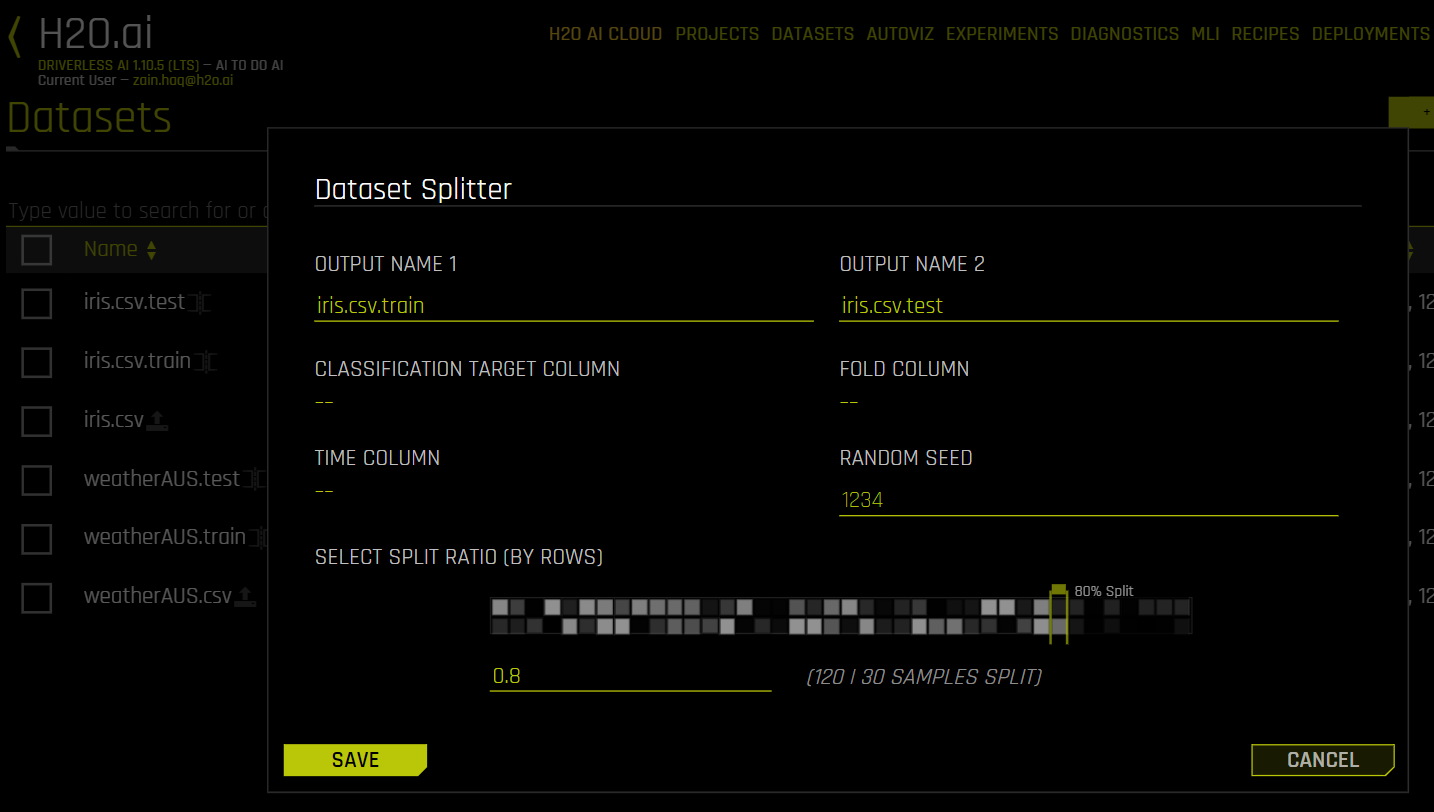
Split datasets
Driverless AI lets you split a dataset into two subsets that can be used as training and validation/test datasets during modeling. When splitting datasets for modeling, each split should have a similar distribution to avoid over fitting on the training set. Depending on the use case, you can either split the dataset randomly, perform a stratified sampling based on the target column, perform a fold column-based split to keep rows belonging to the same group together, or perform a time column-based split to train on past data and validate/test on future data.
Perform the following steps to split a dataset:
Click the dataset or select the [Click for Actions] button next to the dataset that you want to split and select Data Prep > Split from the submenu that appears.
The Dataset Splitter form displays. Optionally edit the default output names for each segment of the split. (For example, you can name one segment test and the other validation.)
Optionally specify a Target column (for stratified sampling), a Fold column (to keep rows belonging to the same group together), a Time column, and/or a Random Seed (defaults to 1234).
Use the slider to select a split ratio or enter a value in the Train/Valid Split Ratio field.
Click Save when you are done.
When this process has completed, the split datasets are made available on the Datasets page.