 않습니다.
Surrogate Decision Tree 플롯¶
이 플롯은 회귀 분석 모델뿐만 아니라 이진 및 다중 클래스 분류 모델에 사용할 수 있습니다.
Decision Tree 플롯에서 강조 표시된 행은 확률이 가장 높은 리프 노드에 대한 경로를 표시하고 해당 행에 대한 Driverless AI 모델 예측에 영향을 미치는 글로벌하게 중요한 변수 및 상호 작용을 나타냅니다. 경로의 터미널 노드를 클릭하여 특정 경로에 대한 규칙을 확인할 수 있습니다.
Note: Surrogate Decision Tree Explainer 상세 설정 목록은 Surrogate Decision Tree Explainer 설정 를 참조하십시오.
다중 클래스 모델의 경우, 각각의 클래스에 대한 Decision Tree가 만들어집니다. 특정 클래스의 Decision Tree를 확인하려면 페이지의 좌측 상단 모서리에 위치한 Class 를 클릭하고 Decision Tree를 확인해보려는 클래스를 선택하십시오.
Random Forest Feature Importance¶
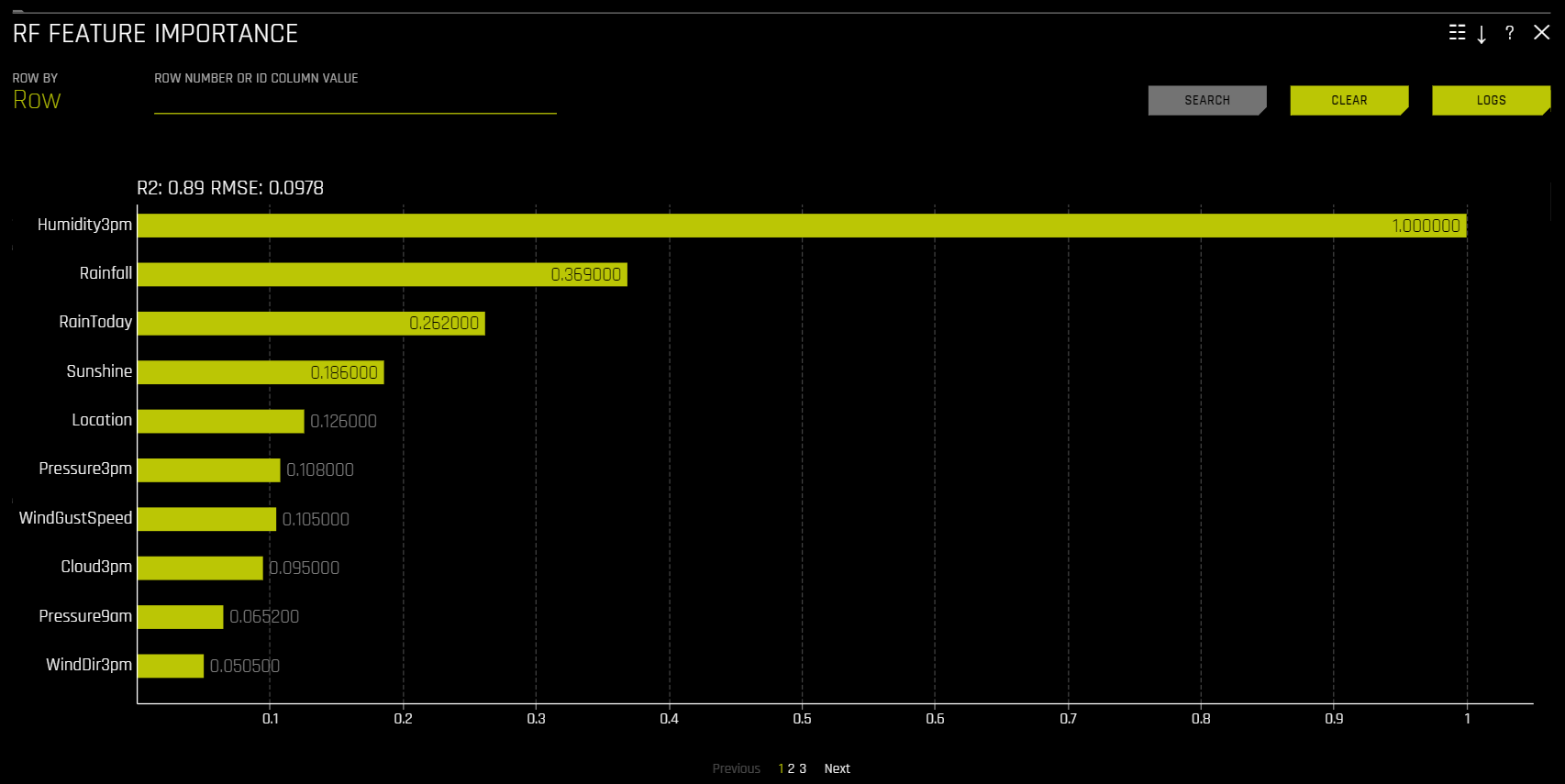
해당 플롯은 이진 분류, 다중 클래스 분류 및 회귀 분석 실험의 모든 모델에 사용할 수 있습니다.
Global Feature Importance vs Local Feature Importance
전역 기능 중요성(노란색)은 Driverless AI 모델의 전체 예측에 대한 입력 변수의 기여도를 측정한 것입니다. 전역 기능 중요성은 Random Forest 대리 모델의 모든 Decision Tree에서 단일 변수에 의한 분리 기준의 개선 집계에 의해 계산됩니다.
로컬 기능 중요성(회색)은 Driverless AI 모델의 단일 예측에 대한 입력 변수의 기여도를 측정한 것입니다. 회귀분석 및 이항 사례에 대한 로컬 기능 중요성 값은 Random Forest 대리 모델을 통해 단일 데이터 행을 추적하고 절대 LOCO 값을 반환하여 계산합니다. 다중 클래스의 경우, 훈련된 지도 모델의 채점을 다시 수행하고 각 변수를 누락으로 설정한 영향을 측정하여 로컬 기능 중요성 값을 계산합니다. 그 후 삭제되거나 대체된 각 열에 대해 클래스 간 차이의 절대값이 계산됩니다.
가장 큰 contributor가 1의 값을 갖도록 글로벌 및 로컬 변수 중요도가 모두 스케일됩니다.
Note: time series 실험의 빌드 시, MLI에 대해 가공된 특성이 사용됩니다. 이것은 원시 time series 특성이 IID(독립적이고 동일하게 분산됨)가 아니기 때문에 munged time series 특성이 원시 time series 특성보다 MLI에 더 유용한 특성이기 때문입니다.
Random Forest Partial Dependence 및 Individual Conditional Expectation¶
Partial Dependence 및 ICE 플롯은 Driverless AI 및 대리 모델 모두에 사용할 수 있습니다. 해당 플롯에 대한 자세한 내용은 이전 Partial Dependence (PDP) 및 Individual Conditional Expectation (ICE) 섹션을 참조하십시오.
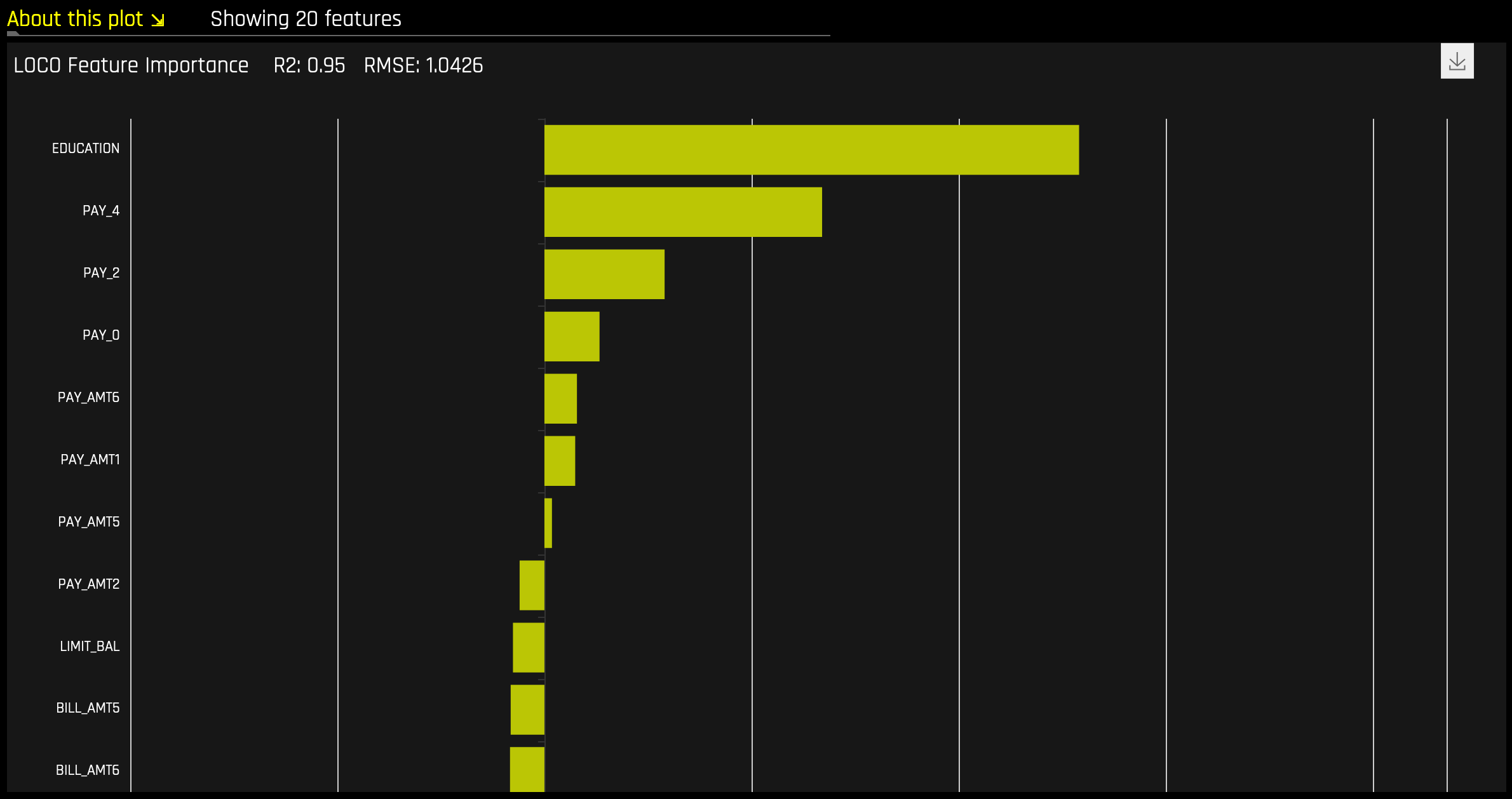
Random Forest LOCO¶
이 플롯은 회귀 분석 모델뿐만 아니라 이진 및 다중 클래스 분류 모델에 사용할 수 있습니다.
