Key terms
This page provides an overview of key terms and concepts that apply to H2O MLOps.
Workspaces
In MLOps, a workspace is the main folder that contains experiments, artifacts, models, and deployments. Workspaces are designed to be collaborative, and can be shared between multiple individuals. Additionally, workspace owners can specify role-based access control for each individual that is invited to collaborate on a workspace. Workspaces can be used to group all work items for a specific team, or can be used to group all work items for a specific use case.
- Access to users is controlled at the workspace level. If a user has read and write access to a workspace, they are able to make changes to all experiments, models, and deployments associated with that workspace.
- Any projects that have been created in H2O Driverless AI are automatically synchronized with H2O MLOps workspaces.
BYOM (Bring Your Own Model)
BYOM, or Bring Your Own Model, refers to the process of importing models trained outside the H2O MLOps platform, such as models from H2O Driverless AI, H2O-3, or MLflow, for deployment and management in H2O MLOps.
Experiments
In MLOps, an experiment is defined as the output of a training job. Many different experiments can be rapidly created by modifying specific parameters and hyperparameters. Experiments can be imported in the following formats:
- Driverless AI MOJO (directly through DAI interface, or by dragging and dropping file).
- H2O-3 open source MOJO (dragging and dropping file).
- Third-party model frameworks. This includes scikit-learn, PyTorch, XGBoost, LightGBM, and TensorFlow. Import by dragging and dropping an MLflow packaged file.
Before an experiment can be deployed, it must first be registered in the H2O MLOps Model Registry.
Experiment metadata
Each experiment in the H2O.ai Storage can have multiple key-value pairs attached to it. These values are not interpreted by the storage itself but can be interpreted by the clients or client services that access data in the Storage.
Experiments that are added to H2O MLOps from the MLflow Model Registry include both the MLflow model name (source_model_name) and MLflow version number (source_model_version) as part of the experiment metadata.
Artifacts in MLOps
Defining artifacts and experiment artifacts
- Artifact: An arbitrary binary large object (BLOB) attached to a particular entity in the H2O.ai Storage.
- Experiment Artifact: Any artifact that is attached to the experiment entity.
Artifact type
Because any entity can have multiple artifacts attached to it, specific artifacts must be identified by their type. Type is an arbitrary string. Artifact type is recognized by and relevant to MLOps deployments.
The following is a list of artifact types:
dai/mojo_pipeline(Natively supported, ingestion supported)h2o3/mojo(Natively supported, ingestion supported)Python/MLflow(Ingestion supported)
Deployable artifact type
A deployable artifact type is an artifact type that the Deployer knows how to process and deploy. Each deployable artifact type consists of the name, readable name, and reference to the artifact type.
Artifact processor
Artifact processor is the routine that takes the raw artifact data and transforms it into the format that is digestible by the runtime. In this routine, an artifact is defined by its name, the model type that it produces, and a container image reference.
Artifact processors can be any container image that can be pulled from the target deployment environment. Each processor needs to recognize and use two environmental variables.
The following is a list of artifact processor environment variables:
SOURCE_PATH: Path to the file containing the raw data of the artifactTARGET_PATH: Path where the processor saves its output. This path is passed asMODEL_PATHto the runtime
Deployments
In MLOps, deployments are created when model version(s) are served for scoring. Deployments are configured by Type (real-time, batch) and Mode (single model, A/B, C/C).
A deployment is always tied to a specific model version. You cannot edit or replace the version of an existing deployment. To serve a new model version, you must create a new deployment.
To minimize disruption, endpoints can be reused across deployments by deploying the new model and updating the endpoint target from the old deployment to the new deployment. This allows you to continue using the same endpoint with zero downtime.
Runtime image
A runtime image is a named, logical grouping that represents a category of scoring runtime container images in H2O MLOps. Each runtime image can contain multiple runtime image versions. Runtime images organize the different scorer implementations (for example, "DAI MOJO Scorer" or "H2O-3 MOJO Scorer") at the highest level of the runtime hierarchy.
Runtime image version
A runtime image version is a specific tagged container image associated with a runtime image. It points to an actual container image in a registry (for example, registry.example.com/dai-mojo-scorer:1.2.0). Multiple runtime image versions can exist under a single runtime image, enabling version tracking and controlled rollouts of new scorer images.
Runtime
A runtime is a deployable scoring configuration that combines a runtime image with a model type, environment variables, volumes, and security settings. When you create a deployment, you select a runtime. H2O MLOps resolves the appropriate container image version from the runtime's associated runtime image.
