Driverless AI 中的时间序列¶
时间序列预测是商业分析中最常见和重要的任务之一,在现实世界中有广泛的应用,如销量、天气、股市和能源需求预测等。H2O 认为自动化能帮助我们的用户及时地交付商业价值。因此,我们在 Driverless AI 中整合了先进的时间序列分析和 Kaggle 大师的时间序列插件。
使得自动化成为可能的关键功能/插件包括:
时间分组(如不同门店和部门)的自动处理
可靠的时间序列验证
考虑间隔和预测期
仅使用过去的信息(即不会泄露数据)
专用于时间序列的特征工程插件
日期特征,如星期几、几月几号等
自回归功能,如最优滞后和滞后-特征交互
不同类型的指数加权移动平均
聚合了过去信息(不同时间分组和时间间隔)
目标转换和差异化
与现有特征工程功能(插件和优化)集成
基于滚动窗口的预测,用于可采用测试时增强或调整的时间序列实验
自动生成管道(请参见 “From Kaggle Grand Masters’ Recipes to Production Ready in a Few Clicks” 博文 .)
了解时间序列¶
以下将深入介绍 Driverless AI 中的时间序列。关于在运行时间序列实验时的最佳实践概述,请参见 时间序列最佳实践.
建模方法¶
Driverless AI 使用 GBM、GLM 和神经网络,侧重特定于时间序列的特征工程。特征工程包括:
自回归元件:创建滞后变量
与滞后变量相关的聚合特征:移动平均、指数平滑描述性统计、相关性
特定于日期的特征:周数、星期、月、年
目标转换:积分/微分、单变量变换(如对数、平方根)。
此方法与 AutoDL 特征结合,是遗传算法的一部分。具体的选择仍取决于验证准确度。换句话说,就是应用相同的转换/基因;而且,可通过时间序列实施新的转换。某些转换(如目标编码)已停用。
在运行时间序列实验时,Driverless AI 可通过及时将验证窗口回滚(和使用越来越少的训练数据)构建多个模型。
用户可配置的选项¶
间隔¶
对时间序列预测问题进行正确建模的指导原则是在模型训练数据集中使用历史数据,这样就能模拟评分时的数据/信息环境(即部署的预测)。具体来讲,您要对训练集进行分割,以处理:1) 在进行预测时可供模型使用的信息和 2) 或模型应加以优化以进行预测的单位数量。
对于特定的训练数据集,间隔和预测期是决定了如何将训练数据集拆分为训练样本和验证样本的参数。
间隔 是从训练集结束到测试集开始所间隔的时间仓数量(与时间相关)。例如:
假设训练期间在 2020 年 1 月 1 日、2020 年 1 月 2 日、2020 年 1 月 3 日和 2020 年 1 月 4 日产生了每日数据,则用于训练的总天数就为 4 天。
另外,测试数据的起始日期为 2020 年 1 月 6 日。测试数据中只有 1 天。
其前一日(2020 年 1 月 5 日)不属于训练数据,不能用于训练(因为这一天中的信息在评分时可能不可用)。此日期也不能被用来衍生用于测试数据的信息(如历史滞后)。
这里的时间仓(或时间单位)为 1 天,是分隔数据中的不同样本/行的时间间隔。
概括地说,有 4 种用于训练数据的时间仓/单位,1 种用于测试数据和间隔的时间仓/单位。
以下公式可用于估算从训练数据结束到测试数据开始的间隔。
间隔 = min(time bin test) - max(time bin train) - 1.
在此例中,min(time bin test) 为 6(或 2020 年 1 月 6 日)。此值为测试数据中最早的一天(也是唯一的一天)。
max(time bin train) 为 4(或 2020 年 1 月 4 日)。此值为训练数据中最晚的一天(或最近的一天)。
因此,间隔为 1 个时间仓(或在此例中为 1 天),因为`间隔 = 6 - 4 - 1`或`间隔 = 1`.
