JDBC 设置¶
Driverless AI 让您能从 Driverless AI 应用程序内探索 Java 数据库连接 (JDBC) 数据源。本节介绍如何配置 Driverless AI 与 JDBC 配合使用。
请注意:根据您所安装的 Docker 版本,在启动 Driverless AI Docker 映像时,使用 docker run --runtime=nvidia (>= Docker 19.03) 或 nvidia-docker (< Docker 19.03) 命令。使用 docker version 检查所使用的 Docker 版本。
已测试的数据库¶
以下数据库已进行过最低功能性测试。请注意,未包含在此列表中的 JDBC 驱动程序应该能与 Driverless AI 一起使用。即使在已测试的数据库列表中没有看到您的 JDBC 驱动程序,我们仍然建议您对其进行测试。请参阅本章末尾的 添加未经测试的 JDBC 驱动程序 一节,了解如何尝试使用未经测试的 JDBC 驱动程序。
Oracle DB
PostgreSQL
Amazon Redshift
Teradata
配置属性说明¶
jdbc_app_configs: JDBC 连接器的配置。这是一个具有多个密钥的 JSON/字典字符串。请注意:此配置需要将 JSON 密钥(通常是要配置的数据库的名称)与包含url、jarpath和classpath字段的嵌套 JSON 相关联。此外,应采用以下格式:
"""{"my_jdbc_database": {"url": "jdbc:my_jdbc_database://hostname:port/database", "jarpath": "/path/to/my/jdbc/database.jar", "classpath": "com.my.jdbc.Driver"}}"""例如:
"""{ "postgres": { "url": "jdbc:postgresql://ip address:port/postgres", "jarpath": "/path/to/postgres_driver.jar", "classpath": "org.postgresql.Driver" }, "mysql": { "url":"mysql connection string", "jarpath": "/path/to/mysql_driver.jar", "classpath": "my.sql.classpath.Driver" } }"""请注意:
jdbc_app_configs的预期输入为 JSON 字符串. 必须使用双引号 ("...") 来表示 JSON 字典 内 的密钥和值, 外 引号必须为"""、'''或'的格式。根据配置值的应用方式,可能需要不同形式的外引号。以下示例展示了两种应用外引号的独特方法。
通过 config.toml 文件应用的配置值:
jdbc_app_configs = """{"my_json_string": "value", "json_key_2": "value2"}"""通过 环境变量 应用的配置值:
DRIVERLESS_AI_JDBC_APP_CONFIGS='{"my_json_string": "value", "json_key_2": "value2"}'例如:
DRIVERLESS_AI_JDBC_APP_CONFIGS='{ "postgres": {"url": "jdbc:postgresql://192.xxx.x.xxx:aaaa:/name_of_database;user=name_of_user;password=your_password","jarpath": "/config/postgresql-xx.x.x.jar","classpath": "org.postgresql.Driver"}, "postgres-local": {"url": "jdbc:postgresql://123.xxx.xxx.xxx:aaaa/name_of_database","jarpath": "/config/postgresql-xx.x.x.jar","classpath": "org.postgresql.Driver"}, "ms-sql": {"url": "jdbc:sqlserver://192.xxx.x.xxx:aaaa;databaseName=name_of_database;user=name_of_user;password=your_password","Username":"your_username","passsword":"your_password","jarpath": "/config/sqljdbc42.jar","classpath": "com.microsoft.sqlserver.jdbc.SQLServerDriver"}, "oracle": {"url": "jdbc:oracle:thin:@192.xxx.x.xxx:aaaa/orclpdb1