Explainer (Recipes) Expert Settings
The following is a list of the explainer-specific expert settings that are available when setting up a new interpretation. These settings can be accessed when running interpretation from the MLI page under recipes tab. For info on general MLI expert settings, see Interpretation Expert Settings.
Absolute Permutation Feature Importance Explainer Settings
mli_sample_size
Sample size
Specify the sample size for the absolute permutation feature importance explainer. This value defaults to 100000.
missing_values
List of values that should be interpreted as missing values
Specify the list of values that should be interpreted as missing values during data import. This applies to both numeric and string columns. Note that ‘nan’ is always interpreted as a missing value for numeric columns.
Example: ""\"['', '?', 'None', 'nan', 'N/A', 'unknown', 'inf']\""
autodoc_feature_importance_num_perm
Number of Permutations for Feature Importance
Specify the number of permutations to make per feature when computing feature importance. This is set to 1 by default.
autodoc_feature_importance_scorer
Feature Importance Scorer
Specify the name of the scorer to be used when calculating feature importance. Leave this setting unspecified to use the default scorer for the experiment.
MLI AutoDoc Explainer Settings
autodoc_report_name
AutoDoc Name
Specify the name of the AutoDoc.
autodoc_template
AutoDoc Template Location
Specify the AutoDoc template path. Provide the full path to your custom AutoDoc template. To generate the standard AutoDoc, leave this field empty.
autodoc_output_type
AutoDoc File Output Type
Specify the AutoDoc file output type. Choose from docx (the default value) and md.
autodoc_subtemplate_type
AutoDoc Sub-Template Type
Specify the type of sub-templates to use. Choose from the following:
auto (Default)
md
docx
autodoc_max_cm_size
Confusion Matrix Max Number of Classes
Specify the maximum number of classes in the confusion matrix. This value defaults to 10.
autodoc_num_features
Number of Top Features to Document
Specify the number of top features to display in the document. To disable this setting, specify -1. This is set to 50 by default.
autodoc_min_relative_importance
Minimum Relative Feature Importance Threshold
Specify the minimum relative feature importance in order for a feature to be displayed. This value must be a float >= 0 and <= 1. This is set to 0.003 by default.
autodoc_include_permutation_feature_importance
Permutation Feature Importance
Specify whether to compute permutation-based feature importance. This is disabled by default.
autodoc_feature_importance_num_perm
Number of Permutations for Feature Importance
Specify the number of permutations to make per feature when computing feature importance. This is set to 1 by default.
autodoc_feature_importance_scorer
Feature Importance Scorer
Specify the name of the scorer to be used when calculating feature importance. Leave this setting unspecified to use the default scorer for the experiment.
autodoc_pd_max_rows
PDP and Shapley Summary Plot Max Rows
Specify the number of rows shown for the partial dependence plots (PDP) and Shapley values summary plot in the AutoDoc. Random sampling is used for datasets with more than the autodoc_pd_max_rows limit. This value defaults to 10000.
autodoc_pd_max_runtime
PDP Max Runtime in Seconds
Specify the maximum number of seconds Partial Dependency computation can take when generating a report. Set to -1 for no time limit.
autodoc_out_of_range
PDP Out of Range
Specify the number of standard deviations outside of the range of a column to include in partial dependence plots. This shows how the model reacts to data it has not seen before. This is set to 3 by default.
autodoc_num_rows
ICE Number of Rows
Specify the number of rows to include in PDP and ICE plots if individual rows are not specified. This is set to 0 by default.
autodoc_population_stability_index
Population Stability Index
Specify whether to include a population stability index if the experiment is a binary classification or regression problem. This is disabled by default.
autodoc_population_stability_index_n_quantiles
Population Stability Index Number of Quantiles
Specify the number of quantiles to use for the population stability index. This is set to 10 by default.
autodoc_prediction_stats
Prediction Statistics
Specify whether to include prediction statistics information if the experiment is a binary classification or regression problem. This value is disabled by default.
autodoc_prediction_stats_n_quantiles
Prediction Statistics Number of Quantiles
Specify the number of quantiles to use for prediction statistics. This is set to 20 by default.
autodoc_response_rate
Response Rates Plot
Specify whether to include response rates information if the experiment is a binary classification problem. This is disabled by default.
