Driverless AI 中的 NLP¶
本节介绍 Driverless AI 的 NLP(文本)处理功能。Driverless AI 平台能够支持独立文本和具有其他列类型(作为预测性特征)的文本。基于 TensorFlow 的架构和 PyTorch 转换器架构(例如,BERT)主要用于特征工程和模型构建。
详细信息,请参阅:
注解
GPU usage 为 Driverless 中的 NLP 和图像用例带来显著提升。
NLP 特征工程与建模¶
Driverless AI 中的预训练 PyTorch 模型

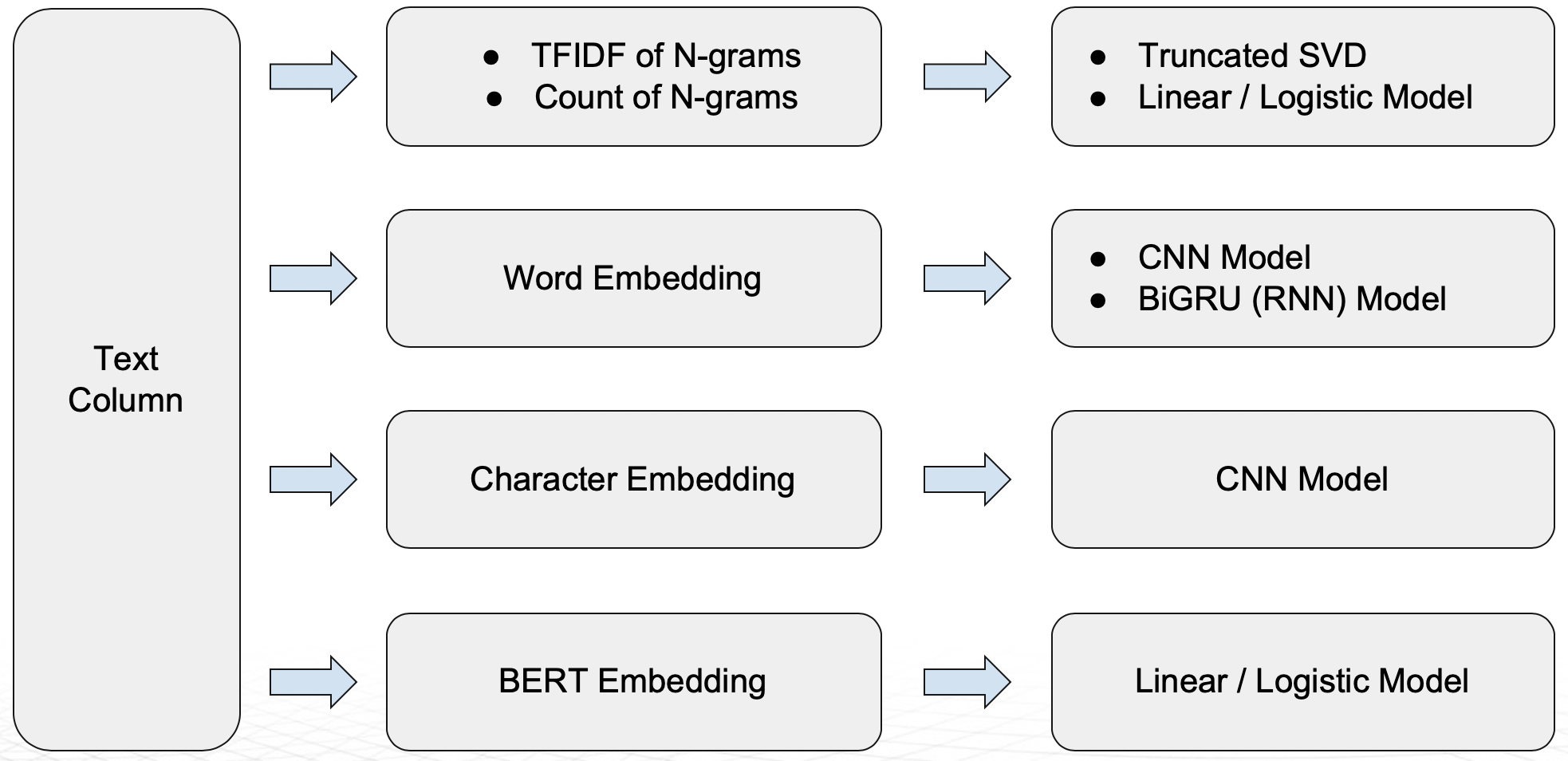
以下 NLP 插件适用于文本列。可在 here 获取 NLP 转换器 的完整列表。
n 元语法频率/TF-IDF + 截断奇异值分解
n 元语法频率/TF-IDF + 线性/逻辑回归
词嵌入 + CNN 模型 (TensorFlow)
词嵌入 + BiGRU 模型 (TensorFlow)
字符嵌入 + CNN 模型 (TensorFlow)
基于 BERT/DistilBERT 的特征工程嵌套 (PyTorch)
支持将多种转换器架构(例如 BERT)作为建模算法 (PyTorch)
n-gram
n 元语法 是给定文本或语音样本中 n 项的连续序列。
n-gram Frequency
基于频率的特征以向量的形式表示给定文本中每个词的计数,是为不同的 n 元语法值创建的。例如,一元语法相当于单个词,二元语法相当于两个成对的连续词,依此类推。出现更频繁的词和 n 元语法将获得更高的权重。而那些较为罕见的词和 n 元语法将获得较低的权重。
