Driverless AI 中的无监督算法(实验性)¶
在 1.10 版本中,Driverless AI 公开了可用于无监督建模的无监督转换器,即:
从概念上讲,无监督实验的整体管道与常规监督实验的管道类似,但存在几处明显差异:
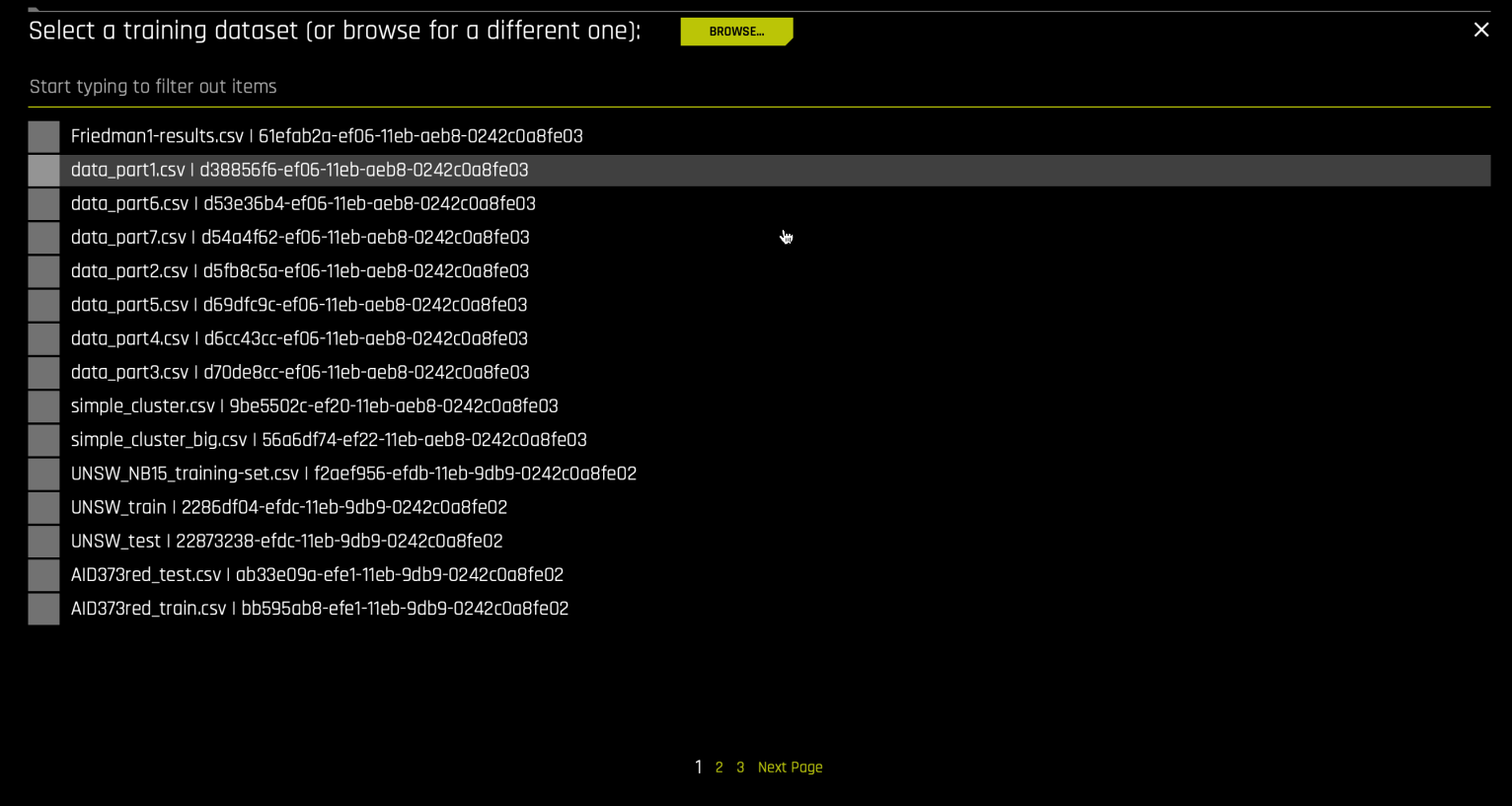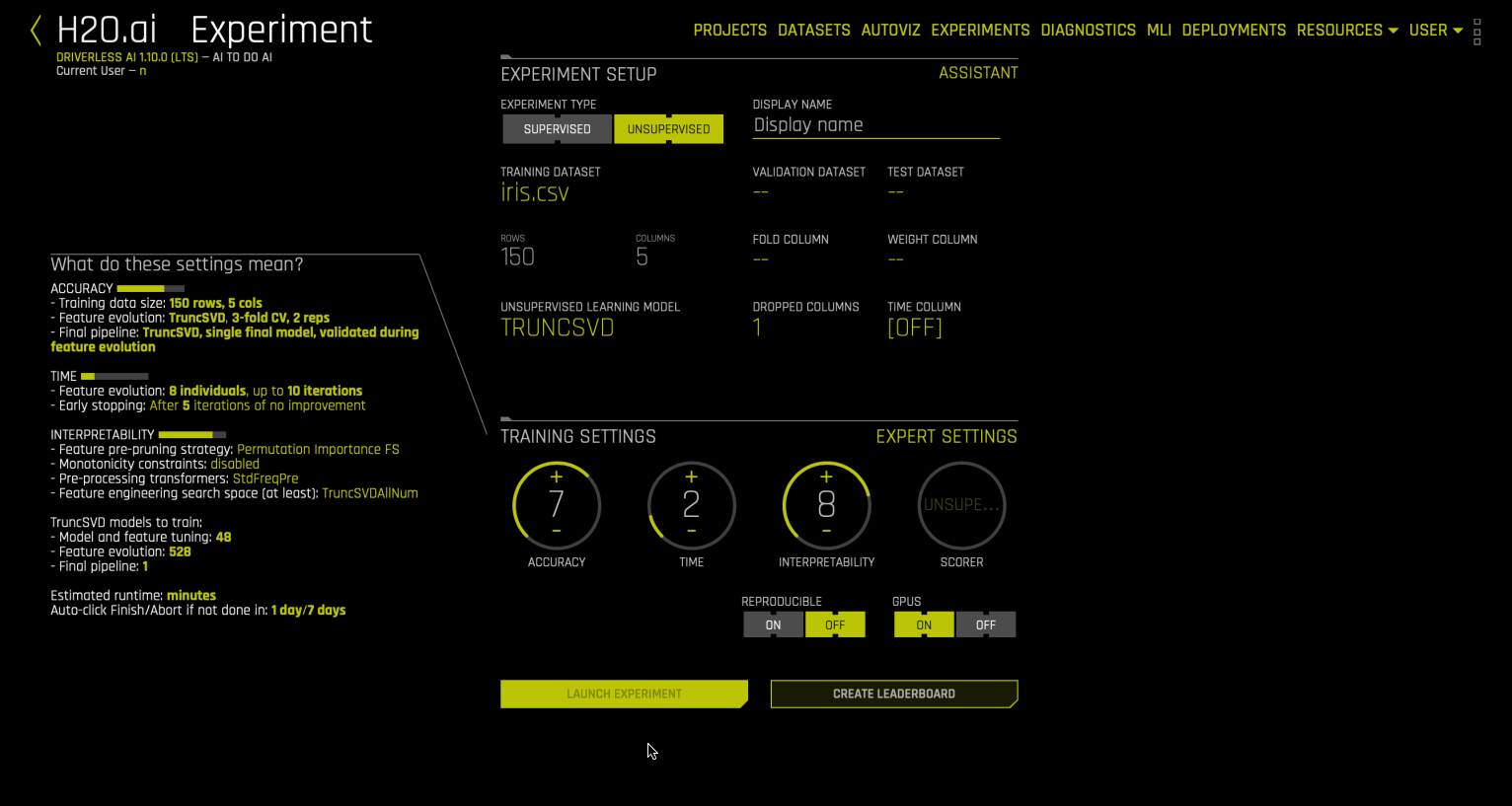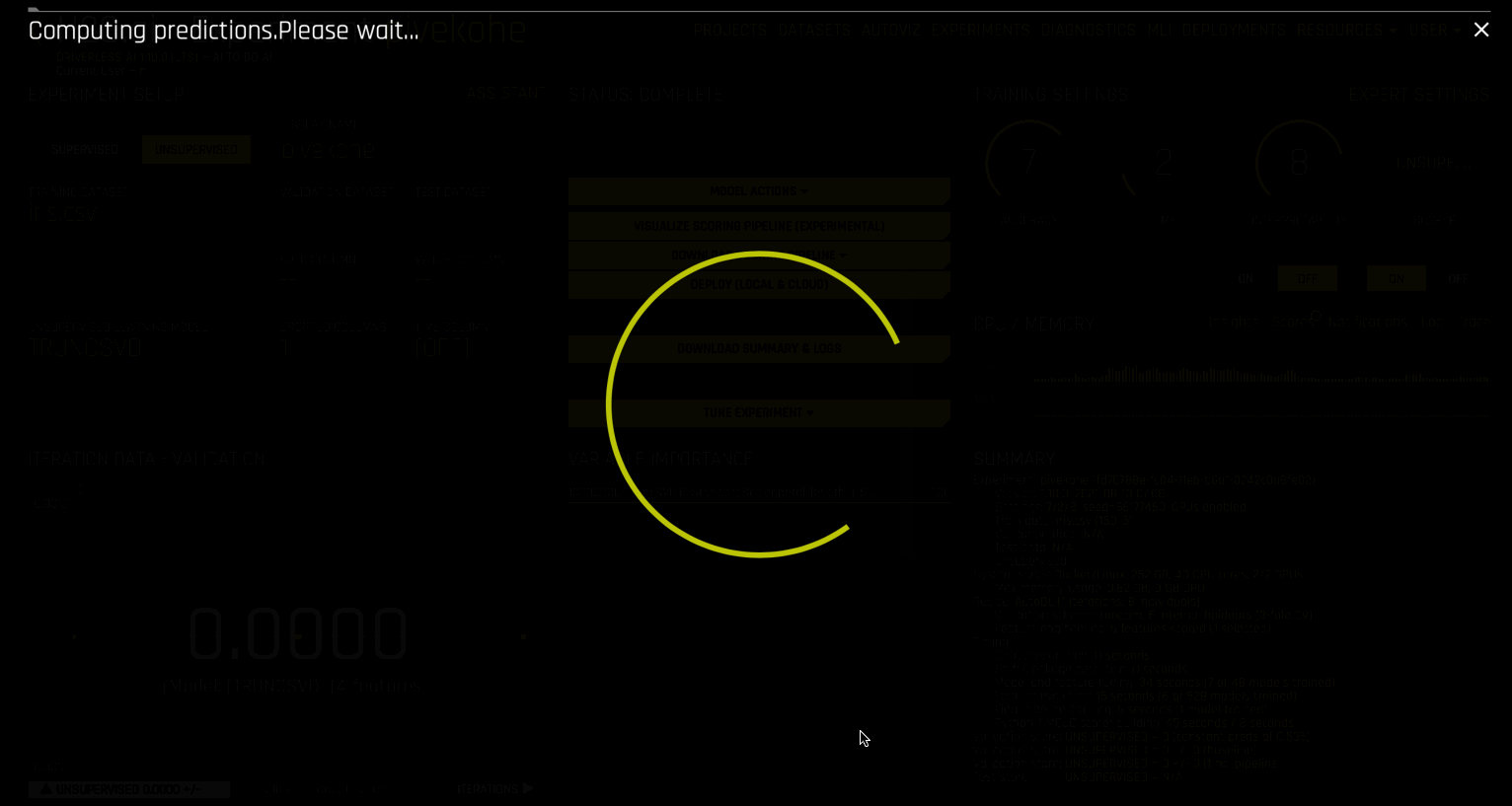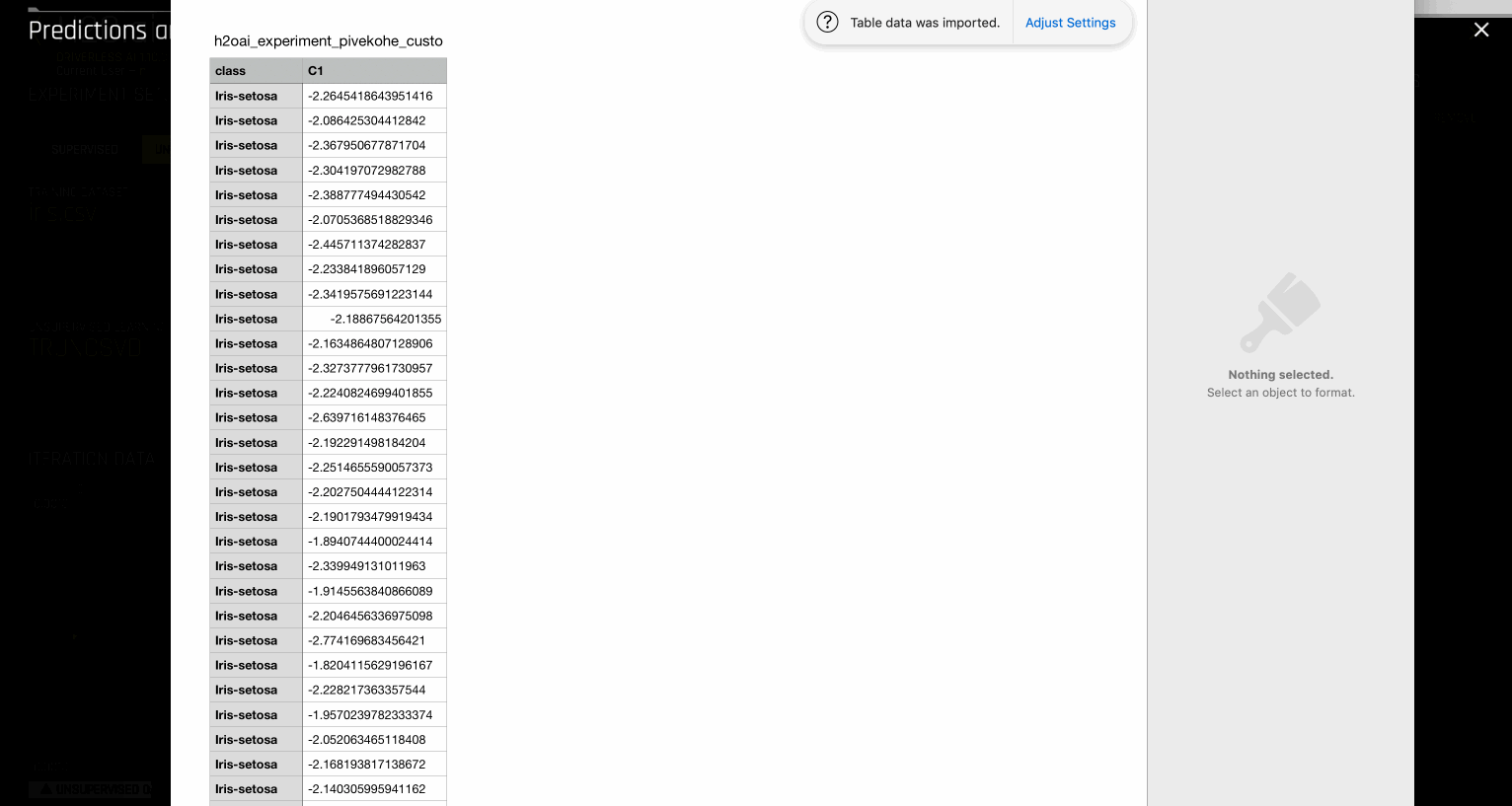
只能选择一种无监督算法(模型、管道)(例如聚类或异常检测,但不能同时选两者)。换言之,遗传算法中的所有个体都为同一个模型类型,但它们可以有不同参数(例如,聚类数、用于聚类的列)。
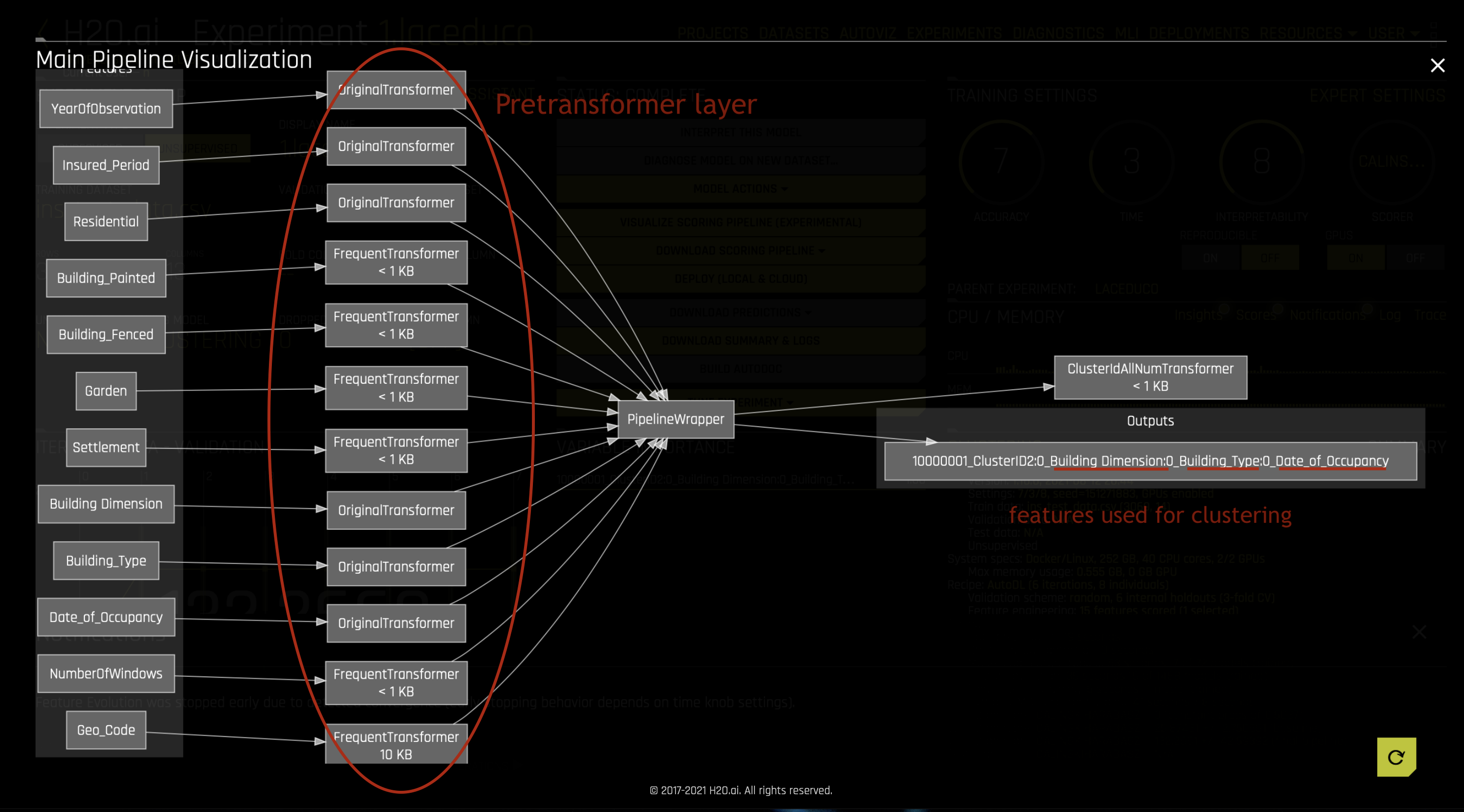
每个此类无监督建模管道均由一个预转换器、一个转换器和一个模型组成。无需标签 (y)。
无监督模型只有一个函数:列出包括的预转换器、包含的转换器和所有适用评分器。模型本身是纯传递函数,models.predict() 方法返回转换器管道的输出(转换器生成的任何特征)。这也意味着模型的变量重要性不明确,在特征中均匀分布。对于聚类,只有 1 个特征(分配的聚类标签),其变量重要性为 1.0。
