Snowflake 设置¶
Driverless AI 允许您在 Driverless AI 应用程序内搜索 Snowflake 数据源。本节介绍如何配置 Driverless AI 与 Snowflake 配合使用。此设置要求您启用身份验证。如果您启用 Snowflake 连接器,文件系统将在 UI 中可用,但您无法使用无身份验证的连接器。
请注意:根据您所安装的 Docker 版本,在启动 Driverless AI Docker 映像时,使用 docker run --runtime=nvidia (>= Docker 19.03) 或 nvidia-docker (< Docker 19.03) 命令。使用 docker version 检查所使用的 Docker 版本。
配置属性说明¶
snowflake_account: Snowflake 帐户 IDsnowflake_user: 用于访问 Snowflake 帐户的用户名snowflake_password: 用于访问 Snowflake 帐户的密码enabled_file_systems: 您要启用的文件系统。为使数据连接器正常运行,必须进行此项配置。
启用有身份验证的 Snowflake¶
此示例通过传递 account 、user 和 password 变量启用有身份验证的 Snowflake 数据连接器。
nvidia-docker run \
--rm \
--shm-size=256m \
-e DRIVERLESS_AI_ENABLED_FILE_SYSTEMS="file,snow" \
-e DRIVERLESS_AI_SNOWFLAKE_ACCOUNT = "<account_id>" \
-e DRIVERLESS_AI_SNOWFLAKE_USER = "<username>" \
-e DRIVERLESS_AI_SNOWFLAKE_PASSWORD = "<password>"\
-u `id -u`:`id -g` \
-p 12345:12345 \
-v `pwd`/data:/data \
-v `pwd`/log:/log \
-v `pwd`/license:/license \
-v `pwd`/tmp:/tmp \
-v `pwd`/service_account_json.json:/service_account_json.json \
h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
此实例展示了如何在 config.toml 文件中配置 Snowflake 选项并在于 Docker 中启动 Driverless AI 时指定该文件。
配置 Driverless AI config.toml 文件。设置以下配置选项。
enabled_file_systems = "file, snow"
snowflake_account = "<account_id>"
snowflake_user = "<username>"
snowflake_password = "<password>"
将 config.toml 文件挂载至 Docker 容器。
nvidia-docker run \ --pid=host \ --init \ --rm \ --shm-size=256m \ --add-host name.node:172.16.2.186 \ -e DRIVERLESS_AI_CONFIG_FILE=/path/in/docker/config.toml \ -p 12345:12345 \ -v /local/path/to/config.toml:/path/in/docker/config.toml \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -v /tmp/dtmp/:/tmp \ -v /tmp/dlog/:/log \ -v /tmp/dlicense/:/license \ -v /tmp/ddata/:/data \ -u $(id -u):$(id -g) \ h2oai/dai-centos7-x86_64:1.10.1-cuda11.2.2.xx