autodoc_response_rate_n_quantiles
Response Rates Plot Number of Quantiles
Specify the number of quantiles to use for response rates information. This is set to 10 by default.
autodoc_gini_plot
Show GINI Plot
Specify whether to show the GINI plot. This is disabled by default.
autodoc_enable_shapley_values
Enable Shapley Values
Specify whether to show Shapley values results in the AutoDoc. This is enabled by default.
autodoc_global_klime_num_features
Global k-LIME Number of Features
Specify the number of features to show in a k-LIME global GLM coefficients table. This value must be an integer greater than 0 or -1. To show all features, set this value to -1.
autodoc_global_klime_num_tables
Global k-LIME Number of Tables
Specify the number of k-LIME global GLM coefficients tables to show in the AutoDoc. Set this value to 1 to show one table with coefficients sorted by absolute value. Set this value to 2 to show two tables - one with the top positive coefficients and another with the top negative coefficients. This value is set to 1 by default.
autodoc_data_summary_col_num
Number of Features in Data Summary Table
Specify the number of features to be shown in the data summary table. This value must be an integer. To show all columns, specify any value lower than 1. This is set to -1 by default.
autodoc_list_all_config_settings
List All Config Settings
Specify whether to show all config settings. If this is disabled, only settings that have been changed are listed. All settings are listed when enabled. This is disabled by default.
autodoc_keras_summary_line_length
Keras Model Architecture Summary Line Length
Specify the line length of the Keras model architecture summary. This value must be either an integer greater than 0 or -1. To use the default line length, set this value to -1 (default).
autodoc_transformer_architecture_max_lines
NLP/Image Transformer Architecture Max Lines
Specify the maximum number of lines shown for advanced transformer architecture in the Feature section. Note that the full architecture can be found in the appendix.
autodoc_full_architecture_in_appendix
Appendix NLP/Image Transformer Architecture
Specify whether to show the full NLP/Image transformer architecture in the appendix. This is disabled by default.
autodoc_coef_table_appendix_results_table
Full GLM Coefficients Table in the Appendix
Specify whether to show the full GLM coefficient table(s) in the appendix. This is disabled by default.
autodoc_coef_table_num_models
GLM Coefficient Tables Number of Models
Specify the number of models for which a GLM coefficients table is shown in the AutoDoc. This value must be -1 or an integer >= 1. Set this value to -1 to show tables for all models. This is set to 1 by default.
autodoc_coef_table_num_folds
GLM Coefficient Tables Number of Folds Per Model
Specify the number of folds per model for which a GLM coefficients table is shown in the AutoDoc. This value must be be -1 (default) or an integer >= 1 (-1 shows all folds per model).
autodoc_coef_table_num_coef
GLM Coefficient Tables Number of Coefficients
Specify the number of coefficients to show within a GLM coefficients table in the AutoDoc. This is set to 50 by default. Set this value to -1 to show all coefficients.
autodoc_coef_table_num_classes
GLM Coefficient Tables Number of Classes
Specify the number of classes to show within a GLM coefficients table in the AutoDoc. Set this value to -1 to show all classes. This is set to 9 by default.
autodoc_num_histogram_plots
Number of Histograms to Show
Specify the number of top features for which to show histograms. This is set to 10 by default.
Disparate Impact Analysis Explainer Settings
For information on Disparate Impact Analysis in Driverless AI, see Disparate Impact Analysis (DIA). The following is a list of parameters that can be toggled from the recipes tab of the MLI page when running a new interpretation.
dia_cols
List of Features for Which to Compute DIA
Specify a list of specific features for which to compute DIA.
cut_off
Cut Off
Specify a cut off when performing DIA.
maximize_metric
Maximize Metric
Specify a metric to use when computing DIA. Choose from the following:
F1
F05
F2
MCC
use_holdout_preds
Use Internal Holdout Predictions
Specify whether to use internal holdout predictions when computing DIA. This is enabled by default.
sample_size
Sample Size for Disparate Impact Analysis
Specify the sample size for Disparate Impact Analysis. By default, this value is set to 100000.
max_card
Max Cardinality for Categorical Variables
Specify the max cardinality for categorical variables. By default, this value is set to 10.
min_card
Minimum Cardinality for Categorical Variables
Specify the minimum cardinality for categorical variables. By default, this value is set to 2.
num_card
Max Cardinality for Numeric Variables to be Considered Categorical
Specify the max cardinality for numeric variables to be considered categorical. By default, this value is set to 25.
fast_approx
Speed Up Predictions With a Fast Approximation
Specify whether to increase the speed of predictions with a fast approximation. This is enabled by default.
