Importing Datasets
Supported file types
Driverless AI supports the following dataset file formats:
arff
avro
bin
bz2
csv (See note below)
dat
feather
gz
jay (See note below)
orc (See notes below)
parquet (See notes below)
pickle / pkl (See note below)
tgz
tsv
txt
xls
xlsx
xz
zip
Note
Compressed Parquet files are typically the most efficient file type to use with Driverless AI.
CSV in UTF-16 encoding is only supported when implemented with a byte order mark (BOM). If a BOM is not present, the dataset is read as UTF-8.
For ORC and Parquet file formats, if you select to import multiple files, those files will be imported as multiple datasets. If you select a folder of ORC or Parquet files, the folder will be imported as a single dataset. Tools like Spark/Hive export data as multiple ORC or Parquet files that are stored in a directory with a user-defined name. For example, if you export with
Spark dataFrame.write.parquet("/data/big_parquet_dataset"), Spark creates a folder /data/big_parquet_dataset, which will contain multiple Parquet files (depending on the number of partitions in the input dataset) and metadata. Exporting ORC files produces a similar result.For ORC and Parquet file formats, you may receive a “Failed to ingest binary file with ORC / Parquet: lists with structs are not supported” error when ingesting an ORC or Parquet file that has a struct as an element of an array. This is because PyArrow cannot handle a struct that’s an element of an array.
A workaround to flatten Parquet files is provided in Sparkling Water. Refer to our Sparkling Water solution for more information.
To use Parquet files that have columns with list type, the
data_import_explode_list_type_columns_in_parquetconfig.toml option must be set totrue. (Note that this setting is disabled by default.) When this option is enabled, columns with list type are “exploded” into separate new columns. That is, each list in a cell is split into separate items which are then used to create new columns. Refer to the following image for a visual representation of this process: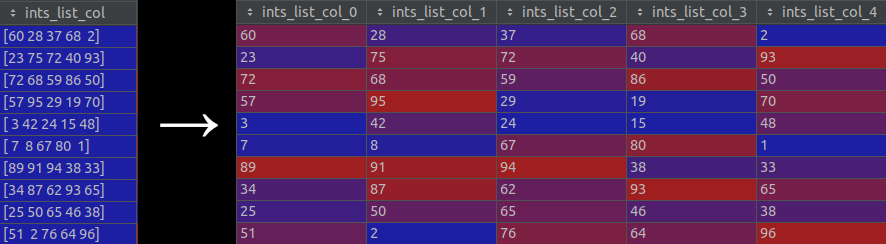
You can create new datasets from Python script files (custom recipes) by selecting Data Recipe URL or Upload Data Recipe from the Add Dataset (or Drag & Drop) dropdown menu. If you select the Data Recipe URL option, the URL must point to either an HTML or raw version of the file, a GitHub repository or tree, or a local file. In addition, you can create a new dataset by modifying an existing dataset with a custom recipe. Refer to Modify by custom data recipe for more information. Datasets created or added from recipes will be saved as .jay files.
To avoid potential errors, converting pickle files to CSV or .jay files is recommended. The following is an example of how to convert a pickle file to a CSV file using Datatable:
import datatable as dt import pandas as pd df = pd.read_pickle("test.pkl") dt = dt.Frame(df) dt.to_csv("test.csv")
Adding datasets
You can add datasets using one of the following methods:
Drag and drop files from your local machine directly onto this page. Note that this method currently works for files that are less than 10 GB.
or
Click the Add Dataset (or Drag & Drop) button to upload or add a dataset.
Notes:
Upload File, File System, HDFS, S3, Data Recipe URL, and Upload Data Recipe are enabled by default. These can be disabled by removing them from the
enabled_file_systemssetting in the config.toml file. (Refer to Using the config.toml file section for more information.)If File System is disabled, Driverless AI will open a local filebrowser by default.
If Driverless AI was started with data connectors enabled for Azure Blob Storage, BlueData Datatap, Google Big Query, Google Cloud Storage, KDB+, Minio, Snowflake, or JDBC, then these options will appear in the Add Dataset (or Drag & Drop) dropdown menu. Refer to the Enabling Data Connectors section for more information.
When specifying to add a dataset using Data Recipe URL, the URL must point to either an HTML or raw version of the file, a GitHub repository or tree, or a local file. When adding or uploading datasets via recipes, the dataset will be saved as a .jay file.
Datasets must be in delimited text format.
Driverless AI can detect the following separators: ,|;t
When importing a folder, the entire folder and all of its contents are read into Driverless AI as a single file.
When importing a folder, all of the files in the folder must have the same columns.
If you try to import a folder via a data connector on Windows, the import will fail if the folder contains files that do not have file extensions (the resulting error is usually related to the above note).
Upon completion, the datasets will appear in the Datasets Overview page. Click on a dataset to open a submenu. From this menu, you can specify to Rename, view Details of, Visualize, Split, Download, or Delete a dataset. Note: You cannot delete a dataset that was used in an active experiment. You have to delete the experiment first.