H2O Driverless AI Release Notes¶
H2O Driverless AI is a high-performance, GPU-enabled, client-server application for the rapid development and deployment of state-of-the-art predictive analytics models. It reads tabular data from various sources and automates data visualization, grand-master level automatic feature engineering, model validation (overfitting and leakage prevention), model parameter tuning, model interpretability and model deployment. H2O Driverless AI is currently targeting common regression, binomial classification, and multinomial classification applications including loss-given-default, probability of default, customer churn, campaign response, fraud detection, anti-money-laundering, and predictive asset maintenance models. It also handles time-series problems for individual or grouped time-series such as weekly sales predictions per store and department, with time-causal feature engineering and validation schemes. The ability to model unstructured data is coming soon.
High-level capabilities:
- Client/server application for rapid experimentation and deployment of state-of-the-art supervised machine learning models
- Automatically creates machine learning modeling pipelines for highest predictive accuracy
- Automatically creates stand-alone scoring pipeline for in-process scoring or client/server scoring via http or tcp protocols, in Python and Java (low-latency scoring).
- Python API or GUI (Java API coming soon)
- Multi-GPU and multi-CPU support for powerful workstations and NVidia DGX supercomputers
- Machine Learning model interpretation module with global and local model interpretation
- Automatic Visualization module
- Multi-user support
- Backward compatibility
Problem types supported:
- Regression (continuous target variable, for age, income, house price, loss prediction, time-series forecasting)
- Binary classification (0/1 or “N”/”Y”, for fraud prediction, churn prediction, failure prediction, etc.)
- Multinomial classification (0/1/2/3 or “A”/”B”/”C”/”D” for categorical target variables, for prediction of membership type, next-action, product recommendation, etc.)
Data types supported:
- Tabular structured data, rows are observations, columns are fields/features/variables