NLP Partial Dependence Plot Explainer Settings
max_tokens
Number of text tokens
Specify the number of text tokens for the NLP Partial Dependence plot. This value defaults to 20.
custom_tokens
List of custom text tokens
Specify a list of custom text tokens for which to compute NLP partial dependence. For example, ["text_feature('word_1')"], where text_feature is the name of the model text feature.
NLP Vectorizer + Linear Model Text Feature Importance Explainer Settings
txt_cols
Text feature for which to compute explanation
Specify the text feature for which to compute explanation.
cut_off
Cut off for deciphering binary class outcome
Specify the cut off for deciphering binary class outcome based on DAI model predictions. Any DAI prediction greater than the cut off is the target label and any DAI prediction less than the cut off is the non-target label.
maximize_metric
Cut off based on a metric to maximize
Calculate cut off based on a metric to maximize, which will decipher binary class outcome based on DAI model predictions. Any DAI prediction greater than the cut off is the target label and any DAI prediction less than the cut off is the non-target label. It should be noted that specifying a cut off AND a max metric will give precedence to the cut off.
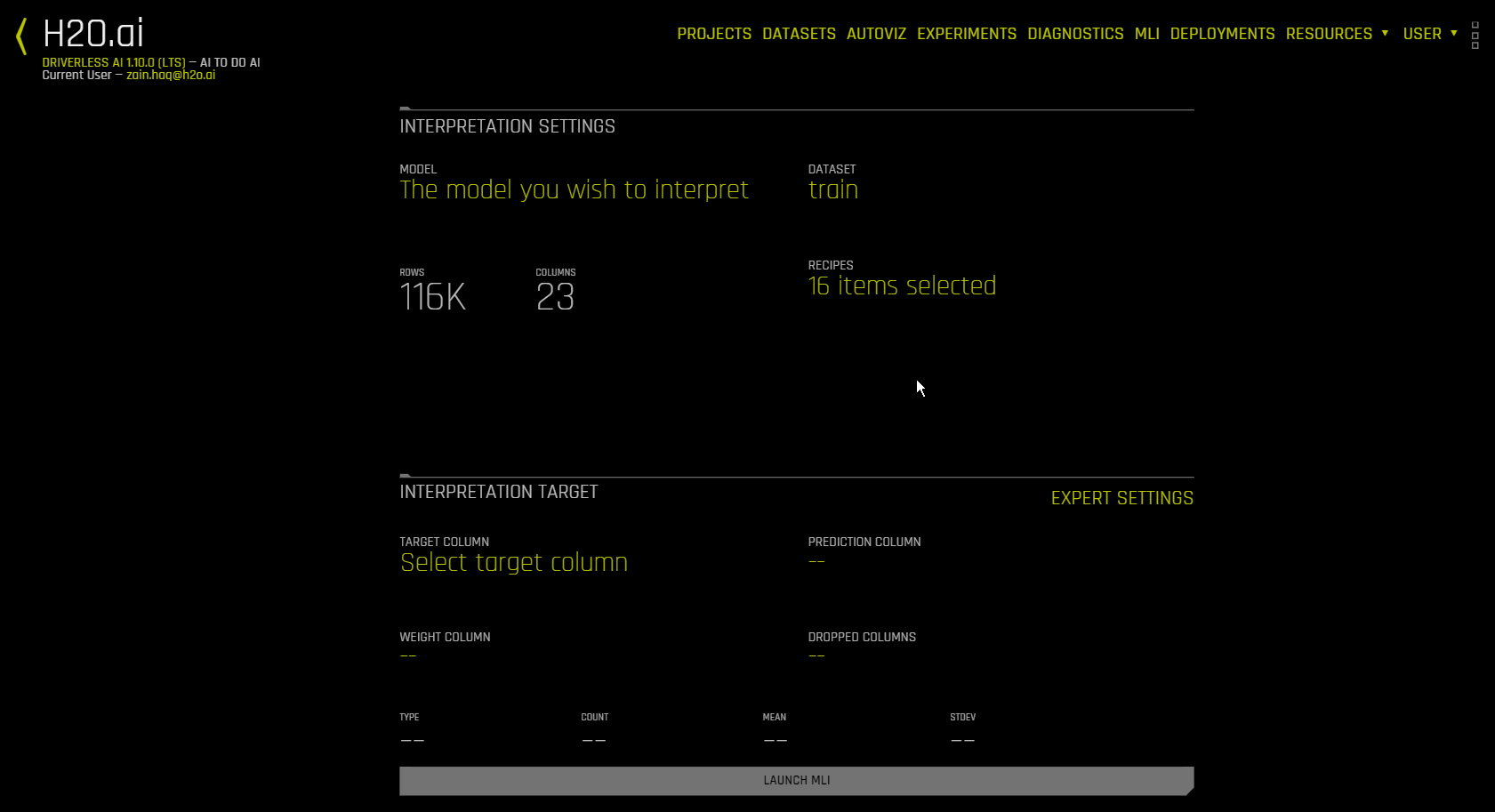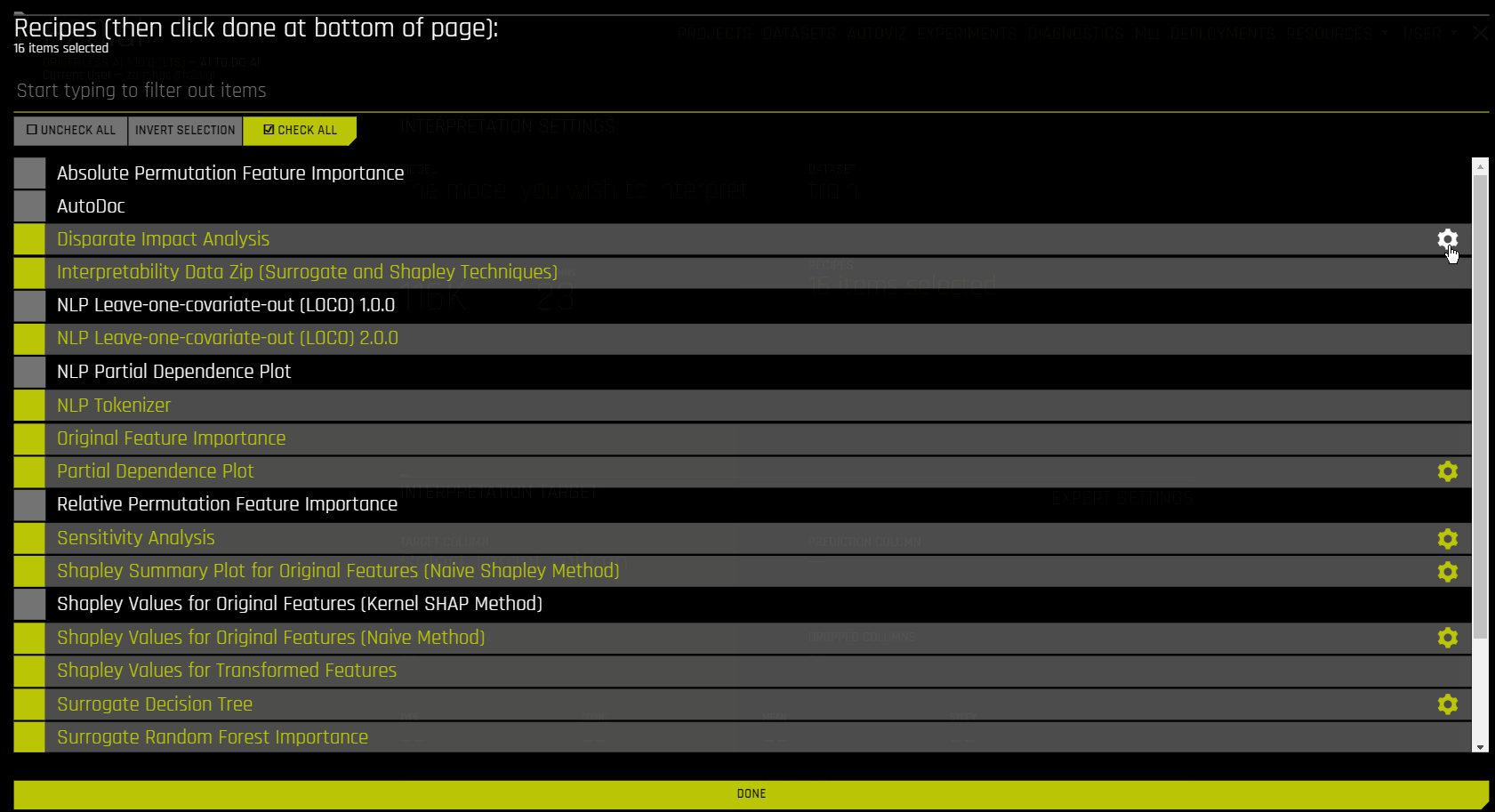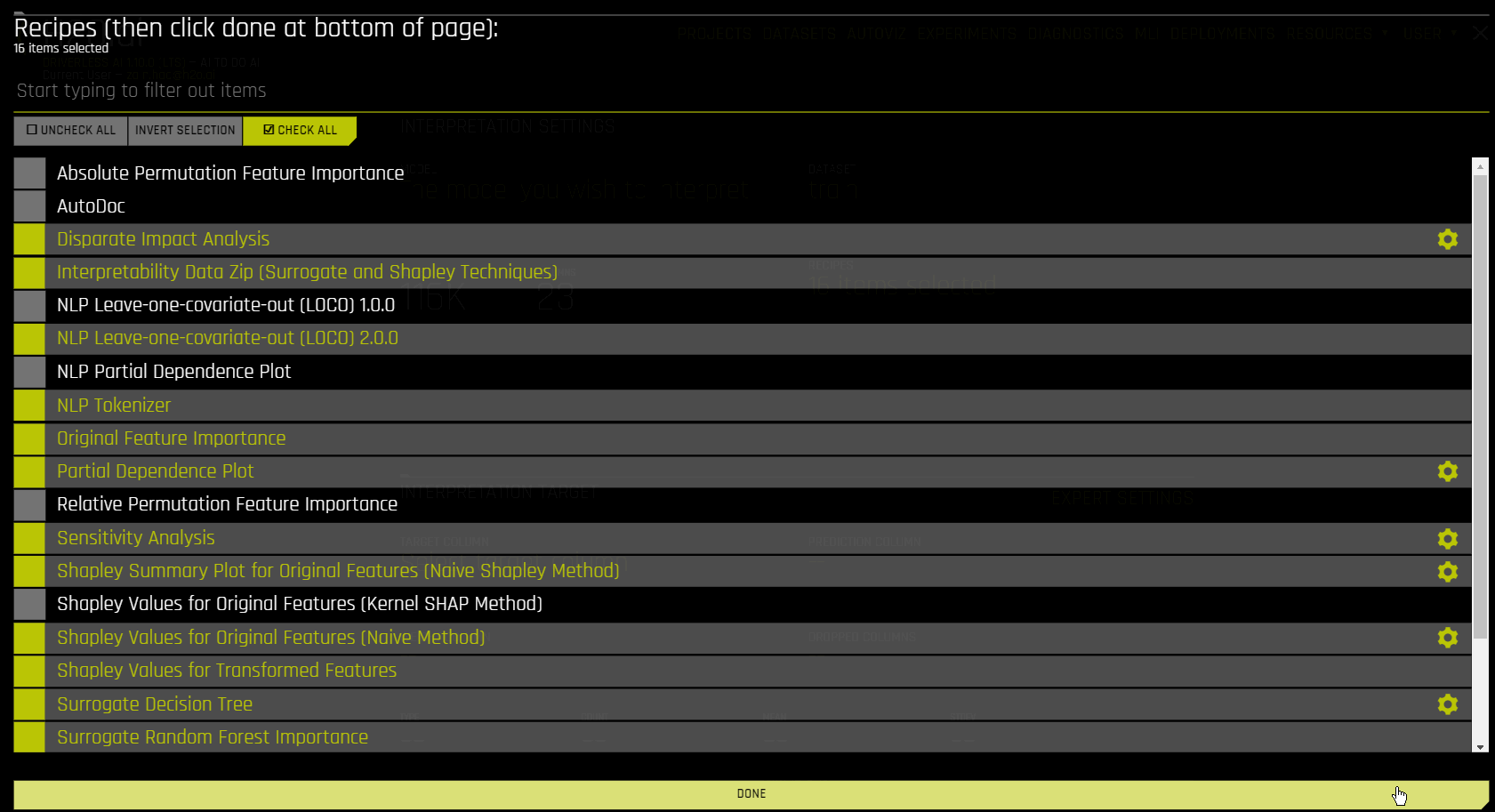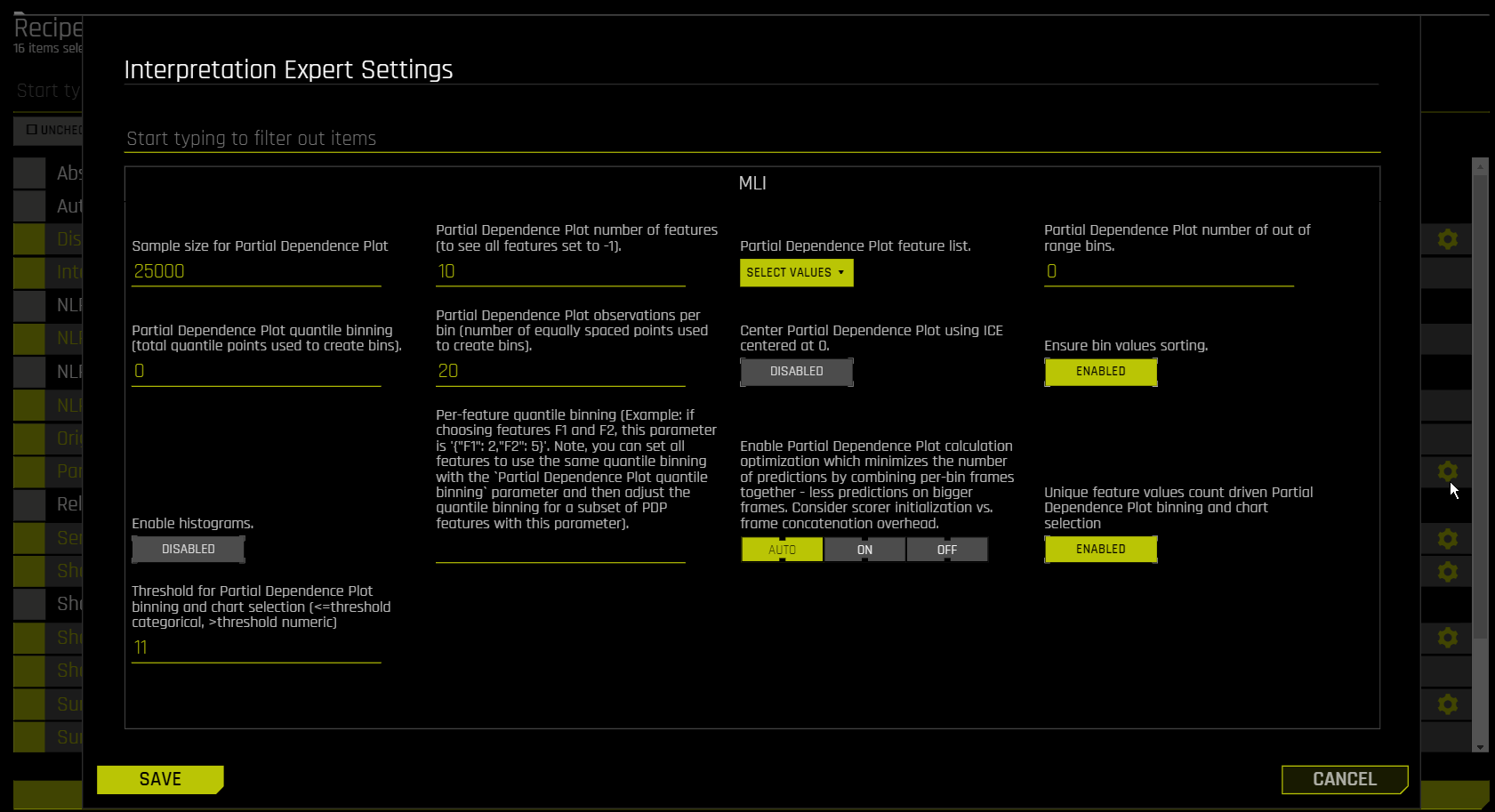
Partial Dependence Plot Explainer Settings
For information on Partial Dependence Plots in Driverless AI, see Partial Dependence Plot (PDP). The following is a list of parameters that can be toggled from the recipes tab of the MLI page when running a new interpretation.
