Interpreting a Model¶
There are two methods you can use for interpreting models:
- Using the Interpret this Model button on a completed experiment page to interpret a Driverless AI model on original and transformed features.
- Using the MLI (Machine Learning Interpretability) link in the upper right corner of the UI to interpret either a Driverless AI model or an external model.
Notes:
- MLI no longer runs on experiments from previous releases, but also does not require internet to run on current models.
- MLI is not supported for NLP experiments. Please contact H2O support for assistance with interpreting NLP experiments.
Additional Resources¶
Click hereto download our MLI cheat sheet.- Click here to view our H2O Driverless AI Machine Learning Interpretability walkthrough video.
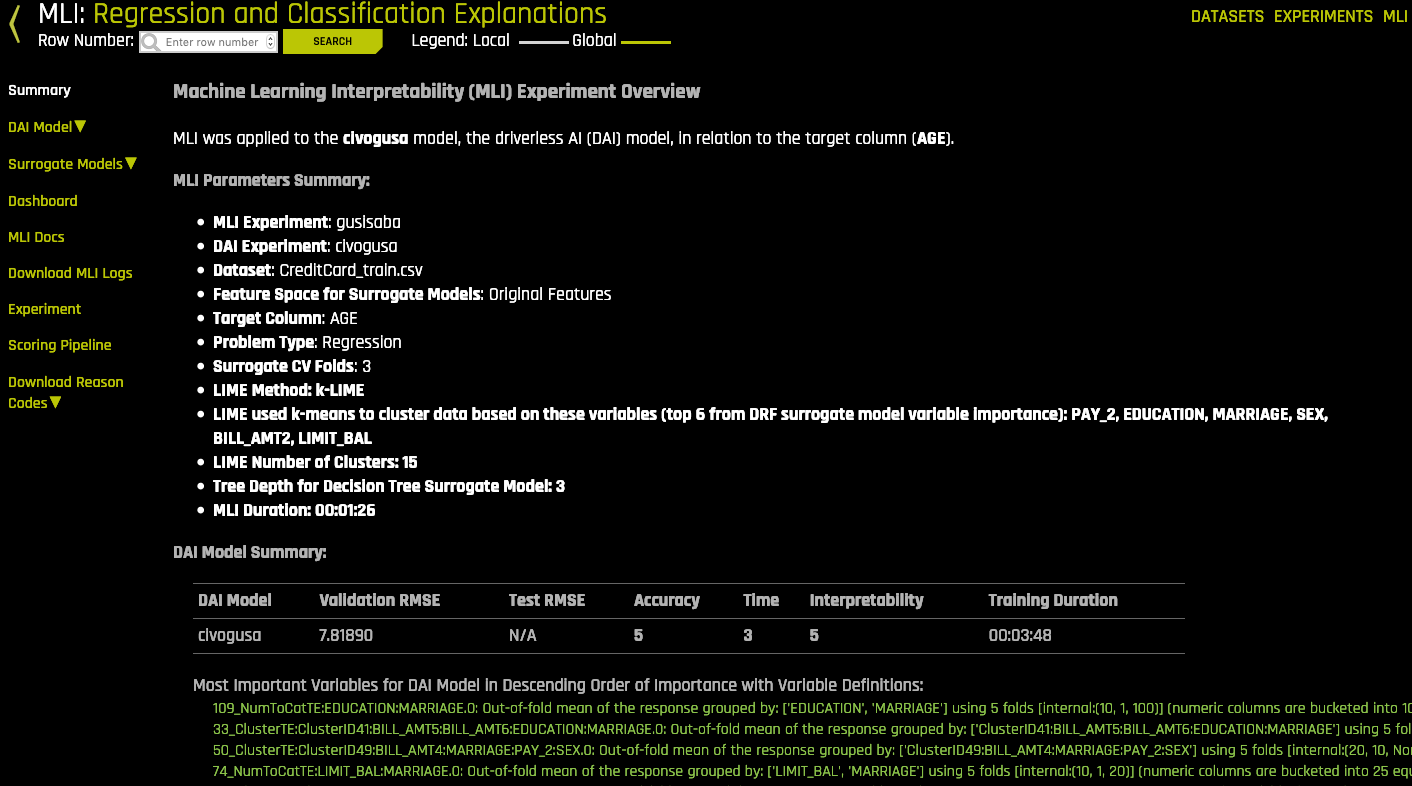
Intrepret this Model Button - Non-Time-Series¶
Clicking the Interpret this Model button on a completed experiment page launches the Model Interpretation for that experiment. Python and Java logs can be viewed for non-time-series experiments while the interpretation is running.
For non-time-series experiments, this page provides several visual explanations and reason codes for the trained Driverless AI model and its results. More information about this page is available in the Understanding the Model Interpretation Page section later in this chapter.
Interpret this Model Button - Time-Series¶
Limitations:
- MLI for time series will not run without a test set from a Driverless AI experiment. In future releases, internal validation predictions will be used if a test set is not provided.
- When the test set contains actuals, you will see the time series metric plot and the group metrics table. If there are no actuals, MLI will run, but you will see only the prediction value time series and a Shapley table.
- Model interpretation for time-series experiments is currently in an alpha state and changes are imminent.
Multi-Group Time Series MLI¶
This section describes how to run MLI on time series data for multiple groups.
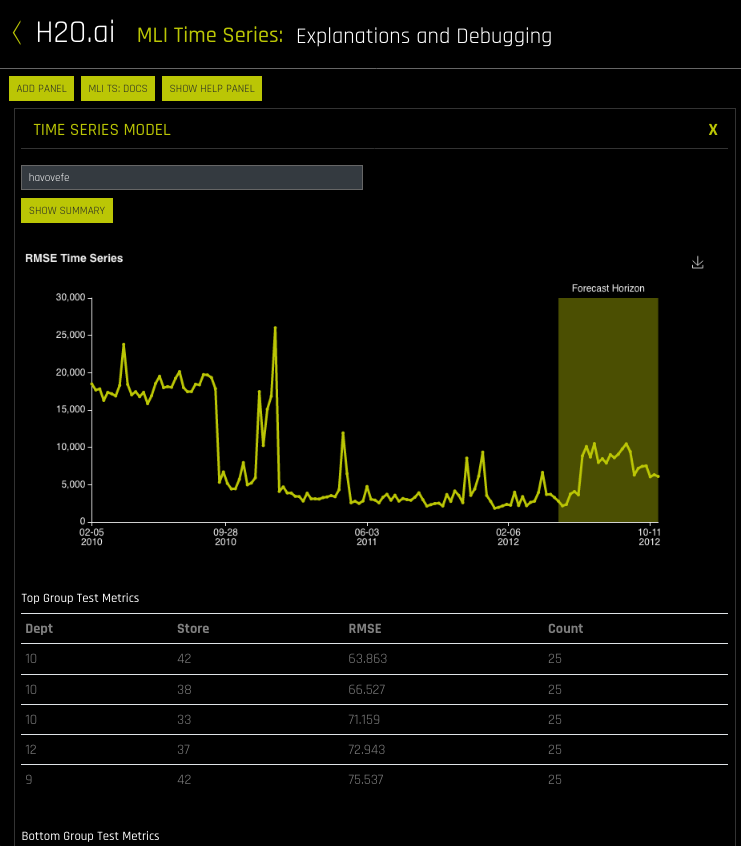
- Click the Interpret this Model (alpha) button on a completed time series experiment to launch Model Interpretation for that experiment. This page includes the following:
- A Help panel describing how to read and use this page. Click the Hide Help Button to hide this text.
- If the test set includes actuals, then a panel will display showing a time series plot and the top and bottom group matrix tables based on the scorer that was used in the experiment. Note that this panel can be resized if necessary.
- A Show Summary button that provides details about the experiment settings that were used.
- A Group Search entry field for selecting the groups to view.
