Internal Validation Technique¶
This section describes the technique behind internal validation in Driverless AI.
For the experiment, Driverless AI will either:
split the data into a training set and internal validation set
or
use cross validation to split the data into \(n\) folds
Driverless AI chooses the method based on the size of the data and the Accuracy setting. For method 1, part of the data is removed to be used for internal validation. (Note: This train and internal validation split may be repeated if the data is small so that more data can be used for training.)
For method 2, however, no data is wasted for internal validation. With cross validation, the whole dataset is utilized, and each model is trained on a different subset of the training data. The following visualization shows an example of cross validation with 5 folds.
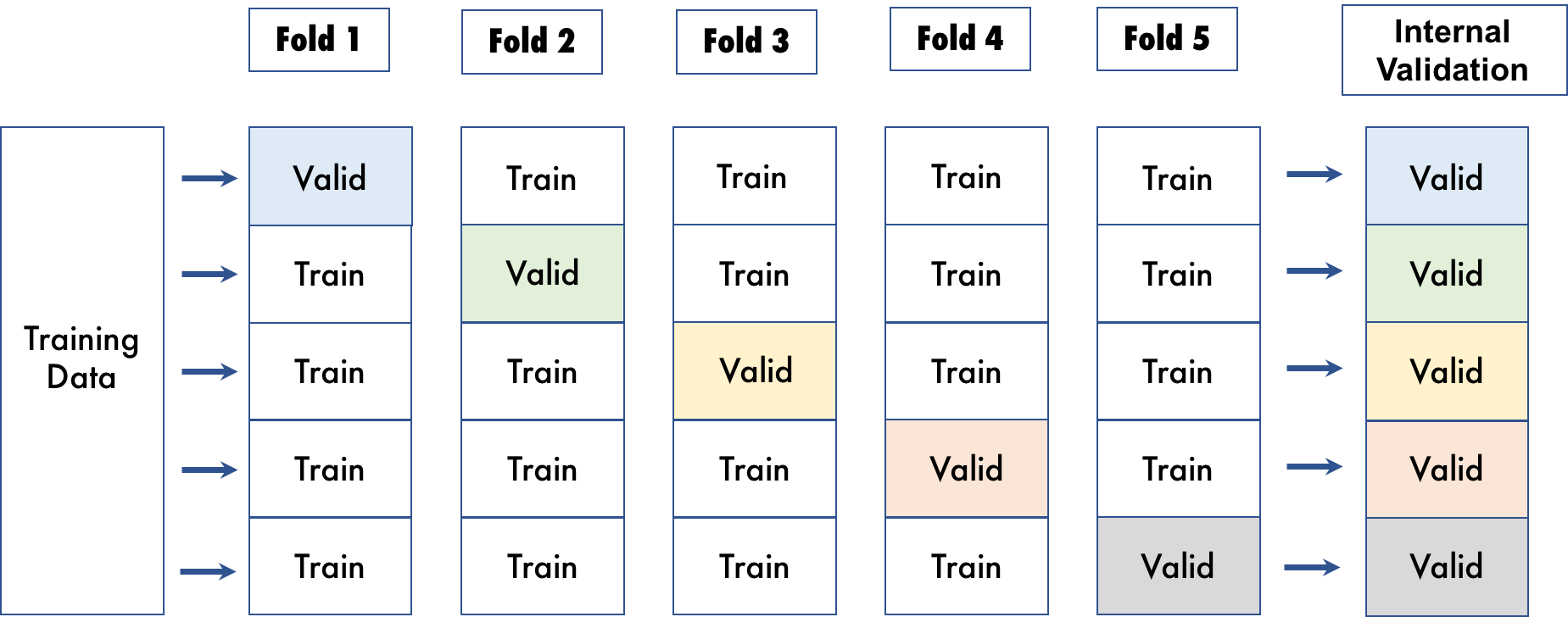
Driverless AI randomly splits the data into the specified number of folds for cross validation. With cross validation, the whole dataset is utilized, and each model is trained on a different subset of the training data.
Driverless AI will not automatically create the internal validation data randomly if a user provides a Fold Column or a Validation Dataset. If a Fold Column or a Validation Dataset is provided, Driverless AI will use that data to calculate the performance of the Driverless AI models and to calculate all performance graphs and statistics.
If the experiment is a Time Series use case, and a Time Column is selected, Driverless AI will change the way the internal validation data is created. In the case of temporal data, it is important to train on historical data and validate on more recent data. Driverless AI does not perform random splits, but instead respects the temporal nature of the data to prevent any data leakage. In addition, the train/validation split is a function of the time gap between train and test as well as the forecast horizon (amount of time periods to predict). If test data is provided, Driverless AI will suggest values for these parameters that lead to a validation set that resembles the test set as much as possible. But users can control the creation of the validation split in order to adjust it to the actual application.