Driverless AI 中的遗传算法¶
Driverless AI 旨在确定数据集的 最佳管道 。这涉及数据转换、特征工程、模型超参数调优、评分和集成。
遗传算法 流程是一个试错选择流程,但它是可再现的。在 Driverless AI 中,genetic algorithm 在实验的 Feature Evolution stage 期间执行。特征演变是缓慢突变参数之间的竞争,目的是找出最好的 individuals. 特征演变 不是完全随机的,其信息来自于建模算法的 variable importance 交互表。Driverless AI Brain 缓存关于群体中最佳基因、交互和参数的信息,以及来自之前实验的信息(如果已启用),并可在遗传算法突变中使用。
Driverless AI 还集成了 Optuna ,采用 Bayesian 优化技术 进行模型超参数搜索。它可以结合遗传算法,用于特征工程的模型超参数调优。还可编写 自定义代码 以切换内置突变策略。详情请参见 additional information 部分。
在模型构建和特征调优过程中,通过自助法和交叉验证来防止 过拟合 ,同时通过平衡遗传算法中的开发和探索来防止 欠拟合 。
Understanding Genetic Algorithm 及其 Driverless AI 等效项。
The Full Picture :Driverless AI 中的端到端管道。
Reading the logs :实验日志中所示的工作流程。
了解遗传算法¶
Genetic Algorithm 是一种受自然淘汰过程启发而产生的搜索启发式算法,即选出最适合的个体为下一代繁衍后代。
在深入了解之前,考虑某些 Driverless AI 等效项的定义:
基因存储关于 feature transformation 的类型和参数的信息。它在概念上就像真正的基因,其中存在的信息用于形成蛋白质这样的东西。
转换器是应用基因的实际代码。
个体由一个基因组组成,其中包含一组 基因,即关于哪些转换和使用哪些参数执行的信息。它还包含 模型超参数 和一些 附加信息 ,如应用的目标转换等。个体创建一个
群体,通过随机选择的配对 tournament process 来决定获胜者。个体的
拟合度分数是基于评分指标的模型评估和分数。
以下是遗传算法及其 Driverless AI 等效项的相关步骤:
Initialization
考虑给定问题的所有可能的解决方案。这就产生了群体。最流行的初始化技术是使用随机二进制字符串。
Driverless AI :来自 Tuning Phase 的个体通过遗传算法馈入,作为特征演变的随机可能解决方案。
Fitness Assignment
给每个个体分配一个拟合度分数,进一步确定被选择进行繁殖的概率。拟合度分数越高,被选择进行繁殖的几率就越高。
Driverless AI :个体的拟合度分数是基于评分指标的模型评估值。
Selection
选择个体进行后代繁殖。然后被选中的个体两个一对,以提高繁殖能力。这些个体将其基因传给下一代。遗传算法使用拟合度比例选择技术,确保有用的解决方案用于重组。
Driverless AI :在群体中执行 tournament 以找到群体的最佳子集(最好的一半)。
Reproduction : crossover mutation
这一阶段涉及子群体的创建。算法采用适用于父群体的变异运算符。此阶段的两个主要运算符包括交叉和突变。
