Key terms
This page provides an overview of key terms and concepts that apply to H2O MLOps.
Projects
In MLOps, a project is the main folder that contains experiments, artifacts, models, and deployments. Projects are designed to be collaborative, and can be shared between multiple individuals. Additionally, project owners can specify role-based access control for each individual that is invited to collaborate on a project. Projects can be used to group all work items for a specific team, or can be used to group all work items for a specific use case.
Notes:
-
Access to users is controlled at the project level. If a user has read and write access to a project, they are able to make changes to all experiments, models, and deployments associated with that project.
-
Any projects that have been created in H2O Driverless AI are automatically synchronized with H2O MLOps projects.
Experiments
In MLOps, an experiment is defined as the output of a training job. Many different experiments can be rapidly created by modifying specific parameters and hyperparameters. Experiments can be imported in the following formats:
- Driverless AI MOJO (directly through DAI interface, or by dragging and dropping file)
- H2O-3 open source MOJO (dragging and dropping file)
- 3rd party model frameworks (e.g. scikit-learn, PyTorch, XGBoost, LightGBM, TensorFlow; dragging and dropping MLflow packaged file, or dragging and dropping serialized Pickle file)
Note: Before an experiment can be deployed, it must first be registered in the MLOps Model Registry.
Registered models and model versions
In MLOps, a registered model is a collection of individual model versions. Registered models are used to group registered model versions that are relevant to a specific problem. New experiments and iterations can be registered as updated versions of the model.
In MLOps, a model version has a one-to-one relationship with experiments within a given Project. When you want to proceed with serving your best experiment, you can register that experiment as a model version.
Notes:
-
Model versions can be served in multiple deployments. There is no limitation on the number of deployments a single model version can be a part of.
-
In any given project, an experiment can only be registered as one model version. This allows for a one-to-one mapping between an experiment and the model version.
Deployments
In MLOps, deployments are created when model version(s) are served for scoring. Configured for Environment, Type (real-time, batch), and Mode (single model, A/B, C/C). Model version(s) can be replaced, without changing any other configuration details.
Drift detection
Drift detection in MLOps is based on Feature Drift. This term is used to describe situations where the input values for features during scoring differ from the input values for features during training. When drift increases, it means that the model is seeing data that it was not trained on, and so the performance and results of the model may not be accurate.
Drift evaluation
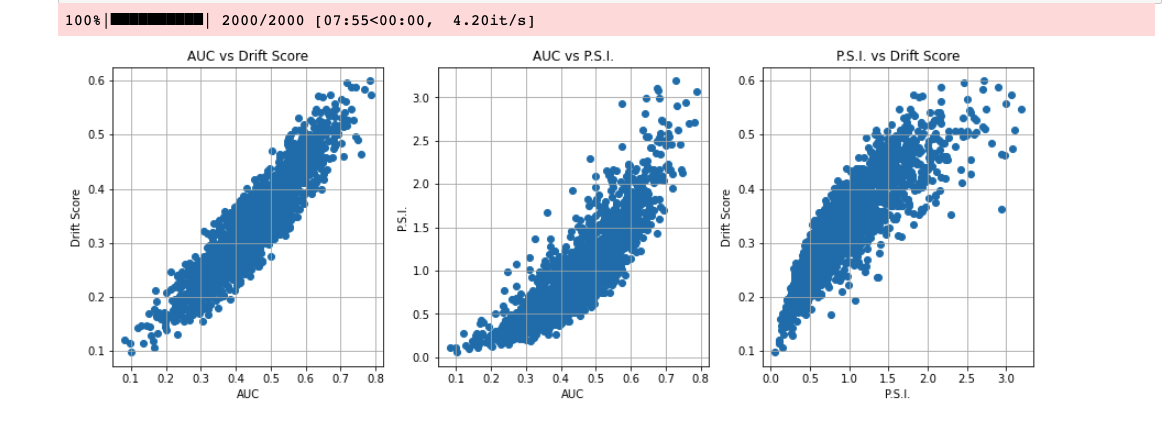
The drift evaluation metrics used in MLOps are the Population Stability Index (PSI) and Drift Score. The PSI only works for numerical features, whereas drift score can work with categorical features.
The following image compares PSI, drift score and AUC.
Population Stability Index
To learn how the PSI is calculated in MLOps, refer to the following steps:
-
The reference samples are binned in a maximum of 10 equal bins. Depending on the distribution, you may end up with less or unequally populated bins. Equal binning gives less weight to tails.
-
Compute the frequency of each bin.
-
Apply the binning to scoring samples and compute frequencies.
-
Compute PSI as follows:

Notes:
- PSI does not support missing values.
- PSI is more suited for numerical features or ordinal features. This metric may have difficulty with categorical features, particularly with high cardinality categoricals.
Drift score
To learn how drift score is calculated in MLOps, refer to the following steps:
-
The reference samples are binned in a maximum of 10 equal bins. Depending on the distribution, you may end up with less or unequally populated bins. Equal binning gives less weight to tails.
-
Compute the frequency of each bin.
-
Apply the binning to scoring samples and compute frequencies.
-
Compute drift score as follows:
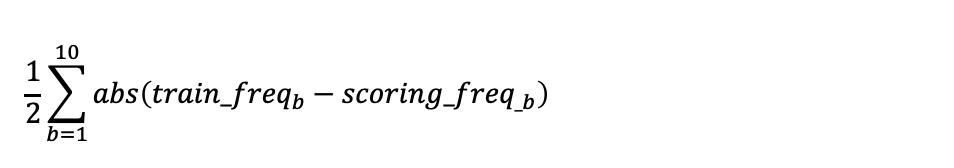
- Submit and view feedback for this page
- Send feedback about H2O MLOps to cloud-feedback@h2o.ai