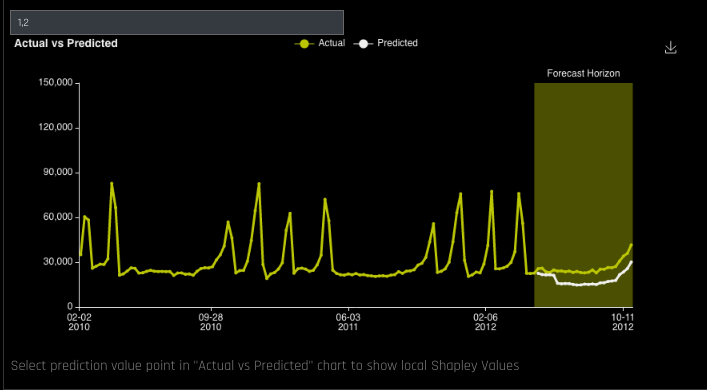
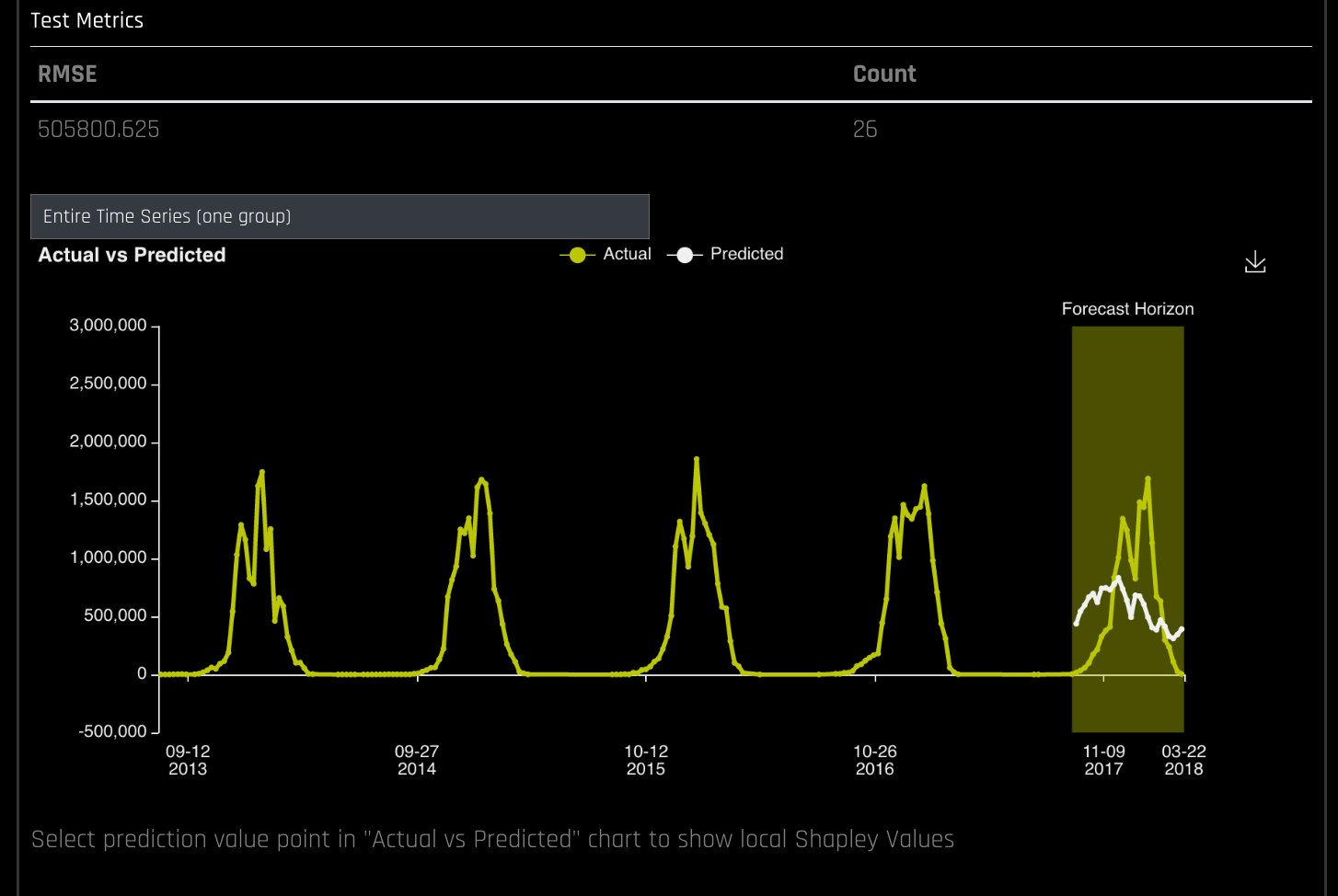
- Scroll to the bottom of the panel and select a grouping in the Group Search field to view a graph of Actual vs. Predicted values for the group. The outputted graph can be downloaded to your local machine.
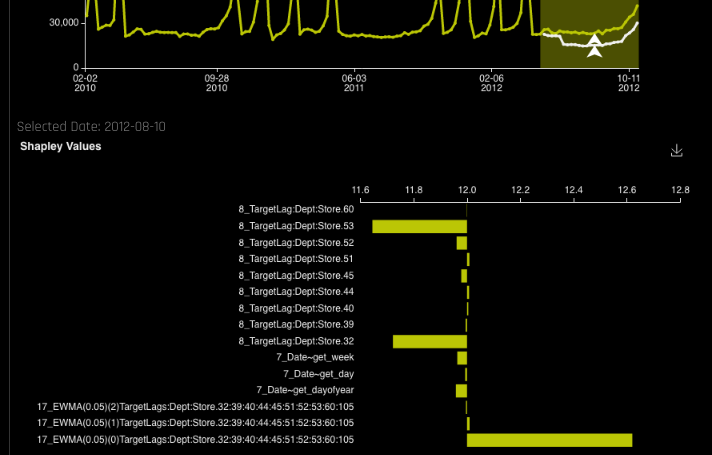
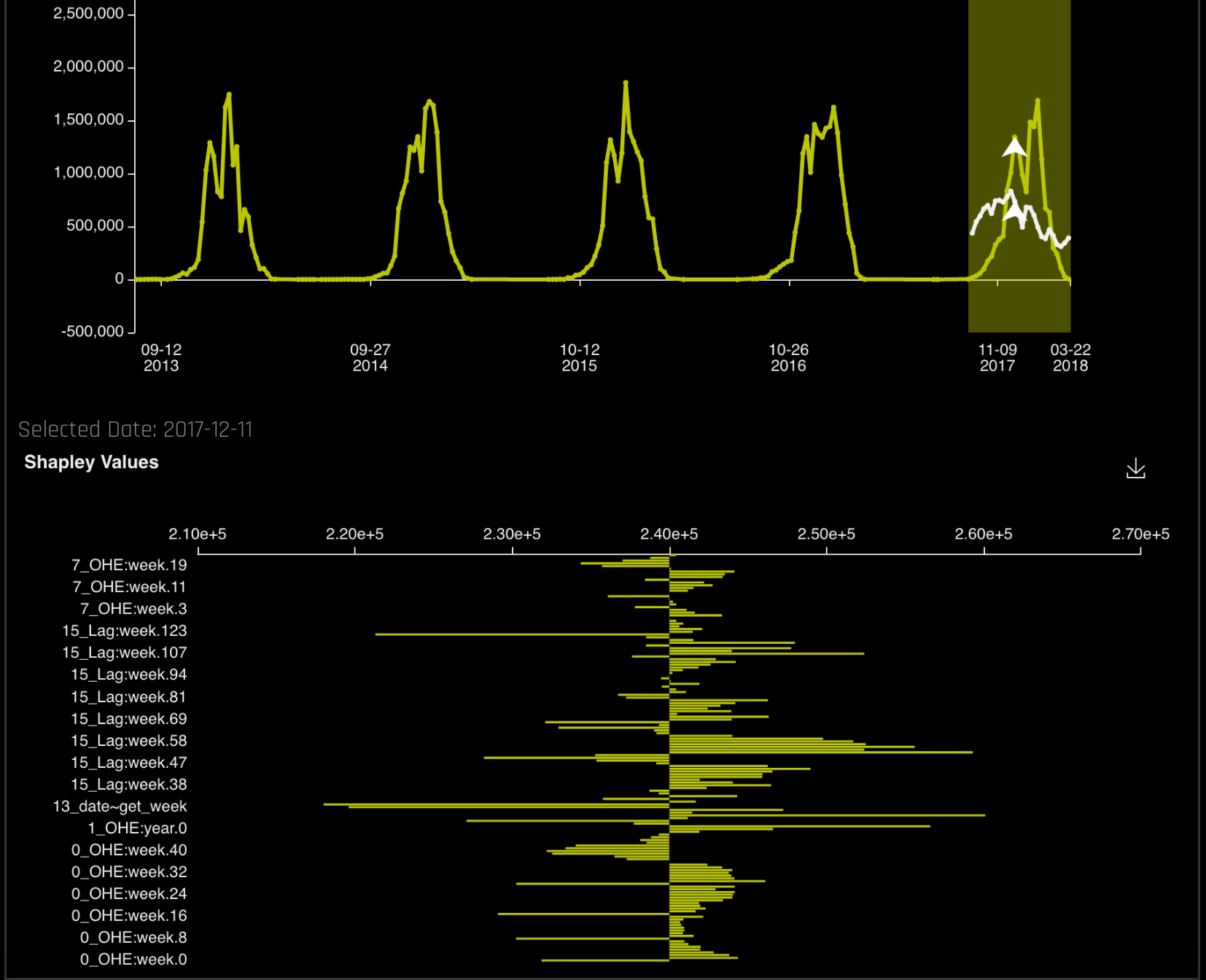
- Click on a prediction point in the plot (white line) to view Shapley values for that prediction point. The Shapley values plot can also be downloaded to your local machine.
- Click Add Panel to add a new MLI Time Series panel. This allows you to compare different groups in the same model and also provides the flexibility to do a “side-by-side” comparison between different models.
Single Time Series MLI¶
Time Series MLI can also be run when only one group is available.
- Click the Interpret this Model (alpha) button on a completed time series experiment to launch Model Interpretation for that experiment. This page includes the following:
- A Help panel describing how to read and use this page. Click the Hide Help Button to hide this text.
- If the test set includes actuals, then a panel will display showing a time series plot showing the single group’s matrix tables based on the scorer that was used in the experiment. Note that this panel can be resized if necessary.
- A Show Summary button that provides details about the experiment settings that were used.
- A Group Search entry field for selecting the group to view. Note that for Single Time Series MLI, there will only be one option in this field.