TF-IDF of n-grams
基于频率的特征可与逆文档频率相乘,以得到词频-逆文档频率 (TF-IDF) 向量。此操作还可对语料库中出现的罕见词条赋予重要性,这可能会对某些分类任务有所帮助。

Truncated SVD Features
TF-IDF 和 n 元语法频率均会导致表征向量的维度较高。为防止出现这样的结果, 截断奇异值分解 通常用来将向量化数组分解为较低维度。
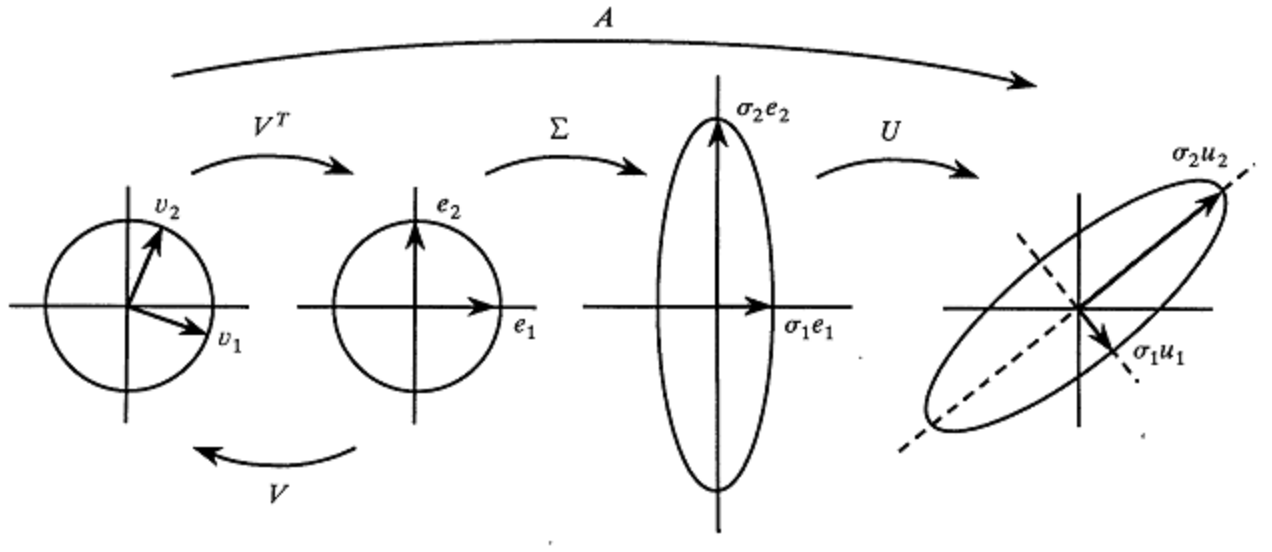
Linear Models for TF-IDF Vectors
Driverless AI NLP 插件还提供了线性模型。这些模型会捕捉对实现高准确率的过程至关重要并被用作基本 DAI 模型中特征的线性相关性。
Word Embeddings
词嵌入是用于形容一组文本特征工程技术的术语,其中,词汇表中的单词或短语被映射到实数向量。采取此种表示形式是为了将具有相似含义的词放置得比较近或使其彼此等距放置。例如,在此种向量表示形式中,单词 “king” 与单词 “queen” 紧密相关。
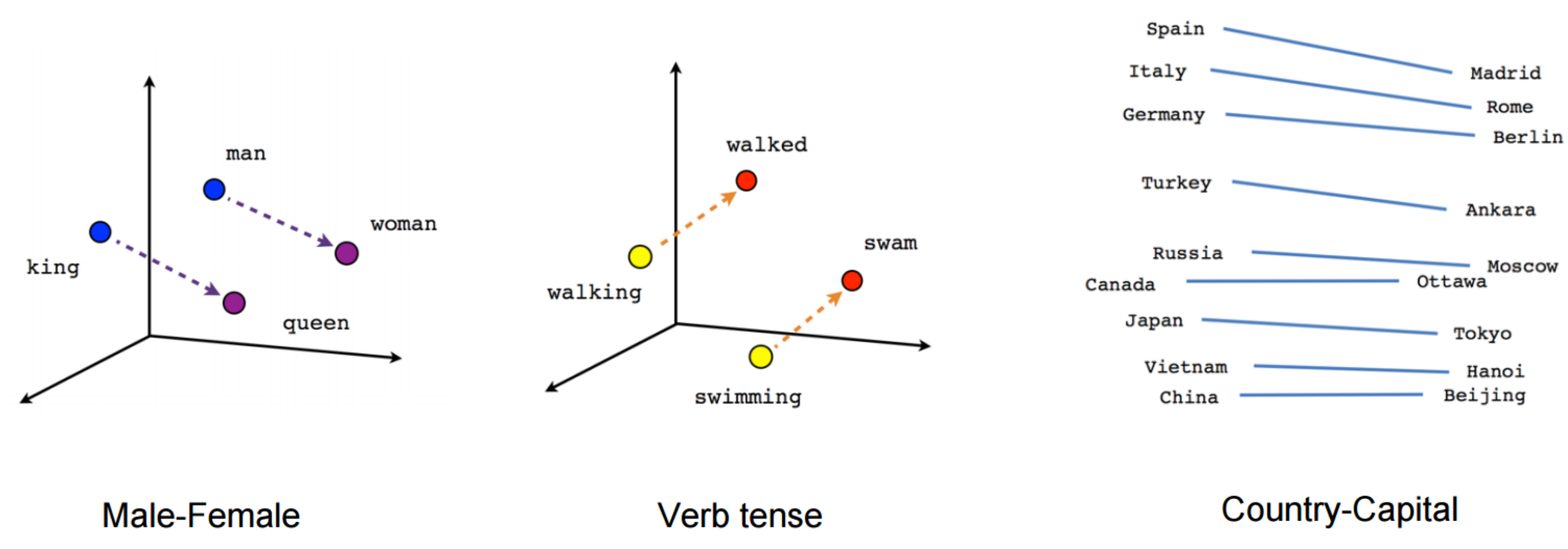
TF-IDF 和基于频率的模型表示计数和重要的词信息,但是它们缺乏这些单词的语义语境。因此,可利用词嵌入技术来弥补这种语义信息的缺乏。
CNN Models for Word Embedding
