Sparkling Water¶
The Sparkling Water page shows clusters created by the current user, the state of the cluster, the cluster type, and the cluster creation date. From this page, you can launch a new cluster, view the details of existing clusters, or delete a cluster.
Note: When Enterprise Steam is started for the first time, no clusters will appear in the UI.
Launch Cluster¶
There are two different types of Sparkling Water backends. You have to decide which backend to use when launching the cluster. Steam administrator might assign you a specific backend type and it will be automatically selected. Internal backend is recommended if you are unsure which one to pick.
Internal Backend¶
Select Launch New Cluster.
Select Sparkling Water - Internal Backend from the Cluster Type dropdown menu.
Select a Cluster Profile from the dropdown menu to use when setting up the new cluster. Cluster profiles are configured by the Steam administrator and provide the allowed minimum, maximum and default values for each options in a cluster profile.
Configure the new cluster.
Cluster Name: Specify a name for this cluster.
Sparkling Water Version: Specify the Sparkling Water version to use.
Python Environment: Specify the Python environment to use. Additional environments can be added on the Minio page.
Dataset parameters: Optionally provide estimated dataset parameters described in section below. Cluster parameters will be preset to accommodate your dataset within selected profile limits.
Maximum Idle Time [HRS]: Specify the maximum idle time of the Sparkling Water cluster. The cluster will shut down if it is idle for longer than the maximum idle time.
Maximum Uptime [HRS]: Set the duration after which the cluster automatically shuts down.
YARN Queue: (Optional) If instructed by your Steam administrator select or enter the name of YARN queue that will be used for this H2O cluster. Note that the YARN queue cannot contain spaces. Leave this empty to use the default YARN queue.
Save cluster data: Only available if enabled by administrator in the selected profile. Choose whether you want to persist cluster data on cluster reaching uptime or idle time limit.
Optionally specify the following additional advanced options.
Number of Executors: Specify the number of of Spark executors.
Memory per Executors [GB]: Specify the amount of memory allocated to a single Spark executor.
Executor Cores: Specify the number of cores per executor.
Extra Memory [%]: Specify the extra memory allocated to a single node as a percentage of memory per node. Algorithms like XGBoost use this additional memory, and you may need to increase this value if you are unable to build XGBoost models.
H2O Threads per Node: Specify the number of threads (CPUs) to use per node.
Startup Timeout [SEC]: Specify the startup timeout. The cluster will terminate if it cannot start within this time.