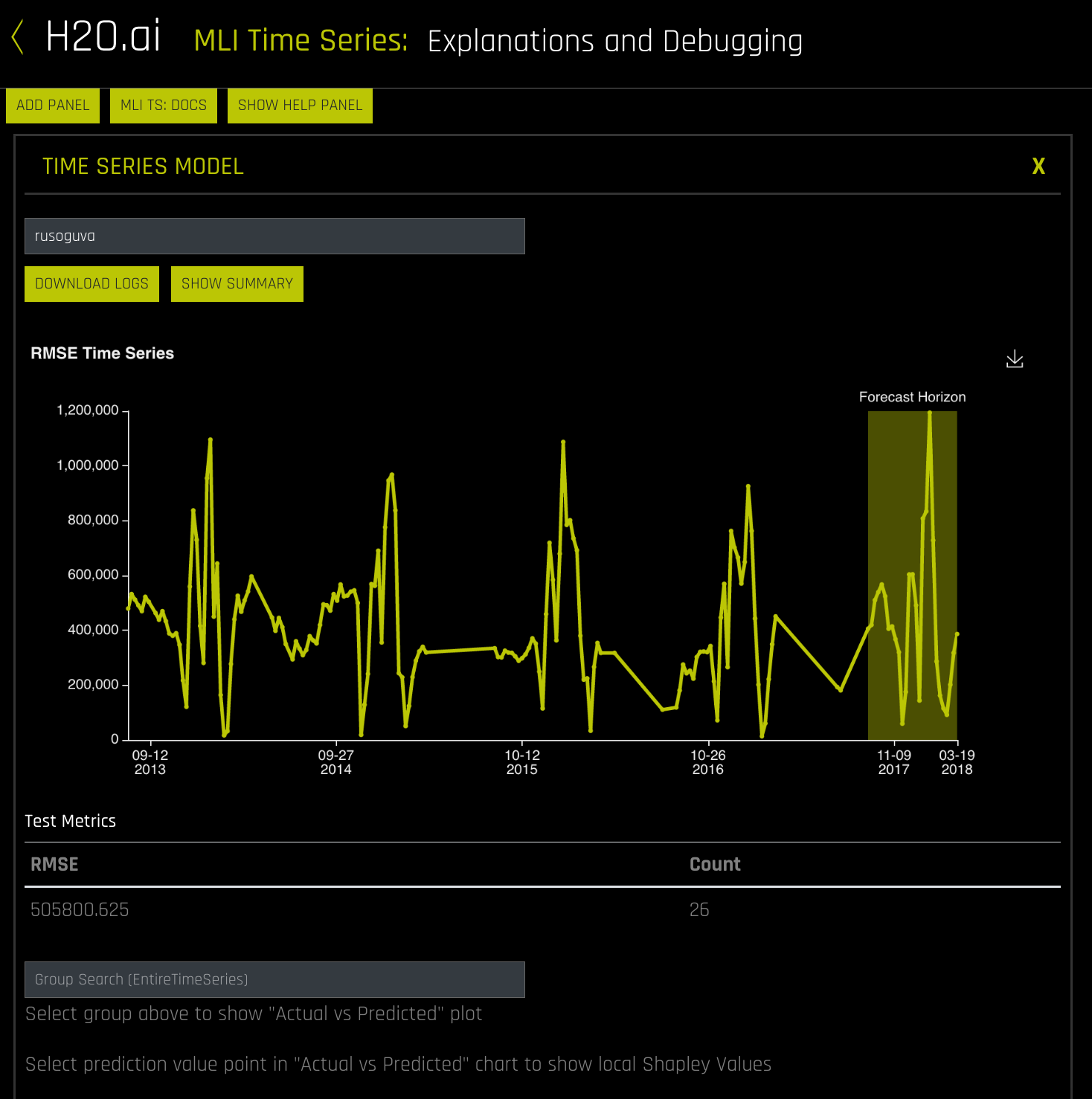
- Scroll to the bottom of the panel and select an option in the Group Search field to view a graph of Actual vs. Predicted values for the group. (Note that for Single Time Series MLI, there will only be one option in this field.) The outputted graph can be downloaded to your local machine.
- Click on a prediction point in the plot (white line) to view Shapley values for that prediction point. The Shapley values plot can also be downloaded to your local machine.
- Click Add Panel to add a new MLI Time Series panel. This allows you to do a “side-by-side” comparison between different models.
Model Interpretation on Driverless AI Models¶
This method allows you to run model interpretation on a Driverless AI model. This method is similar to clicking “Interpret This Model” on an experiment summary page.
- Click the MLI link in the upper-right corner of the UI to view a list of interpreted models.

- Click the New Interpretation button.
- Select the dataset that was used to train the model that you will use for interpretation.
- Specify the Driverless AI model that you want to use for the interpretation. Once selected, the Target Column used for the model will be selected.
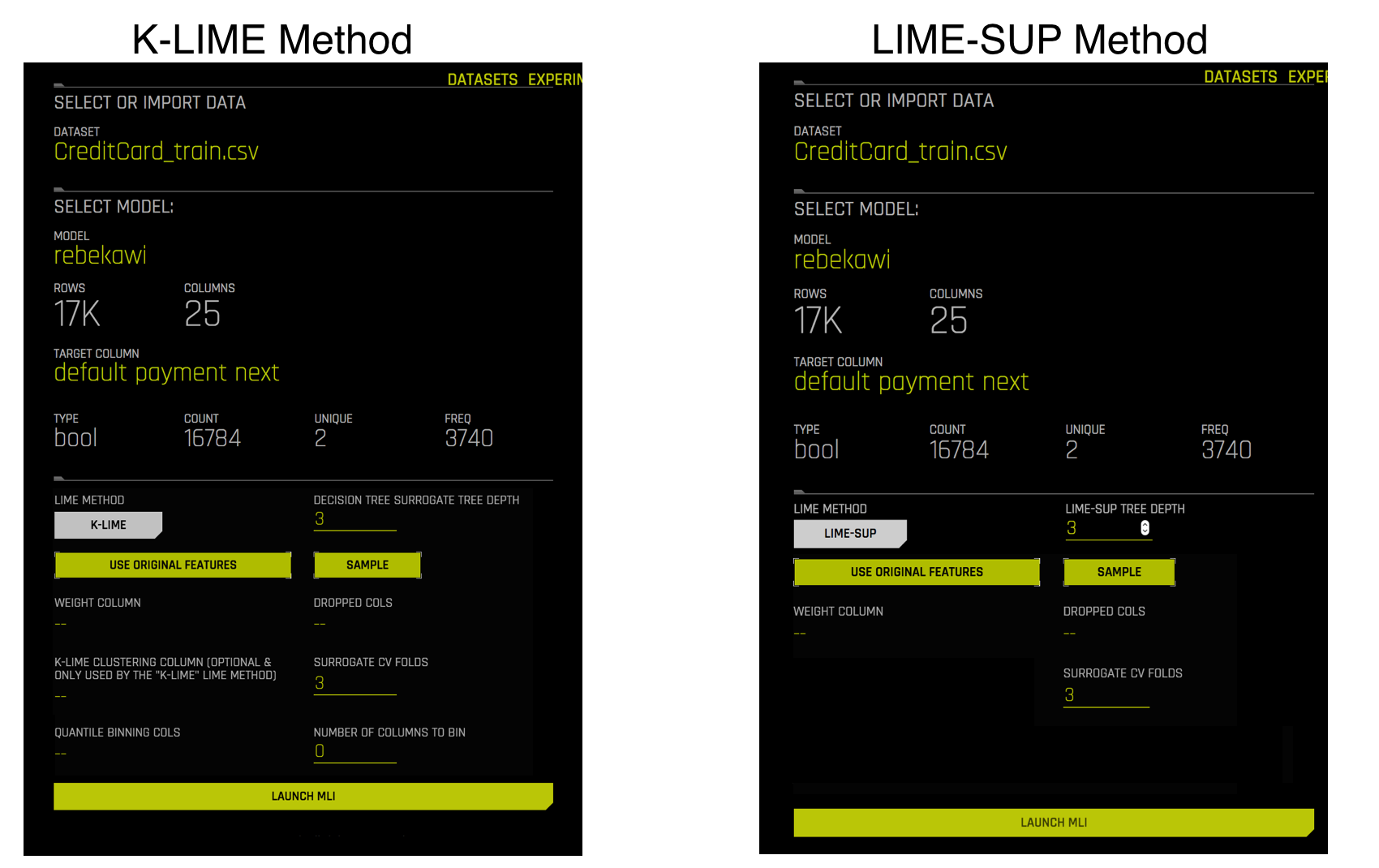
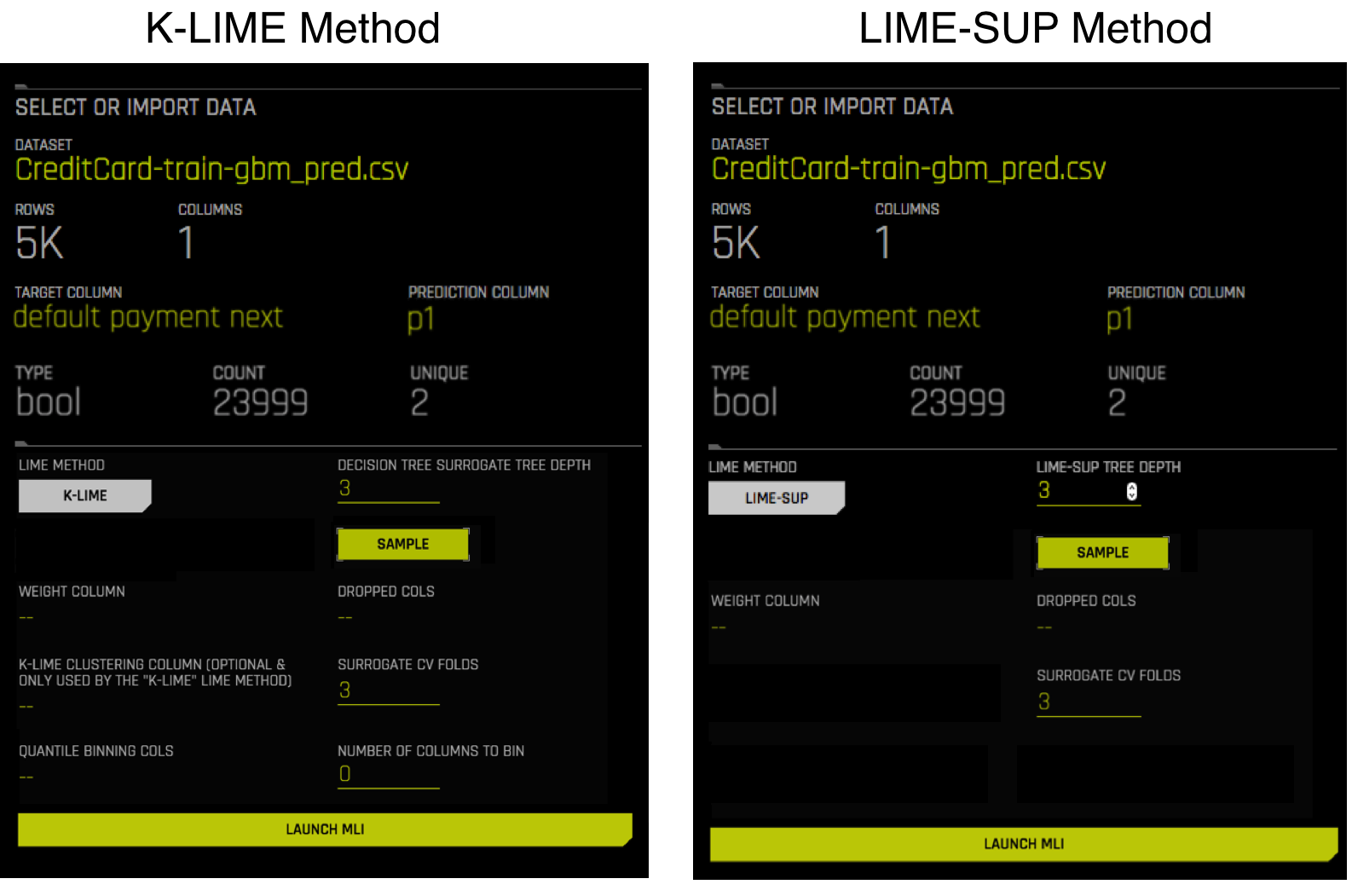
- Select a LIME method of either K-LIME (default) or LIME-SUP.