尽管卷积神经网络 (CNN) 模型主要用于图像级别的机器学习任务,但与 RNN 模型相比,在将文本表示为信息的 CNN 用例已被证明相当有效且更迅速。在 Driverless AI 中,我们将词嵌入作为输入变量传递给 CNN 模型,而 CNN 模型会返回可被用作新特征集、经过交叉验证的预测结果。
Bi-directional GRU Models for Word Embedding
循环神经网络,与长短期记忆单元 (LSTM) 和门控循环单元 (GRU) 一样,均是用于 NLP 问题的先进算法。在 Driverless AI 中,我们为之前的词步骤和之后的步骤实现双向 GRU 特征,以预测当前状态。例如,在句子 “John is walking on the golf course” 中,单向模型将表示基于 “John is walking on” 而表示 “golf” 的状态,但是不会表示 “course”。使用双向模型,则表示还将考虑后面的单词,使模型具有更强的预测性能。
简单地说,双向 GRU 模型将两个独立的 RNN 模型合并成单个模型。GRU 架构与 LSTM 架构类似,可提供较高的速度和准确率。与 CNN 模型一样,我们将词嵌入作为输入变量传递给 GRU 模型,而 GRU 模型会返回可被用作新特征集、经过交叉验证的预测结果。
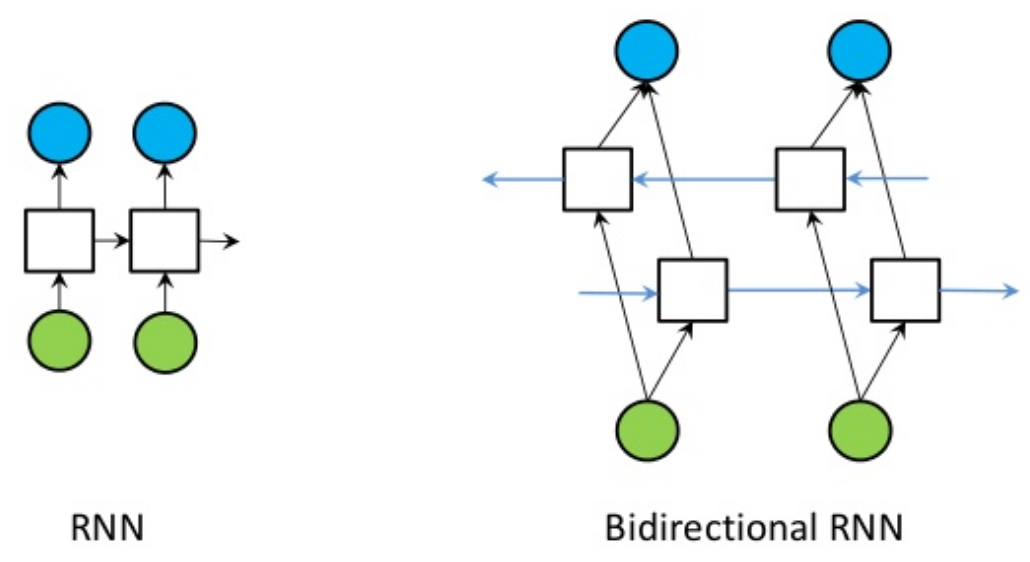
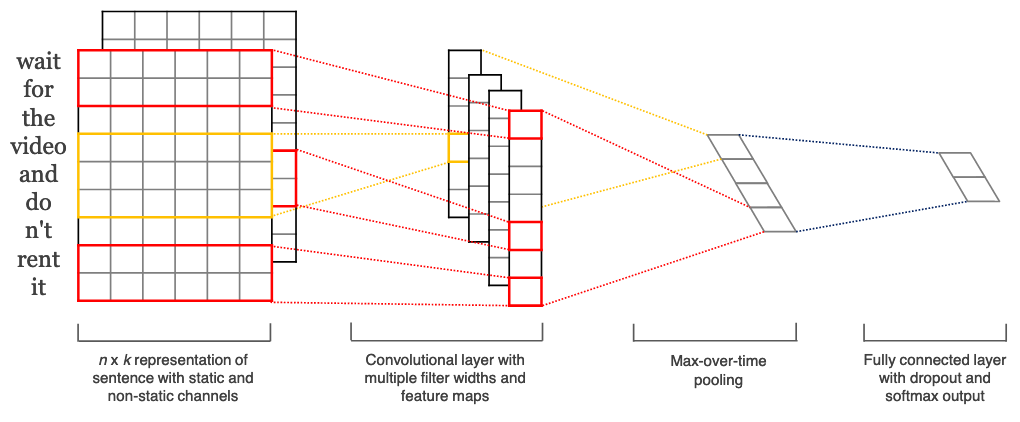
CNN Models for Character Embedding
对于像日语和汉语这样字符起主要作用的语言,可以将字符级别的嵌入用作 NLP 插件。