Runtimes, runtime images, and runtime image versions follow a state lifecycle: ACTIVE, DEPRECATED, and DISABLED. For more information, see Understand runtime management.
Drift detection
Drift detection in MLOps is based on Feature Drift. This term is used to describe situations where the input values for features during scoring differ from the input values for features during training. When drift increases, it means that the model is seeing data that it was not trained on, and so the performance and results of the model may not be accurate.
Drift evaluation
The drift evaluation metrics used in MLOps are the Population Stability Index (PSI) and Drift Score. The PSI only works for numerical features, whereas drift score can work with categorical features.
The following image compares PSI, drift score and AUC.
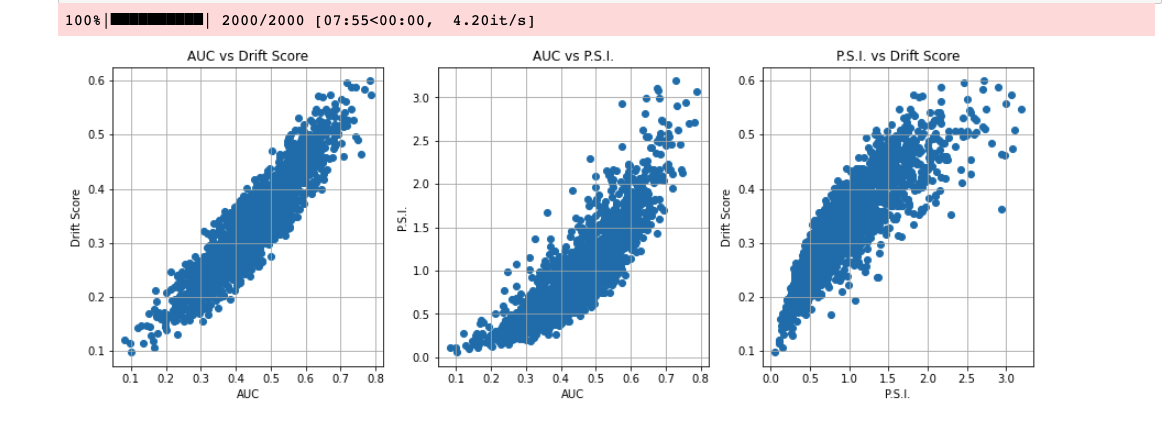
Population Stability Index
To learn how the PSI is calculated in MLOps, refer to the following steps:
-
The reference samples are binned in a maximum of 10 equal bins. Depending on the distribution, you may end up with less or unequally populated bins. Equal binning gives less weight to tails.
-
Compute the frequency of each bin.
-
Apply the binning to scoring samples and compute frequencies.
-
Compute PSI as follows:

- PSI does not support missing values.
- PSI is more suited for numerical features or ordinal features. This metric may have difficulty with categorical features, particularly with high cardinality categoricals.
Drift score
To learn how drift score is calculated in MLOps, refer to the following steps:
-
The reference samples are binned in a maximum of 10 equal bins. Depending on the distribution, you may end up with less or unequally populated bins. Equal binning gives less weight to tails.
-
Compute the frequency of each bin.
-
Apply the binning to scoring samples and compute frequencies.
-
Compute drift score as follows:
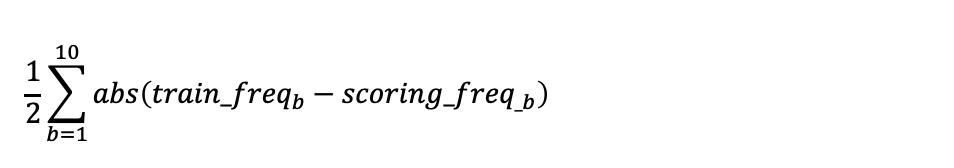
Node affinity and toleration
As stated in the official Kubernetes documentation, "node affinity is a property of Pods that attracts them to a set of nodes, either as a preference or a hard requirement. Taints are the opposite—they allow a node to repel a set of pods. Tolerations are applied to pods, and allow (but do not require) the pods to schedule onto nodes with matching taints." In the case of MLOps, these options let you ensure that scorers (pods) are scheduled onto specific machines (nodes) in a cluster that have been set up for machine learning tasks.
- Submit and view feedback for this page
- Send feedback about H2O MLOps to cloud-feedback@h2o.ai