Local feature importance는 학습된 모델 규칙 또는 매개변수와 개별행 속성의 조합이 해당 행에 대한 모델 예측에 어떠한 영향을 미치는지 설명하는 동시에 비선형성 및 상호 작용을 고려합니다. 해당 플롯에 보고된 Local feature importance 값은 LOCO(leave-one-covariate-out) 방법의 변종에 기초합니다(Lei et al, 2017).
이진 및 회귀분석 모델에 대한 LOCO 변형 방법은 Random Forest 대리 모델을 탐색하고 원래 예측에서 모든 트리에 대한 관심 변수를 포함하는 규칙의 예측 기여도를 제거하여 계산됩니다. Local LOCO 값은 Random Forest 대리 모델을 통해 단일 데이터 행을 추적하여 계산됩니다. 전역 LOCO 값은 데이터 세트의 모든 행에 대한 LOCO 값의 평균입니다.
다중 클래스 모델에 대한 LOCO-변종 방법은 학습된 지도 모델을 다시 스코어링하고 각각의 변수를 결측값으로 설정하는 영향의 측정을 통해 행별 로컬 feature importance 값을 계산한다는 점에서 약간 다릅니다. 그 후, 삭제되거나 대체된 각 열에 대한 클래스에 걸친 차이의 절대값 합계가 계산됩니다.
해당하는 Driverless AI 및 K-LIME 예측과 함께 입력 데이터 행이 주어짐:
debt_to_income_ ratio |
credit_ score |
savings_acct_ balance |
observed_ default |
H2OAI_predicted_ default |
K-LIME_predicted_ default |
|---|---|---|---|---|---|
30 |
600 |
1000 |
1 |
0.85 |
0.9 |
Driverless AI 모델을 F( X)로 취하면, LOCO-변종 feature importance 값은 아래와 같이 계산됩니다.
첫째, 수정된 예측이 계산됩니다.
\(F_{~debt\_to\_income\_ratio} = F(NA, 600, 1000) = 0.99\)
\(F_{~credit\_score} = F(30, NA, 1000) = 0.73\)
\(F_{~savings\_acct\_balance} = F(30, 600, NA) = 0.82\)
둘째, 기존의 예측은 스케일되지 않은 로컬 feature importance 값을 생성하기 위해 각각 수정된 예측에서 차감됩니다 .
\(\text{LOCO}_{debt\_to\_income\_ratio} = F_{~debt\_to\_income\_ratio} - 0.85 = 0.99 - 0.85 = 0.14\)
\(\text{LOCO}_{credit\_score} = F_{~credit\_score} - 0.85 = 0.73 - 0.85 = -0.12\)
\(\text{LOCO}_{savings\_acct\_balance} = F_{~savings\_acct\_balance} - 0.85 = 0.82 - 0.85 = -0.03\)
마지막으로 LOCO 값은 행의 각 값을 행의 최대 값으로 나누고 이 몫의 절대 크기를 취하여 0과 1 사이에서 스케일됩니다.
\(\text{Scaled}(\text{LOCO}_{debt\_to\_income\_ratio}) = \text{Abs}(\text{LOCO}_{~debt\_to\_income\_ratio}/0.14) = 1\)
\(\text{Scaled}(\text{LOCO}_{credit\_score}) = \text{Abs}(\text{LOCO}_{~credit\_score}/0.14) = 0.86\)
\(\text{Scaled}(\text{LOCO}_{savings\_acct\_balance}) = \text{Abs}(\text{LOCO}_{~savings\_acct\_balance} / 0.14) = 0.21\)
이러한 LOCO 변종 feature importance 값의 한 가지 단점은 K-LIME과 다르게 LOCO 값에 의문이 생길 때 이를 나타내는 수학적 오류 비율의 생성이 어렵다는 것입니다.
NLP Surrogate 모델¶
이러한 플롯은 자연어 처리(NLP) 모델에 사용할 수 있습니다.
NLP Surrogate 모델의 경우, Driverless AI는 모든 텍스트 특성을 토큰화하여 TF-IDF 매트릭스를 생성합니다. 결과 프레임은 학습 데이터 세트의 숫자 또는 범주 열에 추가되고 원본 텍스트 열은 제거됩니다. 그 후, 해당 프레임은 토큰 및 원래의 숫자 또는 범주 기능으로 구성된 예측 열이 있는 대리 모델의 학습에 사용됩니다.
Notes:
NLP에 대한 MLI 지원은 이진 분류 및 회귀 분석 실험에만 사용이 가능합니다.
TF-IDF 행렬의 각 행에는 \(N\) 열이 포함되어 있습니다. 여기서 \(N\) 은 해당 행에 대해 적합한 값을 포함한 말뭉치의 총 토큰 수입니다(부재 시 0).
Driverless AI는 현재 MLI NLP 문제에 대한 K-LIME 스코어링 파이프라인을 생성하지 않습니다.
잔차에서 Surrogate Model 실행¶
Driverless AI에서 잔차(관측값과 예측값의 차이)는 모델 디버깅을 위해 MLI surrogate model에서 대상으로 사용할 수 있습니다. 잔차의 계산에 사용되는 방법은 문제 유형에 따라 달라집니다. 분류 문제일 경우, 지정된 클래스에 대한 logloss 잔차가 계산됩니다. 회귀 분석 문제의 경우, 목표값 및 예측값 사이의 차이의 제곱을 계산하여 잔차가 결정됩니다.
잔차에 대한 MLI surrogate model 모델을 실행하려면 Debug Model Residuals 해석 상세 설정을 활성화하십시오. 분류 실험의 경우, Class for Debugging Classification Model Logloss Residuals 해석 상세 설정을 사용하여 관심 결과로 사용할 클래스를 지정하십시오(회귀 분석 문제에는 표시되지 않음). 해석 완료 시, Surrogate Models on Residuals 탭을 클릭하여 모델을 확인할 수 있습니다.

NLP 플롯¶
본 섹션에서는 NLP 탭에서 사용할 수 있는 플롯에 관해 설명합니다.
참고
다음 플롯은 자연어 처리(NLP) 모델에 대해서만 사용할 수 있습니다.
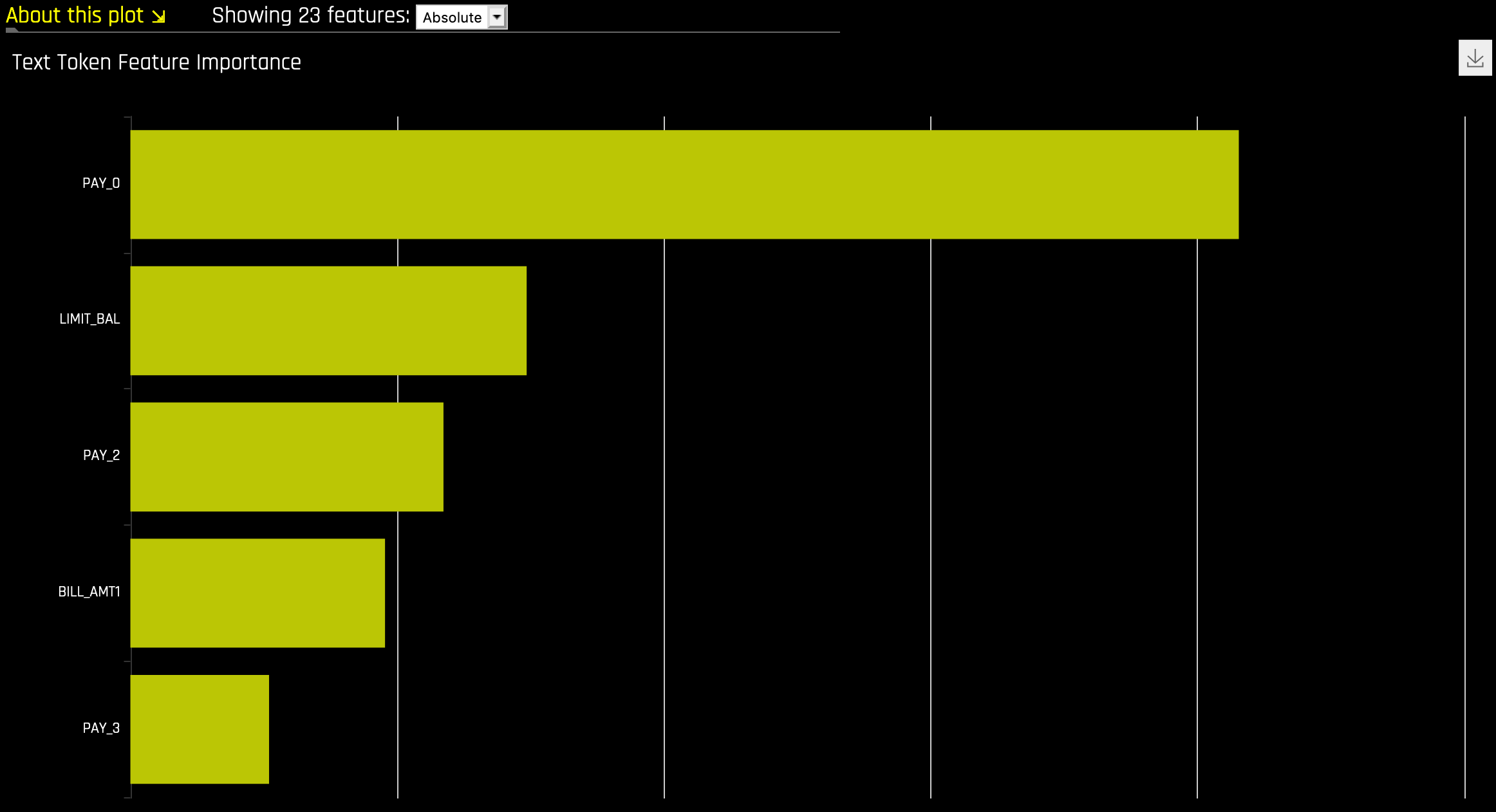
NLP Leave-One-Covariate-Out (LOCO)¶
이 플롯은 이항, 다중 클래스, 회귀분석 자연어 처리(NLP) 모델에 사용할 수 있습니다. 이것은 모델 해석 페이지의 ** NLP** 탭에 위치하며 이는 NLP 모델에서만 표시됩니다.