仅当有指标(评分器)通过 score(X, actual=None, predicted=transformed_X) 评估转换质量时,才可能实现自动机器学习。例如,对于给定数据集、给定标签和指标,可评估由 K-Means 聚类算法创建的标签的质量。如果没有评分器可用,则使用 无监督评分器,它对任何输入都返回 0。此值可忽略不计,它向 Driverless AI 发出信号,表明实验是在第一次迭代后聚合的。
1.10.0 版本不支持 MLI,但计划在未来版本中支持。
对于无监督实验,最终模型没有集成和交叉验证(强制
fixed_ensemble_level=0)。因此,无法创建训练保持预测(所有数据用于最终模型)。如果训练数据需要聚类分配等预测结果,请对训练数据作出预测,通常会伴随过拟合警告(由于 AutoML 期间的大量调优),因为使用同一数据执行 fit() 和 predict()。
Isolation Forest 异常检测¶
Isolation forest 通过随机拆分决策树来隔离或标识异常条目。具体思路是,在特征空间 outlier 将进一步远离常规观测值,从而减少用于隔离至树的终端节点的随机拆分。此算法根据每个观测值在森林中的路径长度(从根节点至终端节点)为其分配异常得分。分数越低,相应行越有可能异常。Driverless AI 在内部执行 sklearn’s Isolation Forest 实现。