突变:此运算符将新的遗传信息添加到新的子群体。这是通过翻转染色体中的一些片段来实现的。突变解决了局部最小值问题,提高了多样性。
交叉:此运算符交换两个父级的遗传信息以产生后代。它在随机选择的父对上执行,以生成一个与父群体大小相等的子群体。
Driverless AI :获胜子群体的基因、特征和模型超参数突变成新后代(无性繁殖)。Mutation 包括 添加、干扰或修剪 genes.
基因添加策略是以平衡开发和探索原始变量的重要性为基础的。添加基因,可探索重要性较高的原始变量的额外转换。
来自先前优胜者的最佳基因成为优良基因池的一部分,可供后代使用和共享。
可以修剪特定的输出特征。当变量重要性低于特定阈值(基于可解释性设置)时,特征会被修剪。对于大部分模型,将基于信息增益变量重要性(即模型特定的变量重要性)对基因进行修剪。对于一些像 CUML RF 之类的模型,则是基于 Shapley 排列重要性。
Replacement
代际更替发生在此阶段,即以新的子群体替换旧群体。新群体的拟合度分数高于旧群体。
Driverless AI :获胜子群体的基因(添加、修剪和干扰)、特征、模型超参数发生突变,使群体恢复到竞争之前的规模。
Termination
替换完成后,使用停止准则来提供终止的依据。算法将在获得阈值拟合度解决方案后终止。它会把此解决方案视为群体中的最优解决方案。
Driverless AI :对个体进行评分,如果达到停止准则则终止演变,否则继续选择流程。
全局¶
这里我们详述 Driverless 在实验期间按顺序执行的不同阶段的工作,以输出数据集的最佳管道-
将 Accuracy, Time and Interpretabilty knob 设置转换为要构建的迭代数和模型数。
执行 目标调优 :为手头的问题找到目标变量的最佳表示形式。要实现这一点,使用简单的允许特征转换和模型参数(从内部插件池中选择)构建(如果可用则为 LightGBM)模型,并选择分数最高的目标转换。摘要 zip 或实验 GUI 中的
target_transform_tuning_leaderboard_simple.json文件列出了构建的模型及其分数和参数。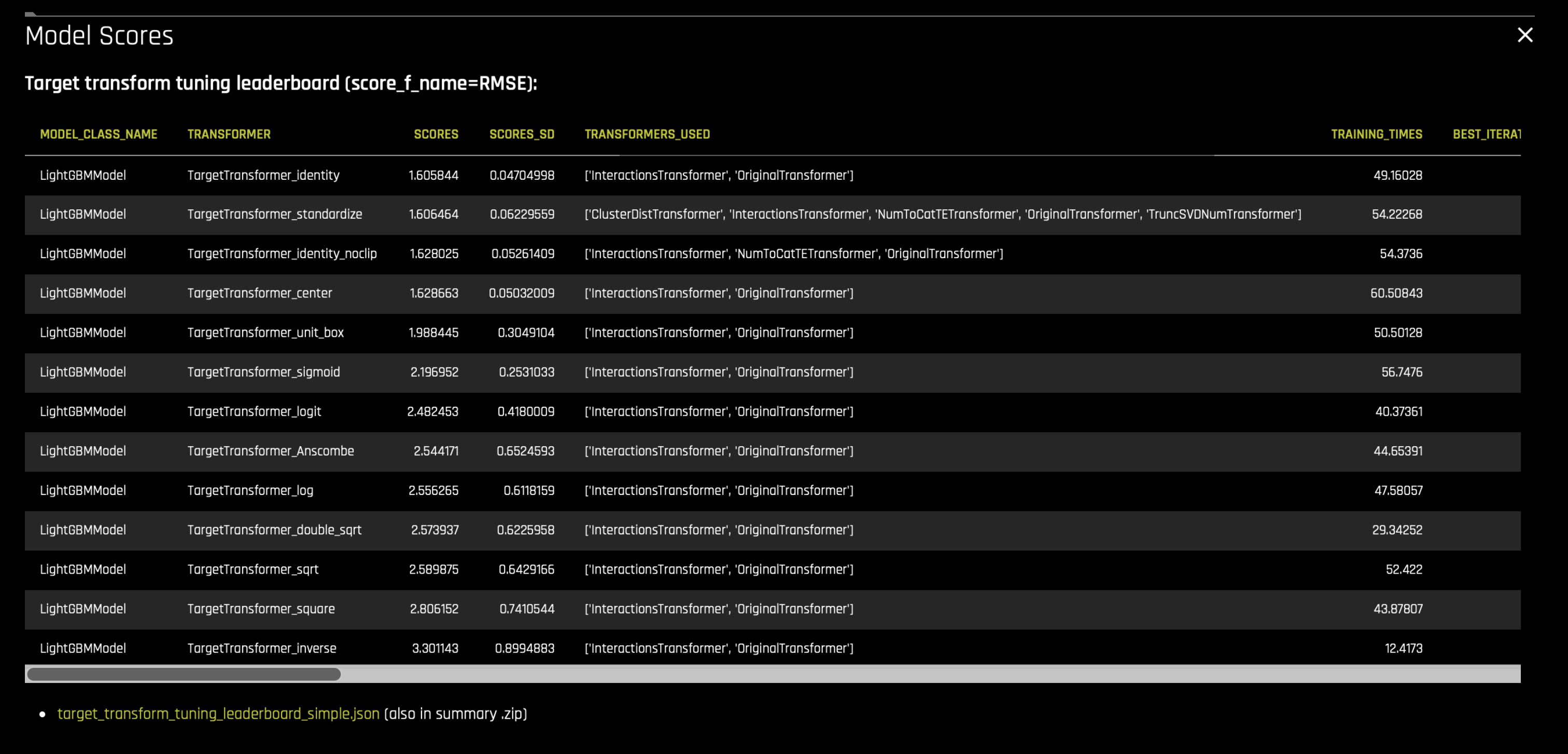
数据泄露和移位检测 :
Leakage Detection :为了检测数据泄露,Driverless AI 运行一个模型(如果可用则为 LightGBM)来获得变量重要性表(用于决定每个特征对目标变量的预测能力)。然后,对每个具有较高变量重要性的特征建立简单的模型。具有高 AUC(用于分类)或 R2 分数(回归)的模型将作为潜在泄漏特征报告给用户。
Shift Detection :为了检测训练、验证或测试数据集之间的分布移位,Driverless AI 训练一个二项模型,以预测一行属于哪个数据集。例如,如果只使用一个特定特征作为预测器构建的模型,能够以较高的准确度分离训练和测试数据,如 AUC 为 0.9,这表明该特征在训练和测试数据中的分布存在漂移。应该删除移位的特征。或者,通过将它们用作标签/分箱来创建更有意义的聚合特征。
这些特征会以通知的形式报告给用户,如果设置了阈值,则这些特征会被删除。
模型和特征 调优阶段 :调优是随机选择参数,以找到最佳 individuals.