- i.i.d. (identically and independently distributed) data
- Numeric, categorical and textual fields
- Missing values are allowed
- Time-series data with a single time-series (time flows across the entire dataset, not per block of data)
- Grouped time-series (e.g., sales per store per department per week, all in one file, with 3 columns for store, dept, week)
- Time-series problems with a gap between training and testing (i.e., the time to deploy), and a known forecast horizon (after which model has to be retrained)
Data types NOT supported:
- Image/video/audio
Data sources supported:
- Local file system or NFS
- File upload from browser or Python client
- Hadoop (HDFS)
- S3 (Amazon)
- Azure Blob storage
- Blue Data Tap
- Google big query
- Google cloud storage
- kdb+
- Minio
- Snowflake
File formats supported:
- Plain text formats of columnar data (.csv, .tsv, .txt)
- Compressed archives (.zip, .gz, .bz2)
- Excel
- Parquet
- Feather
- Python datatable (.nff, .jay)
Architecture¶
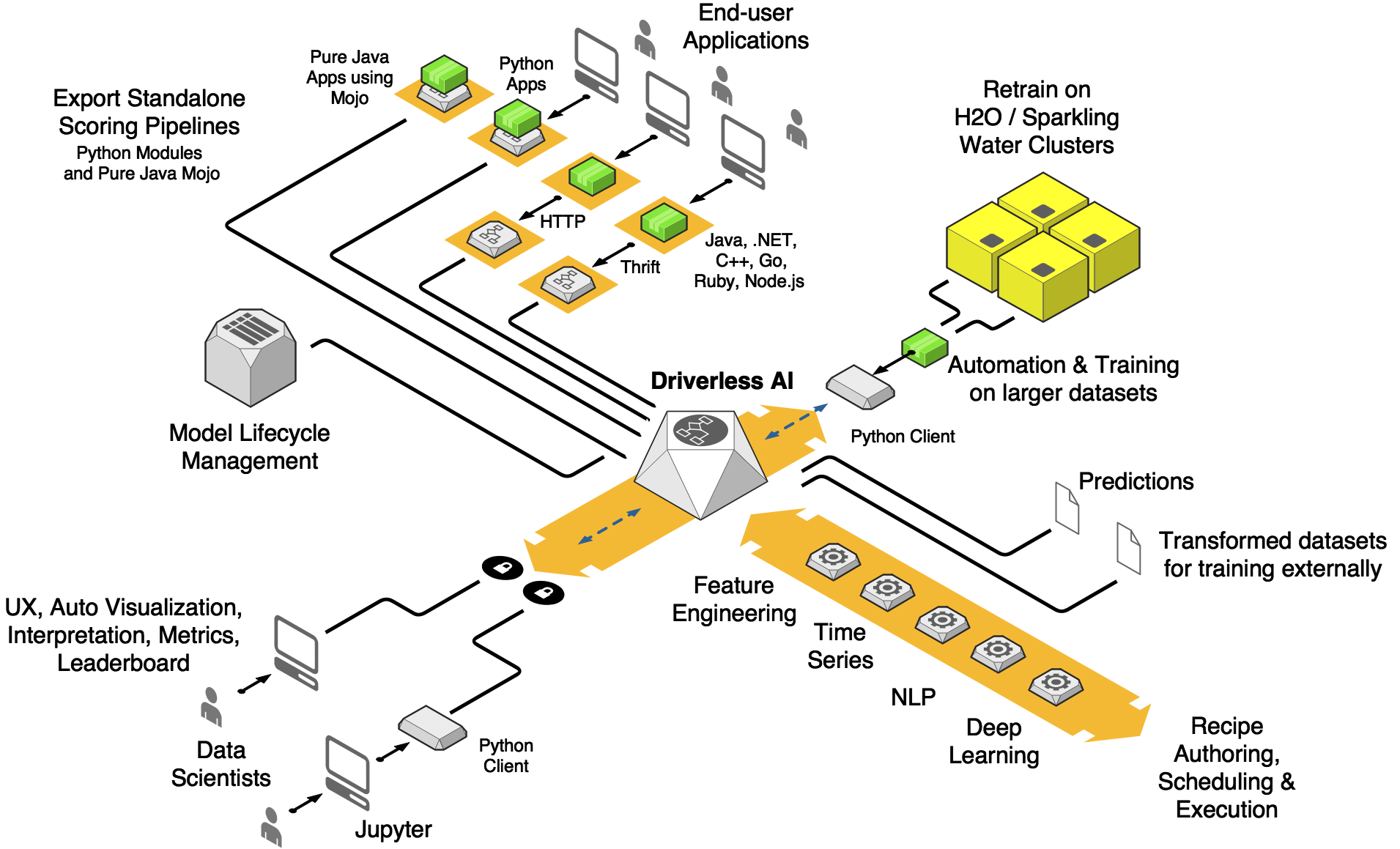
DAI architecture
Roadmap¶
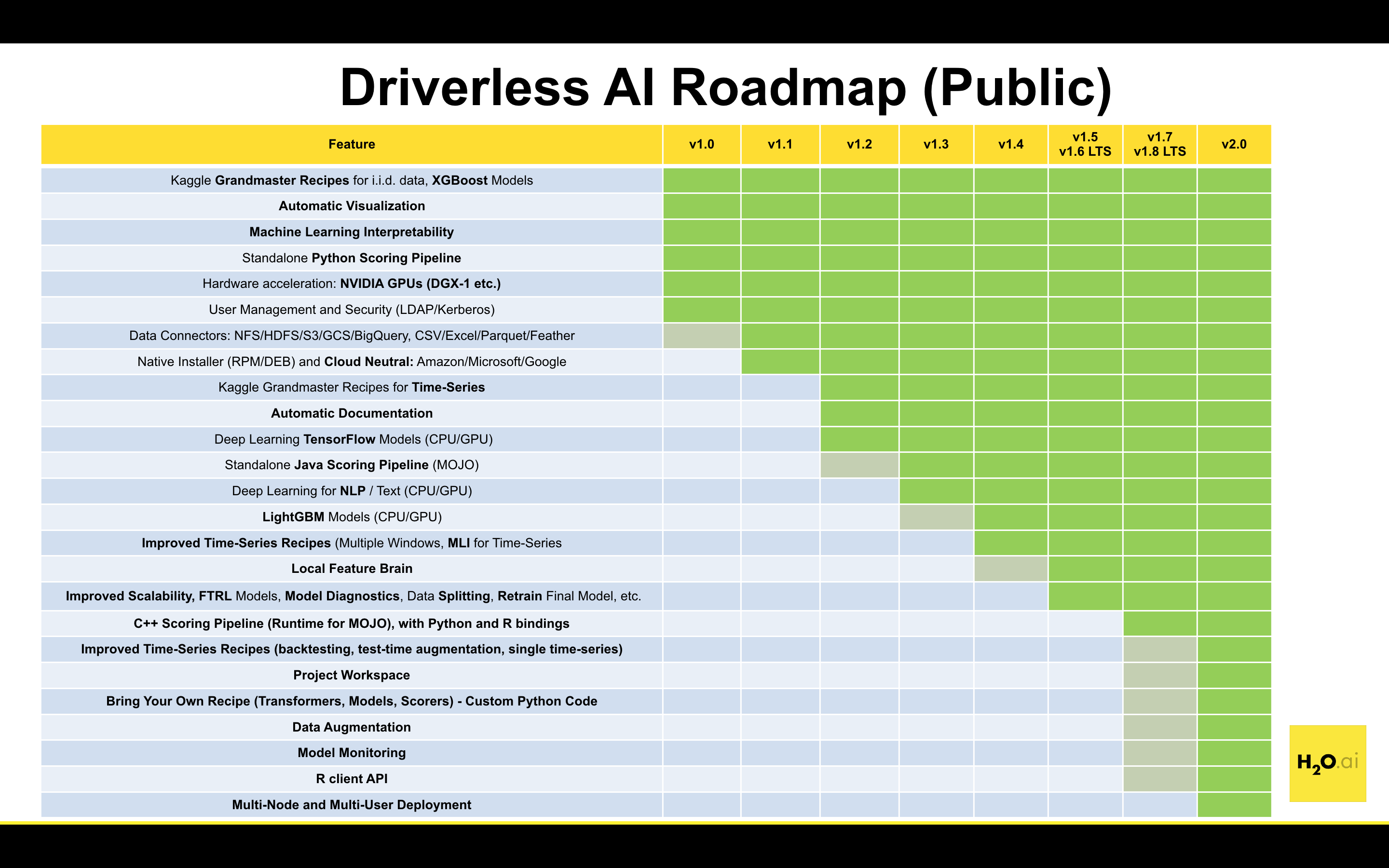
DAI roadmap
Change Log¶
Version 1.6.5 LTS (Oct 21, 2019)¶
- Added startup check for Terraform configuration
- Fixed ‘Unable to cast str32 into bool8’ bug in scoring
- Fixed MLI scoring pipeline imports
- Documentation updates:
- Improved documentation for security and authentication (OpenID, PAM, LDAP)
- Improved documentation for Parquet files
- Improved documentation for feature engineering transformers
- Various bug fixes
Version 1.6.4 LTS (Aug 19, 2019)¶
- ML Core updates:
- Speed up schema detection
- DAI now drops rows with missing values when diagnosing regression problems
- Speed up column type detection
- Fixed growth of individuals
- Fixed n_jobs for predict
- Target column is no longer included in predictors for skewed datasets
- Added an option to prevent users from downloading data files locally
- Improved UI split functionality
- A new “max_listing_items” config option to limit the number of items fetched in listing pages
- Model Ops updates:
- MOJO runtime upgraded to version 2.1.3 which supports perpetual MOJO pipeline
- Upgraded deployment templates to version matching MOJO runtime version
- MLI updates:
- Fix to MLI schema builder