- K-LIME creates one global surrogate GLM on the entire training data and also creates numerous local surrogate GLMs on samples formed from k-means clusters in the training data. The features used for k-means are selected from the Random Forest surrogate model’s variable importance. The number of features used for k-means is the minimum of the top 25% of variables from the Random Forest surrogate model’s variable importance and the max number of variables that can be used for k-means, which is set by the user in the config.toml setting for
mli_max_number_cluster_vars. (Note, if the number of features in the dataset are less than or equal to 6, then all features are used for k-means clustering.) The previous setting can be turned off to use all features for k-means by settinguse_all_columns_klime_kmeansin the config.toml file totrue. All penalized GLM surrogates are trained to model the predictions of the Driverless AI model. The number of clusters for local explanations is chosen by a grid search in which the \(R2\) between the Driverless AI model predictions and all of the local K-LIME model predictions is maximized. The global and local linear model’s intercepts, coefficients, \(R2\) values, accuracy, and predictions can all be used to debug and develop explanations for the Driverless AI model’s behavior.- LIME-SUP explains local regions of the trained Driverless AI model in terms of the original variables. Local regions are defined by each leaf node path of the decision tree surrogate model instead of simulated, perturbed observation samples - as in the original LIME. For each local region, a local GLM model is trained on the original inputs and the predictions of the Driverless AI model. Then the parameters of this local GLM can be used to generate approximate, local explanations of the Driverless AI model.
- For K-LIME interpretations, specify the depth that you want for your decision tree surrogate model. The tree depth value can be a value from 2-5 and defaults to 3. For LIME-SUP interpretations, specify the LIME-SUP tree depth. This can be a value from 2-5 and defaults to 3.
- Specify whether to use original features or transformed features in the surrogate model for the new interpretation. Note: If this option is disabled, then the K-LIME clustering column option will not be available, and quantile binning will not be available.
- Specify whether to perform the interpretation on a sample of the training data. By default, MLI will sample the training dataset if it is greater than 100k rows. (Note that this value can be modified in the config.toml setting for
mli_sample_size.) Turn this toggle off to run MLI on the entire dataset. - Optionally specify weight and dropped columns.
- For K-LIME interpretations, optionally specify a clustering column. Note that this column should be categorical. Also note that this is only available when K-LIME is used as the LIME method and when Use Original Features is enabled. If the LIME method is changed to LIME-SUP, then this option is no longer available.
- Optionally specify the number of surrogate cross-validation folds to use (from 0 to 10). When running experiments, Driverless AI automatically splits the training data and uses the validation data to determine the performance of the model parameter tuning and feature engineering steps. For a new interpretation, Driverless AI uses 3 cross-validation folds by default for the interpretation.
- For K-LIME interpretations, optionally specify one or more columns to generate decile bins (uniform distribution) to help with MLI accuracy. Columns selected are added to top n columns for quantile binning selection. If a column is not numeric or not in the dataset (transformed features), then the column will be skipped. Note: This option is only available when Use Original Features is enabled.
- For K-LIME interpretations, optionally specify the number of top variable importance numeric columns to run decile binning to help with MLI accuracy. (Note that variable importances are generated from a Random Forest model.) This defaults to 0, and the maximum value is 10. Note: This option is only available when Use Original Features is enabled.
- Click the Launch MLI button.
Model Interpretation on External Models¶
Model Interpretation does not need to be run on a Driverless AI experiment. You can train an external model and run Model Interpretability on the predictions.
- Click the MLI link in the upper-right corner of the UI to view a list of interpreted models.
Click the New Interpretation button.
Select the dataset that you want to use for the model interpretation. This must include a prediction column that was generated by the external model. If the dataset does not have predictions, then you can join the external predictions. An example showing how to do this in Python is available in the Run Model Interpretation on External Model Predictions section of the Credit Card Demo.
Note: When running interpretations on an external model, leave the Select Model option empty. That option is for selecting a Driverless AI model.
Specify a Target Column (actuals) and the Prediction Column (scores from the model).
Select a LIME method of either K-LIME (default) or LIME-SUP.
- K-LIME creates one global surrogate GLM on the entire training data and also creates numerous local surrogate GLMs on samples formed from k-means clusters in the training data. The features used for k-means are selected from the Random Forest surrogate model’s variable importance. The number of features used for k-means is the minimum of the top 25% of variables from the Random Forest surrogate model’s variable importance and the max number of variables that can be used for k-means, which is set by the user in the config.toml setting for
mli_max_number_cluster_vars. (Note, if the number of features in the dataset are less than or equal to 6, then all features are used for k-means clustering.) The previous setting can be turned off to use all features for k-means by settinguse_all_columns_klime_kmeansin the config.toml file totrue. All penalized GLM surrogates are trained to model the predictions of the Driverless AI model. The number of clusters for local explanations is chosen by a grid search in which the \(R2\) between the Driverless AI model predictions and all of the local K-LIME model predictions is maximized. The global and local linear model’s intercepts, coefficients, \(R2\) values, accuracy, and predictions can all be used to debug and develop explanations for the Driverless AI model’s behavior.- LIME-SUP explains local regions of the trained Driverless AI model in terms of the original variables. Local regions are defined by each leaf node path of the decision tree surrogate model instead of simulated, perturbed observation samples - as in the original LIME. For each local region, a local GLM model is trained on the original inputs and the predictions of the Driverless AI model. Then the parameters of this local GLM can be used to generate approximate, local explanations of the Driverless AI model.
- For K-LIME interpretations, specify the depth that you want for your decision tree surrogate model. The tree depth value can be a value from 2-5 and defaults to 3. For LIME-SUP interpretations, specify the LIME-SUP tree depth. This can be a value from 2-5 and defaults to 3.
- Specify whether to perform the interpretation on a sample of the training data. By default, MLI will sample the training dataset if it is greater than 100k rows. (Note that this value can be modified in the config.toml setting for
mli_sample_size.) Turn this toggle off to run MLI on the entire dataset. - Optionally specify weight and dropped columns.
- For K-LIME interpretations, optionally specify a clustering column. Note that this column should be categorical. Also note that this is only available when K-LIME is used as the LIME method. If the LIME method is changed to LIME-SUP, then this option is no longer available.
- Optionally specify the number of surrogate cross-validation folds to use (from 0 to 10). When running experiments, Driverless AI automatically splits the training data and uses the validation data to determine the performance of the model parameter tuning and feature engineering steps. For a new interpretation, Driverless AI uses 3 cross-validation folds by default for the interpretation.
- For K-LIME interpretations, optionally specify one or more columns to generate decile bins (uniform distribution) to help with MLI accuracy. Columns selected are added to top n columns for quantile binning selection. If a column is not numeric or not in the dataset (transformed features), then the column will be skipped.
- For K-LIME interpretations, optionally specify the number of top variable importance numeric columns to run decile binning to help with MLI accuracy. (Note that variable importances are generated from a Random Forest model.) This value is combined with any specific columns selected for quantile binning. This defaults to 0, and the maximum value is 10.
- Click the Launch MLI button.
{kind=link}
Understanding the Model Interpretation Page¶
The Model Interpretation page opens with a Summary of the interpretation. This page also provides left-hand navigation for viewing additional plots. This navigation includes:
- Summary: Provides a summary of the MLI experiment. See the Summary Page section for more information.
- DAI Model: Provides Feature Importance and Shapley plots for transformed features. (Shapley plots not supported for RuleFit and TensorFlow models.) See DAI Model Dropdown for more information.
- Surrogate Models: Provides KLIME and Decision Tree plots. This also includes a Random Forest submenu, which includes Global and Local Feature Importance plots for original features and a Partial Dependence plot. See Surrogate Models Dropdown for more information.
- Dashboard: A single page with a Global Interpretable Model Explanations plot, a Feature Importance plot, a Decision Tree plot, and a Partial Dependence plot. See the Dashboard Page section for more information.
- MLI Docs: A link to the “Machine Learning Interpretability with Driverless AI” booklet.
- Download MLI Logs: Downloads a zip file of the logs that were generated during this interpretation.
- Experiment: Provides a link back to the experiment that generated this interpretation.
- Scoring Pipeline: Downloads the scoring pipeline for this interpretation.
- Download Reason Codes: Download a CSV file of LIME and/or Shapley reason codes.
Summary Page¶
The Summary page is the first page that opens when you view an interpretation. This page provides an overview of the interpretation, including the dataset and Driverless AI experiment (if available) that were used for the interpretation along with the feature space (original or transformed), target column, problem type, and k-Lime information. If the interpretation was created from a Driverless AI model, then a table with the Driverless AI model summary is also included along with the top variables for the model.
DAI Model Dropdown¶
This menu provides a Feature Importance plot and a Shapley plot (not supported for RuleFit and TensorFlow models) for transformed features.