在字符嵌入中,每个字符均以向量的形式表示,而不是以词的形式表示。Driverless AI 将字符级别的嵌入作为 CNN 模型的输入变量,然后提取类概率作为下游模型的特征。
下图展示了此 NLP 插件创建的整体特征集:
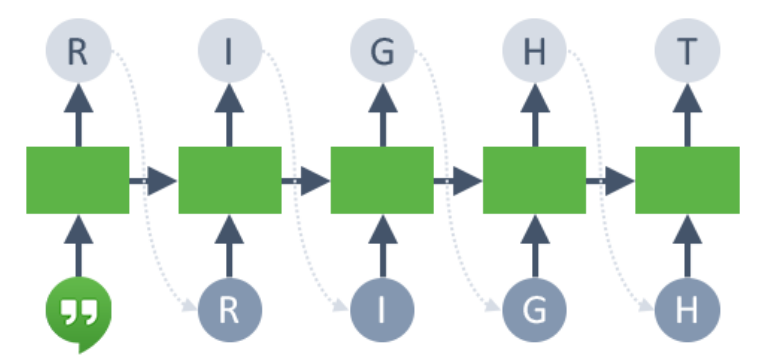
BERT/DistilBERT Models for Feature Engineering
基于转换器的语言模型(如 BERT)是最先进的 NLP 模型,可用于各种 NLP 任务。这些模型通过使用注意机制来捕捉词间的上下文关系。不同于按顺序读取文本的方向模型,基于转换器的模型一次性读取整个文本序列,允许其根据其周围的所有词学习词的上下文语境。与早期嵌入方法相比,这些模型所获得的嵌入效果有所改进。
BERT 和 DistilBERT 模型可用于为任何文本列生成嵌入。这些预训练的模型用于获得文本嵌入,而后使用线性/逻辑回归,以生成可在之后用于 Driverless AI 中任何下游模型的特征。请参阅专家设置主题中的 NLP 设置,以进一步了解如何为特征工程启用这些模型。我们建议使用 GPU 来利用这些模型的能力并加速特征工程的进程。
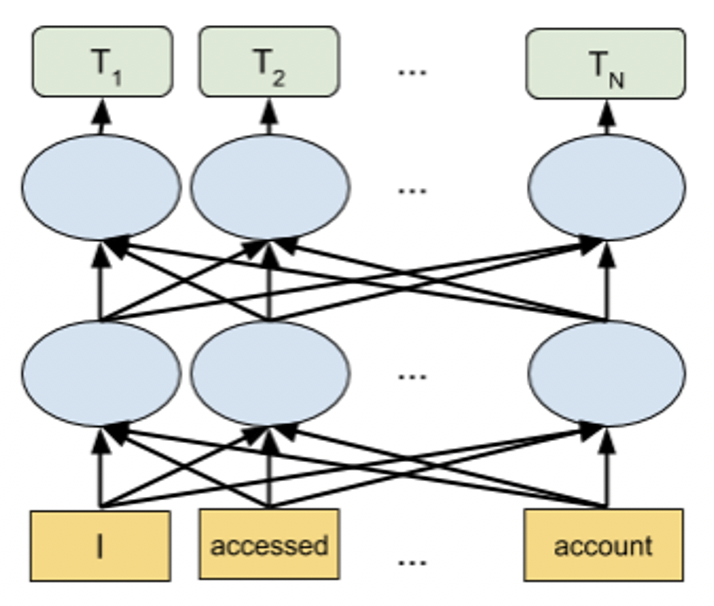
PyTorch Transformer Architecture Models (eg. BERT) as Modeling Algorithms
从 Driverless AI 1.9 版开始,支持将下图所示基于转换器的架构作为 Driverless AI 的模型。