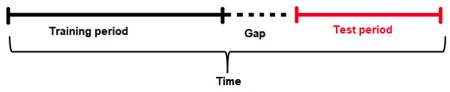
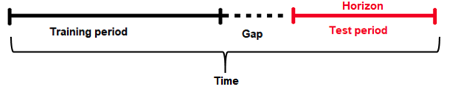
预测期¶
在应用模型时经常无法获取最新数据(或频繁更新数据表的代价较大),因此需在考虑“未来间隔”的情况下构建一些模型。例如,如果更新一个特定数据表需花费一周的时间,则理想情况下您需要使用“今天”的数据提前 7 天预测;因此,建议采用 6 天的间隔。在不指定间隔的情况下使用原始数据提前 7 天预测是不现实的(并且也不可能发生,因为在此示例中数据每周更新一次)。类似地,如果您想提前更长时间预测,可以使用“间隔”。例如,如果您想知道在未来 7 天会发生什么事件,则将间隔设置为 6 天。
预测期 (或预测长度)为测试数据跨越的时间段(例如,一天、一周等)。换句话说,预测期是模型可以预测的未来时间段(或者是或模型应加以优化以进行预测的单位数量)。在特征选择和工程以及模型选择期间,要使用预测期。请注意,预测期可能不等于预测次数。实际预测次数由测试数据集决定。
数据更新的周期性可能要求模型预测考虑未来比较长的时间。在理想情况中,可非常快地更新数据,因此总是能获取到最新数据来进行预测。在这种场景中,不要求模型能预测未来相当长时间内的情况,而是专注于最大限度提高短期预测能力。但是,情况并不总是这样,并且模型需要能对未来一长段时间进行预测,因为在数据更新后的每一天,进行预测的代价都非常高。
另外,未来每个数据点都不相同。例如,通过今日的数据预测明天的情况比通过今日的数据预测后天的情况要容易。因此,指定预测期有利于构建能够优化这些未来时间间隔的预测准确度的模型。
预测间隔¶
对于回归问题,启用 prediction_intervals 专家设置,以让 Driverless AI 在预测帧内额外提供两列:y.lower 和 y.upper。在某一概率下,用于预测样本的真目标值预计有一定的概率会在 [y.lower, y.upper] 区间内。可通过 prediction_intervals_alpha 专家设置指定此置信度的默认值 (0.9)。