Driverless 创建一个多样化的个体集合。首先,它仔细研究并创建 “SEQUENCE” 模型(基于允许的算法),使用简单的特征转换和模型参数添加它们。这些允许的算法和特征转换显示在实验预览中。“默认”包括简单基因,如原始数值、日期、文本数据的 tfidf 或 bert 嵌套、目标编码、频率编码、证据权重编码、聚类、交互等。这些默认特征很简单,并支持 MOJO 创建。这些模型参数列表和特征转换由 Driverless AI 专家数据科学家插件内部选择,适用于手头的数据集,并兼容实验设置。
然后,如果群体中需要更多个体,则添加 “RANDOM” 模型。这些模型的类型(算法)与 SEQUENCE 中的相同,但对模型使用突变参数调用,以获得 随机超参数和(默认+额外)随机特征 。
评估 “GLM ONE HOT ENCODED” 模型,如果在数据集上运行良好,则将该模型添加为一个个体。
将 参考个体 “CONSTANT MODEL” 添加到组合,以便我们了解可以对分数执行的最好的常量预测(无论输入数据如何,预测的都是相同的事情)。
这就是创建 个体多样性群体 的方法。
对所有个体进行评分:
每次调优迭代,都要对多批个体(给定硬件)进行评分
将以更高的准确度重新创建原始特征集,每批都将特征重要性传递给下一批,因此它可以 利用 重要性来创建更好的特征。
每个被评分的个体都经历了特征转换、模型训练、预测和指标评分。
然后在个体中执行 tournament 以将最佳个体传递至 演变阶段。
如果(为高可解释性设置)选择了 “FS” 策略(特征选择策略),则添加 “EXTRA_FS” 模型,且此模型 替代 上述非参考个体之一。此特殊个体具有的特征会基于数据集的 permutation importance 进行预修剪。
实验的调优阶段排行榜列出所有胜出的个体(即在联赛中得分最高的模型)。摘要 zip 工件将其作为
tuning_leaderboard_simple.json或 txt 文件包含在内。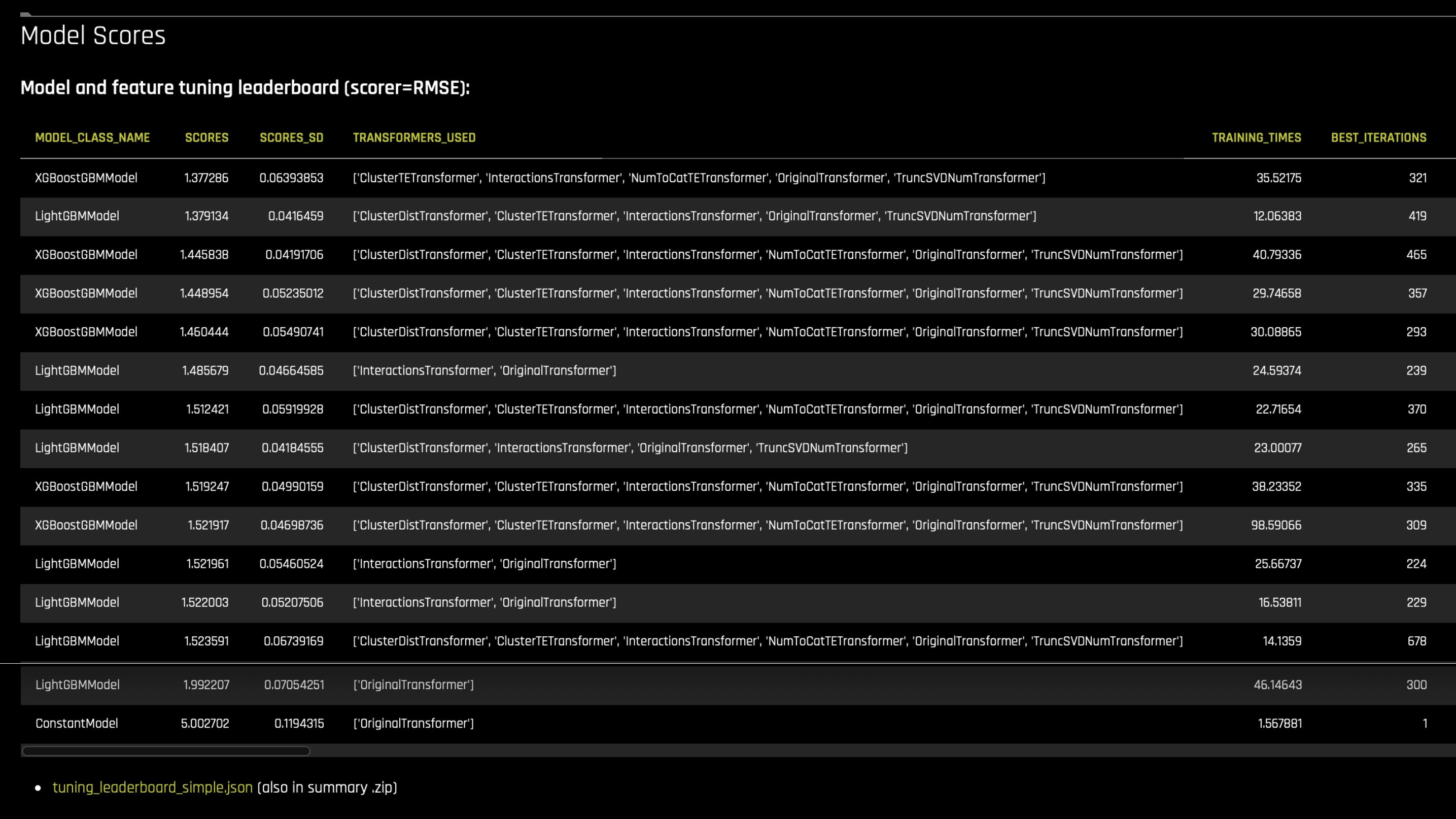
特征 演变阶段 :演变是缓慢突变参数之间的竞争,目的是找到最佳 individuals. 在演变阶段,我们从 调优阶段 中的最佳个体(得分最高)开始。调优阶段创建的个体可能多余或少于群体所需的数量。因此,第一步是修剪或增加新个体,以创造所需的群体规模。
evolution_begin_leaderboard_simple.json文件列出这些个体(未评分的是新增个体,用于使群体达到合适的规模)。实验每迭代一次,每个个体都根据自己的基因创建一个新模型。
根据训练数据对个体群体进行训练,并可使用提前停止功能(如果可用)。
根据给定指标对群体进行评分,并采用自助法(默认选择)。
Tournament 是基于所选策略在个体中执行的,用于确定群体的获胜子集
获胜子群体的基因、特征和模型发生突变,使群体恢复到竞争之前的规模(无性繁殖)。在遗传算法中,突变包括添加、修剪和干扰基因。还可修剪特定的输出特征。基因添加策略是以平衡开发和探索原始变量的重要性为基础的。添加基因,可探索重要性较高的原始变量的额外转换。对于大部分模型,将基于信息增益变量重要性对基因进行修剪。对于一些像 CUML RF 之类的模型,则是基于 Shapley 排列重要性。当变量重要性低于特定阈值(基于可解释性设置)时,特征会被修剪。另请参见 Mutation strategies.