Spark Properties: This shows a list of additional Spark properties for the cluster. This list is maintained by your administrator.
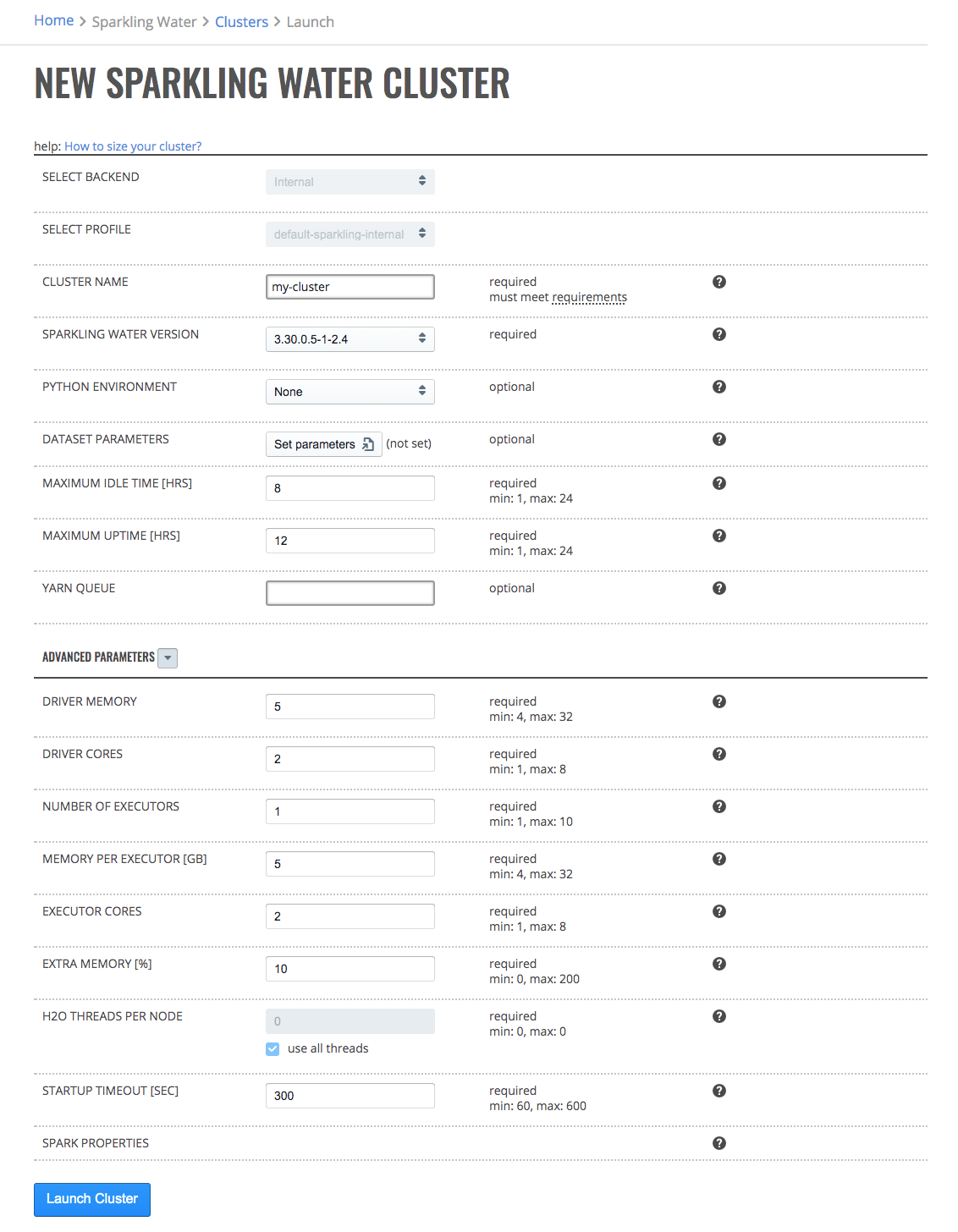
Click the Launch New Cluster button to launch a new cluster.
Upon successful validation of parameters, the cluster will begin starting and you will be taken back to the previous page. It takes up to 5 minutes for Sparkling Water cluster to launch.
External Backend¶
Select Launch New Cluster.
Select Sparkling Water - External Backend from the Cluster Type dropdown menu.
Select a Cluster Profile from the dropdown menu to use when setting up the new cluster. Cluster profiles are configured by the Steam administrator and provide the allowed minimum, maximum and default values for each options in a cluster profile.
Configure the new cluster.
Cluster Name: Specify a name for this cluster.
Sparkling Water Version: Specify the Sparkling Water version to use.
Python Environment: Specify the Python environment to use. Additional environments can be added on the Minio page.
Dataset parameters: Optionally provide estimated dataset parameters described in section below. Cluster parameters will be preset to accommodate your dataset within selected profile limits.
Maximum Idle Time [HRS]: Specify the maximum idle time of the Sparkling Water cluster. The cluster will shut down if it is idle for longer than the maximum idle time.
Maximum Uptime [HRS]: Set the duration after which the cluster automatically shuts down.
YARN Queue: (Optional) If instructed by your Steam administrator select or enter the name of YARN queue that will be used for this H2O cluster. Note that the YARN queue cannot contain spaces. Leave this empty to use the default YARN queue.
Save cluster data: Only available if enabled by administrator in the selected profile. Choose whether you want to persist cluster data on cluster reaching uptime or idle time limit.
Optionally specify the following additional advanced options.
Number of Executors: Specify the number of of Spark executors.
Memory per Executors [GB]: Specify the amount of memory allocated to a single Spark executor.
Executor Cores: Specify the number of cores per executor.
Extra Memory [%]: Specify the extra memory allocated to a single node as a percentage of memory per node. Algorithms like XGBoost use this additional memory, and you may need to increase this value if you are unable to build XGBoost models.
Number of H2O Nodes: Specify the number of H2O nodes.
Memory per H2O Node [GB]: Specify the amount of memory to allocate to H2O per node.
H2O Threads per Node: Specify the number of threads (CPUs) to use per node.
Startup Timeout [SEC]: Specify the startup timeout. The cluster will terminate if it cannot start within this time.
Spark Properties: This shows a list of additional Spark properties for the cluster. This list is maintained by your administrator.
