Task 7: Score new data
To score on new data (future dates) using the built time series model, you must first upload a dataset similar to the training dataset, but without the target and sample weight columns. Then, consider the following steps to score new data:
- Click Close.
- In the H2O Driverless AI navigation menu, click EXPERIMENTS.
- In the Experiments table, click tutorial-2a.
- Click MODEL ACTIONS and select PREDICT.
- Select the columns to include, which should be the ones on the training dataset minus the target and sample weight columns.
- Click DONE.
- After the model scores all the new data, you can access the latest predictions in the Jobs section. Click OPEN.
- Click DOWNLOAD PREDICTIONS.
- Optional: In the Specify File Name box, enter a name for the file predictions.
- Click DOWNLOAD.
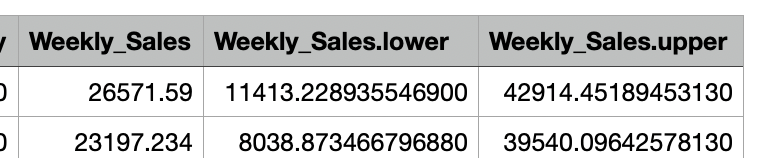
The CSV file will contain all the selected columns for the predictions, along with the target column's predicted values. Additionally, it will include the lower and upper target column values, which represent the bounds of the prediction interval. These lower and upper values provide a range within which the actual future values of the target column are expected to fall. This range helps in understanding the forecast's confidence level, offering a more comprehensive view of potential future outcomes.
Rolling-window-based predictions
H2O Driverless AI supports rolling-window-based predictions for time series experiments with two options: Test Time Augmentation (TTA) or re-fit.
Both options are useful for assessing the pipeline's performance in predicting not just a single forecast horizon but many in succession. TTA simulates the process where the model stays the same, but the features are refreshed using newly available data. Re-fit simulates the process of re-fitting the entire pipeline (including the model) once new data is available.
This process is automated when the test set spans for a longer period than the forecast horizon and if the target values of the test set are known. If the user scores a test set that meets these conditions after the experiment is finished, rolling predictions with TTA will be applied. Re-fit, on the other hand, is only applicable for test sets provided during an experiment.
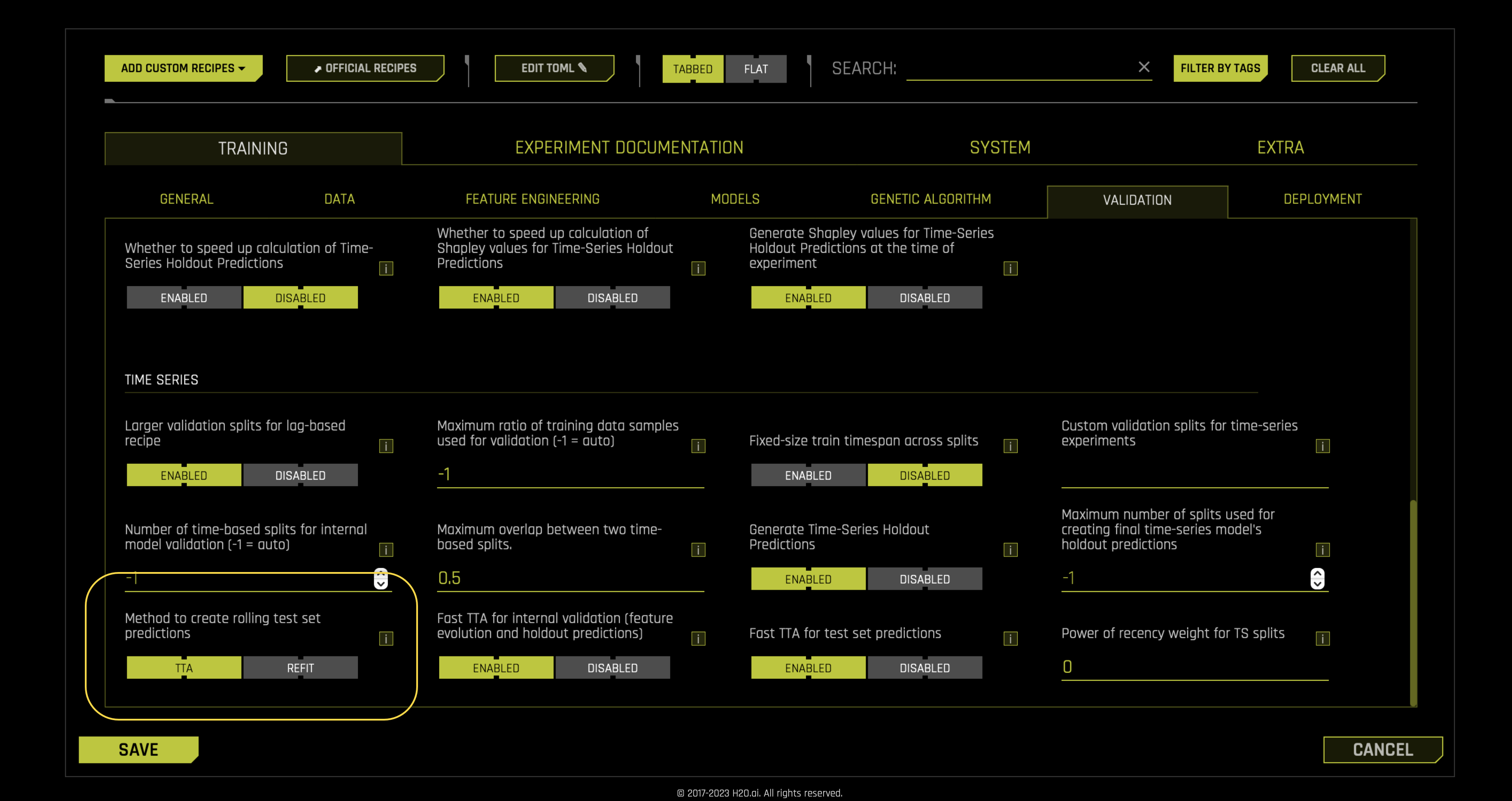
TTA is the default option for a time series experiment, but you can change it in the following expert setting: Method to create rolling test set predictions. To access the expert setting, consider the following steps:
- After selecting the target column of a time series experiment, click EXPERT SETTINGS.
- Click the VALIDATION tab.
- Submit and view feedback for this page
- Send feedback about H2O Driverless AI | Tutorials to cloud-feedback@h2o.ai