Driverless AI 利用保持预测通过以经验为主的方式确定间隔(Williams, W.H. and Goodman, M.L. “A Simple Method for the Construction of Empirical Confidence Limits for Economic Forecasts.” Journal of the American Statistical Association, 66, 752-754. 1971)。此方法对底层模型或误差分布不做任何假设,已被证明性能要优于很多其他方法(Lee, Yun Shin and Scholtes, Stefan. “Empirical prediction intervals revisited.” International Journal of Forecasting, 30, 217-234. 2014)。
请注意:
此特征适用于回归任务(i.i.d. 和时间序列)。
此特征适用于所有类型的模型。
此特征目前不支持使用 MOJO。
需针对每个个体时间分组计算预测间隔。
time_period_in_seconds¶
请注意:time_period_in_seconds 只在 Python 客户端和 R 客户端中可用。不能在 UI 上指定以秒为单位的时间段。
在 Driverless AI 中,预测期(即 num_prediction_periods)需要被分割成长度未知的时间段。要解决这一问题,您可以在运行 start_experiment_sync``(Python 客户端)或 ``train (R 客户端)时使用可选的 time_period_in_seconds 参数。此参数用于指定以实时单位计算的预测期(同样适用于间隔)。如果没有指定此参数,则 Driverless AI 会自动检测实验中的时间段长度,预测期值会等于此时间段的长度,即如果您确定数据的时间段为 1 周,您可以设置 num_prediction_periods=14 ,否则模型可能无法正常工作。