BERT 模型支持多种语言。DistilBERT 是 BERT 的精华版,与 BERT 相比,DistilBERT 的参数更少(少 40%),速度更快(加速 60%),同时保留了 95% 的 BERT 级别性能。如果训练时间和模型大小很重要,DistilBERT 模型将十分有用。请参阅专家设置主题的 NLP 设置,进一步了解如何将这些模型作为建模算法启用。我们建议使用 GPU 来利用这些模型的能力并加速模型训练时间。
除了这些技术,Driverless AI 还支持使用 custom NLP recipes,例如 PyTorch 或 Flair。
NLP 特征命名约定¶
NLP 特征命名约定有助于了解已创建特征的类型。
特征名称使用的语法如下:
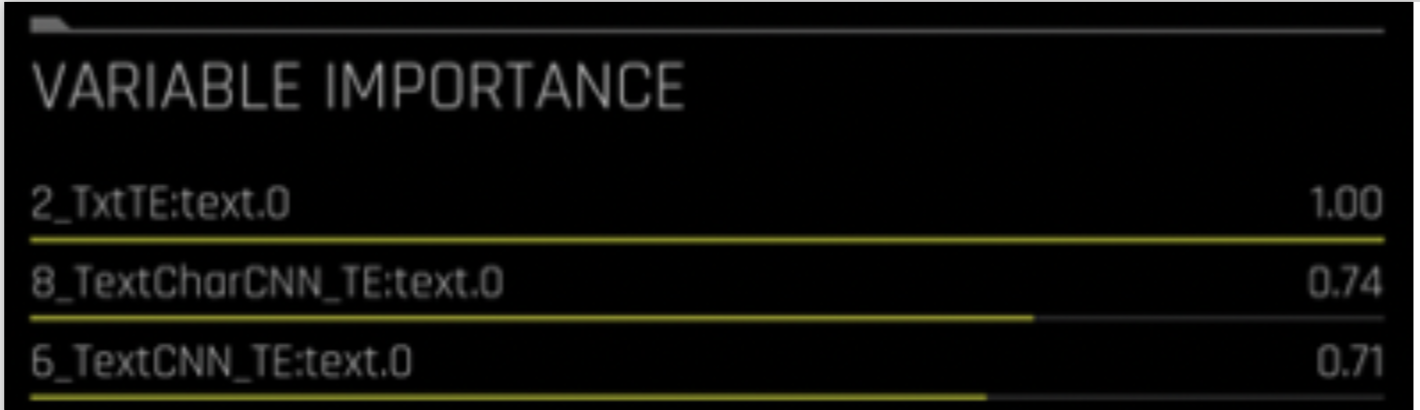
[FEAT TYPE]:[COL].[TARGET_CLASS]
[FEAT TYPE] 表示以下之一:
Txt – n 元语法频率/TF-IDF + 截断奇异值分解
TxtTE – n 元语法频率/TF-IDF + 线性模型
TextCNN_TE – 词嵌入 + CNN 模型
TextBiGRU_TE – 词嵌入 + 双向 GRU 模型
TextCharCNN_TE – 字符嵌入 + CNN 模型
[COL] 表示文本列的名称。
[TARGET_CLASS] 表示要进行模型预测的目标类。
例如,TxtTE:text.0 相当于使用 n 元语法频率/TF-IDF,然后使用线性模型,来对文本列 “text” 进行 0 类预测。
NLP 解释器¶
以下是可用 NLP 解释器列表。更多信息,请参阅 解释器插件 和 NLP 绘图.