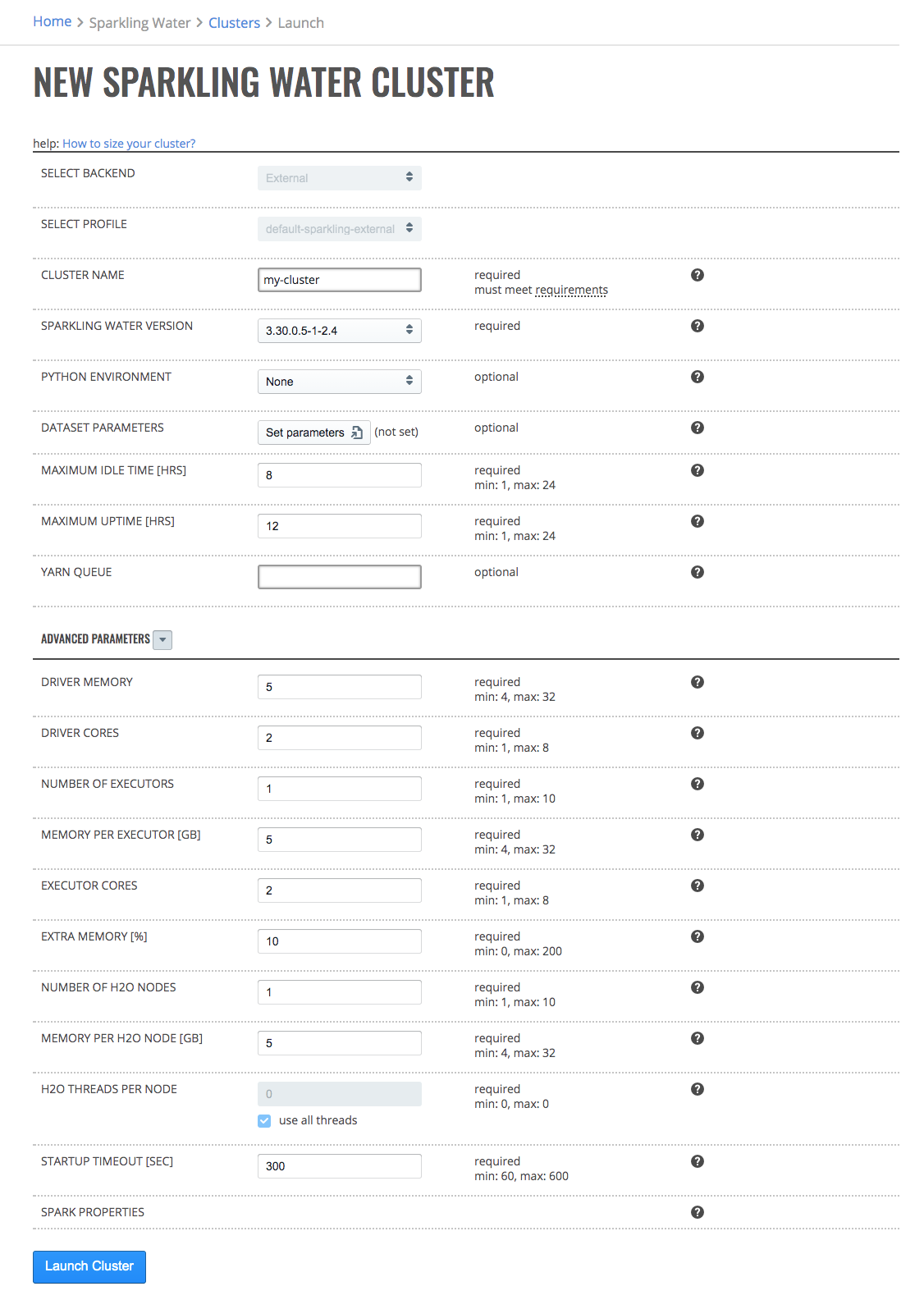
Click the Launch New Cluster button to launch a new cluster.
Upon successful validation of parameters, the cluster will begin starting and you will be taken back to the previous page. It takes up to 5 minutes for Sparkling Water cluster to launch.
Cancel Cluster¶
To cancel a cluster in with status Starting, click the Actions > Cancel option. Confirm the cancellation by clicking the Yes, Stop button. Cluster will transition to the Stopped state.
Accessing H2O Flow¶
Once the cluster has started you may click on the cluster name. This opens H2O Flow in a new tab.