- Fix parsing of categorical reason codes
- Added ability to handle integer time column
- Various bug fixes
Version 1.6.3 LTS (June 14, 2019)¶
- Included an Audit log feature
- Fixed support for decimal types for parquet files in MOJO
- Autodoc can order PDP/ICE by feature importance
- Session Management updates
- Upgraded datatable
- Improved reproducibility
- Model diagnostics now uses a weight column
- MLI can build surrogate models on all the original features or on all the transformed features that DAI uses
- Internal server cache now respects usernames
- Fixed an issue with time series settings
- Fixed an out of memory error when loading a MOJO
- Fixed Python scoring package for TensorFlow
- Added OpenID configurations
- Documentation updates:
- Updated the list of artifacts available in the Experiment Summary
- Clarified language in the documentation for unsupported (but available) features
- For the Terraform requirement in deployments, clarified that only Terraform versions in the 0.11.x release are supported, and specifically 0.11.10 or greater
- Fixed link to the Miniconda installation instructions
- Various bug fixes
Version 1.6.2 LTS (May 10, 2019)¶
- This version provides PPC64le artifacts
- Improved stability of datatable
- Improved path filtering in the file browser
- Fixed units for RMSPE scorer to be a percentage (multiply by 100)
- Fixed segmentation fault on Ubuntu 18 with installed font package
- Fixed IBM Spectrum Conductor authentication
- Fixed handling of EC2 machine credentials
- Fixed of Lag transformer configuration
- Fixed KDB and Snowflake Error Reporting
- Gradually reduce number of used workers for column statistics computation in case of failure.
- Hide default Tornado header exposing used version of Tornado
- Documentation updates:
- Added instructions for installing via AWS Marketplace
- Improved documentation for installing via Google Cloud
- Improved FAQ documentation
- Added Data Sampling documentation topic
- Various bug fixes
Version 1.6.1 LTS (Apr 18, 2019)¶
- Several fixes for MLI (partial dependence plots, Shapley values)
- Improved documentation for model deployment, time-series scoring, AutoVis and FAQs
Version 1.6.0 LTS (Apr 5, 2019)¶
Private build only.