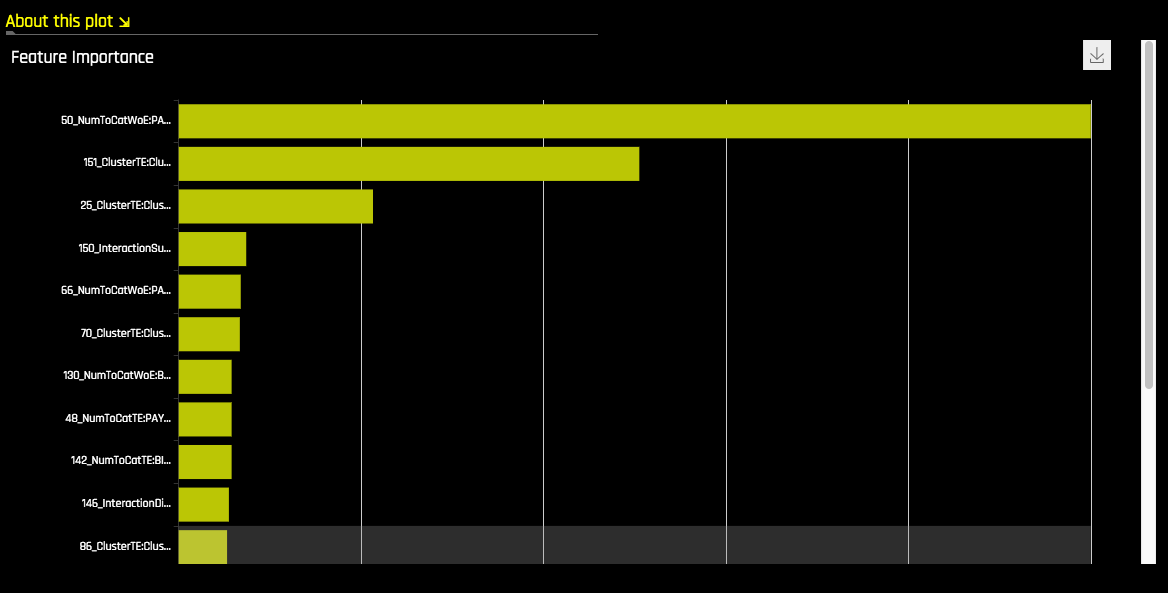
Feature Importance¶
This plot shows the Driverless AI feature importance. Driverless AI feature importance is a measure of the contribution of an input variable to the overall predictions of the Driverless AI model. Global feature importance is calculated by aggregating the improvement in splitting criterion caused by a single variable across all of the decision trees in the Driverless AI model.
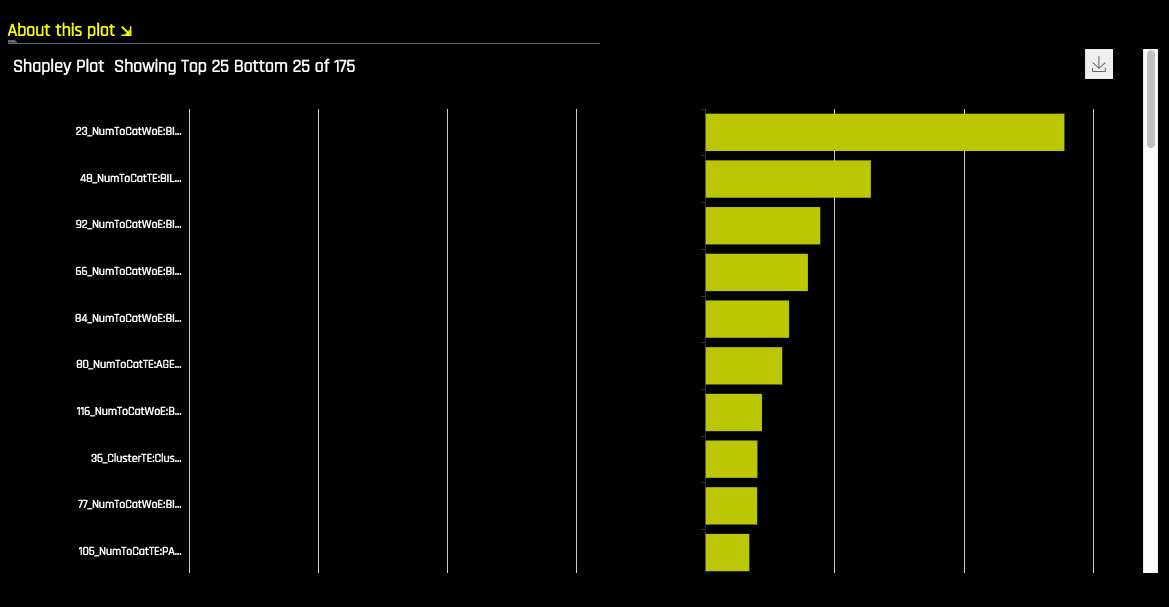
Shapley Plot¶
Shapley explanations are a technique with credible theoretical support that presents consistent global and local variable contributions. Local numeric Shapley values are calculated by tracing single rows of data through a trained tree ensemble and aggregating the contribution of each input variable as the row of data moves through the trained ensemble.
For regression tasks, Shapley values sum to the prediction of the Driverless AI model. For classification problems, Shapely values sum to the prediction of the Driverless AI model before applying the link function. Global Shapley values are the average of the absolute Shapley values over every row of a data set.
Note: Shapley plots are not supported for RuleFit and TensorFlow models.
More information is available at https://arxiv.org/abs/1706.06060.
Surrogate Models Dropdown¶
The Surrogate Models dropdown includes KLIME/LIME-SUP and Decision Tree plots as well as a Random Forest submenu, which includes Global and Local Feature Importance plots for original features and a Partial Dependence plot.
Note: For multiclass classification experiments, only the Local Feature Importance plot is available in this dropdown.
K-LIME and LIME-SUP¶
The MLI screen includes a KLIME or LIME-SUP graph. A KLIME graph is available by default when you interpret a model from the experiment page. When you create a new interpretation, you can instead choose to use LIME-SUP as the LIME method. Note that these graphs are essentially the same, but the KLIME/LIME-SUP distinction provides insight into the LIME method that was used during model interpretation.
The K-LIME Technique¶
K-LIME is a variant of the LIME technique proposed by Ribeiro at al (2016). K-LIME generates global and local explanations that increase the transparency of the Driverless AI model, and allow model behavior to be validated and debugged by analyzing the provided plots, and comparing global and local explanations to one-another, to known standards, to domain knowledge, and to reasonable expectations.
K-LIME creates one global surrogate GLM on the entire training data and also creates numerous local surrogate GLMs on samples formed from k-means clusters in the training data. The features used for k-means are selected from the Random Forest surrogate model’s variable importance. The number of features used for k-means is the minimum of the top 25% of variables from the Random Forest surrogate model’s variable importance and the max number of variables that can be used for k-means, which is set by the user in the config.toml setting for mli_max_number_cluster_vars. (Note, if the number of features in the dataset are less than or equal to 6, then all features are used for k-means clustering.) The previous setting can be turned off to use all features for k-means by setting use_all_columns_klime_kmeans in the config.toml file to true. All penalized GLM surrogates are trained to model the predictions of the Driverless AI model. The number of clusters for local explanations is chosen by a grid search in which the \(R^2\) between the Driverless AI model predictions and all of the local K-LIME model predictions is maximized. The global and local linear model’s intercepts, coefficients, \(R^2\) values, accuracy, and predictions can all be used to debug and develop explanations for the Driverless AI model’s behavior.
The parameters of the global K-LIME model give an indication of overall linear feature importance and the overall average direction in which an input variable influences the Driverless AI model predictions. The global model is also used to generate explanations for very small clusters (\(N < 20\)) where fitting a local linear model is inappropriate.
The in-cluster linear model parameters can be used to profile the local region, to give an average description of the important variables in the local region, and to understand the average direction in which an input variable affects the Driverless AI model predictions. For a point within a cluster, the sum of the local linear model intercept and the products of each coefficient with their respective input variable value are the K-LIME prediction. By disaggregating the K-LIME predictions into individual coefficient and input variable value products, the local linear impact of the variable can be determined. This product is sometimes referred to as a reason code and is used to create explanations for the Driverless AI model’s behavior.
In the following example, reason codes are created by evaluating and disaggregating a local linear model.
Given the row of input data with its corresponding Driverless AI and K-LIME predictions:
| debt_to_income_ ratio | credit_ score | savings_acct_ balance | observed_ default | H2OAI_predicted_ default | K-LIME_predicted_ default |
|---|---|---|---|---|---|
| 30 | 600 | 1000 | 1 | 0.85 | 0.9 |
And the local linear model:
\(\small{y_\text{K-LIME} = 0.1 + 0.01 * debt\_to\_income\_ratio + 0.0005 * credit\_score + 0.0002 * savings\_account\_balance}\)
It can be seen that the local linear contributions for each variable are:
- debt_to_income_ratio: 0.01 * 30 = 0.3
- credit_score: 0.0005 * 600 = 0.3
- savings_acct_balance: 0.0002 * 1000 = 0.2
Each local contribution is positive and thus contributes positively to the Driverless AI model’s prediction of 0.85 for H2OAI_predicted_default. By taking into consideration the value of each contribution, reason codes for the Driverless AI decision can be derived. debt_to_income_ratio and credit_score would be the two largest negative reason codes, followed by savings_acct_balance.
The local linear model intercept and the products of each coefficient and corresponding value sum to the K-LIME prediction. Moreover it can be seen that these linear explanations are reasonably representative of the nonlinear model’s behavior for this individual because the K-LIME predictions are within 5.5% of the Driverless AI model prediction. This information is encoded into English language rules which can be viewed by clicking the Explanations button.