此示例通过传递 account 、user 和 password 变量启用有身份验证的 Snowflake 数据连接器。
导出 Driverless AI config.toml 文件或将其添加至 ~/.bashrc。例如:
# DEB and RPM export DRIVERLESS_AI_CONFIG_FILE="/etc/dai/config.toml" # TAR SH export DRIVERLESS_AI_CONFIG_FILE="/path/to/your/unpacked/dai/directory/config.toml"
在 config.toml 文件中指定以下配置选项。
# File System Support # upload : standard upload feature # file : local file system/server file system # hdfs : Hadoop file system, remember to configure the HDFS config folder path and keytab below # dtap : Blue Data Tap file system, remember to configure the DTap section below # s3 : Amazon S3, optionally configure secret and access key below # gcs : Google Cloud Storage, remember to configure gcs_path_to_service_account_json below # gbq : Google Big Query, remember to configure gcs_path_to_service_account_json below # minio : Minio Cloud Storage, remember to configure secret and access key below # snow : Snowflake Data Warehouse, remember to configure Snowflake credentials below (account name, username, password) # kdb : KDB+ Time Series Database, remember to configure KDB credentials below (hostname and port, optionally: username, password, classpath, and jvm_args) # azrbs : Azure Blob Storage, remember to configure Azure credentials below (account name, account key) # jdbc: JDBC Connector, remember to configure JDBC below. (jdbc_app_configs) # hive: Hive Connector, remember to configure Hive below. (hive_app_configs) # recipe_url: load custom recipe from URL # recipe_file: load custom recipe from local file system enabled_file_systems = "file, snow" # Snowflake Connector credentials snowflake_account = "<account_id>" snowflake_user = "<username>" snowflake_password = "<password>"
完成后,保存更改,然后停止/重启 Driverless AI。