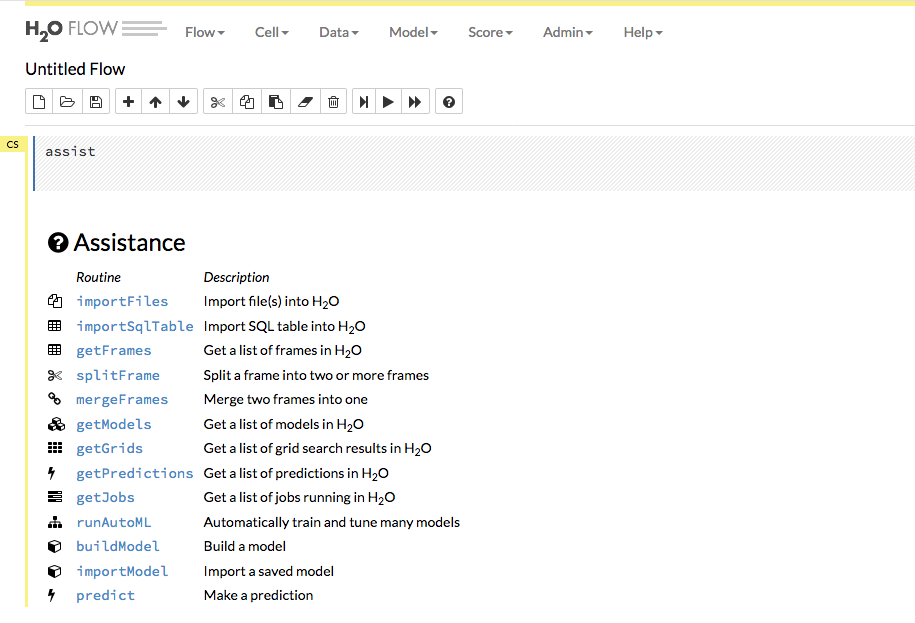
Use the menu items at the top to import/upload your data into Flow and to build and score models.
The Data dropdown allows you to import or upload a dataset, import SQL table, split or merge frames, and impute data.
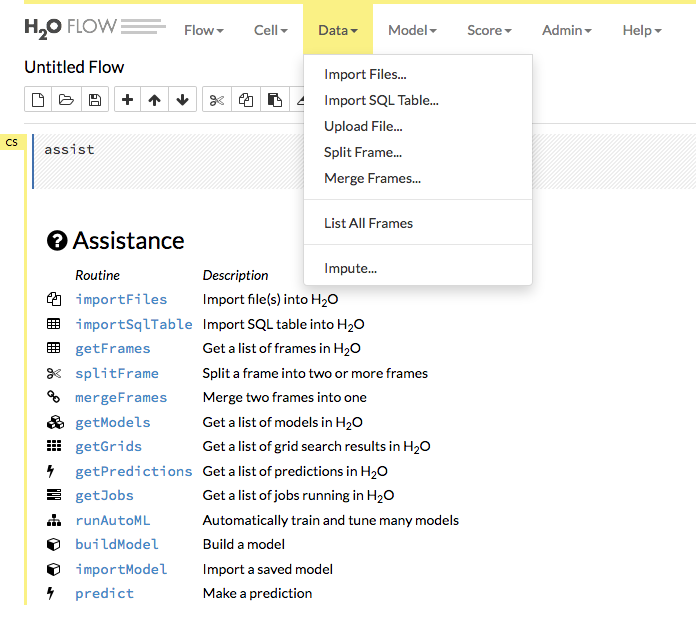
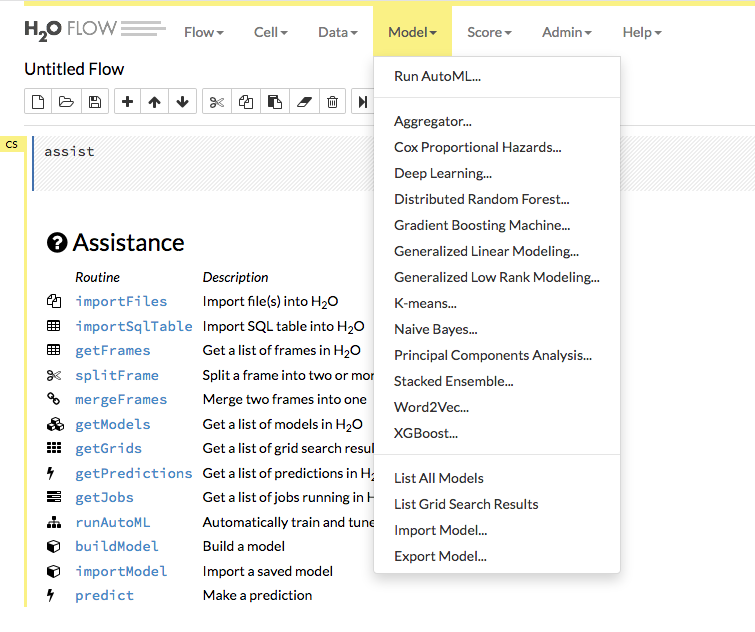
Use the Model dropdown to select an algorithm and begin building models or to import/export models.
Refer to the H2O Flow documentation for more information on how to use H2O Flow.