返回 A…
最终的演变排行榜群体列示在
evolution_end_leaderboard_simple.json文件中。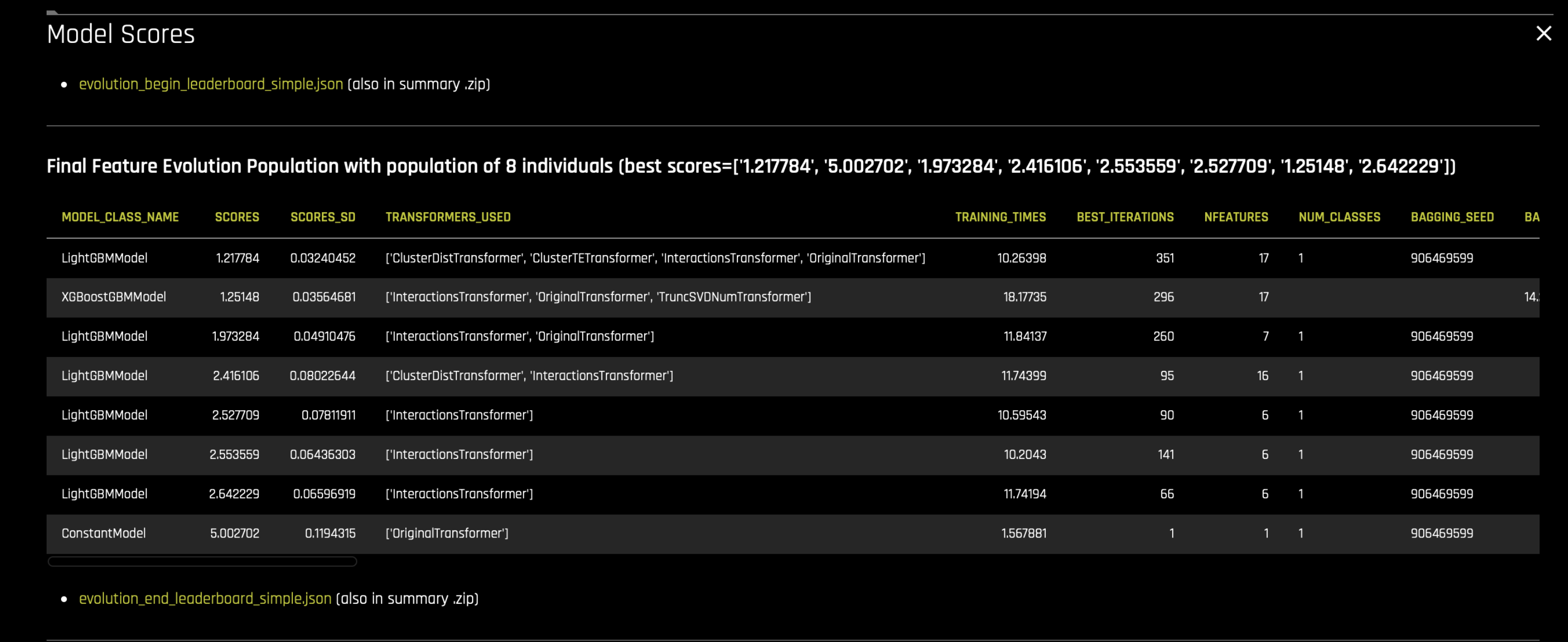
从演变最终排行榜中选择最终模型进行集成。这些模型列示在摘要 zip 中的
final_leaderboard_simple.json文件。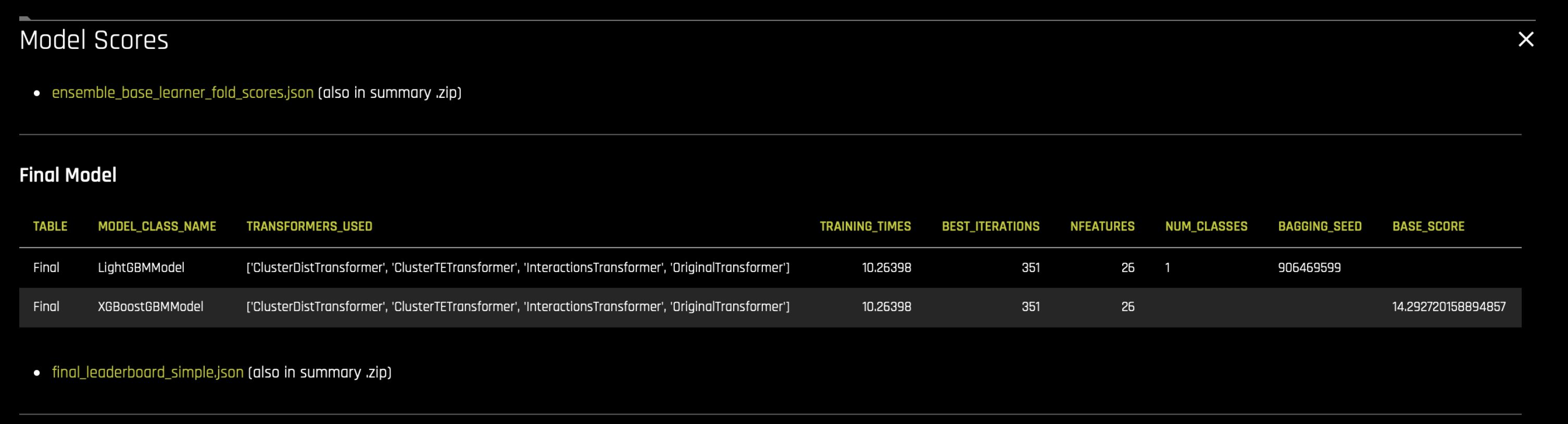
all_leaderboard_simple.json文件列示所有排行榜模型的完整历程,包括其分数和参数以及它们所处的阶段。
集成和最终评分管道创建:使用 MOJO 和/或 Python scoring pipelines 集成最终模型,并构建最终生产管道。
Driverless AI 同时支持堆叠和混合集成技术。可以在启动实验时使用 ensemble_meta_learner 参数启用这些技术。采用带爬山算法的线性混合器来确定集成中模型的混合分数或权重。采用额外树算法执行堆叠。用于集成的权重和其他参数以及最终模型的得分列示在实验的摘要 zip 存档中的
ensemble_model_description.json和ensemble_scores.json文件内。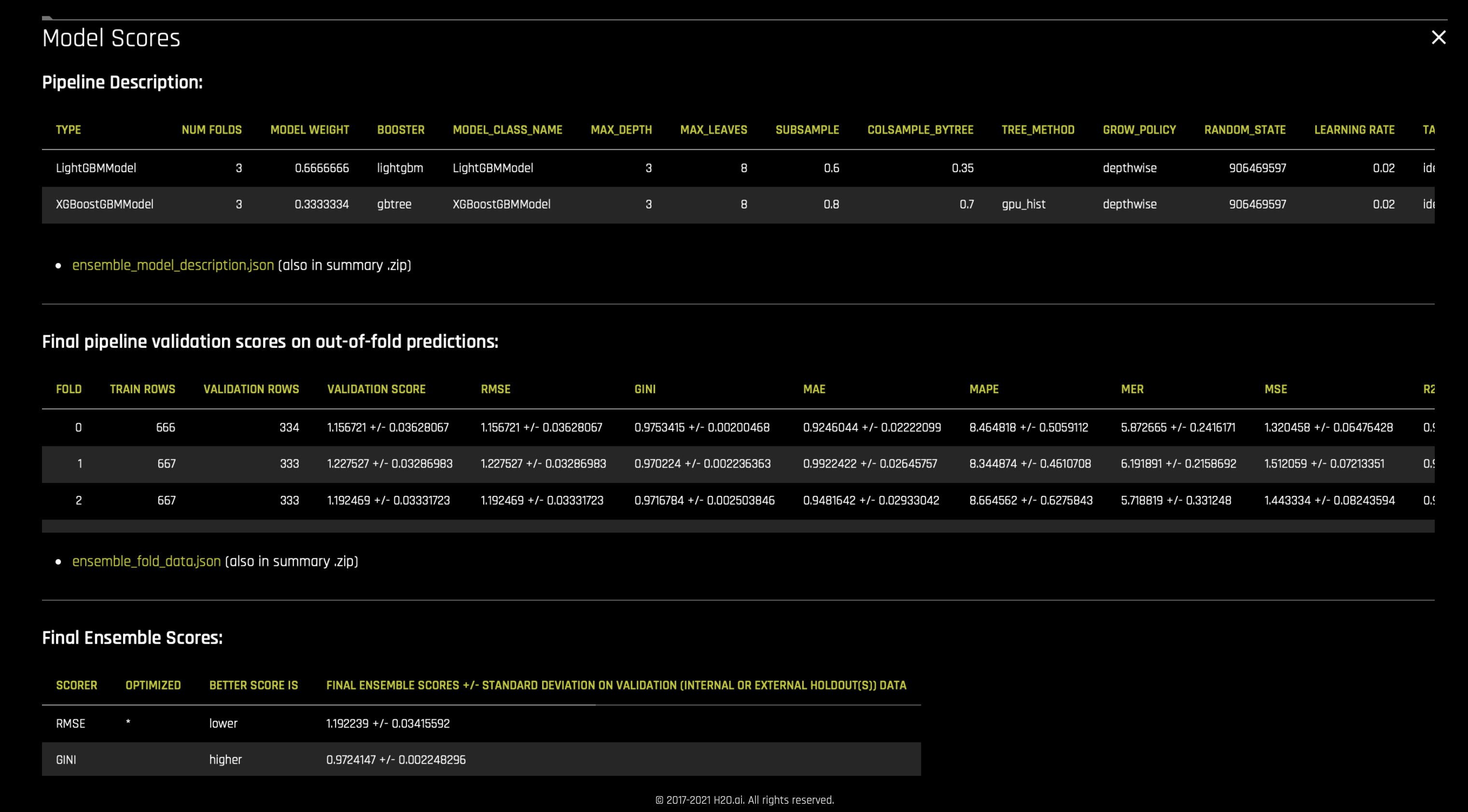
请注意:
特征和模型调优排行榜表 列示了模型的一个名为 特征成本 的参数。特征成本并不等于模型中所用特征的数量,而是基于其复杂性(或可解释性),即所用的转换/应用的交互/花费的时间。例如,较之高成本模型,低成本模型可能拥有更多数量的较高可解释性特征(即成本数 !=使用的特征数)。此参数用于遗传算法的工作流程中,用于在已给出实验的可解释性刻度盘设置的情况下,确定是否需要减少特征计数。
演变开始排行榜表 中的某些个体未进行评分。出现这种状况的原因可能是:
它们违反了一些针对可解释性设置的给定选择而施加于特征计数上的限制,因此发生了更改,而分数不再适用。
它们是末尾新增的个体,用于凑足群体所需的总个体数,因此尚未评分。
另请参见 additional details.
阅读日志¶
“实验”预览提供了实验各个阶段中完成的迭代次数和构建的模型总数(包括交叉验证模型)的估值。例如(从日志中)-
点击 here 下载并查看此例中使用的样本日志文件。
INFO | Number of individuals: 8
INFO | Estimated target transform tuning iterations: 2
INFO | Estimated model and feature parameter tuning iterations: 4
INFO | Estimated total (tuning + feature evolution) number of iterations: 16
INFO | Estimated total (backend + tuning + feature evolution + final) number of models to train: 598
INFO | Backend tuning: 0 model(s)
INFO | Target transform tuning: 18 model(s)
INFO | Model and feature tuning: 48 model(s)
INFO | Feature pre-pruning: 0 model(s)
INFO | Feature evolution: 528 model(s)
INFO | Final pipeline: 3 model(s)
INFO | ACCURACY [7/10]:
INFO | - Training data size: *1,000 rows, 11 cols*
INFO | - Feature evolution: *LightGBM*, *3-fold CV**, 2 reps*
INFO | - Final pipeline: *LightGBM, averaged across 3-fold CV splits*
INFO |
INFO | TIME [2/10]:
INFO | - Feature evolution: *8 individuals*, up to *10 iterations*
INFO | - Early stopping: After *5* iterations of no improvement
