Create your own evaluation datasets
Overview
The Custom Eval feature in H2O LLM DataStudio enables you to create your own evaluation datasets from various document formats (such as PDFs and DOC files), from audio and video files and existing datasets. These evaluation datasets can be downloaded in JSON formats for each evaluation type, allowing for seamless integration with H2O Eval Studio.
Custom Eval only supports English language.
Instructions
To create your own evaluation dataset, consider the following instructions:
Before starting the process, you must integrate h2ogpte by providing the required credentials. You cannot create a new eval dataset without configuring h2ogpte. For more information, see Settings.
- On the H2O LLM DataStudio left navigation menu, click Custom Eval.
- On the Create Your Own Eval Datasets page, click New.
- On the Project name text box, enter a name for the project.
- On the Description text box, enter a description for the project.
- On the Dataset type drop-down menu, select the evaluation dataset type. The available dataset types are,
-
Question type:
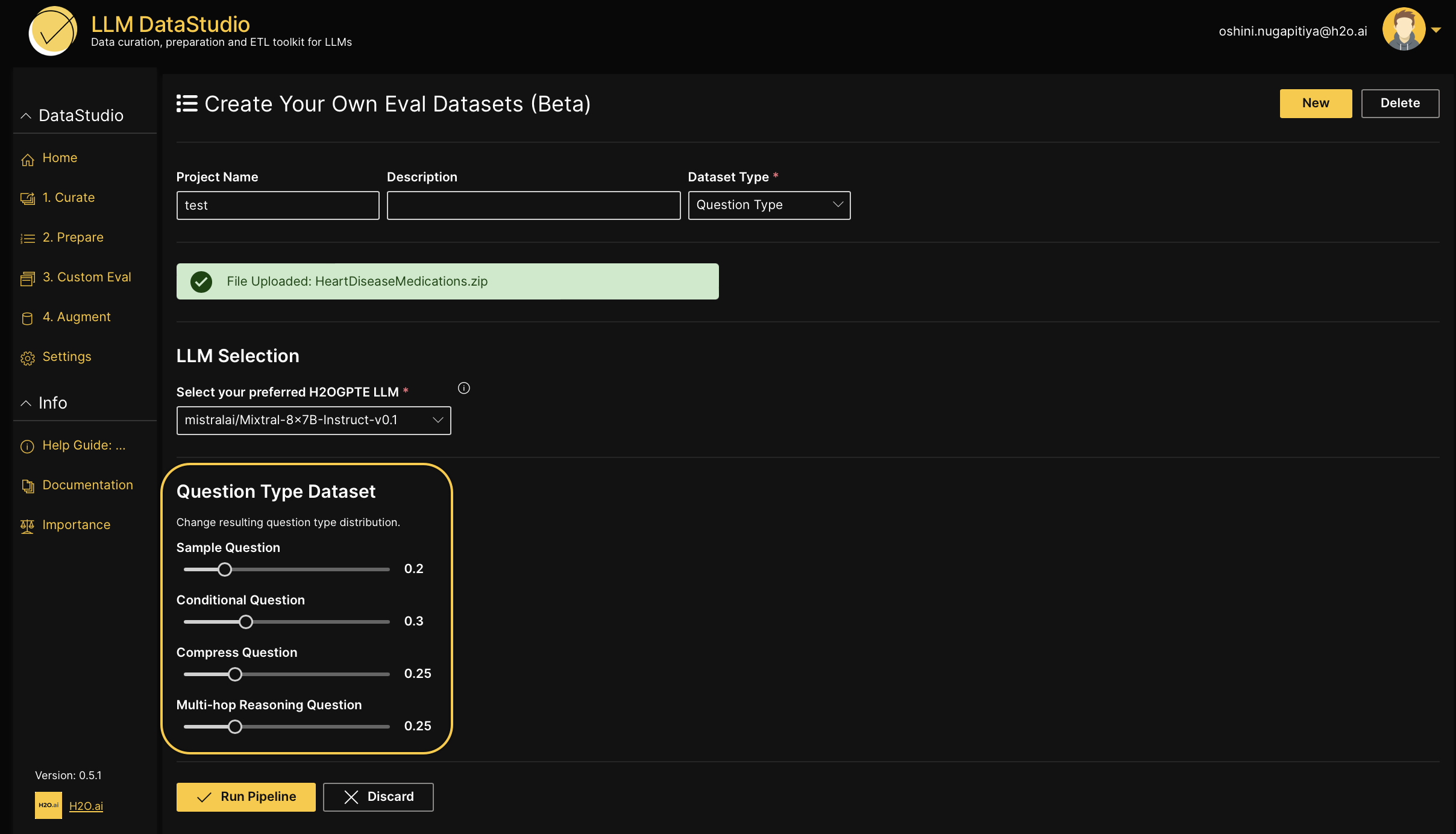
-
Simple question: Simplifies the question and makes it easier to understand.
-
Conditional question: Increases question complexity by incorporating scenarios or conditions affecting the context.
-
Compress question: Makes the question more indirect and shorter while retaining its essence.
-
Multihop reasoning question: Increases question complexity by requiring multiple logical connections or inferences.
-
Multi-Choice: In this dataset, each entry consists of a question followed by multiple answer choices with one correct, or most appropriate answer and three incorrect choices.
-
Token presence: In this dataset, each entry includes a question, the correct answer, and a list of key tokens that are relevant to the answer.
-
- In the Do you already have a QA Dataset? drop-down menu, select Yes if you have a Q&A dataset in CSV format. Otherwise, click No.
If you select No, H2O LLM DataStudio will generate Q&A pairs from the uploaded document for you.
7. In the Ingestion pipeline selection section, toggle the Use h2oGPTe's ingestion pipeline option to choose between using the h2oGPTe's ingestion pipeline or the default LLM DataStudio pipeline.
If this is turned on, it will initiate the following process:
- A new collection is created in h2oGPTe.
- The document is uploaded directly to this collection.
- h2oGPTe generates and returns content chunks from the uploaded document.
If this is turned off, the ingestion pipeline of LLM DataStudio is used automatically.
-
Click Next.
-
If you selected Yes on the Do you already have a QA Dataset? drop-down menu, follow these steps:
- Click Browse to upload the Q&A dataset in CSV file format.
- Click Upload.
- In the LLM selection section, select your preferred H2OGPTE LLM from the available LLMs.
- In the Configure columns section, select the columns which contain the context, question, and answer from the given options.
- In the Question type dataset section, configure the question type distribution for the resulting evaluation dataset.
- Click Run pipeline.
If you selected No on the Do you already have a QA Dataset? drop-down menu, follow these steps:
- Click Browse to upload the document or add the webpage URL if you are generating question-answer pairs from a webpage, or PDF web URL.
- Click Upload.
- In the LLM selection section, select your preferred H2OGPTE LLM from the available LLMs.
- Use the slider labeled Number of tokens per chunk to adjust the tokenization settings. This controls the maximum number of tokens per chunk of text processed by the model. The default is set to 1000 tokens.
- In the Question type dataset section, configure the question type distribution for the resulting evaluation dataset.
- Click Run pipeline.
- Submit and view feedback for this page
- Send feedback about H2O LLM DataStudio | Docs to cloud-feedback@h2o.ai