Cluster Details¶
To view the details of a cluster, click the Actions > Detail option. The cluster detail displays the following information:

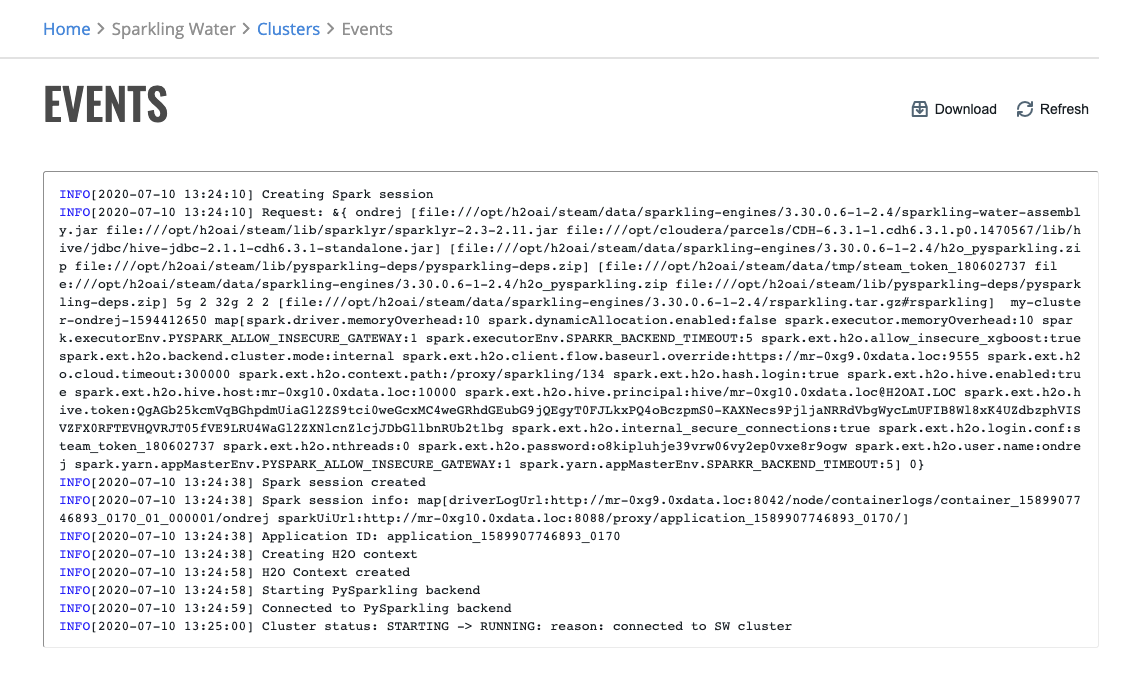
Cluster Events¶
To view the events of a cluster, click the Actions > Events option.
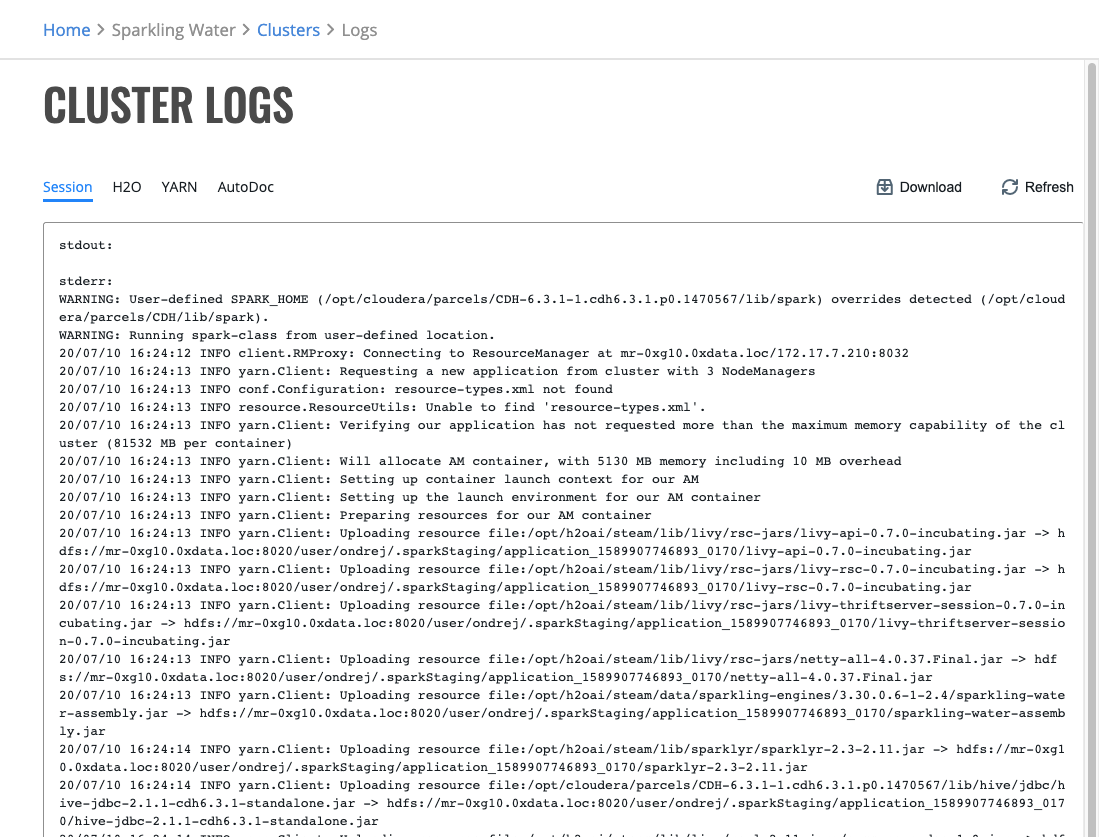
Cluster Logs¶
You can see Spark session, H2O, YARN and ML-Autodoc logs by clicking on the Actions > Logs option. On this page you may download a complete log bundle for troubleshooting.
