H2O Driverless AI 소개¶
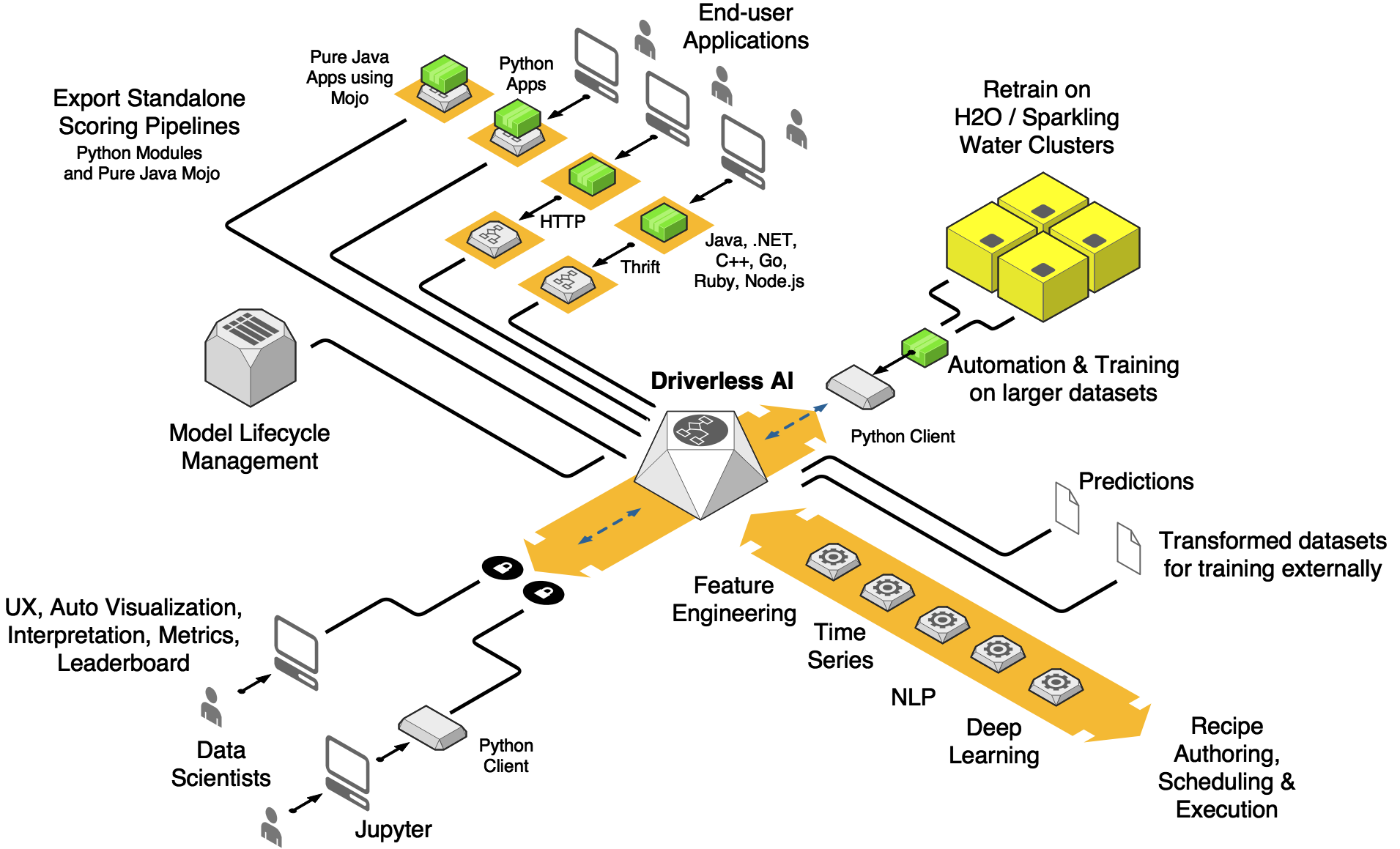
H2O Driverless AI는 최첨단 예측 분석 모델의 신속한 개발 및 배포를 위한 고성능 GPU 지원 클라이언트-서버 애플리케이션입니다. H2O Driverless AI는 다양한 소스로부터 표로 나타낸 데이터를 읽고, 데이터 시각화, 그랜드 마스터 수준의 자동 변수 가공, 모델 검증(과적합 및 누출 방지), 모델 매개변수 튜닝, 모델 해석 가능성 및 모델 배포를 자동화합니다. H2O Driverless AI는 현재 부도 시 손실률, 부도율, 고객 이탈, 캠페인 반응, 부정 탐지, 자금세탁방지 및 자산 예측 유지 관리 모델을 포함한 일반적인 회귀 분석, 이항 분류 및 다항 분류 애플리케이션을 목표로 합니다. 또한, H2O Driverless AI는 시간 인과 변수 가공 및 검증 체계를 사용하여 매장 및 부서별 주간 판매 예측과 같은 개별 또는 그룹화된 시계열에 대한 시계열 문제를 처리합니다. Driverless AI는 이미지 및 텍스트 데이터(NLP) 사용 사례도 처리할 수 있습니다.