","jarpath": "ojdbc7.jar","classpath": "oracle.jdbc.OracleDriver"}, "db2": {"url": "jdbc:db2://127.x.x.x:aaaaa/name_of_database","jarpath": "db2jcc4.jar","classpath": "com.ibm.db2.jcc.DB2Driver"}, "mysql": {"url": "jdbc:mysql://192.xxx.x.xxx:aaaa;","jarpath": "mysql-connector.jar","classpath": "com.mysql.jdbc.Driver"}, "Snowflake": {"url": "jdbc:snowflake://<account_name>.snowflakecomputing.com/?<connection_params>","jarpath": "/config/snowflake-jdbc-x.x.x.jar","classpath": "net.snowflake.client.jdbc.SnowflakeDriver"}, "Derby": {"url": "jdbc:derby://127.x.x.x:aaaa/name_of_database","jarpath": "/config/derbyclient.jar","classpath": "org.apache.derby.jdbc.ClientDriver"} }'\
jdbc_app_jvm_args: 用于 JDBC 连接器的额外 jvm 参数。例如,”-Xmx4g”。jdbc_app_classpath: 可选择为 JDBC 连接器指定替代 classpath。enabled_file_systems: 您要启用的文件系统。为使数据连接器正常运行,必须进行此项配置。
获取 JDBC 驱动程序¶
下载 JDBC 驱动程序 JAR 文件:
请注意:请记录驱动程序 classpath,因为配置时需要使用(例如,org.postgresql.Driver)。
将驱动程序 JAR 文件复制到可挂载至 Docker 容器的位置。
请注意:存储 JDBC jar 文件的文件夹必须可见/可由 dai 进程用户读取。
启用 JDBC 连接器¶
此示例启用了 PostgresQL JDBC 连接器。请注意,JDBC 连接字符串因所使用的数据库而异。
nvidia-docker run \
--pid=host \
--init \
--rm \
--shm-size=256m \
--add-host name.node:172.16.2.186 \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,hdfs,jdbc" \
-e DRIVERLESS_AI_JDBC_APP_CONFIGS='{"postgres":
{"url": "jdbc:postgres://localhost:5432/my_database",
"jarpath": "/path/to/postgresql/jdbc/driver.jar",
"classpath": "org.postgresql.Driver"}}' \
-e DRIVERLESS_AI_JDBC_APP_JVM_ARGS="-Xmx2g" \
-p 12345:12345 \
-v /path/to/local/postgresql/jdbc/driver.jar:/path/to/postgresql/jdbc/driver.jar \
-v /etc/passwd:/etc/passwd:ro \
-v /etc/group:/etc/group:ro \
-v /tmp/dtmp/:/tmp \
-v /tmp/dlog/:/log \
-v /tmp/dlicense/:/license \
-v /tmp/ddata/:/data \
-u $(id -u):$(id -g) \
h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
本示例展示如何在 config.toml 文件中配置 JDBC 选项并在于 Docker 中启动 Driverless AI 时指定此文件。
配置 Driverless AI config.toml 文件。设置以下配置选项:
enabled_file_systems = "file, upload, jdbc" jdbc_app_configs = """{"postgres": {"url": "jdbc:postgres://localhost:5432/my_database", "jarpath": "/path/to/postgresql/jdbc/driver.jar", "classpath": "org.postgresql.Driver"}}"""
将 config.toml 文件和必需的 JAR 文件挂载至 Docker 容器。