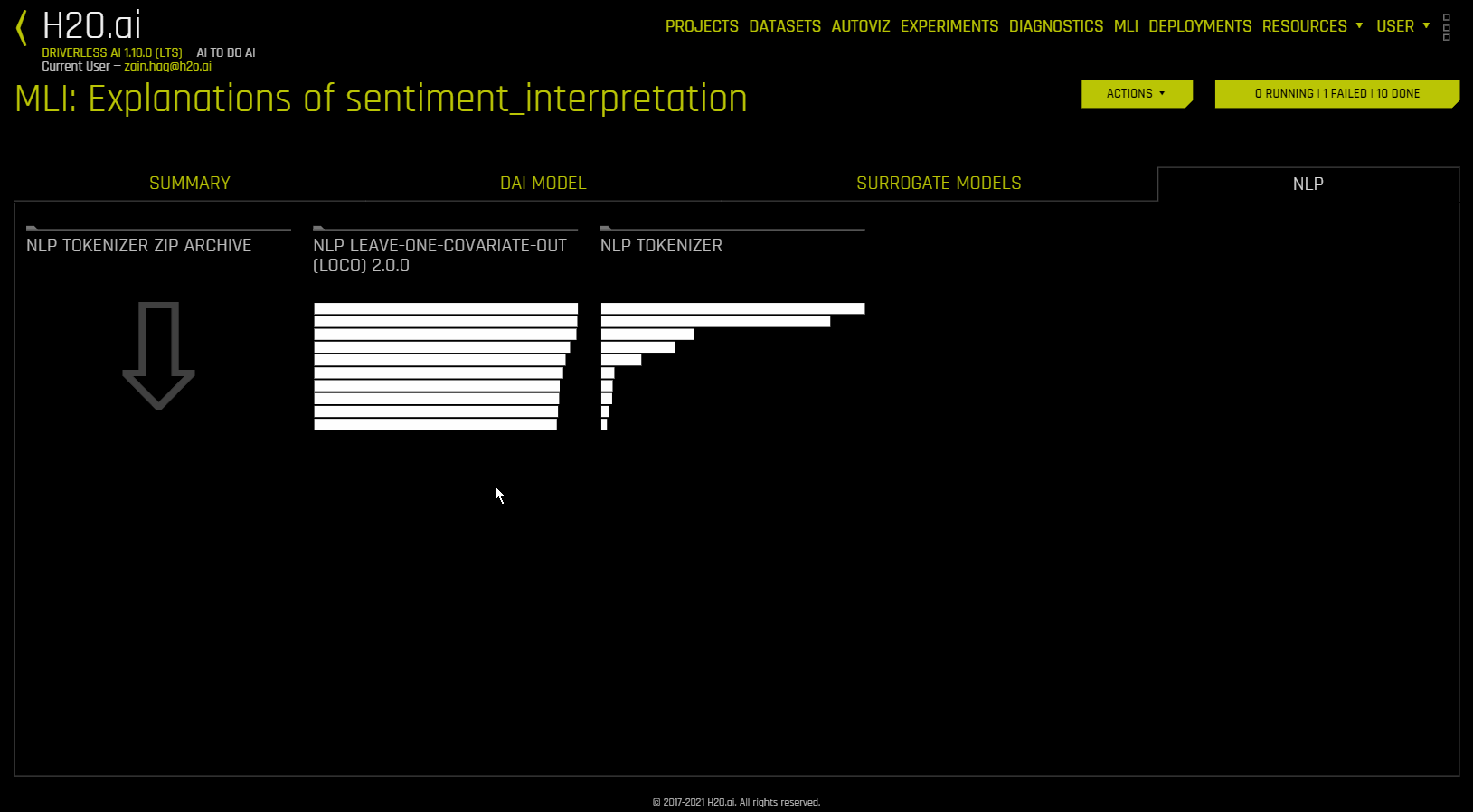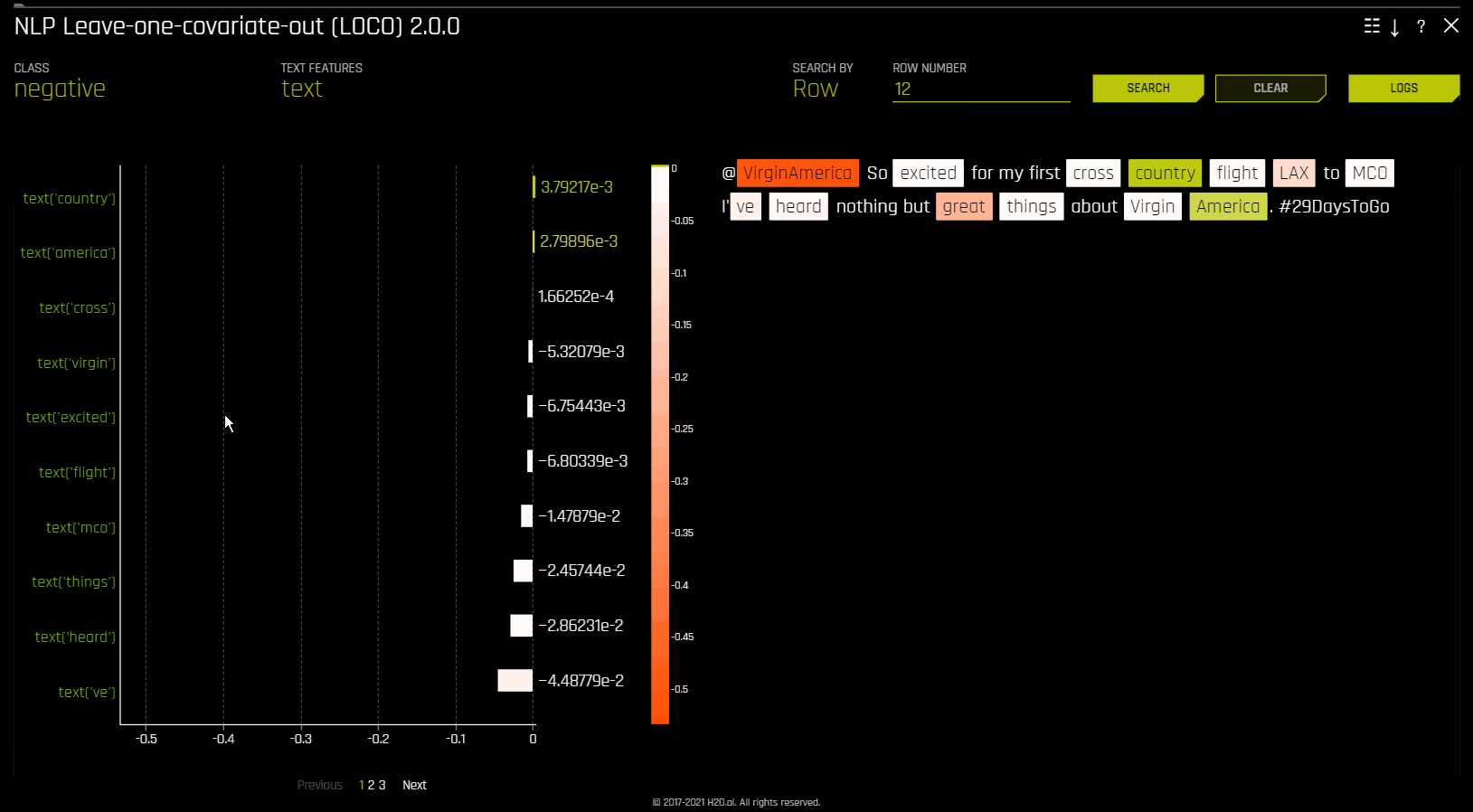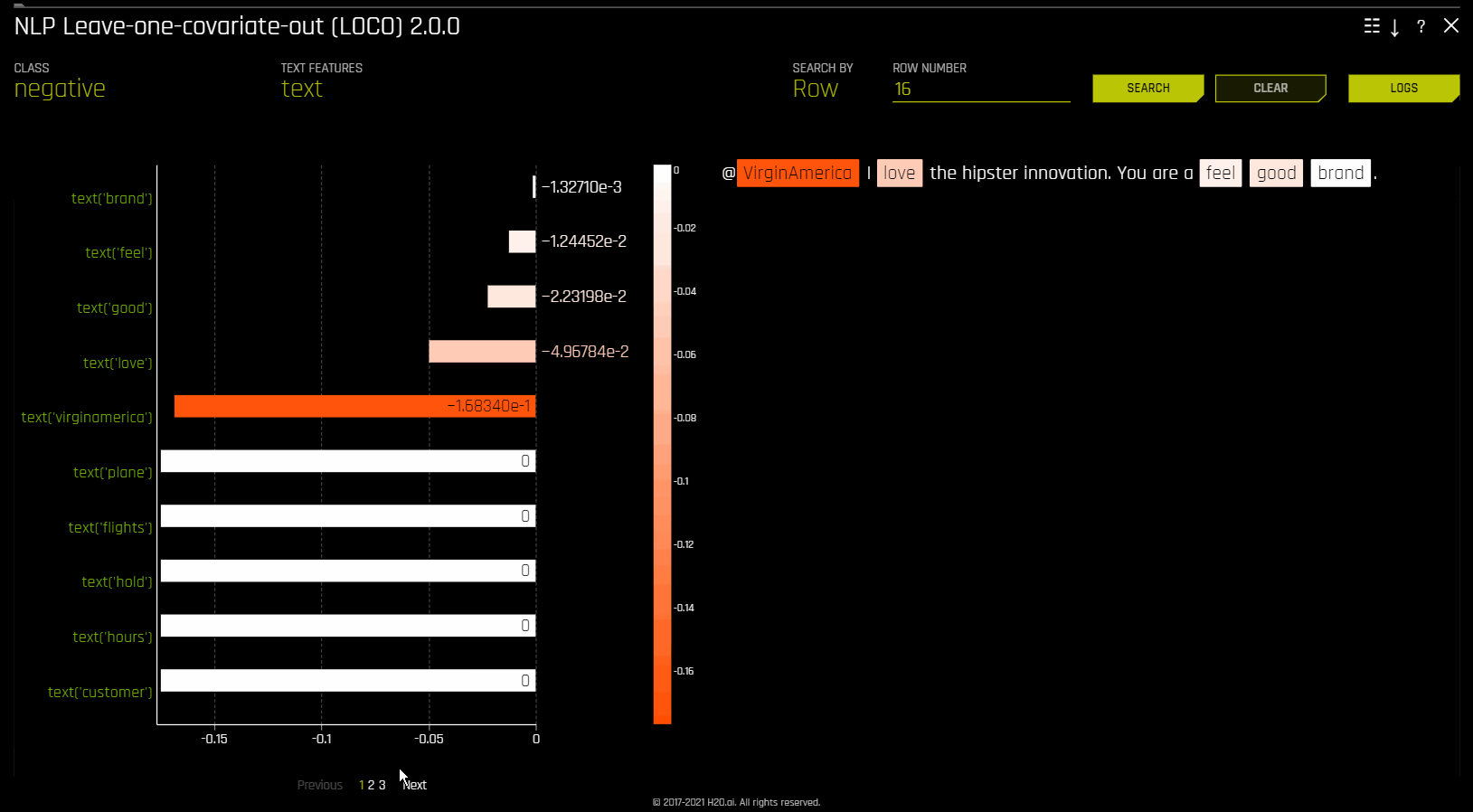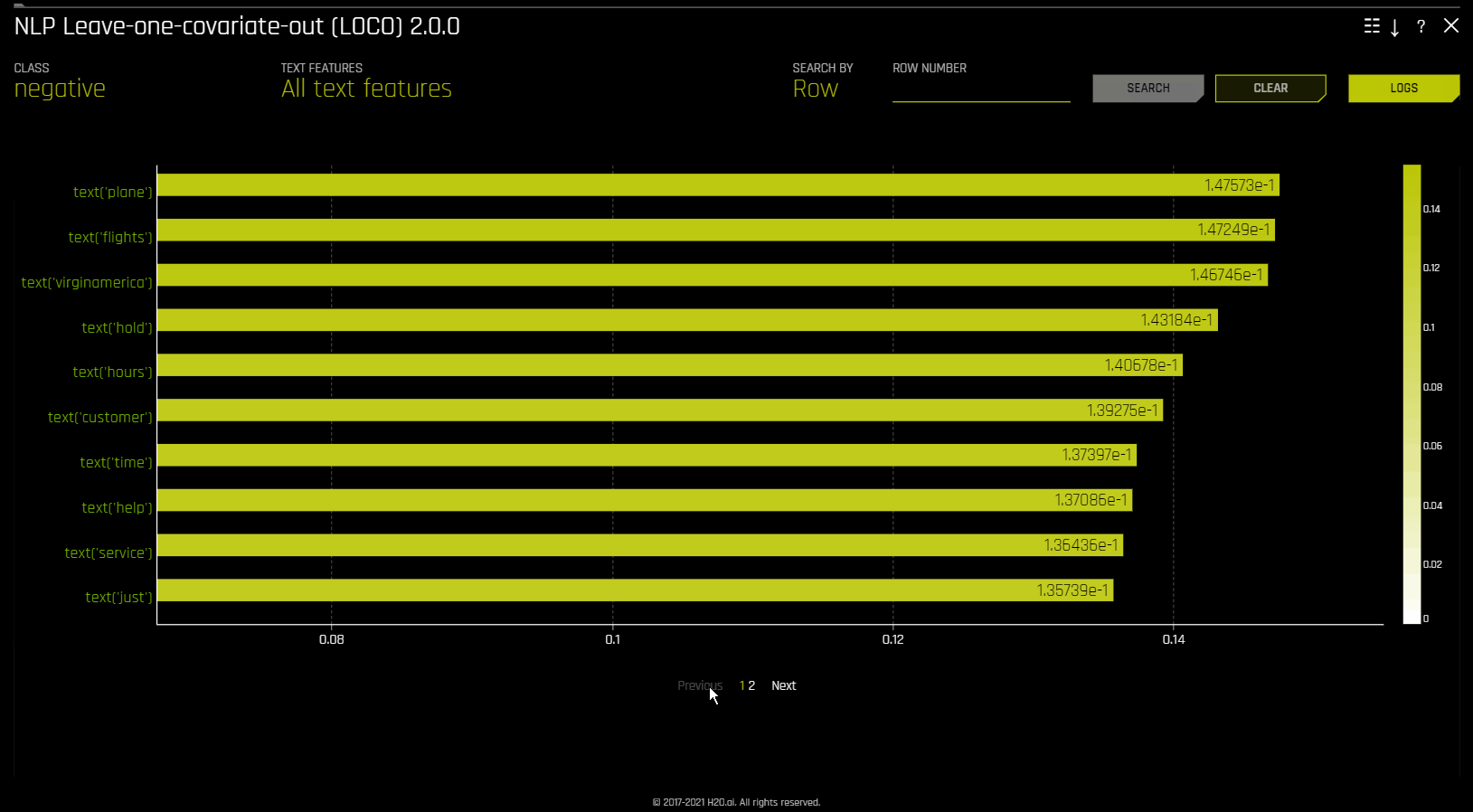
이 플롯은 토큰이 발생하는 단일 열로부터만 특정 토큰을 제거하여 NLP 모델에 LOCO(leave-one-covariate-out) 스타일 방식을 적용합니다. 예를 들어, column1 및 column2 모두에 foo 토큰이 있는 경우, 토큰이 같더라도 두 열에 대해 LOCO가 별도로 계산됩니다. 토큰에 대한 TF-IDF는 두 열에서 다릅니다. 결과 점수와 기존 점수(토큰 포함)의 차이는 텍스트 특성에 대한 특정 변경 사항이 모델에 의해 만들어진 예측을 어떻게 바꾸는지 확인하고자 할 때 유용합니다. Driverless AI는 각각의 개별 열에 대해 별도의 TF-IDF vectorizer를 맞추고 결과를 연결합니다. 결과 중요도 프레임의 용어(토큰)는 열 이름을 사용하여 래핑됩니다.
열1(〈and〉) |
열1(〈apple〉) |
열2(〈and〉) |