- Fixed import of string columns larger than 2GB
- Fixed AutoViz crashes on Windows
- Fixed quantile binning in MLI
- Plot global absolute mean Shapley values instead of global mean Shapley values in MLI
- Improvements to PDP/ICE plots in MLI
- Validated Terraform version in AWS Lambda deployment
- Added support for NULL variable importance in AutoDoc
- Made Variable Importance table size configurable in AutoDoc
- Improved support for various combinations of data import options being enabled/disabled
- CUDA is now part of distribution for easier installation
- Security updates:
- Enforced SSL settings to be honored for all h2oai_client calls
- Added config option to prevent using LocalStorage in the browser to cache information
- Upgraded Tornado server version to 5.1.1
- Improved session expiration and autologout functionality
- Disabled access to Driverless AI data folder in file browser
- Provided an option to filter content that is shown in the file browser
- Use login name for HDFS impersonation instead of predefined name
- Disabled autocomplete in login form
- Various bug fixes
Version 1.5.4 (Feb 24, 2019)¶
- Speed up calculation of column statistics for date/datetime columns using certain formats (now uses ‘max_rows_col_stats’ parameter)
- Added computation of standard deviation for variable importances in experiment summary files
- Added computation of shift of variable importances between feature evolution and final pipeline
- Fix link to MLI Time-Series experiment
- Fix display bug for iteration scores for long experiments
- Fix display bug for early finish of experiment for GLM models
- Fix display bug for k-LIME when target is skewed
- Fix display bug for forecast horizon in MLI for Time-Series
- Fix MLI for Time-Series for single time group column
- Fix in-server scoring of time-series experiments created in 1.5.0 and 1.5.1
- Fix OpenBLAS dependency
- Detect disabled GPU persistence mode in Docker
- Reduce disk usage during TensorFlow NLP experiments
- Reduce disk usage of aborted experiments
- Refresh reported size of experiments during start of application
- Disable TensorFlow NLP transformers by default to speed up experiments (can enable in expert settings)
- Improved progress percentage shown during experiment
- Improved documentation (upgrade on Windows, how to create the simplest model, DTap connectors, etc.)
- Various bug fixes
Version 1.5.3 (Feb 8, 2019)¶
- Added support for splitting datasets by time via time column containing date, datetime or integer values
- Added option to disable file upload
- Require authentication to download experiment artifacts
- Automatically drop predictor columns from training frame if not found in validation or test frame and warn
- Improved performance by using physical CPU cores only (configurable in config.toml)
- Added option to not show inactive data connectors
- Various bug fixes
Version 1.5.2 (Feb 2, 2019)¶
- Added world-level bidirectional GRU Tensorflow models for NLP features
- Added character-level CNN Tensorflow models for NLP features
- Added support to import multiple individual datasets at once
- Added support for holdout predictions for time-series experiments
- Added support for regression and multinomial classification for FTRL (in addition to binomial classification)
- Improved scoring for time-series when test data contains actual target values (missing target values will be predicted)
- Reduced memory usage for LightGBM models
- Improved performance for feature engineering
- Improved speed for TensorFlow models
- Improved MLI GUI for time-series problems
- Fix final model fold splits when fold_column is provided
- Various bug fixes
Version 1.5.1 (Jan 22, 2019)¶
- Fix MOJO for GLM
- Add back .csv file of experiment summary
- Improve collection of pipeline timing artifacts
- Clean up Docker tag
Version 1.5.0 (Jan 18, 2019)¶
- Added model diagnostics (interactive model metrics on new test data incl. residual analysis for regression)
- Added FTRL model (Follow The Regularized Leader)
- Added Kolmogorov-Smirnov metric (degree of separation between positives and negatives)
- Added ability to retrain (only) the final model on new data
- Added one-hot encoding for low-cardinality categorical features, for GLM
- Added choice between 32-bit (now default) and 64-bit precision
- Added system information (CPU, GPU, disk, memory, experiments)
- Added support for time-series data with many more time gaps, and with weekday-only data
- Added one-click deployment to Amazon Lambda
- Added ability to split datasets randomly, with option to stratify by target column or group by fold column
- Added support for OpenID authentication
- Added connector for BlueData
- Improved responsiveness of the GUI under heavy load situations
- Improved speed and reduce memory footprint of feature engineering
- Improved performance for RuleFit models and enable GPU and multinomial support
- Improved auto-detection of temporal frequency for time-series problems