分组¶
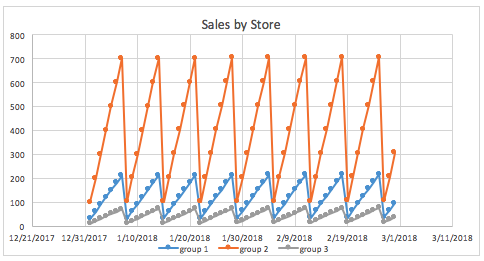
分组是数据中的分类列,能显著帮助预测时间序列问题中的目标变量。例如,用户可能需要利用给定的门店和产品信息来预测销量。能够发现门店和产品的组合会产生差异非常大的销量预测结果对于目标变量的预测非常关键,因为相对于小门店和/或不受欢迎的产品而言,大门店或受欢迎的产品会带来更高的销量。
例如,如果我们不知道数据中有可用的门店,并且我们要尝试发现销量随时间的分布情况(以及所有门店的汇总),则可能出现以下现象:
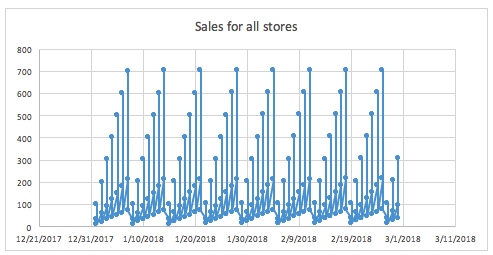
按门店分组的相同图表能更清晰地显示不同门店的销量情况。
滞后¶
所生成的主要时间序列特征是滞后特征,即为变量的过去值。在具有时间戳 \(t\) 的给定样本中,考虑了在过去某一时差 \(T\) (滞后)的特征。例如,如果今天的销量为 300,昨天的销量为 250,则销量方面一天的滞后就为 250。可对任何特征和目标创建滞后项。
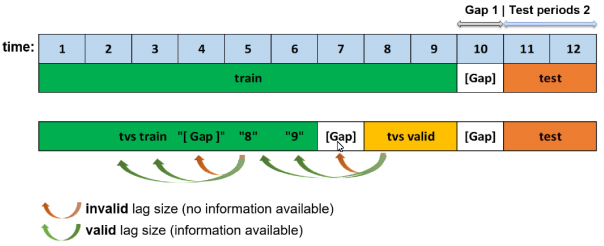
如前所述,训练数据集将进行适当的拆分,以使验证数据样本量与测试数据集样本量相等。如果要测定有效的滞后项,我们必须考虑在对测试数据集评估我们的模型时会发生什么情况。本质上,最小滞后阶数必须大于间隔大小。
除了最小可用滞后项以外,Driverless AI 还会尝试发现基于自相关的预测性滞后阶数。
“滞后”变量在时间序列中非常重要,因为知道在过去的不同时间段内发生了什么情况会极大地方便对未来的预测。请参考以下示例,以了解 1 天和 2 天的滞后项:
日期 |
销量 |
Lag1 |
Lag2 |
|---|---|---|---|
2020 年 1 月 1 日 |
100 |
- |
- |
2020 年 1 月 2 日 |
150 |
100 |
- |
2020 年 1 月 3 日 |
160 |