使用 Snowflake 添加数据集¶
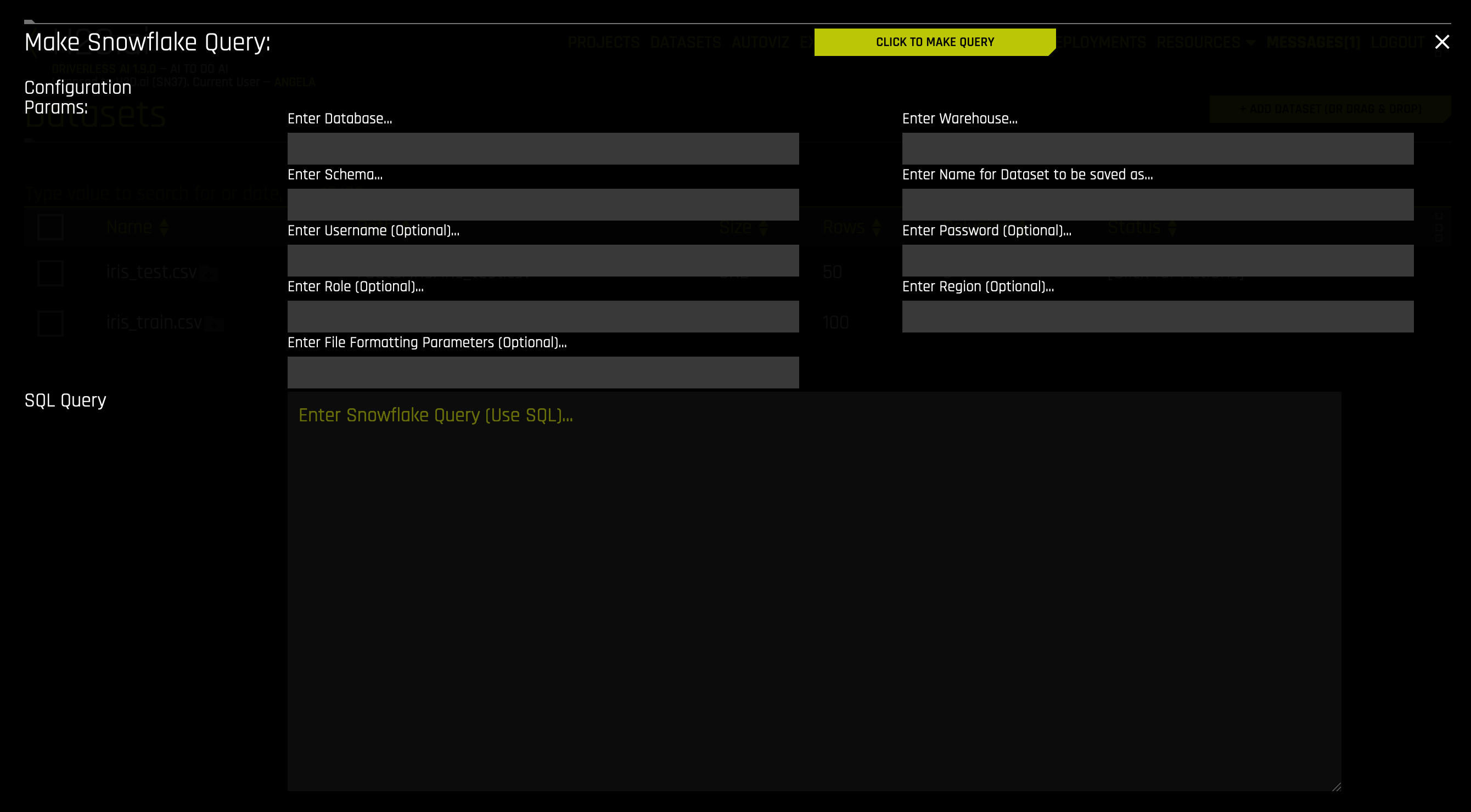
在 Snowflake 连接器启用后,您可以通过在 添加数据集(或拖放) 下拉菜单中选择 Snowflake 来添加数据集。

指定以下信息以添加数据集。
输入数据库:指定您所查询的 Snowflake 数据库名称。
输入数据仓库:指定您所查询的 Snowflake 数据仓库名称。
输入模式:指定您所查询的数据集模式。
输入将被另存为的数据集的名称:指定保存数据集时使用的名称。注意此名称只能为 CSV 文件(例如,myfile.csv)。
输入用户名:(选填)指定与此 Snowflake 帐户相关的用户名。如果启动 Driverless AI 时在 config.toml 中指定了
snowflake_user,则可将此字段保留为空,否则,此字段为必填字段。输入密码:(选填)指定与此 Snowflake 帐户相关的密码。如果启动 Driverless AI 时在 config.toml 中指定了
snowflake_password,则可将此字段保留为空,否则,此字段为必填字段。输入角色:(选填)按照 Snowflake 中的要求指定您的角色。更多信息,请访问 https://docs.snowflake.net/manuals/user-guide/security-access-control-overview.html。
输入区域:(选填)指定您所查询数据仓库的区域。在 Snowflake 提供用于访问数据库的 URL 中(<optional-deployment-name>.<region>.<cloud-provider>.snowflakecomputing.com 中)可以找到此区域。此字段为选填字段,如果启动 Driverless AI 时为
snowflake_url指定了<region>,则也可将此字段保留为空。输入文件格式化参数:(选填)指定用于格式化数据集的任何附加参数。https://docs.snowflake.com/en/sql-reference/sql/create-file-format.html#type-csv 中列出了可用的参数。(请注意:只将参数用于
TYPE = CSV. )例如,如果您的数据集中有一个包含逗号的文本列,则可以通过使用FIELD_DELIMITER='character'指定不同的分隔符。多个参数必须使用空格分隔:
FIELD_DELIMITER=',' FIELD_OPTIONALLY_ENCLOSED_BY="" SKIP_BLANK_LINES=TRUE请注意:务必确保指定的分隔符没有被用作单元格内的字符。否则,会发生错误。例如,您可能指定以下内容以加载 “AMAZON_REVIEWS” 数据集:
数据库:UTIL_DB
数据仓库:DAI_SNOWFLAKE_TEST
模式:AMAZON_REVIEWS_SCHEMA
查询:SELECT * FROM AMAZON_REVIEWS
输入文件格式化参数(选填):FIELD_OPTIONALLY_ENCLOSED_BY = ‘”’
在上例中,如果未设置
FIELD_OPTIONALLY_ENCLOSED_BY选项,以下行会导致无法导入数据集(因为默认的数据集分隔符为,):positive, 2012-05-03,Wonderful\, tasty taffy,0,0,3,5,2012,Thu,0请注意:Snowflake 中具有空值的数值列有时会被转换为字符串(例如 \ \N )。为防止此事件发生,将
NULL_IF=()添加到“文件格式化参数”的输入中。
输入 Snowflake 查询:指定您想执行的 Snowflake 查询。
完成后,选择 单击以执行查询 按钮以添加数据集。