构建模型时,可以切换 Driverless AI 的准确度和时间旋钮来调整在模型调优时所执行的操作,但目前由于孤立森林没有使用评分器,所以在执行 genetic algorithm 时,模型将立即聚合并将 tuning phase 中的一个模型用作最终模型。默认设置中将忽略可解释性旋钮。可使用 isolation_forest_nestimators 专家设置参数调整孤立森林模型的树数或 n_estimators。
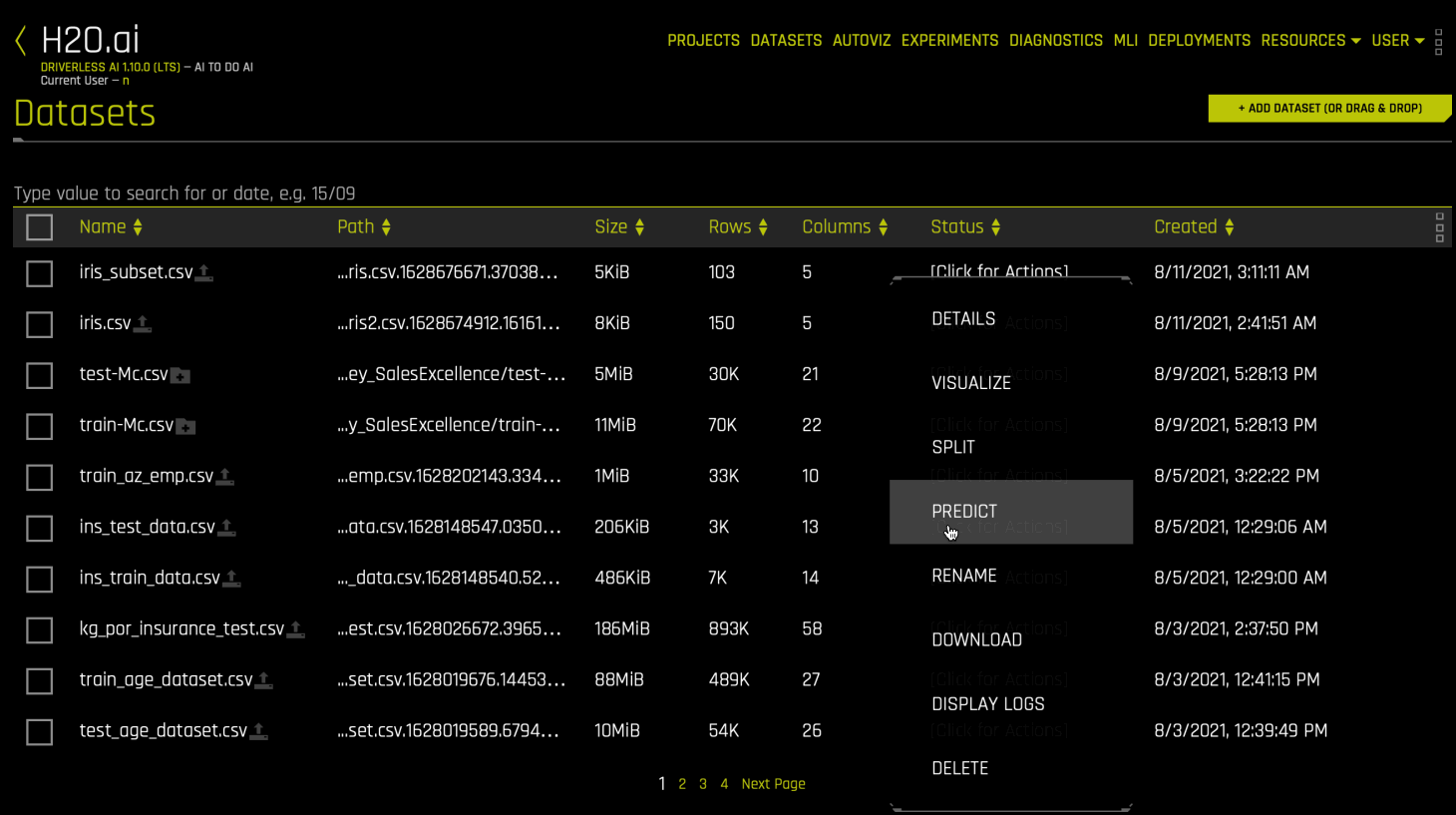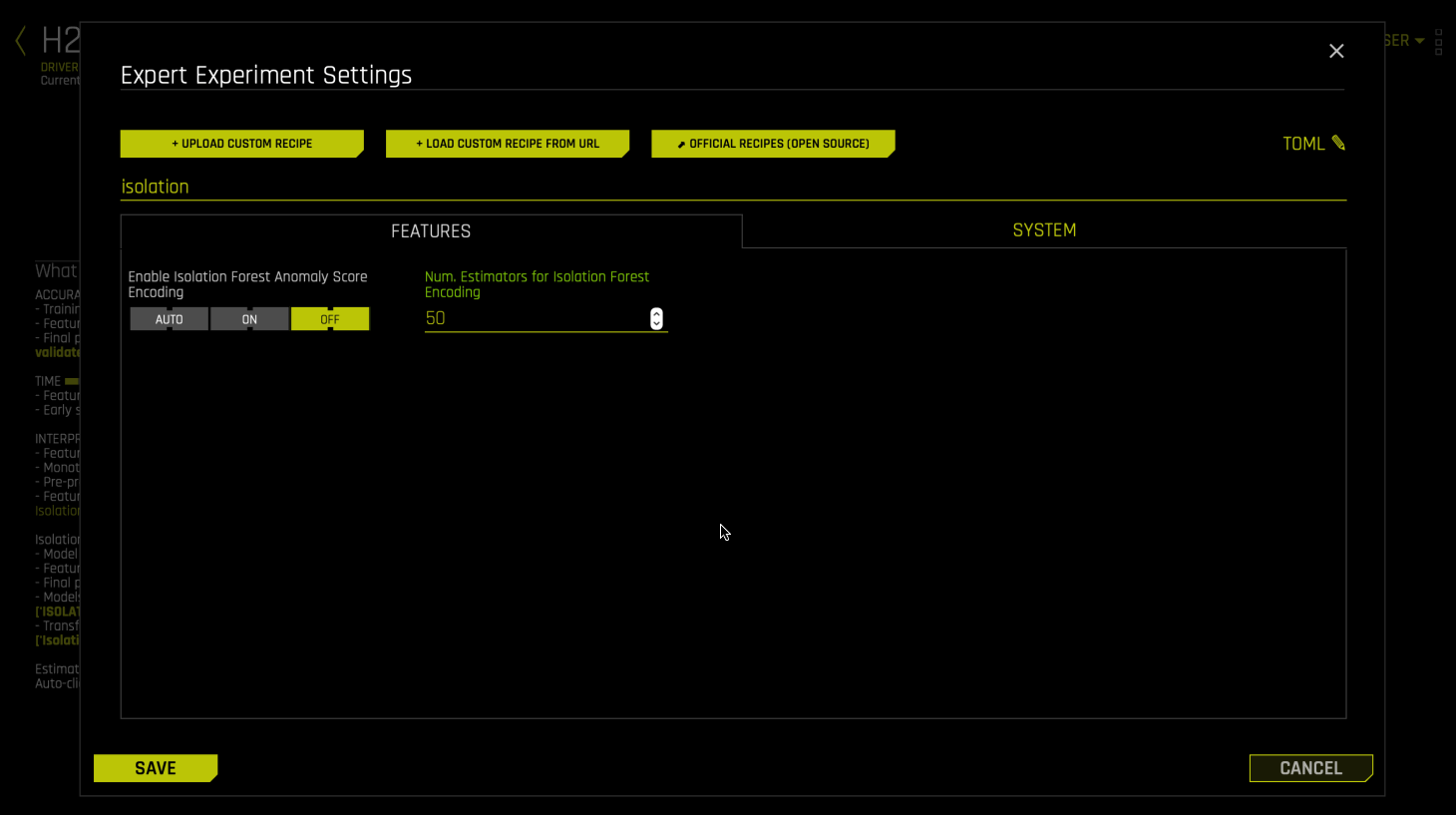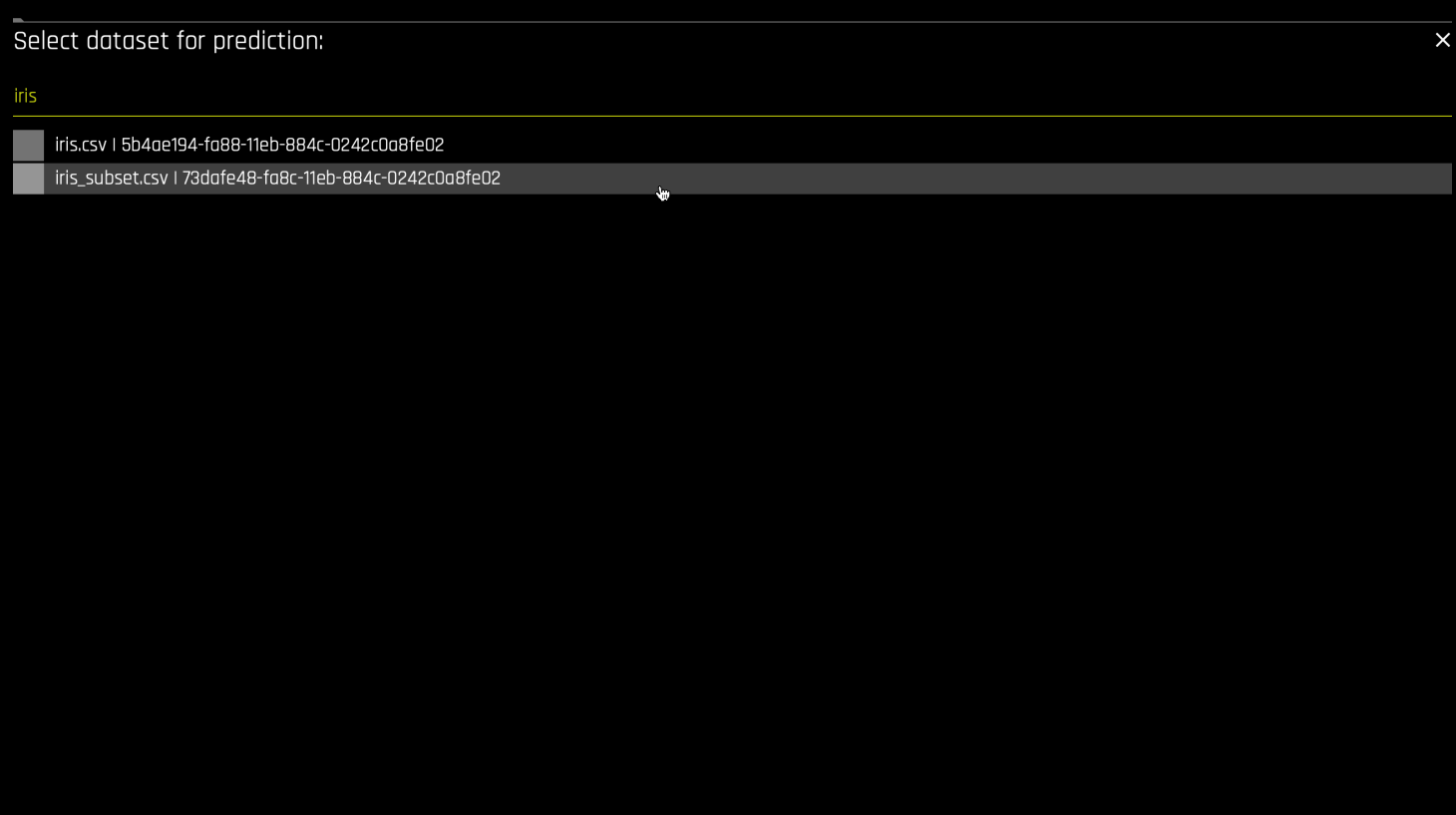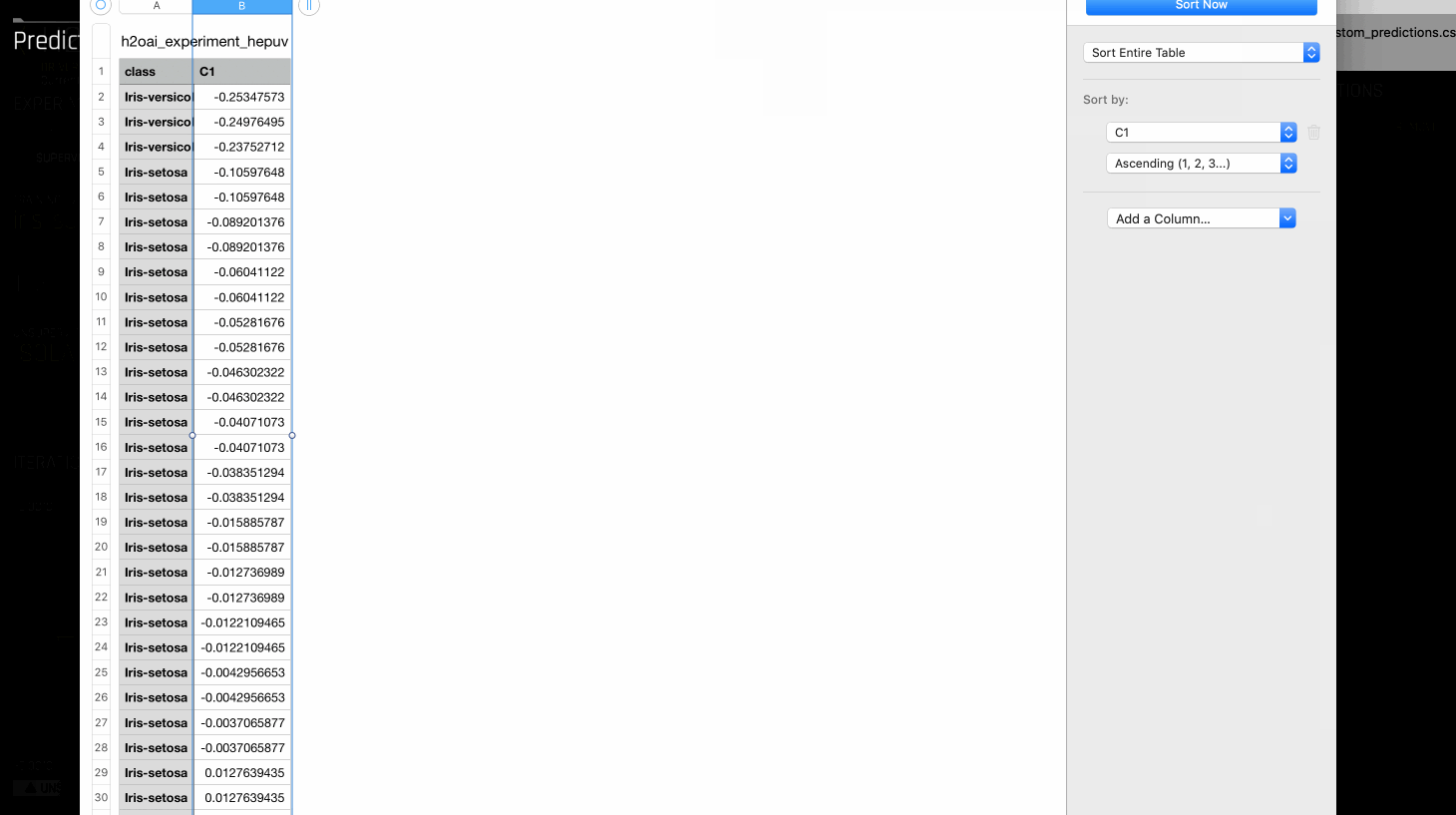
构建模型后,可以在同一数据集上进行预测以获得 分数 。行分数越低,就越有可能是模型的异常值。Visualize Scoring Pipeline option 汇总构建模型中使用的特征和应用的转换。