150 |
100 |
2020 年 1 月 4 日 |
200 |
160 |
150 |
2020 年 1 月 5 日 |
210 |
200 |
160 |
2020 年 1 月 6 日 |
150 |
210 |
200 |
2020 年 1 月 7 日 |
160 |
150 |
210 |
2020 年 1 月 8 日 |
120 |
160 |
150 |
2020 年 1 月 9 日 |
80 |
120 |
160 |
2020 年 1 月 10 日 |
70 |
80 |
120 |
Driverless AI 确定的设置¶
窗口/移动平均¶
利用以上滞后项表格,可以得出移动平均值 2 就是 Lag1 和 Lag2 的平均数:
日期 |
销量 |
Lag1 |
Lag2 |
MA2 |
|---|---|---|---|---|
2020 年 1 月 1 日 |
100 |
- |
- |
- |
2020 年 1 月 2 日 |
150 |
100 |
- |
- |
2020 年 1 月 3 日 |
160 |
150 |
100 |
125 |
2020 年 1 月 4 日 |
200 |
160 |
150 |
155 |
2020 年 1 月 5 日 |
210 |
200 |
160 |
180 |
2020 年 1 月 6 日 |
150 |
210 |
200 |
205 |
2020 年 1 月 7 日 |
160 |
150 |
210 |
180 |
2020 年 1 月 8 日 |
120 |
160 |
150 |
155 |
2020 年 1 月 9 日 |
80 |
120 |
160 |
140 |
2020 年 1 月 10 日 |
70 |
80 |
120 |
100 |
计算多个(而非一个)滞后项的平均数可以提高目标变量定义的稳定性。其可能包括各种滞后值,例如滞后 [1-30] 或滞后 [20-40] 或滞后 [7-70 by 7]。
指数加权¶