- Improved accuracy of final single model if external validation provided
- Improved final pipeline if external validation data is provided (add ensembling)
- Improved k-LIME in MLI by using original features deemed important by DAI instead of all original features
- Improved MLI by using 3-fold CV by default for all surrogate models
- Improved GUI for MLI time series (integrated help, better integration)
- Added ability to view MLI time series logs while MLI time series experiment is running
- PDF version of the Automatic Report (AutoDoc) is now replaced by a Word version
- Various bug fixes (GLM accuracy, UI slowness, MLI UI, AutoVis)
Version 1.4.2 (Dec 3, 2018)¶
- Support for IBM Power architecture
- Speed up training and reduce size of final pipeline
- Reduced resource utilization during training of final pipeline
- Display test set metrics (ROC, ROCPR, Gains, Lift) in GUI in addition to validation metrics (if test set provided)
- Show location of best threshold for Accuracy, MCC and F1 in ROC curves
- Add relative point sizing for scatter plots in AutoVis
- Fix file upload and add model checkpointing in python client API
- Various bug fixes
Version 1.4.1 (Nov 11, 2018)¶
- Improved integration of MLI for time-series
- Reduced disk and memory usage during final ensemble
- Allow scoring and transformations on previously imported datasets
- Enable checkpoint restart for unfinished models
- Add startup checks for OpenCL platforms for LightGBM on GPUs
- Improved feature importances for ensembles
- Faster dataset statistics for date/datetime columns
- Faster MOJO batch scoring
- Fix potential hangs
- Fix ‘not in list’ error in MOJO
- Fix NullPointerException in MLI
- Fix outlier detection in AutoVis
- Various bug fixes
Version 1.4.0 (Oct 27, 2018)¶
- Enable LightGBM by default (now with MOJO)
- LightGBM tuned for GBM decision trees, Random Forest (rf), and Dropouts meet Multiple Additive Regression Trees (dart)
- Add ‘isHoliday’ feature for time columns
- Add ‘time’ column type for date/datetime columns in data preview
- Add support for binary datatable file ingest in .jay format
- Improved final ensemble (each model has its own feature pipeline)
- Automatic smart checkpointing (feature brain) from prior experiments
- Add kdb+ connector
- Feature selection of original columns for data with many columns to handle >>100 columns
- Improved time-series recipe (multiple validation splits, better logic)
- Improved performance of AutoVis
- Improved date detection logic (now detects %Y%m%d and %Y-%m date formats)
- Automatic fallback to CPU mode if GPU runs out of memory (for XGBoost, GLM and LightGBM)
- No longer require header for validation and testing datasets if data types match
- No longer include text columns for data shift detection
- Add support for time-series models in MLI (including ability to select time-series groups)
- Add ability to download MLI logs from MLI experiment page (includes both Python and Java logs)
- Add ability to view MLI logs while MLI experiment is running (Python and Java logs)
- Add ability to download LIME and Shapley reason codes from MLI page
- Add ability to run MLI on transformed features
- Display all variables for MLI variable importance for both DAI and surrogate models in MLI summary
- Include variable definitions for DAI variable importance list in MLI summary
- Fix Gains/Lift charts when observations weights are given
- Various bug fixes
Version 1.3.1 (Sep 12, 2018)¶
- Fix ‘Broken pipe’ failures for TensorFlow models
- Fix time-series problems with categorical features and interpretability >= 8
- Various bug fixes
Version 1.3.0 (Sep 4, 2018)¶
- Added LightGBM models - now have [XGBoost, LightGBM, GLM, TensorFlow, RuleFit]
- Added TensorFlow NLP recipe based on CNN Deeplearning models (sentiment analysis, document classification, etc.)
- Added MOJO for GLM
- Added detailed confusion matrix statistics
- Added more expert settings
- Improved data exploration (columnar statistics and row-based data preview)
- Improved speed of feature evolution stage
- Improved speed of GLM
- Report single-pass score on external validation and test data (instead of bootstrap mean)
- Reduced memory overhead for data processing
- Reduced number of open files - fixes ‘Bad file descriptor’ error on Mac/Docker
- Simplified Python client API
- Query any data point in the MLI UI from the original dataset due to “on-demand” reason code generation
- Enhanced k-means clustering in k-LIME by only using a subset of features. See The K-LIME Technique for more information.
- Report k-means centers for k-LIME in MLI summary for better cluster interpretation
- Improved MLI experiment listing details
- Various bug fixes
Version 1.2.2 (July 5, 2018)¶
- MOJO Java scoring pipeline for time-series problems
- Multi-class confusion matrices
- AUCMACRO Scorer: Multi-class AUC via macro-averaging (in addition to the default micro-averaging)
- Expert settings (configuration override) for each experiment from GUI and client APIs.