Note: YARN logs are not available when the cluster is running.
Documentation¶
If the Actions > Documentation option is available it will take you to up-to-date documentation of H2O.
Launch Copy of Cluster¶
You can launch a copy of a cluster by clicking the Actions > Launch Copy option. You must give the cluster a name before you can launch it.
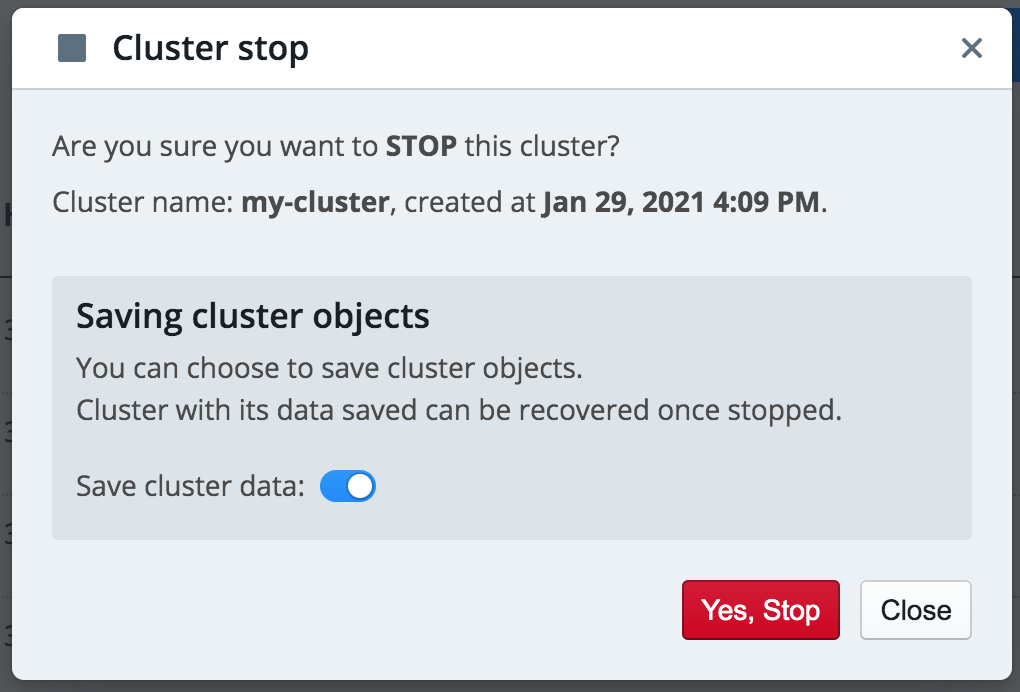
Stopping Clusters¶
To stop a Running cluster, click the Actions > Stop option. When the confirmation window appears, click the Yes, Stop button to stop the cluster.
You can also choose whether to save cluster data if your profile allows it. If chosen, such cluster can be restarted and its data recovered.