INFO |
INFO | INTERPRETABILITY [8/10]:
INFO | - Feature pre-pruning strategy: Permutation Importance FS
INFO | - Monotonicity constraints: enabled
INFO | - Feature engineering search space: [Interactions, Original]
INFO |
INFO | LightGBM models to train:
INFO | - Target transform tuning: *18*
INFO | - Model and feature tuning: *48*
INFO | - Feature evolution: *528*
INFO | - Final pipeline: *3*
本实验仅创建 LightGBM 模型。列示的模型计数估值将每个 nfold 模型都视为一个计数。
由于这是一个回归问题,因此执行目标调优并创建 18 个模型来确定数据集的最佳 target transformation. 这将通过三折交叉验证创建 3 个模型,每个模型重复 2 次,即两个不同的数据集视图(训练/有效拆分中)。此操作在两个迭代中完成。
接下来的 4 次迭代将用于模型和特征参数调优。这包括创建大约 8*3*2(个体*折叠数*重复次数) ~ 48 个模型。
调优阶段的输出模型通过遗传算法进行特征演变。遗传算法在 8 个个体(群体大小)上执行。接下来的 10 次迭代用于特征演变,对大约 (10 * 8/2[群体子集] * (3*2) (交叉验证折叠数*重复次数) ~240 个新模型进行评分。其上限为 528 个模型。如果 5 次迭代后分数仍未提高,则提前停止。
最终管道是通过单个个体和三折交叉验证创建的。
这些估值是基于“准确度”/“时间”/“可解释性”刻度盘设置、所选模型的类型,以及实验的其他专家设置而产生的。
然后转换器为实验提供搜索空间,并逐个特征进行安排。
WARNING| - Feature engineering search space: [CVCatNumEncode, CVTargetEncode, Frequent, Interactions, NumCatTE, OneHotEncoding, Original]
DATA | LightGBMModel *default* feature->transformer map
DATA | X_0 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_1 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer', 'InteractionsTransformer']
DATA | X_2 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_3 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_4 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_5 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_6 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_7 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_8 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
DATA | X_9 :['OriginalTransformer', 'CVTargetEncodeTransformer', 'OneHotEncodingTransformer']
验证拆分 创建。在内部对数据集进行拆分,以创建用于模型构建和调优的交叉验证折叠。本例中,特征演变阶段将需要 3 折交叉验证并重复 2 次,即完成数据视图。最终管道也将执行 3 折交叉验证。在将数据集拆分成多个折叠进行内部验证之后,计算 Kolmogorov-Smirnov 统计数据,以查看折叠是否具有类似的数据分布。
INFO | Preparing validation splits...