NLP LOCO 解释器 :NLP LOCO 图会从记录中所有文本特征中移除特定标记,并预测不包括此标记时的局部重要性,以此将留一协变量输出 (LOCO) 类型的方法应用于 NLP 模型。当尝试确定对文本特征的特定更改会如何更改模型所作出的预测时,所得到的评分和原始评分(包括标记)之间的差异非常有用。
NLP 部分依赖性图解释器 :NLP 部分依赖性(黄色)描述了 Driverless AI 模型在输入文本标记保留在相应文本中和不包含在相应文本以及 +/-1 标准偏差范围内时的平均预测行为。ICE(灰色)显示单行数据在输入文本标记保留在相应文本中和不包含在相应文本中时的预测行为。文本标记是从 TF-IDF 生成的。
NLP 记号赋予器解释器 :NLP 记号赋予器图显示语料库(大型结构化文本集)中每个标记的全局和局部重要性值。此语料库在标记化过程之前根据 Driverless AI 模型所使用的文本特征自动生成。局部重要性值通过将词频-逆文档频率 (TF-IDF) 用作每行中每个标记的加权因子计算得出。TF-IDF 随标记在给定文档中出现的次数成比例增加,并被语料库中包含此标记的文档数所抵消。
NLP 向量化器 + 线性模型 (VLM) 文本特征重要性解释器 :NLP 向量化器 + 线性模型 (VLM) 文本特征重要性将单个单词的 TF-IDF 用作相关文本列中的特征,使用这些特征构建一个线性模型(目前为 GLM),然后将其拟合成 Driverless AI 模型的预测类(二元分类)或连续预测(回归)。线性模型的系数给出单词的重要性。注意,此解释器默认按字母顺序使用第一个文本列。