Restarting saved Clusters¶
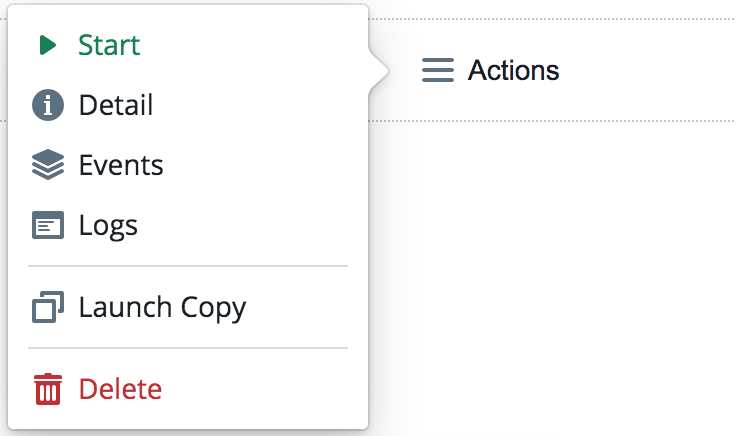
Cluster that has been saved can be restarted and its data recovered by clicking on Actions > Start option. Following limitations apply based on used H2O version.
saved data can be loaded only into clusters with the same version of H2O
3.32.0.1 and earlier versions: all models are saved and restored
3.32.0.2 and later: all models and grids are saved and restored
3.34.0.1 and later: all models, grids and frames of data are saved and restored
Marking Clusters as Failed¶
On a rare occasion, a cluster might get stuck in a Stopping state due to infrastructure failure. To manually resolve this situation, you can mark cluster as Failed with Actions > Mark as failed.
Deleting Clusters¶
To delete a cluster, click the Actions > Delete option beside the cluster that you want to delete, then confirm the request.
Notebooks¶
Enterprise Steam allows you to upload and run PySparkling and RSparking Jupyter Notebooks from within the cluster. More information about Jupyter Notebooks is available here: https://jupyter.org/.
Accessing Notebooks¶
In the Enterprise Steam UI, navigate to the Clusters page and click the My Notebooks button in the upper-right corner to view available notebooks.
Creating New Notebooks¶
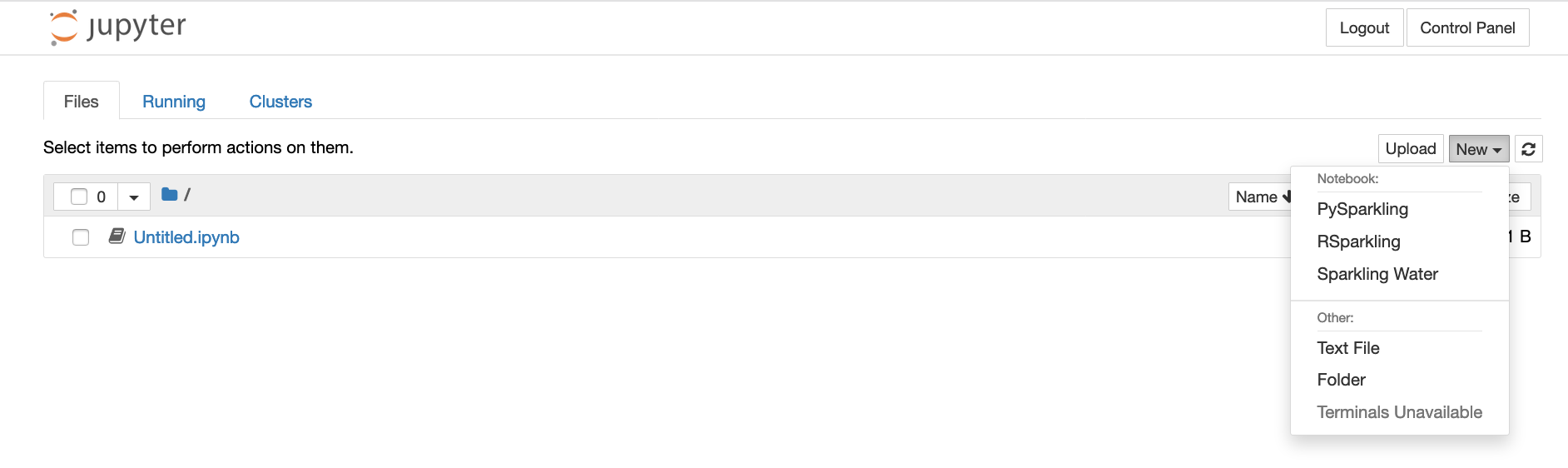
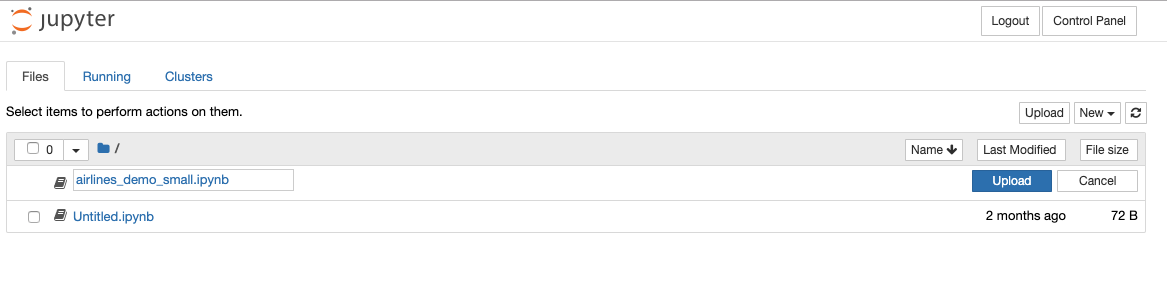
On the Jupyter Notebook Files tab, click New dropdown and select the type of notebook or other file that you want to create. Then create and save the new notebook.