- Support for HTTPS
- Improved downsampling logic for time-series problems (if enabled through accuracy knob settings)
- LDAP readonly access to Active Directory
- Snowflake data connector
- Various bug fixes
Version 1.2.1 (June 26, 2018)¶
- Added LIME-SUP (alpha) to MLI as alternative to k-LIME (local regions are defined by decision tree instead of k-means)
- Added RuleFit model (alpha), now have [GBM, GLM, TensorFlow, RuleFit] - TensorFlow and RuleFit are disabled by default
- Added Minio (private cloud storage) connector
- Added support for importing folders from S3
- Added ‘Upload File’ option to ‘Add Dataset’ (in addition to drag & drop)
- Predictions for binary classification problems now have 2 columns (probabilities per class), for consistency with multi-class
- Improved model parameter tuning
- Improved feature engineering for time-series problems
- Improved speed of MOJO generation and loading
- Improved speed of time-series related automatic calculations in the GUI
- Fixed potential rare hangs at end of experiment
- No longer require internet to run MLI
- Various bug fixes
Version 1.2.0 (June 11, 2018)¶
- Time-Series recipe
- Low-latency standalone MOJO Java scoring pipelines (now beta)
- Enable Elastic Net Generalized Linear Modeling (GLM) with lambda search (and GPU support), for interpretability>=6 and accuracy<=5 by default (alpha)
- Enable TensorFlow (TF) Deep Learning models (with GPU support) for interpretability=1 and/or multi-class models (alpha, enable via config.toml)
- Support for pre-tuning of [GBM, GLM, TF] models for picking best feature evolution model parameters
- Support for final ensemble consisting of mix of [GBM, GLM, TF] models
- Automatic Report (AutoDoc) in PDF and Markdown format as part of summary zip file
- Interactive tour (assistant) for first-time users
- MLI now runs on experiments from previous releases
- Surrogate models in MLI now use 3 folds by default
- Improved small data recipe with up to 10 cross-validation folds
- Improved accuracy for binary classification with imbalanced data
- Additional time-series transformers for interactions and aggreations between lags and lagging of non-target columns
- Faster creation of MOJOs
- Progress report during data ingest
- Normalize binarized multi-class confusion matrices by class count (global scaling factor)
- Improved parsing of boolean environment variables for configuration
- Various bug fixes
Version 1.1.6 (May 29, 2018)¶
- Improved performance for large datasets
- Improved speed and user interface for MLI
- Improved accuracy for binary classification with imbalanced data
- Improved generalization estimate for experiments with given validation data
- Reduced size of experiment directories
- Support for Parquet files
- Support for bzip2 compressed files
- Added Data preview in UI: ‘Describe’
- No longer add ID column to holdout and test set predictions for simplicity
- Various bug fixes
Version 1.1.4 (May 17, 2018)¶
- Native builds (RPM/DEB) for 1.1.3
Version 1.1.3 (May 16, 2018)¶
- Faster speed for systems with large CPU core counts
- Faster and more robust handling of user-specified missing values for training and scoring
- Same validation scheme for feature engineering and final ensemble for high enough accuracy
- MOJO scoring pipeline for text transformers
- Fixed single-row scoring in Python scoring pipeline (broken in 1.1.2)
- Fixed default scorer when experiment is started too quickly
- Improved responsiveness for time-series GUI
- Improved responsiveness after experiment abort
- Improved load balancing of memory usage for multi-GPU XGBoost
- Improved UI for selection of columns to drop
- Various bug fixes
Version 1.1.2 (May 8, 2018)¶
- Support for automatic time-series recipe (alpha)
- Now using Generalized Linear Model (GLM) instead of XGBoost (GBM) for interpretability 10
- Added experiment preview with runtime and memory usage estimation
- Added MER scorer (Median Error Rate, Median Abs. Percentage Error)
- Added ability to use integer column as time column
- Speed up type enforcement during scoring
- Support for reading ARFF file format (alpha)
- Quantile Binning for MLI
- Various bug fixes
Version 1.1.1 (April 23, 2018)¶
- Support string columns larger than 2GB
Version 1.1.0 (April 19, 2018)¶
- AWS/Azure integration (hourly cloud usage)
- Bug fixes for MOJO pipeline scoring (now beta)
- Google Cloud storage and BigQuery (alpha)
- Speed up categorical column stats computation during data import
- Further improved memory management on GPUs
- Improved accuracy for MAE scorer
- Ability to build scoring pipelines on demand (if not enabled by default)
- Additional target transformer for regression problems sqrt(sqrt(x))
- Add GLM models as candidates for interpretability=10 (alpha, disabled by default)
- Improved performance of native builds (RPM/DEB)
- Improved estimation of error bars
- Various bug fixes
Version 1.0.30 (April 5, 2018)¶
- Speed up MOJO pipeline creation and disable MOJO by default (still alpha)
- Improved memory management on GPUs
- Support for optional 32-bit floating-point precision for reduced memory footprint
- Added logging of test set scoring and data transformations
- Various bug fixes
Version 1.0.29 (April 4, 2018)¶