要基于这些分数创建 标签 ,分位数值可用作阈值。例如,如果您知道数据集中有 5% 的行异常,则可以用它来计算分数的第 95 个分位数。此分位数可以作为阈值来将每一行分类为是否异常。
可以使用 Python scoring pipeline 将孤立森林模型部署至生产环境(目前不支持 MOJO)。
用例思路:给定一个异常的检测实验,您可以对训练数据集(包括所有原始列)创建预测,并重新上传至 Driverless AI 来执行监督实验。对于给定的类似数据集(在生产中),您现在有一个无监督评分器来告知每一行的异常分数,以及一个监督评分器提供每个特征的 Shapley 贡献原因码来解释每一行是否异常的原因。
KMeans 聚类¶
聚类算法将观察结果划分成多个聚类。Driverless AI 使用 sklearn KMeans 聚类算法划分观察结果,使它们属于具有最接近平均值(聚类质心)的聚类。
Driverless AI 公开以下在数值和分类列上运行的无监督 模型 ,以构建 K-Means 聚类模型。您可以根据数据集的特征选择模型类型,或者(逐个)运行所有模型,以确定哪个模型最适合您的数据集。
KMeans :仅在数值列上执行 K-Means 聚类
KMeansFreq :在数值和 frequency transformed 分类上执行 K-Means 聚类(整数列仅被视为数值)