Adding Notebooks¶
On the Jupyter Notebook Files tab, click the Upload button.
Browse to the location on your local machine where your notebooks is stored.
Click Upload to complete the notebook upload process.
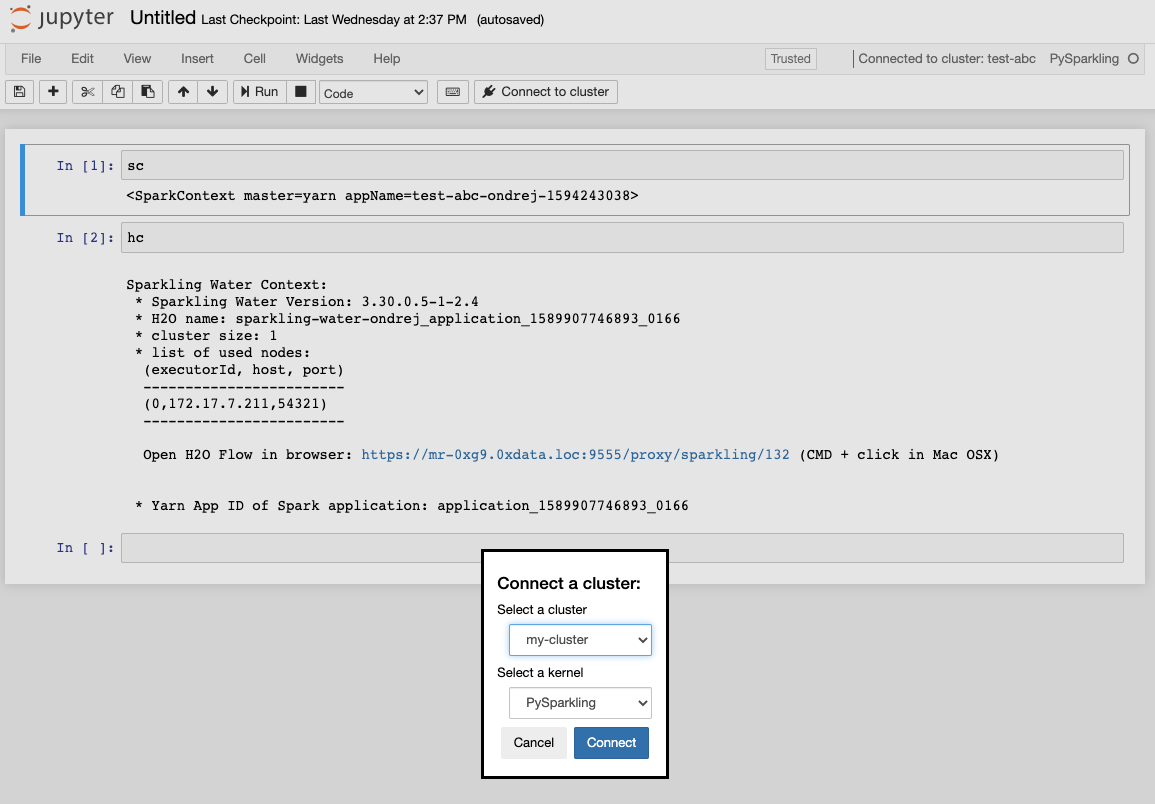
Connecting Notebooks¶
Once you open a notebook you have to connect it to one of your running clusters.
On the Jupyter Notebook page, click the Connect to cluster button.
Select which cluster to connect to.
Select which kernel to use.
Click Connect to link the notebook with the cluster.
All cells in the notebook now execute on the Sparkling Water cluster. SparkContext is automatically available as a variable sc and H2OContext as hc as seen below.