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/jdbc/driver.jar:/path/in/docker/jdbc/driver.jar \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
此示例启用了 PostgresQL JDBC 连接器。
请注意:
JDBC 连接字符串因所使用的数据库而异。
此配置需要将 JSON 密钥(通常是要配置的数据库的名称)与包含
url、jarpath和classpath字段的嵌套 JSON 相关联。此外,应采用以下格式:"""{"my_jdbc_database": {"url": "jdbc:my_jdbc_database://hostname:port/database", "jarpath": "/path/to/my/jdbc/database.jar", "classpath": "com.my.jdbc.Driver"}}"""
导出 Driverless AI config.toml 文件或将其添加至 ~/.bashrc。例如:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
在 config.toml 文件中编辑以下值。
# File System Support # upload : standard upload feature # file : local file system/server file system # hdfs : Hadoop file system, remember to configure the HDFS config folder path and keytab below # dtap : Blue Data Tap file system, remember to configure the DTap section below # s3 : Amazon S3, optionally configure secret and access key below # gcs : Google Cloud Storage, remember to configure gcs_path_to_service_account_json below # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below # minio : Minio Cloud Storage, remember to configure secret and access key below # snow : Snowflake Data Warehouse, remember to configure Snowflake credentials below (account name, username, password) # kdb : KDB+ Time Series Database, remember to configure KDB credentials below (hostname and port, optionally: username, password, classpath, and jvm_args) # azrbs : Azure Blob Storage, remember to configure Azure credentials below (account name, account key) # jdbc: JDBC Connector, remember to configure JDBC below. (jdbc_app_configs) # hive: Hive Connector, remember to configure Hive below. (hive_app_configs) # recipe_url: load custom recipe from URL # recipe_file: load custom recipe from local file system enabled_file_systems = "upload, file, hdfs, jdbc" # Configuration for JDBC Connector. # JSON/Dictionary String with multiple keys. # Format as a single line without using carriage returns (the following example is formatted for readability). # Use triple quotations to ensure that the text is read as a single string. # Example: # """{ # "postgres": { # "url": "jdbc:postgresql://ip