- If MOJO fails to build, no MOJO will be available, but experiment can still succeed
Version 1.0.28 (April 3, 2018)¶
- (Non-docker) RPM installers for RHEL7/CentOS7/SLES 12 with systemd support
Version 1.0.27 (March 31, 2018)¶
- MOJO scoring pipeline for Java standalone cross-platform low-latency scoring (alpha)
- Various bug fixes
Version 1.0.26 (March 28, 2018)¶
- Improved performance and reduced memory usage for large datasets
- Improved performance for F0.5, F2 and accuracy
- Improved performance of MLI
- Distribution shift detection now also between validation and test data
- Batch scoring example using datatable
- Various enhancements for AutoVis (outliers, parallel coordinates, log file)
- Various bug fixes
Version 1.0.25 (March 22, 2018)¶
- New scorers for binary/multinomial classification: F0.5, F2 and accuracy
- Precision-recall curve for binary/multinomial classification models
- Plot of actual vs predicted values for regression problems
- Support for excluding feature transformations by operation type
- Support for reading binary file formats: datatable and Feather
- Improved multi-GPU memory load balancing
- Improved display of initial tuning results
- Reduced memory usage during creation of final model
- Fixed several bugs in creation of final scoring pipeline
- Various UI improvements (e.g., zooming on iteration scoreboard)
- Various bug fixes
Version 1.0.24 (March 8, 2018)¶
- Fix test set scoring bug for data with an ID column (introduced in 1.0.23)
- Allow renaming of MLI experiments
- Ability to limit maximum number of cores used for datatable
- Print validation scores and error bars across final ensemble model CV folds in logs
- Various UI improvements
- Various bug fixes
Version 1.0.23 (March 7, 2018)¶
- Support for Gains and Lift curves for binomial and multinomial classification
- Support for multi-GPU single-model training for large datasets
- Improved recipes for large datasets (faster and less memory/disk usage)
- Improved recipes for text features
- Increased sensitivity of interpretability setting for feature engineering complexity
- Disable automatic time column detection by default to avoid confusion
- Automatic column type conversion for test and validation data, and during scoring
- Improved speed of MLI
- Improved feature importances for MLI on transformed features
- Added ability to download each MLI plot as a PNG file
- Added support for dropped columns and weight column to MLI stand-alone page
- Fix serialization of bytes objects larger than 4 GiB
- Fix failure to build scoring pipeline with ‘command not found’ error
- Various UI improvements
- Various bug fixes
Version 1.0.22 (Feb 23, 2018)¶
- Fix CPU-only mode
- Improved robustness of datatable CSV parser
Version 1.0.21 (Feb 21, 2018)¶
- Fix MLI GUI scaling issue on Mac
- Work-around segfault in truncated SVD scipy backend
- Various bug fixes
Version 1.0.20 (Feb 17, 2018)¶
- HDFS/S3/Excel data connectors
- LDAP/PAM/Kerberos authentication
- Automatic setting of default values for accuracy / time / interpretability
- Interpretability: per-observation and per-feature (signed) contributions to predicted values in scoring pipeline
- Interpretability setting now affects feature engineering complexity and final model complexity
- Standalone MLI scoring pipeline for Python
- Time setting of 1 now runs for only 1 iteration
- Early stopping of experiments if convergence is detected
- ROC curve display for binomial and multinomial classification, with confusion matrices and threshold/F1/MCC display
- Training/Validation/Test data shift detectors
- Added AUCPR scorer for multinomial classification
- Improved handling of imbalanced binary classification problems
- Configuration file for runtime limits such as cores/memory/harddrive (for admins)
- Various GUI improvements (ability to rename experiments, re-run experiments, logs)
- Various bug fixes
Version 1.0.19 (Jan 28, 2018)¶
- Fix hang during final ensemble (accuracy >= 5) for larger datasets
- Allow scoring of all models built in older versions (>= 1.0.13) in GUI
- More detailed progress messages in the GUI during experiments
- Fix scoring pipeline to only use relative paths
- Error bars in model summary are now +/- 1*stddev (instead of 2*stddev)
- Added RMSPE scorer (RMS Percentage Error)
- Added SMAPE scorer (Symmetric Mean Abs. Percentage Error)
- Added AUCPR scorer (Area under Precision-Recall Curve)
- Gracefully handle inf/-inf in data
- Various UI improvements
- Various bug fixes
Version 1.0.18 (Jan 24, 2018)¶
- Fix migration from version 1.0.15 and earlier
- Confirmation dialog for experiment abort and data/experiment deletion
- Various UI improvements
- Various AutoVis improvements
- Various bug fixes
Version 1.0.17 (Jan 23, 2018)¶
- Fix migration from version 1.0.15 and earlier (partial, for experiments only)
- Added model summary download from GUI
- Restructured and renamed logs archive, and add model summary to it
- Fix regression in AutoVis in 1.0.16 that led to slowdown
- Various bug fixes
Version 1.0.16 (Jan 22, 2018)¶
- Added support for validation dataset (optional, instead of internal validation on training data)
- Standard deviation estimates for model scores (+/- 1 std.dev.)