sample_size
Sample Size for Partial Dependence Plot
When number of rows is above this limit, sample for the Driverless AI partial dependence plot.
max_features
Partial Dependence Plot Number of Features
Specify the number of features that can be viewed on the partial dependence plot. By default, this is set to 10. To view all features, set this value to -1.
features
Partial Dependence Plot Feature List
Specify a list of features for the partial dependence plot.
oor_grid_resolution
PDP Number of Out of Range Bins
Specify the number of out of range bins for the partial dependence plot. By default, this is set to 0.
qtile_grid_resolution
PDP Quantile Binning
Specify the total quantile points used to create bins. By default, this is set to 0.
grid_resolution
PDP Observations Per Bin
Specify the number of equally spaced points used to create bins. By default, this is set to 20.
center
Center PDP Using ICE Centered at 0
Specify whether center the partial dependence plot using ICE centered at 0. This is disabled by default.
sort_bins
Ensure Bin Values Sorting
Specify whether to ensure bin values sorting. This is enabled by default.
histograms
Enable Histograms
Specify whether to enable histograms for the partial dependence plot. This is disabled by default.
qtile-bins
Per-Feature Quantile Binning
Specify per-feature quantile binning. For example, if you select features F1 and F2, this parameter can be specified as '{"F1": 2,"F2": 5}'.
Note: You can set all features to use the same quantile binning with the qtile_grid_resolution parameter and then adjust the quantile binning for a subset of PDP features with this parameter.
1_frame
Enable PDP Calculation Optimization
Specify whether to enable PDP calculation optimization, which minimizes the number of predictions by combining per-bin frames together. By default, this is set to ‘Auto’.
numcat_num_chart
Unique Feature Values Count-Driven PDP Binning and Chart Selection
Specify whether to use dynamic switching between PDP numeric and categorical binning and UI chart selection in cases where features were used both as numeric and categorical by the experiment. This is enabled by default.
numcat_threshold
Threshold for PD/ICE Binning and Chart Selection
If mli_pd_numcat_num_chart is enabled, and if the number of unique feature values is greater than the threshold, then numeric binning and chart is used. Otherwise, categorical binning and chart is used. The default threshold value is 11.
Sensitivity Analysis Explainer Settings
sample_size
Sample Size for Sensitivity Analysis (SA)
When the number of rows is above this limit, sample for Sensitivity Analysis (SA). The default value is 500000.
Shapley Summary Plot Explainer Settings
For information on Shapley Summary Plots in Driverless AI, see Shapley Summary Plot (Original Features). The following is a list of parameters that can be toggled from the recipes tab of the MLI page when running a new interpretation.
max_features
Maximum Number of Features to be Shown
Specify the maximum number of features that are shown in the plot. By default, this value is set to 50.
sample_size
Sample Size
Specify the sample size for the plot. By default, this value is set to 20000.
x_resolution
X-Axis Resolution
Specify the number of Shapley value bins. By default, this value is set to 500.
drilldown_charts
Enable Creation of Per-Feature Shapley / Feature Value Scatter Plots
Specify whether to enable the creation of per-feature Shapley or feature value scatter plots. This is enabled by default.
fast_approx
Speed Up Predictions With a Fast Approximation
Specify whether to increase the speed of predictions with a fast approximation. This is enabled by default.
Shapley Values for Original Features Settings
sample_size
Sample Size for Naive Shapley
When the number of rows is above this limit, sample for Naive Shapley. By default, this value is set to 100000.
fast_approx
Speed Up Predictions With a Fast Approximation
Specify whether to increase the speed of predictions with a fast approximation. This is enabled by default.
Surrogate Decision Tree Explainer Settings
For information on Surrogate Decision Tree Plots in Driverless AI, see Surrogate Decision Tree. The following is a list of parameters that can be toggled from the recipes tab of the MLI page when running a new interpretation.
dt_tree_depth
Decision Tree Depth
Specify the depth of the decision tree. By default, this value is set to 3.
nfolds
Number of CV Folds
Specify the number of CV folds to use. By default, this value is set to 0.
qbin_cols
Quantile Binning Columns
Specify quantile binning columns.
qbin_count
Quantile Bins Count
Specify the number of quantile bins. By default, this value is set to 0.