|---|---|---|
0.1 |
0.0005 |
0.412512 |
NLP LOCO 플롯을 사용하면 행 번호를 지정하여 특정 행에 대한 텍스트를 볼 수 있습니다. 행의 각 토큰은 중요성에 따라 강조 표시됩니다. 서로 다른 텍스트 기능 간에 전환하고 해당 중요성을 전역 및 로컬에서 볼 수 있습니다.
참고
계산 복잡도로 인해 글로벌 중요도 값은 \(N\) (기본적으로 20) 토큰에 대해서만 계산됩니다. 이 값은
mli_nlp_top_n구성 옵션으로 변경이 가능합니다.mli_nlp_min_token_mode구성 옵션에 다음 옵션 중 하나를 지정해서 특정 토큰 선택 방법을 이용할 수 있습니다.linspace: TF-IDF 점수(기본값)에 따라 균등한 간격의 토큰 \(N\) 선택합니다top: TF-IDF 점수에 따라 top \(N\) 토큰을 선택합니다bottom: TF-IDF 점수로 하단 \(N\) 토큰을 선택합니다.
NLP LOCO의 로컬값은 하드웨어 사양에 따라 계산에 오랜 시간이 걸릴 수 있습니다.
Driverless AI는 현재 MLI NLP 문제에 대한 K-LIME 스코어링 파이프라인을 생성하지 않습니다.
NLP 부분 의존도 플롯¶