INFO | [Feature evolution (repeat 1)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | [Feature evolution (repeat 2)] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01793 | means: [14.3447695, 14.362441, 14.366518, 14.318932, 14.340719, 14.370607]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.024698351045656434, pvalue=0.9985813106473687)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.027531279405342373, pvalue=0.9937850958604381)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02358730544637591, pvalue=0.9993204937887651)
INFO | [Final pipeline ] Optimized fold splits: Target fold mean (target transformed) stddev: 0.01329 | means: [14.346849, 14.358292, 14.362315, 14.327351, 14.342845, 14.366349]
INFO | Kolmogorov-Smirnov statistics for splits of fold 0: KstestResult(statistic=0.02176727625829422, pvalue=0.9998424722802827)
INFO | Kolmogorov-Smirnov statistics for splits of fold 1: KstestResult(statistic=0.025154089621855738, pvalue=0.9981216923269776)
INFO | Kolmogorov-Smirnov statistics for splits of fold 2: KstestResult(statistic=0.02074638356497427, pvalue=0.9999414082418556)
INFO | Feature engineering training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | split #4: 666 / 334 - target min -1.264726 / 1.490552, target mean: 14.344769 / 14.362441, target max: 27.710434 / 25.997716, target std: 5.026847 / 4.968671
INFO | split #5: 667 / 333 - target min -1.264726 / 1.101135, target mean: 14.366518 / 14.318931, target max: 26.492384 / 27.710434, target std: 4.981698 / 5.058766
INFO | split #6: 667 / 333 - target min 1.101135 / -1.264726, target mean: 14.340719 / 14.370606, target max: 27.710434 / 26.492384, target std: 5.010135 / 5.002203
INFO | Doing backend tuning on data of shape (666, 11) / (334, 11)
INFO | Maximum number of rows (train or valid) for feature evolution: 667
INFO | Final ensemble training / validation splits:
INFO | split #1: 666 / 334 - target min -1.264726 / 0.766517, target mean: 14.346850 / 14.358292, target max: 27.710434 / 26.761804, target std: 4.981032 / 5.059986
INFO | split #2: 667 / 333 - target min -1.264726 / 2.914631, target mean: 14.362315 / 14.327350, target max: 26.761804 / 27.710434, target std: 4.999868 / 5.022746
INFO | split #3: 667 / 333 - target min 0.766517 / -1.264726, target mean: 14.342844 / 14.366349, target max: 27.710434 / 25.879954, target std: 5.037666 / 4.946448
INFO | Maximum number of rows (train or valid) for final model/ensemble: 667
注册适用的转换和基因以及特征演变的遗传算法的 tournament style 。
INFO | Transformers used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsTransformer', 'OriginalTransformer']
INFO | Genes used (accuracy=7, time=2, interpretability=8, num_classes=1): ['InteractionsGene', 'OriginalGene']
INFO | Tournament style: model
运行 后端调优 作业,以确保一切如期进行。
INFO | Auto-tuning modeling backend: start.
INFO | Backend candidate Job# 0 Name: LightGBMModel using GPU (if applicable) with Booster: lightgbm
INFO | Backend candidate Job# 1 Name: LightGBMModel using CPU with Booster: lightgbm
...
INFO | Auto-tuning modeling backend: end : Duration: 299.8936 s
泄露检测 运行模型以确定各个特征对目标的预测能力。然后,对每个具有较高变量重要性的特征建立简单的模型。具有高 AUC(用于分类)或 R2 分数(回归)的模型将作为潜在泄漏报告给用户。
INFO | Checking for leakage...
...