Like all LIME explanations based on linear models, the local explanations are linear in nature and are offsets from the baseline prediction, or intercept, which represents the average of the penalized linear model residuals. Of course, linear approximations to complex non-linear response functions will not always create suitable explanations and users are urged to check the K-LIME plot, the local model \(R^2\), and the accuracy of the K-LIME prediction to understand the validity of the K-LIME local explanations. When K-LIME accuracy for a given point or set of points is quite low, this can be an indication of extremely nonlinear behavior or the presence of strong or high-degree interactions in this local region of the Driverless AI response function. In cases where K-LIME linear models are not fitting the Driverless AI model well, nonlinear LOCO feature importance values may be a better explanatory tool for local model behavior. As K-LIME local explanations rely on the creation of k-means clusters, extremely wide input data or strong correlation between input variables may also degrade the quality of K-LIME local explanations.
The LIME-SUP Technique¶
LIME-SUP explains local regions of the trained Driverless AI model in terms of the original variables. Local regions are defined by each leaf node path of the decision tree surrogate model instead of simulated, perturbed observation samples - as in the original LIME. For each local region, a local GLM model is trained on the original inputs and the predictions of the Driverless AI model. Then the parameters of this local GLM can be used to generate approximate, local explanations of the Driverless AI model.
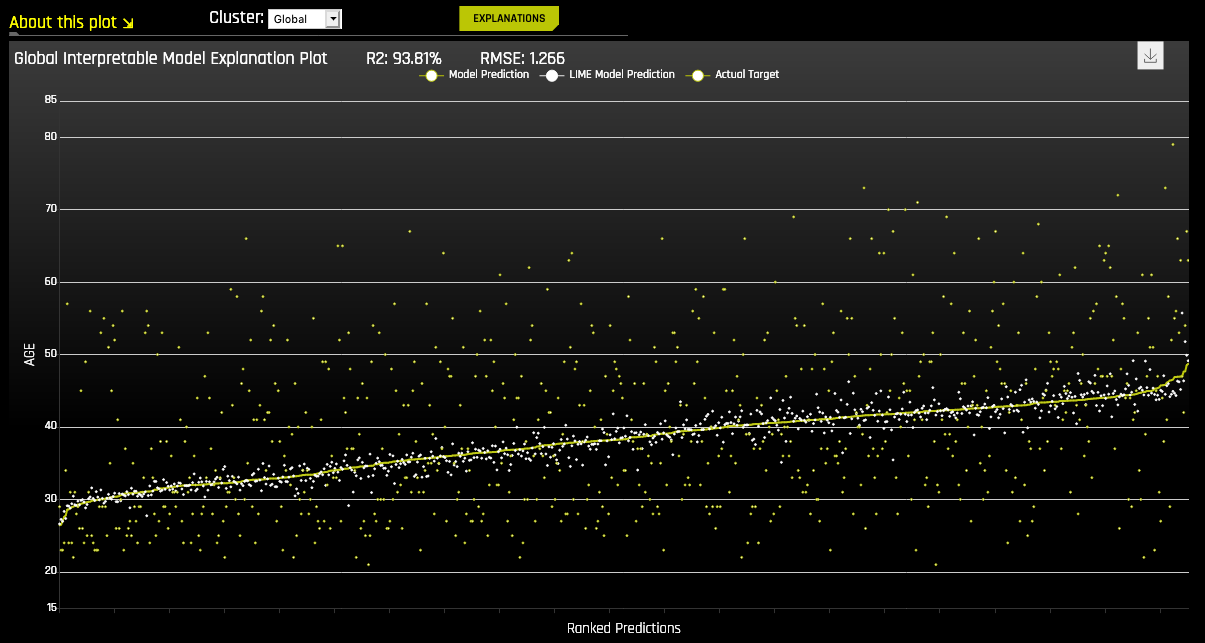
The Global Interpretable Model Explanation Plot
This plot shows Driverless AI model predictions and LIME model predictions in sorted order by the Driverless AI model predictions. This graph is interactive. Hover over the Model Prediction, LIME Model Prediction, or Actual Target radio buttons to magnify the selected predictions. Or click those radio buttons to disable the view in the graph. You can also hover over any point in the graph to view LIME reason codes for that value. By default, this plot shows information for the global LIME model, but you can change the plot view to show local results from a specific cluster. The LIME plot also provides a visual indication of the linearity of the Driverless AI model and the trustworthiness of the LIME explanations. The closer the local linear model approximates the Driverless AI model predictions, the more linear the Driverless AI model and the more accurate the explanation generated by the LIME local linear models.
Decision Tree¶
The Decision Tree Surrogate Model Technique¶
The decision tree surrogate model increases the transparency of the Driverless AI model by displaying an approximate flow-chart of the complex Driverless AI model’s decision making process. The decision tree surrogate model also displays the most important variables in the Driverless AI model and the most important interactions in the Driverless AI model. The decision tree surrogate model can be used for visualizing, validating, and debugging the Driverless AI model by comparing the displayed decision-process, important variables, and important interactions to known standards, domain knowledge, and reasonable expectations.
A surrogate model is a data mining and engineering technique in which a generally simpler model is used to explain another, usually more complex, model or phenomenon. The decision tree surrogate is known to date back at least to 1996 (Craven and Shavlik). The decision tree surrogate model here is trained to predict the predictions of the more complex Driverless AI model using the of original model inputs. The trained surrogate model enables a heuristic understanding (i.e., not a mathematically precise understanding) of the mechanisms of the highly complex and nonlinear Driverless AI model.
The Decision Tree Plot¶
In the Decision Tree plot, the highlighted row shows the path to the highest probability leaf node and indicates the globally important variables and interactions that influence the Driverless AI model prediction for that row.
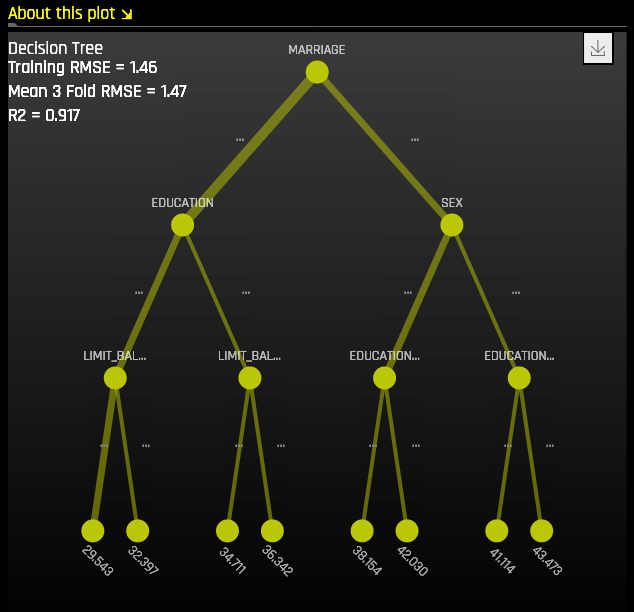
Random Forest Dropdown¶
The Random Forest dropdown provides a submenu that includes a Feature Importance plot, a Partial Dependence plot, and a LOCO plot. These plots are for original features rather than transformed features.
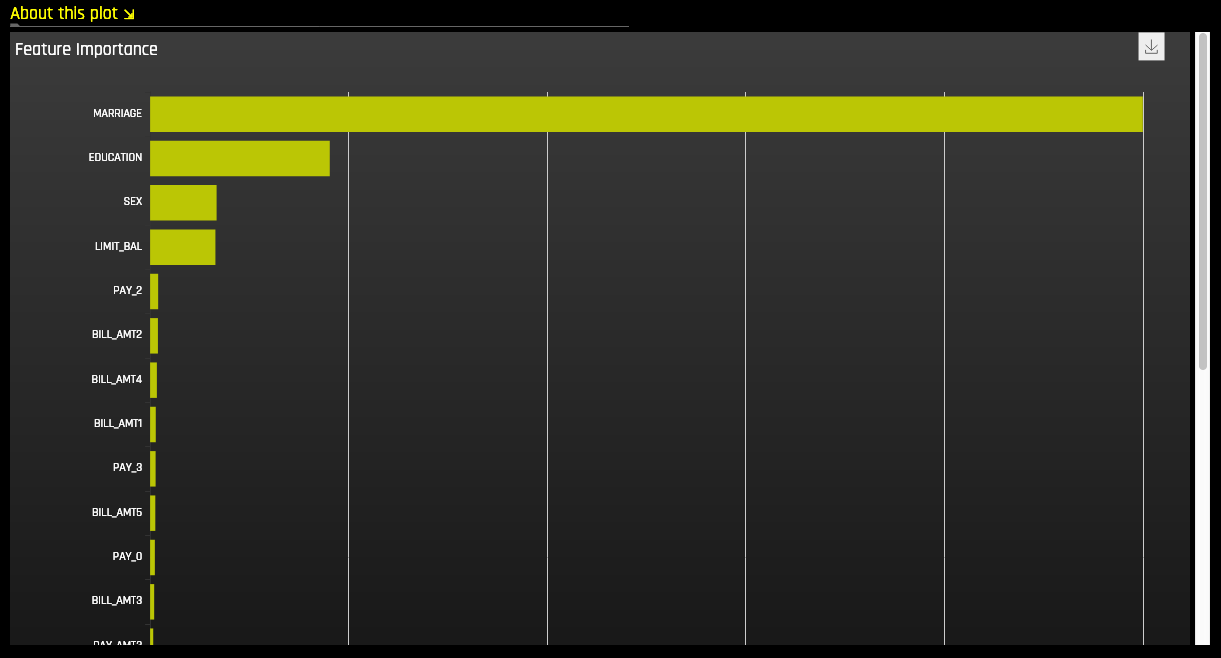
Feature Importance¶
Global Feature Importance vs Local Feature Importance
Global feature importance (yellow) is a measure of the contribution of an input variable to the overall predictions of the Driverless AI model. Global feature importance is calculated by aggregating the improvement in splitting criterion caused by a single variable across all of the decision trees in the Driverless AI model.
Local feature importance (grey) is a measure of the contribution of an input variable to a single prediction of the Driverless AI model. Local feature importance is calculated by removing the contribution of a variable from every decision tree in the Driverless AI model and measuring the difference between the prediction with and without the variable.