指数加权是一种加权移动平均,其中更近的值在权重上要大于之前的值。该权重在 alpha (a)(超)参数 (0,1)(一般在 [0.9 - 0.99] 范围内)的基础上随着时间成指数地减小。例如:
指数权重 = a**(时间)
如果 1 天前的销量 = 3.0 并且 2 天前的销量 =4.5 并且 a=0.95:
指数平滑 = 3.0*(0.95**1) + 4.5*(0.95**2) / ((0.95**1) + (0.95**2)) ≈3.73
基于滚动窗口的预测¶
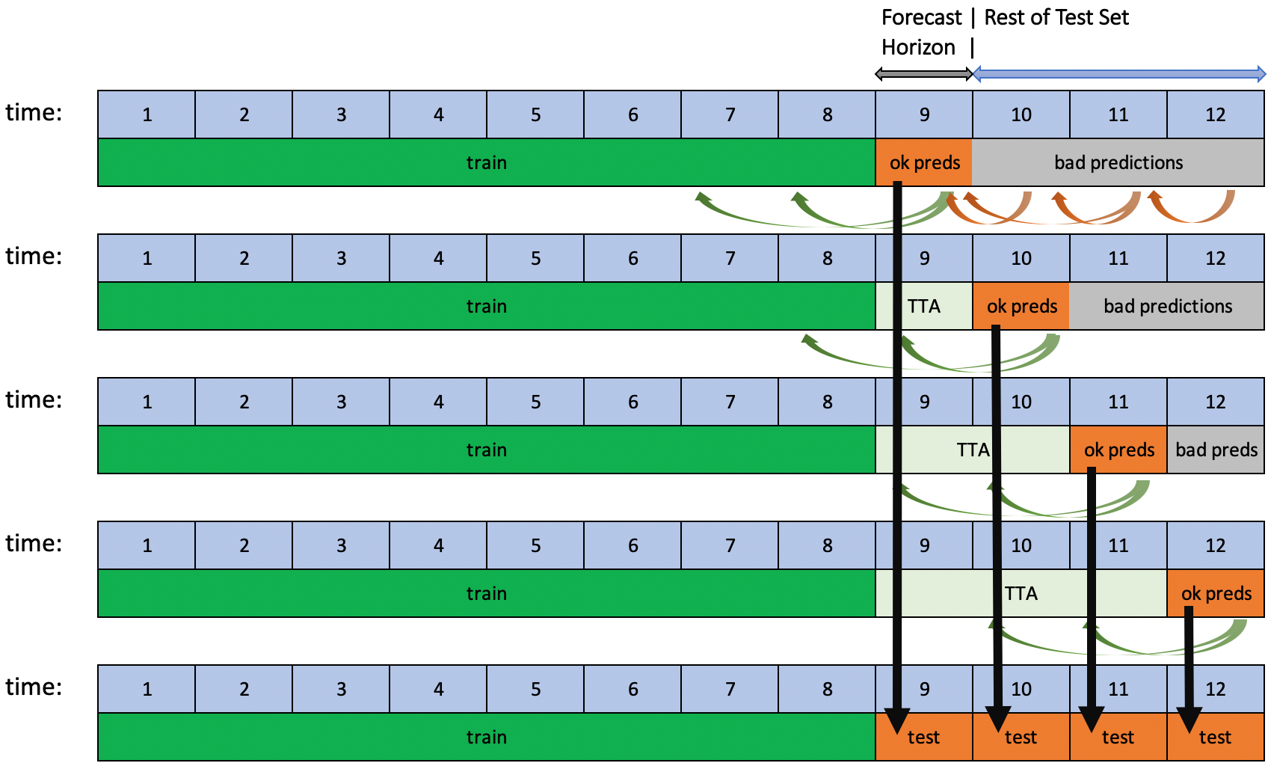
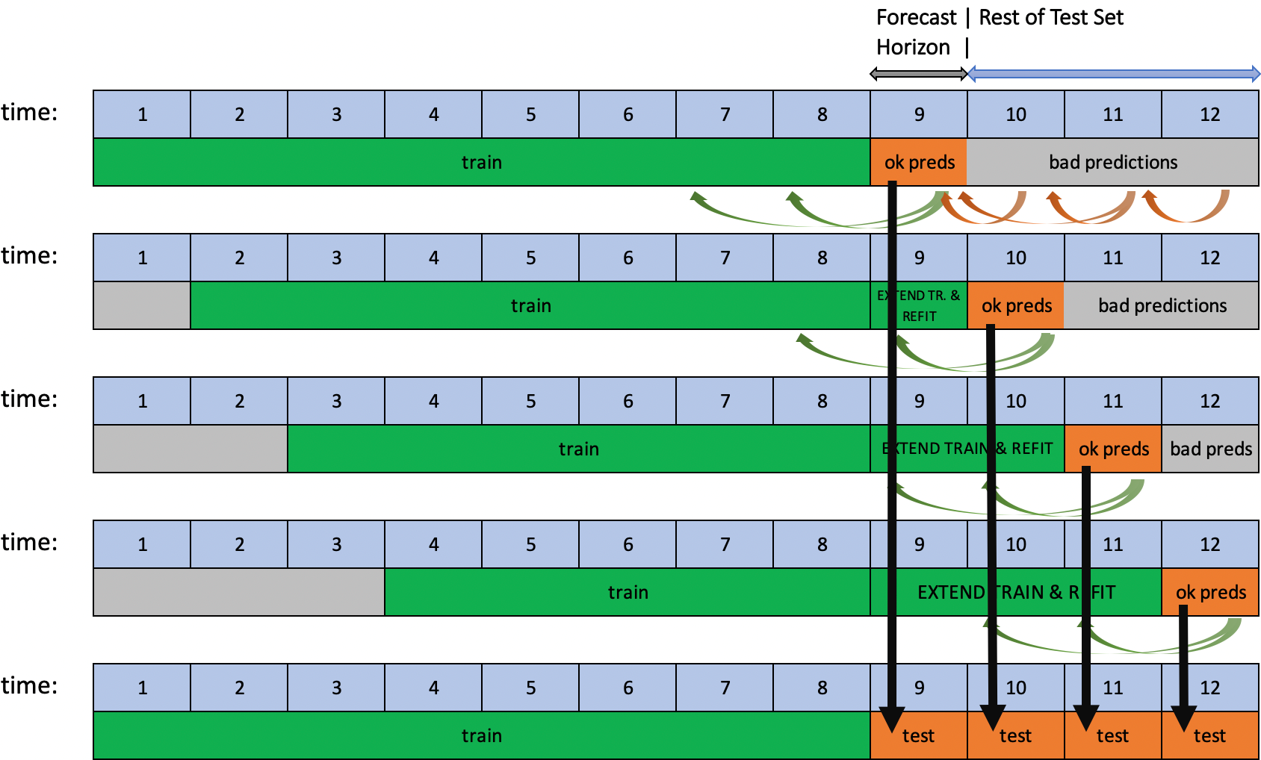
Driverless AI 支持通过两个选项: 测试时增强 (TTA) 或调整对时间序列实验进行基于滚动窗口的预测。
这两个选项都可用来评估用于预测单个预测期以及连续多个预测期的管道性能。TTA 会模拟一个进程,在该进程中,模型不变,但会使用可用的最新数据来刷新特征。调整则会模拟新数据可用之后的对整个管道(包括模型)进行调整的过程。
当测试集的时间跨度超过预测期时,如果测试集的目标值已知,就会自动执行此过程。如果用户在实验结束后对符合这些条件的测试集进行评分,会应用带有 TTA 的滚动预测。另一方面,调整仅适用于在实验过程中提供的测试集。
TTA 是默认选项,可通过 创建滚动测试集预测的方法 专家设置来更改此选项。
时间序列约束条件¶
数据集大小¶
通常,预测期(预测时长):math:H 等于测试数据 \(N_{TEST}\))中的时段数。您要获得足够的训练数据时间段 \(N_{TRAIN}\))。这允许在为特征工程保留足够历史数据的同时,将训练数据集拆分为具有与测试数据集相同的时段数的验证集。
时间序列用例:销量预测¶
以下为 Walmart competition on Kaggle . 期间的典型销量预测示例。为了将销量预测处理为机器学习问题,我们编制了历史销量数据和附加属性,如下所示:
原始数据