높은 수준의 기능:
최첨단 지도 기계 학습 모델의 신속한 실험 및 배포를 위한 클라이언트/서버 애플리케이션
사용자 친화적 GUI
Python 및 R 클라이언트 API
최고의 예측 accuracy를 위해 기계 학습 모델링 파이프라인을 자동으로 생성합니다.
데이터 정제, 특성 선택, 변수 가공, 모델 선택, 모델 튜닝, 앙상블을 자동화합니다.
Python에서 HTTP 또는 TCP 프로토콜을 통해 인프로세스 스코어링 또는 클라이언트/서버 스코어링을 위한 단독 배치 스코어링 파이프라인을 자동으로 생성합니다.
C++ (R 및 Python 런타임 포함) 및 Java (어디에서나 실행)에서 HTTP 또는 TCP 프로토콜을 통해 인프로세스 스코어링 또는 클라이언트/서버 스코어링을 위한 단독(MOJO) 저지연 스코어링 파이프라인을 자동으로 생성합니다.
강력한 워크스테이션 및 NVidia DGX 슈퍼컴퓨터를 위한 다중 GPU 및 다중 CPU 지원
글로벌 및 로컬 모델 해석을 포함한 기계 학습 모델 해석 모듈
자동 시각화 모듈
다중 사용자 지원
하위 호환
지원되는 문제 유형:
회귀 분석(연령, 소득, 가격 또는 손실 예측, time series 예측과 같은 연속 목표 변수)
이항 분(0/1 또는 《N》/》Y” , 부정 예측, 이탈 예측, 실패 예측 등의 경우)
다항 분류( (범주형 타겟 변수의 경우에는 《negative》/》neutral》/》positive》 또는 0/1/2/3 또는 0.5/1.0/2.0, 회원 유형, 다음 조치, 제품 추천, 감성 분석 등의 예측의 경우)
지원되는 데이터 유형:
표 형식의 정형화된 데이터, 행은 관측값, 열은 필드/특성/변수
숫자, 범주 및 문자 필드
이미지
결측치 허용됨
i.i.d.(독립항등분포) 데이터
단일 time series을 포함한 Time Series 데이터(데이터 블록이 아닌 전체 데이터 세트에 걸친 시간 흐름)
그룹화된 time series(예: 주당 매장별, 부서별 매출, 한 파일에 모두 저장 및 매장, 부서, 주에 대한 3개의 열 포함)
학습과 테스트 사이의 gap(즉, 배포 시간)과 알려진 forecast horizon(그 이후 모델을 재학습해야 하는 시점)을 포함한 time series 문제
사용자 정의 레시피를 통해 지원되는 데이터 유형:
비디오
오디오
그래프
지원되는 데이터 소스:
로컬 파일 시스템 또는 NFS
브라우저 또는 Python client에서 파일 업로드
S3(Amazon)
Hadoop(HDFS)
Azure Blob 스토리지
Blue Data Tap
Google BigQuery
Google Cloud storage
kdb+
Minio
Snowflake
JDBC
사용자 정의 데이터 레시피 BYOR(Python, 자체 레시피 가져오기)
지원되는 파일 포맷:
주상 데이터의 일반 문자 형식(.csv, .tsv, .txt)
압축된 아카이브(.zip, .gz, .bz2)
Excel
Parquet
Feather
Python datatable (.jay)