Both global and local variable importance are scaled so that the largest contributor has a value of 1.
Note: Engineered features are used for MLI when a time series experiment is built. This is because munged time series features are more useful features for MLI than raw time series features, as raw time series features are not IID (Independent and Identically Distributed).
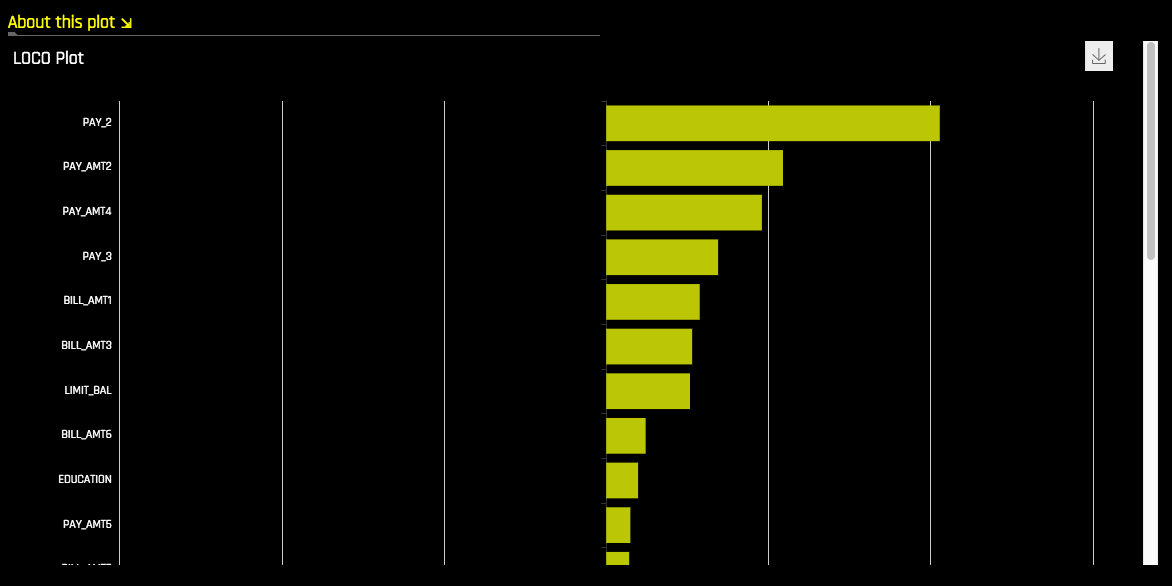
LOCO¶
Local feature importance describes how the combination of the learned model rules or parameters and an individual row’s attributes affect a model’s prediction for that row while taking nonlinearity and interactions into effect. Local feature importance values reported here are based on a variant of the leave-one-covariate-out (LOCO) method (Lei et al, 2017).
In the LOCO-variant method, each local feature importance is found by re-scoring the trained Driverless AI model for each feature in the row of interest, while removing the contribution to the model prediction of splitting rules that contain that feature throughout the ensemble. The original prediction is then subtracted from this modified prediction to find the raw, signed importance for the feature. All local feature importance values for the row are then scaled between 0 and 1 for direct comparison with global feature importance values.
Given the row of input data with its corresponding Driverless AI and K-LIME predictions:
| debt_to_income_ ratio | credit_ score | savings_acct_ balance | observed_ default | H2OAI_predicted_ default | K-LIME_predicted_ default |
|---|---|---|---|---|---|
| 30 | 600 | 1000 | 1 | 0.85 | 0.9 |
Taking the Driverless AI model as F(X), LOCO-variant feature importance values are calculated as follows.
First, the modified predictions are calculated:
\(F_{~debt\_to\_income\_ratio} = F(NA, 600, 1000) = 0.99\)
\(F_{~credit\_score} = F(30, NA, 1000) = 0.73\)
\(F_{~savings\_acct\_balance} = F(30, 600, NA) = 0.82\)
Second, the original prediction is subtracted from each modified prediction to generate the unscaled local feature importance values:
\(\text{LOCO}_{debt\_to\_income\_ratio} = F_{~debt\_to\_income\_ratio} - 0.85 = 0.99 - 0.85 = 0.14\)
\(\text{LOCO}_{credit\_score} = F_{~credit\_score} - 0.85 = 0.73 - 0.85 = -0.12\)
\(\text{LOCO}_{savings\_acct\_balance} = F_{~savings\_acct\_balance} - 0.85 = 0.82 - 0.85 = -0.03\)
Finally LOCO values are scaled between 0 and 1 by dividing each value for the row by the maximum value for the row and taking the absolute magnitude of this quotient.
\(\text{Scaled}(\text{LOCO}_{debt\_to\_income\_ratio}) = \text{Abs}(\text{LOCO}_{~debt\_to\_income\_ratio}/0.14) = 1\)
\(\text{Scaled}(\text{LOCO}_{credit\_score}) = \text{Abs}(\text{LOCO}_{~credit\_score}/0.14) = 0.86\)
\(\text{Scaled}(\text{LOCO}_{savings\_acct\_balance}) = \text{Abs}(\text{LOCO}_{~savings\_acct\_balance} / 0.14) = 0.21\)
One drawback to these LOCO-variant feature importance values is, unlike K-LIME, it is difficult to generate a mathematical error rate to indicate when LOCO values may be questionable.
Partial Dependence and Individual Conditional Expectation (ICE)¶
The Partial Dependence Technique¶
Partial dependence is a measure of the average model prediction with respect to an input variable. Partial dependence plots display how machine-learned response functions change based on the values of an input variable of interest, while taking nonlinearity into consideration and averaging out the effects of all other input variables. Partial dependence plots are well-known and described in the Elements of Statistical Learning (Hastie et al, 2001). Partial dependence plots enable increased transparency in Driverless AI models and the ability to validate and debug Driverless AI models by comparing a variable’s average predictions across its domain to known standards, domain knowledge, and reasonable expectations.
The ICE Technique¶
Individual conditional expectation (ICE) plots, a newer and less well-known adaptation of partial dependence plots, can be used to create more localized explanations for a single individual using the same basic ideas as partial dependence plots. ICE Plots were described by Goldstein et al (2015). ICE values are simply disaggregated partial dependence, but ICE is also a type of nonlinear sensitivity analysis in which the model predictions for a single row are measured while a variable of interest is varied over its domain. ICE plots enable a user to determine whether the model’s treatment of an individual row of data is outside one standard deviation from the average model behavior, whether the treatment of a specific row is valid in comparison to average model behavior, known standards, domain knowledge, and reasonable expectations, and how a model will behave in hypothetical situations where one variable in a selected row is varied across its domain.
Given the row of input data with its corresponding Driverless AI and K-LIME predictions:
| debt_to_income_ ratio | credit_ score | savings_acct_ balance | observed_ default | H2OAI_predicted_ default | K-LIME_predicted_ default |
|---|---|---|---|---|---|
| 30 | 600 | 1000 | 1 | 0.85 | 0.9 |
Taking the Driverless AI model as F(X), assuming credit scores vary from 500 to 800 in the training data, and that increments of 30 are used to plot the ICE curve, ICE is calculated as follows:
\(\text{ICE}_{credit\_score, 500} = F(30, 500, 1000)\)
\(\text{ICE}_{credit\_score, 530} = F(30, 530, 1000)\)
\(\text{ICE}_{credit\_score, 560} = F(30, 560, 1000)\)
\(...\)
\(\text{ICE}_{credit\_score, 800} = F(30, 800, 1000)\)
The one-dimensional partial dependence plots displayed here do not take interactions into account. Large differences in partial dependence and ICE are an indication that strong variable interactions may be present. In this case partial dependence plots may be misleading because average model behavior may not accurately reflect local behavior.
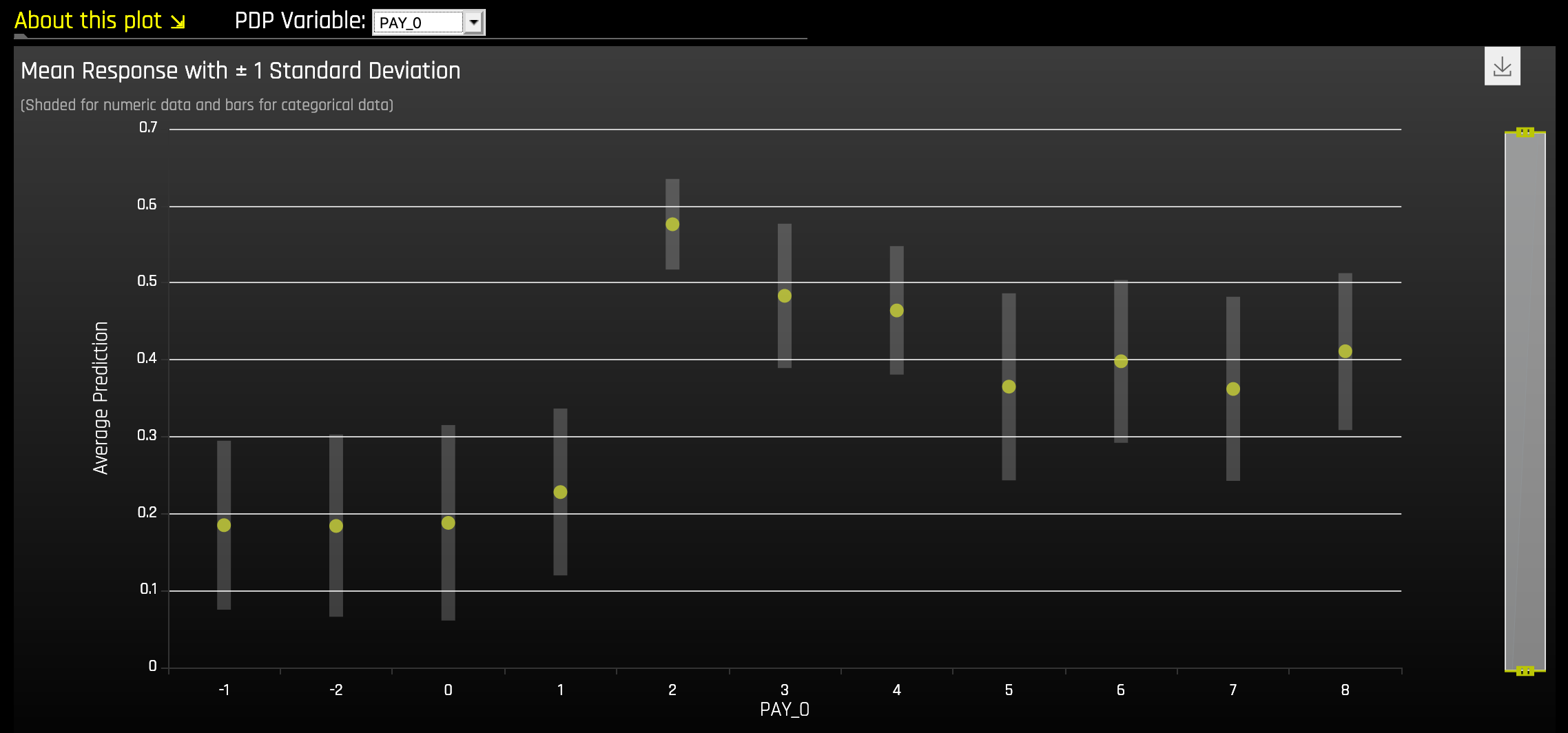
The Partial Dependence Plot¶
Overlaying ICE plots onto partial dependence plots allow the comparison of the Driverless AI model’s treatment of certain examples or individuals to the model’s average predictions over the domain of an input variable of interest.