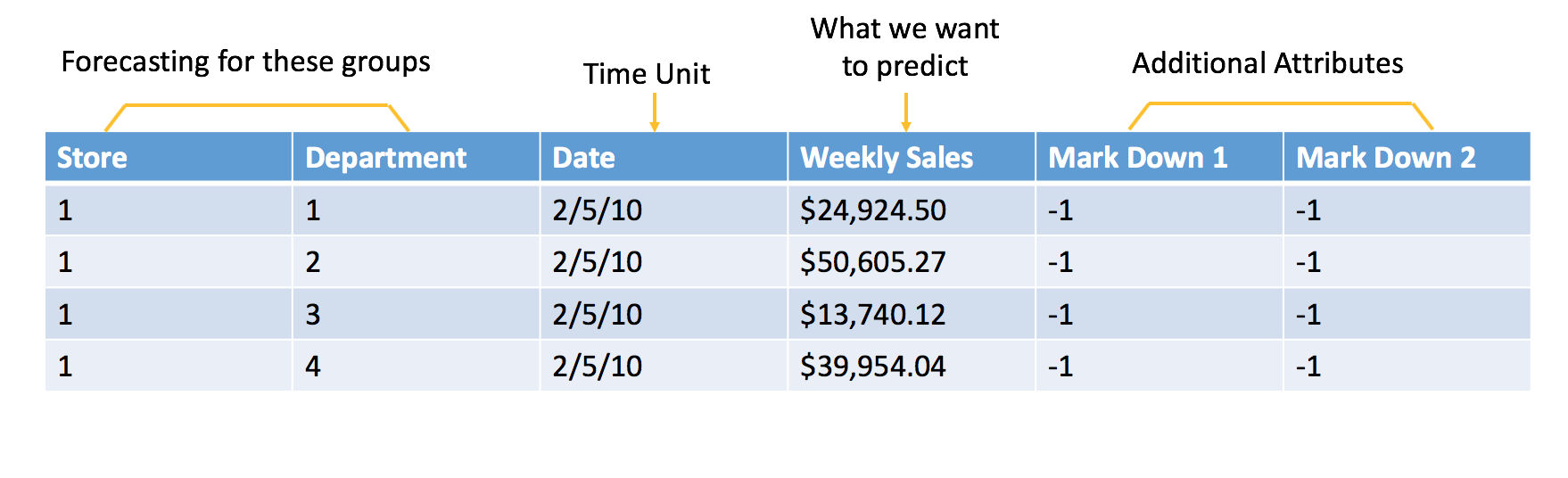
为机器学习编制的数据
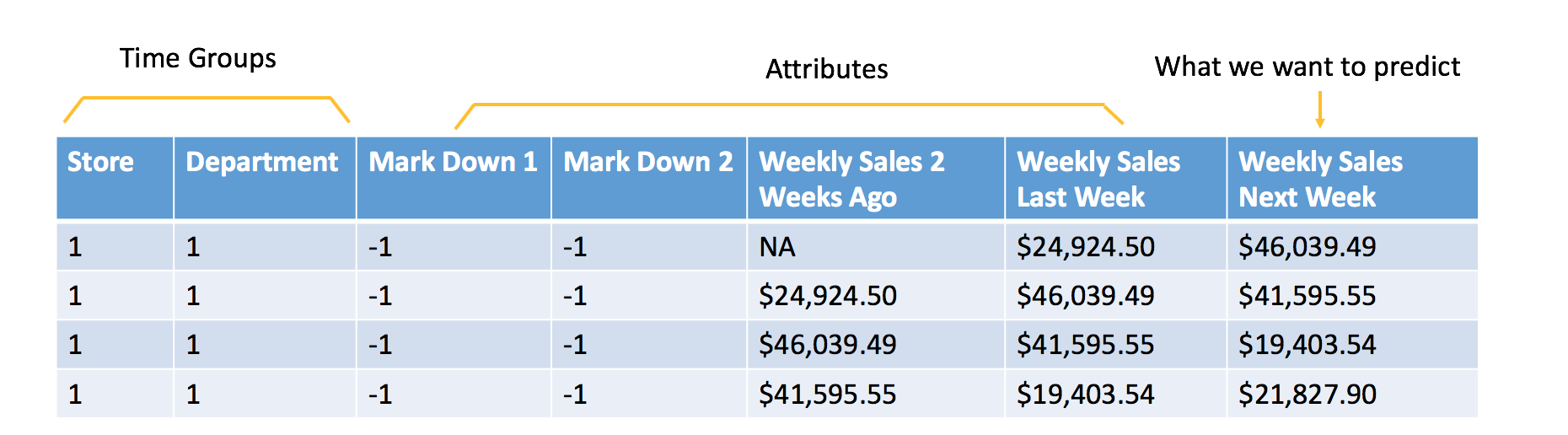
附加属性是我们在评分之时将知道的属性。在此示例中,目标是要预测下一周的销量。因此,必须提前至少一周知道数据中包含的所有属性。在此例中,您可以假设您将知道门店和部门是否会进行降价促销。不会使用本周温度等特征,因为在评分之时没有该信息。
在您以表格形式准备数据后(见上图中的原始数据),Driverless AI 能对这些数据进行编制,以用于机器学习,并对剩下的数据进行清理。如果这是您的第一次会话,Driverless AI 助手会引导您完成整个过程。
与之前的 Driverless AI 示例类似,您需要选择用于训练/测试的数据集,并定义目标。对于时间序列,您需要(通过选择 AUTO 或手动选择日期列)定义时间列。如果必须进行加权评分(例如“Walmart Kaggle competition”),您可以针对不同样本选择具有特定权重的列。

如果您更喜欢自动处理时间分组,可以将时间分组列的设置保留为 AUTO,或定义特定的时间分组。您也可以指定在预测之时不可用的列(更多信息,请参见 关于在预测之时不可用列的更多信息)、预测期(以周为单位)以及训练与测试期的间隔时间(以周为单位)。
在实验结束后,您可以立即进行预测,并下载评分管道,这一点和任何其他 Driverless AI 实验一样。
使用 Driverless AI 时间序列模型进行预测¶
在设置实验的预测期时,您会将要求此模型预测的日期告诉 Driverless AI 实验。在沃尔玛销量预测示例中,我们将 Driverless AI 预测期设置为 1(即未来的 1 周)。这意味着 Driverless AI 期望使用此模型来预测训练结束后的 1 周。由于训练数据在 2020 年 10 月 26 日结束,应使用此模型对 2020 年 11 月 2 日所在的那一周进行评分。
在 2020 年 11 月 2 日所在的那一周过后,用户应该做些什么?