INFO | Time for leakage check for training and None: 30.6861 [secs]
INFO | No significant leakage detected in training data ( R2: 0.7957284 )
对回归问题执行目标调优,找出目标变量的最佳分布(对数、单位框、平方根等),以优化评分器(3 个模型,在 2 次迭代中进行 6 折交叉验证)。每个模型都尝试不同的目标转换。
INFO | Tuned 18/18 target transform tuning models. Tuned [LIGHTGBM] Tuning []
INFO | Target transform search: end : Duration: 389.6202 s
INFO | Target transform: TargetTransformer_identity_noclip
参数和特征调优阶段 从第三次迭代开始进行,并在构建 ~48 个模型 (8*3*2) 时使用 4 次迭代。
构建 8 个个体,并确保模型中包含的特征满足可解释性条件(参见 nfeatures_max 和 ngenes_max)。此外,第 6 次迭代中还添加了一个额外的 FS 个体。请参阅 tuning phase 。因此,此阶段将构建超过 48 个模型。
INFO | Model and feature tuning scores (RMSE, less is better):
INFO | Individual 0 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 1 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 2 : 1.638517 +/- 0.04910973 [Tournament: 1.638517 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 3 : 1.643672 +/- 0.06142867 [Tournament: 1.643672 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 4 : 1.66976 +/- 0.04171555 [Tournament: 1.66976 Model: LIGHTGBM Feature Cost: 13]
INFO | Individual 5 : 1.683212 +/- 0.06572724 [Tournament: 1.683212 Model: LIGHTGBM Feature Cost: 14]
INFO | Individual 6 : 1.690918 +/- 0.05417363 [Tournament: 1.690918 Model: LIGHTGBM Feature Cost: 16]
INFO | Individual 7 : 1.692052 +/- 0.04037833 [Tournament: 1.692052 Model: LIGHTGBM Feature Cost: 17]
INFO | Individual 8 : 2.080228 +/- 0.03523514 [Tournament: 2.080228 Model: LIGHTGBM Feature Cost: 13]
INFO | Applying nfeatures_max and ngenes_max limits to tuning population
INFO | Parameter tuning: end : Duration: 634.5521 s
INFO | Prepare Feature Evolution
INFO | Feature evolution has 0 brain cached individuals out of 8 individuals
INFO | Making 1 new individuals during preparation for evolution
INFO | Pre-pruning 1 gene(s) from 12 active base genes
INFO | Starting search for statistically relevant features (FS scheme)
INFO | FS Permute population of size 1 has 2 unique transformations that include: ['InteractionsTransformer', 'OriginalTransformer']
INFO | Transforming FS train
INFO | Using 2 parallel workers (1 parent workers) for fit_transform.
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | Transforming FS valid
INFO | Submitted 2 and Completed 2 non-identity feature engineering tasks out of 12 total tasks (including 10 identity)
INFO | 10 features created during FS Permute
INFO | Using model LIGHTGBM for FS
使用遗传算法的 特征演变 从第 7 次迭代开始,接下来的 10 次迭代中,每次迭代所得分数约为 (8/2)(子群体)*(3*2)=24 个新模型。
第 16 次迭代结束时,实验尚未聚合,因此特征演变停止。确保模型中包含的特征满足可解释性条件,并且小于最大允许限值(参见 nfeatures_max 和 ngenes_max)。最佳个体和群体存储在 Driverless AI 大脑中,以便重新启动或重新拟合实验。最佳个体进入下一阶段。
INFO | Scored 283/310 models on 31 features. Last Scored [LIGHTGBM]
INFO | Scores (RMSE, less is better):
INFO | Individual 0 : 1.540669 +/- 0.07447481 [Tournament: 1.540669 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 1 : 1.541396 +/- 0.07796533 [Tournament: 1.541396 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 2 : 1.542085 +/- 0.07796533 [Tournament: 1.542085 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 3 : 1.543484 +/- 0.07796533 [Tournament: 1.543484 Model: LIGHTGBM Feature Cost: 9]
INFO | Individual 4 : 1.547386 +/- 0.08567484 [Tournament: 1.547386 Model: LIGHTGBM Feature Cost: 10]
INFO | Individual 5 : 1.557151 +/- 0.08078833 [Tournament: 1.557151 Model: LIGHTGBM Feature Cost: 8]
INFO | Individual 6 : 3.961817 +/- 0.08480774 [Tournament: 3.961817 Model: LIGHTGBM Feature Cost: 4]
INFO | Individual 7 : 4.052189 +/- 0.05662354 [Tournament: 4.052189 Model: LIGHTGBM Feature Cost: 1]
INFO | Best individual with LIGHTGBM model has 7 transformers creating 10 total features and 10 features for model: 1.540669 RMSE
DATA | Top 10 variable importances of best individual:
DATA | LInteraction LGain
DATA | 0 3_X_3 1.000000
DATA | 1 10_InteractionMul:X_0:X_1 0.570066
DATA | 2 4_X_4 0.264919
DATA | 3 10_InteractionAdd:X_0:X_1 0.225805
DATA | 4 2_X_2 0.183059
DATA | 5 0_X_0 0.130161
DATA | 6 1_X_1 0.124281
DATA | 7 10_InteractionDiv:X_0:X_1 0.032255
DATA | 8 10_InteractionSub:X_0:X_1 0.013721
DATA | 9 7_X_7 0.007424
INFO | Experiment has not yet converged after 16 iteration(s). Last few scores: ['1.63849', '1.63852', '1.63852', '1.61909', '1.61909', '1.56956', '1.56956', '1.54208', '1.54208', '1.54067', '1.54067', '1.54067']
INFO | Completed all expected evolution iterations: 17
INFO | Final Feature Evolution Population with population of 8 individuals (best scores=['1.547386', '1.540669', '4.052189', '1.557151', '1.542085', '3.961817', '1.541396', '1.543484'])
...
INFO | Applying nfeatures_max and ngenes_max limits to final individual 0 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 1 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 2 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 3 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 4 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 5 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 6 layer 0
INFO | Applying nfeatures_max and ngenes_max limits to final individual 7 layer 0
INFO | Exporting best individual pickle /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_individual.pickle
INFO | Exporting best population for model-feature caching to /opt/h2oai/dai/tmp/n/h2oai_experiment_59939c96-0150-11ec-a7e1-0242c0a8fe02/best_population.pickle
INFO | Final population size before sampling: 8. After sampling expected population size: 1.
INFO | Final population size after sampling: 1 (0 reference) with models_final=3 and num_ensemble_folds=3
INFO | Final Model sampled population with population of 8 individuals (best scores=['1.540669'])
在第 17 次迭代中,对最终 集成 模型执行三折交叉验证,对所用特征执行一些检查,并创建预测和 python 及 mojo 评分管道 。收集了 工件 的日志和摘要。
INFO | Completed 3/3 final ensemble models.
INFO | Model performance:
INFO | fold: 0, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 2.4198, fit+predict model time: 0.376, total pipeline time: 0.48786, fit pipeline time: 0.29738
INFO | fold: 1, model name: LightGBM, model iterations: 500, model transformed features: 10, total model time: 3.343, fit+predict model time: 0.34681, total pipeline time: 0.43664, fit pipeline time: 0.24267
INFO | fold: 2, model name: LightGBM, model iterations: 473, model transformed features: 10, total model time: 2.1446, fit+predict model time: 0.38534, total pipeline time: 0.41979, fit pipeline time: 0.23152
INFO | Checking for shift in tuning model -> final model variable importances
DATA | New features created only in final pipeline: Count: 0 List: []
DATA | Extra features created in final pipeline compared to genetic algorithm population: Count: 0 List: []
DATA | Missing features from final StackedEnsemble pipeline compared to genetic algorithm population: Count: 0 List: []
INFO | Completed training of the final scoring pipeline
INFO | Predictions and Scoring final pipeline...