This plot shows the partial dependence when a variable is selected and the ICE values when a specific row is selected. Users may select a point on the graph to see the specific value at that point. Partial dependence (yellow) portrays the average prediction behavior of the Driverless AI model across the domain of an input variable along with +/- 1 standard deviation bands. ICE (grey) displays the prediction behavior for an individual row of data when an input variable is toggled across its domain. Currently, partial dependence and ICE plots are only available for the top ten most important original input variables. Categorical variables with 20 or more unique values are never included in these plots.
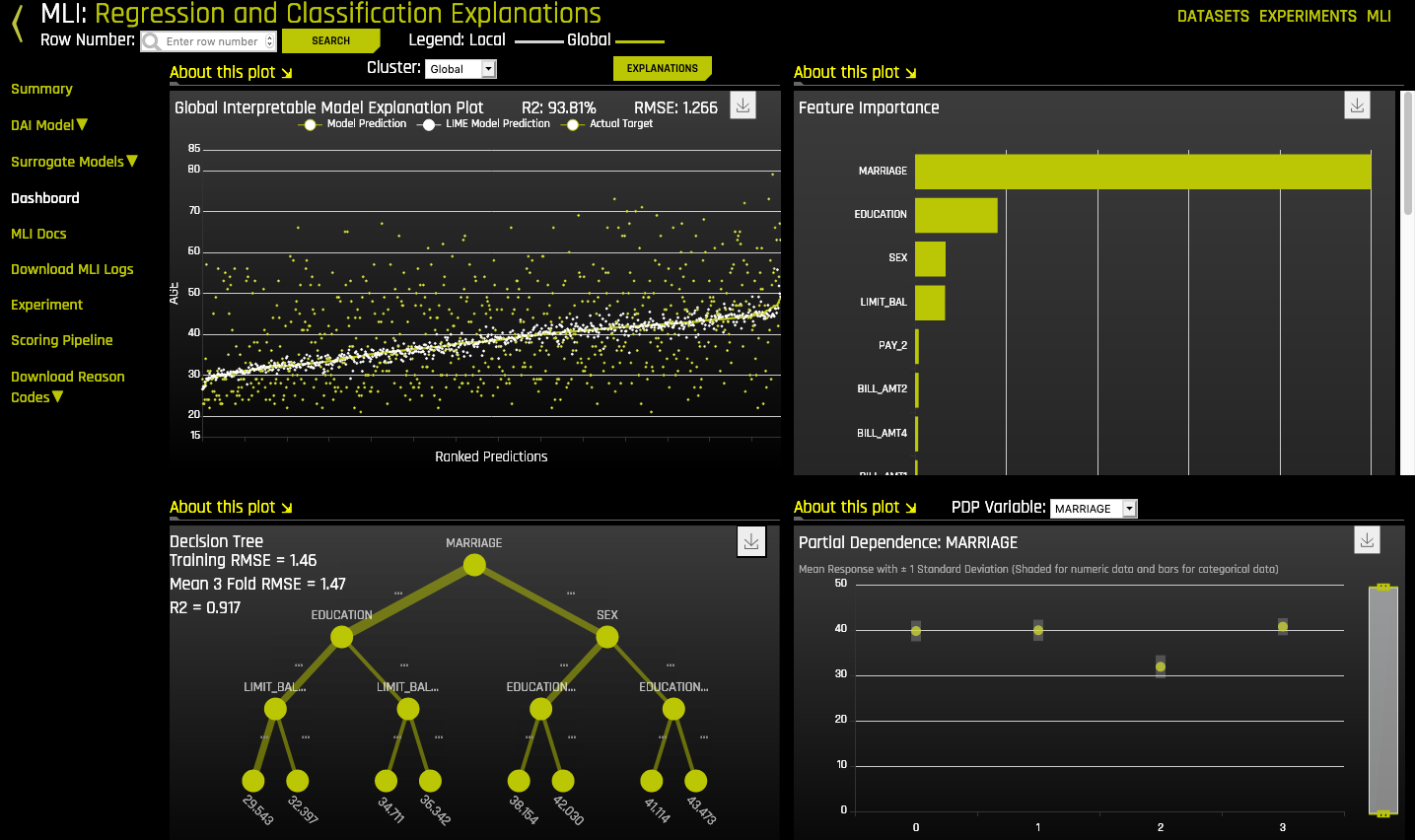
Dashboard Page¶
The Model Interpretation Dashboard includes the following information:
- Global interpretable model explanation plot
- Feature importance (Global for original features; LOCO for interpretations with predictions and when interpreting on raw features)
- Decision tree surrogate model
- Partial dependence and individual conditional expectation plots
Note: The Dashboard is not available for multiclass classification experiments.
General Considerations¶
Machine Learning and Approximate Explanations¶
For years, common sense has deemed the complex, intricate formulas created by training machine learning algorithms to be uninterpretable. While great advances have been made in recent years to make these often nonlinear, non-monotonic, and non-continuous machine-learned response functions more understandable (Hall et al, 2017), it is likely that such functions will never be as directly or universally interpretable as more traditional linear models.
Why consider machine learning approaches for inferential purposes? In general, linear models focus on understanding and predicting average behavior, whereas machine-learned response functions can often make accurate, but more difficult to explain, predictions for subtler aspects of modeled phenomenon. In a sense, linear models create very exact interpretations for approximate models. The approach here seeks to make approximate explanations for very exact models. It is quite possible that an approximate explanation of an exact model may have as much, or more, value and meaning than the exact interpretations of an approximate model. Moreover, the use of machine learning techniques for inferential or predictive purposes does not preclude using linear models for interpretation (Ribeiro et al, 2016).
The Multiplicity of Good Models in Machine Learning¶
It is well understood that for the same set of input variables and prediction targets, complex machine learning algorithms can produce multiple accurate models with very similar, but not exactly the same, internal architectures (Breiman, 2001). This alone is an obstacle to interpretation, but when using these types of algorithms as interpretation tools or with interpretation tools it is important to remember that details of explanations will change across multiple accurate models.
Expectations for Consistency Between Explanatory Techniques¶
- The decision tree surrogate is a global, nonlinear description of the Driverless AI model behavior. Variables that appear in the tree should have a direct relationship with variables that appear in the global feature importance plot. For certain, more linear Driverless AI models, variables that appear in the decision tree surrogate model may also have large coefficients in the global K-LIME model.
- K-LIME explanations are linear, do not consider interactions, and represent offsets from the local linear model intercept. LOCO importance values are nonlinear, do consider interactions, and do not explicitly consider a linear intercept or offset. LIME explanations and LOCO importance values are not expected to have a direct relationship but can align roughly as both are measures of a variable’s local impact on a model’s predictions, especially in more linear regions of the Driverless AI model’s learned response function.
- ICE is a type of nonlinear sensitivity analysis which has a complex relationship to LOCO feature importance values. Comparing ICE to LOCO can only be done at the value of the selected variable that actually appears in the selected row of the training data. When comparing ICE to LOCO the total value of the prediction for the row, the value of the variable in the selected row, and the distance of the ICE value from the average prediction for the selected variable at the value in the selected row must all be considered.
- ICE curves that are outside the standard deviation of partial dependence would be expected to fall into less populated decision paths of the decision tree surrogate; ICE curves that lie within the standard deviation of partial dependence would be expected to belong to more common decision paths.
- Partial dependence takes into consideration nonlinear, but average, behavior of the complex Driverless AI model without considering interactions. Variables with consistently high partial dependence or partial dependence that swings widely across an input variable’s domain will likely also have high global importance values. Strong interactions between input variables can cause ICE values to diverge from partial dependence values.
Current Known Issues¶
- In some cases, after selecting a weight column, you may see that weight column used as an input to the decision tree and random forest surrogate models. This means the weight column could appear as an input in the surrogate decision tree, in the LOCO feature importance chart, or in other unexpected areas of the MLI dashboard.
- In some cases, after selecting a user-defined cluster column for K-LIME, you may see that cluster column used as an input to the decision tree and random forest surrogate models. This means the cluster column could appear as an input in the surrogate decision tree, in the LOCO feature importance chart, or in other unexpected areas of the MLI dashboard.
- Various menu behavior inconsistencies may exist, including an inability to unselect a target column and truncation of target column name