KMeansOHE :在数值和独热编码转换分类列上执行 K-Means 聚类
Driverless 提供以下 评分器 以启用自动无监督聚类:
CALINSKI HARABASZ :Calinski-Harabasz 指数又称方差比标准,是所有聚类的多聚类间离散度之和与聚类间离散度之和的比值。此分数 越高,性能越好。
DAVIES BOULDIN :Davies-Bouldin 指数表示聚类之间的平均“相似性”,其中相似性是将聚类之间的距离与聚类自身大小进行比较的一种度量。Davies-Bouldin 指数 越低,模型的聚类之间分离度越好。
SILHOUETTE :轮廓系数是为每个样本定义的,由两个分数组成。一个样本与同一类中所有其它点之间的平均距离。此分数衡量同一聚类中各点的接近程度。以及一个样本与下一个最近聚类中所有其它点之间的平均距离。此分数衡量不同聚类的点的距离。轮廓系数分数 越高,模型的已定义聚类更好。若数据集较大,则此评分器可能会很慢。 Ref
构建聚类模型时,可以切换 准确度 和 时间 旋钮来调整在模型调优和验证时所执行的操作。对于当前支持的立即可用无监督模型,可解释性 旋钮会被忽略,但是可以编写自定义插件来侦听可解释性设置,以控制模型构建期间的参数突变。unsupervised_clustering_min_clusters 和 unsupervised_clustering_max_clusters 参数可用于专家面板,以设置要构建的聚类数量的上限和下限。