INFO | Scored 286/310 models on 31 features. Last Scored []
...
INFO | Experiment: buvobamu (59939c96-0150-11ec-a7e1-0242c0a8fe02)
INFO | Version: 1.10.0, 2021-08-20 01:48
INFO | Settings: 7/2/8, seed=1037348886, GPUs enabled
INFO | Train data: [XXXXX] (1000, 11)
INFO | Validation data: N/A
INFO | Test data: N/A
INFO | Target column: [XXXXX] (regression, identity_noclip-transformed)
INFO | System specs: Docker/Linux, 252 GB, 40 CPU cores, 2/2 GPUs
INFO | Max memory usage: 0.849 GB, 0.279 GB GPU
INFO | Recipe: AutoDL (16 iterations, 8 individuals)
INFO | Validation scheme: random, 6 internal holdouts (3-fold CV)
INFO | Feature engineering: 31 features scored (10 selected)
INFO | Timing: MOJO latency 0.0571 millis (512.7kB), Python latency 110.0896 millis (1.1GB)
INFO | Data preparation: 310.14 secs
INFO | Shift/Leakage detection: 30.75 secs
INFO | Model and feature tuning: 1027.26 secs (61 of 66 models trained)
INFO | Feature evolution: 2102.52 secs (222 of 528 models trained)
INFO | Final pipeline training: 17.77 secs (3 models trained)
INFO | Python / MOJO scorer building: 49.86 secs / 19.75 secs
INFO | Validation score: RMSE = 5.002508 (constant preds of 14.35)
INFO | Validation score: RMSE = 1.638517 +/- 0.04910973 (baseline)
INFO | Validation score: RMSE = 1.543872 +/- 0.04469455 (final pipeline)
INFO | Test score: RMSE = N/A
INFO |
INFO |
INFO | Final validation scores (internal holdout, bootstrap on folds) +/- stddev:
INFO | optimized: RMSE = 1.543872 +/- 0.04469455 (less is better)
INFO | GINI = 0.9528597 +/- 0.001413133 (more is better)
INFO | MAE = 1.148299 +/- 0.02813014 (less is better)
...
INFO |
2021-08-20 01:48:09,475 C: 14% D:935.5GB M:249.9GB NODE:LOCAL1 7646 INFO | Collecting logs
一些额外详情¶
前置特征选择:根据实验设置,特征缩减可适用于所有模型,或可添加一个特殊的 FS(特征选择)个体,并在遗传算法开始之前减少原始列。减少 所有模型 的特征数量仅适用于以下情况(满足以下条件之一):
列数大于 max_orig_cols_selected,或
非数值列数量大于 max_orig_nonnumeric_cols_selected,或
数值列数量大于 max_orig_numeric_cols_selected
假设所有模型并未满足以上要求;仅对 FS 个体 (EXTRA_FS) 减少特征数量只适用于以下情况(满足以下条件之一):
列数大于 fs_orig_cols_selected,或
非数值列数量大于 fs_orig_numeric_cols_selected,或
数值列数量大于 fs_orig_nonnumeric_cols_selected
调优阶段模型起源:SEQUENCE 和 DefaultIndiv:特征转换和模型超参数是从内部专有数据科学插件建议的基本转换集和参数列表中随机选择的。此集合很简单,并且支持 MOJO 创建以实现管道生产。
Model_origin 为 RANDOM,则允许特征和模型超参数调用其突变列表或函数。
Model_origin 为 EXTRA_FS,则通过基于排列重要性的特征选择 (FS) 添加额外的个体。
Model_origin 为 REF_#,则表示将参考个体作为基线提供(例如 ConstantModel)。
Model_origin 为 GLM_OHE,则表示由 GLM + OHE 生成的特征。
Driverless AI 大脑:在实验构建期间,大脑缓存最佳迭代、参数、模型、基因和群体。它们用于有根据的查找、突变期间交叉验证、实验的 restarts 和 refits 。详情请参见 feature_brain_level.突变策略:对 transformers 执行突变时要应用的策略:样本模式是默认的,倾向于对转换器参数进行采样。
批处理模式倾向于同时执行多种类型的同一转换。
完全模式同时执行更多种类型的同一转换。
以下是一些其他相关专家设置:添加转换器的可能性 (prob_add_genes)、添加最佳共享转换器的可能性 (prob_addbest_genes)、修剪转换器的可能性 (prob_prune_genes)、模型参数突变的可能性 (prob_perturb_xgb)、修剪弱特征的可能性 (prob_prune_by_features)。注意,大多数情况下,默认 Driverless AI 设置执行得最好,这些设置应保持默认值。
通过自定义插件突变:用户可以编写自定义 python 代码并将其连接至内置 Driverless AI 遗传算法,从而控制和指定其自己的突变策略以及需要突变的参数列表。以下是此类插件的 example 。Get_one函数将值列表传递给遗传算法或该参数的 Optuna。如需更多帮助来编写您自己的 custom recipies ,请联系 support@h2o.ai。Optuna:在实验的 Tuning phase 期间,Driverless AI 支持 Optuna 进行模型超参数调优。Optuna 采用了一种叫做树结构 Parzen Estimator 的 Bayesian 优化算法执行超参数优化。详情请参见 enable_genetic_algorithm 和 tournament_style. 选择 Optuna 后,使用 Optuna 对模型超参数进行调优,并将遗传算法用于特征工程。Bayesian 优化利用数据中的结构;由于 Optuna 采用 Bayesian 技术,因此建议在搜索空间不太复杂的情况下使用此技术。关于 Optuna 启动 here 的信息,请参见可切换参数的列表。Leaderboard :实验构建期间,可以指示 Driverless 以建立一系列不同的实验,尝试不同的方法来建立简单和复杂的立即可用模型。