有两个选项:
选项 1:在预测期结束后立即触发 Driverless AI 实验的训练。每周都需重新训练 Driverless AI 实验。
选项 2:使用 测试时增强 (TTA) 来更新历史特征,以便我们可以使用相同的模型对预测期以外时间进行预测。
测试时增强 (TTA) 是指模型保持不变但使用最新数据刷新特征的过程。在我们的沃尔玛销量预测示例中,一个可能非常重要的特征是上周的周销量。在预测期之外,我们的模型就不再知道上一周的周销量。如果提供了新的数据,通过执行 TTA,Driverless AI 会自动生成这些历史特征。
在选项 1 中,我们将使用最新的数据每周启动一个新的 Driverless AI 实验,并使用生成的模型对下一周进行预测。在选项 2 中,我们会通过使用 TTA 继续在预测期以外使用同一个 Driverless AI 实验。
两个选项都各有优劣。通过使用最新的数据重新训练实验,Driverless AI 将能够更改所使用的特征、选择不同的算法和/或选择不同的参数,从而改进模型。由于数据会随时间变化,因此,Driverless AI 可能会发现用于此用例的最佳算法已经改变。
在每个预测期结束后重新训练实验或使用 TTA 可能各自具有明显的优势。请参阅 此示例 以了解如何使用评分管道预测未来数据而非使用 Driverless AI 服务器上的预测端点。
使用 TTA 继续在较长的时间段内使用相同的实验意味着不再需要继续重复执行模型审核过程。但是,模型可能会变得过时。
以下表格列出了多种评分方法及其是否支持 TTA:
评分方法 |
是否支持测试时增强 |
|---|---|
Driverless AI 评分器 |
支持 |
Python 评分管道 |
支持 |
MOJO 评分管道 |
不支持 |
对于不同的用例,在每个预测期结束后重新训练实验或使用 TTA 可能各自具有明显的优势。以下 notebook 展示了如何执行这两种方法和比较它们的性能: Time Series Model Rolling Window .
请注意:
评分器无法调整或重新训练模型。
若要指定用于创建滚动测试集预测的方法,可使用 this expert setting. 请注意,通过此专家设置执行的调整仅适用于用户在实验过程中提供的测试集。最终的评分管道总是会使用 TTA。
触发测试时增强¶
若要执行测试时增强,需创建您的预测数据,以包含在训练数据结束之后一直到您要预测的日期之前产生的任何数据。您希望 Driverless AI 预测的日期应具有缺失值 (NA),这些就是目标列。您必须填充与剩余日期相关的目标值。
以下是对 2020 年 11 月 23 日和 2020 年 11 月 30 日进行预测的示例,在此示例中,将剩余日期用于 TTA:
日期 |
门店 |
部门 |
减价 1 |
减价 2 |
周销量 |
|---|---|---|---|---|---|
2020 年 11 月 2 日 |
1 |
1 |
-1 |
-1 |
$35,000 |
2020 年 11 月 9 日 |
1 |
1 |
-1 |
-1 |
$40,000 |
2020 年 11 月 16 日 |
1 |
1 |
-1 |
-1 |
$45,000 |
2020 年 11 月 23 日 |
1 |
1 |
-1 |
-1 |
NA |
2020 年 11 月 30 日 |
1 |
1 |
-1 |
-1 |
NA |
请注意:
尽管 TTA 的时间跨度可为未来的任意时间长度,但所预测的日期不能超过预测期。
如果所预测的日期包含目标列中的任何非缺失值,则不会对该行触发 TTA。
预测未来的日期¶
若要预测未来日期,需上传包含相关未来日期的数据集,并提供附加信息,如分组 ID 或在未来已知的特征。之后可将数据集用来运行您的预测,并对这些预测进行评分。
以下是在 2020 年 5 月 31 日之前训练的模型实例:
日期 |
分组 ID |
已知特征 1 |
已知特征 2 |
|---|---|---|---|
2020 年 6 月 1 日 |
A |
3 |
1 |
2020 年 6 月 2 日 |
A |
2 |
2 |
2020 年 6 月 3 日 |
A |
4 |
1 |
2020 年 6 月 1 日 |
B |
3 |
0 |
2020 年 6 月 2 日 |
B |
2 |
1 |
2020 年 6 月 3 日 |
B |
4 |
0 |