이 플롯은 이항, 다중 클래스, 회귀분석 자연어 처리(NLP) 모델에 사용할 수 있습니다. 이것은 모델 해석 페이지의 ** NLP** 탭에 위치하며 이는 NLP 모델에서만 표시됩니다.
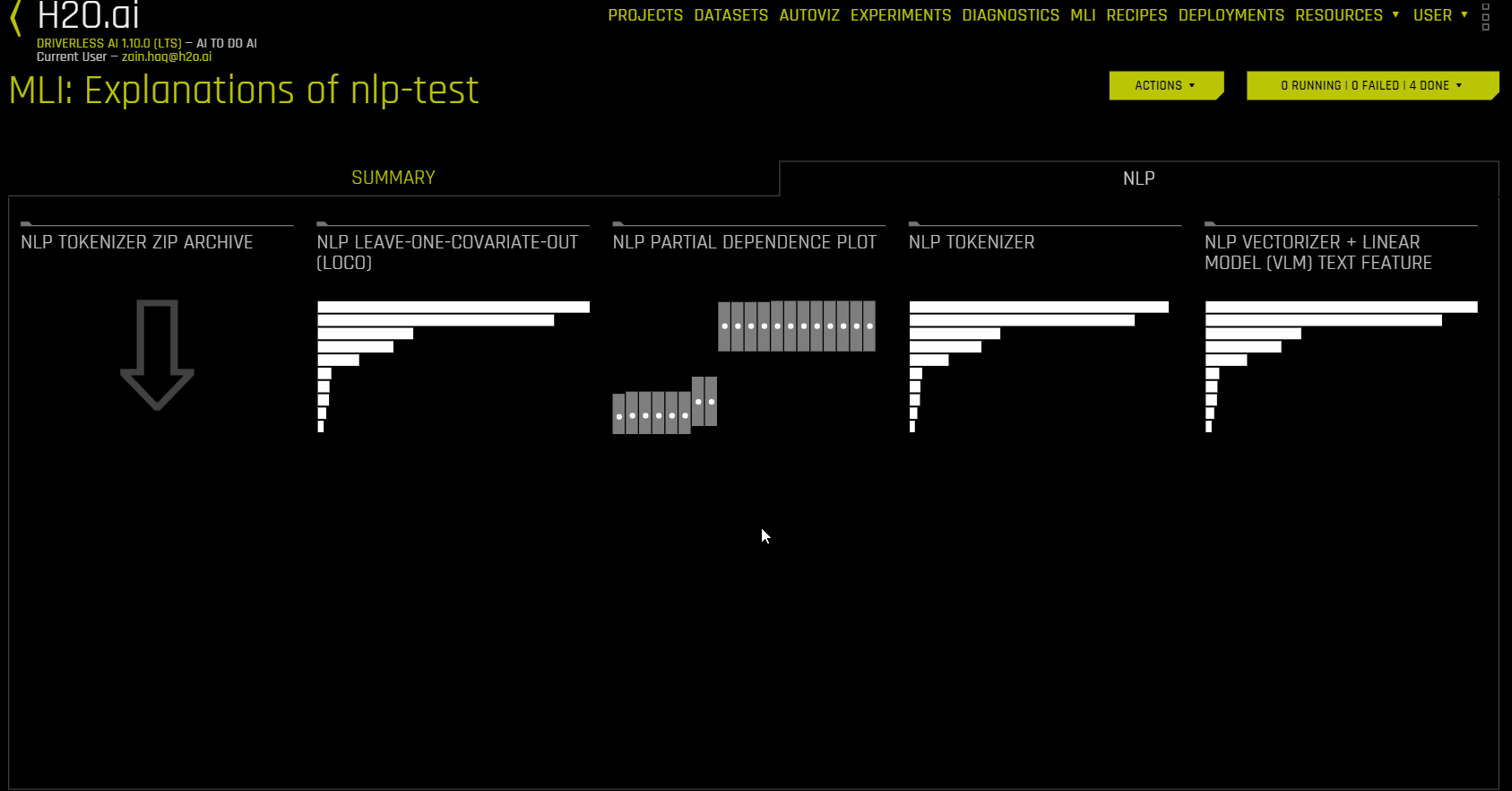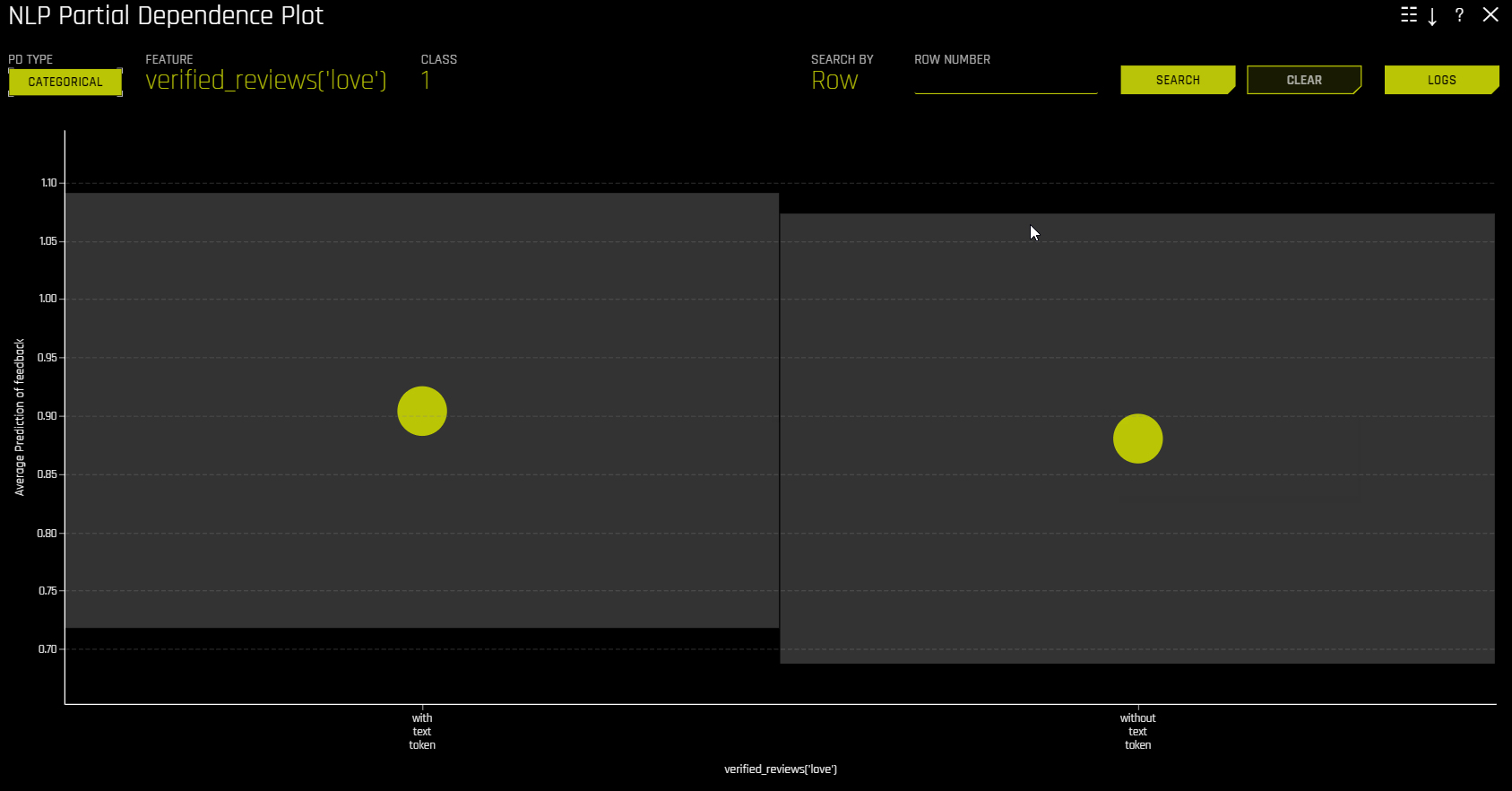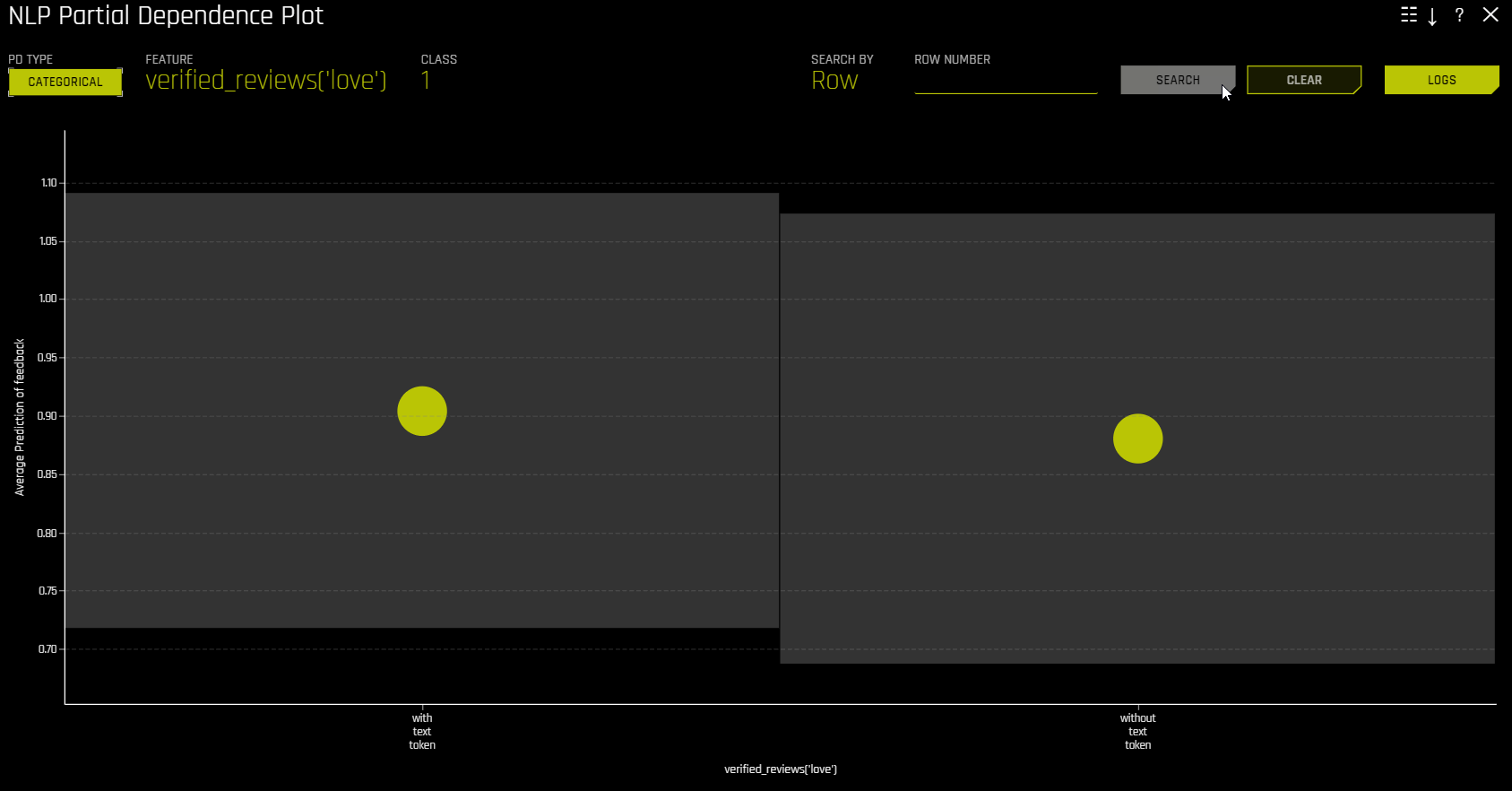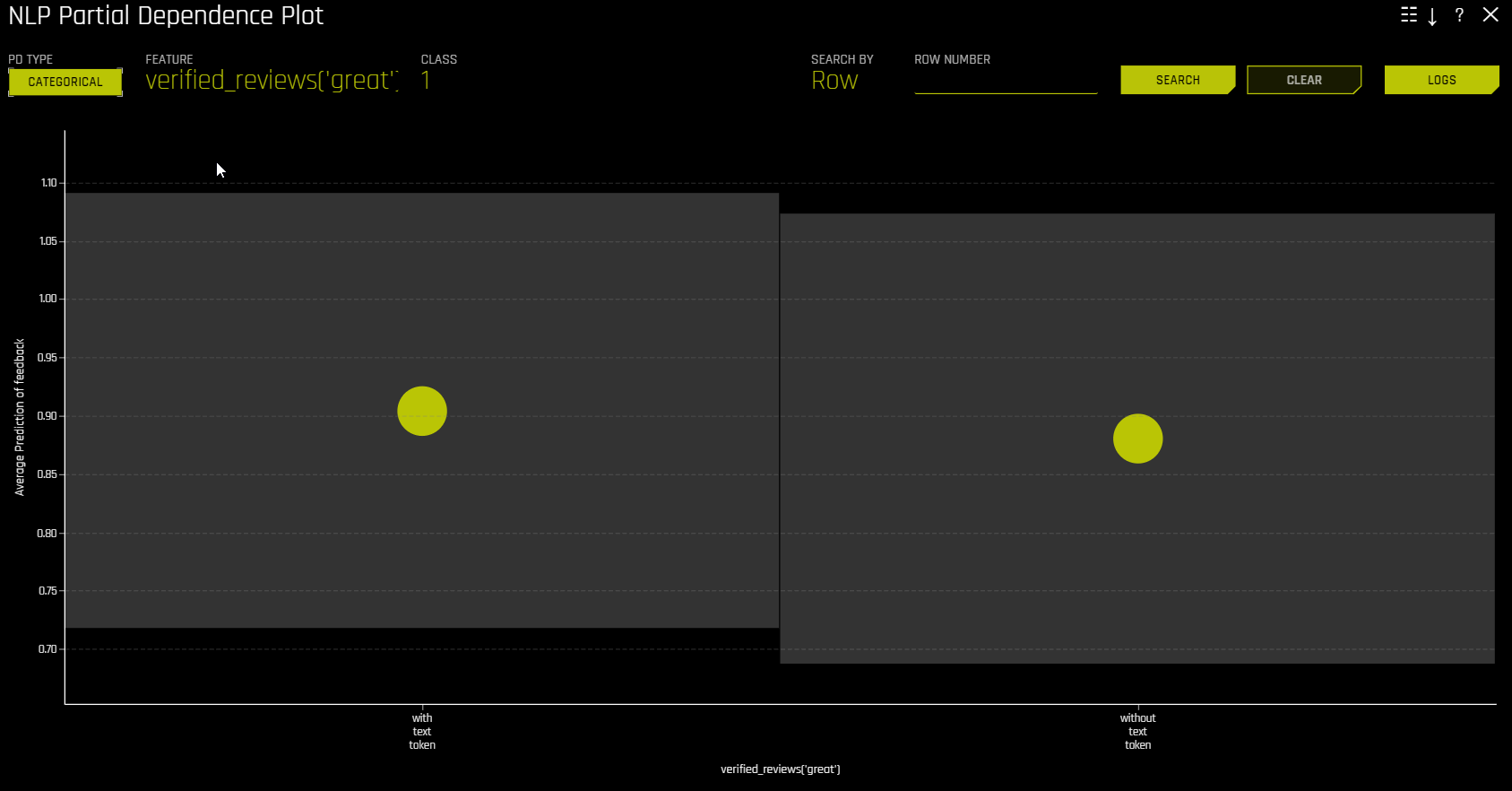
NLP 부분 종속성(노란색)은 입력 텍스트 토큰이 해당 텍스트에 남아 있고 +/- 1 표준 편차 밴드와 함께 해당 텍스트에 포함되지 않은 경우 Driverless AI 모델의 평균 예측 동작을 나타냅니다. ICE(회색)는 입력 텍스트 토큰이 해당 텍스트에 남아 있고 해당 텍스트에 포함되지 않은 경우 데이터의 개별 행에 대한 예측 동작을 표시합니다. 텍스트 토큰은 TF-IDF에서 생성됩니다.
NLP Tokenizer¶
이 플롯은 자연어 처리(NLP) 모델에 사용할 수 있습니다. 이것은 모델 해석 페이지의 ** NLP** 탭에 위치하며 이는 NLP 모델에서만 표시됩니다.