NLP 专家设置¶
Driverless AI 中,有很多适用于 NLP 的可配置设置。更多信息,请参阅专家设置主题中的 NLP 设置 。另请参阅实验设置下 pipeline building recipes 中的 nlp 模型 和 nlp 转换器 。

NLP 示例:情感分析¶
下节提供一个 NLP 示例。此信息基于博文 Automatic Feature Engineering for Text Analytics 使用 Python 客户端的类似示例可在 Python 客户端 中找到。
本示例使用了一个推文情感分析的经典示例,此经典示例使用了 美国航空公司情绪分析数据集 . 请注意,每条推文所表示的情绪均已预先做好标记,而我们的模型将用于标记新推文。我们可以在 Driverless AI 中使用随机拆分将数据集拆分为训练数据和测试数据 (80/20)。在本演示中,我们将使用 ‘text’ 列中的推文和 ‘airline_sentiment’ 列中的情绪(积极、消极或中性)。以下是数据集中的一些样本:

在以表格格式准备好数据集后,我们便可着手使用 Driverless AI。类似于 Driverless AI 设置中的其他问题,我们需要选择数据集,然后指定目标列 (‘airline_sentiment’)。
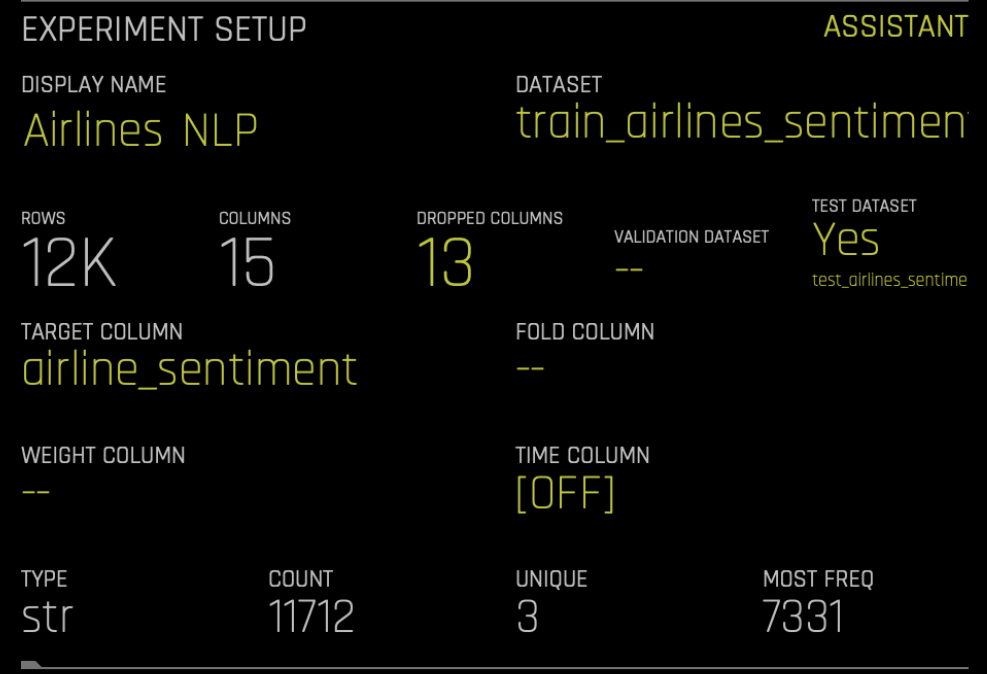