address:port/postgres", # "jarpath": "/path/to/postgres_driver.jar", # "classpath": "org.postgresql.Driver" # }, # "mysql": { # "url":"mysql connection string", # "jarpath": "/path/to/mysql_driver.jar", # "classpath": "my.sql.classpath.Driver" # } # }""" jdbc_app_configs = """{"postgres": {"url": "jdbc:postgres://localhost:5432/my_database", "jarpath": "/path/to/postgresql/jdbc/driver.jar", "classpath": "org.postgresql.Driver"}}""" # extra jvm args for jdbc connector jdbc_app_jvm_args = "" # alternative classpath for jdbc connector jdbc_app_classpath = ""
完成后,保存更改,然后停止/重启 Driverless AI。
使用 JDBC 添加数据集¶
启用 JDBC 连接器后,您可以通过在 添加数据集(或拖放) 下拉菜单中选择 JDBC 来添加数据集。
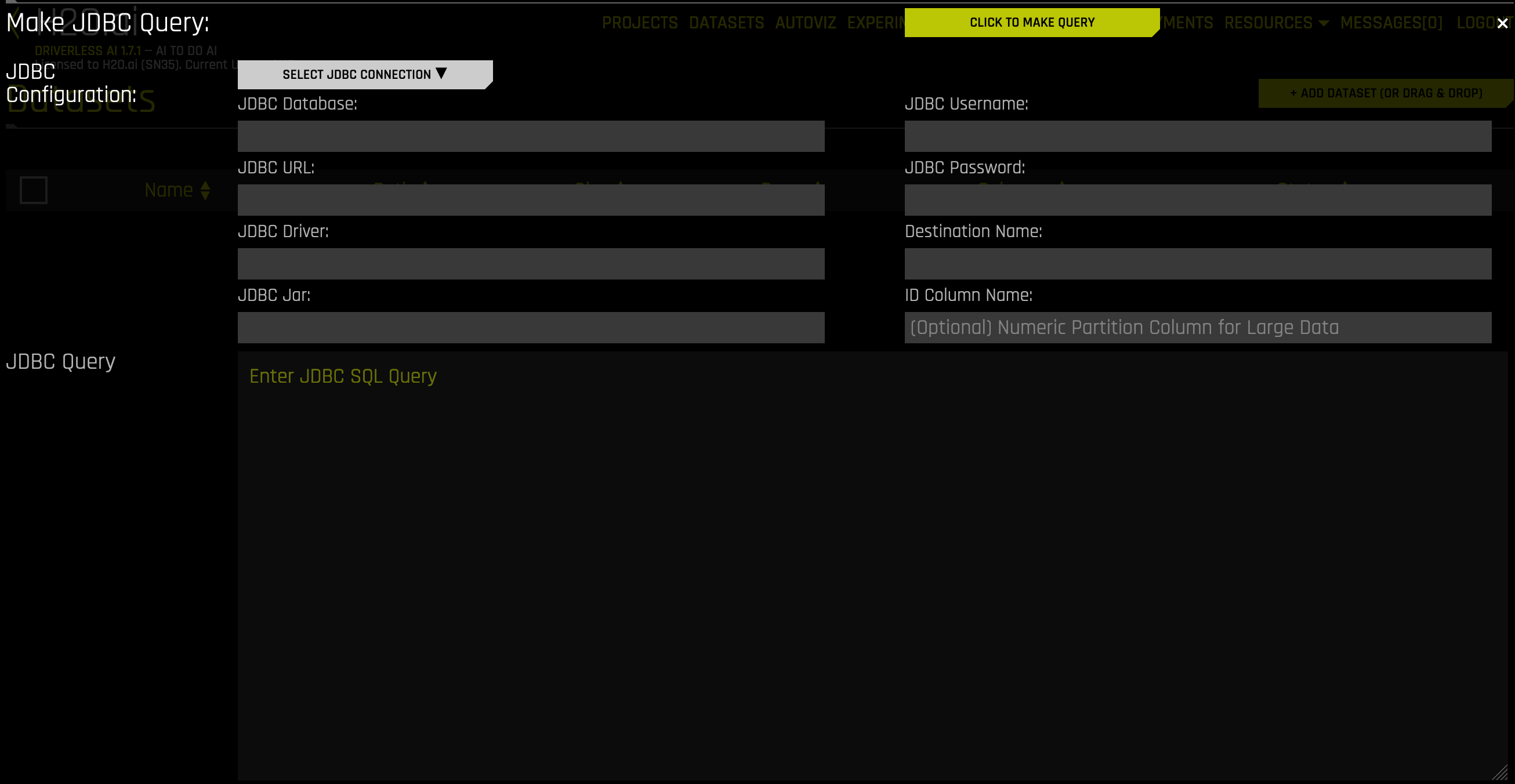
在“数据集”页面点击 添加数据集 按钮。
从显示的列表中选择 JDBC 。
点击 选择 JDBC 连接 按钮以选择 JDBC 配置。
此表单将使用 JDBC 数据库、URL、驱动程序和 Jar 信息进行填充。请填写以下剩余字段:
JDBC 用户名:输入您的 JDBC 用户名。
JDBC 密码 :输入您的 JDBC 密码。(请参见 请注意 部分)
目标名称:输入新数据集的名称。
(选填) ID 列名称 :输入 ID 列的名称。在进行大数据查询时需指定此字段。
请注意:
不要将密码作为 JDBC URL 的一部分。相反,在 JDBC 密码 字段中输入密码。为安全起见,单独输入密码。
由于 Driverless AI 内的资源共享,JDBC 连接器仅分配到相对较少的内存空间。
进行大型查询时,ID 列用于将数据划分成可管理的部分。此操作可确保不会超过最大内存分配。
如果在未指定 ID 列的情况下,执行了大于最大内存分配的查询,则此查询将无法成功完成。
以您想要查询的数据库的格式编写 SQL 查询。(请参阅下方的 查询示例 一节。)格式将因所使用的数据库而异。
点击 点击执行查询 按钮以执行查询。完成此操作所需的时间取决于要查询的数据大小和数据库的网络速度。
成功完成查询后,您将返回至“数据集”页面,并且查询到的数据将可作为新数据集使用。
查询示例¶
以下是 Oracle DB 和 PostgreSQL 的配置和查询示例:
配置:
jdbc_app_configs = """{"oracledb": {"url": "jdbc:oracle:thin:@localhost:1521/oracledatabase", "jarpath": "/home/ubuntu/jdbc-jars/ojdbc8.jar", "classpath": "oracle.jdbc.OracleDriver"}}"""
查询示例:
从 选择 JDBC 连接 下拉菜单中选择 oracledb 。
JDBC 用户名:
oracleuserJDBC 密码:
oracleuserpasswordID 列名称:
查询:
SELECT MIN(ID) AS NEW_ID, EDUCATION, COUNT(EDUCATION) FROM my_oracle_schema.creditcardtrain GROUP BY EDUCATION请注意:由于此查询未指定 ID 列名称,因此将仅适用于小数据。但是,如果针对更大的数据进行查询,则可将 NEW_ID 列用作 ID 列。
点击 点击执行查询 按钮以执行查询。
配置:
jdbc_app_configs = """{"postgres": {"url": "jdbc:postgresql://localhost:5432/postgresdatabase", "jarpath": "/home/ubuntu/postgres-artifacts/postgres/Driver.jar", "classpath": "org.postgresql.Driver"}}"""
查询示例:
从 选择 JDBC 连接 下拉菜单中选择 postgres 。
JDBC 用户名:
postgres_userJDBC 密码:
pguserpasswordID 列名称:
id查询:
SELECT * FROM loan_level WHERE LOAN_TYPE = 5 (selects all columns from table loan_level with column LOAN_TYPE containing value 5)
点击 点击执行查询 按钮以执行查询。
添加未经测试的 JDBC 驱动程序¶
我们建议您尝试使用未经内部测试的 JDBC 驱动程序。
为您的数据库下载 JDBC jar 文件。
将 JDBC jar 文件移动至 DAI 可访问的位置。
使用 JDBC 特定的环境变量启动 Driverless AI Docker 映像。
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="upload,file,hdfs,s3,recipe_file,jdbc" \ -e DRIVERLESS_AI_JDBC_APP_CONFIGS="""{"my_jdbc_database": {"url": "jdbc:my_jdbc_database://hostname:port/database", "jarpath": "/path/to/my/jdbc/database.jar", "classpath": "com.my.jdbc.Driver"}}"""\ -e DRIVERLESS_AI_JDBC_APP_JVM_ARGS="-Xmx2g" \ -p 12345:12345 \ -v /path/to/local/postgresql/jdbc/driver.jar:/path/to/postgresql/jdbc/driver.jar \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
为您的数据库下载 JDBC jar 文件。
将 JDBC jar 文件移动至 DAI 可访问的位置。
配置 Driverless AI config.toml 文件。设置以下配置选项:
enabled_file_systems = "upload, file, hdfs, s3, recipe_file, jdbc" jdbc_app_configs = """{"my_jdbc_database": {"url": "jdbc:my_jdbc_database://hostname:port/database", "jarpath": "/path/to/my/jdbc/database.jar", "classpath": "com.my.jdbc.Driver"}}""" #Optional arguments jdbc_app_jvm_args = "" jdbc_app_classpath = ""
将 config.toml 文件和必需的 JAR 文件挂载至 Docker 容器。
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/jdbc/driver.jar:/path/in/docker/jdbc/driver.jar \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
为您的数据库下载 JDBC jar 文件。
将 JDBC jar 文件移动至 DAI 可访问的位置。
修改以下 config.toml 设置。请注意,当在 Docker 中启动 Driverless AI 时,可将这些设置指定为环境变量。
# enable the JDBC file system enabled_file_systems = "upload, file, hdfs, s3, recipe_file, jdbc" # Configure the JDBC Connector. # JSON/Dictionary String with multiple keys. # Format as a single line without using carriage returns (the following example is formatted for readability). # Use triple quotations to ensure that the text is read as a single string. # Example: jdbc_app_configs = """{"my_jdbc_database": {"url": "jdbc:my_jdbc_database://hostname:port/database", "jarpath": "/path/to/my/jdbc/database.jar", "classpath": "com.my.jdbc.Driver"}}""" # optional extra jvm args for jdbc connector jdbc_app_jvm_args = "" # optional alternative classpath for jdbc connector jdbc_app_classpath = ""
完成后,保存更改,然后停止/重启 Driverless AI。