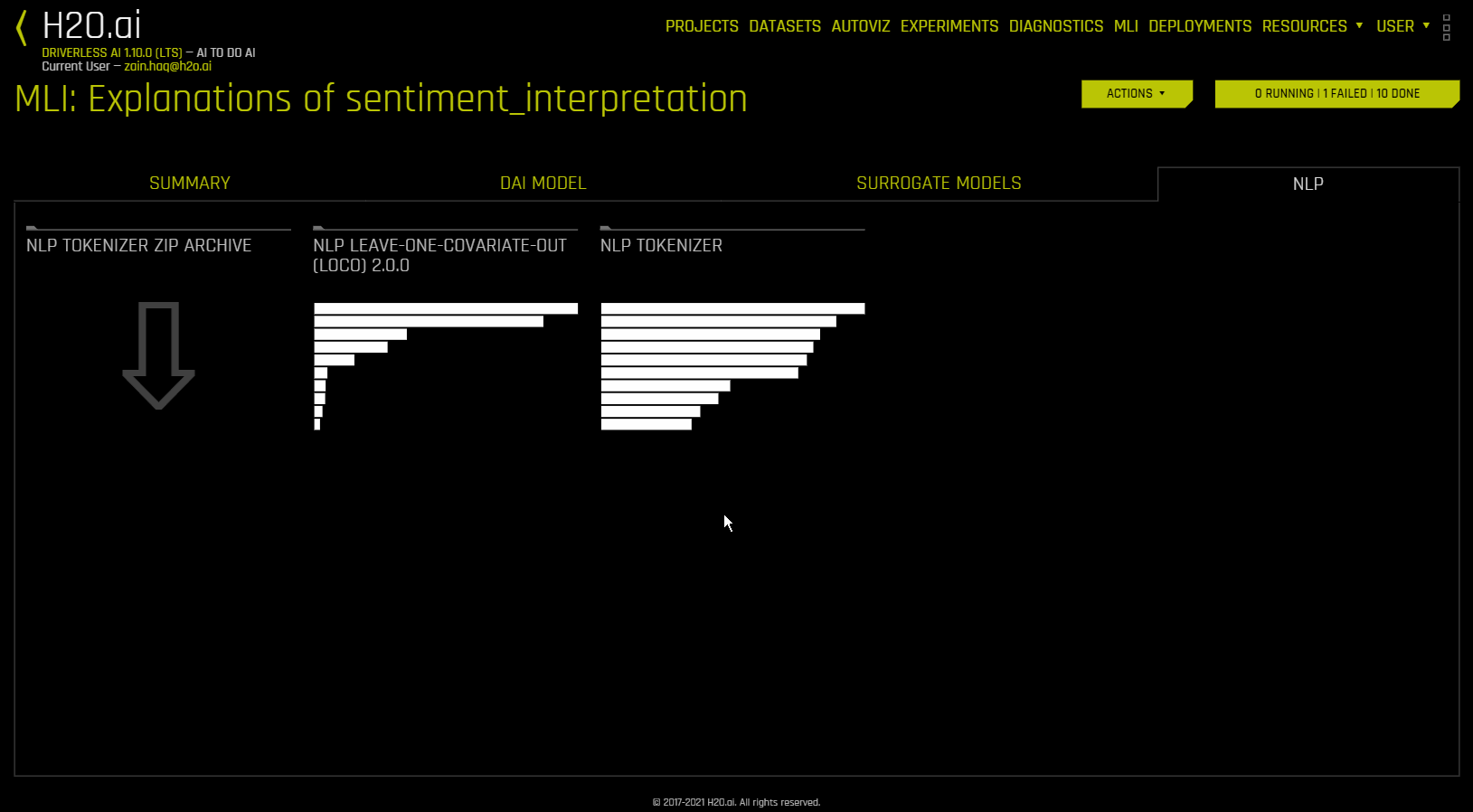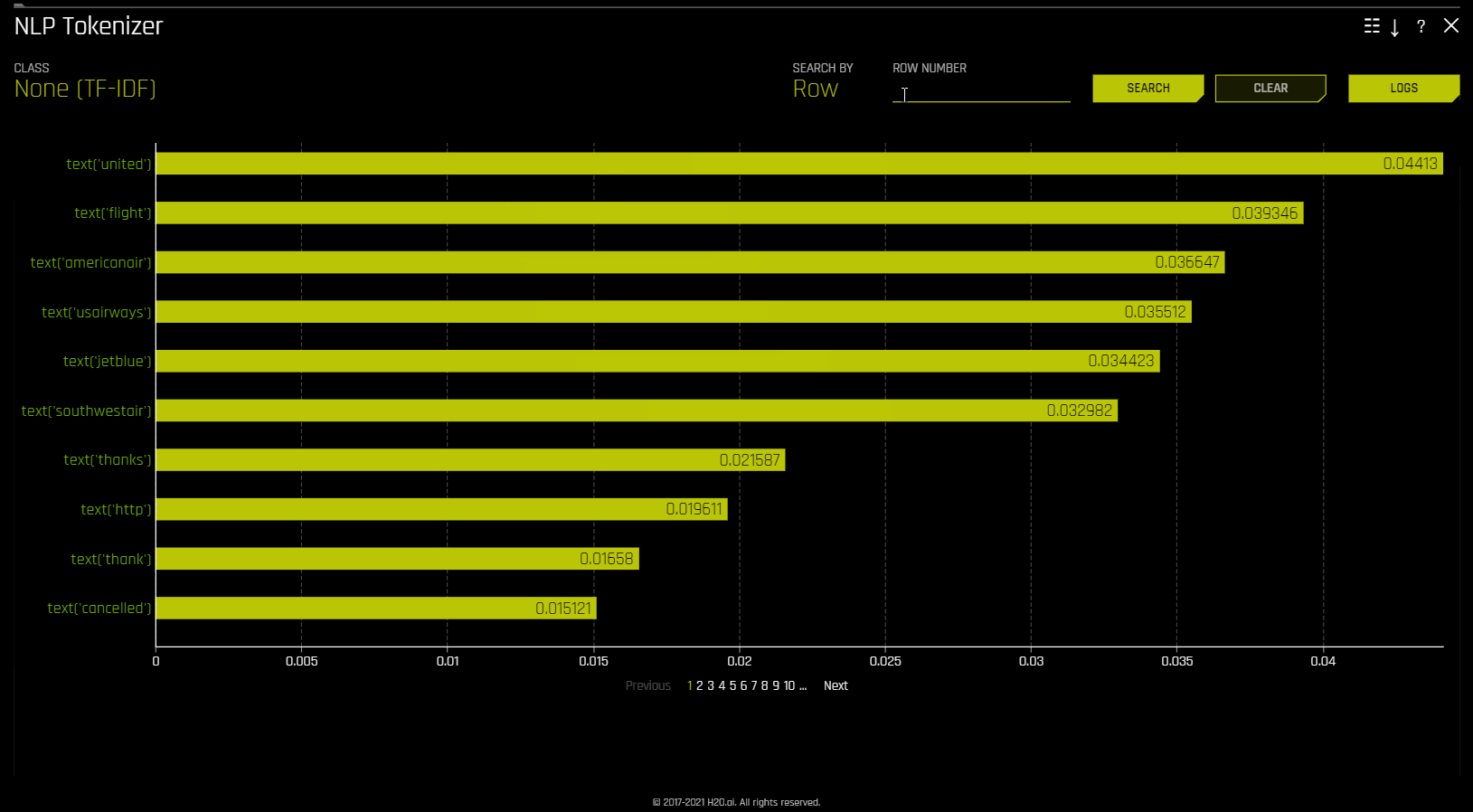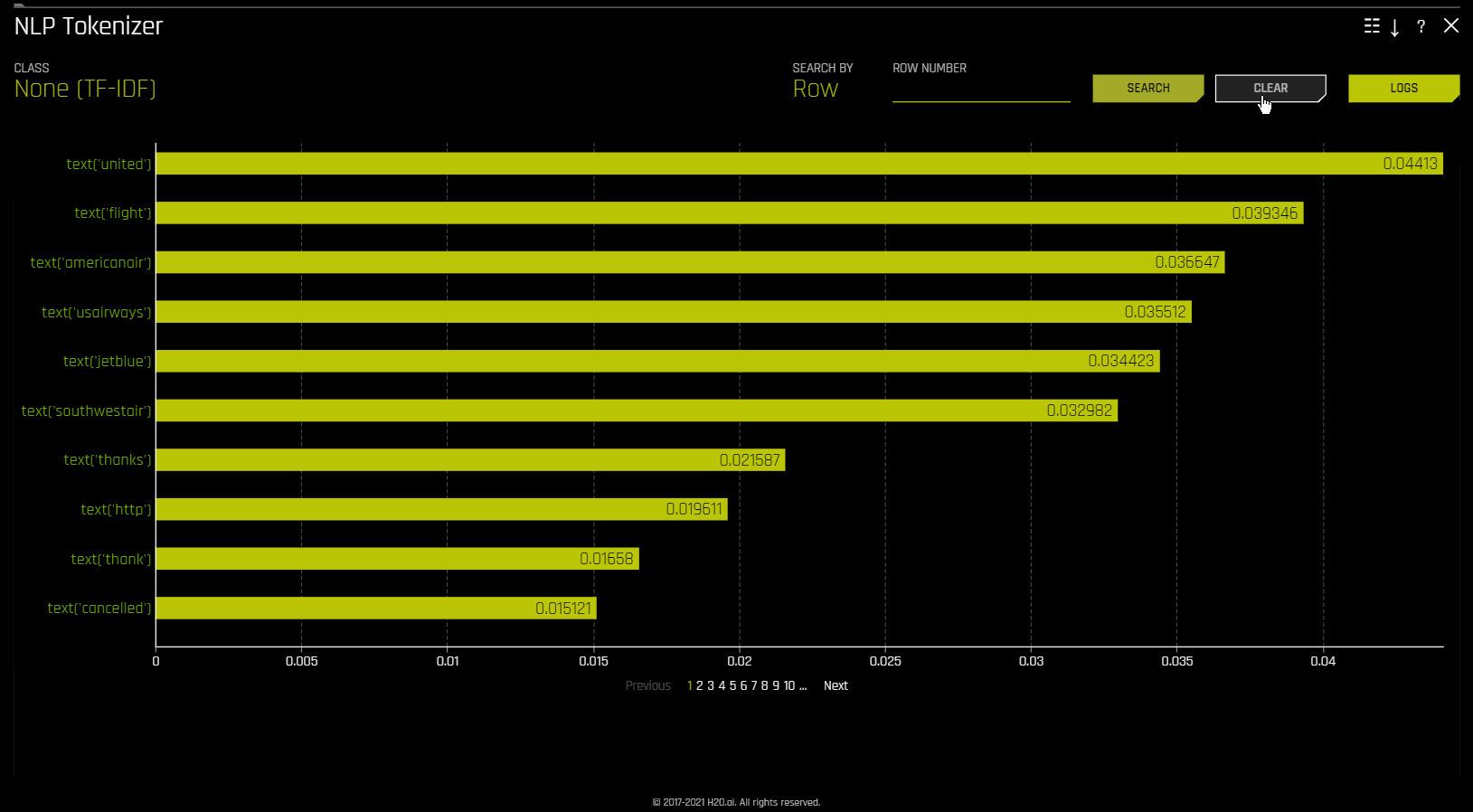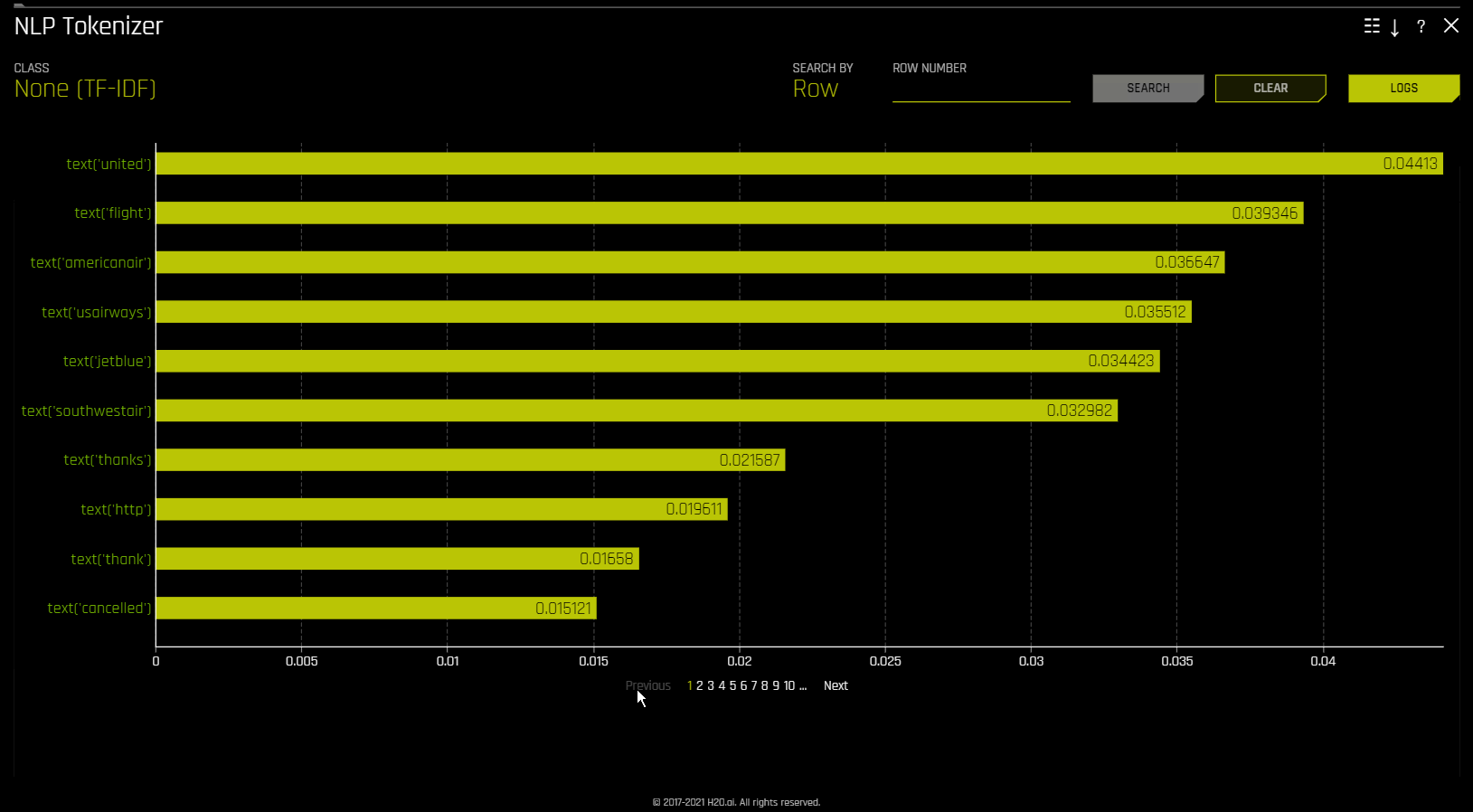
이 플롯은 말뭉치(대규모의 구조화된 텍스트 세트)에 있는 각 토큰의 글로벌 및 로컬 중요도 값을 모두 보여줍니다. 말뭉치는 토큰화 프로세스에 앞서 Driverless AI 모델에서 사용되는 텍스트 기능에서 자동으로 생성됩니다.
로컬 중요도 값은 빈도-역 문서 빈도(TF-IDF)라는 용어를 각 행의 각 토큰에 대한 가중치 요인으로 사용하여 계산합니다. TF-IDF는 주어진 문서에 토큰이 등장하는 횟수에 비례하여 증가하며 토큰을 포함하는 말뭉치의 문서 수에 의해 오프셋됩니다. 확인하려는 행을 지정한 후, Search 버튼을 클릭하여 해당하는 행에 있는 각 토큰의 로컬 중요도를 확인하십시오.
글로벌 중요도 값은 역 문서 빈도 (IDF)를 사용하여 계산하고, 이것은 주어진 토큰이 모든 문서에서 얼마나 일반적인지 또는 희귀한지를 측정합니다.(기본 보기)