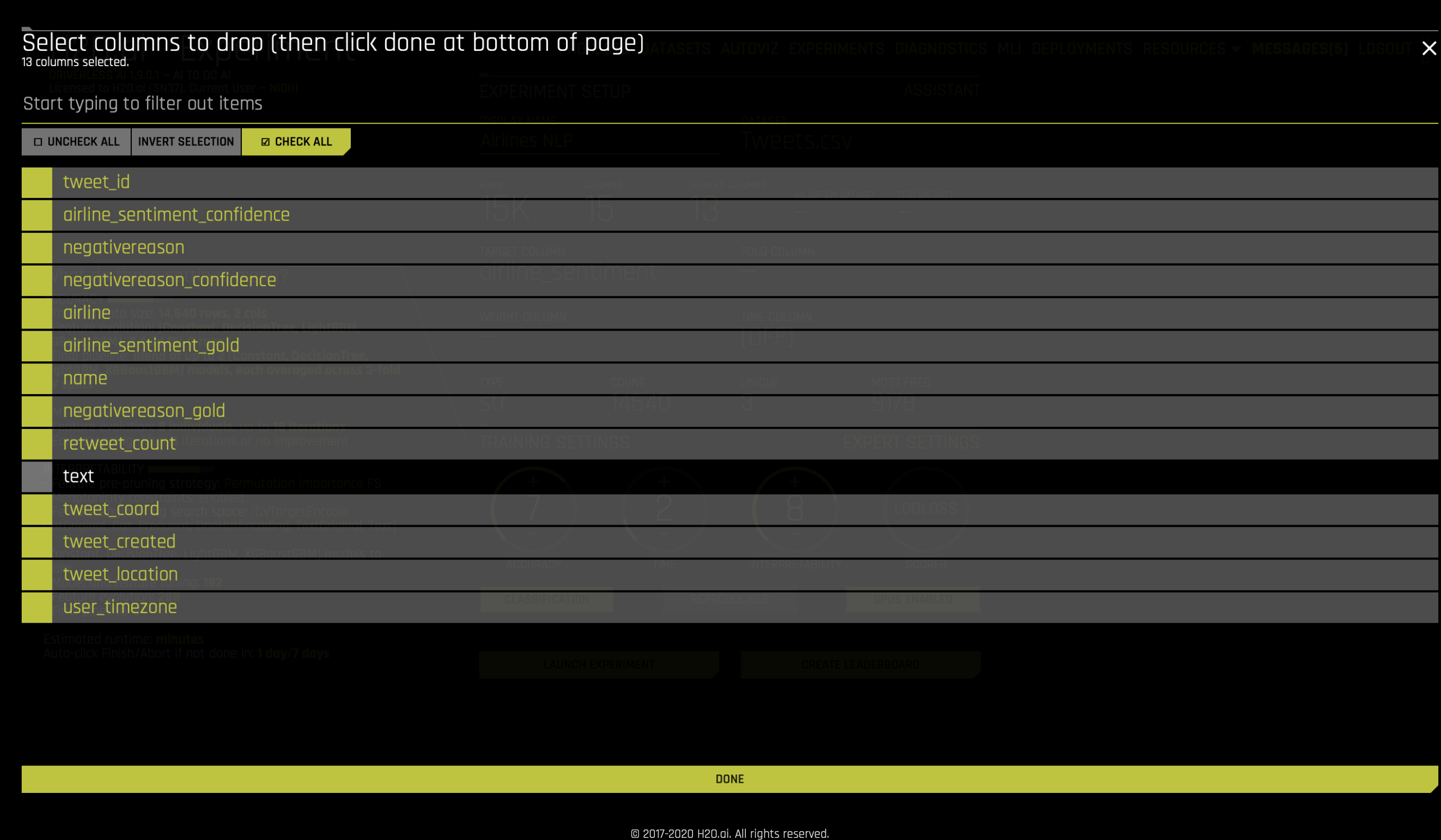
因为我们不想使用数据集中的任何其他列,所以需要点击 删除列 ,然后删除除 文本 以外的所有列,如下所示:
接下来,我们将打开 TensorFlow NLP 插件。我们可以前往 专家设置、 NLP ,并打开以下选项: CNN TensorFlow 模型 、 BiGRU TensorFlow 模型 、 基于字符的 TensorFlow 模型 或 预训练的 PyTorch NLP 模型 。
此时,我们即已准备好启动实验。文本特征将在特征工程进程中自动生成并进行评估。请注意,某些特征(如 TextCNN)依赖于 TensorFlow 模型。我们建议使用 GPU 来利用 TensorFlow 或 PyTorch 转换器模型的能力并加速特征工程的进程。
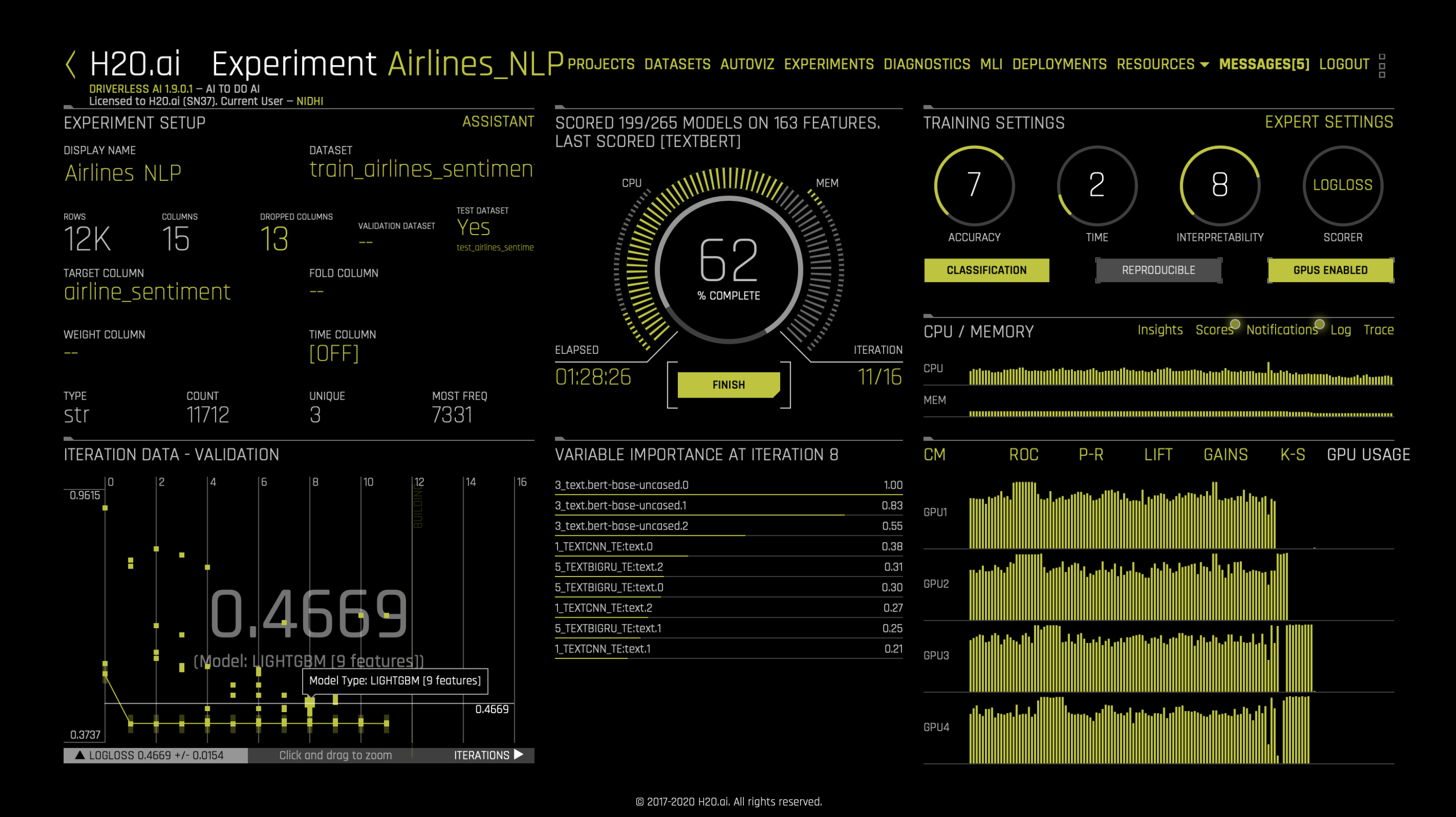
实验完成后,用户可以进行新的预测并下载评分管道,就如同任何其他 Driverless AI 实验一样。
资源:
fastText: https://fasttext.cc/
将 NLP 模型部署到生产¶
TensorFlow 和 BERT 模型(用于特征工程和建模)支持 Python scoring 和 C++ MOJO scoring 。启用 tensorflow_nlp_have_gpus_in_production parameter in config.toml 以在 GPU 上部署模型。