Google BigQuery 设置¶
Driverless AI 让您能从 Driverless AI 应用程序内探索 Google BigQuery 数据源。本节介绍如何配置 Driverless AI 与 Google BigQuery 配合使用。此项设置要求您启用身份验证。如果您启用 GCS 和/或 GBQ 连接器,则这些文件系统将在 UI 中提供,但如果未经身份验证,您将无法使用这些连接器。
若需启用经身份验证的 GBQ 数据连接器,您必须:
从 GCP 获取 JSON 身份验证文件。
将 JSON 文件挂载至 Docker 实例。
使用 gcs_path_to_service_account_json 配置选项指定 /json_auth_file.json 的路径。
请注意:
服务帐户 JSON 中包含由系统管理员提供的身份验证。您将获得一份 JSON 文件,其中可能包含 Google Cloud Storage 和 Google BigQuery 身份验证信息,也可能仅包含其中一个或都不包含。
根据您所安装的 Docker 版本,在启动 Driverless AI Docker 映像时,使用
docker run --runtime=nvidia(>= Docker 19.03) 或nvidia-docker(< Docker 19.03) 命令。使用docker version来检查您使用的 Docker 版本。
启用有身份验证的 GBQ¶
本示例通过传递 JSON 身份验证文件启用经身份验证的 GBQ 数据连接器。这假设 JSON 文件包含 Google BigQuery 身份验证。
nvidia-docker run \
--pid=host \
--rm \
--shm-size=256m \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,gbq" \
-e DRIVERLESS_AI_GCS_PATH_TO_SERVICE_ACCOUNT_JSON="/service_account_json.json" \
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
本示例展示如何在 config.toml 文件中配置 GBQ 数据连接器选项,然后在 Docker 中启动 Driverless AI 时指定此文件。
配置 Driverless AI config.toml 文件。设置以下配置选项:
enabled_file_systems = "file, upload, gbq"
gcs_path_to_service_account_json = "/service_account_json.json"
将 config.toml 文件挂载至 Docker 容器。
nvidia-docker run \ --pid=host \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
本示例通过传递 JSON 身份验证文件启用经身份验证的 GBQ 数据连接器。这假设 JSON 文件包含 Google BigQuery 身份验证。
导出 Driverless AI config.toml 文件或将其添加至 ~/.bashrc。例如:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
在 config.toml 文件中指定以下配置选项。
# File System Support # file : local file system/server file system # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below enabled_file_systems = "file, gbq" # GCS Connector credentials # example (suggested) -- "/licenses/my_service_account_json.json" gcs_path_to_service_account_json = "/service_account_json.json"
完成后,保存更改,然后停止/重启 Driverless AI。
使用 GBQ 添加数据集¶
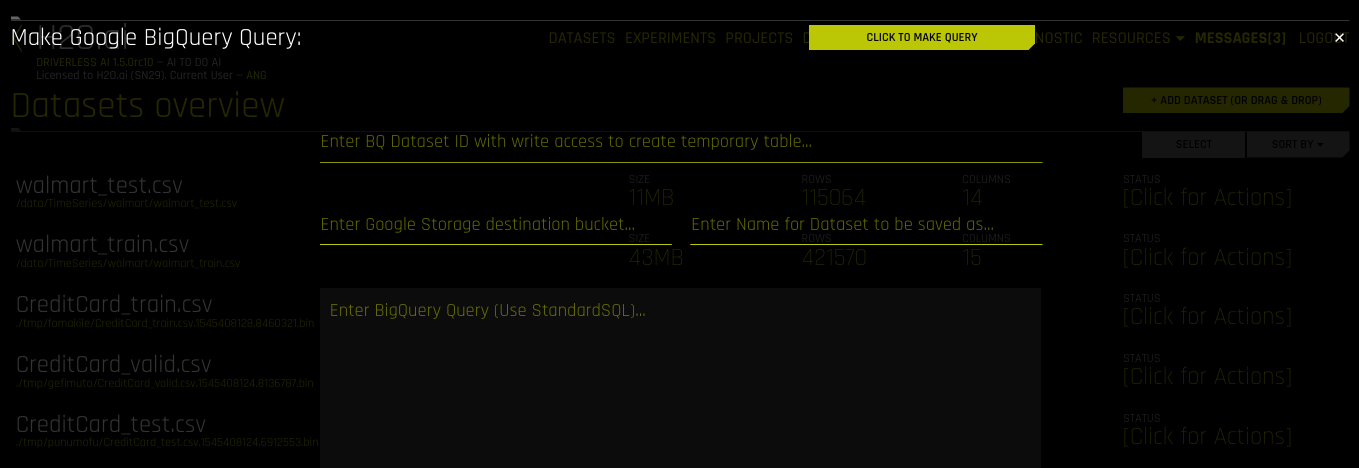
启用 Google BigQuery 后,您可以通过在 添加数据集(或拖放) 下拉菜单中选择 Google Big Query 来添加数据集。

指定以下信息以添加数据集。
输入具有写入权限的 BQ 数据集 ID 来创建临时表:在 Google BigQuery 中输入用户具有读取/写入权限的数据集 ID。BigQuery 会将此数据集作为由查询生成的新表单的位置。
请注意:将 Driverless AI 连接至 GBQ,这将从服务 JSON 文件中继承顶级目录。因此,如果名为 “my-dataset” 的数据集在名为 “dai-gbq” 的顶级目录中,则数据集 ID 输入字段的值应为 “my-dataset”,而不是 “dai-gbq:my-dataset”。
输入 Google Storage 目标存储桶:指定 Google Cloud Storage 目标存储桶的名称。请注意,用户必须具有此存储桶的写入权限。
输入要保存为的数据集名称:指定数据集名称,例如,“my_file”。
输入 BigQuery 查询(使用 StandardSQL):输入您想让 BigQuery 执行的 StandardSQL 查询。例如:
SELECT * FROM <my_dataset>.<my_table>.(可选)指定与 GBQ 连接器一起使用的项目。这相当于在使用命令行界面时提供
--project。完成后,选择 单击以执行查询 按钮以添加数据集。