NLP 탭에서 《NLP Tokenizer ZIP Archive》 를 클릭하면 NLP Tokenizer 플롯과 관련된 파일 아카이브를 다운로드할 수 있습니다.
참고
NLP용 MLI에는 현재 불용어를 제거하는 옵션이 없습니다.
기본적으로 토큰화 프로세스 중에 최대 10,000개의 토큰이 생성됩니다. 이 값은 구성에서 바꿀 수 있습니다.
기본적으로 Driverless AI는 최대 10,000개의 문서를 이용해서 토큰을 추출합니다. 이 값은
config.mli_nlp_sample_limit매개변수를 사용해서 바꿀 수 있습니다. 다운샘플링은 기본 샘플 제한보다 큰 데이터 세트에 사용됩니다.Driverless AI는 현재 MLI NLP 문제에 대한 K-LIME 스코어링 파이프라인을 생성하지 않습니다.
LOCO 방법을 통해, 토큰이 발생하는 단일 열에서만 특정 토큰이 제거됩니다. 예를 들어,
column1및column2모두에foo토큰이 있을 때는 토큰이 같더라도 두 열에 대한 LOCO가 별도로 계산됩니다. 토큰의 TF-IDF는 두 열에서 다릅니다.
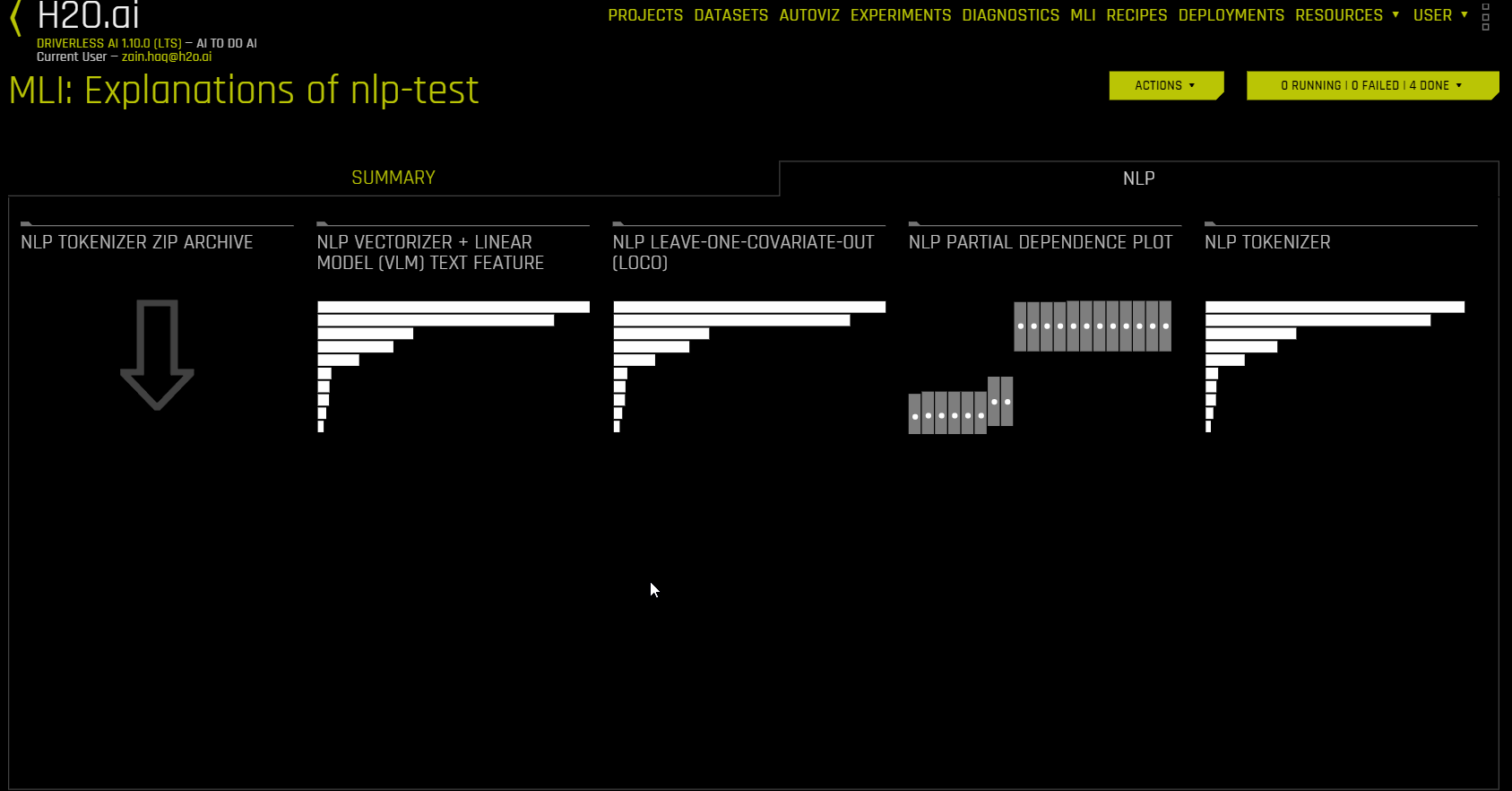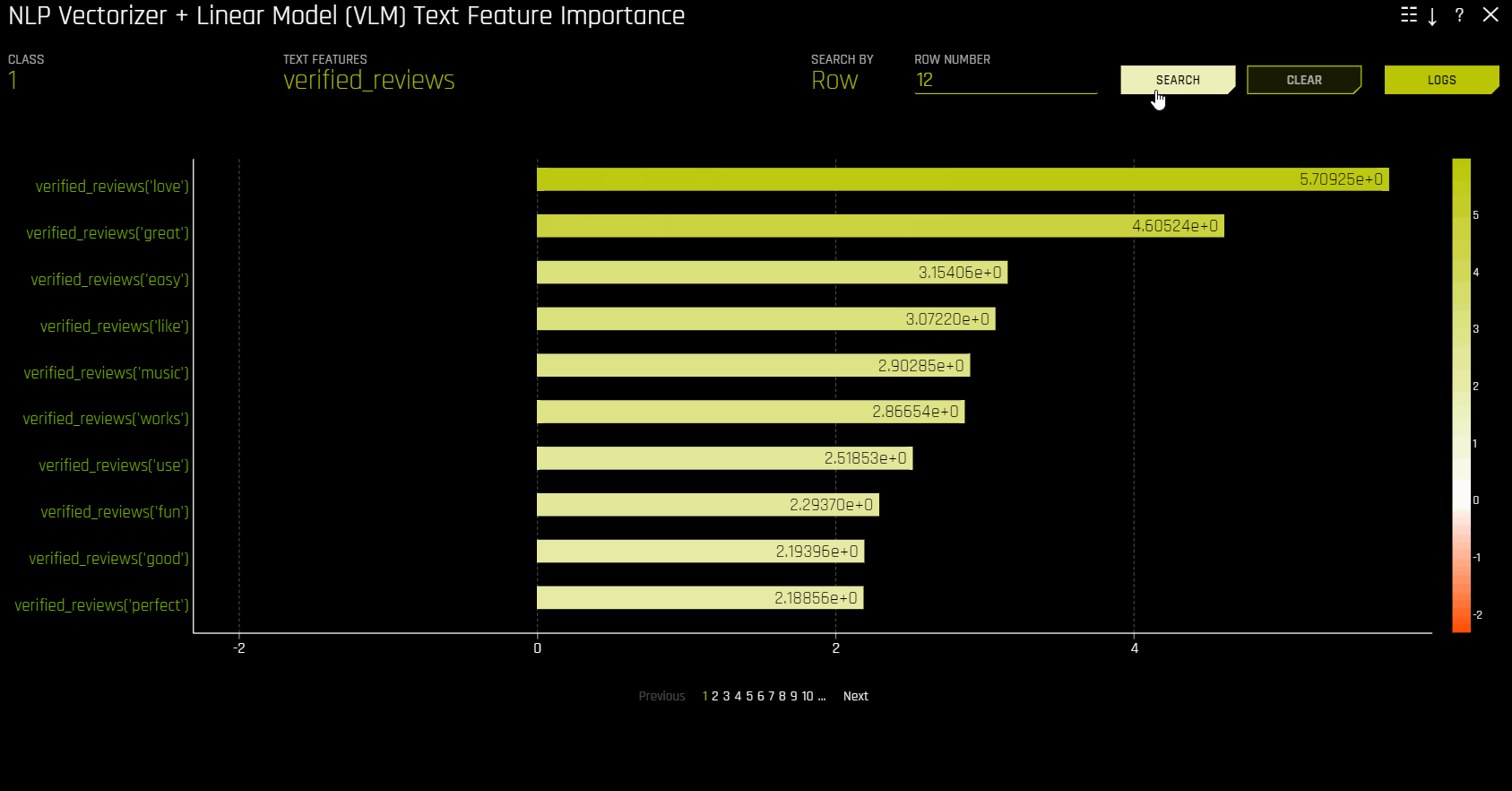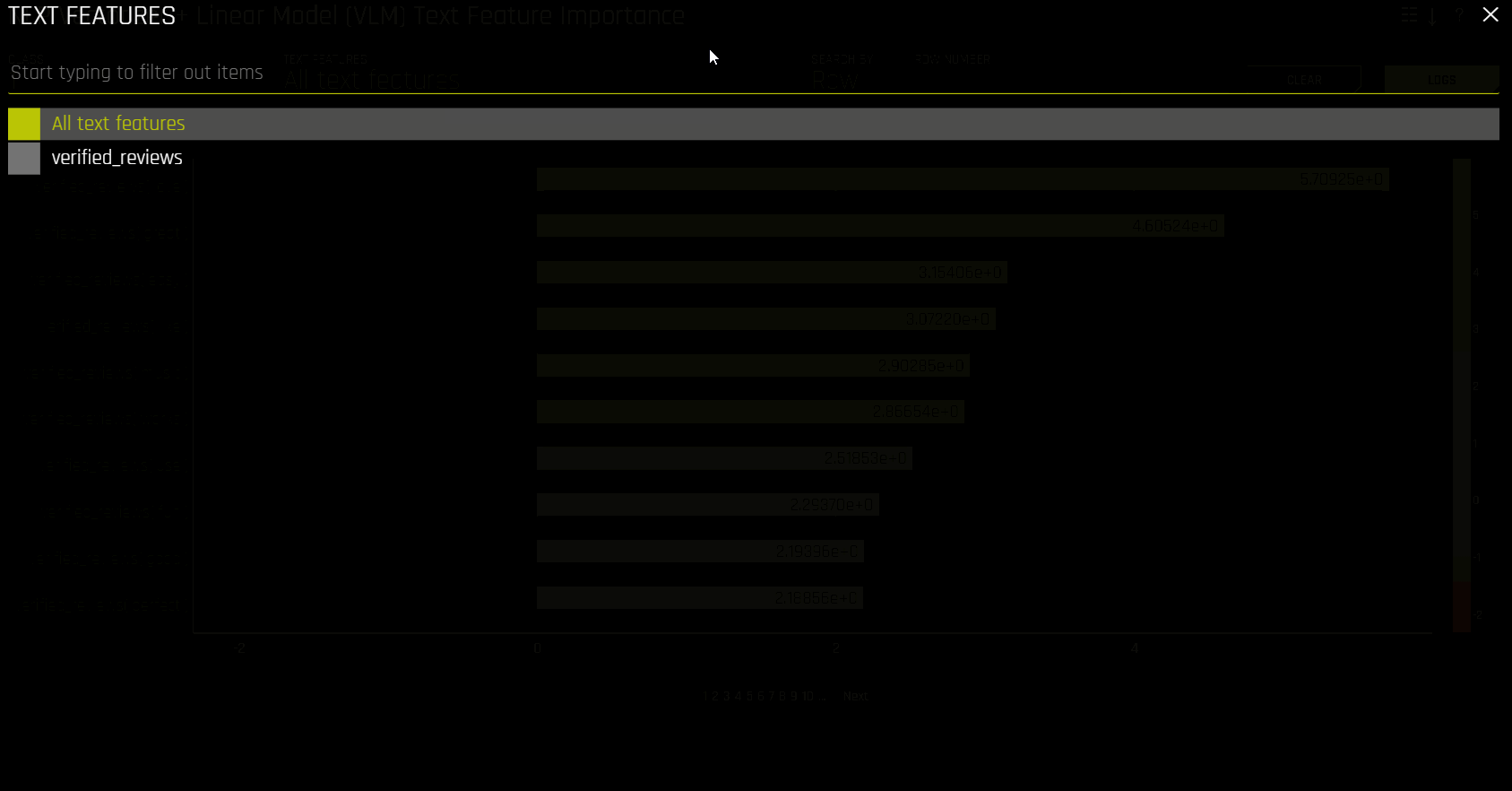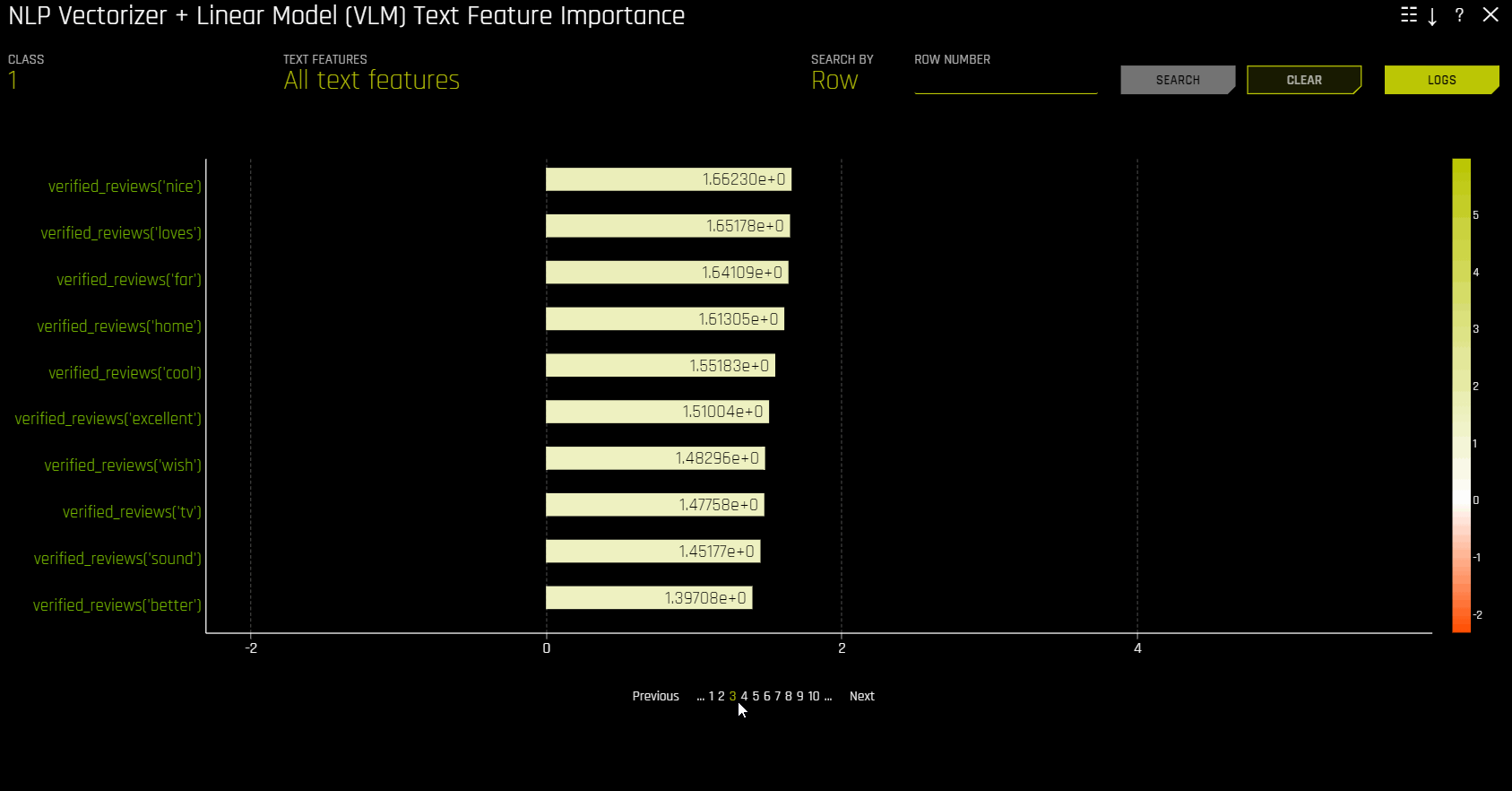
NLP Vectorizer + Linear Model (VLM) Text Feature Importance¶
이 플롯은 이항 및 회귀분석 자연어 처리(NLP) 모델에 사용할 수 있습니다. 이것은 모델 해석 페이지의 NLP 탭에 위치하며 이는 NLP 모델에서만 표시됩니다.
NLP 벡터라이저 + 선형 모델(VLM) 텍스트 기능 중요성은 개별 단어의 TF-IDF를 관심 있는 텍스트 열의 기능으로 사용하고 이러한 기능을 사용하여 선형 모델(현재 GLM)을 구축하며 이를 예측된 클래스(이진 분류) 또는 Driverless AI 모델의 연속 예측(회귀분석) 중 하나에 맞춥니다. 선형 모델의 계수는 단어의 중요성을 나타냅니다. 기본적으로 이 explainer는 알파벳 순서를 바탕으로 첫 번째 텍스트 열을 사용합니다.