模型构建期间,Driverless AI 在特征子集上创建 Kmeans 聚类模型 (介于 2 - 5)。特征子集的大小、用于聚类的列和参数调优是在 genetic algorithm 流程期间确定的。用户可以通过专家设置的 fixed_interaction_depth 参数设置特征子集大小(聚类空间的维数)。值应在 2 到 5 之间。假设 fixed_interaction_depth=4 ,然后聚类将在 4D 中执行。假如说,数据集中存在 4 个以上特征(或在考虑像独热编码这样的预转换之后),则当执行遗传算法时,DAI 将选择输入特征和模型参数(基于内部训练/有效拆分)以确定 4 个特征的最佳可能子集和它们的参数集,以构建优化分数的模型。
对于由(特征子集)聚类模型创建的行,评分器 采用 完整数据集 (预转换所有特征)和 标签 以给出分数。它比较无监督转换器的输出和输入。
实验的 见解 选项卡介绍了聚类转换器在特征子集上的工作情况,以构建最佳模型。它列出了聚类中特征的聚类大小和质心。该绘图以二维形式显示了聚类分离,并且为便于可视化而用颜色编码。使用聚合器算法减少绘图的数据大小。这是 DAI 即将推出的自定义可视化功能(使用 Vega)的预览。
构建模型之前, 预转换 应用于特征。然后该模型建立在这些特征的子集上,并在完整数据集上进行再次评分。因此构建模型之后,可以使用 Visualize Scoring Pipeline option 检查应用于特征的预转换。还可用它检查用于构建聚类模型的特征。可通过在数据集上进行预测来创建聚类 标签 。
为了获得训练(或任何)数据集的聚类标签分配,然后可以使用拟合模型进行预测,就像任何监督模型一样。注意,在同一数据集上执行拟合和预测时,随时都可能发生过拟合。
聚类模型生成 MOJOs 和 Python scoring pipelines 以部署至 production.
您还可通过定义自己的预转换(即输入哪些列和哪些编码用于聚类)、聚类转换器和评分器来编写自定义聚类插件。要查看示例,请参见官方 Driverless AI 插件资料库中的 KMeans Clustering Using RAPIDS.ai recipe 。(要获取最佳结果,使用与您的 Driverless AI 版本相对应的分支版本。)
截断 SVD(降维)¶
Truncated SVD 是一种降维方法,在运行监督算法之前,可应用于数据集以减少特征数量。它分解数据矩阵(其中的列数等于指定截断)。它适用于生成 稀疏 数据的用例(如推荐系统)或用于文本处理中(如 tfidf)。Driverless AI 在内部运行 sklearn Truncated SVD 实现。
Driverless AI 公开 TRUNCSVD 转换器,以减少特征数量。目前用户不能切换任何参数。TRUNCSVD 转换器创建的 n_components 范围在 1 到 5 之间。(注意它们被视为随机突变。)构建模型之后,可以使用 Visualizing scoring pipeline 检查创建的组件数量。此外,可通过对数据集进行预测来获取降维的数据集。目前由于 SVD 实验没有使用评分器,在执行 genetic algorithm 时,模型将立即聚合并将 tuning phase 中的一个模型用作最终模型。
降维模型生成 MOJOs 和 Python 评分管道以部署至 production.
无监督自定义插件¶
Driverless AI 支持 用于无监督学习的自定义 Python 插件 。您可以通过定义自己的预转换、转换器和评分器来编写自定义无监督插件。要查看示例,请参见 official Driverless AI recipes repository.(要获取最佳结果,使用与您的 Driverless AI 版本相对应的分支版本。)