- Computation of all applicable scores for final models (in logs only for now)
- Standard deviation estimates for MLI reason codes (+/- 1 std.dev.) when running in stand-alone mode
- Added ability to abort MLI job
- Improved final ensemble performance
- Improved outlier visualization
- Updated H2O-3 to version 3.16.0.4
- More readable experiment names
- Various speedups
- Various bug fixes
Version 1.0.15 (Jan 11, 2018)¶
- Fix truncated per-experiment log file
- Various bug fixes
Version 1.0.14 (Jan 11, 2018)¶
- Improved performance
Version 1.0.13 (Jan 10, 2018)¶
- Improved estimate of generalization performance for final ensemble by removing leakage from target encoding
- Added API for re-fitting and applying feature engineering on new (potentially larger) data
- Remove access to pre-transformed datasets to avoid unintended leakage issues downstream
- Added mean absolute percentage error (MAPE) scorer
- Enforce monotonicity constraints for binary classification and regression models if interpretability >= 6
- Use squared Pearson correlation for R^2 metric (instead of coefficient of determination) to avoid negative values
- Separated http and tcp scoring pipeline examples
- Reduced size of h2oai_client wheel
- No longer require weight column for test data if it was provided for training data
- Improved accuracy of final modeling pipeline
- Include H2O-3 logs in downloadable logs.zip
- Updated H2O-3 to version 3.16.0.2
- Various bug fixes
Version 1.0.11 (Dec 12, 2017)¶
- Faster multi-GPU training, especially for small data
- Increase default amount of exploration of genetic algorithm for systems with fewer than 4 GPUs
- Improved accuracy of generalization performance estimate for models on small data (< 100k rows)
- Faster abort of experiment
- Improved final ensemble meta-learner
- More robust date parsing
- Various bug fixes
Version 1.0.10 (Dec 4, 2017)¶
- Tool tips and link to documentation in parameter settings screen
- Faster training for multi-class problems with > 5 classes
- Experiment summary displayed in GUI after experiment finishes
- Python Client Library downloadable from the GUI
- Speedup for Maxwell-based GPUs
- Support for multinomial AUC and Gini scorers
- Add MCC and F1 scorers for binomial and multinomial problems
- Faster abort of experiment
- Various bug fixes
Version 1.0.9 (Nov 29, 2017)¶
- Support for time column for causal train/validation splits in time-series datasets
- Automatic detection of the time column from temporal correlations in data
- MLI improvements, dedicated page, selection of datasets and models
- Improved final ensemble meta-learner
- Test set score now displayed in experiment listing
- Original response is preserved in exported datasets
- Various bug fixes
Version 1.0.8 (Nov 21, 2017)¶
- Various bug fixes
Version 1.0.7 (Nov 17, 2017)¶
- Sharing of GPUs between experiments - can run multiple experiments at the same time while sharing GPU resources
- Persistence of experiments and data - can stop and restart the application without loss of data
- Support for weight column for optional user-specified per-row observation weights
- Support for fold column for user-specified grouping of rows in train/validation splits
- Higher accuracy through model tuning
- Faster training - overall improvements and optimization in model training speed
- Separate log file for each experiment
- Ability to delete experiments and datasets from the GUI
- Improved accuracy for regression tasks with very large response values
- Faster test set scoring - Significant improvements in test set scoring in the GUI
- Various bug fixes
Version 1.0.5 (Oct 24, 2017)¶
- Only display scorers that are allowed
- Various bug fixes
Version 1.0.4 (Oct 19, 2017)¶
- Improved automatic type detection logic
- Improved final ensemble accuracy
- Various bug fixes
Version 1.0.3 (Oct 9, 2017)¶
- Various speedups
- Results are now reproducible
- Various bug fixes
Version 1.0.2 (Oct 5, 2017)¶
- Improved final ensemble accuracy
- Weight of Evidence features added
- Various bug fixes
Version 1.0.1 (Oct 4, 2017)¶
- Improved speed of final ensemble
- Various bug fixes
Version 1.0.0 (Sep 24, 2017)¶
- Initial stable release